瞭解 Google 如何在 Google 相簿中開發最先進的圖片分類模型。取得卷積類神經網路的當機課程,然後自行建立圖片分類器,以便區分貓咪相片和狗相片。
必要條件
機器學習密集課程 或具備機器學習基礎知識的同等經驗
精通程式設計的基本知識,以及熟悉 Python 程式設計經驗
引言
Google 在 2013 年 5 月發布了個人相片搜尋,讓使用者能夠根據圖片中的物件擷取相片庫中的相片。
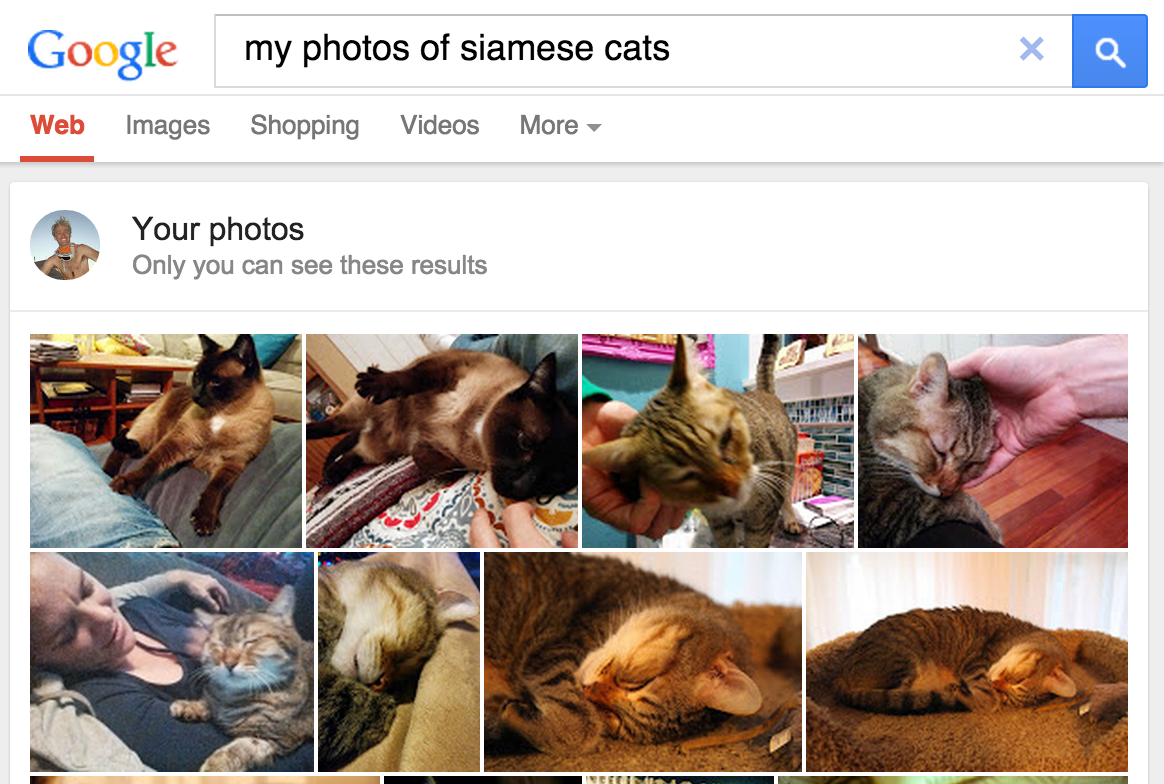 圖 1. 在 Google 相簿中搜尋「Siamese cats」(Siamese 貓) 送貨的商品!
圖 1. 在 Google 相簿中搜尋「Siamese cats」(Siamese 貓) 送貨的商品!
這項功能於 2015 年在 Google 相簿中導入,已廣泛改變,屬於一種改變遊戲的概念,也就是讓電腦視覺軟體能將圖片分類為人類標準,並新增多項功能:
- 使用者不再需要使用「beach」等標籤來標記相片,可將圖片內容分類,省去管理一百或上千張圖片組合的手動工作。
- 使用者可以使用新的方式探索相片集,方法是使用搜尋字詞以找出從未標記的物件。舉例來說,他們可能會搜尋「棕櫚樹」,以背景顯示棕櫚樹的所有假期相片。
- 軟體可能會「查看」使用者隔離的分類,可能無法察覺 (例如區分暹羅和阿斯汀貓),進而有效擴增使用者知識。
圖片分類的運作方式
圖片分類是一項受監督的學習問題:定義一組目標類別 (在圖片中識別的物件),並利用標籤的範例相片訓練模型來辨識。早期的電腦視覺模型仰賴原始像素資料做為模型的輸入內容。不過,如圖 2 所示,僅原始像素資料並未提供足夠的穩定表示法,能夠涵蓋在圖片中擷取的物件的各種變體。物件的位置、物體後方的背景、環境光度、相機角度和相機焦點都會產生原始像素資料中的波動;這些差異都很足夠,無法以像素 RGB 值的加權平均值加以修正。
 圖 2. 左:可拍攝各種姿勢下的相片在各種背景下進行拍攝,並具有不同的背景和光源條件。右:平均考量像素特徵後,並不會產生任何有意義的資訊。
圖 2. 左:可拍攝各種姿勢下的相片在各種背景下進行拍攝,並具有不同的背景和光源條件。右:平均考量像素特徵後,並不會產生任何有意義的資訊。
如要更靈活地建立物件,傳統版電腦視覺模型新增了從像素資料衍生的新功能,例如色彩直方圖、紋理和形狀。這個方法的缺點是,特徵工程會成為真正的負擔,因為許多輸入內容需要調整。以貓分類器來說,哪些顏色最相關?形狀定義的彈性?由於功能需要精確調整,因此建構穩固的模型非常困難,準確率也相當高。