Setelah memverifikasi bahwa masalah Anda dapat diselesaikan dengan ML atau pendekatan AI generatif, Anda siap merumuskan masalah Anda dalam istilah ML. Anda menyusun masalah dalam konteks ML dengan menyelesaikan tugas-tugas berikut:
- Menentukan hasil ideal dan sasaran model.
- Identifikasi output model.
- Tentukan metrik keberhasilan.
Menentukan hasil ideal dan sasaran model
Terlepas dari model ML, apa hasil yang ideal? Dengan kata lain, apakah tugas spesifik yang Anda inginkan untuk dijalankan oleh produk atau fitur? Ini sama saja pernyataan yang sebelumnya Anda tetapkan di Nyatakan tujuan bagian.
Hubungkan sasaran model ke hasil ideal dengan menentukan secara eksplisit hal yang Anda dari model yang Anda inginkan. Tabel berikut menyatakan hasil ideal dan tujuan model untuk aplikasi hipotetis:
| Aplikasi | Hasil yang ideal | Sasaran model |
|---|---|---|
| Aplikasi Cuaca | Hitung presipitasi dalam kelipatan enam jam untuk suatu wilayah geografis. | Memprediksi jumlah presipitasi enam jam untuk wilayah geografis tertentu. |
| Aplikasi mode | Membuat berbagai desain kemeja. | Membuat tiga variasi desain kemeja dari teks dan gambar, di mana teks menyatakan gaya dan warna, dan gambar adalah jenis kemeja (kaos, berkancing, polo). |
| Aplikasi video | Sarankan video yang bermanfaat. | Memprediksi apakah pengguna akan mengklik video. |
| Aplikasi email | Mendeteksi spam. | Memprediksi apakah email merupakan spam atau bukan. |
| Aplikasi keuangan | Meringkas informasi keuangan dari berbagai sumber berita. | Buat ringkasan 50 kata tentang tren keuangan utama dari tujuh hari sebelumnya. |
| Aplikasi peta | Hitung waktu perjalanan. | Perkirakan berapa lama waktu yang dibutuhkan untuk melakukan perjalanan di antara dua titik. |
| Aplikasi perbankan | Mengidentifikasi transaksi penipuan. | Memprediksi apakah transaksi dilakukan oleh pemegang kartu. |
| Aplikasi Makan | Mengidentifikasi masakan berdasarkan menu restoran. | Memprediksi jenis restoran. |
| Aplikasi E-commerce | Menghasilkan balasan dukungan pelanggan tentang produk perusahaan. | Menghasilkan balasan menggunakan analisis sentimen dan laporan pusat informasi. |
Identifikasi output yang Anda butuhkan
Pilihan jenis model Anda bergantung pada konteks dan batasan tertentu dari menyelesaikan masalah Anda. Output model akan menyelesaikan tugas yang ditentukan dalam hasil yang ideal. Jadi, pertanyaan pertama yang harus dijawab adalah "Jenis output apa yang saya butuhkan untuk menyelesaikan masalah?"
Jika Anda perlu mengklasifikasikan sesuatu atau membuat prediksi numerik, Anda mungkin akan gunakan ML prediktif. Jika Anda perlu membuat konten baru atau output terkait natural language understanding, Anda mungkin akan menggunakan AI generatif.
Tabel berikut mencantumkan output ML prediktif dan AI generatif:
| Sistem ML | Contoh output | |
|---|---|---|
| Klasifikasi | Biner | Mengklasifikasikan email sebagai spam atau bukan spam. |
| Multiclass label tunggal | Klasifikasikan hewan pada gambar. | |
| Multi-label kelas | Klasifikasikan semua hewan dalam gambar. | |
| Numerik | Regresi unidimensi | Memprediksi jumlah penayangan yang akan didapatkan video. |
| Regresi multidimensi | Memprediksi tekanan darah, detak jantung, dan kadar kolesterol untuk individu. |
| Jenis model | Contoh output |
|---|---|
| Teks |
Meringkas artikel. Balas ulasan pelanggan. Menerjemahkan dokumen dari bahasa Inggris ke Mandarin. Tulis deskripsi produk. Menganalisis dokumen hukum.
|
| Gambar |
Buat gambar pemasaran. Menerapkan efek visual pada foto. Menghasilkan variasi desain produk.
|
| Audio |
Menghasilkan dialog dalam aksen tertentu.
Membuat komposisi musik singkat dalam genre tertentu, seperti
jazz.
|
| Video |
Buat video yang terlihat realistis.
Menganalisis rekaman video dan menerapkan efek visual.
|
| Multimodal | Buat beberapa jenis output, seperti video dengan teks teks. |
Klasifikasi
Model klasifikasi memprediksi kategori data input, misalnya, apakah suatu input harus diklasifikasikan sebagai A, B, atau C.
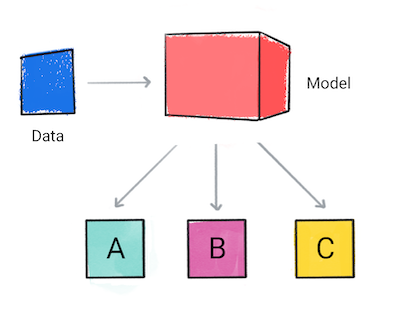
Gambar 1. Model klasifikasi membuat prediksi.
Berdasarkan prediksi model, aplikasi Anda mungkin membuat keputusan. Misalnya, jika prediksinya adalah kategori A, maka lakukanlah X; jika prediksinya berkategori B, maka lakukan, Y; jika prediksinya adalah kategori C, maka lakukan Z. Dalam beberapa kasus, prediksi adalah output aplikasi.
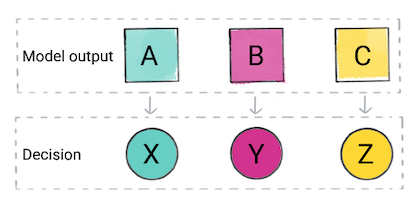
Gambar 2. Output model klasifikasi yang digunakan dalam kode produk untuk membuat keputusan.
Regresi
Model regresi memprediksi nilai numerik.
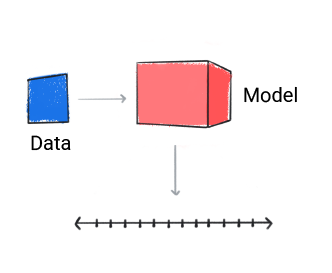
Gambar 3. Model regresi yang membuat prediksi numerik.
Berdasarkan prediksi model, aplikasi Anda mungkin membuat keputusan. Misalnya, jika prediksi berada dalam rentang A, lakukan X; jika prediksi berada dalam rentang B, lakukan Y; jika prediksi berada dalam rentang C, lakukan Z. Dalam beberapa kasus, prediksi adalah output aplikasi.
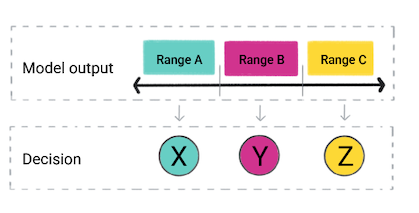
Gambar 4. Output model regresi yang digunakan dalam kode produk untuk membuat sebuah keputusan.
Pertimbangkan skenario berikut:
Anda ingin melakukan cache video berdasarkan prediksi popularitasnya. Dengan kata lain, jika model Anda memprediksi bahwa video akan populer, Anda ingin segera menayangkannya kepada pengguna. Kepada melakukannya, Anda akan menggunakan cache yang lebih efektif dan mahal. Untuk video lainnya, Anda akan menggunakan {i>cache<i} yang berbeda. Kriteria penyimpanan dalam cache Anda adalah sebagai berikut:
- Jika video diprediksi akan mendapatkan 50 penayangan atau lebih, Anda harus menggunakan di cache oleh pengguna.
