
1. 기본 요건
이 Codelab을 수행하려면 몇 가지 기본 요건이 필요합니다. 각 요구사항은 '로컬 테스트'에 필요한지에 따라 표시됩니다. 또는 "집계 서비스".
1.1. 로컬 테스트 도구 다운로드 (로컬 테스트)
로컬 테스트를 사용하려면 로컬 테스트 도구를 다운로드해야 합니다. 이 도구는 암호화되지 않은 디버그 보고서에서 요약 보고서를 생성합니다.
로컬 테스트 도구는 GitHub의 Lambda JAR 보관 파일에서 다운로드할 수 있습니다. 이름은 LocalTestingTool_{version}.jar로 지정되어야 합니다.
1.2. JAVA JRE가 설치되어 있는지 확인하세요 (Local Testing and Aggregation Service).
'Terminal'을 엽니다. java --version를 사용하여 머신에 Java 또는 openJDK가 설치되어 있는지 확인합니다.

설치되지 않은 경우 Java 사이트 또는 openJDK 사이트에서 다운로드하여 설치할 수 있습니다.
1.3. 집계 가능한 보고서 변환기 다운로드 (로컬 테스트 및 집계 서비스)
개인 정보 보호 샌드박스 데모 GitHub 저장소에서 집계 가능한 보고서 변환기의 사본을 다운로드할 수 있습니다.
1.4. 광고 개인 정보 보호 API 사용 설정 (로컬 테스트 및 집계 서비스)
브라우저에서 chrome://settings/adPrivacy으로 이동하여 모든 Ad Privacy API를 사용 설정합니다.
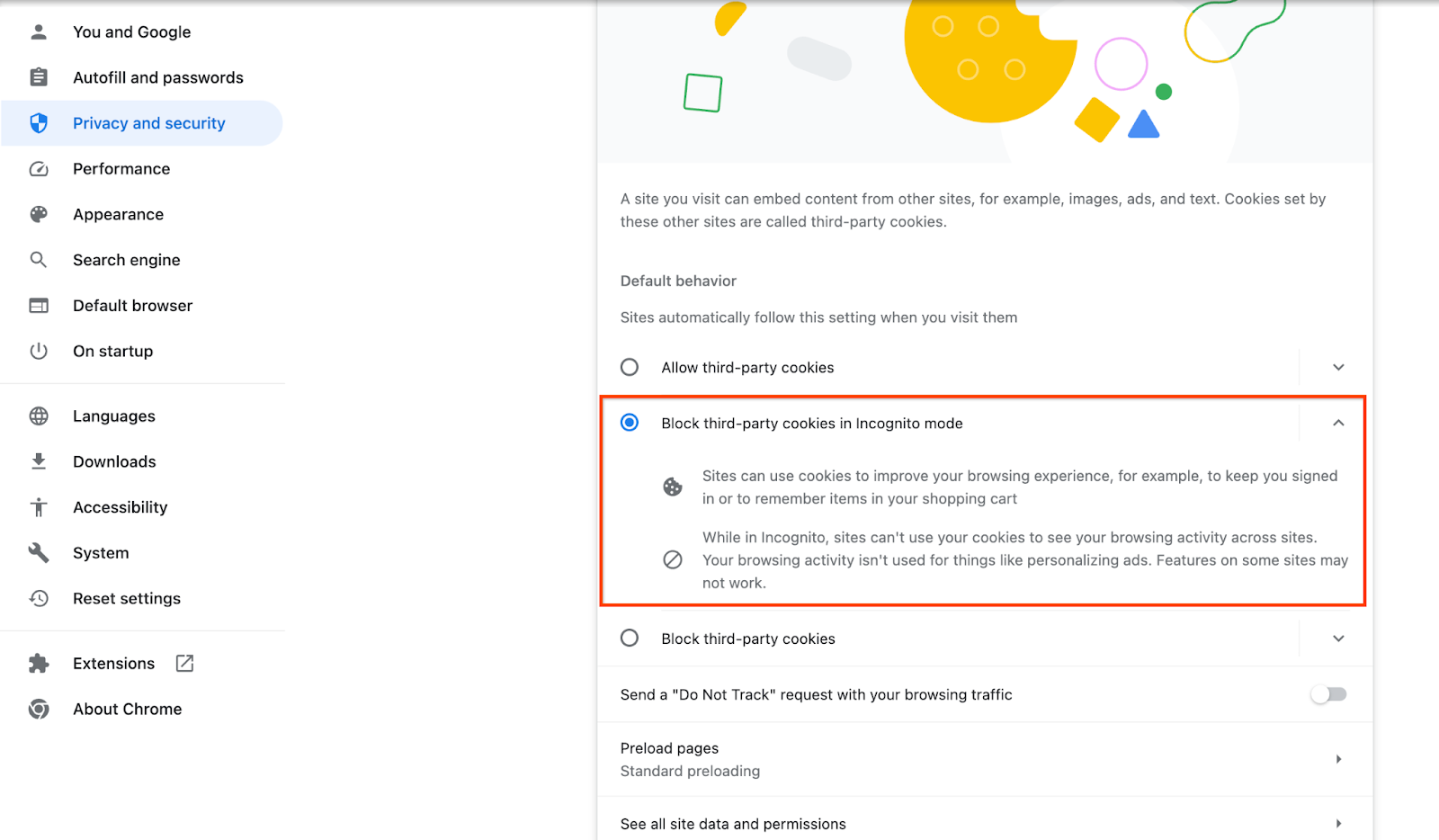
서드 파티 쿠키가 사용 설정되어 있는지 확인합니다.
브라우저에서 chrome://settings/cookies 페이지로 이동하여 '시크릿 모드에서 서드 파티 쿠키 차단'을 선택합니다.
1.5. 웹 및 Android 등록 (집계 서비스)
프로덕션 환경에서 개인 정보 보호 샌드박스 API를 사용하려면 Chrome 및 Android 모두에 대해 등록 및 증명을 완료해야 합니다.
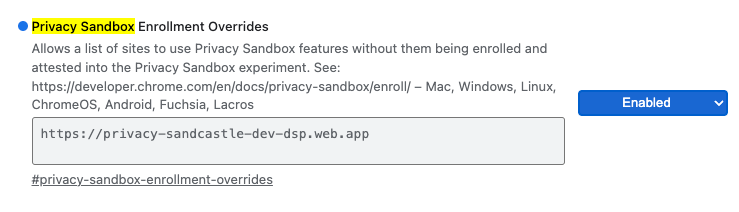
로컬 테스트의 경우 Chrome 플래그 및 CLI 스위치를 사용하여 등록을 사용 중지할 수 있습니다.
데모에 Chrome 플래그를 사용하려면 chrome://flags/#privacy-sandbox-enrollment-overrides로 이동하여 사이트로 재정의를 업데이트하세요. 데모 사이트를 사용하는 경우 업데이트할 필요가 없습니다.
1.6. 집계 서비스 온보딩 (집계 서비스)
집계 서비스를 이용하려면 코디네이터의 온보딩이 필요합니다. 보고 사이트 주소, AWS 계정 ID, 기타 정보를 제공하여 집계 서비스 온보딩 양식을 작성합니다.
1.7. 클라우드 제공업체 (집계 서비스)
집계 서비스를 사용하려면 클라우드 환경을 사용하는 신뢰할 수 있는 실행 환경을 사용해야 합니다. 집계 서비스는 Amazon Web Services (AWS) 및 Google Cloud (GCP)에서 지원됩니다. 이 Codelab에서는 AWS 통합만 다룹니다.
AWS는 Nitro 엔클레이브라는 신뢰할 수 있는 실행 환경을 제공합니다. AWS 계정이 있는지 확인하고 AWS CLI 설치 및 업데이트 안내에 따라 AWS CLI 환경을 설정하세요.
AWS CLI를 처음 사용하는 경우 CLI 구성 안내를 사용하여 AWS CLI를 구성할 수 있습니다.
1.7.1. AWS S3 버킷 만들기
Terraform 상태를 저장할 AWS S3 버킷과 보고서 및 요약 보고서를 저장할 또 다른 S3 버킷을 생성합니다. 제공된 CLI 명령어를 사용할 수 있습니다. <>의 필드를 적절한 변수로 바꿉니다.
aws s3api create-bucket --bucket <tf_bucket_name> --region us-east-1
aws s3api create-bucket --bucket <report_bucket_name> --region us-east-1
1.7.2. 사용자 액세스 키 만들기
AWS 가이드를 사용하여 사용자 액세스 키를 만듭니다. AWS에서 생성된 createJob 및 getJob API 엔드포인트를 호출하는 데 사용됩니다.
1.7.3. AWS 사용자 및 그룹 권한
AWS에 집계 서비스를 배포하려면 서비스를 배포하는 데 사용된 사용자에게 특정 권한을 제공해야 합니다. 이 Codelab에서는 배포 시 전체 권한을 보장하기 위해 사용자에게 관리자 액세스 권한이 있는지 확인합니다.
1.8. Terraform (집계 서비스)
이 Codelab에서는 Terraform을 사용하여 집계 서비스를 배포합니다. Terraform 바이너리가 로컬 환경에 설치되어 있는지 확인합니다.
Terraform 바이너리를 로컬 환경에 다운로드합니다.
Terraform 바이너리가 다운로드되면 파일을 추출하고 Terraform 바이너리를 /usr/local/bin로 이동합니다.
cp <directory>/terraform /usr/local/bin
classpath에서 Terraform을 사용할 수 있는지 확인합니다.
terraform -v
1.9. Postman (집계 서비스 AWS용)
이 Codelab에서는 요청 관리에 Postman을 사용합니다.
'작업공간'으로 이동하여 작업공간을 만듭니다. 상단 탐색 항목을 열고 '작업공간 만들기'를 선택합니다.
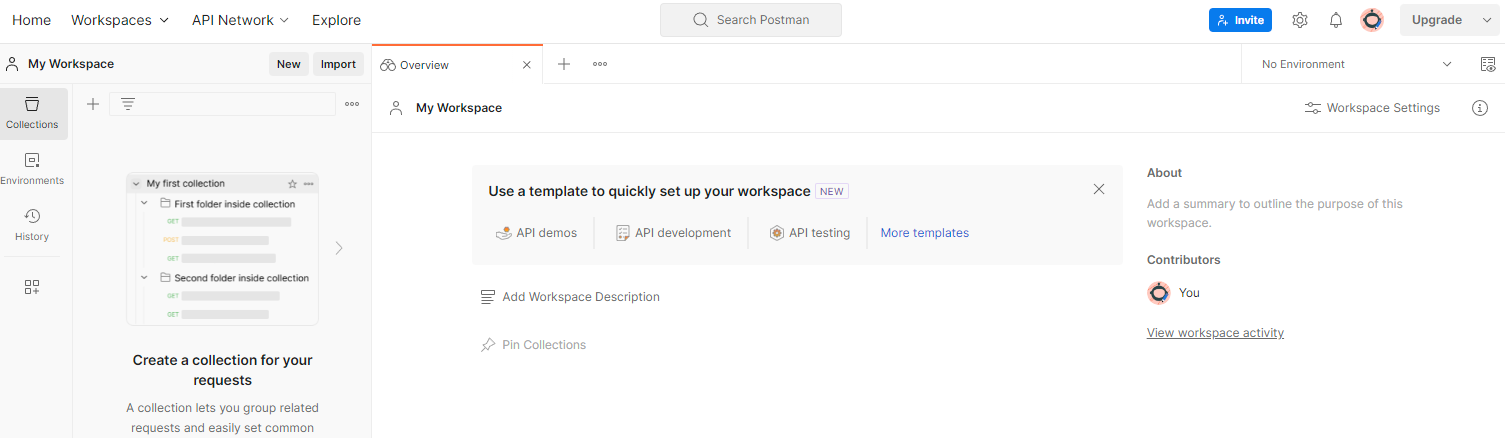
'빈 작업공간'을 선택하고 다음을 클릭하여 이름을 '개인 정보 보호 샌드박스'로 지정합니다. '개인'을 선택합니다. '만들기'를 클릭합니다.
사전 구성된 작업공간 JSON 구성 및 전역 환경 파일을 다운로드합니다.
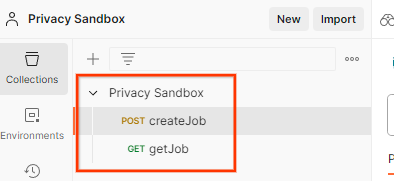
JSON 파일을 '내 작업공간'으로 가져옵니다. 'Import' 버튼을 클릭합니다.

이렇게 하면 createJob 및 getJob HTTP 요청과 함께 개인 정보 보호 샌드박스 컬렉션이 생성됩니다.
AWS '액세스 키' 업데이트 '비밀번호 키' '환경 개요'를 통해 확인할 수 있습니다.
