Убедившись, что вашу проблему лучше всего решить с помощью прогнозного машинного обучения или генеративного подхода искусственного интеллекта, вы готовы сформулировать свою проблему в терминах машинного обучения. Вы формулируете проблему в терминах ML, выполняя следующие задачи:
- Определите идеальный результат и цель модели.
- Определите выходные данные модели.
- Определите показатели успеха.
Определите идеальный результат и цель модели.
Независимо от модели машинного обучения, каков идеальный результат? Другими словами, какую именно задачу вы хотите, чтобы ваш продукт или функция выполняли? Это то же утверждение, которое вы ранее определили в разделе «Установить цель» .
Свяжите цель модели с идеальным результатом, четко определив, чего вы хотите от модели. В следующей таблице указаны идеальные результаты и цель модели для гипотетических приложений:
| Приложение | Идеальный результат | Цель модели |
|---|---|---|
| Приложение погоды | Рассчитайте количество осадков с шагом в шесть часов для географического региона. | Прогнозируйте количество осадков за шесть часов для конкретных географических регионов. |
| Модное приложение | Создавайте разнообразные дизайны рубашек. | Создайте три варианта дизайна рубашки из текста и изображения, где в тексте указывается стиль и цвет, а в изображении — тип рубашки (футболка, рубашка на пуговицах, поло). |
| Видео приложение | Рекомендуйте полезные видео. | Предскажите, нажмет ли пользователь на видео. |
| Почтовое приложение | Обнаружение спама. | Прогнозируйте, является ли электронное письмо спамом. |
| Финансовое приложение | Обобщить финансовую информацию из нескольких источников новостей. | Составьте краткое изложение основных финансовых тенденций за предыдущие семь дней в 50 словах. |
| Приложение «Карта» | Рассчитать время в пути. | Предскажите, сколько времени займет путешествие между двумя точками. |
| Банковское приложение | Выявление мошеннических операций. | Предсказать, была ли транзакция совершена владельцем карты. |
| Обеденное приложение | Определите кухню по меню ресторана. | Предскажите тип ресторана. |
| Приложение для электронной коммерции | Создавайте ответы службы поддержки о продуктах компании. | Создавайте ответы, используя анализ настроений и базу знаний организации. |
Определите необходимый вам результат
Выбор типа модели зависит от конкретного контекста и ограничений вашей проблемы. Выходные данные модели должны выполнять задачу, определенную в идеальном результате. Таким образом, первый вопрос, на который нужно ответить: «Какой тип вывода мне нужен для решения моей проблемы?»
Если вам нужно что-то классифицировать или сделать числовой прогноз, вы, вероятно, будете использовать прогнозное машинное обучение. Если вам нужно создать новый контент или получить результаты, связанные с пониманием естественного языка, вы, вероятно, будете использовать генеративный ИИ.
В следующих таблицах перечислены результаты прогнозного машинного обучения и генеративного искусственного интеллекта:
| система машинного обучения | Пример вывода | |
|---|---|---|
| Классификация | Двоичный | Классифицируйте электронное письмо как спам или не спам. |
| Мультикласс с одной этикеткой | Классифицируйте животное по изображению. | |
| Мультикласс, мульти-метка | Классифицируйте всех животных на изображении. | |
| Числовой | Одномерная регрессия | Предскажите количество просмотров, которые получит видео. |
| Многомерная регрессия | Прогнозируйте артериальное давление, частоту сердечных сокращений и уровень холестерина для человека. |
| Тип модели | Пример вывода |
|---|---|
| Текст | Подведите итог статьи. Ответ на отзывы клиентов. Переведите документы с английского на китайский. Напишите описания товаров. Анализируйте юридические документы. |
| Изображение | Создание маркетинговых изображений. Применяйте визуальные эффекты к фотографиям. Создание вариантов дизайна продукта. |
| Аудио | Создавайте диалог с определенным акцентом. Создайте короткую музыкальную композицию в определенном жанре, например джазе. |
| Видео | Создавайте реалистичные видеоролики. Анализируйте видеоматериалы и применяйте визуальные эффекты. |
| Мультимодальный | Создавайте несколько типов вывода, например видео с текстовыми подписями. |
Классификация
Модель классификации предсказывает, к какой категории принадлежат входные данные, например, следует ли классифицировать входные данные как A, B или C.
