在验证使用预测性预测功能 机器学习或生成式 AI 方法,就可以用机器学习术语来阐述您的问题。 您可以通过完成以下任务来用机器学习术语来表示问题:
- 定义理想的结果和模型的目标。
- 识别模型的输出。
- 定义成效指标。
定义理想的结果和模型的目标
不依赖机器学习模型,理想结果是什么?也就是说, 您希望自己的产品或功能执行的具体任务。这与 陈述目标 部分。
通过明确定义要达成的目标,将模型的目标与理想的结果联系起来 希望模型执行的操作。下表说明了理想的结果和 模型对于假设应用的目标:
| 应用广告系列 | 理想结果 | 模型的目标 |
|---|---|---|
| 天气应用 | 以六小时为增量计算一个地理区域的降水量。 | 预测特定地理区域六小时的降水量。 |
| 时尚应用 | 生成各种衬衫设计。 | 根据文本和图片生成三种类型的衬衫设计, 其中,文本说明样式和颜色,而图片则是 衬衫(T 恤、纽扣、Polo)。 |
| 视频应用 | 推荐实用视频。 | 预测用户是否会点击视频。 |
| “邮件”应用 | 检测垃圾邮件。 | 预测电子邮件是否为垃圾邮件。 |
| 金融应用 | 总结多个新闻媒体的财经信息。 | 生成 50 个字的总结,了解主要财务趋势 前七天。 |
| 地图应用 | 计算行程时间。 | 预测两点之间行程所需的时间。 |
| 银行应用 | 识别欺诈性交易。 | 预测某笔交易是否是持卡人完成的。 |
| 餐饮应用 | 根据餐厅菜单识别菜肴。 | 预测餐馆类型。 |
| 电子商务应用 | 生成有关公司产品的客户支持回复。 | 根据情感分析和组织的情感分析生成回复 知识库。 |
确定您需要的输出
模型类型的选择取决于具体的上下文和 您遇到的问题。模型的输出应完成 理想结果。因此,要回答的第一个问题是 “解决我的问题需要哪种类型的输出?”
如果您需要对数据进行分类或进行数字预测, 使用预测性机器学习。如果您需要生成新内容或生成输出内容 自然语言理解相关任务,您可能会使用生成式 AI。
下表列出了预测性机器学习和生成式 AI 的输出结果:
| 机器学习系统 | 输出示例 | |
|---|---|---|
| 分类 | 二进制 | 将电子邮件归类为垃圾邮件或非垃圾邮件。 |
| 多类别单标签 | 对图片中的动物进行分类。 | |
| 多类别多标签 | 对图片中的所有动物进行分类。 | |
| 数值 | 一维回归 | 预测视频将获得的观看次数。 |
| 多维回归 | 预测血压、心率和胆固醇水平 一个人。 |
| 模型类型 | 输出示例 |
|---|---|
| 文本 |
总结文章。 回复客户评价。 将文档从英语翻译成普通话。 撰写产品说明。 分析法律文件。
|
| 图片 |
生成营销图片。 对照片应用视觉效果。 生成产品设计变体。
|
| 音频 |
以特定口音生成对话。
生成特定流派的短乐曲,例如
爵士乐。
|
| 视频 |
生成逼真的视频。
分析视频片段并应用视觉效果。
|
| 多模态 | 生成多种类型的输出,例如带有文字说明的视频。 |
分类
分类模型 预测输入数据属于哪个类别,例如, 应归类为 A、B 或 C。
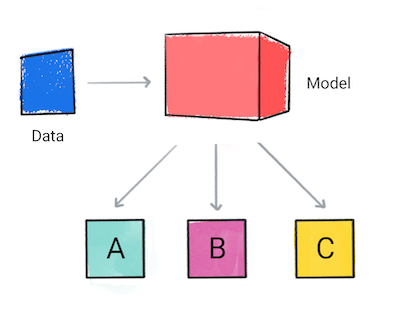
图 1. 进行预测的分类模型。
根据模型的预测,您的应用可能会做出决策。例如,如果 则预测为 A 类,则 X;如果预测结果是 B 类,则 do、Y;如果预测属于 C 类,则执行 Z。在某些情况下, 是应用的输出。
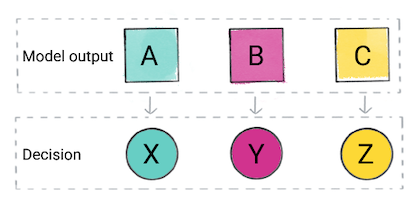
图 2. 分类模型的输出,用于商品代码 做出决定。
回归
回归模型可 数值。
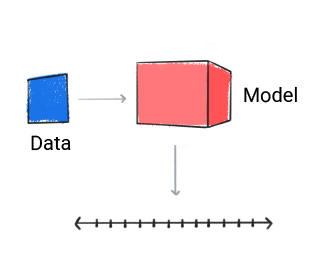
图 3. 进行数值预测的回归模型。
根据模型的预测,您的应用可能会做出决策。例如,如果 预测值在 A 区间内,做 X;如果预测值在 B,执行 Y;如果预测结果在 C 范围内,则执行 Z。在某些情况下, 预测就是应用的输出。

图 4. 产品代码中使用的回归模型输出 做出决定。
请考虑以下场景:
您想要缓存 根据视频的预计热门程度预测视频。换句话说,如果您的模型 预测视频会很受欢迎,您想要快速向用户提供该视频。接收者 那么可以使用更有效、更昂贵的缓存。对于其他视频 将使用不同的缓存您的缓存条件如下:
- 如果预计视频会获得 50 次或更多观看次数, 缓存。
- 如果视频预计会获得 30 到 50 次观看,则您可以使用价格较低的 缓存。
- 如果预测视频的观看次数少于 30 次,则系统不会缓存 视频。
您认为回归模型是正确的方法, 数值—观看次数。不过,在训练回归模型时, 就会发现它会产生 loss:预测值为 28 和 32 为观看次数达到 30 次的视频换言之,虽然您的应用 如果预测结果为 28 与 32,则模型会同时考虑两者 预测效果也一样出色。

图 5. 训练回归模型。
回归模型不了解产品定义的阈值。因此,如果您的 应用的行为 回归模型的预测,您应该考虑实现一个 分类模型。
在这种情况下,分类模型将产生正确的行为 因为分类模型对预测 28 比 32。从某种意义上说,分类模型默认会生成阈值。
此方案强调了两个要点:
预测决策。尽可能预测您的应用将会做出的决策 。在视频示例中,分类模型会预测 从而决定视频是否归入“无缓存”的类别,"便宜 缓存”以及“昂贵的缓存”在模型中隐藏应用行为 导致应用出现错误的行为。
了解问题的限制。如果您的应用 根据不同的阈值确定这些阈值是否 是固定的还是动态的
- 动态阈值:如果阈值是动态的,请使用回归模型 并在应用的代码中设置阈值。这样,您就可以 更新阈值,同时让模型 预测。
- 固定阈值:如果阈值是固定的,请使用分类模型 并根据阈值限制为数据集添加标签。
一般来说,大多数缓存预配是动态的,并且阈值会发生变化 。因此,由于这具体是缓存问题, 是最佳选择。不过,对于许多问题, 因此分类模型是最佳解决方案。
我们再来看一个示例。如果您正在构建一款天气应用,该应用
理想的结果是告知用户未来 6 小时内的雨量,
则可以使用回归模型来预测标签“precipitation_amount.”
| 理想结果 | 理想标签 |
|---|---|
| 告知用户其所在区域的降雨量 接下来的六个小时 | precipitation_amount
|
在天气应用示例中,标签直接指明了理想的结果。
但在某些情况下,这两者之间的一对一关系并不明显
理想结果和标签。例如,在视频应用中,理想结果是
来推荐实用视频但是,数据集中没有名为
useful_to_user.
| 理想结果 | 理想标签 |
|---|---|
| 推荐实用视频。 | ? |
因此,您必须找到一个代理标签。
代理标签
代理标签替换为
标签。无法使用代理标签时
直接衡量您想要预测的内容。在视频应用中,我们无法
衡量用户是否认为视频有用。如果
数据集具有 useful 特征,用户标记了他们找到的所有视频
有用,但由于数据集没有用,因此我们需要一个
实用性的替代标签可以是用户是否愿意分享或点赞 视频。
| 理想结果 | 代理标签 |
|---|---|
| 推荐实用视频。 | shared OR liked |
请谨慎使用代理标签,因为它们不会直接衡量您需要的内容 要预测的内容。例如,下表概述了 推荐实用视频的代理标签:
| 代理标签 | 问题 |
|---|---|
| 预测用户是否会点击“赞”按钮。 | 大多数用户从不点击“顶”。 |
| 预测某个视频是否会热门。 | 不是个性化结果。某些用户可能不喜欢热门视频。 |
| 预测用户是否会分享视频。 | 部分用户不分享视频。有时,人们分享视频的原因 不喜欢。 |
| 预测用户是否会点击播放。 | 最大限度地增加点击诱饵。 |
| 预测观看者观看视频的时长。 | 相比短视频,用户更喜欢长视频。 |
| 预测用户会再次观看视频的次数。 | 偏向于“可重复观看”无法重复观看的视频类型。 |
没有代理标签可以完美替代您的理想结果。所有将 可能存在问题请选择与您的问题 应用场景。
检查您的理解情况
生成
在大多数情况下,您不会训练自己的生成模型,因为这样做 需要大量的训练数据和计算资源。相反, 您将自定义预训练的生成模型。要使用生成模型 生成所需的输出,您可能需要使用以下一种或多种方式 方法:
蒸馏。要创建 与大型模型相比,您可以生成合成的加标签数据集 从用于训练较小模型的较大模型中生成新数据。生成式 模型通常很大,并且会消耗大量资源(例如 和电力)。蒸馏可带来较小、较少的资源密集型 来粗略估算较大模型的性能。
微调或 参数高效微调。 要提高模型在特定任务上的表现,您需要进一步 使用一个数据集来训练模型,该数据集包含您需要的 想要生成的内容。
