
生成 AI モデルは強力なツールですが、 制限されることはありません。その汎用性と適用性は、 出力が不正確、偏り、または偏りのある出力など、 不適切です。そのためには、後処理と厳密な手動評価が そのような出力による害が及ぶリスクを制限します。
Gemini API が提供するモデルは、さまざまな用途に使用できる アプリケーションを開発しました。使用目的 関数は、Gemini API またはウェブ版の Google AI Studio でのみ使用できます 。Gemini API の使用には、生成 AI の使用禁止事項も適用されます。 Policy と Gemini API 利用規約。
大規模言語モデル(LLM)が役立つ理由の一つは、 さまざまな言語タスクに対応できるクリエイティブなツールを開発しました。残念ながら、 大規模言語モデルでは、LLM では提供できない出力を テキスト メッセージを含む 不適切、配慮に欠ける、事実と異なるコンテンツ。さらに、 また、これらのモデルの汎用性が高いため、 どのような種類の望ましくない出力が生成されるかを正確に予測できます。一方、 Gemini API は Google の AI を使って設計されています 基本原則を念頭に置いておくと、開発者が モデルを責任を持って適用する方法を学びました。デベロッパーが安全で責任あるプロダクトを Gemini API にはコンテンツ フィルタリングが組み込まれており、 害の 4 つの側面にわたって調整可能な安全性設定。詳しくは、 安全性設定ガイドをご覧ください。
このドキュメントは、セキュリティ違反が発生した場合に生じる可能性のある安全上のリスクを紹介することを目的としています。 し、新たな安全設計と開発を推奨する おすすめします。(法律および規制によって制限が課せられる場合もあります。 このような考慮事項はこのガイドの範囲外です)。
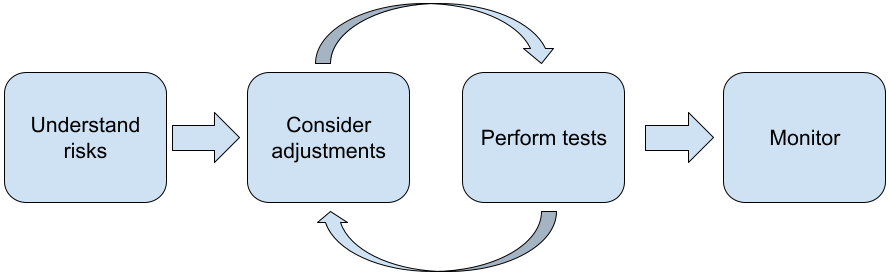
LLM を使用してアプリケーションを構築する場合は、次の手順をおすすめします。
- アプリケーションの安全性リスクを理解する
- 安全性のリスクを軽減するための調整の検討
- ユースケースに適した安全性テストを実施する
- ユーザーからフィードバックを募り、使用状況をモニタリングする
次の段階に達するまで、調整とテストのフェーズを繰り返します。 アプリケーションに最適なパフォーマンスを判断できます。
アプリケーションの安全性に関するリスクを理解する
この文脈において、安全性とは LLM が 有害な言葉やコンテンツを生成するなど、ユーザーに危害を与える 固定観念を助長するようなものです。Gemini API を通じて利用できるモデルは、 Google の AI に関する原則を考慮して設計されている ならびにその使用については、生成 AI の使用禁止対象 ポリシーをご覧ください。API 一般的な言語モデルに対処するための組み込みの安全フィルタを提供 インクルーシブネスの追求に努めています。 固定観念の回避です。ただし、アプリケーションごとに異なる リスクが軽減されます。したがって、アプリケーション オーナーは、 ユーザーとアプリケーションが引き起こす可能性のある損害を把握すること アプリケーションで LLM を安全かつ責任を持って使用できるようにする。
この評価の一環として、危害が及ぶ可能性、 その深刻度と緩和策を判断します。たとえば、 事実に基づいてエッセイを生成するアプリは、 架空のアプリを生成するアプリと比較して、誤った情報を避けることを重視している ストーリーを楽しみましょう。潜在的な安全上のリスクの調査を開始するための優れた方法 エンドユーザーや、エンドユーザーの影響を受ける可能性がある 結果を出力できますこれにはさまざまな形態があり、その一例として、 ユーザーがどのように類似アプリを使用しているかを観察し、 ユーザー調査、アンケート、非公式インタビューの実施 向上します
高度なヒント
- ターゲット内の多様な見込み顧客と会話する ユーザーを適切に識別できるようにして、 潜在的リスクをより広い視野で捉え、多様性を調整する 必要に応じて追加できます。
