
1. Pré-requisitos
Para realizar este codelab, alguns pré-requisitos são necessários. Cada requisito é marcado de acordo com se ele é necessário para "Testes locais" ou "Serviço de agregação".
1.1. Fazer o download da ferramenta de teste local
O teste local exige o download da ferramenta de teste local. A ferramenta vai gerar relatórios resumidos com base nos relatórios de depuração não criptografados.
A ferramenta de teste local está disponível para download nos arquivos JAR do Lambda no GitHub. Ele precisa ser nomeado como LocalTestingTool_{version}.jar.
1.2. Verifique se o JAVA JRE está instalado (serviço de agregação e teste local)
Abra o Terminal e use java --version para verificar se a máquina tem Java ou openJDK instalado.

Se ele não estiver instalado, faça o download e a instalação no site do Java ou no site do OpenJDK.
1.3. Fazer o download do Aggregatable Report Converter (serviço de testes locais e agregação)
É possível fazer o download de uma cópia do conversor de relatórios agregáveis no repositório do GitHub das demonstrações do Sandbox de privacidade.
1.4. Ativar as APIs Ad Privacy (serviço de testes locais e agregação)
No navegador, acesse chrome://settings/adPrivacy e ative todas as APIs de privacidade de anúncios.
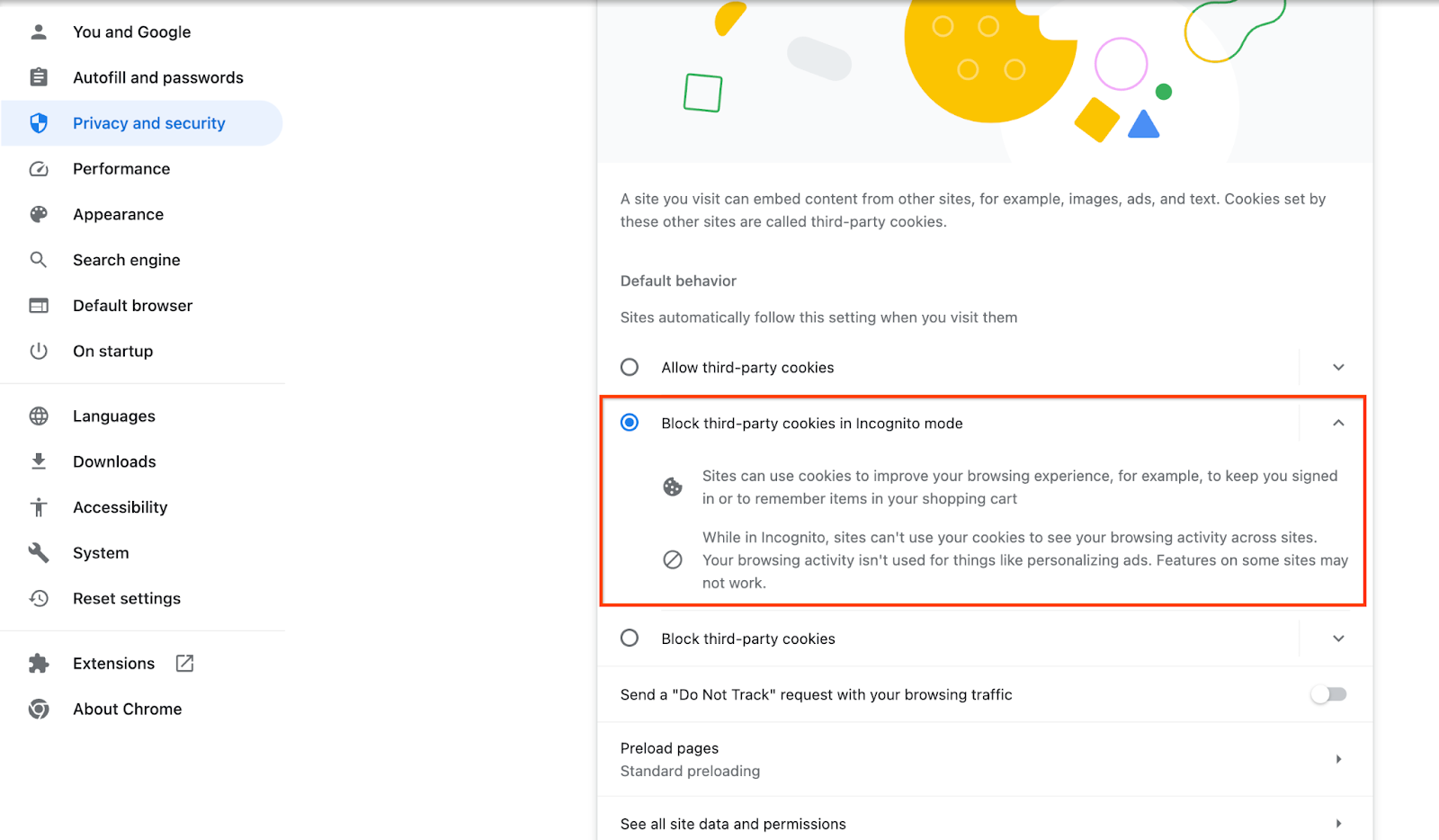
Verifique se os cookies de terceiros estão ativados.
No navegador, acesse chrome://settings/cookies e selecione Bloquear cookies de terceiros no modo de navegação anônima.
1.5. Inscrição na Web e no Android (serviço de agregação)
Para usar as APIs do Sandbox de privacidade em um ambiente de produção, conclua a inscrição e a declaração para o Chrome e o Android.
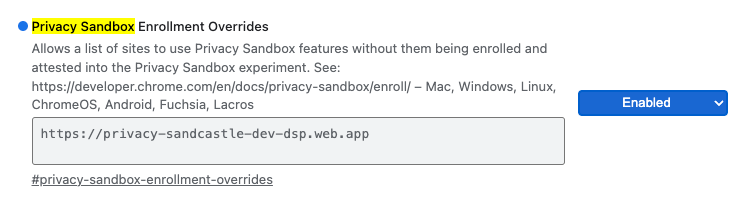
Para testes locais, a inscrição pode ser desativada usando uma flag do Chrome e um switch da CLI.
