Depois de verificar que seu problema é mais bem resolvido usando um modelo ML ou uma abordagem de IA generativa, está tudo pronto para enquadrar seu problema em termos de ML. Você estrutura um problema em termos de ML realizando as seguintes tarefas:
- Defina o resultado ideal e a meta do modelo.
- Identifique a saída do modelo.
- Definir métricas de sucesso.
Definir o resultado ideal e a meta do modelo
Qual é o resultado ideal independente do modelo de ML? Em outras palavras, o que é a tarefa exata que você quer que seu produto ou recurso realize? Isto é igual instrução definida anteriormente em Informar a meta nesta seção.
Conecte o objetivo do modelo ao resultado ideal definindo explicitamente o que você quer que o modelo faça. A tabela a seguir mostra os resultados ideais meta do modelo para aplicativos hipotéticos:
| App | Resultado ideal | Objetivo do modelo |
|---|---|---|
| Aplicativo Weather | Calcula a precipitação em incrementos de seis horas para uma região geográfica. | Preveja valores de precipitação de seis horas para regiões geográficas específicas. |
| App de moda | Gere uma variedade de designs de camisas. | Gere três tipos de camisas com base em texto e imagem. em que o texto indica o estilo e a cor e a imagem é o tipo de camiseta (camiseta, botão ou polo). |
| App de vídeo | Recomende vídeos úteis. | Prever se um usuário clicará em um vídeo. |
| App de e-mail | Detectar spam. | Prever se um e-mail é spam ou não. |
| App de finanças | Resumir informações financeiras de várias fontes de notícias. | Gere resumos de 50 palavras das principais tendências financeiras do dos últimos sete dias. |
| App Mapa | Calcular o tempo de viagem. | Preveja quanto tempo levará para viajar entre dois pontos. |
| App de banco | Identifique transações fraudulentas. | Prever se uma transação foi feita pelo titular do cartão. |
| App de jantar | Identificar a culinária pelo cardápio de um restaurante. | Prever o tipo de restaurante. |
| Aplicativo de e-commerce | Gerar respostas de suporte ao cliente sobre os produtos da empresa. | Gerar respostas usando a análise de sentimento e as necessidades base de conhecimento. |
Identifique a saída que você precisa
A escolha do tipo de modelo depende do contexto e das restrições específicos do o problema. A saída do modelo deve realizar a tarefa definida no o resultado ideal. Portanto, a primeira pergunta a responder é "Que tipo de saída eu preciso para resolver meu problema?"
Se precisar classificar algo ou fazer uma previsão numérica, você provavelmente usar ML preditivo. Se você precisar gerar conteúdo novo ou produzir resultados relacionadas ao processamento de linguagem natural, você provavelmente vai usar a IA generativa.
As tabelas a seguir listam as saídas de ML preditiva e IA generativa:
| sistema de ML | Exemplo de saída | |
|---|---|---|
| Classificação | Binário | Classificar um e-mail como spam ou não spam. |
| Rótulo único multiclasse | Classificar um animal em uma imagem. | |
| Multiclasse com vários rótulos | Classificar todos os animais em uma imagem. | |
| Numérico | Regressão unidimensional | Preveja o número de visualizações de um vídeo. |
| Regressão multidimensional | Prever pressão arterial, frequência cardíaca e níveis de colesterol de um indivíduo. |
| Tipo de modelo | Exemplo de saída |
|---|---|
| Texto |
Resumir um artigo. Responder às avaliações dos clientes Traduzir documentos do inglês para o mandarim. Escreva descrições dos produtos. Analise documentos jurídicos.
|
| Imagem |
Produzir imagens de marketing. Aplique efeitos visuais às fotos. Gerar variações de design de produto.
|
| Áudio |
Gerar diálogos com um sotaque específico.
Gerar uma composição musical curta de um gênero específico, como
jazz.
|
| Vídeo |
Gere vídeos realistas.
