
โมเดลปัญญาประดิษฐ์ (AI) แบบ Generative คือเครื่องมือที่มีประสิทธิภาพ โดยไม่มีข้อจำกัด ประโยชน์ใช้สอยและความเกี่ยวข้องได้ในบางครั้ง ทำให้เกิดผลลัพธ์ที่ไม่คาดคิด เช่น เอาต์พุตที่ไม่ถูกต้อง มีอคติ หรือ น่ารังเกียจ การประมวลผลหลังการประมวลผล และการประเมินด้วยตนเองที่เคร่งครัดเป็นสิ่งจำเป็นเพื่อ ลดความเสี่ยงที่จะเกิดอันตรายจากผลลัพธ์เหล่านั้น
โมเดลจาก Gemini API สามารถใช้กับ แอปพลิเคชัน Generative AI และการประมวลผลภาษาธรรมชาติ (NLP) การใช้รายการเหล่านี้ พร้อมให้ใช้งานผ่าน Gemini API หรือเว็บ Google AI Studio เท่านั้น แอป การใช้งาน Gemini API ของคุณยังขึ้นอยู่กับการใช้งานที่ไม่อนุญาตของ Generative AI ด้วย นโยบายและ ข้อกำหนดในการให้บริการของ Gemini API
ส่วนหนึ่งที่ทำให้โมเดลภาษาขนาดใหญ่ (LLM) มีประโยชน์มากก็คือ เครื่องมือสร้างสรรค์ที่ช่วยจัดการกับงานทางภาษาต่างๆ ได้มากมาย ขออภัย และยังหมายความว่าโมเดลภาษาขนาดใหญ่สามารถสร้างผลลัพธ์ที่คุณ คาดหวังได้ รวมถึงข้อความ ที่ไม่เหมาะสม ไม่มีความละเอียดอ่อน หรือไม่ถูกต้องตามข้อเท็จจริง ยิ่งไปกว่านั้น ความอเนกประสงค์ที่น่าทึ่งของโมเดลเหล่านี้ยังเป็นสิ่งที่ทำให้ คาดการณ์ได้อย่างชัดเจนว่าผลที่ได้ออกมาเป็นแบบไหน ในขณะที่ Gemini API ได้รับการออกแบบด้วย AI ของ Google หลักการต่างๆ ไว้ สิ่งที่นักพัฒนาซอฟต์แวร์จะได้รับ โมเดลเหล่านี้อย่างมีความรับผิดชอบ ช่วยเหลือนักพัฒนาแอปในการสร้างที่ปลอดภัยและมีความรับผิดชอบ เหล่านี้ Gemini API มีการกรองเนื้อหาในตัวเช่นเดียวกับ การตั้งค่าความปลอดภัยที่ปรับได้สำหรับภัยอันตรายทั้ง 4 ด้าน โปรดดู การตั้งค่าความปลอดภัยเพื่อเรียนรู้เพิ่มเติม
เอกสารนี้จัดทำขึ้นเพื่อแนะนำคุณเกี่ยวกับความเสี่ยงด้านความปลอดภัยบางอย่างที่อาจเกิดขึ้นเมื่อ การใช้ LLM และแนะนำการออกแบบและพัฒนาความปลอดภัยใหม่ๆ วิดีโอแนะนำ (โปรดทราบว่ากฎหมายและข้อบังคับอาจกำหนดข้อจำกัด แต่ข้อพิจารณาดังกล่าวอยู่นอกเหนือขอบเขตของคู่มือนี้)
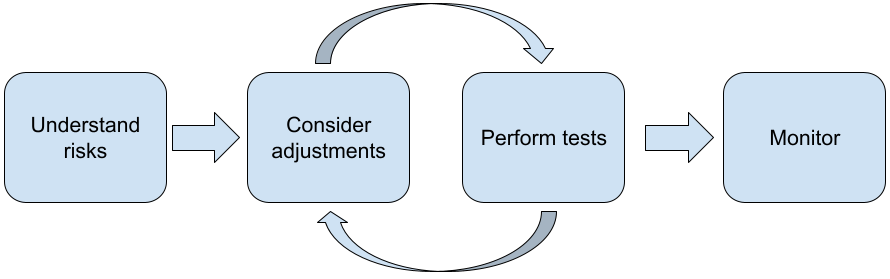
เราขอแนะนำให้ทำตามขั้นตอนต่อไปนี้เมื่อสร้างแอปพลิเคชันด้วย LLM
- การทำความเข้าใจความเสี่ยงด้านความปลอดภัยของแอปพลิเคชัน
- พิจารณาการปรับเปลี่ยนเพื่อลดความเสี่ยงด้านความปลอดภัย
- ทำการทดสอบด้านความปลอดภัยที่เหมาะสมกับ Use Case ของคุณ
