Les soins de santé axés sur les données reposent sur la capacité à générer rapidement des insights fiables et exploitables.
Bien que la norme FHIR offre de nombreux avantages aux développeurs qui créent des solutions de santé numériques de nouvelle génération, sa structure fortement imbriquée peut être difficile à utiliser pour l'analyse.
Pour permettre aux développeurs de créer plus facilement des solutions qui réduisent la complexité de l'utilisation des données FHIR, nous fournissons les pipelines de données FHIR, un ensemble d'outils: des pipelines ETL pour convertir les ressources en schéma Parquet-on-FHIR, une couche de définition des vues et des connecteurs de moteur de requêtes.
FHIR Data Pipes est conçu pour l'évolutivité horizontale et les options de déploiement flexibles (sur site ou dans le cloud). En même temps, il peut être déployé sur une seule machine.
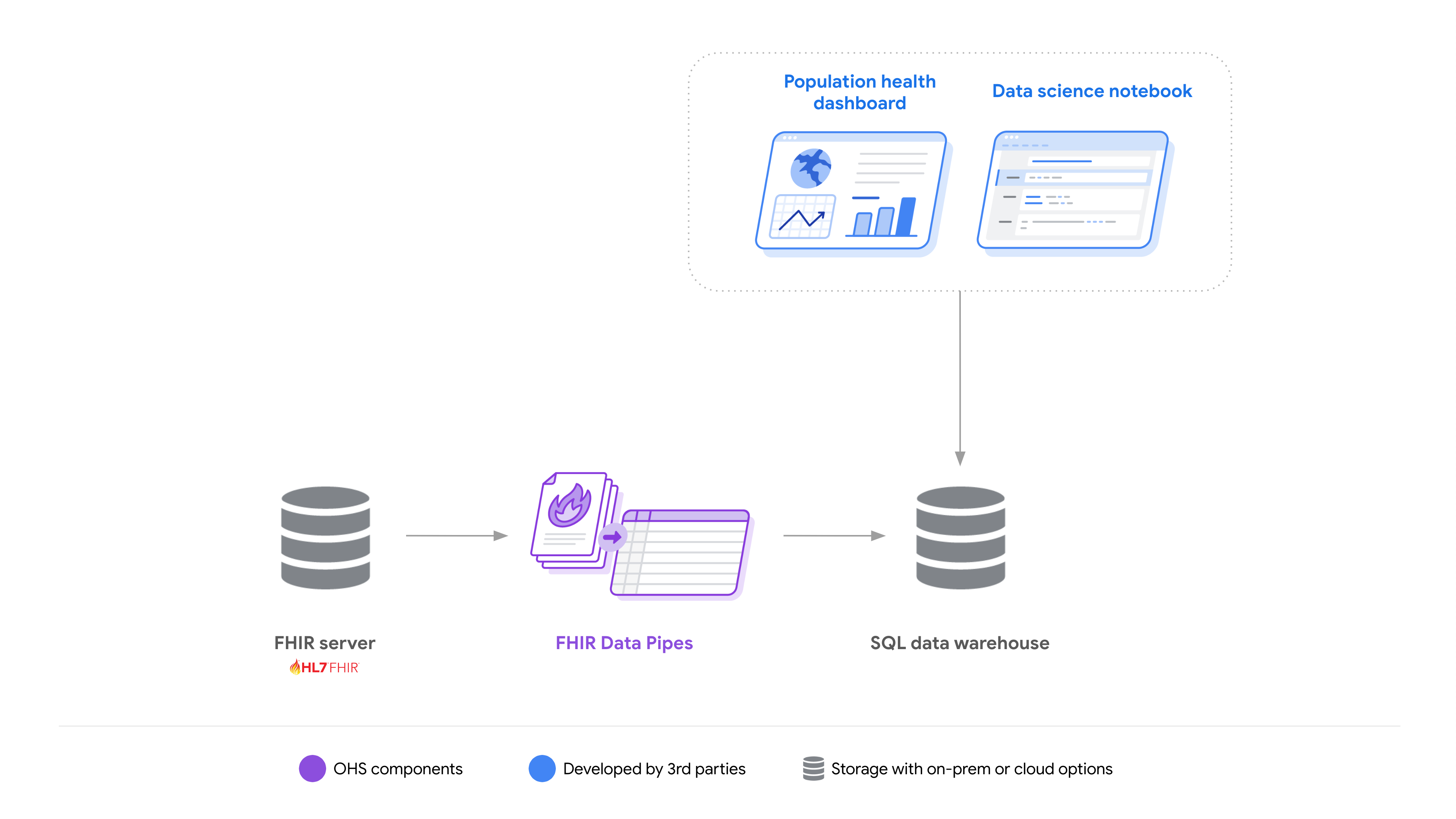
Ensemble, ils permettent aux développeurs de créer et de déployer plus facilement des solutions d'analyse à l'aide de différentes technologies pour différents cas d'utilisation.
En savoir plus sur les canaux de données FHIR et leurs composants: