
1. Prerequisiti
Per eseguire questo codelab, sono necessari alcuni prerequisiti. Ogni requisito è contrassegnato di conseguenza in base al fatto che sia necessario per "Test locali" o "Servizio di aggregazione".
1.1. Scaricare lo strumento di test locale (test locale)
Per i test locali è necessario scaricare lo strumento di test locale. Lo strumento genererà report di riepilogo dai report di debug non criptati.
Lo strumento di test locale è disponibile per il download negli archivi JAR di Lambda su GitHub. Deve essere denominato LocalTestingTool_{version}.jar.
1.2. Assicurati che sia installato JAVA JRE (servizio di test e aggregazione locale)
Apri "Terminale" e usa java --version per verificare se sul tuo computer è installato Java o openJDK.

Se non è installato, puoi scaricarlo e installarlo dal sito Java o dal sito openJDK.
1.3. Scaricare il convertitore di report aggregabili (servizio di test e aggregazione locale)
Puoi scaricare una copia del convertitore di report aggregabili dal repository GitHub di Privacy Sandbox Demos.
1.4. Abilita le API per la privacy degli annunci (servizio di test e aggregazione locale)
Nel browser, vai a chrome://settings/adPrivacy e attiva tutte le API di privacy per gli annunci.
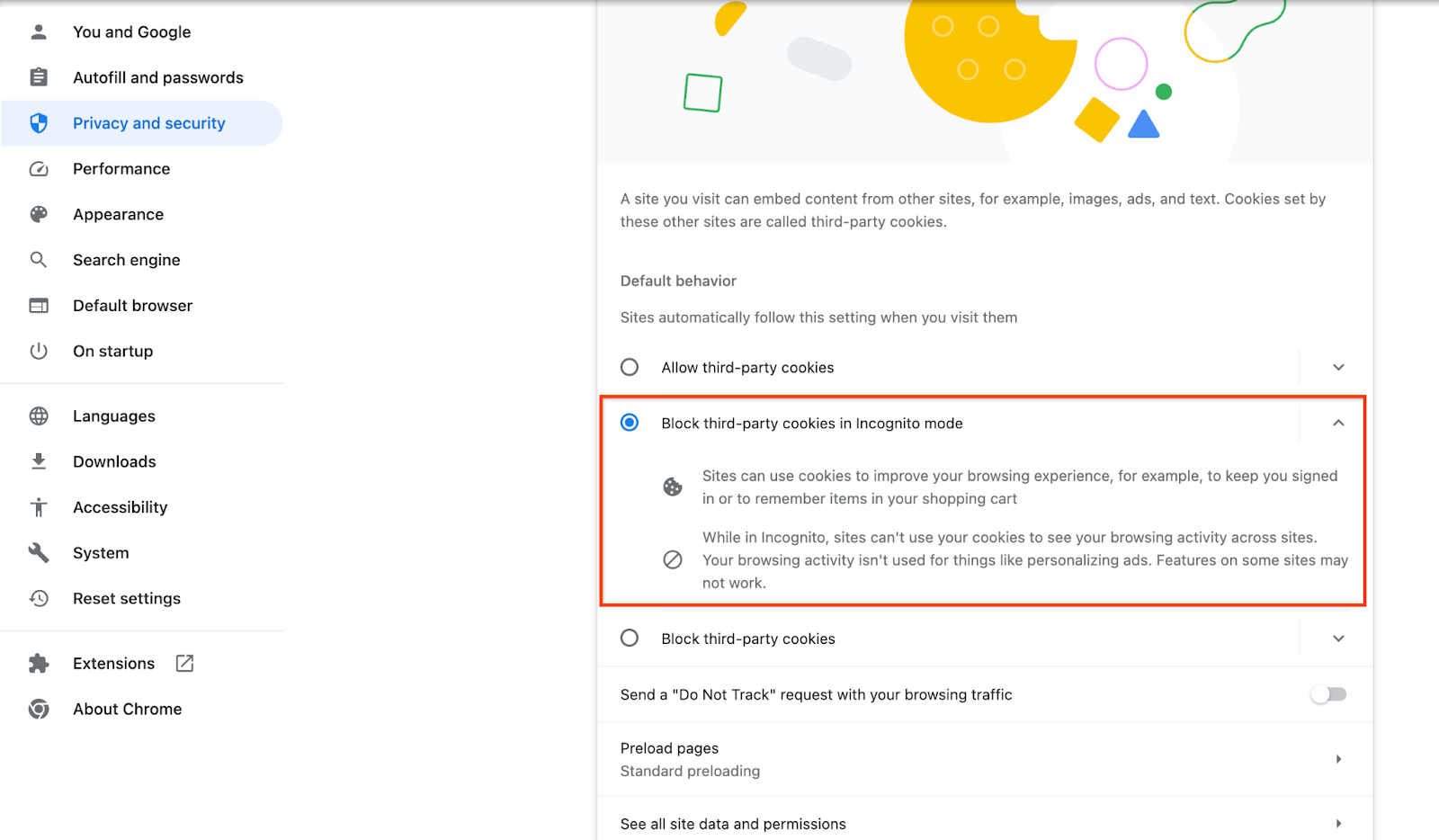
Assicurati che i cookie di terze parti siano attivi.
Nel browser, vai a chrome://settings/cookies e seleziona "Blocca i cookie di terze parti in modalità di navigazione in incognito".
1.5. Registrazione su web e Android (servizio di aggregazione)
Per utilizzare le API Privacy Sandbox in un ambiente di produzione, assicurati di aver completato la registrazione e l'attestazione sia per Chrome che per Android.
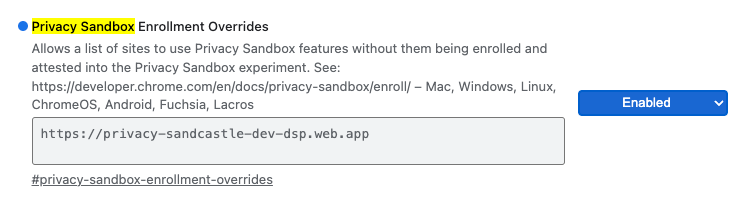
Per i test locali, la registrazione può essere disattivata utilizzando un flag di Chrome e uno switch CLI.
