La atención médica basada en datos depende de la capacidad de generar rápidamente estadísticas confiables y prácticas.
Si bien el estándar FHIR ofrece muchos beneficios a los desarrolladores que compilan soluciones de salud digital de nueva generación, su estructura muy anidada puede ser un desafío para trabajar con las estadísticas.
Para que los desarrolladores puedan crear soluciones que reduzcan la complejidad de trabajar con datos de FHIR, proporcionamos canales de datos de FHIR, un conjunto de herramientas: canalizaciones de ETL para convertir recursos en esquemas de Parquet-on-FHIR, una capa de definición de vistas y conectores de motores de consulta.
FHIR Data Pipes está diseñado para la escalabilidad horizontal y las opciones de implementación flexibles (en las instalaciones o en la nube). Al mismo tiempo, se puede implementar en una sola máquina.
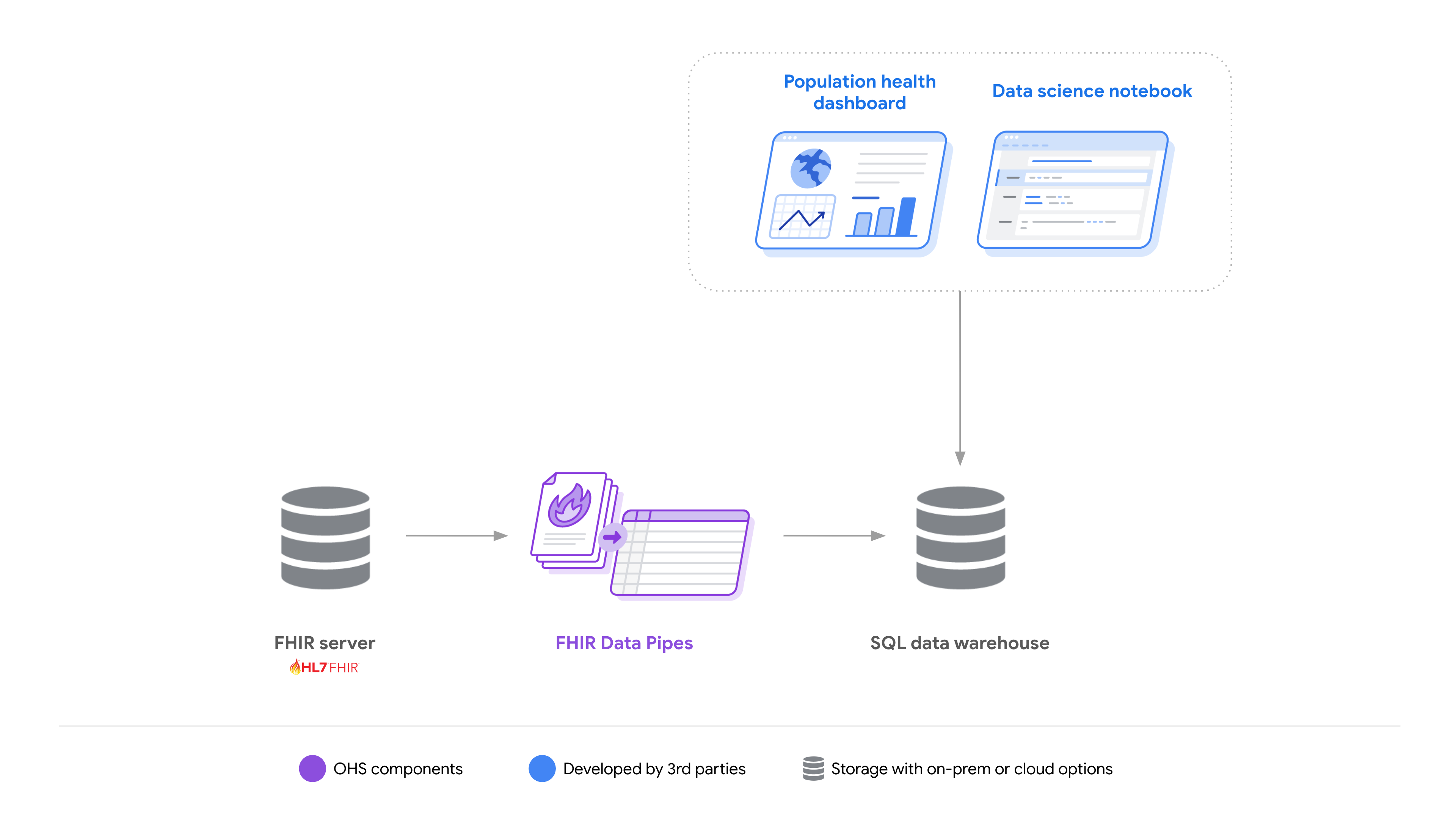
En conjunto, estos servicios permiten que los desarrolladores compilen e implementen soluciones de estadísticas con diferentes tecnologías para una variedad de casos de uso.
Obtén más información sobre los canales de datos de FHIR y sus componentes: