Dopo aver verificato che il problema sia risolto al meglio utilizzando un modello o un approccio all'IA generativa, puoi inquadrare il tuo problema in termini di ML. Puoi inquadrare un problema in termini di ML completando le seguenti attività:
- Definire il risultato ideale e l'obiettivo del modello.
- Identificare l'output del modello.
- Definisci le metriche di successo.
Definire il risultato ideale e l'obiettivo del modello
Indipendentemente dal modello ML, qual è il risultato ideale? In altre parole, che cos'è l'attività esatta che vuoi che venga eseguita con il tuo prodotto o la tua funzionalità? È lo stesso definita in precedenza nella sezione Indica l'obiettivo .
Collega l'obiettivo del modello al risultato ideale definendo esplicitamente ciò che che il modello faccia. La seguente tabella illustra i risultati ideali dell'obiettivo del modello per le app ipotetiche:
| App | Risultato ideale | Obiettivo del modello |
|---|---|---|
| App Meteo | Calcolare le precipitazioni con incrementi di sei ore per una regione geografica. | Prevedi le precipitazioni di sei ore in specifiche regioni geografiche. |
| App Moda | Genera vari modelli di magliette. | Genera tre varietà di design di una camicia a partire da un testo e da un'immagine, dove il testo indica lo stile e il colore e l'immagine è il tipo camicia (t-shirt, bottoni, polo). |
| App video | Consiglia video utili. | Prevedi se un utente farà clic su un video. |
| App di posta | Rilevare lo spam. | Prevedi se un'email è spam o meno. |
| App finanziaria | Riassumere le informazioni finanziarie provenienti da più fonti di notizie. | Genera riepiloghi di 50 parole delle principali tendenze finanziarie dal sette giorni precedenti. |
| App di mappe | Calcolare il tempo di percorrenza. | Prevedi il tempo che impiegherà per spostarsi tra due punti. |
| App di banca | Identificare le transazioni fraudolente. | Prevedi se è stata effettuata una transazione dal titolare della carta. |
| App di ristorazione | Indicare la cucina in base al menu di un ristorante. | Prevede il tipo di ristorante. |
| App e-commerce | Generare risposte dell'assistenza clienti sui prodotti dell'azienda. | Genera risposte utilizzando l'analisi del sentiment e knowledge base. |
Identifica l'output necessario
La scelta del tipo di modello dipende dal contesto e dai vincoli specifici il problema. L'output del modello deve svolgere l'attività definita nel un risultato ideale. Quindi, la prima domanda a cui rispondere è "Che tipo di output devo avere per risolvere il mio problema?"
Per classificare qualcosa o fare una previsione numerica, probabilmente usano l'ML predittivo. Se devi generare nuovi contenuti o produrre output alla comprensione del linguaggio naturale, probabilmente userai l'IA generativa.
Le seguenti tabelle elencano gli output ML predittivi e di IA generativa:
| Sistema ML | Output di esempio | |
|---|---|---|
| Classificazione | Binario | Classificare un'email come spam o non spam. |
| Etichetta singola multiclasse | Classificare un animale in un'immagine. | |
| Più etichette multiclasse | Classificare tutti gli animali presenti in un'immagine. | |
| Valori numerici | Regressione unidimensionale | Prevedere il numero di visualizzazioni che riceverà un video. |
| Regressione multidimensionale | Prevedi la pressione sanguigna, il battito cardiaco e i livelli di colesterolo per un individuo. |
| Tipo di modello | Output di esempio |
|---|---|
| Testo |
Riassumi un articolo. Rispondi alle recensioni dei clienti. Traduci documenti dall'inglese al mandarino. Scrivi le descrizioni dei prodotti. Analizzare i documenti legali.
|
| Immagine |
Realizza immagini di marketing. Applica effetti visivi alle foto. Generare varianti del design del prodotto.
|
| Audio |
Genera il dialogo con un accento specifico.
Generare una breve composizione musicale di un genere specifico, ad esempio
jazz.
|
| Video |
Genera video dall'aspetto realistico.
