La salute basata sui dati si basa sulla possibilità di generare rapidamente informazioni attendibili e utili.
Sebbene lo standard FHIR offra molti vantaggi agli sviluppatori che creano soluzioni di salute digitale di nuova generazione, la sua struttura fortemente nidificata può essere difficile da gestire per l'analisi.
Per semplificare la creazione di soluzioni che riducono la complessità del lavoro con i dati FHIR, offriamo FHIR Data Pipes, un insieme di strumenti: pipeline ETL per convertire le risorse in schema Parquet-on-FHIR, un livello di definizione delle visualizzazioni e connettori del motore di query.
FHIR Data Pipes è progettato per la scalabilità orizzontale e opzioni di deployment flessibili (on-premise o nel cloud). Allo stesso tempo, può essere implementato su una singola macchina.
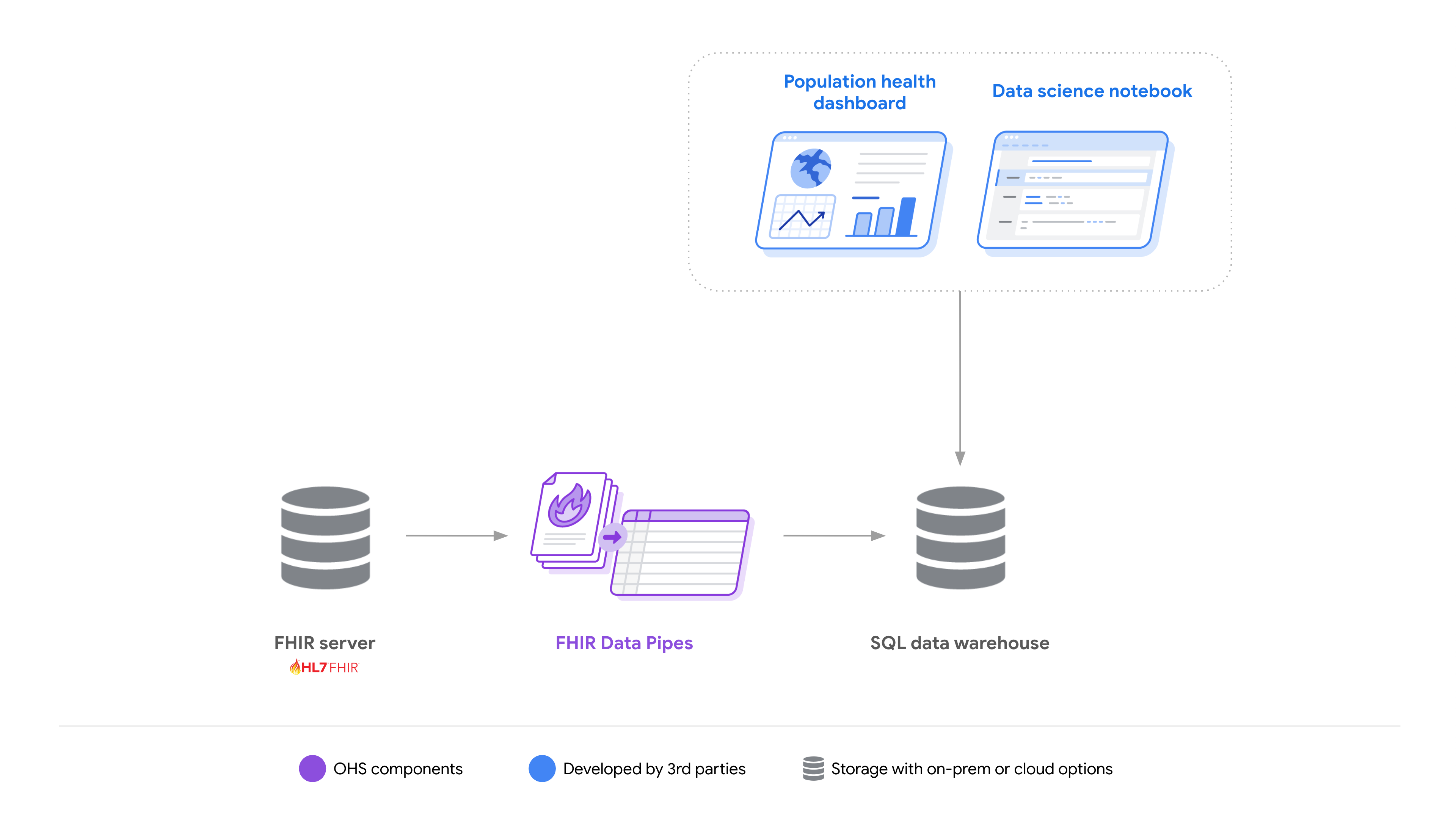
Insieme, questi elementi consentono agli sviluppatori di creare e implementare più facilmente soluzioni di analisi utilizzando tecnologie diverse per una serie di casi d'uso.
Scopri di più su FHIR Data Pipes e sui relativi componenti: