Konwolucyjne sieci neuronowe
Przełom w budowaniu modeli do klasyfikacji obrazów nastąpił wraz z odkryciem, że splotowa sieć neuronowa (CNN) może być używana do stopniowego wyodrębniania coraz bardziej złożonych reprezentacji zawartości obrazu. Zamiast przetwarzania danych w celu wyodrębnienia cech takich jak faktury i kształty, sieć CNN przyjmuje jako dane wejściowe tylko nieprzetworzone dane pikseli obrazu i „uczy się”, jak wyodrębnić te cechy, a na końcu ustala, jakiego obiektu one dotyczą.
Na początek sieć CNN otrzymuje mapę cech wejściowych: trójwymiarową macierz, w której rozmiar pierwszych dwóch wymiarów odpowiada długości i szerokości obrazów w pikselach. Rozmiar trzeciego wymiaru to 3 (odpowiadający 3 kanałom obrazu kolorowego: czerwonemu, zielonemu i niebieskiemu). Sieć CNN składa się z kompletnego zbioru modułów, z których każdy wykonuje 3 operacje.
1. Splot
Konwolucja wyodrębnia płytki z wejściowej mapy cech i stosuje do nich filtry, aby obliczyć nowe cechy, tworząc wyjściową mapę cech lub konwolutowaną cechę (która może mieć inny rozmiar i głębię niż wejściowa mapa cech). Konwolucje są definiowane przez 2 parametry:
- Rozmiar wyodrębnianych płytek (zwykle 3 x 3 lub 5 x 5 pikseli).
- Głębia mapy cech wyjściowych, która odpowiada liczbie zastosowanych filtrów.
