Nachdem Sie sichergestellt haben, dass das Problem am besten gelöst werden kann, entweder durch eine ML- oder generativen KI-Ansatz nutzen, können Sie Ihr Problem in ML-Begriffen beschreiben. Führen Sie die folgenden Aufgaben aus, um ein Problem in Bezug auf ML zu formulieren:
- Definieren Sie das ideale Ergebnis und das Ziel des Modells.
- Identifizieren Sie die Ausgabe des Modells.
- Definieren Sie Erfolgsmetriken.
Das ideale Ergebnis und das Ziel des Modells definieren
Was ist das ideale Ergebnis, unabhängig vom ML-Modell? Mit anderen Worten, was ist die genaue Aufgabe, die Ihr Produkt oder Ihre Funktion ausführen soll? Das Gleiche die Sie zuvor unter Ziel angeben definiert haben. .
Verknüpfen Sie das Ziel des Modells mit dem idealen Ergebnis, indem Sie explizit definieren, was das Modell tun soll. In der folgenden Tabelle sind die idealen Ergebnisse und für hypothetische Apps festgelegt:
| App-Kampagnen | Ideales Ergebnis | Ziel des Modells |
|---|---|---|
| Wetter App | Berechnen Sie den Niederschlag in Sechs-Stunden-Schritten für eine geografische Region. | Sie können die Niederschlagsmengen in den letzten sechs Stunden für bestimmte geografische Regionen vorhersagen. |
| Mode-App | Eine Vielzahl von T-Shirt-Designs erstellen. | Generieren Sie drei Varianten eines T-Shirt-Designs aus Text und einem Bild. wobei der Text den Stil und die Farbe angibt und das Bild die Art Hemd (T-Shirt, Button-up, Polo) |
| Video-App | Empfehlen Sie nützliche Videos. | Vorhersagen, ob ein Nutzer auf ein Video klicken wird. |
| E-Mail-App | Erkennen Sie Spam. | Vorhersagen, ob es sich bei einer E-Mail um Spam handelt. |
| Finanz-App | Finanzinformationen aus verschiedenen Nachrichtenquellen zusammenfassen | Erstelle 50-Wörter-Zusammenfassungen der wichtigsten Finanztrends aus dem in den letzten sieben Tagen. |
| Karten-App | Die Reisezeit berechnen. | Sie können vorhersagen, wie lange die Fahrt zwischen zwei Punkten dauern wird. |
| Banking-App | Identifizieren Sie betrügerische Transaktionen. | Vorhersagen, ob eine Transaktion vom Karteninhaber durchgeführt wurde. |
| Restaurant-App | Kennzeichnen Sie die Küche anhand der Speisekarte eines Restaurants. | Die Art des Restaurants vorhersagen. |
| E-Commerce-App | Antworten auf den Kundensupport zu Produkten des Unternehmens generieren. | Generiere Antworten mithilfe der Sentimentanalyse und der Wissensdatenbank. |
Benötigte Ausgabe ermitteln
Ihre Wahl des Modelltyps hängt vom spezifischen Kontext und den Einschränkungen Ihr Problem zu lösen. Die Ausgabe des Modells sollte die im für ein optimales Ergebnis. Die erste zu beantwortende Frage lautet also: „Welche Art von Ausgabe benötige ich, um mein Problem zu lösen?“
Wenn Sie etwas klassifizieren oder eine numerische Vorhersage treffen müssen, vorausschauendes ML nutzen. Wenn Sie neue Inhalte oder Ausgaben erstellen müssen mit Natural Language Understanding nutzen, verwenden Sie wahrscheinlich generative KI.
In den folgenden Tabellen sind prädiktive Ausgaben für ML und Generative AI aufgeführt:
| ML-System | Beispielausgabe | |
|---|---|---|
| Klassifizierung | Binär | E-Mails als „Spam“ oder „Kein Spam“ klassifizieren |
| Einzelnes Label mit mehreren Klassen | Ein Tier auf einem Bild klassifizieren | |
| Mehrere Klassen mit mehreren Labels | Klassifizieren Sie alle Tiere auf einem Bild. | |
| Numerisch | Eindimensionale Regression | Die Anzahl der Aufrufe eines Videos vorhersagen. |
| Multidimensionale Regression | Blutdruck-, Herzfrequenz- und Cholesterinwerte vorhersagen für als Einzelperson. |
| Modelltyp | Beispielausgabe |
|---|---|
| Text |
Fasse einen Artikel zusammen. Sie können auf Kundenrezensionen antworten. Übersetzen Sie Dokumente aus dem Englischen ins Mandarin. Verfassen Sie Produktbeschreibungen. Rechtsdokumente analysieren
|
| Bild |
Erstellen Sie Marketingbilder. Visuelle Effekte auf Fotos anwenden. Generieren Sie Produktdesignvariationen.
|
| Audio |
Generiere Dialoge mit einem bestimmten Akzent.
Entwickle eine kurze Musikkomposition in einem bestimmten Genre wie
Jazz.
|
| Video |
Erstellen Sie realistisch aussehende Videos.
Analysieren Sie Videomaterial und wenden Sie visuelle Effekte an.
|
| Multimodal | Produzieren Sie verschiedene Ausgabearten, z. B. ein Video mit Untertiteln. |
Klassifizierung
Ein Klassifizierungsmodell sagt vorher, zu welcher Kategorie die Eingabedaten gehören, z. B. ob eine Eingabe als A, B oder C klassifiziert werden.
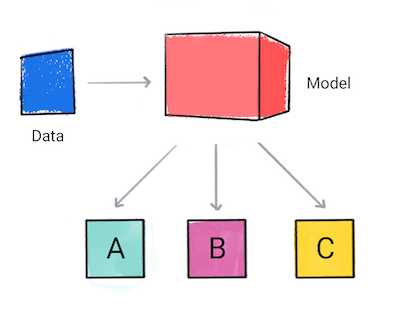
Abbildung 1. Ein Klassifizierungsmodell, das Vorhersagen trifft.
Basierend auf der Vorhersage des Modells trifft Ihre App möglicherweise eine Entscheidung. Wenn beispielsweise ist die Vorhersage Kategorie A, dann folgt X; wenn die Vorhersage Kategorie B ist, Ja, Y; wenn die Vorhersage Kategorie C ist, dann Z. In einigen Fällen kann die Vorhersage ist die Ausgabe der Anwendung.
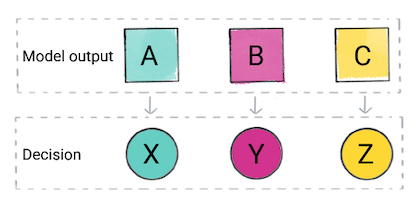
Abbildung 2: Die Ausgabe eines Klassifizierungsmodells eine Entscheidung zu treffen.
Regression
Ein Regressionsmodell sagt einen numerischen Wert.
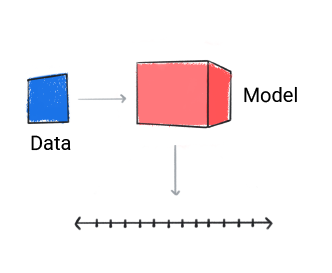
Abbildung 3: Ein Regressionsmodell, das eine numerische Vorhersage trifft.
Basierend auf der Vorhersage des Modells trifft Ihre App möglicherweise eine Entscheidung. Wenn beispielsweise die Vorhersage in den Bereich A fällt, tun X; wenn die Vorhersage in den Bereich fällt, B, wie Y; wenn die Vorhersage in den Bereich C fällt, do Z. In einigen Fällen kann der Vorhersage ist die Ausgabe der Anwendung.
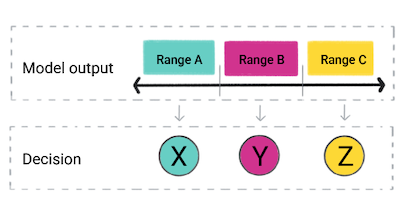
Abbildung 4: Die Ausgabe eines Regressionsmodells wird im Produktcode verwendet, zu treffen.