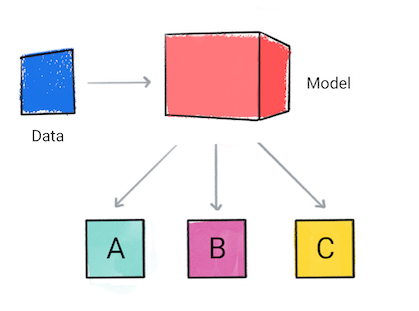
Рисунок 1. Модель классификации, делающая прогнозы.
На основе прогноза модели ваше приложение может принять решение. Например, если прогноз относится к категории А, сделайте X; если прогноз относится к категории B, то сделайте Y; если прогноз относится к категории C, выполните Z. В некоторых случаях прогноз является результатом работы приложения.
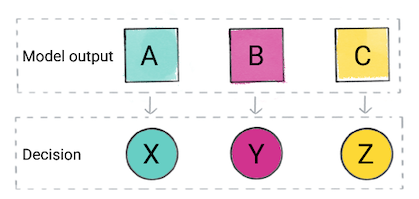
Рисунок 2. Выходные данные модели классификации используются в коде продукта для принятия решения.
Регрессия
Модель регрессии предсказывает числовое значение.
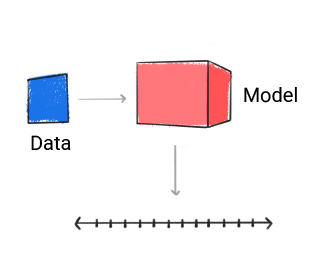
Рисунок 3. Регрессионная модель, делающая числовой прогноз.
На основе прогноза модели ваше приложение может принять решение. Например, если прогноз попадает в диапазон A, выполните X; если прогноз попадает в диапазон B, сделайте Y; если прогноз попадает в диапазон C, выполните Z. В некоторых случаях прогноз является выходными данными приложения.
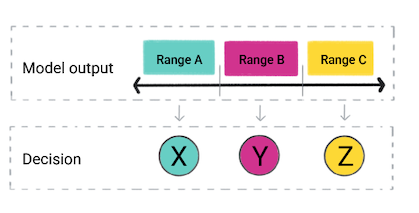
Рисунок 4. Выходные данные регрессионной модели используются в коде продукта для принятия решения.
Рассмотрим следующий сценарий:
Вы хотите кэшировать видео на основе их прогнозируемой популярности. Другими словами, если ваша модель предсказывает, что видео будет популярным, вы хотите быстро показать его пользователям. Для этого вы будете использовать более эффективный и дорогой кеш. Для других видео вы будете использовать другой кеш. Ваши критерии кэширования следующие:
- Если прогнозируется, что видео наберет 50 или более просмотров, вы будете использовать дорогой кеш.
- Если прогнозируется, что видео наберет от 30 до 50 просмотров, вы будете использовать дешевый кеш.
- Если прогнозируется, что видео наберет менее 30 просмотров, вы не будете кэшировать видео.
Вы считаете, что регрессионная модель — это правильный подход, поскольку вы будете прогнозировать числовое значение — количество просмотров. Однако при обучении регрессионной модели вы понимаете, что она приводит к одинаковым потерям для прогноза 28 и 32 для видео, имеющих 30 просмотров. Другими словами, хотя ваше приложение будет вести себя совершенно по-разному, если прогноз равен 28 и 32, модель считает оба прогноза одинаково хорошими.
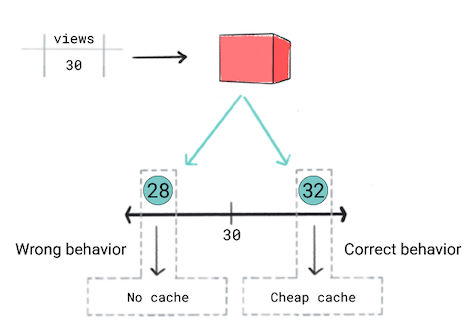
Рисунок 5. Обучение регрессионной модели.
Регрессионные модели не учитывают пороговые значения, определяемые продуктом. Поэтому, если поведение вашего приложения значительно меняется из-за небольших различий в прогнозах регрессионной модели, вам следует вместо этого рассмотреть возможность реализации модели классификации.
В этом сценарии модель классификации будет обеспечивать правильное поведение, поскольку модель классификации приведет к более высоким потерям для прогноза 28, чем 32. В некотором смысле модели классификации по умолчанию создают пороговые значения.
Этот сценарий подчеркивает два важных момента:
Прогнозируйте решение . По возможности предскажите, какое решение примет ваше приложение. В примере с видео модель классификации могла бы предсказать решение, если бы она классифицировала видео по категориям «без кэша», «дешевый кэш» и «дорогой кэш». Скрытие поведения вашего приложения из модели может привести к неправильному поведению вашего приложения.
Поймите ограничения проблемы . Если ваше приложение выполняет разные действия на основе разных пороговых значений, определите, являются ли эти пороговые значения фиксированными или динамическими.
- Динамические пороги. Если пороги являются динамическими, используйте модель регрессии и установите пределы порогов в коде вашего приложения. Это позволяет вам легко обновлять пороговые значения, сохраняя при этом модель, позволяющую делать разумные прогнозы.
- Фиксированные пороговые значения. Если пороговые значения фиксированы, используйте модель классификации и маркируйте свои наборы данных на основе пороговых ограничений.
Как правило, большая часть выделения кэша является динамической, и пороговые значения меняются со временем. Следовательно, поскольку это именно проблема кэширования, лучшим выбором будет регрессионная модель. Однако для многих проблем пороговые значения будут фиксированными, что делает модель классификации лучшим решением.
Давайте посмотрим на другой пример. Если вы создаете погодное приложение, идеальный результат которого — сообщить пользователям, сколько будет дождя в ближайшие шесть часов, вы можете использовать регрессионную модель, которая прогнозирует метку precipitation_amount.
| Идеальный результат | Идеальная этикетка |
|---|---|
| Сообщите пользователям, сколько дождей будет в их районе в ближайшие шесть часов. | precipitation_amount |
В примере с погодным приложением метка напрямую указывает на идеальный результат. Однако в некоторых случаях связь один к одному между идеальным результатом и ярлыком не очевидна. Например, в видеоприложении идеальный результат — рекомендовать полезные видео. Однако в наборе данных нет метки « useful_to_user.
| Идеальный результат | Идеальная этикетка |
|---|---|
| Рекомендуйте полезные видео. | ? |
Поэтому вам необходимо найти метку прокси.
Прокси-метки
Прокси-метки заменяют метки, которых нет в наборе данных. Прокси-метки необходимы, когда вы не можете напрямую измерить то, что хотите спрогнозировать. В видеоприложении мы не можем напрямую измерить, найдет ли пользователь видео полезным. Было бы здорово, если бы в наборе данных была useful функция, и пользователи отмечали все видео, которые они сочли полезными, но поскольку в наборе данных ее нет, нам понадобится прокси-метка, которая заменяет полезность.