提示工程。接收者 让模型执行特定任务,或 以特定格式生成输出,您可以告诉模型想要完成的任务, 或说明您希望如何对输出设置格式换言之, 提示可以包含有关如何执行此任务的自然语言说明 或具有所需输出的说明性示例。
例如,如果您想查找简短的文章摘要,可以输入 以下:
Produce 100-word summaries for each article.如果您想让模型针对特定阅读水平生成文本, 您可以输入以下内容:
All the output should be at a reading level for a 12-year-old.如果您希望模型以特定格式提供其输出, 解释应如何设置输出格式,例如“设置 以表格形式显示结果”- 或者,您也可以演示如何 来生成模型。例如,您可以输入以下内容:
Translate words from English to Spanish. English: Car Spanish: Auto English: Airplane Spanish: Avión English: Home Spanish:______
蒸馏和微调会更新模型的 parameters。提示工程 不会更新模型的参数。相反,提示工程可以帮助 并学习如何根据提示的上下文产生期望的输出。
在某些情况下,您还需要一个 测试数据集,用于评估 对照已知值生成模型的输出,例如 模型总结与人工生成的摘要类似, 非常好。
生成式 AI 还可用于实现预测性机器学习 例如分类或回归。 例如,由于他们对自然语言有深入的了解, 大型语言模型 (LLM) 执行文本分类任务往往比预测性机器学习更出色 针对特定任务进行训练。
定义成效指标
定义您将用来确定机器学习实现是否实现的指标 请求成功。成效指标界定了您关注的方面,例如互动度或 帮助用户采取适当的操作,例如观看他们认为 实用。成功指标与模型的评估指标不同,例如 accuracy、 精确率、 召回,或 AUC。
例如,天气应用的成功和失败指标可定义为 以下:
| 成功 | 用户将打开“会下雨吗?”增加 50% 提升工作效率 |
|---|---|
| 失败 | 用户将打开“会下雨吗?”功能最多 。 |
视频应用指标可定义如下:
| 成功 | 用户在网站上停留的时间平均增加了 20%。 |
|---|---|
| 失败 | 平均而言,用户在网站上停留的时间不会比以前更长。 |
我们建议定义雄心勃勃的成功指标。抱负远大可能会造成差距 成功与失败之间例如,平均支出用户 网站停留时间比以前增加 10%,既不是成功也不失败。 未定义的差距并不重要。
重要的是模型有足够大的距离, 超过 — 成功的定义。例如,在分析模型的 请考虑以下问题:改进模型是否让您 更接近您定义的成功标准?例如,一个模型可能 评估指标,但不会让您离成功标准更近一步, 即使有完美的模型,您也达不到 。另一方面,模型的评估指标可能较差, 更接近成功标准,这表明改进模型 让您离成功更近一步
以下是确定模型是否值得考虑的维度 改善:
做得不够好,但继续。该模型不应 但随着时间的推移,它可能会得到显著改善。
做得不错,继续努力。该模型可用于生产环境 环境,它可能会进一步改进。
足够好,但我们无法不断改进。该模型处于生产环境 但其质量很可能要好一些
不够好,永远不会。该模型不应 那么再多的训练可能就无法实现这一点。
在决定改进模型时,请重新评估增加的资源, 例如工程时间和计算成本,证明 模型。
定义成功和失败指标后,您需要确定 都会对您进行衡量例如,你可以衡量以下六个成功指标: 天、六周或六个月后。
在分析故障指标时,尝试确定系统发生故障的原因。对于 模型可能会预测用户会点击哪些视频, 模型可能会开始推荐可吸引用户互动的点击诱饵标题 。在天气应用示例中,模型可能会准确预测 会下雨,但是覆盖的地理区域过大。
检查您的理解情况
一家时尚公司希望提高服装销量。有人建议使用机器学习 确定该公司应制造哪些服装。他们认为自己可以 训练模型以确定哪种类型的服装时尚。更新后 他们希望将该模型应用于他们的目录, 要制作什么样的衣服
他们应该如何用机器学习术语来描述自己的问题?
理想结果:确定要制造的商品。
模特的目标:预测展示哪些服饰 。
模型输出:二元分类、in_fashion、
not_in_fashion
成功指标:售出 70% 或以上的服装 。
理想结果:确定要订购的面料和用品数量。
模型目标:预测每件商品的生产量。
模型输出:二元分类、make、
do_not_make
成功指标:售出 70% 或以上的服装 。