隆重推出卷積類神經網路
在建構圖片分類模型時,我們發現卷積類神經網路 (CNN) 可用於逐步擷取圖片內容的更高層級表示法,這項發現為建構模型帶來突破。與其事先處理資料來擷取紋理和形狀等特徵,不如讓 CNN 只將圖片的原始像素資料做為輸入內容,並「學習」如何擷取這些特徵,最後推斷這些特徵所構成的物件。
首先,CNN 會接收輸入特徵圖:三維矩陣,其中前兩個維度的大小對應圖片的長度和寬度 (以像素為單位)。第三個維度的大小為 3 (對應於彩色圖片的 3 個通道:紅色、綠色和藍色)。CNN 包含一組模組,每個模組都會執行三項作業。
1. 卷積
卷積運算會擷取輸入特徵圖的圖塊,並套用篩選器來計算新特徵,產生輸出特徵圖或卷積特徵 (可能與輸入特徵圖的大小和深度不同)。卷積函數由兩個參數定義:
- 擷取的圖塊大小 (通常為 3x3 或 5x5 像素)。
- 輸出地圖特徵深度,對應於套用的濾鏡數量。
在卷積期間,濾鏡 (矩陣大小與圖塊大小相同) 會有效地在輸入特徵圖的格線上水平和垂直滑動,每次一個像素,擷取每個對應的圖塊 (請見圖 3)。
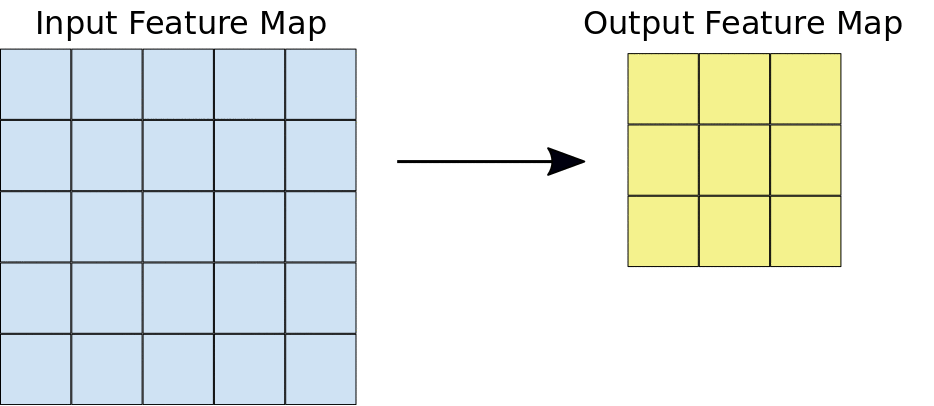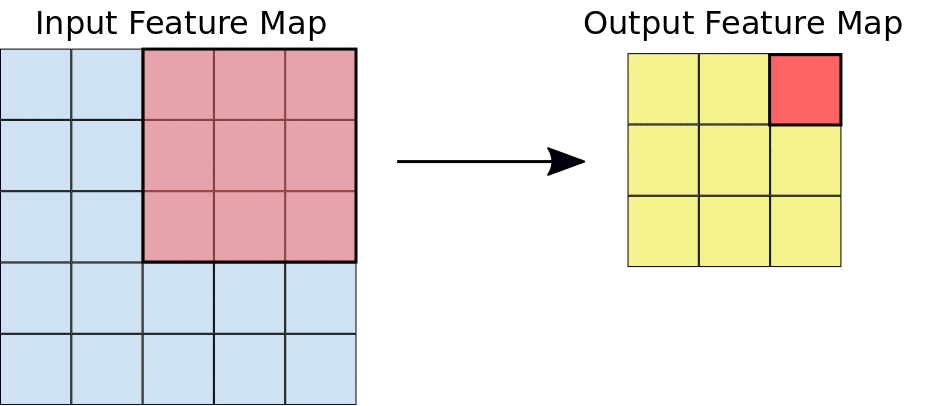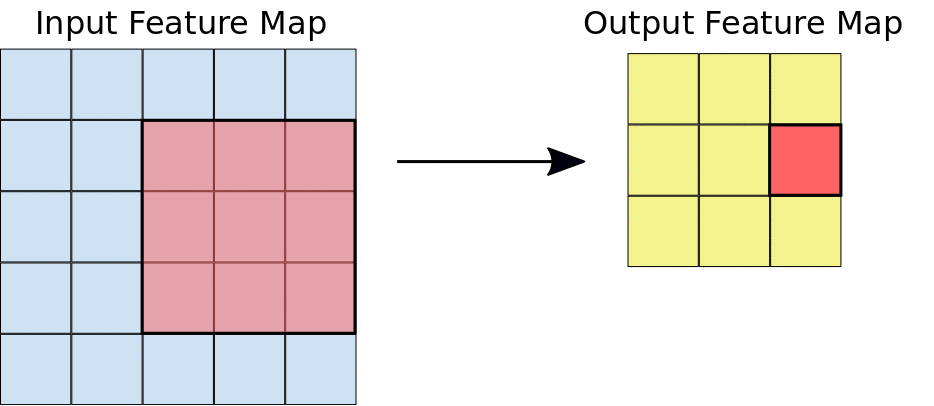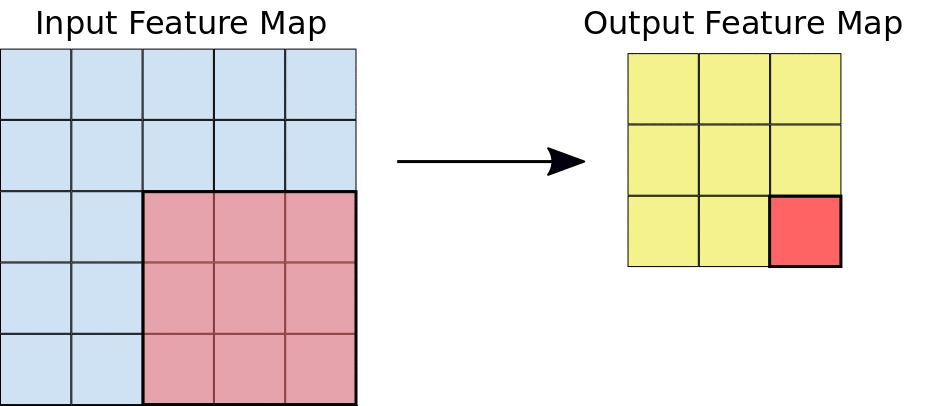 圖 3. 在 5x5 輸入特徵圖 (同樣深度 1) 上執行深度 1 的 3x3 卷積運算。從 5x5 特徵圖中擷取圖塊時,可能會出現九個 3x3 位置,因此這項卷積運算法會產生 3x3 輸出特徵圖。
圖 3. 在 5x5 輸入特徵圖 (同樣深度 1) 上執行深度 1 的 3x3 卷積運算。從 5x5 特徵圖中擷取圖塊時,可能會出現九個 3x3 位置,因此這項卷積運算法會產生 3x3 輸出特徵圖。
對於每個濾鏡區塊組合,CNN 會對濾鏡矩陣和區塊矩陣執行元素相乘運算,然後將結果矩陣的所有元素加總,以取得單一值。每個濾鏡方塊組合的結果值都會在卷積特徵矩陣中輸出 (請參閱圖 4a 和 4b)。
 圖 4a. 左側:5x5 輸入特徵圖 (深度 1)。右側:3x3 卷積運算 (深度 1)。
圖 4a. 左側:5x5 輸入特徵圖 (深度 1)。右側:3x3 卷積運算 (深度 1)。
圖 4b. 左側:在 5x5 輸入特徵圖上執行 3x3 卷積運算。右側:產生的卷積特徵。按一下輸出地圖中的值,查看計算方式。
在訓練期間,CNN 會「學習」濾鏡矩陣的最佳值,進而從輸入特徵圖中擷取有意義的特徵 (紋理、邊緣、形狀)。隨著套用至輸入內容的濾鏡數量 (輸出特徵圖深度) 增加,CNN 可擷取的特徵數量也會隨之增加。不過,篩選器會消耗 CNN 大部分的資源,因此隨著新增更多篩選器,訓練時間也會增加。此外,新增至網路的每個篩選器提供的增量值都比前一個低,因此工程師的目標是建構網路,使用最少的篩選器來擷取精確圖像分類所需的特徵。
2. ReLU
在每個卷積運算之後,CNN 會將修正線性單元 (ReLU) 轉換套用至卷積特徵,以便在模型中引入非線性。ReLU 函式 \(F(x)=max(0,x)\)會針對所有 x > 0 的值傳回 x,並針對所有 x ≤ 0 的值傳回 0。
3. 彙整
ReLU 之後是匯總步驟,其中 CNN 會將卷積特徵降樣 (以節省處理時間),減少特徵圖的維度數量,同時保留最重要的特徵資訊。這項程序常用的演算法稱為「最大值匯集」。