Para usar a flag do Chrome para nossa demonstração, acesse chrome://flags/#privacy-sandbox-enrollment-overrides e atualize a substituição com seu site. Se você for usar nosso site de demonstração, não será necessário fazer uma atualização.
1.6. Integração do serviço de agregação (serviço de agregação)
O serviço de agregação exige integração com os coordenadores para poder ser usado. Preencha o formulário de integração do serviço de agregação com o endereço do site de relatórios, o ID da conta da AWS e outras informações.
1.7. Provedor de nuvem (serviço de agregação)
O serviço de agregação exige o uso de um ambiente de execução confiável que usa um ambiente de nuvem. O serviço de agregação tem suporte no Amazon Web Services (AWS) e no Google Cloud (GCP). Este codelab vai abordar apenas a integração com a AWS.
A AWS oferece um ambiente de execução confiável chamado Nitro Enclaves. Confira se você tem uma conta da AWS e siga as instruções de instalação e atualização da AWS CLI para configurar seu ambiente da AWS CLI.
Se a AWS CLI for nova, você poderá configurá-la usando as instruções de configuração da CLI.
1.7.1. Criar um bucket do AWS S3
Crie um bucket do AWS S3 para armazenar o estado do Terraform e outro bucket do S3 para armazenar seus relatórios e relatórios de resumo. Você pode usar o comando da CLI fornecido. Substitua o campo em <> para as variáveis adequadas.
aws s3api create-bucket --bucket <tf_bucket_name> --region us-east-1
aws s3api create-bucket --bucket <report_bucket_name> --region us-east-1
1.7.2. Criar chave de acesso do usuário
Crie chaves de acesso do usuário usando o guia da AWS. Ele será usado para chamar os endpoints da API createJob e getJob criados na AWS.
1.7.3. Permissões de usuários e grupos da AWS
Para implantar o serviço de agregação na AWS, você precisa conceder determinadas permissões ao usuário usado para implantar o serviço. Para este codelab, verifique se o usuário tem acesso de administrador para garantir permissões totais na implantação.
1.8. Terraform (serviço de agregação)
Este codelab usa o Terraform para implantar o serviço de agregação. Verifique se o binário do Terraform está instalado no seu ambiente local.
Faça o download do binário do Terraform no seu ambiente local.
Depois que o binário do Terraform for transferido, extraia o arquivo e mova-o para /usr/local/bin.
cp <directory>/terraform /usr/local/bin
Verifique se o Terraform está disponível no classpath.
terraform -v
1.9. Postman (para o serviço de agregação da AWS)
Neste codelab, use o Postman para gerenciamento de solicitações.
Para criar um espaço de trabalho, acesse o item de navegação superior Espaços de trabalho e selecione Criar espaço de trabalho.
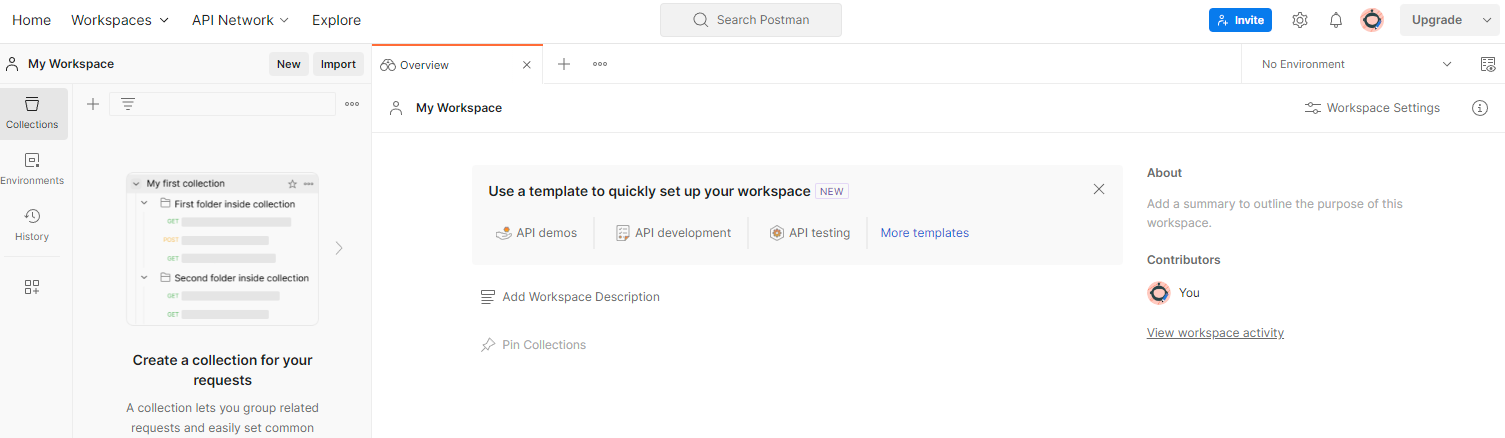
Selecione Espaço de trabalho em branco, clique em "Próxima" e nomeie como Sandbox de privacidade. Selecione Pessoal e clique em Criar.
Faça o download dos arquivos configuração JSON e Ambiente global do espaço de trabalho pré-configurado.
Importe os arquivos JSON para "Meu espaço de trabalho" usando o botão Importar.

Isso vai criar a coleção do Sandbox de privacidade para você, junto com as solicitações HTTP createJob e getJob.
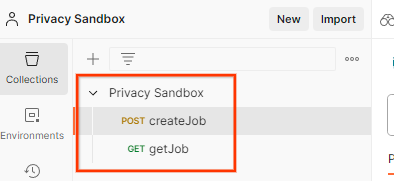
Atualize a "Chave de acesso" e a "Chave secreta" da AWS pelo Visualização rápida do ambiente.