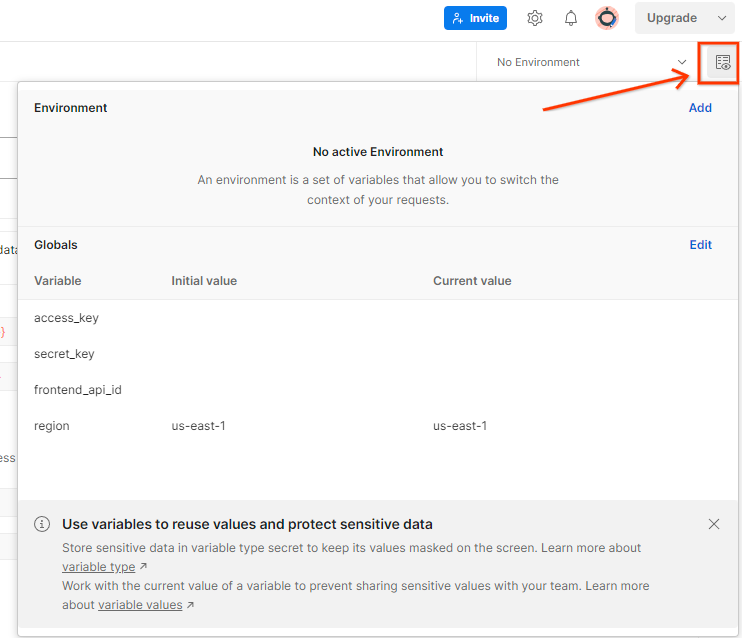
'수정'을 클릭합니다. '현재 값'을 (두 'access_key' 모두) 및 'secret_key'. frontend_api_id는 이 문서의 섹션 3.1.4에 제공됩니다. 그리고 us-east-1 리전을 사용하는 것이 좋습니다. 하지만 다른 리전에 배포하려면 출시된 AMI를 계정에 복사하거나 제공된 스크립트를 사용하여 자체 빌드를 수행해야 합니다.

2. 로컬 테스트 Codelab
컴퓨터에서 로컬 테스트 도구를 사용하여 집계를 수행하고 암호화되지 않은 디버그 보고서를 사용하여 요약 보고서를 생성할 수 있습니다.
Codelab 단계
2.1단계: 보고서 트리거: 보고서를 수집할 수 있도록 비공개 집계 보고를 트리거합니다.
2.2단계: 디버그 집계 가능한 보고서 만들기: 수집된 JSON 보고서를 AVRO 형식의 보고서로 변환합니다.
이 단계는 광고 기술이 API 보고 엔드포인트에서 보고서를 수집하고 JSON 보고서를 AVRO 형식의 보고서로 변환하는 경우와 유사합니다.
2.3단계: 디버그 보고서에서 버킷 키 파싱: 버킷 키는 광고 기술에서 설계합니다. 이 Codelab에서는 버킷이 사전 정의되어 있으므로 제공된 대로 버킷 키를 검색합니다.
2.4단계: 출력 도메인 AVRO 만들기: 버킷 키가 검색되면 출력 도메인 AVRO 파일을 만듭니다.
2.5단계: 로컬 테스트 도구를 사용하여 요약 보고서 만들기: 로컬 테스트 도구를 사용하여 로컬 환경에서 요약 보고서를 만들 수 있습니다.
2.6단계. 요약 보고서 검토: 로컬 테스트 도구에서 생성한 요약 보고서를 검토합니다.
2.1. 트리거 보고서
개인 정보 보호 샌드박스 데모 사이트로 이동합니다. 이렇게 하면 비공개 집계 보고서가 트리거됩니다. chrome://private-aggregation-internals에서 보고서를 볼 수 있습니다.
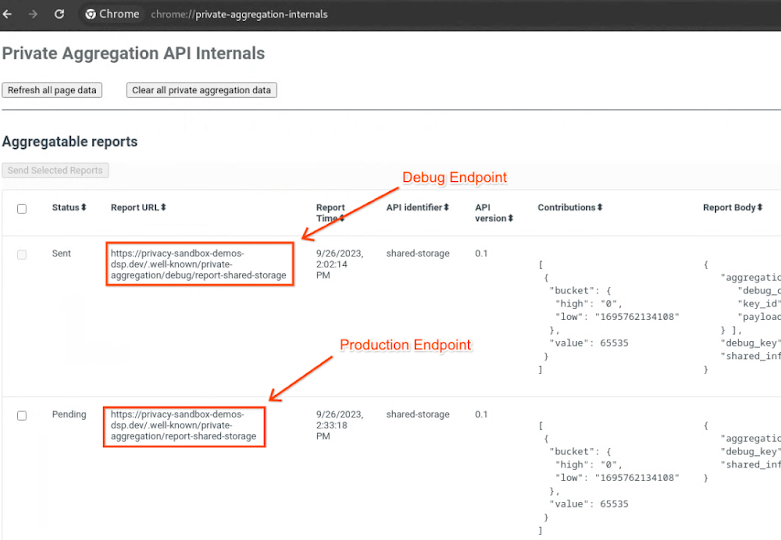
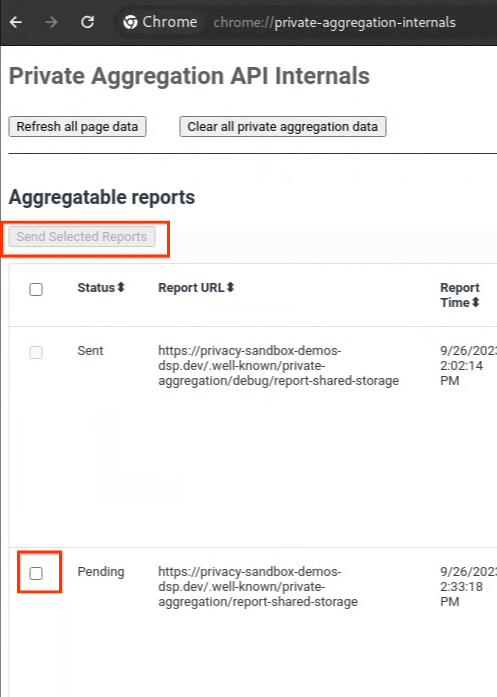
보고서가 '대기 중' 상태인 경우 보고서를 선택한 다음 'Send Selected Reports'를 클릭합니다.
2.2. 디버그 집계 가능한 보고서 만들기
chrome://private-aggregation-internals에서 '보고서 본문'을 복사합니다. [reporting-origin]/.well-known/private-aggregation/report-shared-storage 엔드포인트에서 수신됩니다.
'Report Body(보고서 본문)'에서 aggregation_coordinator_origin에 https://publickeyservice.msmt.aws.privacysandboxservices.com이 포함되어 있는지 확인합니다. 이는 보고서가 AWS 집계 가능한 보고서임을 의미합니다.
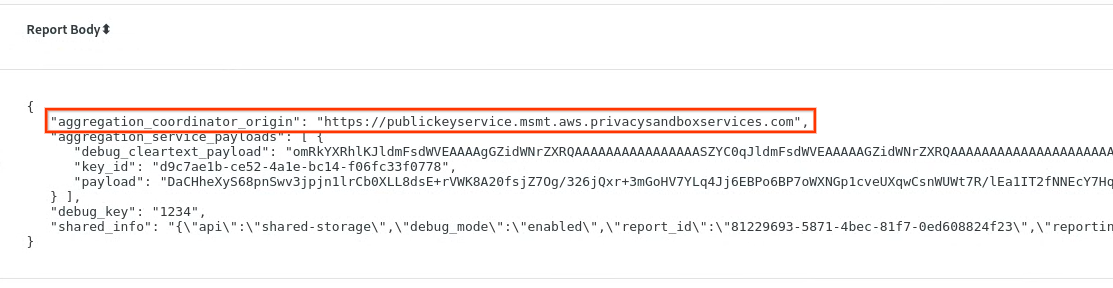
JSON '보고서 본문'을 배치합니다. JSON 파일 형식으로 저장할 수 있습니다 이 예에서는 vim을 사용합니다. 그러나 텍스트 편집기는 원하는 대로 사용할 수 있습니다.
vim report.json
보고서를 report.json에 붙여넣고 파일을 저장합니다.