- การขอความคิดเห็นจากผู้ใช้และตรวจสอบการใช้งาน
ระยะปรับเปลี่ยนและการทดสอบควรเป็นการทำซ้ำจนกระทั่งถึง ประสิทธิภาพที่เหมาะกับแอปพลิเคชันของคุณ
ทำความเข้าใจความเสี่ยงด้านความปลอดภัยของแอปพลิเคชัน
ในบริบทนี้ ความปลอดภัยหมายถึงความสามารถในการหลีกเลี่ยงของ LLM ก่อให้เกิดอันตรายต่อผู้ใช้ เช่น ด้วยการสร้างภาษาหรือเนื้อหาที่ไม่เหมาะสม ที่ส่งเสริมการเหมารวม โมเดลที่พร้อมใช้งานผ่าน Gemini API ได้รับการ ออกแบบโดยคำนึงถึงหลักการเกี่ยวกับ AI ของ Google และการใช้งานของคุณอยู่ภายใต้การใช้งานที่ไม่อนุญาตของ Generative AI นโยบาย API มีตัวกรองความปลอดภัยในตัวเพื่อช่วยจัดการกับโมเดลภาษาทั่วไปบางโมเดล ปัญหาต่างๆ เช่น ภาษาที่เป็นพิษเป็นภัยและวาจาสร้างความเกลียดชัง ตลอดจนการเรียกร้องให้ทุกคนไม่แบ่งแยก และหลีกเลี่ยงการเหมารวม แต่แต่ละแอปพลิเคชันสามารถวางชุดการ์ดที่ต่างกัน ต่อผู้ใช้ ดังนั้น ในฐานะเจ้าของแอปพลิเคชัน คุณจะต้องรับผิดชอบ การรับรู้ผู้ใช้และอันตรายที่อาจเกิดขึ้นกับแอปพลิเคชันของคุณ และ การตรวจสอบว่าแอปพลิเคชันของคุณใช้ LLM อย่างปลอดภัยและมีความรับผิดชอบ
ในการประเมินนี้ คุณควรพิจารณาแนวโน้มที่อันตรายที่อาจเกิดขึ้น เกิดขึ้นและกำหนดความร้ายแรงและขั้นตอนการบรรเทาปัญหา ตัวอย่างเช่น แอปที่สร้างเรียงความจากเหตุการณ์ที่เป็นข้อเท็จจริงจะต้องระมัดระวังมากขึ้น เกี่ยวกับการหลีกเลี่ยงการให้ข้อมูลที่ไม่ถูกต้อง เมื่อเทียบกับแอปที่สร้างเรื่องสมมติ เพื่อความบันเทิง วิธีที่ดีในการเริ่มสำรวจความเสี่ยงด้านความปลอดภัยที่อาจเกิดขึ้น คือการศึกษาผู้ใช้ปลายทางของคุณ และผู้อื่นที่อาจได้รับผลกระทบจาก ผลลัพธ์ของแอปพลิเคชัน ซึ่งอาจใช้ได้หลายรูปแบบ รวมถึงการค้นคว้าสถานะ การศึกษาศิลปะในโดเมนแอปของคุณ การสังเกตวิธีที่ผู้คนใช้แอปที่คล้ายกัน หรือศึกษาผู้ใช้ ทำแบบสำรวจ หรือสัมภาษณ์อย่างไม่เป็นทางการกับ ผู้มีโอกาสเป็นผู้ใช้
เคล็ดลับขั้นสูง
- สื่อสารกับผู้มีโอกาสเป็นผู้ใช้หลากหลายกลุ่มภายในเป้าหมายของคุณ เกี่ยวกับแอปพลิเคชันและวัตถุประสงค์ที่ตั้งใจไว้ เพื่อมองมุมมองที่กว้างขึ้นเกี่ยวกับความเสี่ยงที่อาจเกิดขึ้นและปรับความหลากหลาย เกณฑ์ตามความจำเป็น
- กรอบการจัดการความเสี่ยงเกี่ยวกับ AI เผยแพร่โดยรัฐบาล สถาบันมาตรฐานและเทคโนโลยีแห่งชาติ (National Institute of Standards and Technology หรือ NIST) ยังมอบสิทธิประโยชน์อื่นๆ เพิ่มเติม คำแนะนำโดยละเอียดและแหล่งข้อมูลการเรียนรู้เพิ่มเติมสำหรับการจัดการความเสี่ยงของ AI