- Jika video diprediksi akan mendapatkan 30 sampai 50 penayangan, Anda harus menggunakan di cache oleh pengguna.
- Jika video diperkirakan akan mendapatkan kurang dari 30 penayangan, Anda tidak akan meng-cache video.
Anda pikir model regresi adalah pendekatan yang tepat karena Anda akan memprediksi nilai numerik—jumlah tampilan. Namun, saat melatih model regresi Anda menyadari bahwa model tersebut menghasilkan kerugian untuk prediksi 28 dan 32 untuk video yang memiliki 30 penayangan. Dengan kata lain, meskipun aplikasi Anda akan memiliki jika prediksinya adalah 28 versus 32, model akan mempertimbangkan prediksi yang sama baiknya.
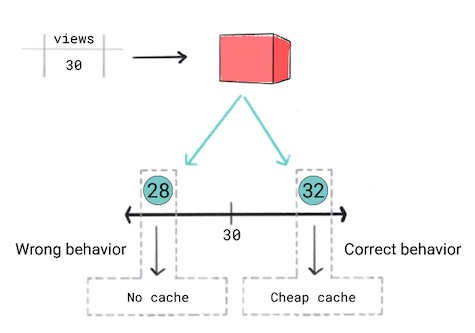
Gambar 5. Melatih model regresi.
Model regresi tidak mengetahui nilai minimum yang ditentukan produk. Oleh karena itu, jika perilaku aplikasi berubah secara signifikan karena perbedaan kecil dalam prediksi model regresi ini, sebaiknya Anda mempertimbangkan untuk model klasifikasi sebagai gantinya.
Dalam skenario ini, model klasifikasi akan menghasilkan perilaku yang benar karena model klasifikasi akan menghasilkan kerugian yang lebih tinggi 28 dibandingkan 32. Bisa dibilang, model klasifikasi menghasilkan nilai minimum secara default.
Skenario ini menyoroti dua poin penting:
Memprediksi keputusan. Jika memungkinkan, prediksikan keputusan yang akan dilakukan aplikasi Anda berapa lama proyek itu akan berlangsung. Dalam contoh video, model klasifikasi akan memprediksi jika kategori yang digunakan untuk mengklasifikasikan video adalah "tidak ada cache", "murah {i>cache<i},” dan "cache mahal". Menyembunyikan perilaku aplikasi dari model dapat menyebabkan aplikasi Anda menghasilkan perilaku yang salah.
Pahami batasan masalah. Jika aplikasi Anda mengambil tindakan berdasarkan ambang batas yang berbeda, menentukan apakah ambang batas tersebut tetap atau dinamis.
- Ambang batas dinamis: Jika nilai minimum bersifat dinamis, gunakan model regresi dan tetapkan batas nilai minimum dalam kode aplikasi Anda. Hal ini memudahkan Anda memperbarui ambang batas sambil tetap membuat model masuk akal terhadap prediksi yang di-output oleh model.
- Ambang batas tetap: Jika ambang batas tetap, gunakan model klasifikasi dan melabeli {i>dataset<i} Anda berdasarkan batas ambang batas tersebut.
Secara umum, sebagian besar penyediaan cache bersifat dinamis dan nilai minimumnya berubah seiring waktu. Oleh karena itu, karena ini secara khusus masalah {i>caching<i}, sebuah model regresi adalah pilihan terbaik. Namun, untuk banyak masalah, nilai minimum data akan tetap, sehingga model klasifikasi menjadi solusi terbaik.