最大值池化運作方式與卷積類似。我們會滑過地圖,並擷取指定大小的圖塊。針對每個資訊方塊,最大值會輸出至新的地圖特徵,所有其他值都會遭到捨棄。最大彙整作業會採用兩個參數:
- 最大匯集篩選器的大小 (通常為 2x2 像素)
- Stride:每個擷取圖塊之間的距離 (以像素為單位)。與卷積不同,卷積會逐像素地在特徵圖上滑動過濾器,而在最大匯集中,步幅會決定每個圖塊的擷取位置。對於 2x2 濾鏡,步幅 2 會指定最大匯集作業會從特徵圖中擷取所有不重疊的 2x2 圖塊 (請參閱圖 5)。
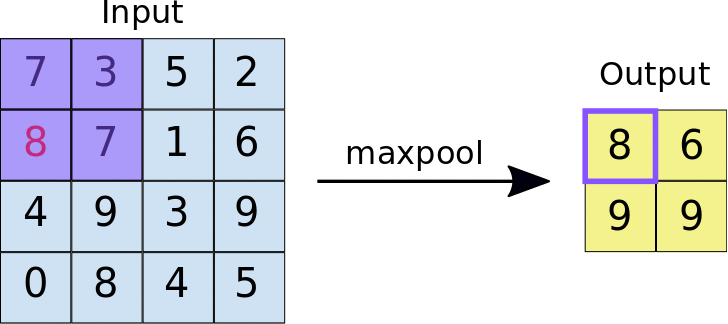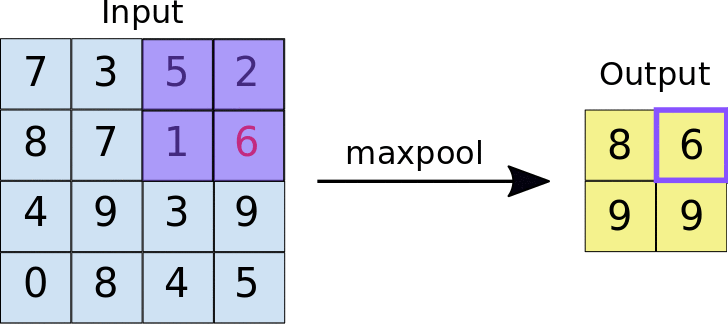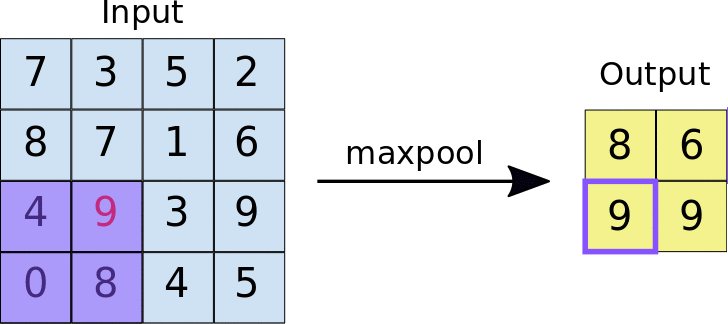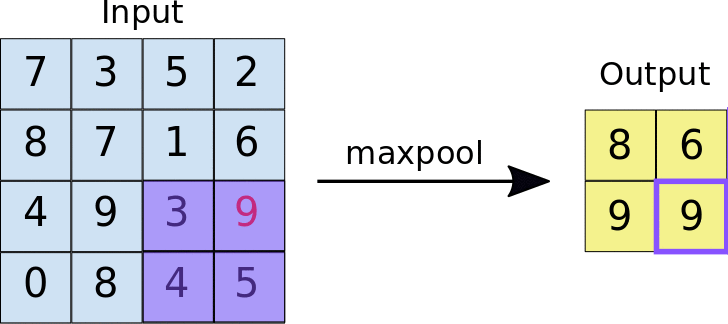
圖 5. 左側:在 4x4 特徵圖上執行最大匯集,使用 2x2 濾鏡和 2 的步幅。右側:最大值池化作業的輸出結果。請注意,產生的地圖項目現在是 2x2,只保留每個圖塊的最大值。
全連接層
卷積神經網路的結尾處有一或多個完全連結的層 (當兩個層「完全連結」時,第一層中的每個節點都會連結至第二層中的每個節點)。他們的工作是根據卷積運算所擷取的特徵執行分類作業。通常,最終的完全連結層會包含 softmax 活化函式,為模型嘗試預測的每個分類標籤輸出 0 到 1 之間的機率值。
圖 6 說明卷積神經網路的端對端結構。

圖 6. 這裡顯示的 CNN 包含兩個卷積模組 (卷積 + ReLU + 彙整),用於提取特徵,以及兩個全連結層,用於分類。其他卷積神經網路可能包含較多或較少的卷積模組,以及較多或較少的完全連結層。工程師經常會進行實驗,找出最能為模型帶來最佳結果的設定。