在使用预测式机器学习或生成式 AI 方法验证您的问题的最佳解决方式后,您就可以用机器学习术语来表述问题了。您可以通过完成以下任务,用机器学习术语来界定问题:
- 定义理想结果和模型目标。
- 确定模型的输出。
- 定义成效指标。
指定理想结果和模型目标
独立于机器学习模型,理想的结果是什么?换句话说,您希望您的产品或功能执行的确切任务是什么?这与您之前在声明目标部分中定义的语句相同。
明确定义您希望模型执行的操作,将模型的目标与理想结果关联起来。下表说明了理想结果和模型对于假设应用的目标:
| 应用广告系列 | 理想成效 | 模型的目标 |
|---|---|---|
| 天气应用 | 计算某个地理区域的降水量(以 6 小时为增量)。 | 预测特定地理区域六小时的降水量。 |
| 时尚应用 | 生成各种衬衫设计。 | 根据文本和图片生成三种衬衫设计,其中文本指明了样式和颜色,图片表示衬衫的类型(T 恤、纽扣衬衫、马球)。 |
| 视频应用 | 推荐有用的视频。 | 预测用户是否会点击视频。 |
| “邮件”应用 | 检测垃圾内容。 | 预测电子邮件是否为垃圾邮件。 |
| 金融应用 | 汇总来自多个新闻媒体的财务信息。 | 生成包含过去 7 天的主要财务趋势的 50 字摘要。 |
| 地图应用 | 计算行程时间。 | 预测两点之间的行程需要多长时间。 |
| 银行应用 | 识别欺诈性交易。 | 预测持卡人是否进行了交易。 |
| 用餐应用 | 根据餐馆的菜单识别菜式。 | 预测餐馆的类型。 |
| 电子商务应用 | 生成有关公司产品的客户服务回复。 | 使用情感分析和组织的知识库生成回复。 |
确定所需的输出
您选择的模型类型取决于问题的具体情境和限制。模型的输出应完成理想结果中定义的任务。因此,第一个要回答的问题是 “我需要使用哪种类型的输出来解决我的问题?”
如果您需要对某事物进行分类或进行数值预测,则可能需要使用预测性机器学习。如果您需要生成与自然语言理解相关的新内容或输出,则可能需要使用生成式 AI。
下表列出了预测性机器学习和生成式 AI 的输出:
| 机器学习系统 | 输出示例 | |
|---|---|---|
| 分类 | 二进制 | 将电子邮件归类为垃圾邮件或非垃圾邮件。 |
| 多类单标签 | 对图片中的动物进行分类。 | |
| 多类多标签 | 对图片中的所有动物进行分类。 | |
| 数值 | 一维回归 | 预测视频将获得的观看次数。 |
| 多维回归 | 预测个人的血压、心率和胆固醇水平。 |
| 模型类型 | 输出示例 |
|---|---|
| 文本 |
总结一篇文章。 回复客户评价。 将文档从英语翻译成普通话。 撰写产品说明。 分析法律文件。
|
| 图片 |
生成营销图片。 为照片应用视觉效果。 生成产品设计变体。
|
| 音频 |
以特定口音生成对话。
生成特定流派的简短乐曲,如爵士。
|
| 视频 |
生成逼真的视频。
分析视频片段并应用视觉效果。
|
| 多模态 | 生成多种类型的输出,例如带有文本字幕的视频。 |
分类
分类模型可预测输入数据属于哪种类别,例如,某个输入应归类为 A、B 还是 C。
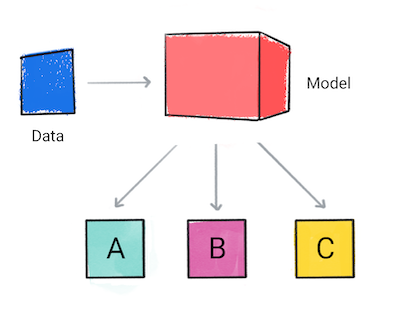
图 1. 进行预测的分类模型。