그런 다음 보고서 폴더로 이동하고 aggregatable_report_converter.jar를 사용하여 집계 가능한 디버그 보고서를 만듭니다. 이렇게 하면 현재 디렉터리에 report.avro라는 집계 가능한 보고서가 생성됩니다.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. 디버그 보고서에서 버킷 키 파싱
집계 서비스에는 일괄 처리 시 두 개의 파일이 필요합니다. 집계 가능한 보고서 및 출력 도메인 파일입니다. 출력 도메인 파일에는 집계 가능한 보고서에서 검색하려는 키가 포함되어 있습니다. output_domain.avro 파일을 만들려면 보고서에서 가져올 수 있는 버킷 키가 필요합니다.
버킷 키는 API 호출자가 설계하며 demo에는 사전 구성된 예시 버킷 키가 포함되어 있습니다. 데모에서 비공개 집계의 디버그 모드를 사용 설정했으므로 'Report Body'(보고서 본문)에서 디버그 일반 텍스트 페이로드를 파싱할 수 있습니다. 버킷 키를 검색합니다. 하지만 이 경우에는 개인 정보 보호 샌드박스 데모 사이트에서 버킷 키를 만듭니다. 이 사이트의 비공개 집계는 디버그 모드이므로 '보고서 본문'의 debug_cleartext_payload를 사용할 수 있습니다. 버킷 키를 가져옵니다
보고서 본문에서 debug_cleartext_payload를 복사합니다.

비공개 집계용 페이로드 디코더 디버그 도구를 열고 debug_cleartext_payload을(를) 'INPUT'에 붙여넣습니다. 상자에서 'Decode'를 클릭합니다.
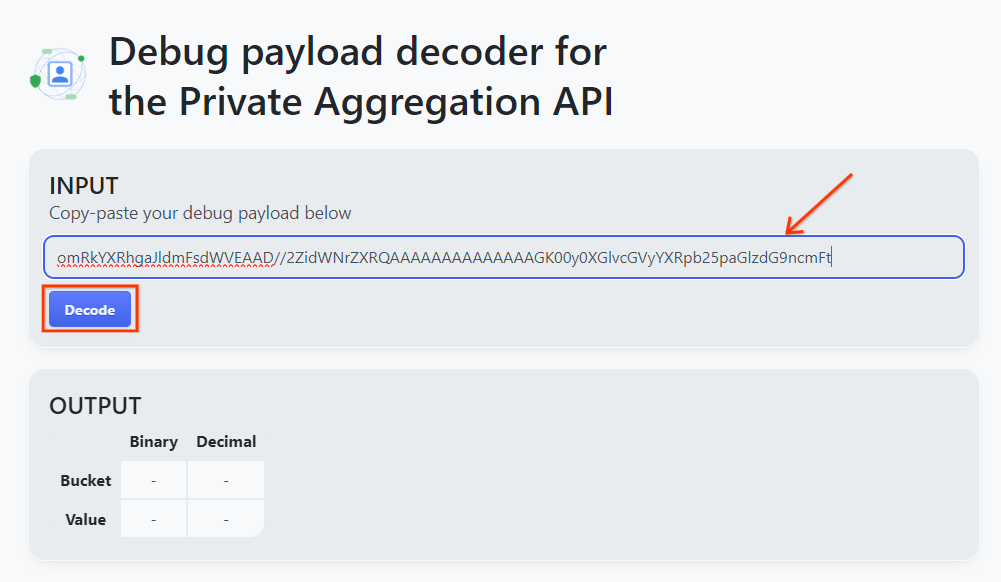
이 페이지는 버킷 키의 십진수 값을 반환합니다. 다음은 샘플 버킷 키입니다.
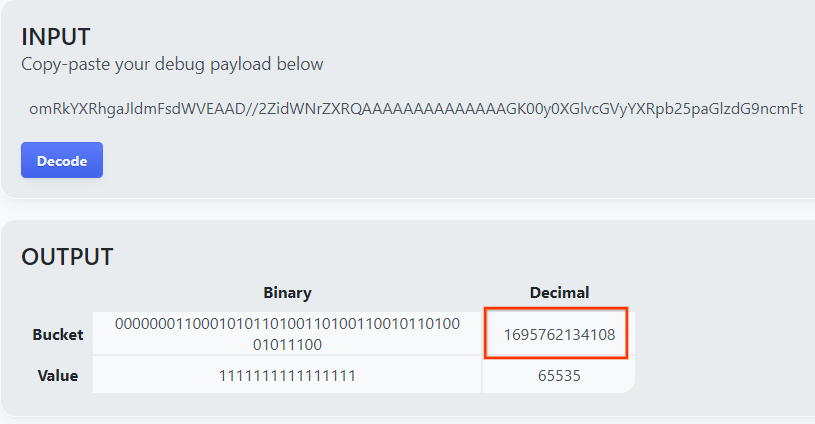
2.4. 출력 도메인 AVRO 만들기
이제 버킷 키가 있으므로 버킷 키의 십진수 값을 복사합니다. 계속해서 버킷 키를 사용하여 output_domain.avro 만들기를 진행합니다.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
이 스크립트는 현재 폴더에 output_domain.avro 파일을 생성합니다.
2.5. 로컬 테스트 도구를 사용하여 요약 보고서 만들기
섹션 1.1에서 다운로드한 LocalTestingTool_{version}.jar를 사용하여 요약 보고서를 만들어 보겠습니다. 다음 명령어를 사용합니다. LocalTestingTool_{version}.jar을 LocalTestingTool용으로 다운로드한 버전으로 바꿔야 합니다.