Mari lihat contoh lain. Jika Anda sedang membangun aplikasi cuaca yang
hasil idealnya adalah memberi tahu pengguna
berapa banyak hujan yang akan turun dalam enam jam ke depan,
Anda dapat menggunakan model regresi yang memprediksi label precipitation_amount.
| Hasil yang ideal | Label ideal |
|---|---|
| Beri tahu pengguna seberapa banyak hujan akan turun di daerah mereka dalam enam jam ke depan. | precipitation_amount
|
Dalam contoh aplikasi cuaca, label secara langsung membahas hasil ideal.
Namun, dalam beberapa kasus, hubungan one-to-one tidak terlihat jelas antara
hasil ideal dan labelnya. Misalnya, dalam aplikasi video, hasil idealnya adalah
untuk merekomendasikan video yang berguna. Namun, tidak ada label dalam
{i>dataset<i} yang disebut
useful_to_user.
| Hasil yang ideal | Label ideal |
|---|---|
| Rekomendasikan video yang bermanfaat. | ? |
Oleh karena itu, Anda harus menemukan label proxy.
Label proxy
Pengganti Label proxy untuk
label yang tidak ada dalam set data. Label proxy diperlukan
ketika Anda tidak dapat
mengukur secara langsung
apa yang ingin Anda prediksi. Di aplikasi video, kita tidak bisa langsung
mengukur apakah pengguna akan menganggap suatu video berguna atau tidak. Akan lebih baik jika
memiliki fitur useful, dan pengguna menandai semua video yang mereka temukan
berguna, tetapi karena {i>dataset<i} tidak, kita membutuhkan label {i>proxy<i} yang
pengganti kegunaan.
Label {i>proxy<i} untuk kegunaan mungkin apakah pengguna akan berbagi atau tidak suka video.
| Hasil yang ideal | Label proxy |
|---|---|
| Rekomendasikan video yang bermanfaat. | shared OR liked |
Berhati-hatilah dengan label proxy karena tidak secara langsung mengukur hal yang Anda inginkan untuk diprediksi. Misalnya, tabel berikut menguraikan masalah dengan label proxy untuk Rekomendasi video berguna:
| Label proxy | Masalah |
|---|---|
| Buat prediksi apakah pengguna akan mengklik "suka" tombol. | Sebagian besar pengguna tidak pernah mengklik "suka". |
| Memprediksi apakah video akan populer atau tidak. | Tidak dipersonalisasi. Beberapa pengguna mungkin tidak menyukai video populer. |
| Memprediksi apakah pengguna akan membagikan video. | Beberapa pengguna tidak berbagi video. Kadang-kadang, orang berbagi video karena mereka tidak menyukainya. |
| Memprediksi apakah pengguna akan mengklik putar. | Memaksimalkan clickbait. |
| Memprediksi berapa lama mereka menonton video. | Lebih memilih video panjang daripada video pendek. |
| Perkirakan berapa kali pengguna akan menonton ulang video. | Konten favorit "dapat ditonton ulang" video dengan genre video yang tidak dapat ditonton ulang. |
Tidak ada label proxy yang dapat menjadi pengganti sempurna untuk hasil ideal Anda. Semua akan memiliki potensi masalah. Pilih salah satu yang memiliki paling sedikit masalah untuk Anda kasus penggunaan.
Memeriksa Pemahaman Anda
Generation
Pada umumnya, Anda tidak perlu melatih model generatif Anda sendiri karena membutuhkan data pelatihan dan sumber daya komputasi dalam jumlah besar. Sebagai gantinya, Anda akan menyesuaikan model generatif yang telah dilatih sebelumnya. Untuk membuat model generatif menghasilkan {i>output<i} yang diinginkan, Anda mungkin perlu menggunakan satu atau beberapa teknik:
Distilasi. Untuk membuat versi yang lebih kecil dari model yang lebih besar, Anda akan membuat set data berlabel sintetis dari model yang lebih besar yang Anda gunakan untuk melatih model yang lebih kecil. Peringkas model biasanya sangat besar dan menghabiskan resource substansial (seperti memori dan listrik). Distilasi memungkinkan proses yang lebih kecil dan tidak terlalu intensif sumber daya untuk memperkirakan performa model yang lebih besar.