Podczas splotu filtry (macierze o tym samym rozmiarze co rozmiar płytki) przesuwają się po siatce mapy cech wejściowych w kierunku poziomym i pionowym, po jednym pikselu naraz, wyodrębniając każdą odpowiadającą płytkę (patrz rys. 3).
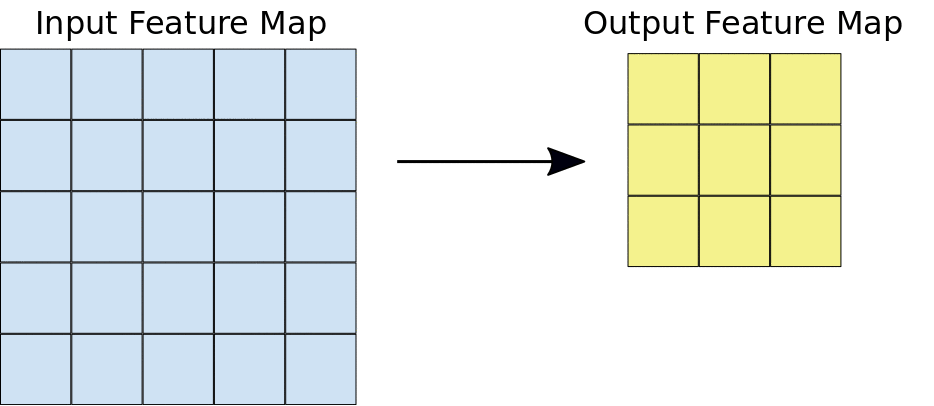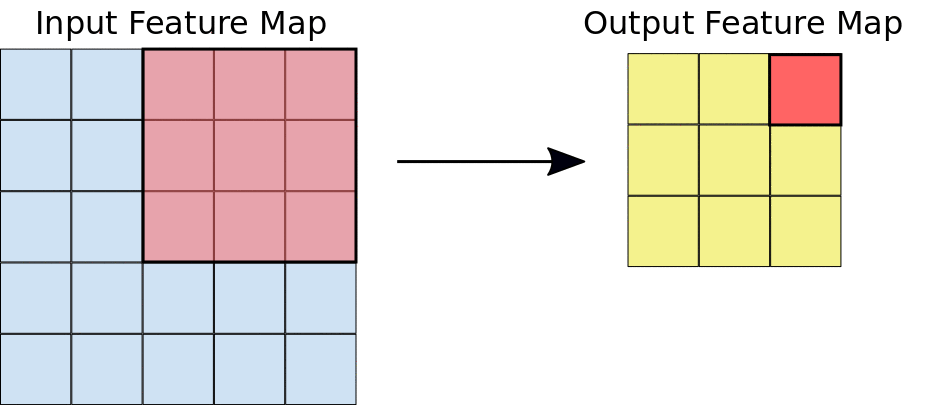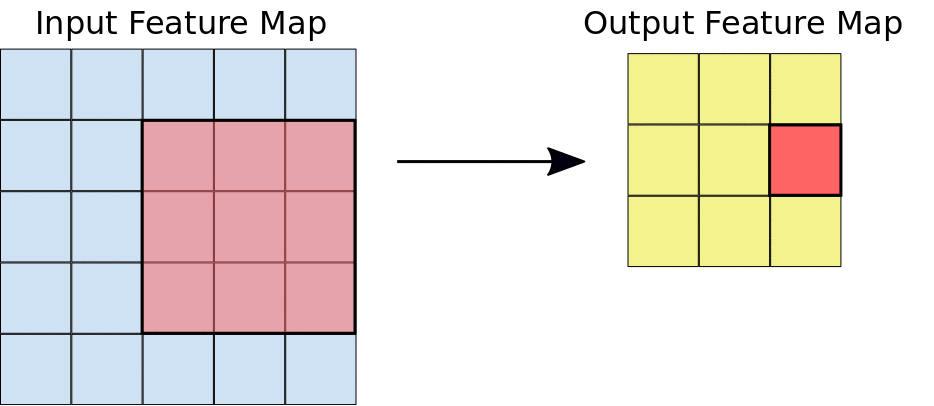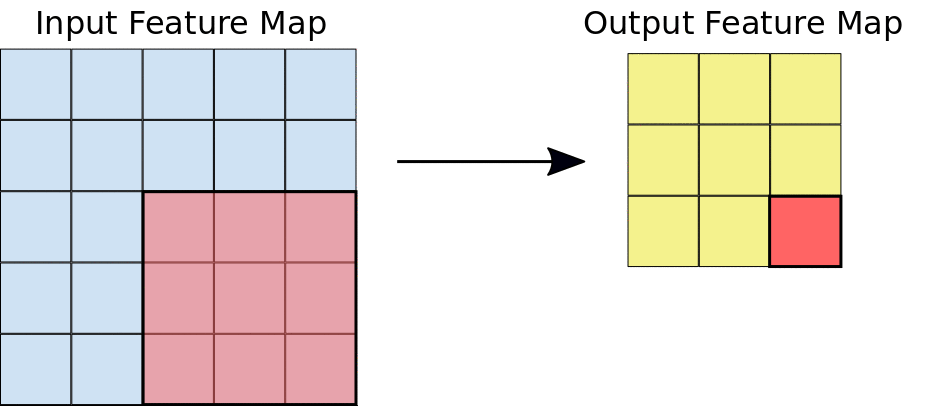 Rysunek 3. Konwolucja 3 x 3 o głębokości 1 wykonana na mapie cech wejściowych 5 x 5, która również ma głębokość 1. Z mapy cech 5 × 5 można wyodrębnić 9 miejsc o wymiarach 3 × 3, więc ta konwolucja wygeneruje mapę cech wyjściowych o wymiarach 3 × 3.
Rysunek 3. Konwolucja 3 x 3 o głębokości 1 wykonana na mapie cech wejściowych 5 x 5, która również ma głębokość 1. Z mapy cech 5 × 5 można wyodrębnić 9 miejsc o wymiarach 3 × 3, więc ta konwolucja wygeneruje mapę cech wyjściowych o wymiarach 3 × 3.
W przypadku każdej pary filtr–płytka sieć CNN wykonuje elementarne mnożenie macierzy filtra i macierzy płytki, a następnie sumuje wszystkie elementy powstałej macierzy, aby uzyskać pojedynczą wartość. Każda z tych wartości dla każdej pary filtrów i płytek jest następnie wyświetlana w formie macierzy zwiniętej cechy (patrz rysunki 4a i 4b).