Stellen Sie sich folgendes Szenario vor:
Sie möchten den Cache verwenden. basierend auf ihrer prognostizierten Beliebtheit. Wenn Ihr Modell also prognostiziert, dass ein Video beliebt sein wird, möchten Sie es Nutzern schnell präsentieren. Bis verwenden Sie den effektiveren und teureren Cache. Bei anderen Videos verwenden Sie einen anderen Cache. Ihre Caching-Kriterien sind:
- Wenn ein Video voraussichtlich 50 oder mehr Aufrufe erzielen wird, verwenden Sie die teuren Cache gespeichert werden.
- Wird ein Video voraussichtlich 30 bis 50 Aufrufe erzielen, verwendest du die billige Cache gespeichert werden.
- Wenn das Video voraussichtlich weniger als 30 Aufrufe erzielt, wird das Element Video.
Sie halten ein Regressionsmodell für den richtigen Ansatz, einen numerischen Wert, d. h. die Anzahl der Aufrufe. Beim Trainieren der Regression stellen Sie fest, dass es dieselben loss für eine Vorhersage von 28 und 32 für Videos mit 30 Aufrufen. Mit anderen Worten: Auch wenn Ihre App sehr wahrscheinlich wenn die Vorhersage bei 28 im Vergleich zu 32 liegt, berücksichtigt das Modell beide Vorhersagen gleichermaßen gut.
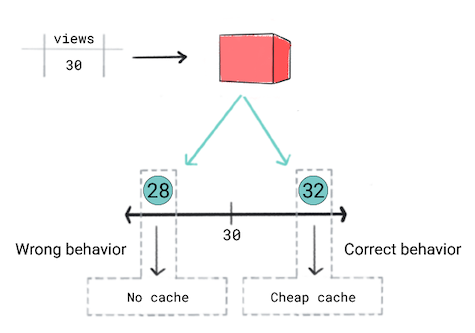
Abbildung 5: Regressionsmodell trainieren.
Regressionsmodelle erkennen produktdefinierte Schwellenwerte nicht. Wenn Ihre das Verhalten einer App aufgrund von geringfügigen Unterschieden in einem Vorhersagen des Regressionsmodells zu ermitteln, sollten Sie erwägen, Klassifizierungsmodells an.
In diesem Szenario würde ein Klassifizierungsmodell da ein Klassifizierungsmodell bei der Vorhersage von 28 als 32. In gewisser Weise erzeugen Klassifizierungsmodelle standardmäßig Grenzwerte.
In diesem Szenario werden zwei wichtige Punkte hervorgehoben:
Entscheidung vorhersagen: Prognostizieren Sie nach Möglichkeit die Entscheidung, nehmen. In diesem Videobeispiel würde ein Klassifizierungsmodell ob die Kategorien, in die Videos eingeordnet wurden, „kein Cache“ waren, "billig „Cache“ und „teuer Cache“. Wenn Sie das Verhalten Ihrer App vor dem Modell verbergen, kann das führen dazu, dass Ihre App das falsche Verhalten erzeugt.
Verstehen Sie die Einschränkungen des Problems. Wenn Ihre App unterschiedliche Maßnahmen basierend auf unterschiedlichen Schwellenwerten fest oder dynamisch sein.
- Dynamische Schwellenwerte: Wenn Schwellenwerte dynamisch sind, verwenden Sie ein Regressionsmodell. und legen Sie die Grenzwerte im Code Ihrer App fest. So können Sie ganz einfach die Schwellenwerte aktualisieren, während das Modell Vorhersagen zu treffen.
- Feste Schwellenwerte: Wenn Schwellenwerte festgelegt sind, verwenden Sie ein Klassifizierungsmodell. und beschriften Sie Ihre Datasets basierend auf den Schwellenwerten.
Im Allgemeinen erfolgt die Cache-Bereitstellung dynamisch und die Grenzwerte ändern sich im Laufe der Zeit. Da es sich speziell um ein Caching-Problem handelt, ist die beste Wahl. Bei vielen Problemen Schwellenwerte festgelegt werden, was ein Klassifizierungsmodell zur besten Lösung macht.