Fine-tuning atau parameter-efficient tuning. Untuk meningkatkan performa model pada tugas tertentu, Anda perlu latih model pada set data yang berisi contoh jenis output yang dihasilkan oleh perusahaan Anda.
Prompt Engineering. Kepada membuat model menjalankan tugas tertentu atau menghasilkan output dalam format tertentu, Anda memberi tahu model tugas yang diinginkan untuk melakukan atau menjelaskan bagaimana Anda ingin memformat {i>output<i}. Dengan kata lain, dapat mencakup petunjuk natural language tentang cara melakukan tugas atau ilustratif dengan output yang diinginkan.
Misalnya, jika Anda ingin ringkasan singkat artikel, Anda dapat memasukkan berikut ini:
Produce 100-word summaries for each article.Jika Anda ingin model ini menghasilkan teks untuk tingkat kemampuan membaca tertentu, Anda dapat memasukkan hal berikut:
All the output should be at a reading level for a 12-year-old.Jika Anda ingin model memberikan output-nya dalam format tertentu, Anda mungkin menjelaskan bagaimana {i>output<i} harus diformat—misalnya, "memformat menghasilkan tabel"—atau Anda dapat mendemonstrasikan tugas dengan memberikan contoh. Misalnya, Anda dapat memasukkan kode berikut:
Translate words from English to Spanish. English: Car Spanish: Auto English: Airplane Spanish: Avión English: Home Spanish:______
Distilasi dan fine-tuning memperbarui atribut parameter. Engineering perintah tidak memperbarui parameter model. Sebaliknya, Prompt Engineering membantu mempelajari cara menghasilkan output yang diinginkan dari konteks prompt.
Dalam beberapa kasus, Anda juga memerlukan set data pengujian untuk mengevaluasi output model generatif terhadap nilai yang diketahui. Misalnya, memeriksa ringkasan model mirip dengan ringkasan buatan manusia, atau yang dinilai manusia ringkasan model.
AI generatif juga dapat digunakan untuk menerapkan ML prediktif solusi, seperti klasifikasi atau regresi. Misalnya, karena pengetahuan mereka yang mendalam tentang natural language, model bahasa besar (LLM) sering dapat melakukan tugas klasifikasi teks lebih baik daripada ML prediktif dilatih untuk tugas tertentu.
Menentukan metrik keberhasilan
Tentukan metrik yang akan Anda gunakan untuk menentukan apakah implementasi ML atau tidak berhasil. Metrik kesuksesan menentukan apa yang penting bagi Anda, seperti keterlibatan atau membantu pengguna mengambil tindakan yang tepat, seperti menonton video yang akan mereka temukan berguna Metrik keberhasilan berbeda dari metrik evaluasi model, seperti akurasi, presisi, penarikan, atau AUC.
Misalnya, metrik keberhasilan dan kegagalan aplikasi cuaca dapat diartikan sebagai hal berikut:
| Berhasil | Pengguna membuka dialog "Apakah akan hujan?" fitur 50 persen lebih sering daripada sebelumnya. |
|---|---|
| Kegagalan | Pengguna membuka dialog "Apakah akan hujan?" fitur tidak lebih dari sebelumnya. |
Metrik aplikasi video dapat ditentukan sebagai berikut:
| Berhasil | Pengguna menghabiskan waktu rata-rata 20 persen lebih banyak di situs. |
|---|---|
| Kegagalan | Pengguna rata-rata menghabiskan waktu di situs rata-rata tidak lebih dari sebelumnya. |
Sebaiknya tentukan metrik keberhasilan yang ambisius. Ambisi yang tinggi dapat menimbulkan kesenjangan antara keberhasilan dan kegagalan. Misalnya, rata-rata pengeluaran pengguna 10 persen lebih banyak waktu di situs dibandingkan sebelumnya berarti tidak berhasil atau gagal. Kesenjangan yang tidak terdefinisi bukanlah yang penting.
