根據預測結果 判斷問題最好的方式 您現在已準備好用機器學習術語來構思問題。 完成下列工作,即可依據機器學習術語找出問題:
- 定義理想的結果和模型的目標。
- 識別模型的輸出內容。
- 定義成效指標。
定義理想的結果和模型的目標
未採用機器學習模型,理想的結果為何?也就是 例如您希望產品或功能執行的確切工作原來是 先前在說明目標一節中定義的語句 專區。
藉由明確定義 讓模型執行下表說明理想的結果, 假設模型的目標:
| 應用程式 | 理想成果 | 模型的目標 |
|---|---|---|
| 「天氣」應用程式 | 以六小時為單位計算地理區域的降水量。 | 預測特定地理區域的六小時降水量。 |
| 時尚應用程式 | 產生各種襯衫設計。 | 根據文字和圖片生成三種襯衫設計 其中文字會指出樣式和顏色,而圖片則是 襯衫 (T 恤、鈕扣、馬球)。 |
| 影片應用程式 | 推薦實用影片。 | 預測使用者是否點選影片。 |
| 郵件應用程式 | 偵測垃圾內容。 | 預測電子郵件是否為垃圾郵件。 |
| 金融應用程式 | 摘要列出多個新聞來源的財經資訊。 | 根據 Google Cloud 業務中 。 |
| 地圖應用程式 | 計算交通時間。 | 預測兩點之間移動所需時間。 |
| 銀行應用程式 | 識別詐欺交易。 | 預測持卡人是否完成交易。 |
| 用餐應用程式 | 依據餐廳的菜單辨識料理。 | 預測餐廳類型。 |
| 電子商務應用程式 | 生成關於公司產品的客戶服務回覆。 | 運用情緒分析和機構的 知識庫 |
找出需要的輸出內容
要選擇的模型類型取決於 問題。模型的輸出內容應會完成 找出理想結果因此,第一個要回答的問題是 「使用哪種輸出方式解決我的問題?」
如果需要分類或進行數值預測 也能使用預測式機器學習如果需要產生新內容或 這可能會使用生成式 AI
下表列出預測式機器學習和生成式 AI 輸出內容:
| 機器學習系統 | 輸出範例 | |
|---|---|---|
| 分類 | 二進位數 | 將電子郵件分類為垃圾郵件或非垃圾郵件。 |
| 多類別單一標籤 | 將圖片中的動物分類。 | |
| 多類別多標籤 | 將圖片中的所有動物分類。 | |
| 數值 | 單維迴歸 | 預測影片獲得的觀看次數。 |
| 多維度迴歸 | 預測血壓、心率和膽固醇濃度 模型 |
| 模型類型 | 輸出範例 |
|---|---|
| 文字 |
提供文章重點摘要。 回覆顧客評論。 將文件從英文翻譯成中文。 撰寫產品說明。 分析法律文件。
|
| 圖片 |
產生行銷圖片。 為相片套用視覺效果。 產生產品設計變化版本。
|
| 音訊 |
以特定口音產生對話。
生成短音樂作品等特定類型的音樂,例如
爵士樂。
|
| 視訊 |
生成逼真的影片。
分析影片片段並套用視覺效果。
|
| 多模態 | 產生多種類型的輸出內容,例如含有字幕的影片。 |
分類
分類模型 預測輸入資料屬於哪個類別,例如輸入內容 應歸類為 A、B 或 C。
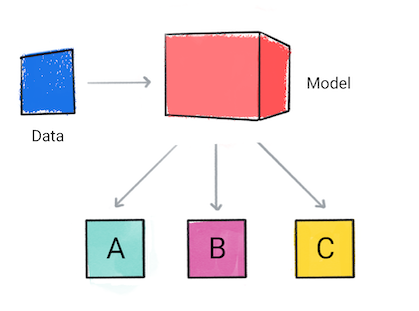
圖 1. 進行預測的分類模型。
應用程式可能會根據模型的預測結果做出決定。舉例來說 預測結果是類別 A,然後執行 X;如果預測值是 B 類別,則 do、Y;如果預測結果是類別 C,則務必 Z。在某些情況下 是應用程式的輸出內容。