您的应用可能会根据模型的预测做出决定。例如,如果预测是类别 A,则执行 X;如果预测是类别 B,则执行 Y;如果预测是类别 C,则执行 Z。在某些情况下,预测是应用的输出。
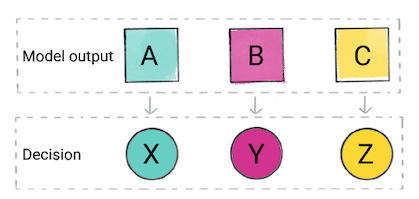
图 2. 产品代码中用于做出决策的分类模型的输出。
回归
回归模型可预测数值。
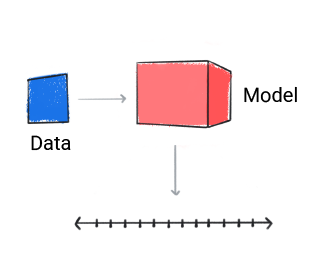
图 3. 进行数值预测的回归模型。
您的应用可能会根据模型的预测做出决定。例如,如果预测在范围 A 内,则执行 X;如果预测在 B 范围内,则执行 Y;如果预测在范围 C 内,则执行 Z。在某些情况下,预测是应用的输出。
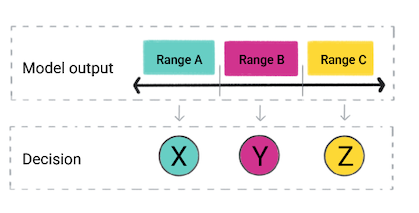
图 4. 回归模型的输出用于产品代码中做出决策。
请考虑以下场景:
您希望根据视频的预测热门程度缓存视频。换言之,如果您的模型预测某个视频会受欢迎,您想要快速将其投放给用户。为此,您将使用更有效且费用更高的缓存。对于其他视频 则需要使用不同的缓存您的缓存条件如下:
- 如果预测视频获得 50 次或更多观看次数,您将使用昂贵的缓存。
- 如果预测视频获得的观看次数为 30 到 50 次,您将使用费用较低的缓存。
- 如果预计视频获得的观看次数会少于 30 次,则不会缓存该视频。
您认为回归模型是正确的方法,因为您将预测一个数值,即观看次数。然而,在训练回归模型时,您发现对于观看次数为 30 的视频,预测值 28 和 32 所产生的损失相同。换言之,虽然在预测为 28 与 32 时应用的行为会截然不同,但模型认为这两个预测的质量相同。
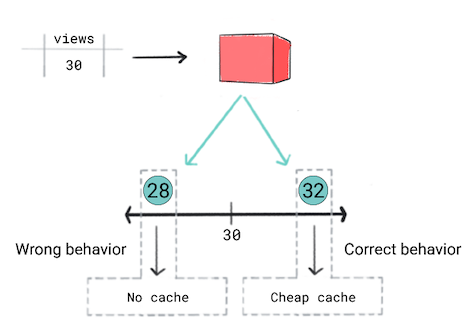
图 5. 训练回归模型。
回归模型不知道产品定义的阈值。因此,如果应用的行为因回归模型的预测结果存在细微差异而发生显著变化,则应考虑实现分类模型。
在这种情况下,分类模型会生成正确的行为,因为分类模型在预测为 28 时的损失要高于 32 的预测。从某种意义上讲,分类模型会默认生成阈值。
此场景突出显示了两个要点:
预测决定。如果可能,预测您的应用将采取的决策。在视频示例中,如果将视频分类为“无缓存”“廉价缓存”和“昂贵的缓存”,分类模型会预测其分类结果。在模型中隐藏应用的行为可能会导致应用产生错误的行为。
了解问题的约束条件。如果您的应用根据不同的阈值执行不同的操作,请确定这些阈值是固定的还是动态的。
- 动态阈值:如果阈值是动态的,请使用回归模型并在应用的代码中设置阈值限制。这样,您就可以轻松更新阈值,同时仍然让模型进行合理的预测。
- 固定阈值:如果阈值是固定的,请使用分类模型并根据阈值限制为数据集添加标签。
通常,大多数缓存预配都是动态的,并且阈值会随时间而变化。由于这具体是一个缓存问题,因此回归模型是最佳选择。但是,对于许多问题,阈值是固定的,因此分类模型是最佳解决方案。
我们来看另一个示例。如果您正在构建一款天气应用,其理想结果是告知用户未来 6 小时内会下多少雨,那么您可以使用预测标签 precipitation_amount. 的回归模型
| 理想成效 | 理想标签 |
|---|---|
| 告知用户未来 6 小时内他们所在区域将会下雨多少。 | precipitation_amount
|