Analise filmagens e aplique efeitos visuais.
|
| Multimodal | Produza vários tipos de saída, como um vídeo com legendas em texto. |
Classificação
Um modelo de classificação prevê a que categoria pertencem os dados de entrada, por exemplo, se uma entrada deve ser classificado como A, B ou C.
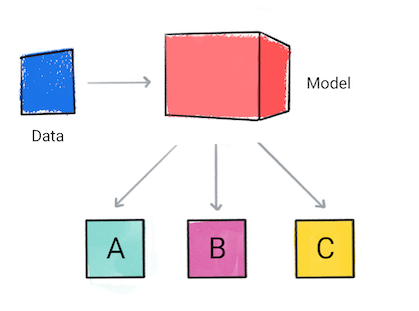
Figura 1. Um modelo de classificação que faz previsões.
Com base na previsão do modelo, o aplicativo pode tomar uma decisão. Por exemplo, se a previsão é categoria A, depois X se a previsão for de categoria B, fazer, Y; se a previsão for de categoria C, faça Z. Em alguns casos, a previsão é a saída do app.
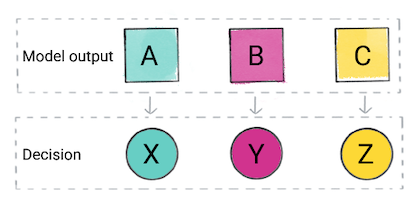
Figura 2. A saída de um modelo de classificação sendo usada no código do produto para tomar uma decisão.
Regressão
Um modelo de regressão prevê um valor numérico.
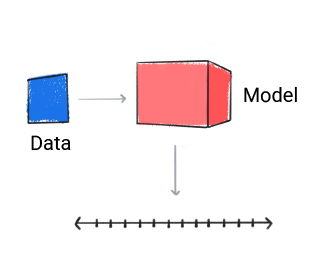
Figura 3. Um modelo de regressão que faz uma previsão numérica.
Com base na previsão do modelo, o aplicativo pode tomar uma decisão. Por exemplo, se a previsão está dentro do intervalo A, do X; se a previsão estiver dentro do intervalo B, do Y; se a previsão estiver dentro do intervalo C, faça Z. Em alguns casos, previsão é a saída do aplicativo.
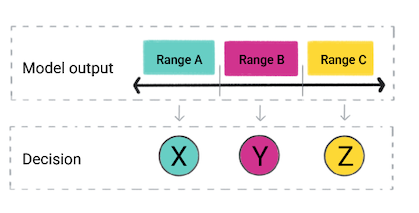
Figura 4. A saída de um modelo de regressão sendo usada no código do produto para uma decisão.
Pense no seguinte cenário:
Você quer armazenar em cache vídeos com base na popularidade prevista. Em outras palavras, se o modelo prevê que um vídeo será popular, você deseja exibi-lo rapidamente aos usuários. Para fizer isso, você usará o cache mais eficaz e caro. Para outros vídeos, você usará um cache diferente. Os critérios de armazenamento em cache são os seguintes:
- Se a previsão de um vídeo ter 50 ou mais visualizações, você vai usar cache.
- Se a previsão de um vídeo ter entre 30 e 50 visualizações, cache.
- Se a previsão for que o vídeo tenha menos de 30 visualizações, você não armazenará o vídeo.
Você acha que um modelo de regressão é a abordagem certa porque vai prever um valor numérico, o número de visualizações. No entanto, ao treinar a regressão é possível perceber que ele produz o mesmo loss para uma previsão de 28 e 32 para vídeos com 30 visualizações. Em outras palavras, embora seu aplicativo tenha comportamento diferente se a previsão for 28 versus 32, o modelo considera ambos e previsões são igualmente boas.
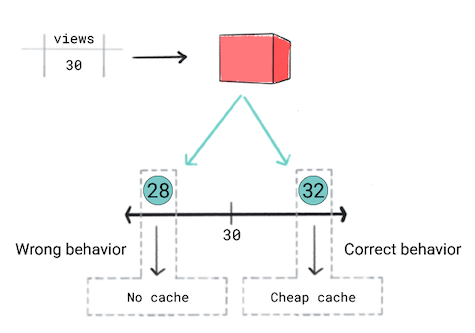
Figura 5. Treinar um modelo de regressão.