 Rysunek 4a. Po lewej: mapa cech wejściowych 5 x 5 (głębia 1). Prawa: konwolucja 3 x 3 (głębokość 1).
Rysunek 4a. Po lewej: mapa cech wejściowych 5 x 5 (głębia 1). Prawa: konwolucja 3 x 3 (głębokość 1).
Ilustracja 4b. Po lewej: konwolucja 3 x 3 jest wykonywana na mapie cech wejściowych 5 x 5. Prawo: uzyskana funkcja sprzężona. Aby sprawdzić, jak została obliczona dana wartość na mapie cech wyjściowych, kliknij ją.
Podczas trenowania sieć CNN „uczy się” optymalnych wartości dla macierzy filtrów, które umożliwiają wyodrębnianie znaczących cech (tekstur, krawędzi, kształtów) z wejściowej mapy cech. Wraz ze wzrostem liczby filtrów (głębi mapy cech wyjściowych) stosowanych na dane wejściowe rośnie liczba cech, które może wyodrębnić sieć CNN. Jednak filtry stanowią większość zasobów wykorzystywanych przez sieć CNN, więc czas treningu również wydłuża się wraz z dodawaniem kolejnych filtrów. Dodatkowo każdy filtr dodany do sieci zapewnia mniejszą wartość przyrostową niż poprzedni, dlatego inżynierowie starają się konstruować sieci, które używają minimalnej liczby filtrów potrzebnych do wyodrębnienia cech niezbędnych do dokładnej klasyfikacji obrazów.
2. ReLU
Po każdej operacji konwolucji CNN stosuje do konwolutowanej cechy transformację ReLU (Rectified Linear Unit), aby wprowadzić do modelu nieliniowości. Funkcja ReLU, \(F(x)=max(0,x)\)zwraca x dla wszystkich wartości x > 0, a dla wszystkich wartości x ≤ 0 zwraca 0.
3. Zbiory
Po ReLU następuje etap zliczania, w którym sieć CNN zmniejsza próbkowanie zwiniętej cechy (aby zaoszczędzić czas przetwarzania), zmniejszając liczbę wymiarów mapy cech, zachowując przy tym najważniejsze informacje o cechach. Typowym algorytmem używanym w tym procesie jest maxpooling.
Maksymalne złączanie działa podobnie jak sprzężenie. Przesuwamy się po mapie funkcji i wyodrębniamy płytki o określonym rozmiarze. W przypadku każdego kafelka maksymalna wartość jest zapisywana w nowej mapie cech, a wszystkie inne wartości są odrzucane. Operacje z maksymalizowanym zbiorem zbiorczym przyjmują 2 parametry:
- Rozmiar filtra maksymalnego złączenia (zazwyczaj 2 x 2 piksele)
- Stride: odległość w pikselach między każdą wyodrębnioną płytką. W odróżnieniu od zastosowanej w konwolucji, w której filtry przesuwają się po mapie cech piksele po pikselu, w maksymalizacji zbiorczym krok określa miejsca, w których wyodrębniono poszczególne płytki. W przypadku filtra 2 x 2 krok 2 oznacza, że operacja maksymalnego złączania wyodrębni z mapy cech wszystkie nienachodzące się na siebie płytki 2 x 2 (patrz rys. 5).