在天气应用示例中,标签直接指明了理想结果。但在某些情况下,理想结果和标签之间不明显是一对一关系。例如,在视频应用中,理想的结果是推荐有用的视频。但是,数据集中没有名为 useful_to_user. 的标签
| 理想成效 | 理想标签 |
|---|---|
| 推荐有用的视频。 | ? |
因此,您必须找到代理标签。
代理标签
代理标签可替换数据集中没有的标签。如果您无法直接衡量要预测的内容,则必须使用代理标签。在视频应用中,我们无法直接衡量
用户是否会觉得视频有用如果数据集具有 useful 特征,并且用户标记了他们认为有用的所有视频,就再好不过了,但由于数据集没有用,我们需要一个代理标签来替代有用性。
实用性的代理标签可能是用户是否会分享或顶视频。
| 理想成效 | 代理标签 |
|---|---|
| 推荐有用的视频。 | shared OR liked |
请谨慎使用代理标签,因为它们无法直接衡量您要预测的内容。例如,下表概述了推荐实用视频的潜在代理标签问题:
| 代理标签 | 问题 |
|---|---|
| 预测用户是否会点击“顶”按钮。 | 大多数用户从不点击“赞”。 |
| 预测某个视频是否会受欢迎。 | 非个性化。部分用户可能不喜欢热门视频。 |
| 预测用户是否会分享视频。 | 某些用户不分享视频。有时候,人们会因为自己“不喜欢”而分享视频。 |
| 预测用户是否会点击播放。 | 尽可能增加点击诱饵。 |
| 预测他们观看视频的时长。 | 与短视频相比,更喜欢长视频。 |
| 预测用户会重新观看视频的次数。 | 相较于无法重复观看的视频类型,更青睐“可重复观看”的视频。 |
任何代理标签都无法完美替代你的理想结果。这一切都有潜在问题。请选择对您的使用场景而言问题最少的那个变体。
检查您的理解情况
生成
在大多数情况下,您不需要训练自己的生成模型,因为这样做需要大量的训练数据和计算资源。而是需要自定义预训练的生成模型。如需获取生成模型来生成所需输出,您可能需要使用以下一种或多种技术:
蒸馏。如需创建较大模型的较小版本,可基于用于训练较小模型的较大模型生成合成的带标签数据集。生成模型通常非常庞大,并且会消耗大量资源(如内存和电力)。蒸馏可让规模较小、资源密集型程度较低的模型大致估算较大模型的性能。
提示工程。要使模型执行特定任务或以特定格式生成输出,您需要告知模型您希望它执行的任务或说明您希望如何设置输出格式。换言之,提示可以包含有关如何执行该任务的自然语言说明或具有所需输出的说明性示例。
例如,如果您需要文章的简短摘要,可以输入以下内容:
Produce 100-word summaries for each article.如果您希望模型为特定阅读水平生成文本,可以输入以下内容:
All the output should be at a reading level for a 12-year-old.如果您希望模型以特定格式提供其输出,您可以说明输出应如何设置格式(例如,“在表格中设置结果的格式”),或者您可以通过提供示例来演示任务。例如,您可以输入以下内容:
Translate words from English to Spanish. English: Car Spanish: Auto English: Airplane Spanish: Avión English: Home Spanish:______
蒸馏和微调会更新模型的参数。提示工程不会更新模型的参数。相反,提示工程可帮助模型学习如何根据提示的上下文生成所需的输出。