Per utilizzare il flag di Chrome per la nostra demo, vai a chrome://flags/#privacy-sandbox-enrollment-overrides e aggiorna l'override con il tuo sito oppure, se utilizzerai il nostro sito demo, non è richiesto alcun aggiornamento.
1.6. Onboarding del servizio di aggregazione (servizio di aggregazione)
Il servizio di aggregazione richiede l'onboarding dei coordinatori per poter essere utilizzato. Compila il modulo di onboarding del servizio di aggregazione fornendo l'indirizzo del sito di generazione di report, l'ID account AWS e altre informazioni.
1.7. Provider di servizi cloud (servizio di aggregazione)
Il servizio di aggregazione richiede l'utilizzo di un ambiente Trusted Execution Environment che utilizza un ambiente cloud. Il servizio di aggregazione è supportato su Amazon Web Services (AWS) e Google Cloud (GCP). Questo Codelab riguarda solo l'integrazione di AWS.
AWS fornisce un ambiente di esecuzione affidabile chiamato Nitro Enclaves. Assicurati di avere un account AWS e segui le istruzioni di installazione e aggiornamento dell'interfaccia a riga di comando AWS per configurare il tuo ambiente AWS CLI.
Se l'interfaccia a riga di comando AWS è nuova, puoi configurarla seguendo le istruzioni per la configurazione dell'interfaccia a riga di comando.
1.7.1. Crea un bucket AWS S3
Crea un bucket AWS S3 per archiviare lo stato di Terraform e un altro bucket S3 per archiviare i report e i report di riepilogo. Puoi utilizzare il comando CLI fornito. Sostituisci il campo in <> con le variabili appropriate.
aws s3api create-bucket --bucket <tf_bucket_name> --region us-east-1
aws s3api create-bucket --bucket <report_bucket_name> --region us-east-1
1.7.2. Creare una chiave di accesso utente
Crea le chiavi di accesso utente utilizzando la guida AWS. Verrà utilizzato per chiamare gli endpoint API createJob e getJob creati su AWS.
1.7.3. Autorizzazioni per utenti e gruppi AWS
Per eseguire il deployment di Aggregation Service su AWS, devi fornire determinate autorizzazioni all'utente utilizzato per il deployment del servizio. Per questo Codelab, assicurati che l'utente abbia accesso amministrativo per garantire autorizzazioni complete durante il deployment.
1.8. Terraform (servizio di aggregazione)
Questo Codelab utilizza Terraform per eseguire il deployment del servizio di aggregazione. Assicurati che il file binario di Terraform sia installato nel tuo ambiente locale.
Scarica il file binario di Terraform nel tuo ambiente locale.
Una volta scaricato il file binario di Terraform, estrailo e spostalo in /usr/local/bin.
cp <directory>/terraform /usr/local/bin
Verifica che Terraform sia disponibile nel percorso di classe.
terraform -v
1.9. Postman (per il servizio di aggregazione AWS)
Per questo Codelab, utilizza Postman per la gestione delle richieste.
Per creare uno spazio di lavoro, vai all'elemento di navigazione in alto "Spazi" e seleziona "Crea spazio di lavoro".
Seleziona "Spazio di lavoro vuoto", fai clic su Avanti e assegna il nome "Privacy Sandbox". Seleziona "Personale" e fai clic su "Crea".
Scarica i file di configurazione JSON e Ambiente globale dell'area di lavoro preconfigurata.
Importa i file JSON in "La mia area di lavoro" utilizzando il pulsante "Importa".

Verrà creata la raccolta Privacy Sandbox insieme alle richieste HTTP createJob e getJob.
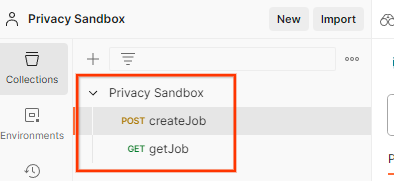
Aggiorna la "Chiave di accesso" e la "Chiave segreta" AWS tramite "Visualizzazione rapida dell'ambiente".
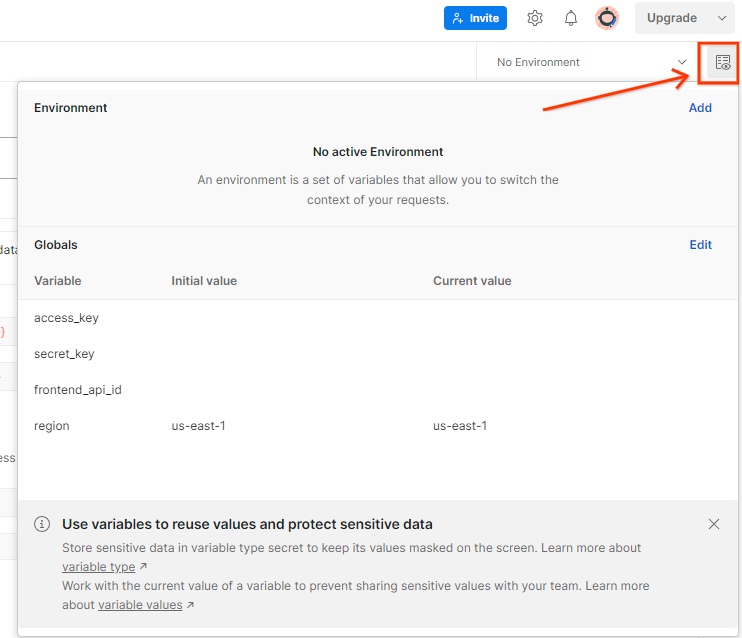
Fai clic su "Modifica" e aggiorna il "Valore corrente" sia di "access_key" sia di "secret_key". Tieni presente che frontend_api_id verrà fornito nella sezione 3.1.4 di questo documento. Ti consigliamo di utilizzare la regione us-east-1. Tuttavia, se vuoi eseguire il deployment in una regione diversa, assicurati di copiare l'AMI rilasciata nel tuo account o di eseguire un'autocostruzione utilizzando gli script forniti.

2. Codelab sui test locali
Puoi utilizzare lo strumento di test locale sul tuo computer per eseguire l'aggregazione e generare report di riepilogo utilizzando i report di debug non criptati.
Passaggi del codelab
Passaggio 2.1. Attiva report: attiva i report di aggregazione privata per poterli raccogliere.
Passaggio 2.2. Crea un report aggregabile per il debug: converti il report JSON raccolto in un report in formato AVRO.
Questo passaggio sarà simile a quando le tecnologie pubblicitarie raccolgono i report dagli endpoint di generazione di report dell'API e convertono i report JSON in report in formato AVRO.
Passaggio 2.3. Analizza la chiave del bucket dal report di debug: le chiavi del bucket sono progettate dalle tecnologie pubblicitarie. In questo codelab, poiché i bucket sono predefiniti, recupera le chiavi dei bucket come indicato.
Passaggio 2.4. Crea il dominio Avro di output: dopo aver recuperato le chiavi del bucket, crea il file Avro del dominio di output.
Passaggio 2.5. Crea report di riepilogo utilizzando lo strumento di test locale: utilizza lo strumento di test locale per creare report di riepilogo nell'ambiente locale.
Passaggio 2.6. Esamina il report di riepilogo: esamina il report di riepilogo creato dallo strumento di test locale.
2.1. Report Trigger
Vai al sito di demo di Privacy Sandbox. Viene attivato un report di aggregazione privato. Puoi visualizzare il report all'indirizzo chrome://private-aggregation-internals.
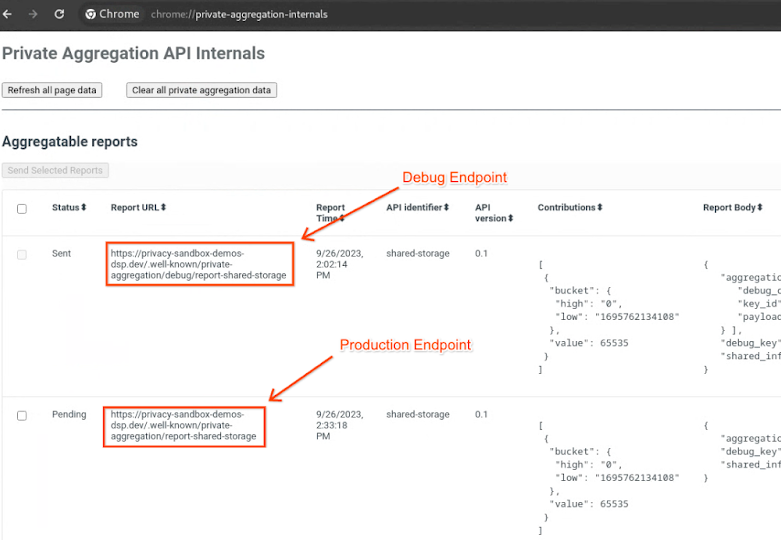
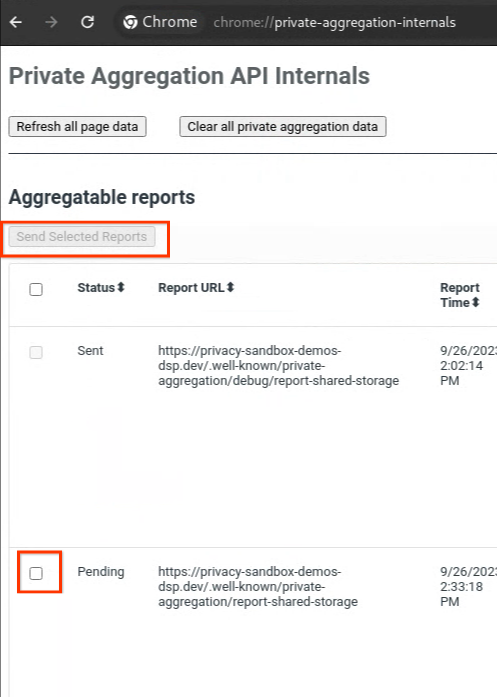
Se il report è in stato "In attesa", puoi selezionarlo e fare clic su "Invia i report selezionati".
2.2. Creare un report aggregabile per il debug
In chrome://private-aggregation-internals, copia il "Testo del report" ricevuto nell'endpoint [reporting-origin]/.well-known/private-aggregation/report-shared-storage.
Assicurati che in "Testo del report", aggregation_coordinator_origin contenga https://publickeyservice.msmt.aws.privacysandboxservices.com, il che significa che il report è aggregabile da AWS.
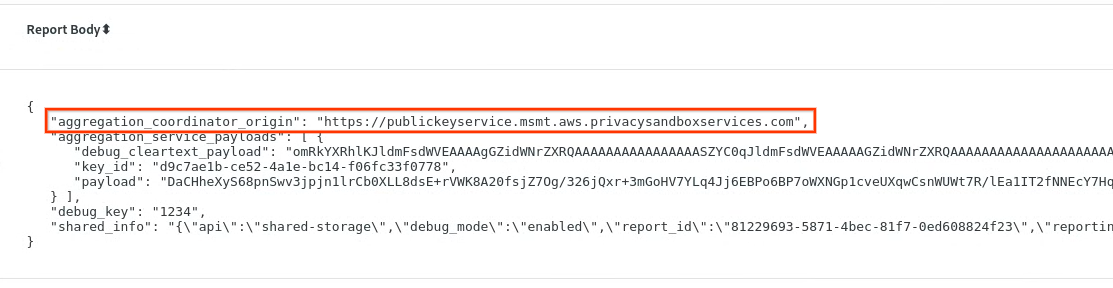
Inserisci il JSON "Report Body" in un file JSON. In questo esempio puoi utilizzare vim. Tuttavia, puoi utilizzare qualsiasi editor di testo.
vim report.json
Incolla il report in report.json e salva il file.

Una volta ottenuto il report, vai alla cartella dei report e utilizza aggregatable_report_converter.jar per creare il report aggregabile per il debug. Viene creato un report aggregabile denominato report.avro nella directory corrente.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Analizza la chiave del bucket dal report di debug
Il servizio di aggregazione richiede due file per l'aggregazione. Il report aggregabile e il file del dominio di output. Il file del dominio di output contiene le chiavi che vuoi recuperare dai report aggregabili. Per creare il file output_domain.avro, devi disporre delle chiavi del bucket che possono essere recuperate dai report.
Le chiavi dei bucket sono progettate dall'autore della chiamata dell'API e la demo contiene chiavi di bucket di esempio precostruite. Poiché nella demo è stata attivata la modalità di debug per l'aggregazione privata, puoi analizzare il payload in testo chiaro di debug dal "Testo del report" per recuperare la chiave del bucket. Tuttavia, in questo caso, la demo di Privacy Sandbox del sito crea le chiavi del bucket. Poiché l'aggregazione privata per questo sito è in modalità di debug, puoi utilizzare debug_cleartext_payload in "Testo del report" per ottenere la chiave del bucket.
