Après avoir vérifié que le problème est mieux résolu, vous pouvez utiliser une prédiction approche du ML ou de l'IA générative, vous êtes prêt à formuler votre problème en termes de ML. Pour formuler un problème en termes de ML, vous devez effectuer les tâches suivantes:
- Définir le résultat idéal et l'objectif du modèle
- Identifier la sortie du modèle
- Définir des indicateurs de réussite.
Définir le résultat idéal et l'objectif du modèle
Quel est le résultat idéal indépendamment du modèle de ML ? En d’autres termes, qu’est-ce que la tâche exacte que vous souhaitez que votre produit ou fonctionnalité effectue ? C'est la même chose que vous avez définie précédemment dans la section Indiquer l'objectif .
Reliez l'objectif du modèle au résultat idéal en définissant explicitement ce que vous que le modèle doit faire. Le tableau suivant indique les résultats idéaux et les pour des applications potentielles:
| Pour applications | Résultat idéal | Objectif du modèle |
|---|---|---|
| Application Météo | Calculer les précipitations par tranches de six heures pour une région géographique. | Prédire les précipitations sur six heures pour des régions géographiques spécifiques |
| Application de mode | Générez une variété de modèles de chemises. | Générer trois types de chemise à partir de texte et d'une image, où le texte indique le style et la couleur, et l'image représente le type (t-shirt, chemise, polo). |
| Application vidéo | Recommandez des vidéos utiles. | Prédisez si un utilisateur va cliquer sur une vidéo. |
| Application Mail | Détecter le spam. | Prédisez si un e-mail est un spam ou non. |
| Application financière | Résumez des informations financières issues de plusieurs sources d'actualités. | Résume en 50 mots les principales tendances financières à partir du sept jours précédents. |
| Cartes | Calculez le temps de trajet. | Prédisez le temps de trajet entre deux points. |
| Application bancaire | Identifiez les transactions frauduleuses. | Prédisez si une transaction a été effectuée par le titulaire de la carte. |
| Application de restauration | Identifier la cuisine par le menu d'un restaurant. | Prédire le type de restaurant |
| Application d'e-commerce | Générer des réponses du service client concernant les produits de l'entreprise. | Générer des réponses à l'aide de l'analyse des sentiments et de l'analyse de votre base de connaissances. |
Identifier les résultats dont vous avez besoin
Le choix du type de modèle dépend du contexte et des contraintes spécifiques votre problème. La sortie du modèle doit accomplir la tâche définie dans le résultat idéal. La première question à se poser est « De quel type de sortie ai-je besoin pour résoudre mon problème ? »
Si vous devez classer quelque chose ou faire une prédiction numérique, utiliser le ML prédictif. Si vous devez générer du nouveau contenu ou produire des sorties pour la compréhension du langage naturel, vous utiliserez probablement l'IA générative.
Les tableaux suivants répertorient les résultats prédictifs du ML et de l'IA générative:
| Système de ML | Exemple de résultat : | |
|---|---|---|
| Classification | Binaire | Classification d'un e-mail comme spam ou non-spam. |
| Multiclasse, étiquette unique | Classer un animal dans une image | |
| Étiquettes multiclasses | Classer tous les animaux d'une image | |
| Numérique | Régression unidimensionnelle | Prédire le nombre de vues d'une vidéo |
| Régression multidimensionnelle | Prédire la tension artérielle, la fréquence cardiaque et le taux de cholestérol pour un individu. |
| Type de modèle | Exemple de résultat : |
|---|---|
| Texte |
Résumez un article. Répondez aux avis des clients. Traduisez des documents de l'anglais vers le mandarin. Rédigez des descriptions de produits. Analysez les documents juridiques.
|
| Image |
Produire des images marketing Appliquez des effets visuels aux photos. Générer des variantes de conception des produits.
|
| Audio |
Générer un dialogue avec un accent spécifique
Générez une courte composition musicale dans un genre spécifique, par exemple
jazz.
|
| Vidéo |
Générez des vidéos d'apparence réaliste.
Analysez des séquences vidéo et appliquez des effets visuels.
|
| Multimode | Produisez différents types de résultats, comme une vidéo avec des sous-titres. |
Classification
Un modèle de classification prédit la catégorie à laquelle appartiennent les données d'entrée (par exemple, si une entrée doivent appartenir à l'une des catégories suivantes : A, B ou C.