Прокси-меткой полезности может быть то, будет ли пользователь делиться видео или нравится ему.
| Идеальный результат | Ярлык прокси |
|---|---|
| Рекомендуйте полезные видео. | shared OR liked |
Будьте осторожны с прокси-метками, поскольку они не измеряют напрямую то, что вы хотите спрогнозировать. Например, в следующей таблице показаны проблемы с потенциальными прокси-ярлыками для раздела «Рекомендовать полезные видео» :
| Ярлык прокси | Проблема |
|---|---|
| Предскажите, нажмет ли пользователь кнопку «Мне нравится». | Большинство пользователей никогда не нажимают «Мне нравится». |
| Прогнозируйте, будет ли видео популярным. | Не персонализированный. Некоторым пользователям могут не понравиться популярные видео. |
| Предскажите, поделится ли пользователь видео. | Некоторые пользователи не делятся видео. Иногда люди делятся видео, потому что они им не нравятся. |
| Предскажите, нажмет ли пользователь кнопку воспроизведения. | Максимизирует кликбейт. |
| Предскажите, как долго они будут смотреть видео. | Отдает предпочтение длинным видео по сравнению с короткими. |
| Предскажите, сколько раз пользователь будет пересматривать видео. | Предпочитает видео, которые можно пересматривать, а не видеожанры, которые нельзя пересматривать. |
Никакой прокси-лейбл не может стать идеальной заменой идеального результата. У всех будут потенциальные проблемы. Выберите тот, который вызывает меньше всего проблем для вашего варианта использования.
Проверьте свое понимание
Поколение
В большинстве случаев вы не будете обучать собственную генеративную модель, поскольку для этого требуются огромные объемы обучающих данных и вычислительных ресурсов. Вместо этого вы настроите предварительно обученную генеративную модель. Чтобы получить генеративную модель для получения желаемого результата, вам может потребоваться использовать один или несколько из следующих методов:
Дистилляция . Чтобы создать уменьшенную версию более крупной модели, вы создаете синтетический помеченный набор данных из более крупной модели, который вы используете для обучения меньшей модели. Генеративные модели обычно имеют гигантские размеры и потребляют значительные ресурсы (например, память и электричество). Дистилляция позволяет меньшей и менее ресурсоемкой модели приблизиться к производительности более крупной модели.
Точная настройка или настройка с эффективным использованием параметров . Чтобы повысить производительность модели при выполнении конкретной задачи, вам необходимо дополнительно обучить модель на наборе данных, содержащем примеры того типа выходных данных, который вы хотите получить.
Оперативный инжиниринг . Чтобы заставить модель выполнять определенную задачу или выдавать выходные данные в определенном формате, вы сообщаете модели задачу, которую вы хотите выполнить, или объясняете, как вы хотите отформатировать выходные данные. Другими словами, подсказка может включать в себя инструкции на естественном языке о том, как выполнить задачу, или наглядные примеры с желаемыми результатами.
Например, если вам нужны краткие обзоры статей, вы можете ввести следующее:
Produce 100-word summaries for each article.Если вы хотите, чтобы модель генерировала текст для определенного уровня чтения, вы можете ввести следующее:
All the output should be at a reading level for a 12-year-old.Если вы хотите, чтобы модель предоставляла выходные данные в определенном формате, вы можете объяснить, как следует форматировать выходные данные (например, «отформатировать результаты в таблице») или продемонстрировать задачу, приведя примеры. Например, вы можете ввести следующее:
Translate words from English to Spanish. English: Car Spanish: Auto English: Airplane Spanish: Avión English: Home Spanish:______
Дистилляция и тонкая настройка обновляют параметры модели. Оперативное проектирование не обновляет параметры модели. Вместо этого разработка подсказки помогает модели научиться получать желаемый результат из контекста подсказки.
В некоторых случаях вам также понадобится тестовый набор данных для оценки результатов генеративной модели по сравнению с известными значениями, например, для проверки того, что сводные данные модели аналогичны сводным данным, созданным человеком, или что люди оценивают сводные данные модели как хорошие.
Генеративный ИИ также можно использовать для реализации решений прогнозного машинного обучения, таких как классификация или регрессия. Например, благодаря глубокому знанию естественного языка модели большого языка (LLM) часто могут выполнять задачи классификации текста лучше, чем прогнозирующее машинное обучение, обученное для конкретной задачи.