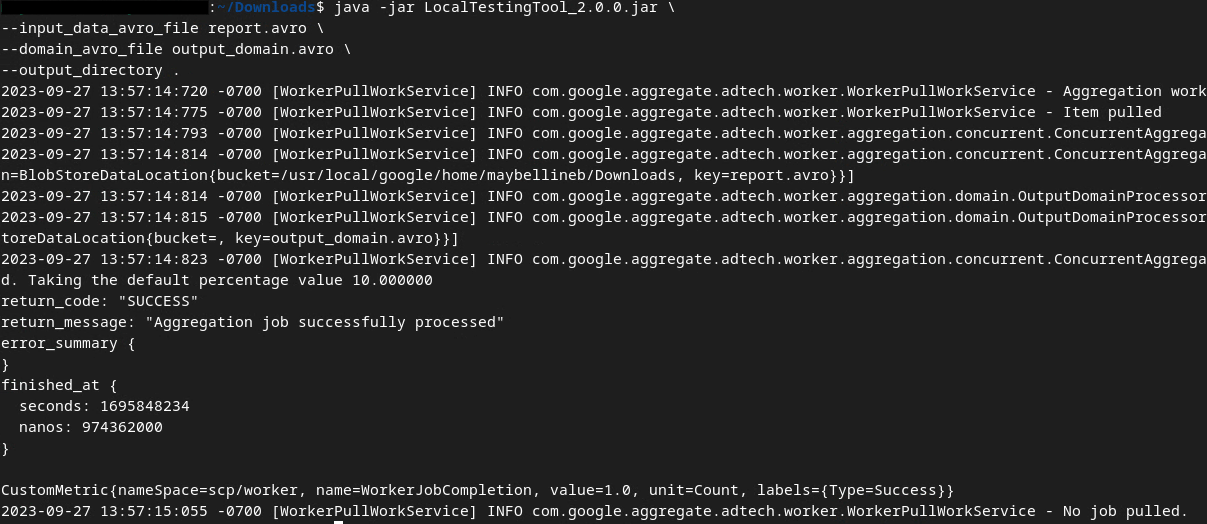
다음 명령어를 실행하여 로컬 개발 환경에서 요약 보고서를 생성합니다.
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
명령어가 실행되면 다음 이미지와 비슷한 화면이 표시됩니다. 이 작업이 완료되면 output.avro 보고서가 생성됩니다.
2.6. 요약 보고서 검토
생성되는 요약 보고서는 AVRO 형식입니다. 이 파일을 읽으려면 AVRO를 JSON 형식으로 변환해야 합니다. 광고 기술은 AVRO 보고서를 다시 JSON으로 변환하도록 코딩하는 것이 이상적입니다.
이 Codelab에서는 제공된 aggregatable_report_converter.jar 도구를 사용하여 AVRO 보고서를 다시 JSON으로 변환합니다.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
그러면 다음 이미지와 유사한 보고서가 반환됩니다. 동일한 디렉터리에 output.json 보고서가 함께 생성됩니다.

원하는 편집기에서 JSON 파일을 열어 요약 보고서를 검토합니다.
3. 집계 서비스 배포
집계 서비스를 배포하려면 다음 단계를 따르세요.
3단계: 집계 서비스 배포: AWS에서 집계 서비스 배포
3.1단계. 집계 서비스 저장소 클론
3.2단계: 사전 빌드된 종속 항목 다운로드
3.3단계. 개발 환경을 만듭니다.
3.4단계. 집계 서비스 배포
3.1. 집계 서비스 저장소 클론
로컬 환경에서 집계 서비스 GitHub 저장소를 클론합니다.
git clone https://github.com/privacysandbox/aggregation-service.git
3.2. 사전 빌드된 종속 항목 다운로드
집계 서비스 저장소를 클론한 후에는 저장소의 Terraform 폴더와 해당 클라우드 폴더로 이동합니다. cloud_provider가 AWS인 경우
cd <repository_root>/terraform/aws
download_prebuilt_dependencies.sh를 실행합니다.
bash download_prebuilt_dependencies.sh
3.3. 개발 환경 만들기
dev라는 폴더를 만듭니다.
mkdir dev
demo 폴더 콘텐츠를 dev 폴더에 복사합니다.
cp -R demo/* dev
dev 폴더로 이동합니다.
cd dev
main.tf 파일을 업데이트하고 i 키를 눌러 input 파일을 수정합니다.
vim main.tf
#을 삭제하고 버킷과 키 이름을 업데이트하여 빨간색 상자의 코드의 주석 처리를 삭제합니다.
AWS main.tf:
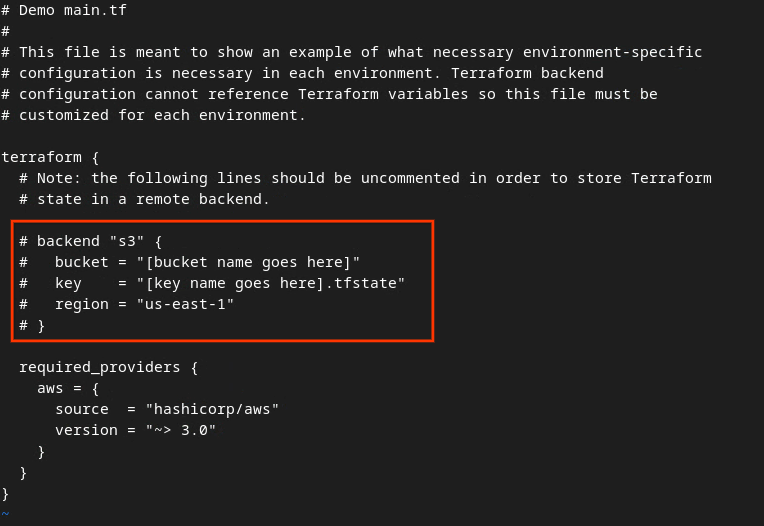
주석 처리되지 않은 코드는 다음과 같이 표시됩니다.
backend "s3" {
bucket = "<tf_state_bucket_name>"
key = "<environment_name>.tfstate"
region = "us-east-1"
}
업데이트가 완료되면 업데이트를 저장하고 esc -> 키를 눌러 편집기를 종료합니다. :wq!입니다. 이렇게 하면 main.tf에 업데이트가 저장됩니다.
그런 다음 example.auto.tfvars의 이름을 dev.auto.tfvars로 바꿉니다.
mv example.auto.tfvars dev.auto.tfvars
dev.auto.tfvars를 업데이트하고 i 키를 눌러 input를 입력합니다.
vim dev.auto.tfvars
이미지 다음 빨간색 상자의 필드를 집계 서비스 온보딩, 환경 및 알림 이메일 중에 제공되는 올바른 AWS ARN 매개변수로 업데이트합니다.
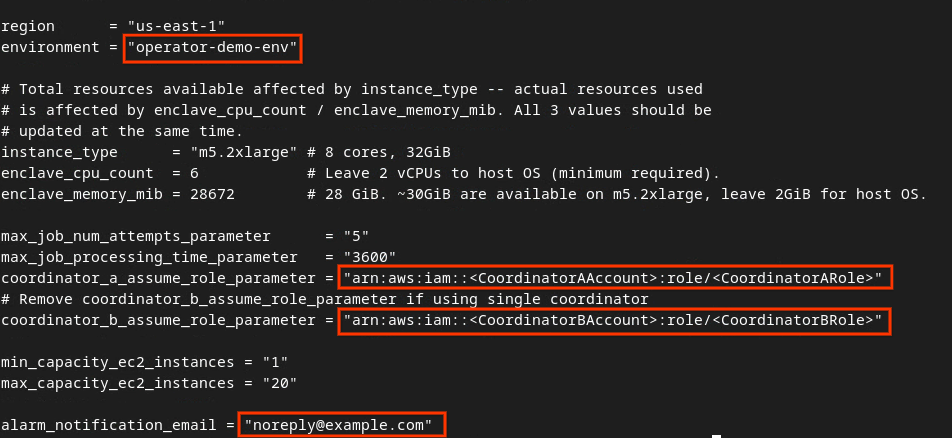
업데이트가 완료되면 esc 키를 누릅니다. -> :wq!입니다. 이렇게 하면 dev.auto.tfvars 파일이 저장되고 다음 이미지와 같이 표시됩니다.