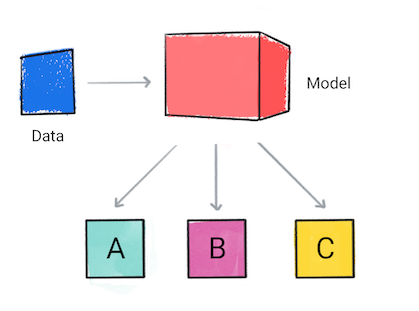
Figure 1. Un modèle de classification qui réalise des prédictions.
En fonction de la prédiction du modèle, votre application peut prendre une décision. Par exemple, si la prédiction est de catégorie A, alors faites X. si la prédiction est de catégorie B, alors do, Y; si la prédiction est de catégorie C, alors faites Z. Dans certains cas, la prédiction est le résultat de l'application.
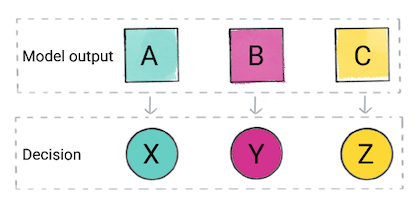
Figure 2. La sortie d'un modèle de classification utilisée dans le code produit pour prendre une décision.
Régression
Un modèle de régression prédit une valeur numérique.
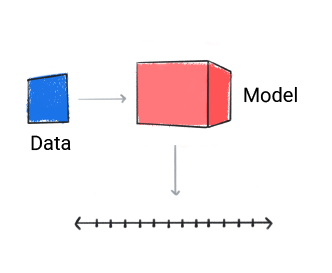
Figure 3. Modèle de régression effectuant une prédiction numérique.
En fonction de la prédiction du modèle, votre application peut prendre une décision. Par exemple, si la prédiction est comprise dans la plage A : X ; si la prédiction est comprise dans la plage B, do Y; si la prédiction est comprise dans la plage C, faire Z. Dans certains cas, la prédiction est la sortie de l'application.
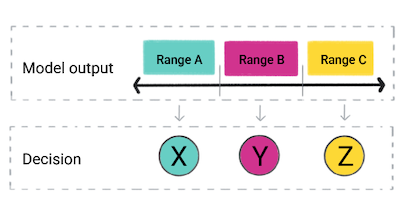
Figure 4. La sortie d'un modèle de régression utilisée dans le code produit pour une décision.
Imaginez le scénario suivant :
Vous souhaitez mettre en cache en fonction de leur popularité prévue. Autrement dit, si votre modèle prédit qu'une vidéo sera populaire, vous souhaitez la diffuser rapidement. À vous utiliserez le cache le plus efficace et le plus cher. Pour les autres vidéos, vous utiliserez un cache différent. Vos critères de mise en cache sont les suivants:
- Si une vidéo est susceptible d'enregistrer 50 vues ou plus, vous devez utiliser la cache.
- Si une vidéo est susceptible d'enregistrer entre 30 et 50 vues, utilisez la méthode cache.
- S'il est prévu que la vidéo atteindra moins de 30 vues, vous ne mettrez pas en cache le vidéo.
Vous pensez qu'un modèle de régression est la bonne approche, car vous allez prédire une valeur numérique (le nombre de vues). Toutefois, lors de l'entraînement de la régression on s'aperçoit qu'il produit la même loss pour une prédiction de 28 et 32 pour les vidéos cumulant 30 vues. En d'autres termes, même si votre application présente un comportement différent si la prédiction est de 28 ou de 32, le modèle considère à la fois les prédictions sont tout aussi efficaces.
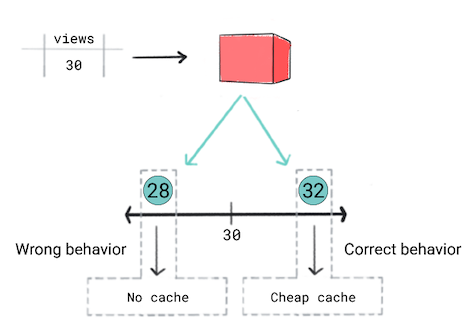
Figure 5. Entraîner un modèle de régression
Les modèles de régression ne tiennent pas compte des seuils définis par le produit. Par conséquent, si votre le comportement de l'application change de manière significative en raison de légères différences au niveau d'une du modèle de régression, vous pouvez appliquer modèle de classification.