- สื่อเผยแพร่ของ DeepMind บน ความเสี่ยงทางจริยธรรมและสังคมต่ออันตรายจากโมเดลภาษา อธิบายวิธีที่โมเดลภาษานั้น แอปพลิเคชันอาจก่อให้เกิดอันตราย
ลองปรับเปลี่ยนเพื่อลดความเสี่ยงด้านความปลอดภัย
ตอนนี้เมื่อมีความเข้าใจเกี่ยวกับความเสี่ยงแล้ว คุณก็จะตัดสินใจได้ว่าจะบรรเทาความเสี่ยงอย่างไร ให้พวกเขา การพิจารณาความเสี่ยงที่ควรจัดลำดับความสำคัญและพิจารณาว่าคุณควรดำเนินการมากน้อยแค่ไหนเพื่อพยายาม การป้องกันข้อบกพร่องนั้นเป็นการตัดสินใจที่สำคัญ คล้ายกับการคัดกรองข้อบกพร่องในซอฟต์แวร์ เมื่อระบุลำดับความสำคัญได้แล้ว คุณก็เริ่มคิดเกี่ยวกับ ประเภทการลดปัญหาที่เหมาะสมที่สุด การเปลี่ยนแปลงง่ายๆ สามารถ สร้างความแตกต่างและลดความเสี่ยง
ตัวอย่างเช่น เมื่อออกแบบแอปพลิเคชันให้คำนึงถึงสิ่งต่อไปนี้
- ปรับแต่งเอาต์พุตโมเดลเพื่อให้แสดงถึงสิ่งที่ยอมรับใน บริบทของแอปพลิเคชัน การปรับแต่งสามารถทำให้เอาต์พุตของโมเดลมากขึ้น คาดการณ์ได้และมีความสม่ำเสมอ จึงช่วยลดความเสี่ยงบางอย่างได้
- การให้วิธีการป้อนข้อมูลที่ช่วยสร้างเอาต์พุตที่ปลอดภัยขึ้น ข้อมูลที่ป้อนอย่างถูกต้อง ที่คุณมอบให้ LLM สามารถสร้างความแตกต่างในคุณภาพของเอาต์พุตได้ ทดลองใช้พรอมต์อินพุตเพื่อค้นหาสิ่งที่ทำงานได้อย่างปลอดภัยที่สุดใน Use Case นั้นคุ้มค่ากับความพยายาม เนื่องจากคุณจะใส่ UX ที่ ช่วยอำนวยความสะดวก เช่น คุณอาจจำกัดให้ผู้ใช้เลือกจาก รายการแบบเลื่อนลงของพรอมต์การป้อนข้อมูล หรือเสนอคำแนะนำแบบป๊อปอัปด้วย คำอธิบายรายละเอียด ข้อความที่คุณพบว่าใช้งานได้อย่างปลอดภัยในบริบทของแอปพลิเคชัน
บล็อกอินพุตและการกรองที่ไม่ปลอดภัยก่อนแสดงต่อ ผู้ใช้ ในสถานการณ์ง่ายๆ คุณสามารถใช้รายการที่บล็อกเพื่อระบุและบล็อกได้ คำหรือวลีที่ไม่ปลอดภัยในพรอมต์หรือคำตอบ หรือต้องใช้เจ้าหน้าที่ตรวจสอบ แก้ไขหรือบล็อกเนื้อหาดังกล่าวด้วยตนเอง
ใช้ตัวแยกประเภทที่ได้รับการฝึกแล้วในการติดป้ายกำกับข้อความแจ้งแต่ละรายการว่าอาจเป็นอันตราย หรือ ของ Google จากนั้น ก็สามารถใช้กลยุทธ์ต่างๆ ในการ จัดการกับคำขอตามประเภทอันตรายที่ตรวจพบ ตัวอย่างเช่น หาก อินพุตมีลักษณะที่ไม่พึงประสงค์หรือเป็นการละเมิดอย่างชัดเจน จึงอาจถูกบล็อกและ แสดงคำตอบที่เป็นสคริปต์ล่วงหน้าแทน