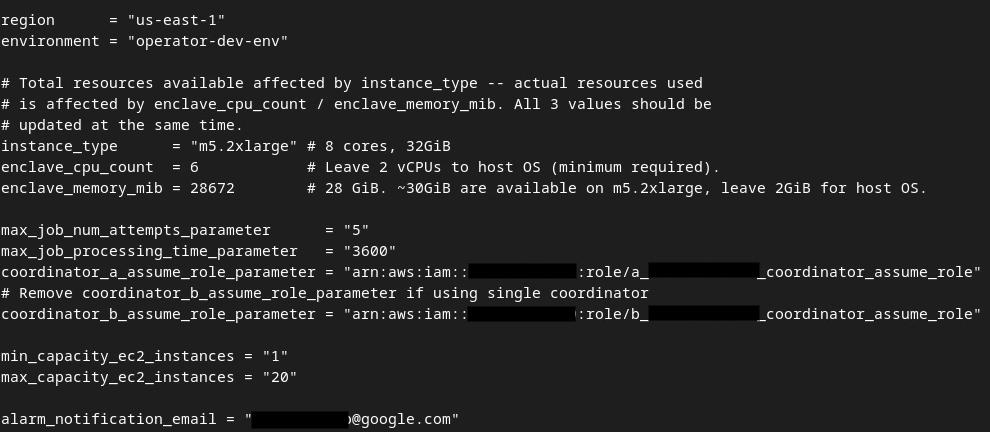
3.4. 집계 서비스 배포
집계 서비스를 배포하려면 동일한 폴더
terraform init
그러면 다음 이미지와 비슷한 결과가 반환됩니다.
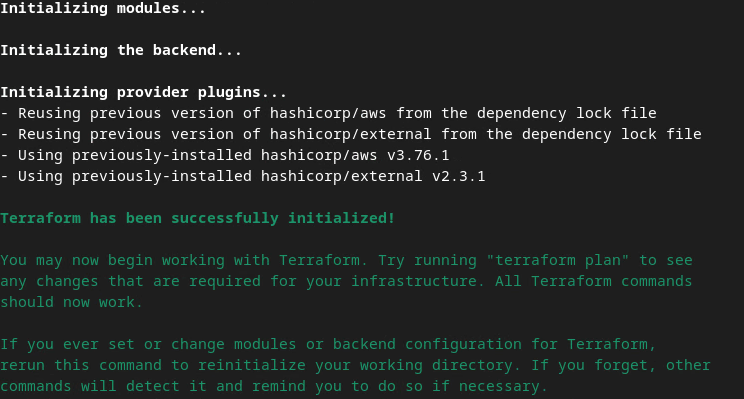
Terraform이 초기화되면 Terraform 실행 계획을 생성합니다. 여기서 추가할 리소스의 수와 다음 이미지와 비슷한 기타 추가 정보를 반환합니다.
terraform plan
다음 '계획'에서 확인할 수 있습니다. 요약할 수 있습니다 새 배포인 경우 변경할 리소스 수가 0개, 폐기 시 0개가 포함된 상태로 추가될 리소스 수가 표시됩니다.
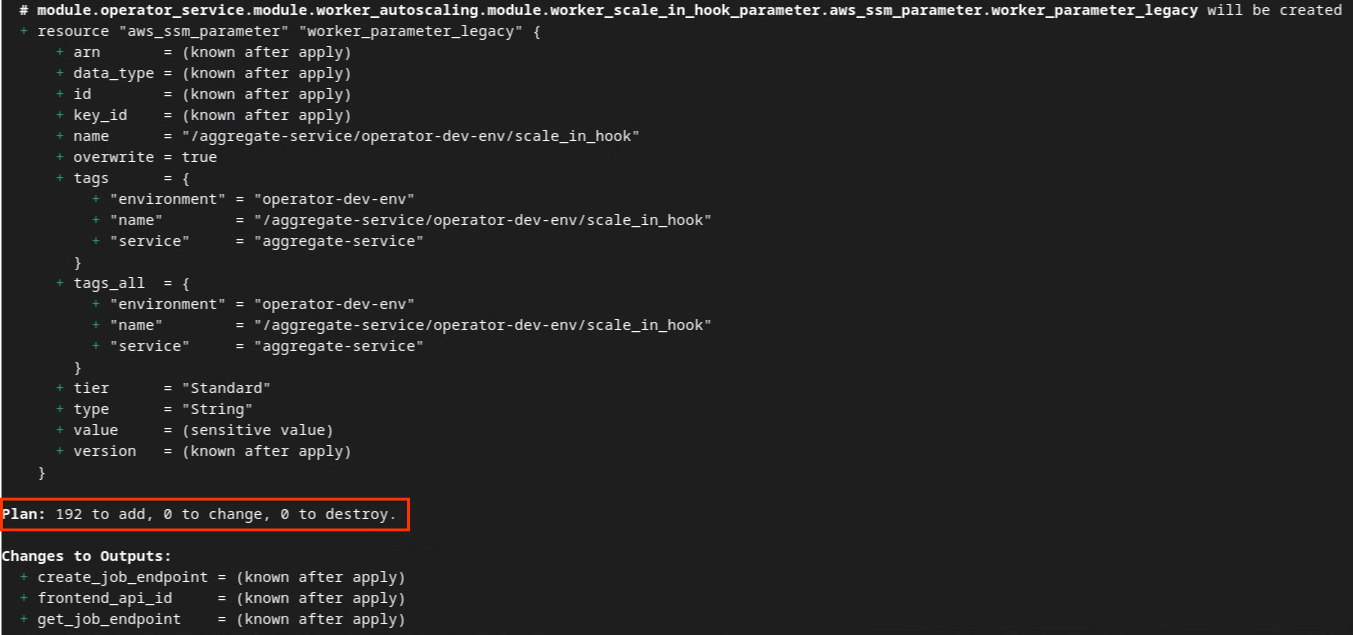
이 작업을 완료하면 Terraform 적용을 진행할 수 있습니다.
