
Informationen zu diesem Codelab
1. Vorbereitung
Für dieses Codelab sind einige Voraussetzungen erforderlich. Jede Anforderung ist entsprechend gekennzeichnet, ob sie für „Lokale Tests“ oder „Aggregationsdienst“ erforderlich ist.
1.1. Lokales Testtool herunterladen (lokales Testen)
Für lokale Tests muss das Tool zum lokalen Testen heruntergeladen werden. Das Tool generiert Zusammenfassungsberichte aus den unverschlüsselten Debugberichten.
Das Tool für lokale Tests kann in den Lambda-JAR-Archiven auf GitHub heruntergeladen werden. Er sollte LocalTestingTool_{version}.jar heißen.
1.2. Prüfen, ob JAVA JRE installiert ist (Local Testing and Aggregation Service)
Öffnen Sie das Terminal und prüfen Sie mit java --version, ob Java oder openJDK auf Ihrem Computer installiert ist.

Wenn es nicht installiert ist, können Sie es von der Java-Website oder der OpenJDK-Website herunterladen und installieren.
1.3. Aggregierbaren Berichtskonverter (lokaler Test- und Aggregationsdienst) herunterladen
Eine Kopie des Aggregationstools für Berichte finden Sie im GitHub-Repository für Privacy Sandbox-Demos.
1.4 APIs für Datenschutz bei Werbung (lokaler Test- und Aggregationsdienst) aktivieren
Rufen Sie in Ihrem Browser chrome://settings/adPrivacy auf und aktivieren Sie alle APIs für den Datenschutz bei Werbung.
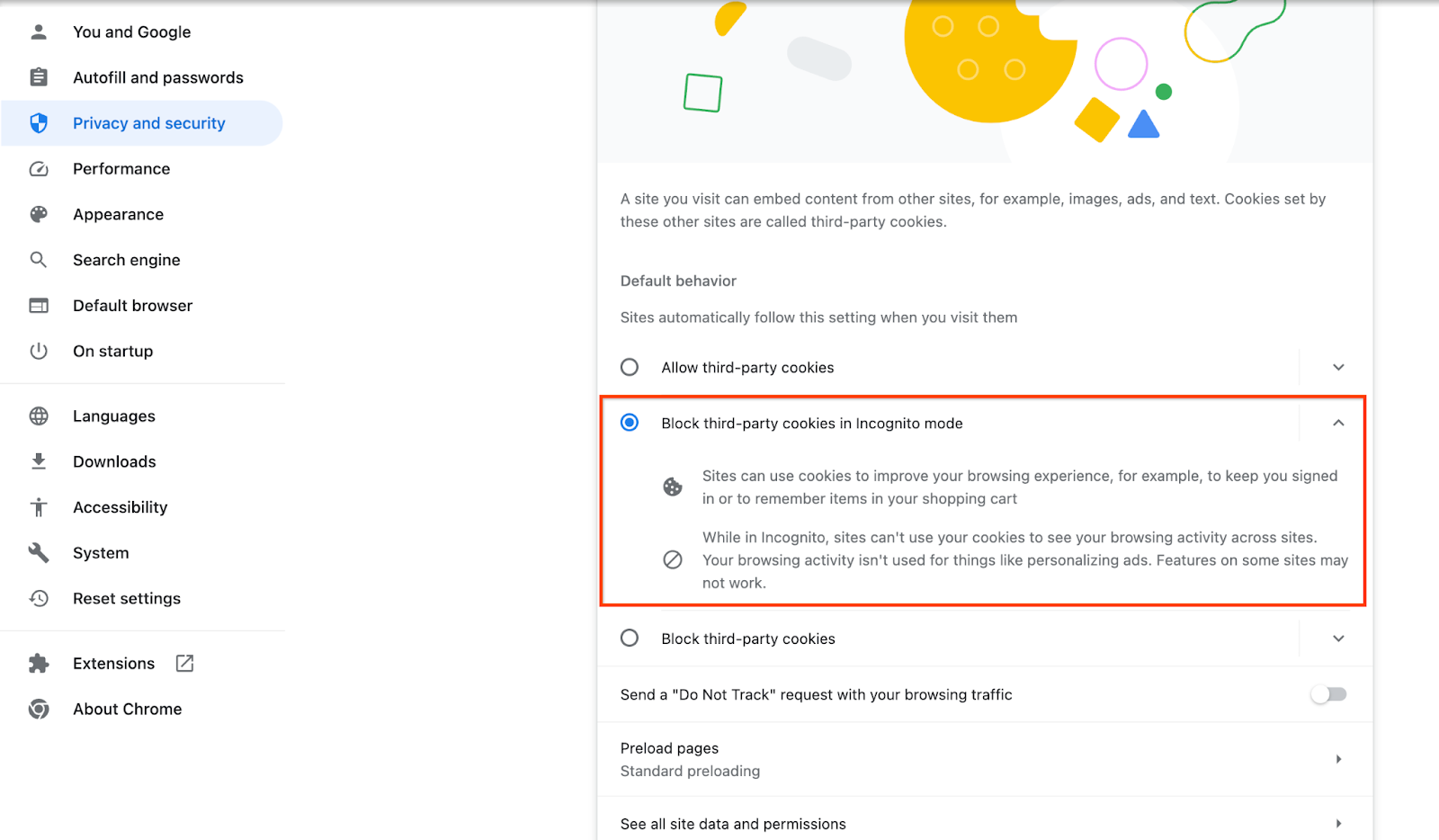
Drittanbieter-Cookies müssen aktiviert sein.
Klicken Sie in Ihrem Browser auf chrome://settings/cookies und wählen Sie Drittanbieter-Cookies im Inkognitomodus blockieren aus.
1.5 Web- und Android-Registrierung (Aggregationsdienst)
Wenn Sie Privacy Sandbox APIs in einer Produktionsumgebung verwenden möchten, müssen Sie sowohl für Chrome als auch für Android die Registrierung und Attestierung durchlaufen.
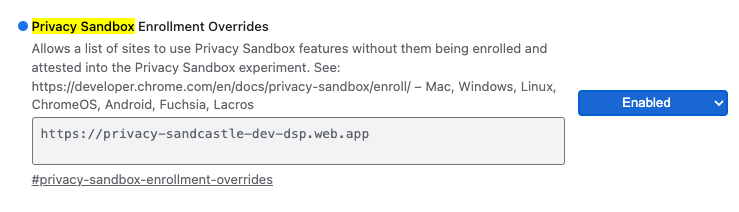
Für lokale Tests kann die Registrierung mit einem Chrome-Flag und einem Befehlszeilenschalter deaktiviert werden.
Wenn Sie das Chrome-Flag für unsere Demo verwenden möchten, rufen Sie chrome://flags/#privacy-sandbox-enrollment-overrides auf und aktualisieren Sie die Überschreibung mit Ihrer Website. Wenn Sie unsere Demo-Website verwenden, ist keine Aktualisierung erforderlich.
1.6 Onboarding des Aggregationsdienstes (Aggregation Service)
Der Aggregationsdienst erfordert ein Onboarding durch Koordinatoren, damit er verwendet werden kann. Füllen Sie das Onboarding-Formular für den Aggregationsdienst aus. Geben Sie dazu die Adresse Ihrer Website für die Berichte, Ihre AWS-Konto-ID und weitere Informationen an.
1.7. Cloud-Anbieter (Aggregationsdienst)
Für den Aggregationsdienst ist die Verwendung einer vertrauenswürdigen Ausführungsumgebung erforderlich, die eine Cloud-Umgebung nutzt. Der Aggregationsdienst wird von Amazon Web Services (AWS) und Google Cloud (GCP) unterstützt. In diesem Codelab wird nur die AWS-Integration behandelt.
AWS bietet eine vertrauenswürdige Ausführungsumgebung namens Nitro Enclaves. Sie benötigen ein AWS-Konto. Folgen Sie der Anleitung zur Installation und Aktualisierung der AWS-Befehlszeile, um Ihre AWS-Befehlszeilen-Umgebung einzurichten.
Wenn Sie die AWS-Befehlszeile noch nicht verwendet haben, können Sie sie mithilfe der Anleitung zur Befehlszeilenkonfiguration konfigurieren.
1.7.1. AWS S3-Bucket erstellen
Erstellen Sie einen AWS S3-Bucket, um den Terraform-Zustand zu speichern, und einen weiteren S3-Bucket, um Berichte und Zusammenfassungsberichte zu speichern. Sie können den angegebenen Befehlszeilenbefehl verwenden. Ersetzen Sie das Feld in <> durch die richtigen Variablen.
aws s3api create-bucket --bucket <tf_bucket_name> --region us-east-1
aws s3api create-bucket --bucket <report_bucket_name> --region us-east-1
1.7.2. Nutzerzugriffsschlüssel erstellen
Erstellen Sie Nutzerzugriffsschlüssel mithilfe des AWS-Leitfadens. Damit werden die auf AWS erstellten createJob- und getJob-API-Endpunkte aufgerufen.
1.7.3. AWS-Nutzer- und ‑Gruppenberechtigungen
Wenn Sie den Aggregations-Dienst auf AWS bereitstellen möchten, müssen Sie dem Nutzer, der für die Bereitstellung des Dienstes verwendet wird, bestimmte Berechtigungen erteilen. Für dieses Codelab muss der Nutzer Administratorzugriff haben, um volle Berechtigungen bei der Bereitstellung zu erhalten.
1.8. Terraform (Aggregationsdienst)
In diesem Codelab wird der Aggregationsdienst mit Terraform bereitgestellt. Achten Sie darauf, dass die Terraform-Binärdatei in Ihrer lokalen Umgebung installiert ist.
Laden Sie die Terraform-Binärdatei in Ihre lokale Umgebung herunter.
Nachdem die Terraform-Binärdatei heruntergeladen wurde, entpacken Sie die Datei und verschieben Sie die Terraform-Binärdatei in /usr/local/bin.
cp <directory>/terraform /usr/local/bin
Prüfen Sie, ob Terraform im Classpath verfügbar ist.
terraform -v
1.9. Postman (für Aggregationsdienst AWS)
Verwenden Sie für dieses Codelab Postman zur Anfrageverwaltung.
Klicken Sie oben in der Navigationsleiste auf Workspaces und wählen Sie Create Workspace (Arbeitsbereich erstellen) aus.
Wählen Sie „Leere Arbeitsfläche“ aus, klicken Sie auf „Weiter“ und geben Sie den Namen „Privacy Sandbox“ ein. Wählen Sie Persönlich aus und klicken Sie auf Erstellen.
Laden Sie die JSON-Konfiguration und die Datei für die globale Umgebung des vorab konfigurierten Arbeitsbereichs herunter.
Importieren Sie die JSON-Dateien über die Schaltfläche Importieren in Mein Arbeitsbereich.

Dadurch wird die Privacy Sandbox-Sammlung zusammen mit den createJob- und getJob-HTTP-Anfragen für Sie erstellt.
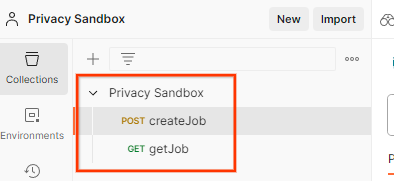
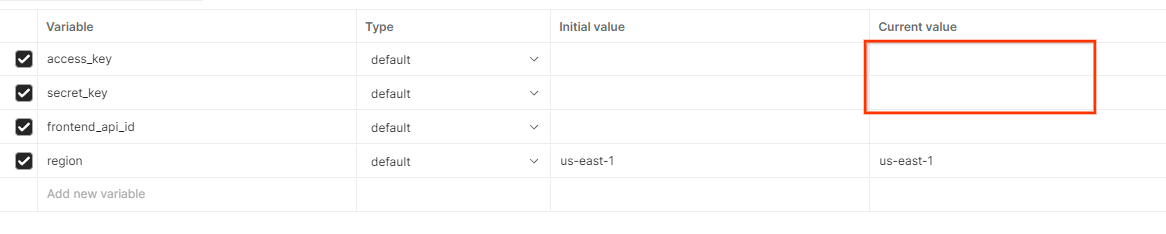
Aktualisieren Sie den AWS-Zugriffsschlüssel und den geheimen Schlüssel über die Umgebungsübersicht.