เคล็ดลับขั้นสูง
-
หากมีสัญญาณระบุว่าเอาต์พุตเป็นอันตราย
แอปพลิเคชันสามารถใช้ตัวเลือกต่อไปนี้ได้:
- ระบุข้อความแสดงข้อผิดพลาดหรือเอาต์พุตที่กำหนดไว้ล่วงหน้า
- ลองใช้ข้อความแจ้งอีกครั้ง เผื่อว่าเอาต์พุตที่ปลอดภัยสำรองคือ เนื่องจากบางครั้งข้อความแจ้งเดียวกันจะ เอาต์พุตที่แตกต่างกัน
-
หากมีสัญญาณระบุว่าเอาต์พุตเป็นอันตราย
แอปพลิเคชันสามารถใช้ตัวเลือกต่อไปนี้ได้:
การใช้มาตรการป้องกันการใช้ในทางที่ผิดโดยเจตนา เช่น การมอบหมาย รหัสที่ไม่ซ้ำกันของผู้ใช้แต่ละราย และกำหนดขีดจำกัดปริมาณคำค้นหาของผู้ใช้ ซึ่งสามารถส่งได้ในระยะเวลาที่กำหนด มาตรการป้องกันอีกอย่างก็คือการพยายาม จากการแทรก Prompt ที่อาจเกิดขึ้น การแทรก Prompt คล้ายกับ SQL คือวิธีที่ผู้ใช้ที่มีเจตนาร้ายออกแบบพรอมต์การป้อนข้อมูล จัดการเอาต์พุตของโมเดล เช่น ด้วยการส่งพรอมต์อินพุต ที่สั่งโมเดลให้ละเว้นตัวอย่างก่อนหน้านี้ โปรดดู นโยบายการใช้งานที่ไม่อนุญาตของ Generative AI เพื่อดูรายละเอียดเกี่ยวกับการใช้ในทางที่ผิดโดยเจตนา
ปรับฟังก์ชันการทำงานให้มีความเสี่ยงต่ำตามธรรมชาติ งานที่มีขอบเขตแคบกว่า (เช่น การแยกคีย์เวิร์ดจากข้อความ ข้อความ) หรือที่มีการควบคุมดูแลโดยมนุษย์มากกว่า (เช่น การสร้างวิดีโอแบบสั้น เนื้อหาที่จะได้รับการตรวจสอบโดยเจ้าหน้าที่) มักมีความเสี่ยงต่ำกว่า ดังนั้นสำหรับ แทนการสร้างแอปพลิเคชันเพื่อเขียนอีเมลตอบกลับ คุณอาจแทนการขยายไปยังเส้นโครงหรือ วลีอื่นๆ
ทำการทดสอบด้านความปลอดภัยที่เหมาะสมกับกรณีการใช้งาน
การทดสอบเป็นส่วนสำคัญในการสร้างแอปพลิเคชันที่มีประสิทธิภาพและปลอดภัย ขอบเขตและกลยุทธ์สำหรับการทดสอบจะแตกต่างกันไป เช่น ไฮกุเพื่อความสนุก โปรแกรมสร้างมีแนวโน้มที่จะก่อให้เกิดความเสี่ยงที่ร้ายแรงน้อยกว่าแอปพลิเคชันที่ออกแบบ สำหรับให้บริษัทกฎหมายใช้สรุปเอกสารทางกฎหมายและช่วยร่างสัญญา แต่ อาจมีผู้ใช้หลากหลายมากกว่าที่ใช้เครื่องสร้างไฮกุ ซึ่งหมายความว่า อาจทำให้เกิดการโจมตีที่ไม่คุ้นเคยหรือ การให้ข้อมูลที่เป็นอันตรายโดยไม่เจตนา ใหญ่กว่า บริบทการนำไปใช้ก็สำคัญเช่นกัน เช่น แอปพลิเคชัน พร้อมเอาต์พุตที่ได้รับการตรวจสอบโดยเจ้าหน้าที่ผู้เชี่ยวชาญก่อนดำเนินการใดๆ อาจมีแนวโน้มที่จะสร้างผลลัพธ์ที่เป็นอันตรายน้อยกว่าผลลัพธ์ที่เหมือนกัน ที่ไม่มีการกำกับดูแลดังกล่าว