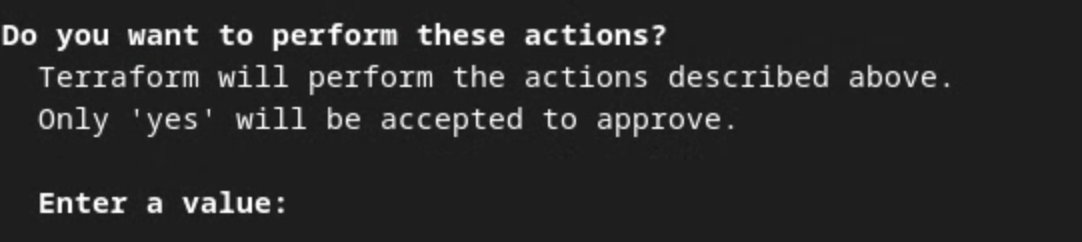
terraform apply
Terraform에서 작업을 수행할 것인지 확인하는 메시지가 표시되면 값에 yes을 입력합니다.
terraform apply가 완료되면 createJob 및 getJob의 다음 엔드포인트가 반환됩니다. 섹션 1.9의 Postman에서 업데이트해야 하는 frontend_api_id도 반환됩니다.

4. 집계 서비스 입력 생성
계속해서 집계 서비스에서 일괄 처리를 위한 AVRO 보고서 만들기를 진행합니다.
4단계: 집계 서비스 입력 생성: 집계 서비스에 대해 일괄 처리되는 집계 서비스 보고서를 생성합니다.
4.1단계. 트리거 보고서
4.2단계. 집계 가능한 보고서 수집
4.3단계. 보고서를 AVRO로 변환
4.4단계: 출력 도메인 AVRO 만들기
4.1. 트리거 보고서
개인 정보 보호 샌드박스 데모 사이트로 이동합니다. 이렇게 하면 비공개 집계 보고서가 트리거됩니다. chrome://private-aggregation-internals에서 보고서를 볼 수 있습니다.
보고서가 '대기 중' 상태인 경우 보고서를 선택한 다음 'Send Selected Reports'를 클릭합니다.
4.2. 집계 가능한 보고서 수집
해당 API의 .well-known 엔드포인트에서 집계 가능한 보고서를 수집합니다.
- 비공개 집계
[reporting-origin] /.well-known/private-aggregation/report-shared-storage - 기여도 보고서 - 요약 보고서
[reporting-origin] /.well-known/attribution-reporting/report-aggregate-attribution
이 Codelab에서는 보고서 수집을 수동으로 실행합니다. 프로덕션에서 광고 기술은 프로그래매틱 방식으로 보고서를 수집하고 변환해야 합니다.
chrome://private-aggregation-internals에서 '보고서 본문'을 복사합니다. [reporting-origin]/.well-known/private-aggregation/report-shared-storage 엔드포인트에서 수신됩니다.
'Report Body(보고서 본문)'에서 aggregation_coordinator_origin에 https://publickeyservice.msmt.aws.privacysandboxservices.com이 포함되어 있는지 확인합니다. 이는 보고서가 AWS 집계 가능한 보고서임을 의미합니다.
JSON '보고서 본문'을 배치합니다. JSON 파일 형식으로 저장할 수 있습니다 이 예에서는 vim을 사용합니다. 그러나 텍스트 편집기는 원하는 대로 사용할 수 있습니다.
vim report.json
보고서를 report.json에 붙여넣고 파일을 저장합니다.
4.3. 보고서를 AVRO로 변환
.well-known 엔드포인트에서 수신된 보고서는 JSON 형식이며 AVRO 보고서 형식으로 변환해야 합니다. JSON 보고서가 있으면 보고서 폴더로 이동하고 aggregatable_report_converter.jar를 사용하여 집계 가능한 디버그 보고서를 만듭니다. 이렇게 하면 현재 디렉터리에 report.avro라는 집계 가능한 보고서가 생성됩니다.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
4.4. 출력 도메인 AVRO 만들기
output_domain.avro 파일을 만들려면 보고서에서 가져올 수 있는 버킷 키가 필요합니다.
버킷 키는 광고 기술에서 설계합니다. 하지만 이 경우에는 개인 정보 보호 샌드박스 데모 사이트에서 버킷 키를 만듭니다. 이 사이트의 비공개 집계는 디버그 모드이므로 '보고서 본문'의 debug_cleartext_payload를 사용할 수 있습니다. 버킷 키를 가져옵니다
계속해서 보고서 본문에서 debug_cleartext_payload를 복사합니다.
goo.gle/ags-payload-decoder를 열고 debug_cleartext_payload을(를) 'INPUT'에 붙여넣습니다. 상자에서 'Decode'를 클릭합니다.
이 페이지는 버킷 키의 십진수 값을 반환합니다. 다음은 샘플 버킷 키입니다.
이제 버킷 키가 있으므로 output_domain.avro를 만듭니다.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
이 스크립트는 현재 폴더에 output_domain.avro 파일을 생성합니다.
4.5. 보고서를 AWS 버킷으로 이동
AVRO 보고서 (섹션 3.2.3)와 출력 도메인 (섹션 3.2.4)이 생성되면 보고서 및 출력 도메인을 보고 S3 버킷으로 이동합니다.
로컬 환경에 AWS CLI가 설정되어 있는 경우 다음 명령어를 사용하여 보고서를 해당 S3 버킷 및 보고서 폴더에 복사합니다.
aws s3 cp report.avro s3://<report_bucket_name>/<report_folder>/
aws s3 cp output_domain.avro s3://<report_bucket_name>/<output_domain_folder>/
5. 집계 서비스 사용량
terraform apply에서 create_job_endpoint, get_job_endpoint, frontend_api_id이 반환됩니다. frontend_api_id를 복사하여 기본 요건 섹션 1.9에서 설정한 postman 전역 변수 frontend_api_id에 배치합니다.
5단계: 집계 서비스 사용량: Aggregation Service API를 사용하여 요약 보고서를 만들고 요약 보고서를 검토합니다.
5.1단계. createJob 엔드포인트를 사용하여 일괄 처리
5.2단계. getJob 엔드포인트를 사용하여 배치 상태 검색
5.3단계. 요약 보고서 검토하기
5.1. createJob 엔드포인트를 사용하여 일괄 처리
Postman에서 'Privacy Sandbox'를 엽니다. 컬렉션을 만들고 'createJob'을 선택합니다.
'Body'를 선택합니다. 'raw'를 선택합니다. 요청 페이로드를 배치합니다.