在某些情况下,您还需要一个测试数据集来根据已知值评估生成模型的输出,例如,检查模型的摘要是否与人工生成的摘要相似,或者人类对模型摘要的评分是否良好。
生成式 AI 还可用于实现预测性机器学习解决方案,例如分类或回归。例如,由于对自然语言有深入的了解,因此大型语言模型 (LLM) 通常可以比针对特定任务训练的预测式机器学习更好地执行文本分类任务。
定义成效指标
定义用于确定机器学习实现是否成功的指标。成功指标定义了您关注的内容,例如互动度或帮助用户采取适当行动(例如观看他们认为有用的视频)。成功指标与模型的评估指标不同,如准确率、精确率、召回率或 AUC 等。
例如,天气应用的成功和失败指标可定义如下:
| 成功 | 用户打开“会下雨吗?”功能的频率比之前高出 50%。 |
|---|---|
| 失败 | 用户打开“会下雨吗?”功能的次数不超过之前。 |
视频应用指标的定义如下:
| 成功 | 用户在网站上停留的时间平均增加了 20%。 |
|---|---|
| 失败 | 用户在网站上花费的平均时间没有比之前长。 |
我们建议您定义雄心勃勃的成效指标。然而,远大抱负可能会导致成功与失败之间存在差距。例如,用户在网站上停留的时间平均比之前多出 10%,既不是成功,也不是失败。未定义的差距并不重要。
重要的是模型能够更接近(或超越)成功定义的能力。例如,在分析模型的性能时,请考虑以下问题:改进模型会让您更接近所定义的成功标准吗?例如,某个模型可能具有出色的评估指标,但不会让您更接近成功标准,这意味着即使拥有完美的模型,也无法满足您定义的成功标准。另一方面,模型的评估指标可能不佳,但让您更接近成功标准,表示改进模型将让您更接近成功。
在确定模型是否值得改进时,需要考虑以下维度:
还不够,请继续操作。模型不应在生产环境中使用,但随着时间的推移,模型可能会得到显著改进。
足够好,请继续。该模型可用于生产环境,还可能进一步改进。
足够好,但无法改进。模型在生产环境中运行,但其表现可能尽可能好。
不够好,永远不会有。模型不应在生产环境中使用,并且很可能无法进行大量训练。
在决定改进模型时,请重新评估资源增加(例如工程时间和计算费用)是否合理地证明了模型的预期改进。
定义成功和失败指标后,您需要确定衡量这些指标的频率。例如,您可以在实现系统 6 天、6 周或 6 个月后衡量您的成功指标。
分析失败指标时,请尝试确定系统出现故障的原因。例如,模型可能会预测用户点击哪些视频,但可能会开始推荐会导致用户互动度下降的点击诱饵标题。在天气应用示例中,模型可以准确预测下雨时间,但会因为地理区域过大。
检查您的理解情况
一家时尚公司想要提高服装销量。有人建议利用机器学习技术来确定这家公司应该生产哪种衣服。他们认为可以训练模型来确定时尚服装类型。在训练模型后,他们希望将该模型应用到其目录中,以决定要制作哪些衣服。
他们应该如何用机器学习术语来表述他们的问题?
理想成效:确定要制造的商品。
模型的目标:预测哪些服装穿着时尚的服装。
模型输出:二元分类、in_fashion、not_in_fashion
成效指标:售出成品衣服的 70% 或以上。
理想结果:确定需要订购多少面料和用品。
型号的目标:预测每种商品要制造多少。
模型输出:二元分类、make、do_not_make
成效指标:售出成品衣服的 70% 或以上。