Os modelos de regressão não reconhecem os limites definidos pelo produto. Portanto, se sua de comportamento do app muda significativamente devido a pequenas diferenças em uma previsões de um modelo de regressão, você deve considerar a implementação modelo de classificação.
Nesse cenário, um modelo de classificação produziria o comportamento correto porque um modelo de classificação produziria uma perda maior para uma previsão do 28 a 32. De certa forma, os modelos de classificação produzem limiares por padrão.
Esse cenário destaca dois pontos importantes:
Prever a decisão. Quando possível, preveja a decisão que seu app vai tomar pode necessitar. No exemplo de vídeo, um modelo de classificação prevê se as categorias em que os vídeos classificava eram "sem cache", "barato cache", e um "cache caro". Ocultar o comportamento do app no modelo pode fazer com que o app produza o comportamento errado.
Entenda as restrições do problema. Caso seu app mude de ações com base em diferentes limites, determine se esses limites são fixos ou dinâmicos.
- Limites dinâmicos: se os limites forem dinâmicos, usar um modelo de regressão e definir os limites no código do app. Isso permite que você atualizar os limites e fazer com que o modelo faça previsões.
- Limites fixos: se os limites forem fixos, use um modelo de classificação. e rotule os conjuntos de dados com base nos limites.
Em geral, a maior parte do provisionamento de cache é dinâmico, e os limites mudam ao longo do tempo. Portanto, como este é especificamente um problema de armazenamento em cache, um de regressão é a melhor escolha. No entanto, para muitos problemas, os limites mínimos serão fixos, tornando o modelo de classificação a melhor solução.
Vamos analisar outro exemplo. Se você está criando um aplicativo de previsão do tempo
o resultado ideal é informar aos usuários quanta chuva vai chover nas próximas seis horas,
é possível usar um modelo de regressão que prevê o rótulo precipitation_amount.
| Resultado ideal | Rótulo ideal |
|---|---|
| Informe aos usuários a quantidade de chuva na área em que nas próximas seis horas. | precipitation_amount
|
No exemplo do app meteorológico, o rótulo aborda diretamente o resultado ideal.
No entanto, em alguns casos, não há uma relação de um para um entre as
o resultado ideal e o rótulo. Por exemplo, no app de vídeo, o resultado ideal
para recomendar vídeos úteis. No entanto, não há nenhum rótulo no conjunto de dados chamado
useful_to_user.
| Resultado ideal | Rótulo ideal |
|---|---|
| Recomende vídeos úteis. | ? |
Portanto, você precisa encontrar um rótulo de proxy.
Rótulos de proxy
Rótulos de proxy substituem
rótulos que não estão no conjunto de dados. Os marcadores de proxy são necessários quando não é possível
medir diretamente o que você quer prever. No app de vídeo, não podemos
avaliar se um usuário considera ou não um vídeo útil. Seria ótimo se
o conjunto de dados tinha um recurso useful, e os usuários marcaram todos os vídeos que encontraram
útil, mas como o conjunto de dados não tem, precisaremos de um rótulo proxy que
substitui a utilidade.
Um rótulo de utilidade pode ser o fato de o usuário compartilhar ou não o vídeo.
| Resultado ideal | Rótulo do proxy |
|---|---|
| Recomende vídeos úteis. | shared OR liked |
Tenha cuidado com rótulos de proxy, porque eles não medem diretamente o que você quer de prever. Por exemplo, a tabela a seguir descreve problemas com possíveis rótulos de proxy para Recomendar vídeos úteis:
| Rótulo do proxy | Problema |
|---|---|
| Prever se o usuário clicará no botão "Gostei" . | A maioria dos usuários nunca clica em "gostei". |
| Preveja se um vídeo fará sucesso. | Não personalizado. Alguns usuários podem não gostar de vídeos em alta. |
| Prever se o usuário vai compartilhar o vídeo. | Alguns usuários não compartilham vídeos. Às vezes, as pessoas compartilham vídeos porque eles não gostam deles. |
| Prever se o usuário vai clicar em "Reproduzir". | Maximiza o clickbait. |
| Preveja por quanto tempo eles assistem o vídeo. | Dá preferência a vídeos longos de forma diferenciada em relação a vídeos curtos. |
| Preveja quantas vezes o usuário vai assistir novamente o vídeo. | Favoritas que podem ser assistidas novamente vídeos em vez de gêneros de vídeo que não podem ser assistidos várias vezes. |
Nenhum rótulo substituto pode ser um substituto perfeito para seu resultado ideal. Todos vão têm problemas em potencial. Escolha aquela que tiver menos problemas para caso de uso de negócios.
Teste seu conhecimento
Geração
Na maioria dos casos, você não vai treinar seu próprio modelo generativo porque isso exige grandes quantidades de dados de treinamento e recursos computacionais. Em vez disso, você vai personalizar um modelo generativo pré-treinado. Para que um modelo generativo produza a saída desejada, talvez seja necessário usar um ou mais dos seguintes técnicas:
Destilação. Para criar um uma versão menor de um modelo maior, você gera um conjunto de dados sintético rotulado do modelo maior usado para treinar o menor. Generativa os modelos costumam ser enormes e consomem muitos recursos (como memória e eletricidade). A extração permite uma camada menor, com menos recursos modelo para aproximar o desempenho do modelo maior.
Ajuste ou ajuste com eficiência de parâmetros. Para melhorar o desempenho de um modelo em uma tarefa específica, é preciso treinar o modelo em um conjunto de dados que contenha exemplos do tipo de saída que você querem produzir.
Engenharia de comandos. Para faça com que o modelo execute uma tarefa específica produza a saída em um formato específico, você informa ao modelo a tarefa fazer ou explicar como você quer que a saída seja formatada. Em outras palavras, o comando pode incluir instruções em linguagem natural sobre como realizar a tarefa ou exemplos ilustrativos com os resultados desejados.
Por exemplo, se quiser resumos curtos de artigos, você pode inserir o seguinte:
Produce 100-word summaries for each article.Se quiser que o modelo gere texto para um nível de leitura específico, você pode inserir o seguinte:
All the output should be at a reading level for a 12-year-old.Se você quiser que o modelo forneça a saída em um formato específico, explicar como a saída deve ser formatada. Por exemplo, "formatar o resultados em uma tabela" — ou demonstrar a tarefa fornecendo exemplos. Por exemplo, você pode inserir o seguinte:
Translate words from English to Spanish. English: Car Spanish: Auto English: Airplane Spanish: Avión English: Home Spanish:______
A extração e o ajuste atualizam o valor parameters. Engenharia de comando não atualiza os parâmetros do modelo. Em vez disso, a engenharia de comandos ajuda o modelo aprende a produzir uma saída desejada usando o contexto do comando.
Em alguns casos, você também vai precisar conjunto de dados de teste para avaliar saída do modelo generativo com valores conhecidos, por exemplo, verificando se os resumos do modelo são semelhantes aos gerados por humanos, ou que humanos classificam os resumos do modelo como bons.
A IA generativa também pode ser usada para implementar um modelo solução, como classificação ou regressão. Por exemplo, devido ao seu profundo conhecimento de linguagem natural, Modelos de linguagem grandes (LLMs) pode realizar com frequência tarefas de classificação de texto melhor do que o ML preditivo treinado para a tarefa específica.
Definir as métricas de sucesso
Definir as métricas que você vai usar para determinar se a implementação de ML for bem-sucedida. As métricas de sucesso definem o que importa para você, como engajamento ajudar os usuários a tomar as medidas apropriadas, como assistir a vídeos que possam úteis. As métricas de sucesso diferem das métricas de avaliação do modelo, como accuracy, precisão, recall, ou AUC.
Por exemplo, as métricas de sucesso e falha de um aplicativo meteorológico podem ser definidas como o seguinte:
| Sucesso | Os usuários abrem o app "Vai chover?" apresentam 50% mais frequência do que antes. |
|---|---|
| Falha | Os usuários abrem o app "Vai chover?" no máximo antes. |
As métricas de apps de vídeo podem ser definidas da seguinte maneira:
| Sucesso | Os usuários passam, em média, 20% mais tempo no site. |
|---|---|
| Falha | Em média, os usuários não passam mais tempo no site do que antes. |
Recomendamos definir métricas de sucesso ambiciosas. Altas ambições podem causar lacunas entre o sucesso e o fracasso. Por exemplo, os usuários que gastam em média 10% a mais de tempo no site do que antes não significa sucesso nem falha. A lacuna indefinida não é o que é importante.
O importante é a capacidade do modelo de se aproximar, ou superam – a definição de sucesso. Por exemplo, ao analisar o tamanho desempenho, considere a seguinte pergunta: melhorar o modelo traria a mais perto dos seus critérios de sucesso definidos? Por exemplo, um modelo pode ter ótimos métricas de avaliação, mas sem aproximar você dos critérios de sucesso, indicando que, mesmo com um modelo perfeito, você não atenderia aos critérios de sucesso definido. Por outro lado, um modelo pode ter métricas de avaliação ruins, mas conseguir você mais perto de seus critérios de sucesso, indicando que melhorar o modelo deixar você mais perto do sucesso.
As dimensões a seguir devem ser consideradas ao determinar se o modelo vale melhorando:
Não é bom o suficiente, mas continue. O modelo não deve ser usado em um ambiente de produção, mas ele pode ser melhorado ao longo do tempo.
Bom o suficiente, e continue. O modelo pode ser usado em um ambiente ambiente de desenvolvimento de software e pode ser melhorado.
Bom o suficiente, mas não pode ser melhor. O modelo está em produção ambiente, mas provavelmente é tão bom quanto possível.
Não é bom o suficiente, e nunca será. O modelo não deve ser usado em um ambiente de produção e nenhuma quantidade de treinamento provavelmente vai chegar lá.
Ao decidir melhorar o modelo, reavalie se o aumento nos recursos como tempo de engenharia e custos de computação, justificam a melhoria prevista o modelo.
Depois de definir as métricas de sucesso e falha, é preciso determinar com que frequência você medirá. Por exemplo, você pode medir suas métricas de sucesso seis dias, seis semanas ou seis meses após a implementação do sistema.
Ao analisar as métricas de falha, tente determinar o motivo da falha do sistema. Para exemplo, o modelo pode prever em quais vídeos os usuários clicarão, mas o pode começar a recomendar títulos de clickbait que geram engajamento desistem. No exemplo do app meteorológico, o modelo pode prever com precisão quando vai chover, mas em uma região geográfica muito grande.
Teste seu conhecimento
Uma empresa de moda quer vender mais roupas. Alguém sugere usar ML para determinar quais roupas a empresa deve fabricar. Eles acham que podem treinar um modelo para determinar que tipo de roupa está na moda. Depois depois de treinar o modelo, aplicá-lo ao catálogo para decidir que roupas fazer.
Como ele deve estruturar o problema em termos de ML?
Resultado ideal: determine quais produtos fabricar.
Meta do modelo: prever quais artigos de vestuário estão de maneira
Saída do modelo: classificação binária, in_fashion,
not_in_fashion
Métricas de sucesso: vender 70% ou mais das roupas feitas.
Resultado ideal: determine a quantidade de tecido e materiais encomendados.
Meta do modelo: prever quanto de cada item será fabricado.
Saída do modelo: classificação binária, make,
do_not_make
Métricas de sucesso: vender 70% ou mais das roupas feitas.