Определите показатели успеха
Определите метрики, которые вы будете использовать, чтобы определить, является ли реализация машинного обучения успешной. Показатели успеха определяют, что вас волнует, например, вовлеченность или помощь пользователям в совершении соответствующих действий, например просмотре видео, которое они сочтут полезным. Показатели успеха отличаются от показателей оценки модели, таких как точность , точность , отзыв или AUC .
Например, показатели успеха и неудачи приложения погоды могут быть определены следующим образом:
| Успех | Пользователи открывают «Будет ли дождь?» появляются на 50 процентов чаще, чем раньше. |
|---|---|
| Отказ | Пользователи открывают «Будет ли дождь?» функция не чаще, чем раньше. |
Метрики видеоприложения можно определить следующим образом:
| Успех | Пользователи проводят на сайте в среднем на 20 процентов больше времени. |
|---|---|
| Отказ | Пользователи проводят на сайте в среднем не больше времени, чем раньше. |
Мы рекомендуем определить амбициозные показатели успеха. Однако высокие амбиции могут привести к разрыву между успехом и неудачей. Например, то, что пользователи проводят на сайте в среднем на 10 процентов больше времени, чем раньше, не является ни успехом, ни провалом. Неопределенный разрыв — это не то, что важно.
Что важно, так это способность вашей модели приближаться или превосходить определение успеха. Например, анализируя эффективность модели, рассмотрите следующий вопрос: приблизит ли улучшение модели к определенным вами критериям успеха? Например, модель может иметь отличные показатели оценки, но не приблизить вас к критериям успеха, а это означает, что даже при наличии идеальной модели вы не сможете соответствовать определенным вами критериям успеха. С другой стороны, модель может иметь плохие показатели оценки, но приближать вас к критериям успеха, указывая на то, что улучшение модели приблизит вас к успеху.
Ниже приведены параметры, которые следует учитывать при определении того, стоит ли улучшать модель:
Недостаточно хорошо, но продолжайте . Модель не следует использовать в производственной среде, но со временем она может быть значительно улучшена.
Достаточно хорошо, и продолжайте . Модель может быть использована в производственной среде и может быть дополнительно улучшена.
Достаточно хорошо, но лучше сделать невозможно . Модель находится в производственной среде, но, вероятно, она настолько хороша, насколько это возможно.
Недостаточно хорошо и никогда не будет . Модель не следует использовать в производственной среде, и никакое обучение, вероятно, не приведет к ее достижению.
Принимая решение об улучшении модели, еще раз оцените, оправдывает ли увеличение ресурсов, таких как время разработки и затраты на вычисления, прогнозируемое улучшение модели.
После определения показателей успеха и неудачи вам необходимо определить, как часто вы будете их измерять. Например, вы можете измерить показатели успеха через шесть дней, шесть недель или шесть месяцев после внедрения системы.
Анализируя метрики сбоев, попытайтесь определить, почему система вышла из строя. Например, модель может предсказывать, какие видео будут нажимать пользователи, но модель может начать рекомендовать кликбейтные заголовки, которые приводят к падению активности пользователей. В примере с погодным приложением модель может точно предсказать, когда пойдет дождь, но для слишком большого географического региона.
Проверьте свое понимание
Модная фирма хочет продавать больше одежды. Кто-то предлагает использовать машинное обучение, чтобы определить, какую одежду следует производить фирме. Они думают, что смогут научить модель определять, какая одежда сейчас в моде. После обучения модели они хотят применить ее к своему каталогу, чтобы решить, какую одежду шить.
Как им следует сформулировать свою проблему с точки зрения ОД?
Идеальный результат : определить, какую продукцию производить.
Цель модели : предсказать, какие предметы одежды сейчас в моде.
Выходные данные модели : бинарная классификация, in_fashion , not_in_fashion
Показатели успеха : Продавайте семьдесят или более процентов произведенной одежды.
Идеальный результат : Определите, сколько ткани и расходных материалов нужно заказать.
Цель модели : спрогнозировать, сколько каждого предмета нужно изготовить.
Выходные данные модели : двоичная классификация, make , do_not_make
Показатели успеха : Продавайте семьдесят или более процентов произведенной одежды.