Sehen wir uns ein weiteres Beispiel an. Wenn Sie eine Wetter-App erstellen,
das ideale Ergebnis darin besteht, den Nutzenden zu sagen, wie viel es in den
nächsten sechs Stunden regnen wird,
könnten Sie ein Regressionsmodell verwenden, das das Label precipitation_amount. vorhersagt
| Ideales Ergebnis | Ideales Label |
|---|---|
| Teilen Sie Nutzern mit, wie viel es in ihrer Region regnen wird in den nächsten sechs Stunden. | precipitation_amount
|
In der Wetter-App-Beispiel zeigt das Label direkt das ideale Ergebnis an.
In einigen Fällen ist jedoch keine Eins-zu-Eins-Beziehung zwischen den
und die Bezeichnung. In der Video-App ist das ideale Ergebnis beispielsweise
um hilfreiche Videos zu empfehlen. Im Dataset gibt es jedoch kein Label namens
useful_to_user.
| Ideales Ergebnis | Ideales Label |
|---|---|
| Nützliche Videos empfehlen | ? |
Daher müssen Sie ein Proxy-Label finden.
Proxy-Labels
Proxy-Labels ersetzen
die nicht im Dataset enthalten sind. Proxy-Labels sind erforderlich, wenn Sie
können Sie direkt messen,
was Sie vorhersagen möchten. In der Video-App können wir
Sie können messen, ob ein Video für Nutzende nützlich ist. Es wäre toll, wenn der
Dataset enthielt die Funktion useful und Nutzer haben alle gefundenen Videos markiert
nützlich ist, aber da das Dataset dies nicht tut, brauchen wir ein Proxy-Label,
die Nützlichkeit ersetzt.
Ein Proxy-Label für die Nützlichkeit könnte angeben, ob der Nutzer Video.
| Ideales Ergebnis | Proxy-Label |
|---|---|
| Nützliche Videos empfehlen | shared OR liked |
Seien Sie bei Proxy-Labels vorsichtig, da sie nicht direkt messen, was Sie möchten vorhersagen können. In der folgenden Tabelle sind beispielsweise Probleme Proxy-Labels für Nützliche Videos empfehlen:
| Proxy-Label | Problem |
|---|---|
| Vorhersagen, ob der Nutzer auf die „Gefällt mir“-Angabe klicken wird Schaltfläche. | Die meisten Nutzer klicken nie auf „Gefällt mir“. |
| Vorhersagen, ob ein Video beliebt sein wird | Nicht personalisiert. Einigen Nutzern gefallen vielleicht nicht die beliebtesten Videos. |
| Vorhersagen, ob der Nutzer das Video teilen wird | Einige Nutzer teilen keine Videos. Manchmal teilen Menschen Videos, die sie nicht mögen. |
| Vorhersagen, ob der Nutzer auf die Wiedergabe klicken wird. | Maximiert Clickbaiting. |
| Vorhersagen, wie lange sie sich das Video ansehen. | Bevorzugt lange Videos anders als kurze Videos. |
| Vorhersagen, wie oft sich der Nutzer das Video noch einmal ansehen wird | Bevorzugt „wiederholbar“ statt Videogenres, die sich nicht noch einmal ansehen können. |
Kein Proxy-Label kann ein perfekter Ersatz für Ihr ideales Ergebnis sein. Alle werden potenzielle Probleme haben. Wählen Sie diejenige aus, die die wenigsten Probleme für Ihr für den Anwendungsfall.
Wissenstest
Generierung
In den meisten Fällen trainieren Sie kein eigenes generatives Modell, enorme Mengen an Trainingsdaten und Rechenressourcen erfordern. Stattdessen passen Sie ein vortrainiertes generatives Modell an. Um ein generatives Modell die gewünschte Ausgabe erzeugen, müssen Sie möglicherweise eine oder mehrere der folgenden Optionen verwenden: Techniken:
Destillation: So erstellen Sie ein kleineren Version eines größeren Modells, generieren Sie ein synthetisches Dataset mit Labels. Modell aus dem größeren Modell, das Sie zum Trainieren des kleineren Modells verwenden. Generatives Modell Modelle sind in der Regel riesig und verbrauchen erhebliche Ressourcen (wie Speicher und Elektrizität). Durch Destillation können kleinere, weniger ressourcenintensive um die Leistung des größeren Modells zu schätzen.