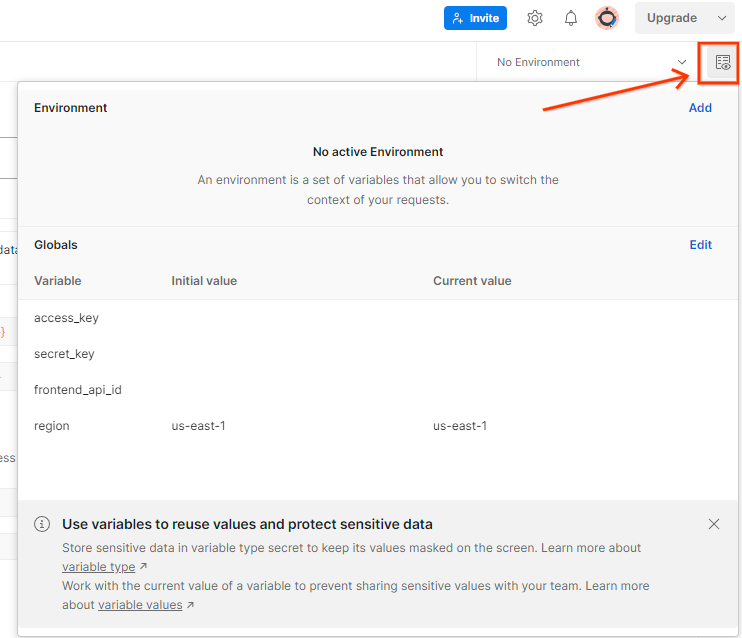
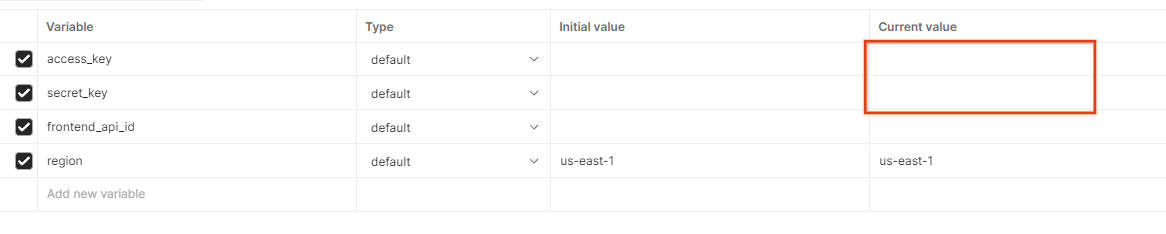
Clique em Editar e atualize o "Valor atual" de access_key e secret_key. frontend_api_id será fornecido na seção 3.1.4 deste documento. Recomendamos usar a região us-east-1. No entanto, se você quiser implantar em uma região diferente, copie o AMI lançado para sua conta ou faça uma autoconstrução usando os scripts fornecidos.

2. Codelab de testes locais
Você pode usar a ferramenta de teste local na sua máquina para realizar a agregação e gerar relatórios de resumo usando os relatórios de depuração não criptografados.
Etapas do codelab
Etapa 2.1. Acionar relatório: acione os relatórios de agregação particular para coletar o relatório.
Etapa 2.2. Criar um relatório de depuração agregável: converta o relatório JSON coletado em um relatório formatado em AVRO.
Essa etapa é semelhante à coleta de relatórios dos endpoints de relatórios da API pelas adtechs e a conversão dos relatórios JSON em relatórios formatados em AVRO.
Etapa 2.3. Analisar a chave do bucket do relatório de depuração: as chaves de bucket são criadas por adtechs. Neste codelab, como os buckets são predefinidos, extraia as chaves de bucket conforme fornecido.
Etapa 2.4. Criar o AVRO do domínio de saída: depois que as chaves do bucket forem recuperadas, crie o arquivo AVRO do domínio de saída.
Etapa 2,5. Criar relatórios resumidos usando a ferramenta de testes locais: use a ferramenta de testes locais para criar relatórios resumidos no ambiente local.
Etapa 2.6. Analisar o relatório de resumo: analise o relatório de resumo criado pela ferramenta de teste local.
2.1. Relatório de acionadores
Acesse o site da demonstração do Sandbox de privacidade. Isso aciona um relatório de agregação particular. Confira o relatório em chrome://private-aggregation-internals.
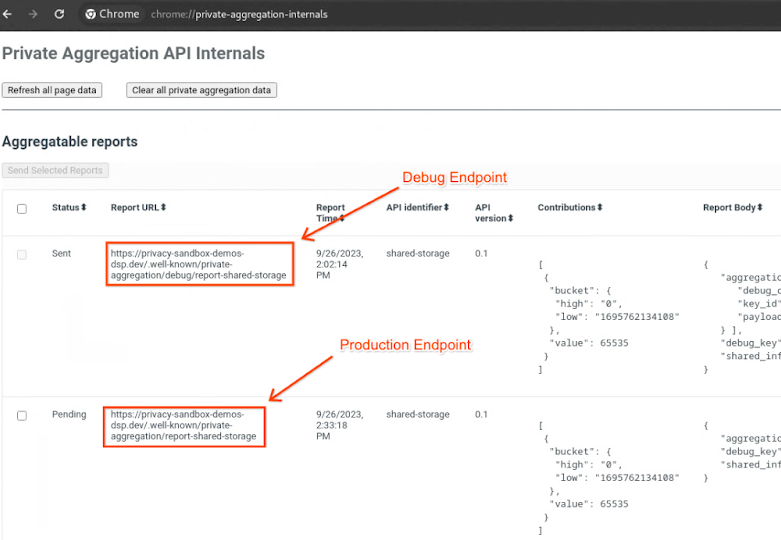
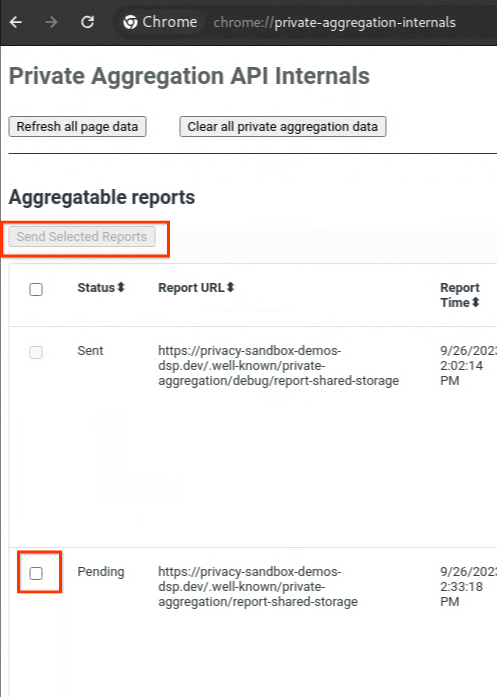
Se a denúncia estiver em Pendente, selecione-a e clique em Enviar relatórios selecionados.