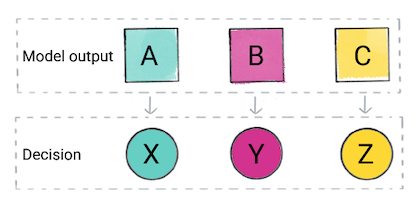
圖 2. 在產品程式碼中使用分類模型輸出內容 做出決定
迴歸
迴歸模型可預測 也就是數值
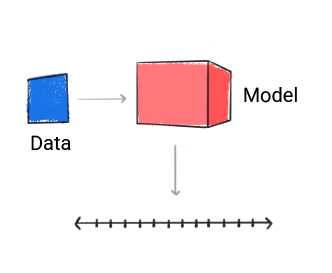
圖 3. 進行數字預測的迴歸模型。
應用程式可能會根據模型的預測結果做出決定。舉例來說 預測結果落在 A 範圍之內,執行 X如果預測值落在範圍內 B,做 Y;如果預測結果落在 C 範圍內,就應該 Z。在某些情況下, 預測「是」應用程式的輸出內容。
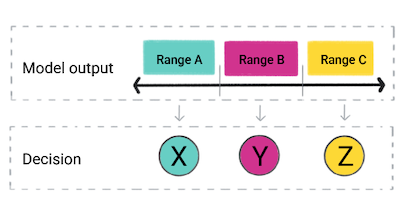
圖 4. 產品程式碼中使用迴歸模型的輸出內容 做出決策
請參考下列情境:
您想要快取 根據預測的熱門程度搜尋影片也就是說 預測影片將會很受歡迎,所以您可能會想快速向使用者提供影片。目的地: 如此一來,您就可以使用更有效且昂貴的快取。至於其他影片 使用不同的快取您的快取條件如下:
- 如果影片預計可獲得 50 次以上觀看次數,則不用付費 快取。
- 假設系統預測影片觀看次數介於 30 到 50 次之間,您就可以選用 快取。
- 如果影片預計獲得不到 30 次觀看,您就不會快取 影片。
你認為迴歸模型是正確的做法 數值,也就是觀看次數。但在訓練迴歸模型時 就會發現兩者產生的 預測結果 28 和 32的損失 觀看次數達 30 次的影片換句話說,雖然您的應用程式 當預測結果是 28 與 32 時,模型會同時考量兩者 而且預測結果一樣好
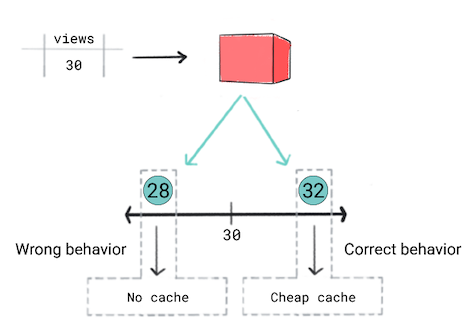
圖 5. 訓練迴歸模型。
迴歸模型不知道產品定義的門檻。因此,如果您的 應用程式的行為會大幅改變,因為 迴歸模型預測 分類模型
在這種情況下,分類模型就會產生正確的行為 因為分類模型的預測 28 比 32。理論上,分類模型預設會產生門檻。
本情境強調兩個重點:
預測決策。請盡可能預測應用程式的 取而代之在影片範例中,分類模型會預測 偵測影片分類後是否會「沒有快取」"便宜 快取」「高昂的快取」從模型中隱藏應用程式行為 會導致應用程式產生錯誤的行為。
瞭解問題限制。如果您的應用程式使用 會依據不同的門檻偵測動作 固定或動態變動
- 動態門檻:如果閾值是動態的,請使用迴歸模型 ,並在應用程式的程式碼中設定閾值限制。方便您輕鬆使用 更新門檻,同時讓模型 預測結果
- 固定門檻:如果門檻固定,請使用分類模型 並根據門檻限制為資料集加上標籤
一般來說,大部分的快取佈建作業都是動態的,且門檻會變動 長期下來。由於這是快取問題 迴歸模型是最佳選擇不過,在許多問題中 使分類模型成為最佳解決方案
接著再舉一個例子。如果要建構的天氣應用程式
最理想的結果是讓使用者知道接下來 6 小時內會下雨。
您可以用迴歸模型來預測「precipitation_amount.」標籤
| 理想成果 | 理想標籤 |
|---|---|
| 告知使用者所在地區的降雨量 在接下來的 6 小時 | precipitation_amount
|
在天氣應用程式範例中,標籤會直接說明理想結果。
但在某些情況下,一對一
並加上理想結果和標籤以影片應用程式為例,理想的結果是
推薦實用影片。但在名為
useful_to_user.