Feinabstimmung oder parametereffiziente Abstimmung. Um die Leistung eines Modells bei einer bestimmten Aufgabe zu verbessern, Trainieren Sie das Modell mit einem Dataset, das Beispiele für den Ausgabetyp enthält die Sie produzieren möchten.
Prompt Engineering: Bis damit das Modell eine bestimmte Aufgabe ausführt eine Ausgabe in einem bestimmten Format zu generieren, teilen Sie dem Modell mit, oder erklären, wie die Ausgabe formatiert werden soll. Mit anderen Worten, der Parameter Ein Prompt kann Anweisungen in natürlicher Sprache zur Ausführung der Aufgabe enthalten oder Beispiele mit den gewünschten Ausgaben.
Wenn Sie beispielsweise kurze Zusammenfassungen von Artikeln möchten, können Sie die Folgendes:
Produce 100-word summaries for each article.Wenn das Modell Text für eine bestimmte Lesestufe generieren soll, könnten Sie Folgendes eingeben:
All the output should be at a reading level for a 12-year-old.Wenn Sie möchten, dass das Modell seine Ausgabe in einem bestimmten Format liefert, können Sie erklären, wie die Ausgabe formatiert werden soll, zum Beispiel: „Formatieren Sie die Ergebnisse in einer Tabelle“ – oder Sie könnten die Aufgabe indem Sie Beispiele dafür nennen. Sie könnten beispielsweise Folgendes eingeben:
Translate words from English to Spanish. English: Car Spanish: Auto English: Airplane Spanish: Avión English: Home Spanish:______
Durch Destillation und Feinabstimmung werden parameters Prompt-Engineering werden die Parameter des Modells nicht aktualisiert. Stattdessen hilft Prompt Engineering Modell lernen, wie aus dem Kontext des Prompts eine gewünschte Ausgabe erzeugt wird.
In einigen Fällen benötigen Sie auch eine Test-Dataset zur Auswertung eines die Ausgabe eines generativen Modells anhand bekannter Werte. Beispielsweise wird geprüft, Die Zusammenfassungen des Modells ähneln denen von Menschen oder können von Menschen bewertet werden. die Zusammenfassungen des Modells als gut befunden haben.
Generative KI kann auch zum Implementieren einer ML-Vorhersage wie Klassifizierung oder Regression. Aufgrund ihres fundierten Sprachwissens Large Language Models (LLMs) kann Textklassifizierungsaufgaben häufig besser ausführen als ML-Vorhersagen die für die jeweilige Aufgabe trainiert wurden.
Erfolgsmetriken definieren
Definieren Sie die Messwerte, anhand derer Sie feststellen, ob die ML-Implementierung erfolgreich war. Erfolgsmetriken definieren, was Ihnen wichtig ist, wie Interaktion oder Nutzer bei der Ausführung geeigneter Aktionen unterstützen, wie z. B. dem Ansehen von Videos, die sie nützlich sind. Erfolgsmesswerte unterscheiden sich von den Bewertungsmesswerten des Modells, Genauigkeit, Precision, Rückruf oder AUC:
Die Erfolgs- und Fehlermesswerte der Wetter-App können beispielsweise wie folgt definiert werden: Folgendes:
| Erfolg | Nutzer öffnen die Seite „Wird es regnen?“ 50 Prozent häufiger als als zuvor. |
|---|---|
| Fehler | Nutzer öffnen die Seite „Wird es regnen?“ nicht häufiger als vorher. |
Die Messwerte für Video-Apps können so definiert werden:
| Erfolg | Nutzer verbringen durchschnittlich 20 % mehr Zeit auf der Website. |
|---|---|
| Fehler | Nutzer verbringen durchschnittlich nicht mehr Zeit auf der Website als zuvor. |
Wir empfehlen, ehrgeizige Messwerte für den Erfolg zu definieren. Hohe Ambitionen können Lücken verursachen zwischen Erfolg und Misserfolg. Beispiel: Nutzer, die durchschnittlich 10 Prozent mehr Verweildauer auf der Website als zuvor ist weder Erfolg noch Misserfolg. Die undefinierte Lücke ist nicht wichtig.