2.2. Criar um relatório agregável de depuração
Em chrome://private-aggregation-internals, copie o "Corpo do relatório" recebido no endpoint [reporting-origin]/.well-known/private-aggregation/report-shared-storage.
Verifique se, no Corpo do relatório, o aggregation_coordinator_origin contém https://publickeyservice.msmt.aws.privacysandboxservices.com, o que significa que o relatório é agregável pela AWS.
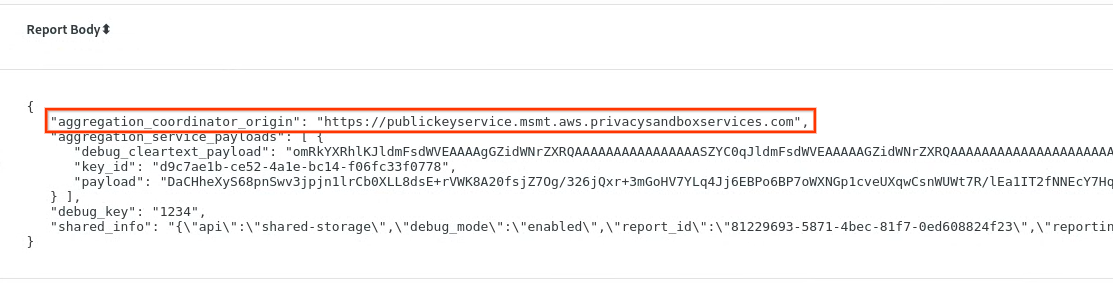
Coloque o JSON "Corpo do relatório" em um arquivo JSON. Neste exemplo, use o vim. Mas você pode usar qualquer editor de texto.
vim report.json
Cole o relatório em report.json e salve o arquivo.

Depois disso, navegue até a pasta de relatórios e use aggregatable_report_converter.jar para criar o relatório agregável de depuração. Isso cria um relatório agregável chamado report.avro no seu diretório atual.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Analisar a chave do bucket do relatório de depuração
O serviço de agregação exige dois arquivos ao agrupar. O relatório que pode ser agregado e o arquivo de domínio de saída. O arquivo de domínio de saída contém as chaves que você quer recuperar dos relatórios agregáveis. Para criar o arquivo output_domain.avro, você precisa das chaves do bucket que podem ser recuperadas dos relatórios.
As chaves de bucket são projetadas pelo autor da chamada da API, e a demonstração contém exemplos de chaves de bucket pré-construídas. Como a demonstração ativou o modo de depuração para a agregação particular, você pode analisar o payload de texto não criptografado de depuração do "Corpo do relatório" para extrair a chave do bucket. No entanto, neste caso, a demonstração do sandbox de privacidade do site cria as chaves do bucket. Como a agregação privada para esse site está no modo de depuração, use o debug_cleartext_payload do Corpo do relatório para acessar a chave do bucket.
Copie o debug_cleartext_payload do corpo do relatório.

Abra a ferramenta Decodificador de payload de depuração para agregação privada e cole o debug_cleartext_payload na caixa INPUT e clique em Decode.
A página retorna o valor decimal da chave do bucket. Confira a seguir um exemplo de chave de bucket.
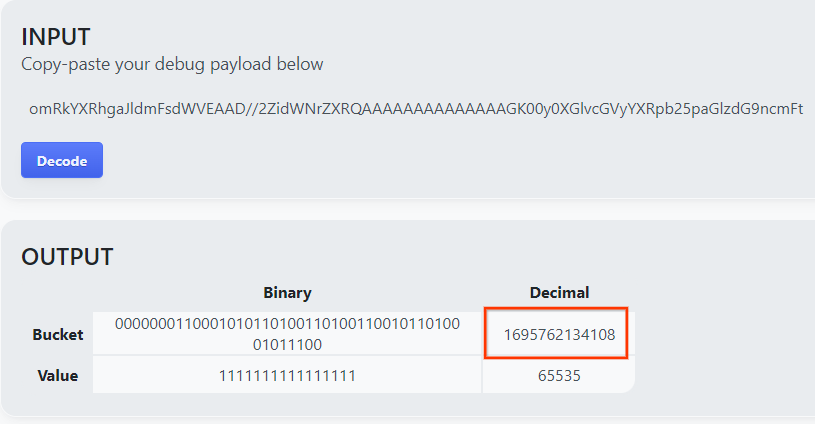
2.4. Criar o AVRO do domínio de saída
Agora que temos a chave do bucket, copie o valor decimal dela. Crie o output_domain.avro usando a chave do bucket. Substitua
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
O script cria o arquivo output_domain.avro na sua pasta atual.
2.5. Criar relatórios de resumo usando a ferramenta de teste local
Vamos usar o LocalTestingTool_{version}.jar que foi feito o download na seção 1.1 para criar os relatórios de resumo. Use o comando a seguir. Substitua LocalTestingTool_{version}.jar pela versão transferida por download para a LocalTestingTool.