Analizza i filmati e applica effetti visivi.
|
| Multimodale | Produci più tipi di output, come un video con sottotitoli codificati di testo. |
Classificazione
Un modello di classificazione prevede a quale categoria appartengono i dati di input, ad esempio se un input devono essere classificate come A, B o C.
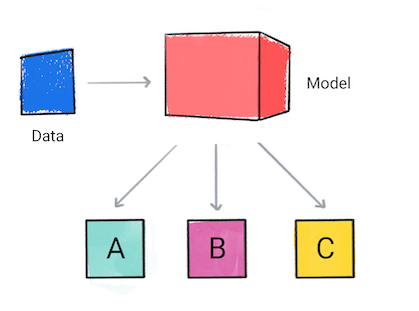
Figura 1. Un modello di classificazione che fa previsioni.
In base alla previsione del modello, la tua app potrebbe prendere una decisione. Ad esempio, se la previsione è la categoria A, quindi fai X; Se la previsione è la categoria B, fare, Y; se la previsione è la categoria C, fai Z. In alcuni casi, la previsione è l'output dell'app.
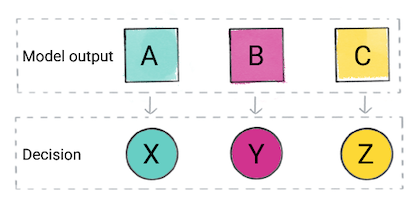
Figura 2. L'output di un modello di classificazione utilizzato nel codice del prodotto per prendere una decisione.
Regressione
Un modello di regressione prevede un valore numerico.
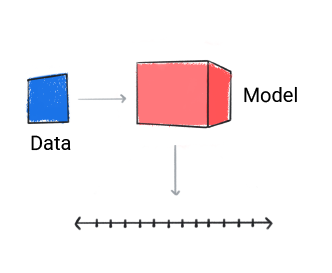
Figura 3. Un modello di regressione che esegue una previsione numerica.
In base alla previsione del modello, la tua app potrebbe prendere una decisione. Ad esempio, se la previsione rientra nell'intervallo A, fare X; se la previsione rientra nell'intervallo B, fare Y; se la previsione rientra nell'intervallo C, fare Z. In alcuni casi, previsione è l'output dell'app.
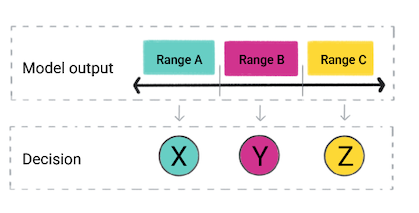
Figura 4. L'output di un modello di regressione utilizzato nel codice del prodotto per effettuare una decisione.
Tieni presente il seguente scenario:
Vuoi memorizzare nella cache video in base alla popolarità prevista. In altre parole, se il tuo modello prevede che un video diventerà popolare, vuoi mostrarlo rapidamente agli utenti. A al contrario, utilizzerai la cache più efficiente e costosa. Per gli altri video, userai un'altra cache. I criteri di memorizzazione nella cache sono i seguenti:
- Se si prevede che un video ottenga 50 o più visualizzazioni, verrà utilizzata la scheda .
- Se si prevede che un video ottenga tra 30 e 50 visualizzazioni, verrà utilizzato il modello economico .
- Se si prevede che il video otterrà meno di 30 visualizzazioni, non memorizzerai nella cache video.
Pensi che un modello di regressione sia l'approccio giusto perché prevederai un valore numerico, ovvero il numero di visualizzazioni. Tuttavia, quando si addestra la regressione ti rendi conto che produce lo stesso perdita per una previsione di 28 e 32 per i video che hanno 30 visualizzazioni. In altre parole, anche se la tua app avrà comportamento diverso se la previsione è 28 rispetto a 32, il modello considera previsioni altrettanto buone.
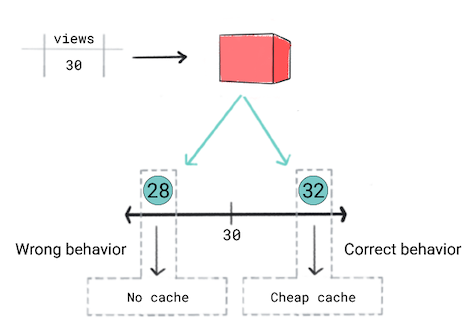
Figura 5. Addestramento di un modello di regressione.