Dans ce scénario, un modèle de classification produira le comportement correct car un modèle de classification produirait une perte plus élevée pour une prédiction 28 que 32. En un sens, les modèles de classification produisent des seuils par défaut.
Ce scénario met en évidence deux points importants:
Prédire la décision Si possible, prédire la décision prise par votre application prendre. Dans l'exemple de la vidéo, un modèle de classification prédirait si les catégories dans lesquelles il classait les vidéos n'étaient "pas de cache", "pas cher" "Cache", et "cache coûteux". Le fait de masquer le comportement de votre application dans le modèle peut peut entraîner un comportement incorrect de votre application.
Comprenez les contraintes du problème. Si votre application prend différentes en fonction de différents seuils, déterminez si ces seuils sont fixes ou dynamiques.
- Seuils dynamiques: si les seuils sont dynamiques, utiliser un modèle de régression et définissez les seuils dans le code de votre application. Vous pouvez ainsi facilement les seuils tout en faisant en sorte que le modèle des prédictions.
- Seuils fixes: si les seuils sont fixes, utilisez un modèle de classification et étiquetez vos ensembles de données en fonction des seuils.
En général, le provisionnement du cache est dynamique et les seuils changent au fil du temps. Comme il s'agit spécifiquement d'un problème de mise en cache, de régression automatique est le meilleur choix. Cependant, pour de nombreux problèmes, les seuils seront fixes, ce qui fait du modèle de classification la meilleure solution.
Examinons un autre exemple. Si vous développez une application météo
le résultat idéal est d'indiquer aux utilisateurs
combien il pleuvra dans les six prochaines heures,
vous pouvez utiliser un modèle de régression qui prédit l'étiquette precipitation_amount.
| Résultat idéal | Étiquette idéale |
|---|---|
| Indiquez aux utilisateurs la quantité de pluie prévue dans leur région au cours des six prochaines heures. | precipitation_amount
|
Dans l'exemple de l'application météo, l'étiquette répond directement au résultat idéal.
Cependant, dans certains cas, il n'existe pas de relation de type un à un entre les
le résultat idéal et l'étiquette. Par exemple, dans l'application vidéo, le résultat idéal est
afin de recommander des vidéos utiles. Cependant, l'ensemble de données ne comporte pas d'étiquette appelée
useful_to_user.
| Résultat idéal | Étiquette idéale |
|---|---|
| Recommandez des vidéos utiles. | ? |
Vous devez donc trouver une étiquette de proxy.
Étiquettes de proxy
Remplacement par les étiquettes de proxy
d'étiquettes qui ne figurent pas
dans l'ensemble de données. Les étiquettes de proxy sont
nécessaires lorsque vous ne pouvez pas
pour mesurer directement
ce que vous voulez prédire. Dans l'application vidéo, nous ne pouvons pas directement
Évaluer si un utilisateur trouvera une vidéo utile ou non Dans l'idéal,
l'ensemble de données comportait la fonctionnalité useful, et les utilisateurs ont marqué toutes les vidéos qu'ils ont trouvées
mais comme l'ensemble de données ne l'est pas, nous aurons besoin d'une étiquette de proxy
se substitue à l'utilité.
Une étiquette de proxy pour l'utilité pourrait indiquer si l'utilisateur partagera ou aimera la vidéo.