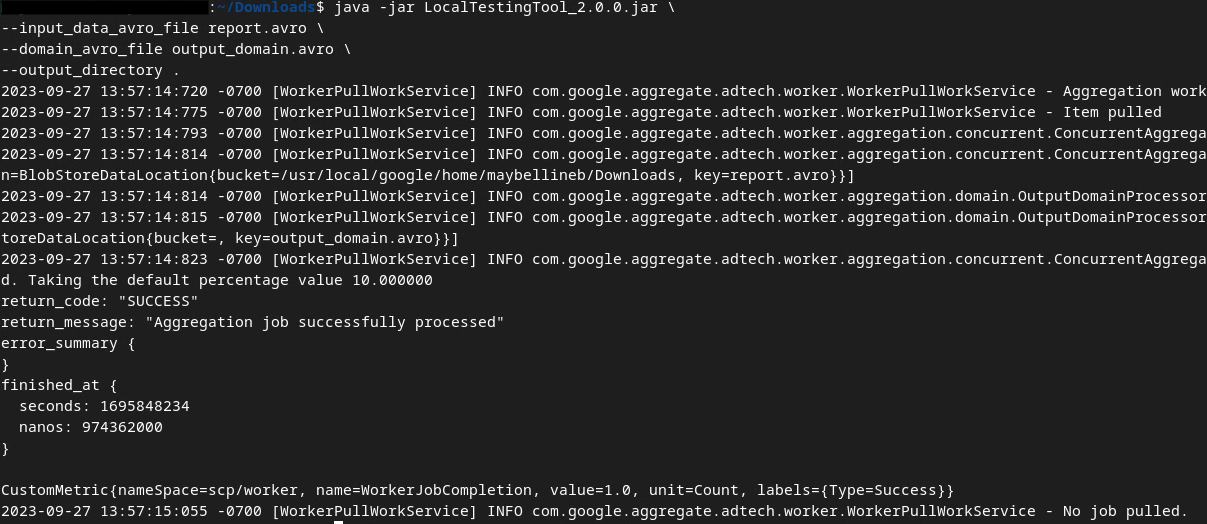
Execute o comando abaixo para gerar um relatório de resumo no seu ambiente de desenvolvimento local:
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
Você vai encontrar algo parecido com a imagem a seguir quando o comando for executado. Um relatório output.avro é criado quando isso é concluído.
2.6. Analisar o relatório resumido
O relatório de resumo criado é no formato AVRO. Para ler isso, você precisa converter o formato AVRO em JSON. O ideal é que a adtech codifique para converter relatórios AVRO em JSON.
Para o codelab, vamos usar a ferramenta aggregatable_report_converter.jar fornecida para converter o relatório AVRO em JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
Isso vai retornar um relatório semelhante à imagem abaixo. Além de um relatório output.json criado no mesmo diretório.

Abra o arquivo JSON em um editor de sua preferência para analisar o relatório resumido.
3. Implantação do serviço de agregação
Para implantar o serviço de agregação, siga estas etapas:
Etapa 3: Implantação do serviço de agregação: implantar o serviço de agregação na AWS
Etapa 3.1. Clone o repositório do serviço de agregação
Etapa 3.2. Fazer o download de dependências pré-criadas
Etapa 3.3. Criar um ambiente de desenvolvimento
Etapa 3.4. Implantar o serviço de agregação
3.1. Clonar o repositório do serviço de agregação
No seu ambiente local, clone o repositório do GitHub do serviço de agregação.
git clone https://github.com/privacysandbox/aggregation-service.git
3.2. Fazer o download de dependências pré-criadas
Depois de clonar o repositório do serviço de agregação, acesse a pasta do Terraform do repositório e a pasta correspondente na nuvem. Se o cloud_provider for AWS, prossiga para
cd <repository_root>/terraform/aws
Em download_prebuilt_dependencies.sh.
bash download_prebuilt_dependencies.sh
3.3. Criar um ambiente de desenvolvimento
Crie um ambiente de desenvolvimento em dev.
mkdir dev
Copie o conteúdo da pasta demo para a pasta dev.
cp -R demo/* dev
Mova para a pasta dev.
cd dev
Atualize o arquivo main.tf e pressione i para que o input edite o arquivo.
vim main.tf
Remova o caractere # para remover a marca de comentário do código na caixa vermelha e atualize os nomes do bucket e da chave.
Para o main.tf da AWS:
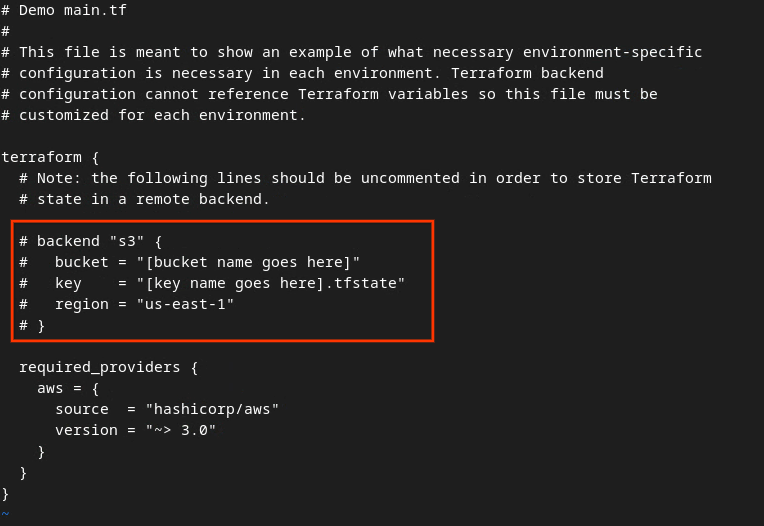
O código sem comentários vai ficar assim:
backend "s3" {
bucket = "<tf_state_bucket_name>"
key = "<environment_name>.tfstate"
region = "us-east-1"
}
Quando as atualizações forem concluídas, salve as atualizações e saia do editor pressionando esc -> :wq!. Isso salva as atualizações em main.tf.
Em seguida, renomeie example.auto.tfvars como dev.auto.tfvars.
mv example.auto.tfvars dev.auto.tfvars
Atualize dev.auto.tfvars e pressione i para input editar o arquivo.
vim dev.auto.tfvars
Atualize os campos na caixa vermelha conforme a imagem com os parâmetros corretos do ARN da AWS fornecidos durante a integração do serviço de agregação, o ambiente e o e-mail de notificação.