I modelli di regressione non sono a conoscenza delle soglie definite dal prodotto. Pertanto, se il comportamento dell'app cambia in modo significativo a causa di lievi differenze di previsioni del modello di regressione, dovresti valutare l'implementazione di un modello di classificazione.
In questo scenario, un modello di classificazione produrrebbe il comportamento corretto perché un modello di classificazione produrrebbe una perdita maggiore per una previsione 28 di 32. In un certo senso, i modelli di classificazione producono soglie per impostazione predefinita.
Questo scenario evidenzia due punti importanti:
Prevedi la decisione. Se possibile, prevedi la decisione che prenderà la tua app . Nell'esempio del video, un modello di classificazione prevede decidere se le categorie in cui classificava i video fossero "senza cache", "economico Cache", e "cache costosa". Nascondere il comportamento dell'app dal modello può causare il comportamento errato della tua app.
Comprendi i vincoli del problema. Se la tua app richiede azioni basate su soglie diverse, determina se tali soglie sono fissi o dinamici.
- Soglie dinamiche: se le soglie sono dinamiche, utilizza un modello di regressione e imposta i limiti di soglia nel codice della tua app. In questo modo puoi facilmente Aggiornare le soglie, mantenendo comunque il modello ragionevole per le previsioni.
- Soglie fisse: se le soglie sono fisse, utilizza un modello di classificazione ed etichettare i set di dati in base ai limiti di soglia.
In generale, la maggior parte del provisioning della cache è dinamico e le soglie cambiano. nel tempo. Di conseguenza, poiché si tratta nello specifico di un problema di memorizzazione nella cache, di regressione lineare è la scelta migliore. Tuttavia, per molti problemi, le soglie saranno fisse, per cui un modello di classificazione sarà la soluzione migliore.
Esaminiamo un altro esempio. Se stai creando un'app meteo la cui
il risultato ideale è dire agli utenti quanto pioverà nelle prossime sei ore,
potresti utilizzare un modello di regressione che prevede l'etichetta precipitation_amount.
| Risultato ideale | Etichetta ideale |
|---|---|
| Indica agli utenti quanto pioverà nella loro zona le prossime sei ore. | precipitation_amount
|
Nell'esempio dell'app per il meteo, l'etichetta indica direttamente il risultato ideale.
Tuttavia, in alcuni casi, non è evidente una relazione one-to-one tra
il risultato ideale e l'etichetta. Ad esempio, nell'app video, il risultato ideale è
per consigliare video utili. Tuttavia, nel set di dati non sono presenti etichette
useful_to_user.
| Risultato ideale | Etichetta ideale |
|---|---|
| Consiglia video utili. | ? |
Pertanto, è necessario trovare un'etichetta proxy.
Etichette proxy
Le etichette proxy sostituiscono per
che non sono incluse nel set di dati. Le etichette del proxy sono necessarie quando non puoi
a misurare direttamente ciò che vuoi prevedere. Nell'app video non possiamo
misurare se un utente troverà utile un video. Sarebbe bello se le
aveva una funzionalità useful e gli utenti hanno contrassegnato tutti i video che hanno trovato
ma poiché il set di dati non lo fa, abbiamo bisogno di un'etichetta proxy che
sostituisce l'utilità.
Un'etichetta del proxy per essere utile potrebbe indicare se l'utente condividerà o apprezzerà il video.