| Résultat idéal | Étiquette de proxy |
|---|---|
| Recommandez des vidéos utiles. | shared OR liked |
Soyez prudent avec les étiquettes de proxy, car elles ne mesurent pas directement ce que vous voulez à prédire. Par exemple, le tableau suivant décrit les problèmes liés aux Étiquettes de proxy pour Recommander des vidéos utiles:
| Étiquette de proxy | Problème |
|---|---|
| Prédire si l'utilisateur cliquera sur le bouton "J'aime" . | La plupart des utilisateurs ne cliquent jamais sur "J'aime". |
| Prédisez si une vidéo sera populaire. | Non personnalisé. Il est possible que certains utilisateurs n'aiment pas les vidéos populaires. |
| Prédire si l'utilisateur partagera ou non la vidéo. | Certains utilisateurs ne partagent pas de vidéos. Parfois, les gens partagent des vidéos parce que ils ne les aiment pas. |
| Prédit si l'utilisateur va cliquer sur le bouton de lecture. | Maximiser les pièges à clics. |
| Prédisez la durée de visionnage de la vidéo. | Privilégie les vidéos longues de façon différente par rapport aux vidéos courtes. |
| Prédire le nombre de fois où l'utilisateur regardera à nouveau la vidéo | Favorise les "replayables" par rapport aux genres de vidéos non réutilisables. |
Aucune étiquette de procuration ne peut remplacer parfaitement votre résultat idéal. Tous des problèmes potentiels. Choisissez celle qui pose le moins de problèmes à votre de ce cas d'utilisation.
Testez vos connaissances
Génération
Dans la plupart des cas, vous n'entraînerez pas votre propre modèle génératif, nécessite d'énormes quantités de données d'entraînement et de ressources de calcul. À la place, vous allez personnaliser un modèle génératif pré-entraîné. Pour qu'un modèle génératif puisse générer le résultat souhaité, vous devrez peut-être utiliser un ou plusieurs des techniques:
Distillation : Pour créer un version plus petite d'un modèle plus grand, vous générez un ensemble de données synthétique étiqueté à partir du plus grand modèle utilisé pour entraîner le plus petit modèle. Modèles génératifs les modèles sont généralement gigantesques et consomment beaucoup de ressources et l'électricité). La distillation permet d'exécuter les opérations plus petites, moins gourmandes en ressources, pour se rapprocher des performances du plus grand modèle.
Réglage ou réglage efficace des paramètres. Pour améliorer les performances d'un modèle sur une tâche spécifique, vous devez entraîner le modèle sur un ensemble de données contenant des exemples du type de résultat souhaitez produire.
Ingénierie des requêtes : À que le modèle effectue une tâche spécifique produit une sortie dans un format spécifique, vous indiquez au modèle la tâche souhaitée faire ou expliquer comment vous souhaitez formater la sortie. En d'autres termes, peut inclure des instructions en langage naturel sur la façon d'effectuer la tâche ou des exemples illustratifs avec les résultats souhaités.
Par exemple, pour obtenir de brefs résumés d'articles, vous pouvez saisir le suivantes:
Produce 100-word summaries for each article.Si vous voulez que le modèle génère du texte pour un niveau de lecture spécifique, vous pouvez saisir les éléments suivants:
All the output should be at a reading level for a 12-year-old.Si vous souhaitez que le modèle renvoie ses résultats dans un format spécifique, vous pouvez expliquer comment la sortie doit être formatée (par exemple, "formater le résultats dans un tableau » - ou vous pouvez démontrer la tâche en lui donnant des exemples. Par exemple, vous pouvez saisir les éléments suivants:
Translate words from English to Spanish. English: Car Spanish: Auto English: Airplane Spanish: Avión English: Home Spanish:______
La distillation et l'affinage mettent à jour parameters. Ingénierie des requêtes ne met pas à jour ses paramètres. L'ingénierie des requêtes permet à générer le résultat souhaité à partir du contexte de la requête.
Dans certains cas, vous aurez également besoin ensemble de données de test pour évaluer la sortie du modèle génératif par rapport à des valeurs connues, par exemple, en vérifiant que les résumés du modèle sont semblables à ceux générés par l'humain, ou que les humains évaluent que les résumés du modèle sont satisfaisants.
L'IA générative permet aussi d'implémenter un modèle de ML prédictif comme la classification ou la régression. Par exemple, grâce à sa connaissance approfondie du langage naturel, grands modèles de langage (LLM) permet souvent d'effectuer des tâches de classification de texte plus efficacement que le ML prédictif. entraînés pour la tâche spécifique.
Définir les indicateurs de réussite
Définissez les métriques que vous utiliserez pour déterminer si l'implémentation de ML est réussi. Les indicateurs de réussite définissent ce qui vous intéresse, comme l'engagement ou en aidant les utilisateurs à agir de manière appropriée, par exemple regarder des vidéos qu'ils trouveront utiles. Les métriques de réussite diffèrent des métriques d'évaluation du modèle, accuracy, précision, rappel, ou AUC.