- AI リスク管理フレームワーク 米国政府が発表した アメリカ国立標準技術研究所(NIST)は、 AI リスク管理に関する詳細なガイダンスと追加の学習リソースを提供します。
- DeepMind の 言語モデルから危害が及ぶ倫理的および社会的リスクを 言語モデルがどのようにトレーニングされ、 害を及ぼす可能性があります。
安全性のリスクを軽減するための調整を検討する
リスクを理解したら、次はリスクを軽減する方法を決定できます。 できます。どのリスクに優先的に取り組むべきかを判断し、 ソフトウェアのバグのトリアージと同様に、 できます。優先順位が決まったら いくつかの緩和策も用意しています。多くの場合、単純な変更が 変化を生み、リスクを軽減できます。
たとえば、アプリケーションを設計する際は、次の点を考慮してください。
- モデル出力のチューニング: 許容される出力レベルをより適切に反映するように アプリケーションのコンテキストです。チューニングにより、モデルの出力をより 一貫性があり予測可能であるため、特定のリスクの軽減に役立ちます。
- より安全な出力を実現する入力方法を提供する。正確な入力 LLM に与える情報が出力の品質に違いを生む可能性があります。 入力プロンプトを試してみて、環境内で最も安全に機能するプロンプトを見つける お客様に最適な UX を提供できるため 容易になります。たとえば、ユーザーがここで選択するように制限して、 入力プロンプトのプルダウン リストから選択することも、 アプリのコンテキストで安全だとわかっているフレーズを選べます。
安全でない入力をブロックし、出力をフィルタして表示する前に ユーザーです。単純なケースでは、ブロックリストを使用して プロンプトやレスポンスで安全でない単語やフレーズが含まれていたり、人間のレビュアーを必要とする そうしたコンテンツを手動で変更またはブロックできます。
トレーニング済みの分類器を使用して、各プロンプトに潜在的な有害性や 敵対的シグナルですその後、戦略を 検出された有害性の種類に基づいてリクエストを処理します。たとえば、 明らかに敵対的または攻撃的である入力は、ブロックされ、 既定のレスポンスを出力します。
高度なヒント
-
シグナルによって出力が有害であると判断される場合
アプリケーションでは、次のオプションを使用できます。
- エラー メッセージまたは既定の出力を提供します。
- 別の安全な出力を使用できる場合は、プロンプトをもう一度お試しください 同じプロンプトでも、同じプロンプトで 出力です。
-
シグナルによって出力が有害であると判断される場合
アプリケーションでは、次のオプションを使用できます。
故意の不正使用に対する安全保護対策を講じる。たとえば、 各ユーザーに一意の ID が割り当てられ、ユーザークエリの量に制限が課されます。 一定の期間に送信できますもう 1 つの対策として、 プロンプト インジェクションを防止できます。SQL に似たプロンプト インジェクション インジェクションは、悪意のあるユーザーがプロンプトを入力プロンプトを 入力プロンプトを送信するなど、モデルの出力を操作 前の例をすべて無視するようにモデルに指示するものです。詳しくは、 生成 AI の使用禁止に関するポリシー をご覧ください。
本質的にリスクの低いものに機能を調整する。 範囲が狭いタスク(例: 特定の文献からキーワードを抽出する) 人間が監視する能力が高い(例: ショート動画の生成など) 人間がレビューするコンテンツなど)であれば、多くの場合、リスクは低くなります。たとえば、 メール返信を作成するアプリケーションを作成する代わりに、 概要をひっくりかえるか提案するかを 使用することになるでしょう。
ユースケースに適した安全性テストを実施する
