Google が Google フォトの検索機能を強化する最先端の画像分類モデルをどのように開発したかをご覧ください。畳み込みニューラル ネットワークに関する集中講座を受講すると、猫の写真と犬の写真を区別する独自の画像分類器を構築できます。
Prerequisites
機械学習集中講座 または ML の基礎知識に関する同等の経験
プログラミングの基礎知識と Python を使ったコーディング経験
はじめに
2013 年 5 月、Google は個人の写真の検索をリリースし、ユーザーが画像内のオブジェクトに基づいてライブラリで写真を取得できるようになりました。
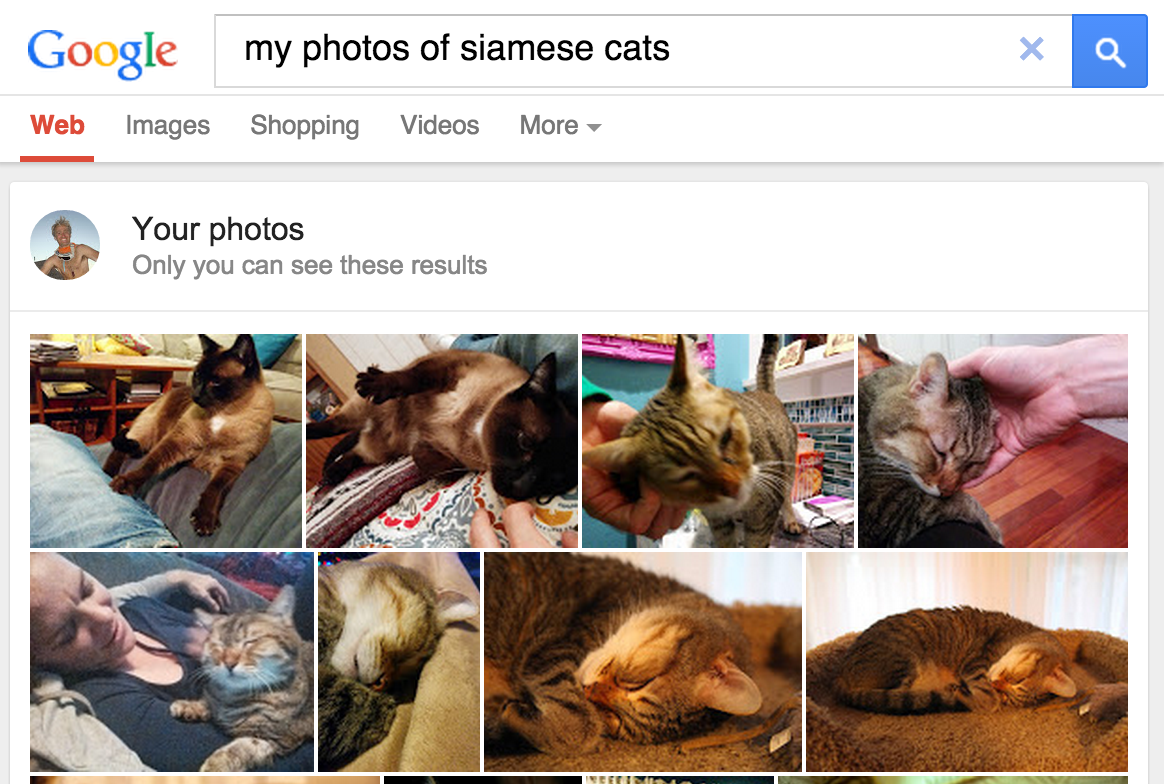 図 1. Google フォトでシャムネコが検索され、商品を届けてくれます!
図 1. Google フォトでシャムネコが検索され、商品を届けてくれます!
この機能は、2015 年に Google フォトに組み込まれましたが、ゲーム チェンジャーとして広く認識されるようになりました。概念実証とは、コンピュータ ビジョン ソフトウェアが画像を人間の基準に分類し、次のような方法で価値を高めることができる概念実証です。
- ユーザーは「beach」のようなラベルで写真をタグ付けする必要がなくなり、画像コンテンツを分類できます。これにより、数百から数千もの画像のセットを管理するのに非常に手間のかかる作業が不要になります。
- ユーザーは検索キーワードを使用して、これまでにない方法でタグが付けられている可能性がある写真を検索して検索できます。たとえば、「ヤシの木」と検索すると、背景にヤシの木がある休暇の写真がすべて表示されます。
- ソフトウェアでは、エンドユーザー自身が認識できない分類的識別(例: シャム猫とアビス猫を認識する)がユーザーに効果的に影響を及ぼし、ドメインに関する知識を増強する可能性があります。
画像分類の仕組み
画像分類は教師あり学習の問題です。ターゲット クラスのセット(画像内で識別するオブジェクト)を定義し、ラベル付けされたサンプル写真を使用してそれらを認識するようにモデルをトレーニングします。初期のコンピュータ ビジョン モデルは、生の入力データをモデルへの入力として使用していました。ただし、図 2 に示すように、元のピクセルデータだけでは、画像でキャプチャされたオブジェクトの無数のバリエーションを網羅するのに十分な安定性の表現は提供されません。オブジェクトの位置、オブジェクトの背後の背景、アンビエント ライティング、カメラアングル、カメラのフォーカスはすべて、生のピクセルデータに変動が生じる場合があります。この違いは十分にあり、ピクセル RGB 値の加重平均を取るだけでは補正できません。
 図 2. 左: さまざまな背景や照明条件で、猫の写真をさまざまなポーズで撮影できます。右: この多様性を考慮してピクセルデータを平均しても、有意義な情報は得られません。
図 2. 左: さまざまな背景や照明条件で、猫の写真をさまざまなポーズで撮影できます。右: この多様性を考慮してピクセルデータを平均しても、有意義な情報は得られません。
オブジェクトをより柔軟にモデル化するために、従来のコンピュータ ビジョン モデルでは、カラー ヒストグラム、テクスチャ、図形など、ピクセルデータから派生した新機能が追加されています。このアプローチの欠点は、調整する入力が大量にあり、特徴量エンジニアリングが大きな負担となったことです。猫の分類器の場合、どの色が最も関連性がありましたか。図形の定義の柔軟性。機能を正確に調整する必要があったため、堅牢なモデルの構築は非常に困難で、精度が損なわれました。