| Risultato ideale | Etichetta del proxy |
|---|---|
| Consiglia video utili. | shared OR liked |
Fai attenzione alle etichette del proxy perché non misurano direttamente ciò che vuoi da prevedere. Ad esempio, la seguente tabella illustra i problemi etichette proxy per Consiglia video utili:
| Etichetta del proxy | Problema |
|---|---|
| Prevedi se l'utente farà clic sul pulsante "Mi piace" . | La maggior parte degli utenti non fa mai clic su "Mi piace". |
| Prevedi se un video diventerà popolare. | Non personalizzato. Alcuni utenti potrebbero non apprezzare i video popolari. |
| Prevedi se l'utente condividerà il video. | Alcuni utenti non condividono i video. A volte le persone condividono i video non gli piacciono. |
| Prevedi se l'utente farà clic sul pulsante di riproduzione. | Massimizza il clickbait. |
| Prevedere per quanto tempo guarda il video. | Favorisce i video lunghi rispetto a quelli brevi. |
| Prevedere quante volte l'utente guarderà nuovamente il video. | Predilige il "riguardabile" video su generi video che non possono essere riguardati. |
Nessuna etichetta proxy può sostituire il risultato ideale. Tutti potrebbero verificarsi problemi. Scegli quello che presenta i meno problemi per il tuo caso d'uso.
Verifica le tue conoscenze
Generazione
Nella maggior parte dei casi, non addestrerai il tuo modello generativo perché così facendo richiede enormi quantità di dati di addestramento e di risorse di calcolo. Invece, personalizzerai un modello generativo preaddestrato. Per far sì che un modello generativo produrre l'output desiderato, potrebbe essere necessario utilizzare uno o più dei seguenti tecniche:
Distillazione: Per creare un una versione più piccola di un modello più grande, viene generato un set di dati etichettato sintetico a partire dal modello più grande che usi per addestrare il modello più piccolo. Generative sono generalmente enormi e consumano risorse sostanziali (come ed elettricità). La distillazione consente di ridurre il consumo di risorse per approssimare le prestazioni del modello più grande.
Ottimizzazione o ottimizzazione efficiente dei parametri. Per migliorare le prestazioni di un modello su un'attività specifica, devi ulteriormente il modello su un set di dati che contiene esempi del tipo di output che vuoi produrre.
Progettazione del prompt. A far eseguire al modello un'attività specifica produrre un output in un formato specifico, dici al modello l'attività che vuoi o spiegare come vuoi formattare l'output. In altre parole, del prompt può includere istruzioni in linguaggio naturale su come eseguire l'attività o esempi illustrativi con gli output desiderati.
Ad esempio, se vuoi brevi riepiloghi degli articoli, puoi inserire il seguenti:
Produce 100-word summaries for each article.Se vuoi che il modello generi testo per uno specifico livello di lettura, puoi inserire quanto segue:
All the output should be at a reading level for a 12-year-old.Se vuoi che il modello fornisca il suo output in un formato specifico, spiegare come deve essere formattato l'output, ad esempio "formatta il risultati in una tabella" oppure puoi dimostrare l'attività degli esempi. Ad esempio, potresti inserire quanto segue:
Translate words from English to Spanish. English: Car Spanish: Auto English: Airplane Spanish: Avión English: Home Spanish:______
La distillazione e l'ottimizzazione aggiornano parametri. Ingegneria del prompt non aggiorna i parametri del modello. Piuttosto, il prompt engineering aiuta del modello apprendono come produrre l'output desiderato dal contesto del prompt.
In alcuni casi, sarà necessaria anche una set di dati di test per valutare un dell'output del modello generativo rispetto a valori noti, ad esempio controllando che i riassunti del modello sono simili a quelli generati da persone fisiche o che valutano le persone i riassunti del modello.
L'IA generativa può essere usata anche per implementare un machine learning predittivo soluzione come la classificazione o la regressione. Ad esempio, a causa della loro profonda conoscenza del linguaggio naturale, modelli linguistici di grandi dimensioni (LLM) può eseguire spesso attività di classificazione del testo meglio del ML predittivo addestrato per l'attività specifica.