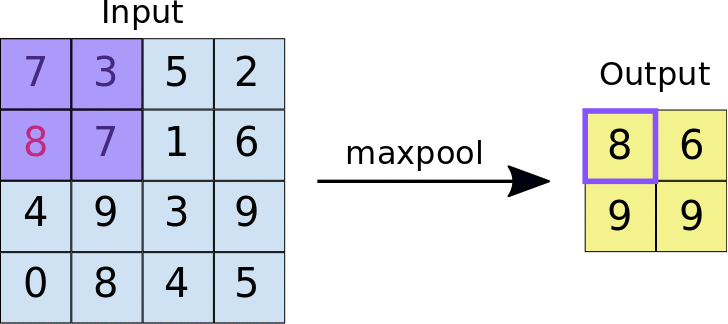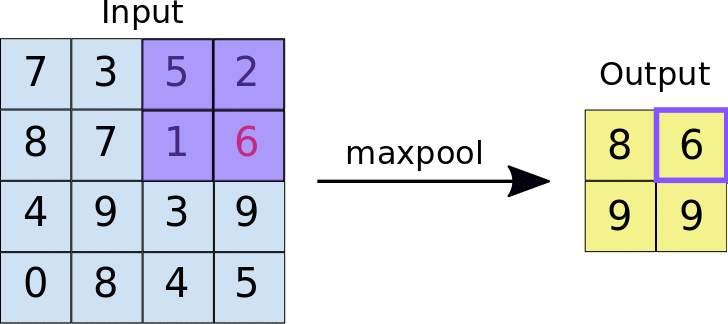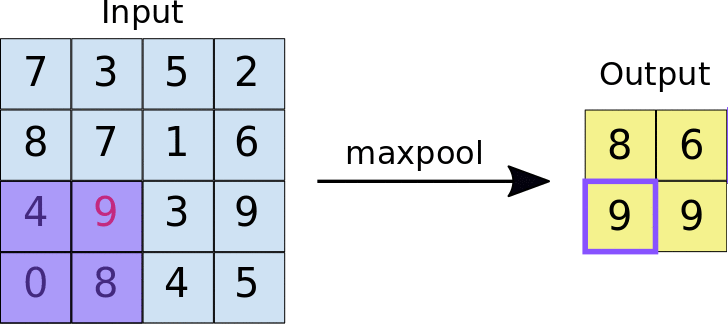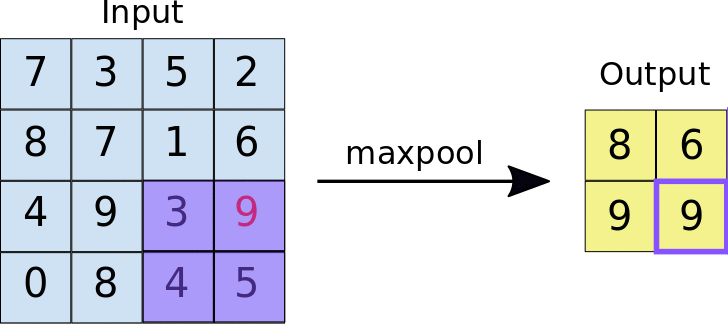
Ilustracja 5. Po lewej: maksymalne zwijanie wykonywane na mapie cech 4 × 4 z filtrem 2 × 2 i krok 2. Prawo: wynik operacji zgrupowania maksymalnego. Zwróć uwagę, że powstała mapa cech ma teraz wymiary 2 x 2 i zawiera tylko wartości maksymalne z każdej płytki.
Warstwy w pełni połączone
Na końcu sieci neuronowej konwolucyjnej znajduje się co najmniej 1 warstwę o pełnym połączeniu (gdy 2 warstwy są „w pełni połączone”, każdy węzeł w pierwszej warstwie jest połączony z każdym węzłem w drugiej warstwie). Ich zadaniem jest klasyfikowanie na podstawie cech wyodrębnionych przez operacje splotu. Ostatnia warstwa w pełni połączona zawiera zwykle funkcję aktywacji softmax, która dla każdej etykiety klasyfikacji, którą model próbuje przewidzieć, zwraca wartość prawdopodobieństwa z zakresu od 0 do 1.
Rysunek 6 przedstawia kompleksową strukturę sieci neuronowej splotkowej.

Rysunek 6. Wyświetlona tu sieć CNN zawiera 2 moduły sprzężone (sprzężenie + ReLU + zwijanie) do wyodrębniania cech oraz 2 warstwy w pełni połączone do klasyfikacji. Inne sieci CNN mogą zawierać większą lub mniejszą liczbę modułów konwolucyjnych oraz więcej lub mniej warstw w pełni połączonych. Inżynierowie często eksperymentują, aby znaleźć konfigurację, która przynosi najlepsze wyniki w przypadku ich modelu.