การเปลี่ยนแปลงและการทดสอบหลายครั้งไม่ใช่เรื่องแปลก ก่อนที่จะมั่นใจว่าคุณพร้อมเปิดตัวแล้ว แม้แต่สำหรับแอปพลิเคชันที่ มีความเสี่ยงค่อนข้างต่ำ การทดสอบ 2 ประเภทมีประโยชน์อย่างยิ่งสำหรับ AI แอปพลิเคชัน:
การเปรียบเทียบความปลอดภัยเกี่ยวข้องกับการออกแบบเมตริกความปลอดภัยที่แสดงถึง วิธีที่แอปพลิเคชันของคุณอาจไม่ปลอดภัยในบริบทที่มีโอกาส ใช้ แล้วทดสอบว่าแอปพลิเคชันของคุณทำงานกับเมตริกได้ดีเพียงใด โดยใช้ชุดข้อมูลการประเมิน คุณควรคำนึงถึงขีดจำกัดขั้นต่ำ ระดับความปลอดภัยที่ยอมรับได้ก่อนการทดสอบ เพื่อที่ 1) คุณสามารถ ประเมินผลการทดสอบเทียบกับความคาดหวังเหล่านั้น และ 2) คุณสามารถรวบรวม ชุดข้อมูลการประเมินตามการทดสอบที่ประเมินเมตริกที่คุณสนใจ ก็สำคัญที่สุด
เคล็ดลับขั้นสูง
- ระวังการใช้วิธี "ไม่เผยแพร่" มากเกินไป เนื่องจากมีแนวโน้ม คุณจะต้องสร้างชุดข้อมูลการทดสอบของคุณเองโดยใช้เจ้าหน้าที่ตรวจสอบ เหมาะสมกับบริบทของแอปพลิเคชันของคุณ
- หากคุณมีเมตริกมากกว่า 1 รายการ คุณจะต้องตัดสินใจว่า ข้อดีข้อเสียหากการเปลี่ยนแปลงนำไปสู่การปรับปรุงเมตริกเดียว ความเสียหายของผู้อื่น เช่นเดียวกับงานด้านวิศวกรรมประสิทธิภาพอื่นๆ อาจต้องให้ความสำคัญกับประสิทธิภาพในส่วนที่แย่ที่สุดในการประเมิน การตั้งค่า แทนที่จะเป็นประสิทธิภาพโดยเฉลี่ย
การทดสอบที่ไม่พึงประสงค์ คือ ความพยายามเชิงรุกที่จะแบ่ง แอปพลิเคชัน เป้าหมายคือการระบุจุดอ่อน เพื่อให้คุณสามารถ เพื่อชดเชยได้ตามความเหมาะสม การทดสอบที่ไม่เหมาะสมอาจใช้เวลา เวลา/ความพยายามที่สำคัญจากผู้ประเมินที่มีความเชี่ยวชาญในการสมัครของคุณ — แต่ยิ่งทำมาก ยิ่งมีโอกาสเห็นปัญหามากขึ้น โดยเฉพาะอย่างยิ่ง ที่เกิดขึ้นน้อยมากหรือเฉพาะหลังจากที่เรียกใช้ แอปพลิเคชัน
- การทดสอบที่ไม่เหมาะสมคือวิธีในการประเมิน ML อย่างเป็นระบบ
โมเดลโดยมีจุดประสงค์เพื่อเรียนรู้ลักษณะการทำงานของโมเดลที่มี
อินพุตที่เป็นอันตราย
โดยไม่เจตนา:
- ข้อมูลที่ป้อนอาจเป็นอันตราย หากข้อมูลนั้นได้รับการออกแบบมาอย่างชัดเจน สร้างเอาต์พุตที่ไม่ปลอดภัยหรือเป็นอันตราย เช่น ขอให้ส่งข้อความ เพื่อสร้างคำพูดแสดงความเกลียดชัง ศาสนา
- อินพุตเป็นอันตรายโดยไม่ตั้งใจเมื่อตัวอินพุตเองอาจ ไม่มีพิษมีภัย แต่สร้างผลลัพธ์ที่เป็นอันตราย เช่น การถาม เพื่ออธิบายถึงบุคคลจากชาติพันธุ์เฉพาะและ ได้รับความคิดเห็นเกี่ยวกับการเหยียดเชื้อชาติ