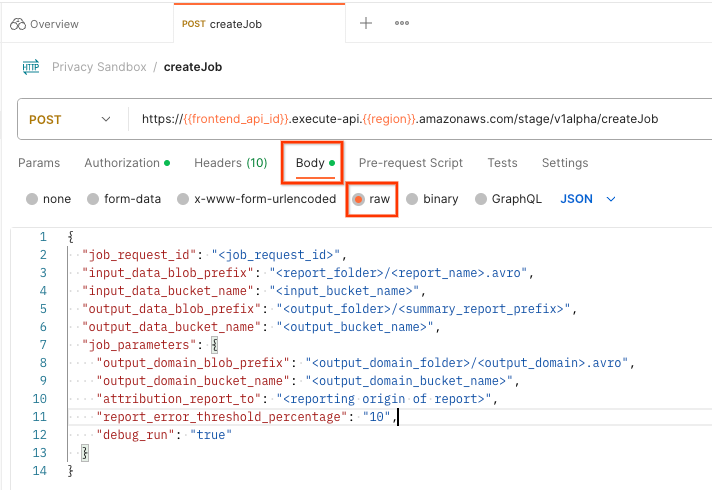
createJob 페이로드 스키마는 github에서 확인할 수 있으며 다음과 유사합니다. <>를 적절한 필드로 바꿉니다.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
'Send'를 클릭하면 job_request_id를 사용하여 작업이 생성됩니다. 집계 서비스에서 요청을 수락하면 HTTP 202 응답을 받게 됩니다. 다른 가능한 반환 코드는 HTTP 응답 코드에서 확인할 수 있습니다.

5.2. getJob 엔드포인트를 사용하여 배치 상태 검색
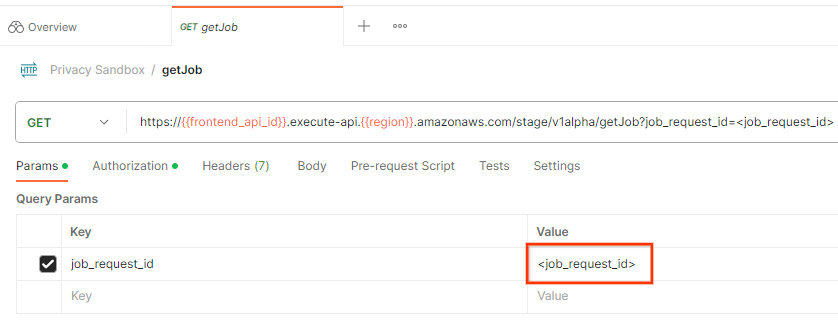
작업 요청 상태를 확인하려면 getJob 엔드포인트를 사용하면 됩니다. 'getJob'을 선택합니다. '개인 정보 보호 샌드박스'에서 컬렉션입니다.
'Params'에서 job_request_id 값을 createJob 요청에서 전송된 job_request_id로 업데이트합니다.
getJob의 결과는 HTTP 상태 200과 함께 작업 요청의 상태를 반환해야 합니다. 요청 'Body' 에는 job_status, return_message, error_messages (작업에 오류가 발생한 경우)와 같은 필수 정보가 포함됩니다.
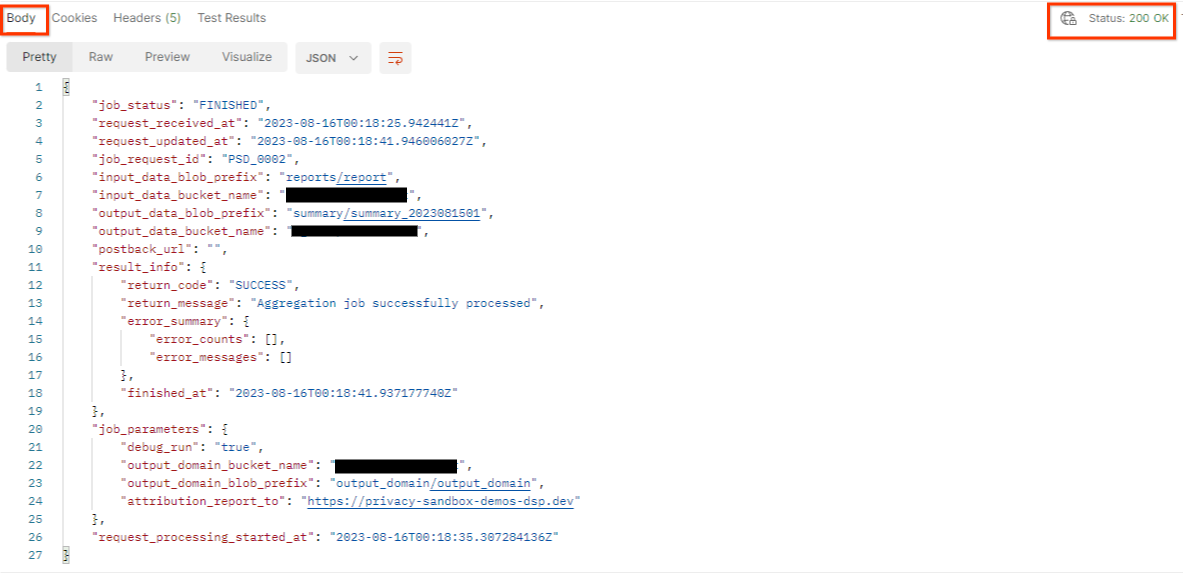
생성된 데모 보고서의 보고 사이트가 AWS ID에 온보딩된 사이트와 다르므로 PRIVACY_BUDGET_AUTHORIZATION_ERROR return_code가 포함된 응답을 받을 수 있습니다. 보고서의 데이터가 보고 출처의 사이트가 AWS ID에 온보딩된 보고 사이트와 일치하지 않습니다.
{
"job_status": "FINISHED",
"request_received_at": "2023-12-07T22:50:58.830956Z",
"request_updated_at": "2023-12-07T22:51:10.526326456Z",
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"postback_url": "",
"result_info": {
"return_code": "PRIVACY_BUDGET_AUTHORIZATION_ERROR",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-12-07T22:51:10.517730898Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"attribution_report_to": "https://privacy-sandbox-demos-dsp.dev",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
},
"request_processing_started_at": "2023-12-07T22:51:06.034472697Z"
}
5.3. 요약 보고서 검토하기
출력 S3 버킷으로 요약 보고서를 받으면 이 보고서를 로컬 환경으로 다운로드할 수 있습니다. 요약 보고서는 AVRO 형식이며 JSON으로 다시 변환할 수 있습니다. aggregatable_report_converter.jar를 사용하여 다음 명령어로 보고서를 읽을 수 있습니다.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
이렇게 하면 다음 이미지와 비슷한 각 버킷 키에서 집계된 값의 JSON이 반환됩니다.

createJob 요청에 debug_run가 true로 포함되어 있으면 output_data_blob_prefix에 있는 디버그 폴더에서 요약 보고서를 수신할 수 있습니다. 보고서는 AVRO 형식이며 이전 명령어를 사용하여 JSON으로 변환할 수 있습니다.
보고서에는 버킷 키, 노이즈가 제거된 측정항목, 노이즈가 제거된 측정항목에 추가되어 요약 보고서를 구성하는 노이즈가 포함됩니다. 보고서는 다음 이미지와 유사합니다.

또한 주석에는 다음을 의미하는 in_reports 및 in_domain가 포함됩니다.
- in_reports - 집계 가능한 보고서 내에서 버킷 키를 사용할 수 있습니다.
- in_domain - 버킷 키는 output_domain AVRO 파일에서 사용할 수 있습니다.