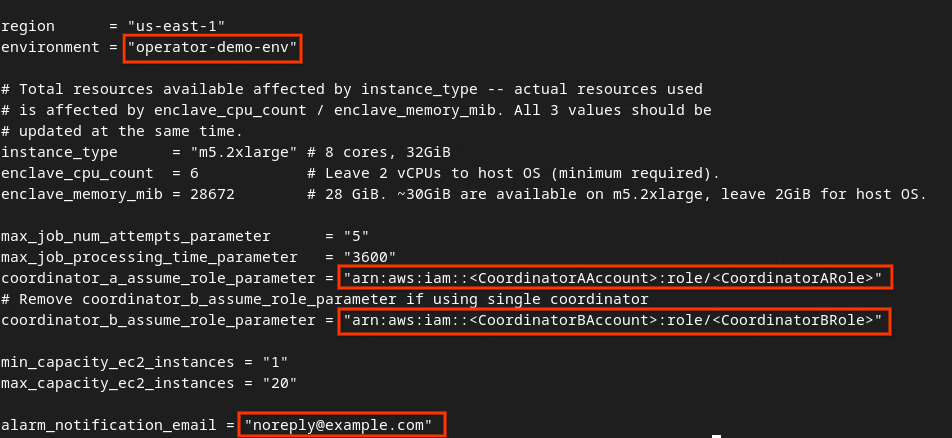
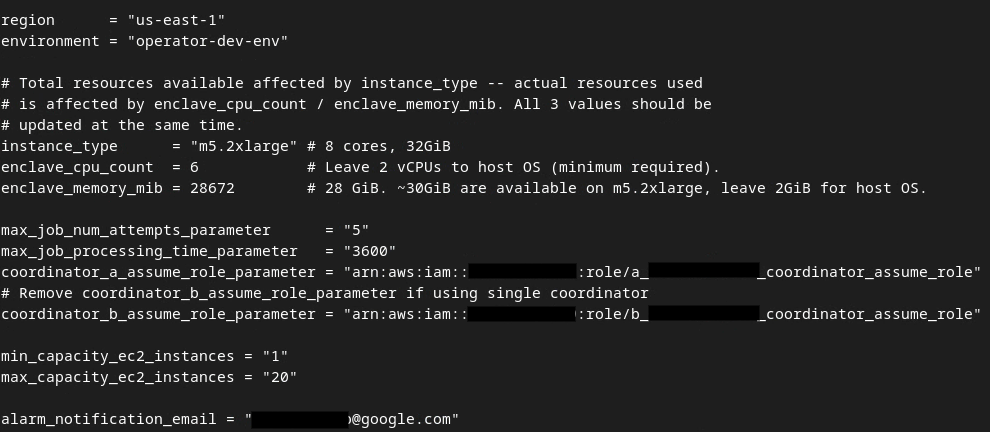
Quando as atualizações forem concluídas, pressione esc -> :wq!. O arquivo dev.auto.tfvars será salvo e vai ficar parecido com a imagem a seguir.
3.4. Implantar o serviço de agregação
Para implantar o serviço de agregação, na mesma pasta
terraform init
Isso vai retornar algo semelhante à imagem abaixo:
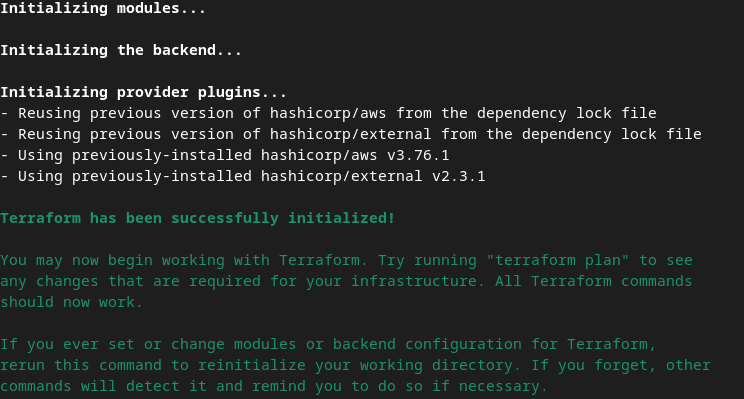
Depois que o Terraform for inicializado, crie o plano de execução do Terraform. Onde ele retorna o número de recursos a serem adicionados e outras informações semelhantes à imagem abaixo.
terraform plan
Confira abaixo o resumo do plano. Se for uma nova implantação, você vai ver o número de recursos que serão adicionados com 0 para mudar e 0 para destruir.