- สิ่งที่ทำให้การทดสอบที่ไม่พึงประสงค์และแตกต่างจากการประเมินมาตรฐานคือ
องค์ประกอบของข้อมูลที่ใช้สำหรับการทดสอบ สำหรับการทดสอบที่ไม่พึงประสงค์ ให้เลือก
ข้อมูลทดสอบที่น่าจะทำให้เกิดผลลัพธ์ที่เป็นปัญหาจาก
โมเดล ซึ่งหมายถึงการตรวจสอบพฤติกรรมของโมเดลสำหรับประเภท
อันตรายที่อาจเกิดขึ้นได้ รวมถึงตัวอย่างที่พบได้ยากหรือผิดปกติ
เคส Edge Case ที่เกี่ยวข้องกับนโยบายความปลอดภัย และควรมี
ความหลากหลายในมิติต่างๆ ของประโยค เช่น โครงสร้าง
ความหมายและความยาว คุณสามารถดูข้อมูล AI ที่มีความรับผิดชอบของ Google
แนวทางปฏิบัติใน
ความเป็นธรรม
เพื่อดูรายละเอียดเพิ่มเติมเกี่ยวกับสิ่งที่ต้องพิจารณาเมื่อสร้างชุดข้อมูลทดสอบ
เคล็ดลับขั้นสูง
- ใช้ การทดสอบอัตโนมัติ แทนที่จะใช้วิธีแบบดั้งเดิมในการ ขอคนมาอยู่ใน "ทีมสีแดง" เพื่อพยายามทำลายแอปพลิเคชันของคุณ ในการทดสอบอัตโนมัติ ฟิลด์ "ทีมสีแดง" เป็นอีกโมเดลภาษาหนึ่งที่ค้นหาข้อความที่ป้อนที่ แสดงเอาต์พุตที่เป็นอันตรายจากโมเดลที่กำลังทดสอบ
- การทดสอบที่ไม่เหมาะสมคือวิธีในการประเมิน ML อย่างเป็นระบบ
โมเดลโดยมีจุดประสงค์เพื่อเรียนรู้ลักษณะการทำงานของโมเดลที่มี
อินพุตที่เป็นอันตราย
โดยไม่เจตนา:
ตรวจหาปัญหา
ไม่ว่าคุณจะทดสอบและยอมแพ้มากน้อยแค่ไหน ก็ไม่สามารถรับประกันความสมบูรณ์แบบได้ วางแผนล่วงหน้าว่าจะสังเกตและจัดการกับปัญหาต่างๆ ที่เกิดขึ้นอย่างไร ทั่วไป ได้แก่ การสร้างช่องทางที่มีการตรวจสอบเพื่อให้ผู้ใช้แชร์ความคิดเห็น (เช่น คะแนนชอบ/ไม่ชอบ) และทำการศึกษาผู้ใช้เพื่อชักชวนเชิงรุก ความคิดเห็นจากผู้ใช้หลากหลายกลุ่ม ซึ่งมีประโยชน์มากโดยเฉพาะเมื่อมีรูปแบบการใช้งาน แตกต่างจากความคาดหวัง
เคล็ดลับขั้นสูง
- เมื่อผู้ใช้ให้ความคิดเห็นเกี่ยวกับผลิตภัณฑ์ AI ก็ช่วยปรับปรุง AI ได้อย่างมาก ประสิทธิภาพและประสบการณ์ของผู้ใช้เมื่อเวลาผ่านไป ตัวอย่างเช่น ช่วยให้คุณเลือกตัวอย่างที่ดียิ่งขึ้นสำหรับการปรับแต่งพรอมต์ บทแสดงความคิดเห็นและการควบคุม ในคู่มือเกี่ยวกับผู้คนและ AI ของ Google มุ่งเน้นสิ่งสำคัญที่ควรคำนึงถึงเมื่อออกแบบ กลไกการส่งความคิดเห็น
ขั้นตอนถัดไป
- โปรดดู คู่มือการตั้งค่าความปลอดภัย เพื่อเรียนรู้เกี่ยวกับ การตั้งค่าความปลอดภัยที่พร้อมใช้งานผ่าน Gemini API
- ดูข้อมูลเบื้องต้นเกี่ยวกับข้อความแจ้งเพื่อรับ เริ่มเขียนพรอมต์แรกของคุณ