Yang penting adalah kapasitas model Anda untuk mendekat—atau melampaui—definisi kesuksesan. Misalnya, saat menganalisis performa, pertimbangkan pertanyaan berikut: Apakah meningkatkan model akan membantu Anda mendekati kriteria keberhasilan yang Anda tetapkan? Misalnya, sebuah model mungkin memiliki evaluasi, tetapi tidak membuat Anda semakin dekat dengan kriteria keberhasilan, yang menunjukkan bahwa bahkan dengan model yang sempurna, Anda tidak akan memenuhi kriteria keberhasilan didefinisikan. Di sisi lain, model mungkin memiliki metrik evaluasi yang buruk, tetapi semakin dekat dengan kriteria keberhasilan, yang menunjukkan bahwa meningkatkan model akan membawa Anda lebih dekat menuju kesuksesan.
Berikut adalah dimensi yang perlu dipertimbangkan saat menentukan apakah model tersebut layak digunakan memperbaiki:
Kurang baik, tetapi lanjutkan. Model tidak boleh digunakan dalam lingkungan produksi Anda, tetapi seiring waktu mungkin akan meningkat secara signifikan.
Cukup baik, dan lanjutkan. Model ini dapat digunakan dalam lingkungan production yang lebih baik, dan bisa lebih ditingkatkan.
Cukup bagus, tetapi tidak dapat ditingkatkan. Model berada dalam produksi yang lebih baik, tapi mungkin sudah bagus.
Tidak cukup baik, dan tidak akan pernah cukup. Model tidak boleh digunakan dalam lingkungan produksi dan tidak adanya pelatihan mungkin akan membuatnya sampai di sana.
Ketika memutuskan untuk meningkatkan kualitas model, evaluasi ulang apakah peningkatan sumber daya, seperti waktu rekayasa dan biaya komputasi, membenarkan prediksi peningkatan model.
Setelah menentukan metrik keberhasilan dan kegagalan, Anda perlu menentukan frekuensi Anda akan mengukurnya. Misalnya, Anda dapat mengukur metrik kesuksesan Anda dengan enam hari, enam minggu, atau enam bulan setelah menerapkan sistem.
Saat menganalisis metrik kegagalan, cobalah untuk mencari tahu mengapa sistem gagal. Sebagai misalnya, model ini mungkin memprediksi video mana yang akan diklik pengguna, tetapi mungkin mulai merekomendasikan judul clickbait yang menyebabkan engagement pengguna pengguna keluar. Dalam contoh aplikasi cuaca, model mungkin secara akurat memprediksi kapan akan hujan tetapi untuk wilayah geografis yang terlalu luas.
Memeriksa Pemahaman Anda
Sebuah perusahaan mode ingin menjual lebih banyak pakaian. Seseorang menyarankan penggunaan ML untuk menentukan pakaian mana yang harus diproduksi perusahaan. Menurut mereka, mereka bisa melatih model untuk menentukan jenis pakaian mana yang sedang populer. Sesudah mereka melatih model, mereka ingin menerapkannya ke katalog pakaian mana yang harus dibuat.
Bagaimana sebaiknya mereka merumuskan masalah dalam istilah ML?
Hasil ideal: Tentukan produk mana yang akan diproduksi.
Sasaran model: Memprediksi artikel pakaian yang dipakai mode.
Output model: Klasifikasi biner, in_fashion,
not_in_fashion
Metrik keberhasilan: Menjual tujuh puluh persen pakaian atau lebih dilakukan.
Hasil ideal: Tentukan jumlah bahan dan persediaan yang dapat dipesan.
Sasaran model: Memprediksi jumlah setiap item yang akan diproduksi.
Output model: Klasifikasi biner, make,
do_not_make
Metrik keberhasilan: Menjual tujuh puluh persen pakaian atau lebih dilakukan.