Par exemple, les métriques de réussite et d'échec de l'application météo peuvent être définies comme suit : les éléments suivants:
| Opération réussie | Les utilisateurs ouvrent la fenêtre "Va-t-il pleuvoir ?" présente 50 % plus souvent qu'avant. |
|---|---|
| Échec | Les utilisateurs ouvrent la fenêtre "Va-t-il pleuvoir ?" pas plus souvent que auparavant. |
Les métriques d'application vidéo peuvent être définies comme suit:
| Opération réussie | Les utilisateurs passent en moyenne 20 % de temps en plus sur le site. |
|---|---|
| Échec | En moyenne, les utilisateurs ne passent pas plus de temps sur le site qu'auparavant. |
Nous vous recommandons de définir des métriques de réussite ambitieuses. Les grandes ambitions peuvent créer des écarts entre la réussite et l'échec. Par exemple, les utilisateurs dépensent en moyenne 10 % de temps en plus sur le site n'est ni une réussite, ni un échec. L'écart indéfini n'est pas ce qui est important.
Ce qui est important, c'est la capacité de votre modèle à se rapprocher. dépasser : la définition du succès. Par exemple, lors de l'analyse sur les performances de votre modèle, posez-vous la question suivante : plus proches des critères de réussite que vous avez définis ? Par exemple, un modèle peut avoir d'évaluation, mais ne vous rapprochez pas de vos critères de réussite, indiquant que même avec un modèle parfait, vous ne rempliriez pas les critères de réussite définis. D'un autre côté, un modèle peut avoir des métriques d'évaluation médiocres, mais vous rapprochez de vos critères de réussite, ce qui indique que l'amélioration du modèle vous rapprocher du succès.
Vous trouverez ci-dessous les dimensions à prendre en compte pour déterminer la valeur du modèle. s'améliorent:
Pas assez, mais continuez. Ce modèle ne doit pas être utilisé dans un environnement mais il peut être considérablement amélioré au fil du temps.
Très bien, et continuez. Le modèle peut être utilisé en production et pourrait être encore améliorée.
Assez bon, mais on ne peut pas l'améliorer. Le modèle est en production mais il est probablement aussi bon que possible.
Pas assez bien, et ne le sera jamais. Ce modèle ne doit pas être utilisé dans un environnement dans l'environnement de production et peu d'entraînement suffit.
Lorsque vous décidez d'améliorer le modèle, réévaluez si l'augmentation des ressources comme le temps d'ingénierie et les coûts de calcul, justifient l'amélioration prévue le modèle.
Après avoir défini les métriques de réussite et d'échec, vous devez déterminer vous les mesurerez. Par exemple, vous pouvez mesurer vos métriques de réussite six jours, six semaines ou six mois après la mise en œuvre du système.
Lorsque vous analysez les métriques d'échec, essayez de déterminer pourquoi le système a échoué. Pour Par exemple, le modèle peut prédire sur quelles vidéos les utilisateurs vont cliquer, mais peut commencer à recommander des pièges à clics qui incitent les utilisateurs d’abandon. Dans l'application météo, le modèle peut prédire avec précision va pleuvoir, mais sur une zone géographique trop étendue.
Testez vos connaissances
Une entreprise de mode souhaite vendre plus de vêtements. Quelqu'un suggère d'utiliser le ML pour déterminer quels vêtements l'entreprise doit fabriquer. Ils pensent pouvoir entraîner un modèle pour déterminer le type de vêtements à la mode. Après avant d'entraîner le modèle, il veut l'appliquer à son catalogue quels vêtements fabriquer.
Comment doit-elle formuler son problème en termes de ML ?
Résultat idéal: déterminez les produits à fabriquer.
Objectif du modèle: prédire la nature des vêtements mode.
Sortie du modèle: classification binaire, in_fashion,
not_in_fashion
Indicateurs de réussite: vendre 70 % des vêtements ou plus.
Résultat idéal: déterminez la quantité de tissu et de fournitures à commander.
Objectif du modèle: prédire la quantité de chaque article à fabriquer.
Sortie du modèle: classification binaire, make,
do_not_make
Indicateurs de réussite: vendre 70 % des vêtements ou plus.