Copia debug_cleartext_payload dal corpo del report.

Apri lo strumento Debug payload decoder for Private Aggregation (Decodificatore del payload di debug per l'aggregazione privata), incolla il tuo debug_cleartext_payload nella casella "INPUT" e fai clic su "Decodifica".
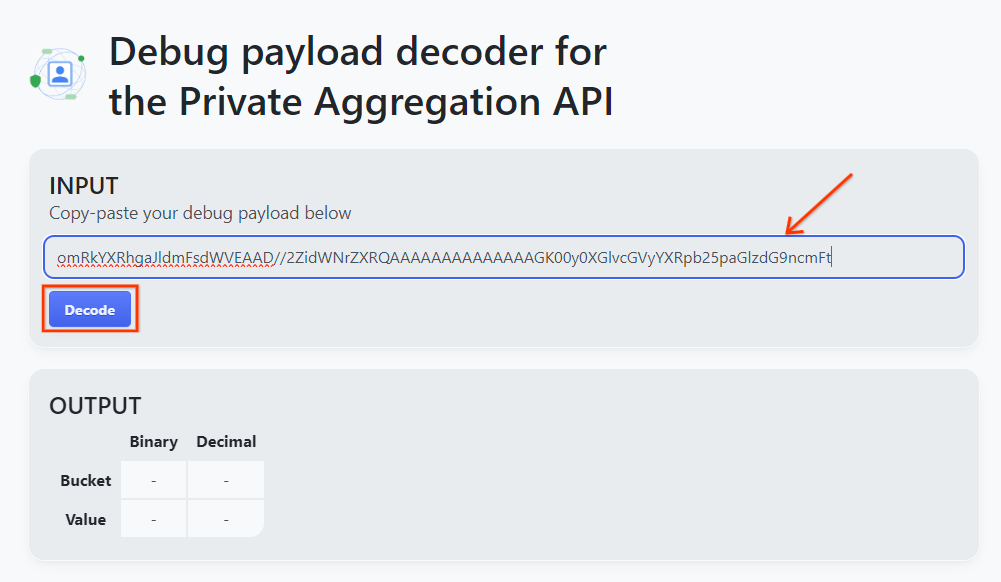
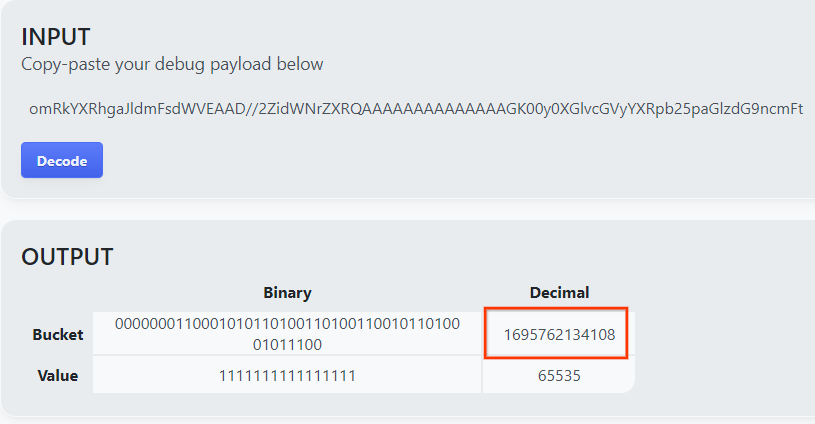
La pagina restituisce il valore decimale della chiave del bucket. Di seguito è riportata una chiave del bucket di esempio.
2.4. Crea il dominio di output AVRO
Ora che abbiamo la chiave del bucket, copia il valore decimale della chiave del bucket. Procedi a creare il output_domain.avro utilizzando la chiave del bucket. Assicurati di sostituire
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Lo script crea il file output_domain.avro nella cartella corrente.
2.5. Creare report di riepilogo utilizzando lo strumento di test locale
Utilizzeremo LocalTestingTool_{version}.jar scaricato nella sezione 1.1 per creare i report di riepilogo. Utilizza il seguente comando. Devi sostituire LocalTestingTool_{version}.jar con la versione scaricata per LocalTestingTool.
Esegui il seguente comando per generare un report di riepilogo nell'ambiente di sviluppo locale:
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
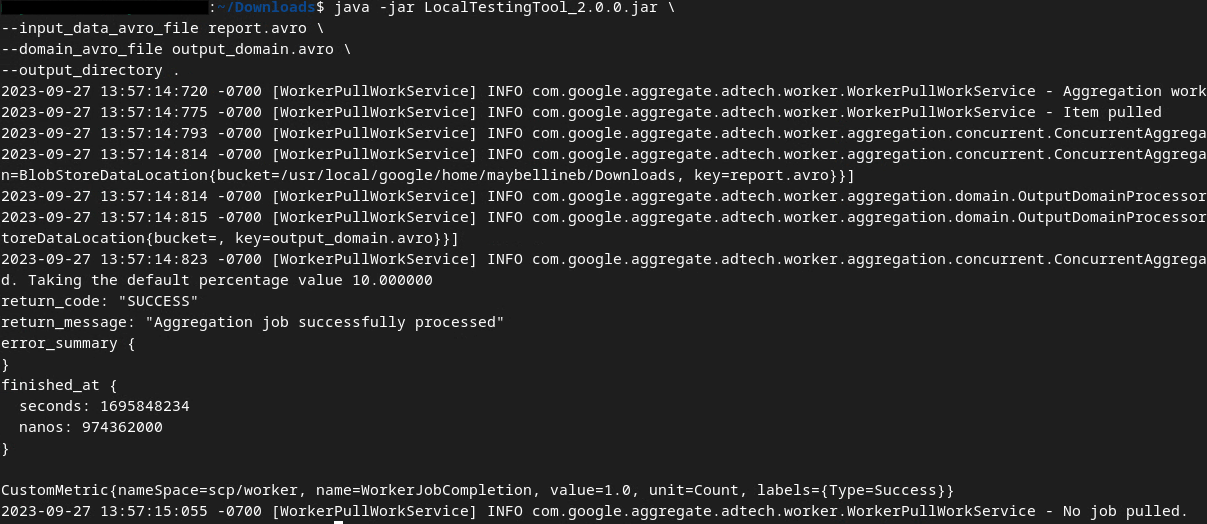
Una volta eseguito il comando, dovresti vedere qualcosa di simile all'immagine seguente. Al termine dell'operazione viene creato un report output.avro.
2.6. Esamina il report di riepilogo
Il report di riepilogo creato è in formato AVRO. Per poterlo leggere, devi convertirlo da AVRO a un formato JSON. Idealmente, la tecnologia pubblicitaria dovrebbe codificare per convertire i report AVRO in JSON.
Per il nostro Codelab, utilizzeremo lo strumento aggregatable_report_converter.jar fornito per convertire il report AVRO in JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
Viene visualizzato un report simile all'immagine seguente. Insieme a un report output.json creato nella stessa directory.

Apri il file JSON in un editor a tua scelta per esaminare il report di riepilogo.
3. Deployment del servizio di aggregazione
Per eseguire il deployment di Aggregation Service:
Passaggio 3: Deployment del servizio di aggregazione: esegui il deployment del servizio di aggregazione su AWS
Passaggio 3.1. Clona il repository del servizio di aggregazione
Passaggio 3.2. Scarica le dipendenze precompilate
Passaggio 3.3. Crea un ambiente di sviluppo
Passaggio 3.4. Esegui il deployment del servizio di aggregazione
3.1. Clona il repository del servizio di aggregazione
Nell'ambiente locale, clona il repository GitHub del servizio di aggregazione.
git clone https://github.com/privacysandbox/aggregation-service.git
3.2. Scarica le dipendenze precompilate
Dopo aver clonato il repository del servizio di aggregazione, vai alla cartella Terraform del repository e alla cartella cloud corrispondente. Se cloud_provider è AWS, puoi andare a
cd <repository_root>/terraform/aws
In download_prebuilt_dependencies.sh.
bash download_prebuilt_dependencies.sh
3.3 Crea un ambiente di sviluppo
Crea un ambiente di sviluppo in dev.
mkdir dev
Copia i contenuti della cartella demo nella cartella dev.
cp -R demo/* dev
Vai alla cartella dev.
cd dev
Aggiorna il file main.tf e premi i per input per modificarlo.
vim main.tf
Rimuovi il commento dal codice nella casella rossa rimuovendo il # e aggiornando i nomi del bucket e delle chiavi.
Per il file main.tf AWS:
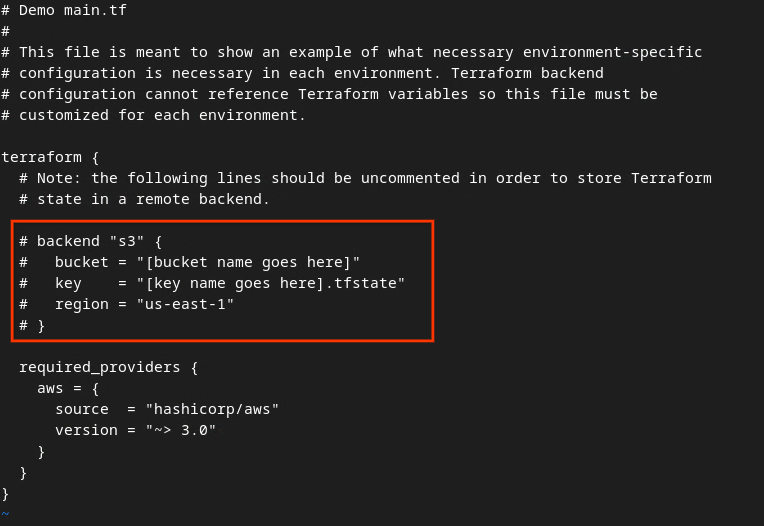
Il codice senza commenti dovrebbe avere il seguente aspetto.
backend "s3" {
bucket = "<tf_state_bucket_name>"
key = "<environment_name>.tfstate"
region = "us-east-1"
}
Al termine degli aggiornamenti, salvali ed esci dall'editor premendo esc -> :wq!. Gli aggiornamenti vengono salvati su main.tf.
Poi, rinomina example.auto.tfvars in dev.auto.tfvars.
mv example.auto.tfvars dev.auto.tfvars
Aggiorna dev.auto.tfvars e premi i per input per modificare il file.
vim dev.auto.tfvars
Aggiorna i campi nella casella rossa dell'immagine seguente con i parametri ARN AWS corretti forniti durante l'onboarding del servizio di aggregazione, l'ambiente e l'email di notifica.
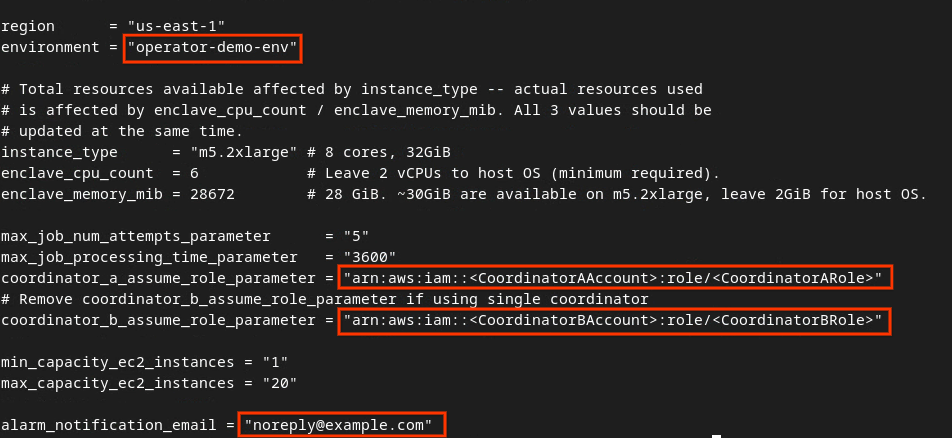
Al termine degli aggiornamenti, premi esc -> :wq!. Il file dev.auto.tfvars viene salvato e dovrebbe avere il seguente aspetto.
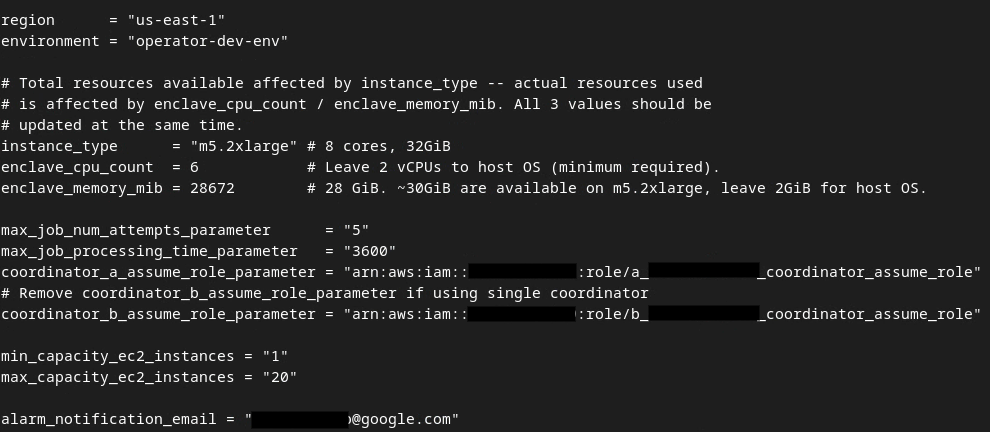
3.4. Esegui il deployment del servizio di aggregazione
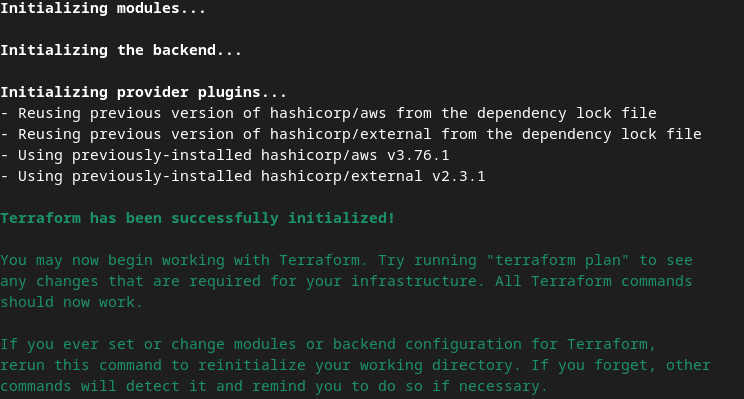
Per eseguire il deployment del servizio di aggregazione, inizializza Terraform nella stessa cartella
terraform init
Dovresti visualizzare qualcosa di simile alla seguente immagine:
Una volta inizializzato Terraform, crea il piano di esecuzione di Terraform. che restituisce il numero di risorse da aggiungere e altre informazioni aggiuntive simili all'immagine seguente.
terraform plan
Di seguito puoi vedere il riepilogo "Piano". Se si tratta di un nuovo deployment, dovresti vedere il numero di risorse che verranno aggiunte con 0 da modificare e 0 da eliminare.
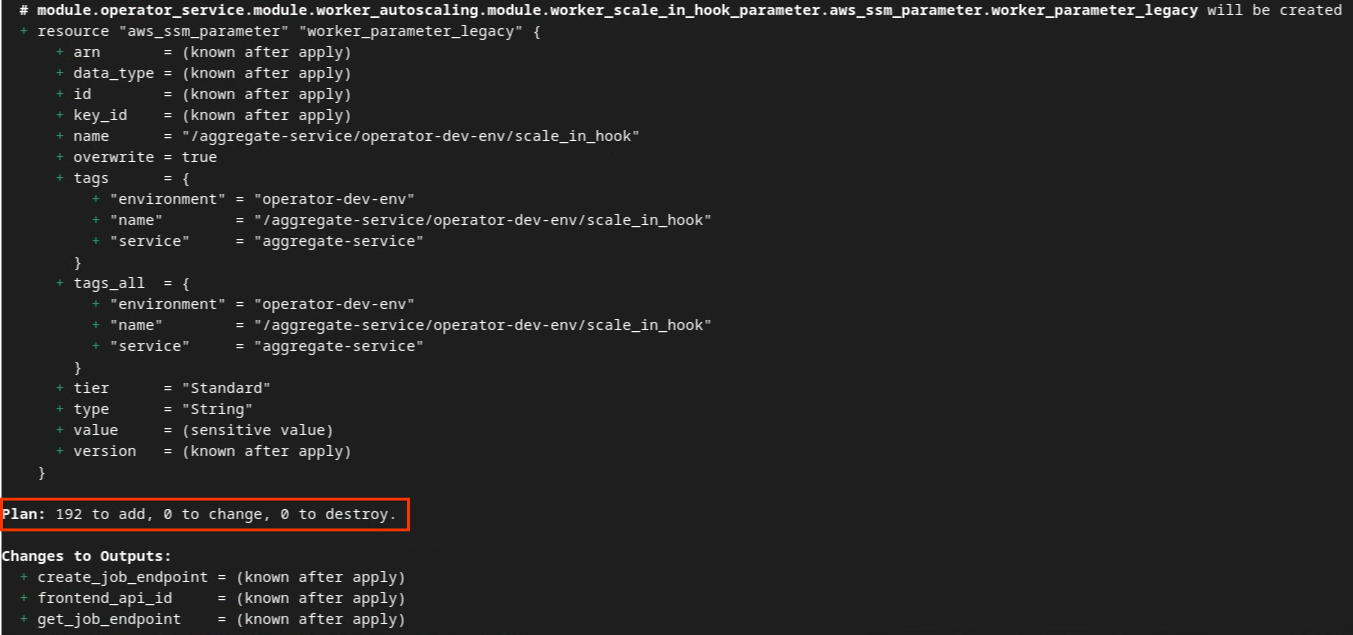
Al termine, puoi procedere con l'applicazione di Terraform.
terraform apply
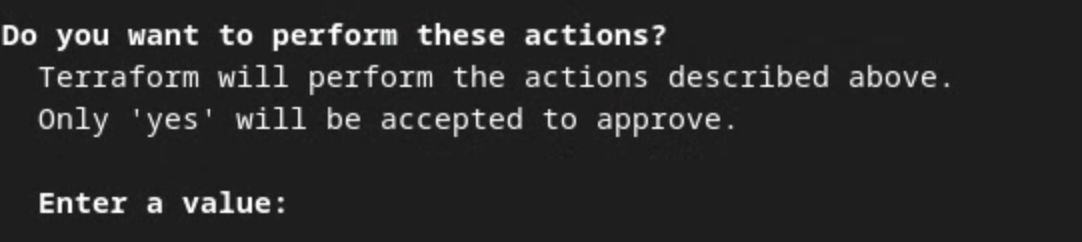
Quando ti viene chiesto di confermare l'esecuzione delle azioni da parte di Terraform, inserisci un yes nel valore.
Al termine di terraform apply, vengono restituiti i seguenti endpoint per createJob e getJob. Viene restituito anche il valore frontend_api_id da aggiornare in Postman nella sezione 1.9.

4. Creazione dell'input del servizio di aggregazione
Procedi creando i report AVRO per l'aggregazione nel servizio di aggregazione.
Passaggio 4: Creazione dell'input del servizio di aggregazione: crea i report del servizio di aggregazione raggruppati per il servizio di aggregazione.
Passaggio 4.1. Attiva report
Passaggio 4.2. Raccogli i report aggregabili
Passaggio 4.3. Converti i report in AVRO
Passaggio 4.4. Crea il dominio di output AVRO
4.1. Report Trigger
Vai al sito di demo di Privacy Sandbox. Viene attivato un report di aggregazione privato. Puoi visualizzare il report all'indirizzo chrome://private-aggregation-internals.
Se il report è in stato "In attesa", puoi selezionarlo e fare clic su "Invia i report selezionati".
4.2. Raccogliere report aggregabili
Raccogli i report aggregabili dagli endpoint .well-known della tua API corrispondente.
- Private Aggregation
[reporting-origin] /.well-known/private-aggregation/report-shared-storage - Report sull'attribuzione - Report di riepilogo
[reporting-origin] /.well-known/attribution-reporting/report-aggregate-attribution
Per questo codelab, eseguirai la raccolta dei report manualmente. In produzione, le tecnologie pubblicitarie devono raccogliere e convertire i report in modo programmatico.
In chrome://private-aggregation-internals, copia il "Testo del report" ricevuto nell'endpoint [reporting-origin]/.well-known/private-aggregation/report-shared-storage.
Assicurati che in "Testo del report", aggregation_coordinator_origin contenga https://publickeyservice.msmt.aws.privacysandboxservices.com, il che significa che il report è aggregabile da AWS.
Inserisci il JSON "Report Body" in un file JSON. In questo esempio puoi utilizzare vim. Tuttavia, puoi utilizzare qualsiasi editor di testo.
vim report.json
Incolla il report in report.json e salva il file.
4.3. Convertire i report in AVRO
I report ricevuti dagli endpoint .well-known sono in formato JSON e devono essere convertiti in formato report AVRO. Una volta ottenuto il report JSON, vai alla cartella dei report e utilizza aggregatable_report_converter.jar per creare il report aggregabile di debug. Viene creato un report aggregabile denominato report.avro nella directory corrente.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
4.4. Crea il dominio di output AVRO
Per creare il file output_domain.avro, devi disporre delle chiavi del bucket che possono essere recuperate dai report.
Le chiavi dei bucket sono progettate dalla tecnologia pubblicitaria. Tuttavia, in questo caso, le chiavi dei bucket vengono create dal sito Privacy Sandbox demo. Poiché l'aggregazione privata per questo sito è in modalità di debug, puoi utilizzare debug_cleartext_payload in "Testo del report" per ottenere la chiave del bucket.
Copia debug_cleartext_payload dal corpo del report.
Apri goo.gle/ags-payload-decoder, incolla il tuo debug_cleartext_payload nella casella "INPUT" e fai clic su "Decodifica".
La pagina restituisce il valore decimale della chiave del bucket. Di seguito è riportata una chiave del bucket di esempio.
Ora che abbiamo la chiave del bucket, crea output_domain.avro. Assicurati di sostituire
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Lo script crea il file output_domain.avro nella cartella corrente.
4.5. Spostare i report nel bucket AWS
Dopo aver creato i report AVRO (sezione 3.2.3) e il dominio di output (sezione 3.2.4), sposta i report e il dominio di output nei bucket S3 dei report.
Se hai configurato AWS CLI nel tuo ambiente locale, utilizza i seguenti comandi per copiare i report nel bucket S3 e nella cartella dei report corrispondenti.
aws s3 cp report.avro s3://<report_bucket_name>/<report_folder>/
aws s3 cp output_domain.avro s3://<report_bucket_name>/<output_domain_folder>/
5. Utilizzo del servizio di aggregazione
Da terraform apply, vengono restituiti create_job_endpoint, get_job_endpoint e frontend_api_id. Copia frontend_api_id e inseriscilo nella variabile globale di Postman frontend_api_id che hai configurato nella sezione dei prerequisiti 1.9.
Passaggio 5. Utilizzo del servizio di aggregazione: utilizza l'API Aggregation Service per creare report di riepilogo e rivederli.
Passaggio 5.1. Utilizzo dell'endpoint createJob per l'elaborazione collettiva
Passaggio 5.2. Utilizzo dell'endpoint getJob per recuperare lo stato del batch
Passaggio 5.3. Esaminare il report di riepilogo
5.1. Utilizzo dell'endpoint createJob per i batch
In Postman, apri la raccolta "Privacy Sandbox" e seleziona "createJob".
Seleziona "Body" e "raw" per inserire il payload della richiesta.
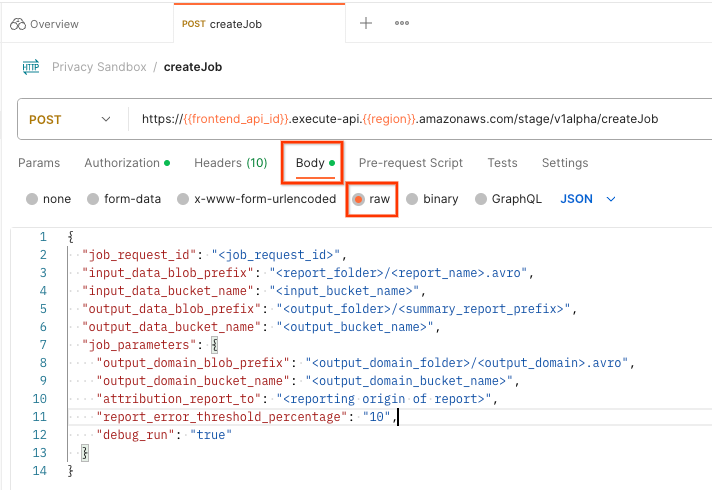
Lo schema del payload createJob è disponibile su github e ha un aspetto simile al seguente. Sostituisci <> con i campi appropriati.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
], // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Dopo aver fatto clic su "Invia", viene creato il job con il job_request_id. Una volta che la richiesta viene accettata dal servizio di aggregazione, dovresti ricevere una risposta HTTP 202. Altri possibili codici di ritorno sono disponibili nella pagina Codici di risposta HTTP

5.2. Utilizzo dell'endpoint getJob per recuperare lo stato del batch
Per controllare lo stato della richiesta di job, puoi utilizzare l'endpoint getJob. Seleziona "getJob" nella raccolta "Privacy Sandbox".
In "Params", aggiorna il valore job_request_id con il valore job_request_id inviato nella richiesta createJob.
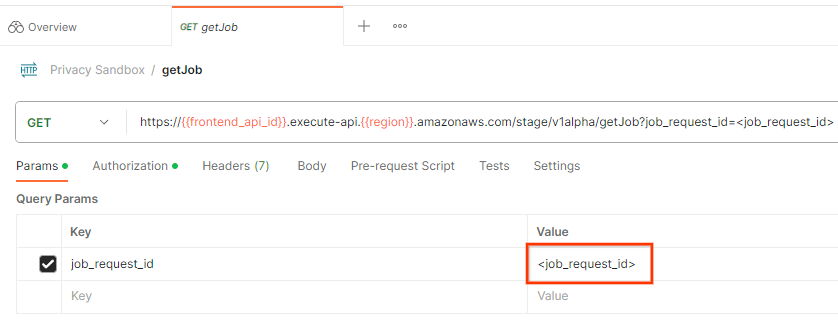
Il risultato di getJob deve restituire lo stato della richiesta di lavoro con un codice di stato HTTP 200. La richiesta "Body" contiene le informazioni necessarie, come job_status, return_message e error_messages (se il job ha generato un errore).
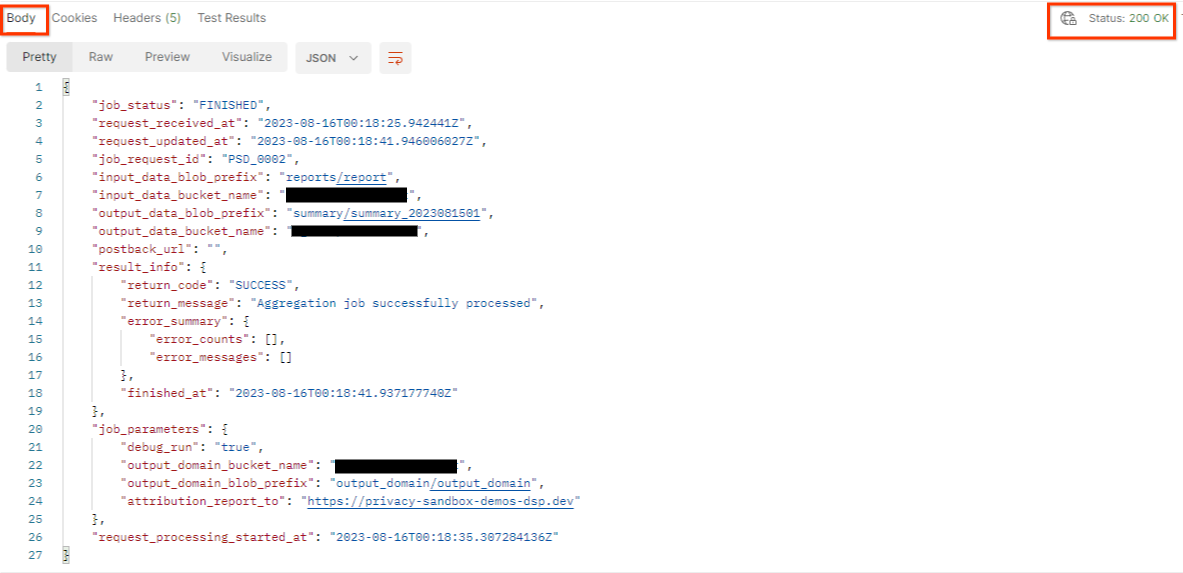
Poiché il sito di generazione del report demo è diverso dal sito di cui è stato eseguito l'onboarding nel tuo ID AWS, potresti ricevere una risposta con PRIVACY_BUDGET_AUTHORIZATION_ERROR return_code. Questo è normale perché il sito dell'origine report dei report non corrisponde al sito di generazione dei report di cui è stato eseguito il provisioning per l'ID AWS.
{
"job_status": "FINISHED",
"request_received_at": "2023-12-07T22:50:58.830956Z",
"request_updated_at": "2023-12-07T22:51:10.526326456Z",
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"postback_url": "",
"result_info": {
"return_code": "PRIVACY_BUDGET_AUTHORIZATION_ERROR",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-12-07T22:51:10.517730898Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"attribution_report_to": "https://privacy-sandbox-demos-dsp.dev",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
},
"request_processing_started_at": "2023-12-07T22:51:06.034472697Z"
}
5.3. Esaminare il report di riepilogo
Una volta ricevuto il report di riepilogo nel bucket S3 di output, puoi scaricarlo nel tuo ambiente locale. I report di riepilogo sono in formato AVRO e possono essere convertiti nuovamente in JSON. Puoi utilizzare aggregatable_report_converter.jar per leggere il report utilizzando il seguente comando.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
Viene restituito un JSON dei valori aggregati di ogni chiave del bucket simile all'immagine seguente.

Se la richiesta createJob include debug_run come true, puoi ricevere il report di riepilogo nella cartella di debug che si trova in output_data_blob_prefix. Il report è in formato AVRO e può essere convertito in JSON utilizzando il comando precedente.
Il report contiene la chiave del bucket, la metrica senza rumore e il rumore aggiunto alla metrica senza rumore per formare il report di riepilogo. Il report è simile all'immagine seguente.

Le annotazioni contengono anche in_reports e in_domain, che significano:
- in_reports: la chiave del bucket è disponibile all'interno dei report aggregabili.
- in_domain: la chiave del bucket è disponibile all'interno del file AVRO output_domain.