| 理想成果 | 理想標籤 |
|---|---|
| 推薦實用影片。 | ? |
因此,您必須找出 Proxy 標籤。
Proxy 標籤
Proxy 標籤替代
也就是不在資料集內的標籤
直接測量想要預測的內容在影片應用程式中,我們無法
評估使用者是否會覺得影片很實用如果
資料集具有 useful 功能,使用者標示了自己找到的所有影片
但由於資料集不需要,因此我們需要一個 Proxy 標籤
以及實用性的替代方法
提供便利性的 Proxy 標籤 能指出使用者會分享或按讚 影片。
| 理想成果 | Proxy 標籤 |
|---|---|
| 推薦實用影片。 | shared OR liked |
請謹慎使用 Proxy 標籤,因為這類標籤無法直接評估所需內容 以便預測例如,下表概述了潛在的問題 推薦實用影片的 Proxy 標籤:
| Proxy 標籤 | 問題 |
|---|---|
| 預測使用者是否點選「喜歡」按鈕。 | 大部分的使用者都不會按下「喜歡」。 |
| 預測影片是否熱門。 | 非個人化搜尋結果。部分使用者可能會不喜歡熱門影片。 |
| 預測使用者是否分享影片。 | 部分使用者不會分享影片。有時觀眾分享影片的原因 他們「不喜歡」 |
| 預測使用者是否點選播放。 | 盡量提高誘餌式點擊。 |
| 預測觀眾觀看影片的時間長度。 | 比起短片,長片較喜歡長篇影片。 |
| 預測使用者再次觀看影片的次數。 | 喜好項目:「可重複觀看」不能重複觀看的影片類型更勝以往 |
沒有任何替代標籤能取代理想結果。所有人都將 都可能發生潛在問題請挑選您最不容易問題的 具體來說,您可以設計提示來解決業務工作
驗收學習成果
代別
在多數情況下,您不需要訓練自己的生成式模型,因為這麼做的用意是 需要大量的訓練資料和運算資源 您將自訂預先訓練的生成式模型為了取得 產生所需的輸出內容,您可能需要使用下列一或多項 技巧:
精煉作業。如要建立 並產生合成標籤資料集 並使用較大型的模型來訓練較小型的模型生成式 模型通常無害且耗用大量資源 (例如記憶體) 電費、電力) 和電力) 搭配。精煉作業可以用來建構規模較小、所需資源較少 以估算大型模型的成效
微調或 高效調整參數: 如要提升特定工作上的模型效能,您需要 用來訓練模型,該資料集含有您的輸出類型範例 想要製作的內容
提示工程:目的地: 取得模型執行特定工作 您要生成特定格式的輸出內容 該如何執行或說明輸出結果的格式。也就是說 提示可以包含如何執行工作的自然語言指示 或舉例說明想輸出的內容
舉例來說,如果您想獲得文章摘要,可以在 包括:
Produce 100-word summaries for each article.如要讓模型產生特定讀物分級的文字 那麼,您可以輸入:
All the output should be at a reading level for a 12-year-old.如果您希望模型以特定格式提供輸出內容,您可以 說明輸出內容的格式,例如「格式化 或展示工作成果 用自己的例子來說明舉例來說,您可以輸入以下內容:
Translate words from English to Spanish. English: Car Spanish: Auto English: Airplane Spanish: Avión English: Home Spanish:______
精煉與微調會更新模型的 參數。提示工程 模型的參數不會更新相反地,提示工程可以 模型會學習如何根據提示內容生成所需的輸出內容
在某些情況下,您還需要 測試資料集來評估 根據已知值對生成式模型輸出內容 模型的摘要與人類生成的摘要相似 模型的摘要品質也很好
生成式 AI 也能用來導入預測式機器學習 例如分類或迴歸 舉例來說,因為他們對自然語言有深厚的瞭解 大型語言模型 (LLM) 可能比預測式機器學習更能有效執行文字分類工作 特定任務訓練而成
定義成效指標
定義您用來決定機器學習實作的指標 代表成功。成效指標可以定義您重視的指標,例如參與度或 協助使用者採取適當行動,例如觀看他們找到的影片 很實用成效指標與模型的評估指標不同,例如 準確率、 精確度、 喚回度,或 AUC。
舉例來說,天氣應用程式的成功和失敗指標可以定義為 包括:
| 成功 | 使用者開啟「會下雨嗎?」產品特色 |
|---|---|
| 失敗 | 使用者開啟「會下雨嗎?」功能的頻率 。 |
影片應用程式指標的定義可能如下:
| 成功 | 使用者在網站上停留的時間平均增加 20%。 |
|---|---|
| 失敗 | 相較於過去,使用者平均在網站上停留的時間不多。 |
建議您定義明確的成效指標。目標過高會造成資料缺口 成功與失敗之間取得平衡舉例來說,使用者 網站停留時間比以往多 10%,既不是成功,也沒有失敗。 間隔未定義並不重要。
重要的是,模型能否更接近 成功的定義舉例來說,分析模型的 請思考以下問題:改善模型能否讓您獲得 最貼近您訂定的成功標準?例如,模型可能 但不會讓你更接近成功標準 就算是完美的模型,還是無法達到 另一方面,模型的評估指標可能偏低 就接近成功標準,這意味著改善模型 逐步邁向成功
以下是判斷模型是否價值時需考慮的維度 改善:
非常好,但請繼續。模型不應用於 但長期下來這個架構可能會大幅改善。
夠好了,請繼續。模型可用於正式環境 也可能會精進
不錯,但無法再精益求精。模型處於正式環境 但一定可以做到。
能力不足,永遠不會改變。模型不應用於 而且不多進行的訓練都有機會達成這個目標
在決定改善模型時,請重新評估資源是否增加 例如工程時間和運算成本 模型
定義成功和失敗指標後,您需要決定多久 進行評估例如,您可以測量成效指標 六 啟動系統後的 15 天、6 週或 6 個月。
在分析失敗指標時,請嘗試判斷系統失敗的原因。適用對象 例如,模型可能預測使用者會點選哪些影片 模型可能會開始建議 使用者參與度 提高點擊的誘餌式點擊標題 落地生意。在天氣應用程式範例中,模型可能會準確預測 可能會下雨,但地理區域過大
驗收學習成果
一家時尚公司想提高服飾銷售量。有人建議使用機器學習技術 決定要製造哪件衣服。他們認為自己可以 訓練模型來判斷衣服的類型。更新後 訓練模型時,會想將模型套用至目錄 各種衣服
他們該如何以機器學習術語來構思問題?
理想成果:決定要製造哪些產品。
模型的目標:預測哪些服飾文章出現在 。
模型輸出:二進位分類、in_fashion、
not_in_fashion
成效指標:衣服銷量 70% 以上 執行。
理想成果:判斷要訂購的布料和用品。
模型的目標:預測每個商品的製造量。
模型輸出:二進位分類、make、
do_not_make
成效指標:衣服銷量 70% 以上 執行。