テストは堅牢で安全なアプリケーションを構築するための重要な要素ですが、 テストの範囲と戦略はさまざまです。たとえば、楽しむための俳句や、 アプリケーションを開発したアプリケーションよりも深刻なリスクが低くなります。 法律事務所が法的文書の要約や契約書の草案作成に活用できますしかし、 俳句ジェネレータは幅広いユーザーが使用できるため、 意図せず有害な入力が行われる可能性があり、 大きくなります実装のコンテキストも重要です。たとえば なんらかの措置を行う前に、人間の専門家がレビューするアウトプットを含む 有害な出力を生成する可能性が低いとみなされる可能性があります。 そのような監視なしに アプリケーションを保護できます
変更とテストを何度か繰り返すことは珍しくない リリースする準備ができているかを確信できます。たとえば、 比較的リスクは低いです。AI に関して特に有用なのは、次の 2 種類のテストです。 アプリケーション:
安全ベンチマークでは、安全性に関する指標を設計します。 どのように問題が発生する可能性が高く 指標に基づいてアプリケーションのパフォーマンスを 評価データセットを使用します最低限の金額と 安全指標の許容レベルを確認してから、 その期待に照らしてテスト結果を評価する 関心のある指標を評価するテストに基づく評価データセット ほとんど変わりません
高度なヒント
- 既製のアプローチに過剰に頼ることには注意が必要です。 評価担当者を使用して独自のテスト データセットを構築し、 アプリのコンテキストに合わせて調整できます。
- 指標が複数ある場合は トレードオフとして ある指標の変化が 悪影響を及ぼす可能性があります。他のパフォーマンスエンジニアリングと同様に 評価の最悪のケースのパフォーマンスに注目し 平均的なパフォーマンスではなく
敵対的テストでは、事前に 説明します。目標は 対処すべき弱点を突き止めること 是正手順を提示します。敵対的テストでは アプリケーションの専門知識を持つ評価担当者が多大な時間と労力を必要とする - しかし これを繰り返すほど 問題を発見する可能性は高まり 特にめったに発生しないイベントや 説明します。
- 敵対的テストは ML を体系的に評価する方法
与えられたときにどのように動作するかを学習する目的で、
悪意のある、または意図せずに有害な入力:
- 入力が悪意のあるものとなるのは、その入力が 安全でない、または有害な出力を生成する 生成モデルを利用して、特定のネガティブな 宗教
- 入力自体が有害な動作をする可能性がある場合、入力が 無害だが有害な出力を生成する(例: テキスト プロンプトに 特定の民族の人物を表す生成モデルを 人種差別的なコンテンツも受け取ります。
- 敵対的テストと標準的な評価の違いは、 テストに使用するデータの構成。敵対的テストの場合は、 出力を導き出す可能性が最も高いテストデータ 行います。つまり、すべてのタイプのモデルに対するモデルの挙動を 発生する可能性のある危害(希少な例や珍しい例、 安全性ポリシーに関連するエッジケースも 検出できますまた、 文のさまざまな側面(構造、 説明します。詳しくは、Google の責任ある AI への取り組みに関する 実践方法 公平性 をご覧ください。
- 敵対的テストは ML を体系的に評価する方法
与えられたときにどのように動作するかを学習する目的で、
悪意のある、または意図せずに有害な入力:
問題をモニタリングする
どれだけテストして軽減しても、完璧が保証されるわけではありません。そのため、 発生する問題を特定して対処する方法を事前に計画する。コモン モニタリング チャネルを設定してユーザーがフィードバックを共有できるようにするなど、 (高評価/低評価など)ユーザー調査を実施して積極的に情報を求める 多様なユーザーからのフィードバックを収集できます。特に、使用パターンが 予測と異なっています
高度なヒント
- ユーザーが AI プロダクトにフィードバックを送ると、AI の大幅な改善につながる パフォーマンスやユーザーエクスペリエンスの推移を プロンプト調整に適した例を選択できます「 フィードバックと制御の章 Google の People and AI ガイドブックの インフラストラクチャを設計する際に考慮すべき、 フィードバックメカニズムがあります。