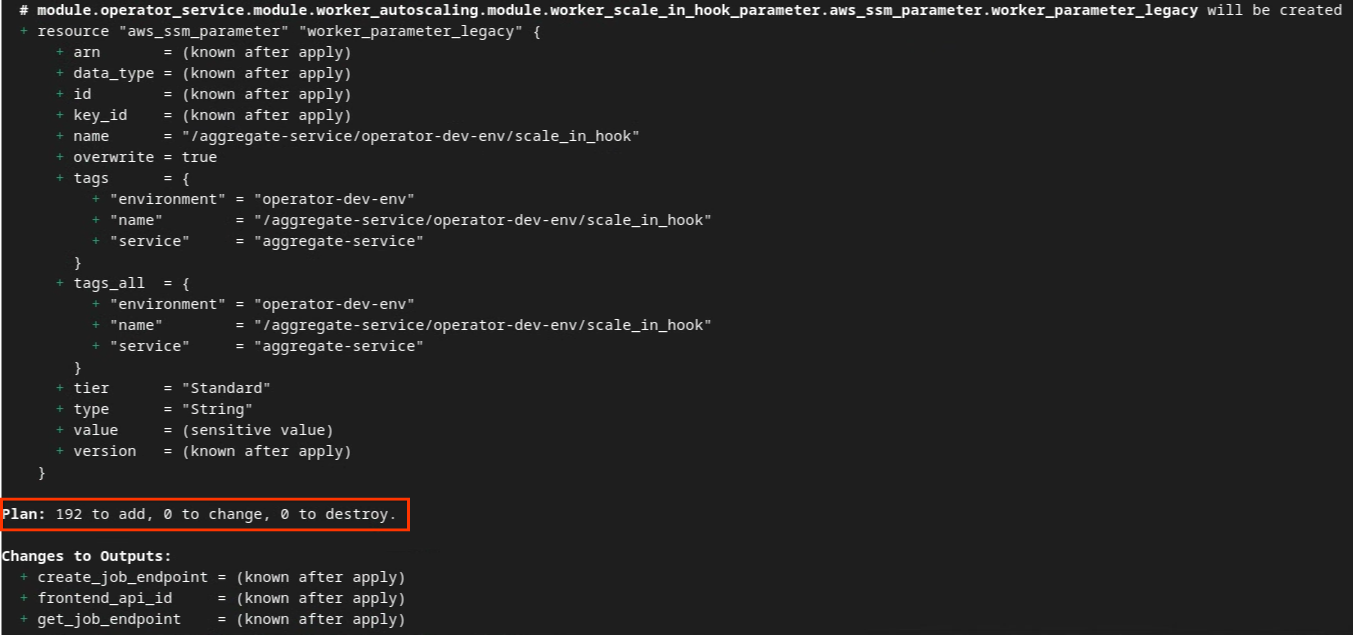
Depois disso, você pode aplicar o Terraform.
terraform apply
Quando o Terraform solicitar a confirmação da execução das ações, insira um yes no valor.
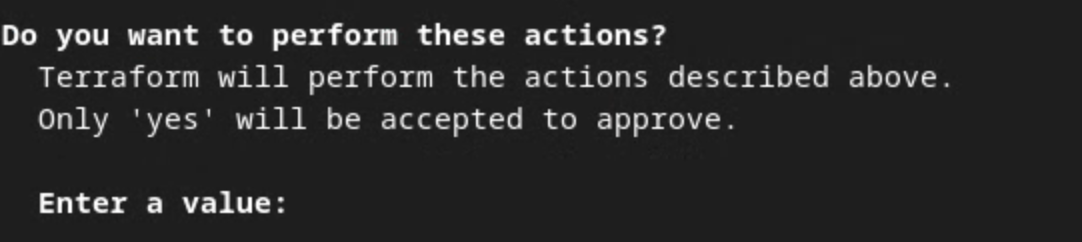
Quando terraform apply terminar, os seguintes endpoints para createJob e getJob serão retornados. O frontend_api_id que você precisa atualizar no Postman na seção 1.9 também é retornado.

4. Criação de entrada de serviço de agregação
Crie os relatórios AVRO para lote no serviço de agregação.
Etapa 4: Criação de entrada do serviço de agregação: crie os relatórios do serviço de agregação que são agrupados para o serviço de agregação.
Etapa 4.1. Acionar relatório
Etapa 4.2. Coletar relatórios agregáveis
Etapa 4.3. Converter relatórios para AVRO
Etapa 4.4. Criar o AVRO do domínio de saída
4.1. Relatório de acionadores
Acesse o site da demonstração do Sandbox de privacidade. Isso aciona um relatório de agregação particular. Confira o relatório em chrome://private-aggregation-internals.
Se a denúncia estiver em Pendente, selecione-a e clique em Enviar relatórios selecionados.
4.2. Coletar relatórios agregáveis
Colete relatórios agregáveis dos endpoints .well-known da API correspondente.
- Private Aggregation
[reporting-origin] /.well-known/private-aggregation/report-shared-storage - Relatórios de atribuição: relatório de resumo
[reporting-origin] /.well-known/attribution-reporting/report-aggregate-attribution
Neste codelab, você vai realizar a coleta de relatórios manualmente. Na produção, as adtechs precisam coletar e converter os relatórios de forma programática.
Em chrome://private-aggregation-internals, copie o "Corpo do relatório" recebido no endpoint [reporting-origin]/.well-known/private-aggregation/report-shared-storage.
Verifique se, no Corpo do relatório, o aggregation_coordinator_origin contém https://publickeyservice.msmt.aws.privacysandboxservices.com, o que significa que o relatório é agregável pela AWS.
Coloque o JSON "Corpo do relatório" em um arquivo JSON. Neste exemplo, use o vim. Mas você pode usar qualquer editor de texto.
vim report.json
Cole o relatório em report.json e salve o arquivo.
4.3. Converter relatórios para AVRO
Os relatórios recebidos dos endpoints .well-known estão no formato JSON e precisam ser convertidos no formato de relatório AVRO. Depois de ter o relatório JSON, navegue até a pasta de relatórios e use aggregatable_report_converter.jar para ajudar a criar o relatório agregável de depuração. Isso cria um relatório agregável chamado report.avro no seu diretório atual.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
4.4. Criar o AVRO do domínio de saída
Para criar o arquivo output_domain.avro, você precisa das chaves do bucket que podem ser recuperadas dos relatórios.
As chaves de bucket são projetadas pela adtech. No entanto, neste caso, a demonstração do Sandbox de privacidade do site cria as chaves de bucket. Como a agregação privada para esse site está no modo de depuração, use o debug_cleartext_payload do Corpo do relatório para acessar a chave do bucket.
Copie o debug_cleartext_payload do corpo do relatório.
Abra goo.gle/ags-payload-decoder e cole o debug_cleartext_payload na caixa INPUT e clique em Decode.
A página retorna o valor decimal da chave do bucket. Confira a seguir um exemplo de chave de bucket.
Agora que temos a chave do bucket, crie o output_domain.avro. Substitua
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
O script cria o arquivo output_domain.avro na sua pasta atual.
4.5. Mover relatórios para o bucket da AWS
Depois de criar os relatórios do AVRO (seção 3.2.3) e o domínio de saída (seção 3.2.4), mova os relatórios e o domínio de saída para os buckets do S3 de relatórios.