Definisci le metriche di successo
Definisci le metriche che userai per determinare se l'implementazione ML ha successo. Le metriche sul successo definiscono ciò che ti interessa, ad esempio il coinvolgimento o Aiutando gli utenti a intraprendere le azioni appropriate, ad esempio guardare video che troveranno utile. Le metriche di successo differiscono dalle metriche di valutazione del modello, ad esempio accuratezza, precisione, richiamo o AUC:
Ad esempio, le metriche di successo e fallimento dell'app meteo potrebbero essere definite le seguenti:
| Operazione riuscita | Gli utenti aprono il messaggio "Pioverà?" più spesso del 50% rispetto a prima. |
|---|---|
| Errore | Gli utenti aprono il messaggio "Pioverà?" una caratteristica non più spesso di in precedenza. |
Le metriche per app video possono essere definite come segue:
| Operazione riuscita | Gli utenti trascorrono in media il 20% di tempo in più sul sito. |
|---|---|
| Errore | In media, gli utenti non trascorrono più tempo sul sito rispetto a prima. |
Consigliamo di definire metriche di successo ambiziose. Ambizioni elevate possono causare lacune tra successo e fallimento. Ad esempio, gli utenti spendono in media Il 10% in più di tempo sul sito rispetto al passato non significa né successo né fallimento. Questo divario indefinito non è ciò che è importante.
È importante la capacità del modello di avvicinarsi, oppure la definizione di successo. Ad esempio, quando analizzi il modello del rendimento, considera la seguente domanda: Migliorare il modello ti più vicina ai criteri di successo che hai definito? Ad esempio, un modello potrebbe avere senza però avvicinarti ai criteri di successo, indicando che anche con un modello perfetto, non soddisferesti i criteri di successo che definito. D'altra parte, un modello potrebbe avere metriche di valutazione scadenti, ma ottenere i tuoi criteri di successo, il che indica che migliorare il modello per farti avvicinare al successo.
Di seguito sono riportate le dimensioni da considerare per determinare se il modello vale miglioramento:
Non è sufficiente, ma continua. Il modello non deve essere utilizzato in una nell'ambiente di produzione, ma nel tempo potrebbe essere migliorato significativamente.
Ottimo e continua. Il modello può essere utilizzato in un ambiente dell'ambiente e potrebbe essere ulteriormente migliorato.
Abbastanza buona, ma non si può migliorare. Il modello è in fase di produzione dell'ambiente, ma probabilmente è ottimale.
Non è abbastanza e non lo sarà mai. Il modello non deve essere utilizzato in una nell'ambiente di produzione e non è richiesta una quantità di addestramento specifica.
Quando decidi di migliorare il modello, rivaluta se l'aumento delle risorse, come il tempo di progettazione e i costi di calcolo, giustificano il miglioramento previsto del modello.
Dopo aver definito le metriche di successo e fallimento, devi determinare la frequenza potrai misurarle. Ad esempio, puoi misurare le tue metriche di successo giorni, sei settimane o sei mesi dopo l'implementazione del sistema.
Quando analizzi le metriche di errore, prova a determinare il motivo del malfunzionamento del sistema. Per Ad esempio, il modello potrebbe prevedere su quali video gli utenti faranno clic, ma potrebbe iniziare a consigliare titoli clickbait che stimolano il coinvolgimento degli utenti per gli utenti finali. Nell'esempio dell'app per il meteo, il modello potrebbe prevedere con precisione quando pioverà, ma per una regione troppo ampia.
Verifica le tue conoscenze
Un'azienda di moda vuole vendere più capi di abbigliamento. Qualcuno suggerisce di usare l'ML per determinare quali vestiti dovrebbe produrre l'azienda. Pensano di poter addestrare un modello per determinare quali tipi di vestiti sono di moda. Dopo il giorno quando addestra il modello, vuole applicarlo al proprio catalogo per quali vestiti realizzare.
Come dovrebbe inquadrare il suo problema in termini di ML?
Risultato ideale: determina quali prodotti fabbricare.
Obiettivo del modello: prevedere quali articoli di abbigliamento sono presenti moda.
Output del modello: classificazione binaria, in_fashion,
not_in_fashion
Metriche di successo: vendi il settanta per cento o più di capi di abbigliamento in cui viene eseguito il deployment.
Risultato ideale: consente di determinare la quantità di tessuti e materiali da ordinare.
Obiettivo del modello: prevedere la quantità di ciascun articolo da produrre.
Output del modello: classificazione binaria, make,
do_not_make
Metriche di successo: vendi il settanta per cento o più di capi di abbigliamento in cui viene eseguito il deployment.