Wichtig ist die Kapazität Ihres Modells, näher zu kommen die Definition von Erfolg. Beim Analysieren der Leistung sollten Sie sich folgende Frage stellen: Würde die Verbesserung des Modells Ihren Erfolgskriterien näher kommt? Zum Beispiel könnte ein Modell eine großartige werden, aber nicht Ihren Erfolgskriterien näher gebracht, dass Sie selbst mit einem perfekten Modell nicht die Erfolgskriterien erfüllen, definiert. Andererseits hat ein Modell möglicherweise schlechte Bewertungsmesswerte, Sie näher an Ihren Erfolgskriterien sind, was darauf hinweist, dass die Verbesserung des Modells Ihrem Erfolg näherzubringen.
Die folgenden Dimensionen sind zu berücksichtigen, wenn es darum geht, den Wert des Modells zu bestimmen. wird verbessert:
Nicht gut genug, aber weiter. Das Modell sollte nicht in mit der Zeit erheblich verbessert werden.
Gut genug und weiter! Das Modell könnte in einer Produktionsumgebung und wird möglicherweise weiter verbessert.
Gut genug, aber es kann nicht verbessert werden. Das Modell befindet sich in der Produktion aber es ist wahrscheinlich so gut wie möglich.
Nicht gut genug und wird es auch nicht sein. Das Modell sollte nicht in in einer Produktionsumgebung und ohne intensives Training schaffen wird.
Wenn Sie sich entscheiden, das Modell zu verbessern, überlegen Sie erneut, ob der Anstieg der Ressourcen, wie die Entwicklungszeit und die Computing-Kosten, rechtfertigen die prognostizierte Verbesserung des das Modell zu verstehen.
Nachdem Sie die Erfolgs- und Fehlermetriken definiert haben, müssen Sie bestimmen, wie oft messen Sie sie. Sie können beispielsweise Ihre Erfolgsmetriken sechs Tage, sechs Wochen oder sechs Monate nach der Implementierung des Systems.
Versuchen Sie bei der Analyse von Fehlermesswerten herauszufinden, warum das System fehlgeschlagen ist. Für sagt das Modell möglicherweise vorher, auf welche Videos Nutzer klicken werden, aber der könnte das Modell Clickbaiting-Titel empfehlen, die das Nutzer-Engagement aussteigen. In dem Beispiel der Wetter-App könnte das Modell genau vorhersagen, es in einer geografischen Region zu regnen wird.
Wissenstest
Ein Modeunternehmen möchte mehr Kleidung verkaufen. Jemand schlägt ML vor, entscheiden, welche Kleidung das Unternehmen herstellen soll. Sie glauben, dass sie Ein Modell trainieren, um zu bestimmen, welche Art von Kleidung in Mode ist. Nachher Sie trainieren das Modell und möchten es auf ihren Katalog anwenden, um zu entscheiden, welche Kleidung gefertigt werden soll.
Wie sollten sie ihr Problem in Bezug auf ML beschreiben?
Ideales Ergebnis: Entscheiden, welche Produkte hergestellt werden sollen.
Ziel des Modells: Vorhersagen, welche Kleidungsstücke sich dort befinden Mode.
Modellausgabe: Binäre Klassifizierung, in_fashion
not_in_fashion
Erfolgsmesswerte: Verkaufen Sie mindestens 70 % der Kleidung. gemacht.
Ideales Ergebnis: Lege fest, wie viele Stoffe und Vorräte bestellt werden sollen.
Ziel des Modells: Vorhersage, wie viel von jedem Artikel hergestellt werden soll.
Modellausgabe: Binäre Klassifizierung, make
do_not_make
Erfolgsmesswerte: Verkaufen Sie mindestens 70 % der Kleidung. gemacht.