Se você tiver a configuração da AWS CLI no seu ambiente local, use os comandos a seguir para copiar os relatórios para o bucket e a pasta de relatórios do S3 correspondentes.
aws s3 cp report.avro s3://<report_bucket_name>/<report_folder>/
aws s3 cp output_domain.avro s3://<report_bucket_name>/<output_domain_folder>/
5. Uso do serviço de agregação
A terraform apply retorna create_job_endpoint, get_job_endpoint e frontend_api_id. Copie o frontend_api_id e coloque-o na variável global frontend_api_id do Postman que você configurou na seção de pré-requisitos 1.9.
Etapa 5: Uso do serviço de agregação: use a API do serviço de agregação para criar relatórios de resumo e analisar esses relatórios.
Etapa 5.1. Como usar o endpoint createJob para processar em lote
Etapa 5.2. Como usar o endpoint getJob para recuperar o status do lote
Etapa 5.3. Como analisar o relatório resumido
5.1. Como usar o endpoint createJob para lotes
No Postman, abra a coleção Privacy Sandbox e selecione createJob.
Selecione "Body" e "raw" para colocar o payload da solicitação.
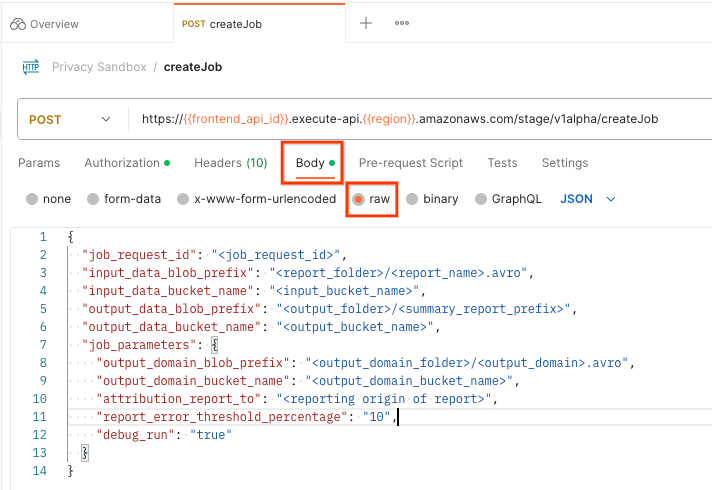
O esquema de payload createJob está disponível no github e é semelhante ao seguinte. Substitua <> pelos campos adequados.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
], // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Ao clicar em Enviar, o job é criado com o job_request_id. Você vai receber uma resposta HTTP 202 quando a solicitação for aceita pelo serviço de agregação. Outros códigos de retorno possíveis podem ser encontrados em Códigos de resposta HTTP.

5.2. Como usar o endpoint getJob para recuperar o status do lote
Para verificar o status da solicitação de job, use o endpoint getJob. Selecione getJob na coleção Sandbox de privacidade.
Em Params, atualize o valor job_request_id para o job_request_id enviado na solicitação createJob.
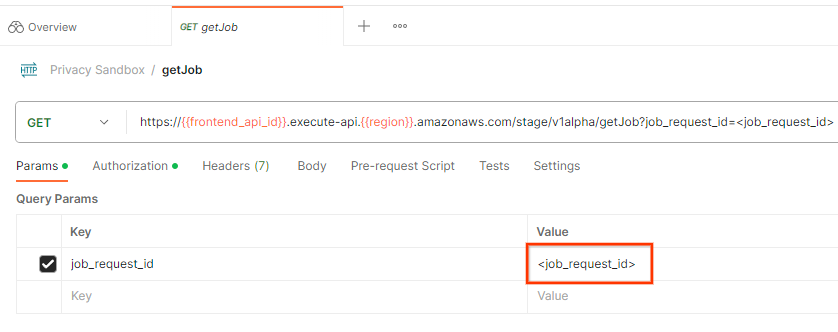
O resultado da getJob deve retornar o status da solicitação de job com um status HTTP de 200. O corpo da solicitação contém as informações necessárias, como job_status, return_message e error_messages (se o job tiver falhado).
Como o site de relatórios do relatório de demonstração gerado é diferente do site integrado no seu AWS ID, você pode receber uma resposta com PRIVACY_BUDGET_AUTHORIZATION_ERROR return_code. Isso é normal, já que o site de origem dos relatórios não corresponde ao site de relatórios integrado ao AWS ID.
{
"job_status": "FINISHED",
"request_received_at": "2023-12-07T22:50:58.830956Z",
"request_updated_at": "2023-12-07T22:51:10.526326456Z",
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"postback_url": "",
"result_info": {
"return_code": "PRIVACY_BUDGET_AUTHORIZATION_ERROR",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-12-07T22:51:10.517730898Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"attribution_report_to": "https://privacy-sandbox-demos-dsp.dev",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
},
"request_processing_started_at": "2023-12-07T22:51:06.034472697Z"
}
5.3. Como analisar o relatório resumido
Depois de receber o relatório de resumo no bucket do S3 de saída, você pode fazer o download dele no seu ambiente local. Os relatórios de resumo estão no formato AVRO e podem ser convertidos de volta em JSON. Você pode usar aggregatable_report_converter.jar para ler seu relatório usando o comando a seguir.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
Isso retorna um JSON de valores agregados de cada chave de bucket que se parece com a imagem a seguir.

Se a solicitação createJob incluir debug_run como true, você poderá receber o relatório de resumo na pasta de depuração localizada no output_data_blob_prefix. O relatório está no formato AVRO e pode ser convertido em JSON usando o comando anterior.
O relatório contém a chave do bucket, a métrica sem ruído e o ruído adicionado à métrica sem ruído para formar o relatório resumido. O relatório é semelhante à imagem a seguir.

As anotações também contêm in_reports e in_domain, o que significa:
- in_reports: a chave do bucket está disponível nos relatórios agregáveis.
- in_domain: a chave do bucket está disponível no arquivo AVRO output_domain.