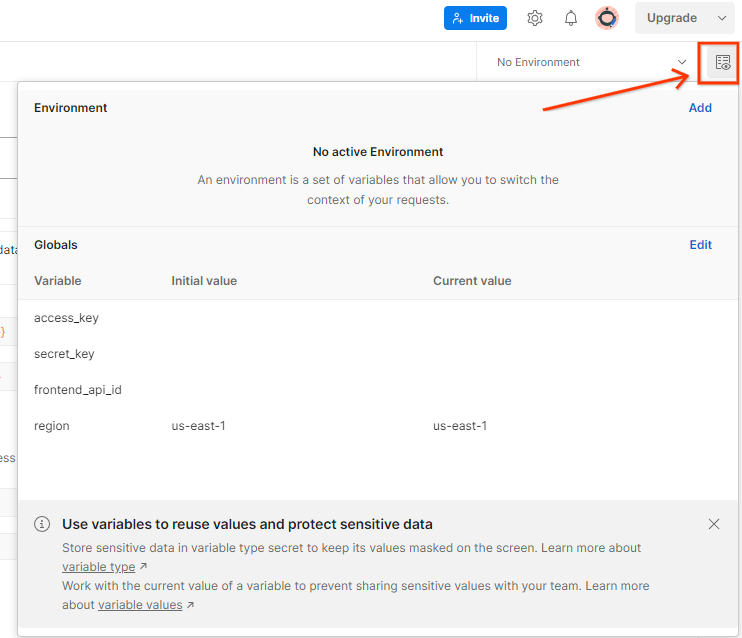
Klicken Sie auf Bearbeiten und aktualisieren Sie den „Aktuellen Wert“ sowohl für access_key als auch für secret_key. frontend_api_id wird in Abschnitt 3.1.4 dieses Dokuments bereitgestellt. Wir empfehlen die Verwendung der Region „us-east-1“. Wenn Sie die Bereitstellung jedoch in einer anderen Region vornehmen möchten, müssen Sie das veröffentlichte AMI in Ihr Konto kopieren oder mit den bereitgestellten Scripts selbst ein Image erstellen.

2. Codelab zum lokalen Testen
Sie können das lokale Testtool auf Ihrem Computer verwenden, um die Aggregation durchzuführen und Zusammenfassungsberichte mithilfe der unverschlüsselten Debugberichte zu erstellen.
Codelab-Schritte
Schritt 2.1: Bericht auslösen: Sie können Berichte zur privaten Aggregation auslösen, um sie abrufen zu können.
Schritt 2.2: Aggregierbaren Debug-Bericht erstellen: Konvertieren Sie den erfassten JSON-Bericht in einen Bericht im AVRO-Format.
Dieser Schritt ähnelt dem, wenn Anzeigentechnologien die Berichte von den API-Berichtsendpunkten abrufen und die JSON-Berichte in Berichte im AVRO-Format konvertieren.
Schritt 2.3: Bucket-Schlüssel aus dem Debug-Bericht analysieren: Bucket-Schlüssel werden von Anbietern von Anzeigentechnologien erstellt. Da die Bucket in diesem Codelab vordefiniert sind, rufen Sie die Bucket-Schlüssel wie angegeben ab.
Schritt 2.4: AVRO-Datei für die Ausgabedomain erstellen: Nachdem die Bucketschlüssel abgerufen wurden, erstellen Sie die AVRO-Datei für die Ausgabedomain.
Schritt 2.5: Zusammenfassungsberichte mit dem Tool für lokale Tests erstellen: Mit dem Tool für lokale Tests können Sie Zusammenfassungsberichte in der lokalen Umgebung erstellen.
Schritt 2.6: Zusammenfassungsbericht prüfen: Sehen Sie sich den vom Local Testing Tool erstellten Zusammenfassungsbericht an.
2.1. Triggerbericht
Rufen Sie die Demo-Website für die Privacy Sandbox auf. Dadurch wird ein Bericht zur privaten Aggregation ausgelöst. Sie können den Bericht unter chrome://private-aggregation-internals aufrufen.
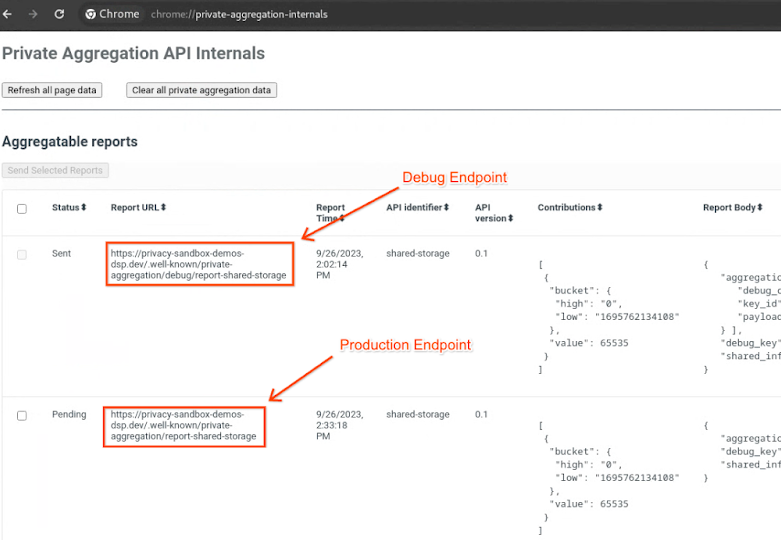
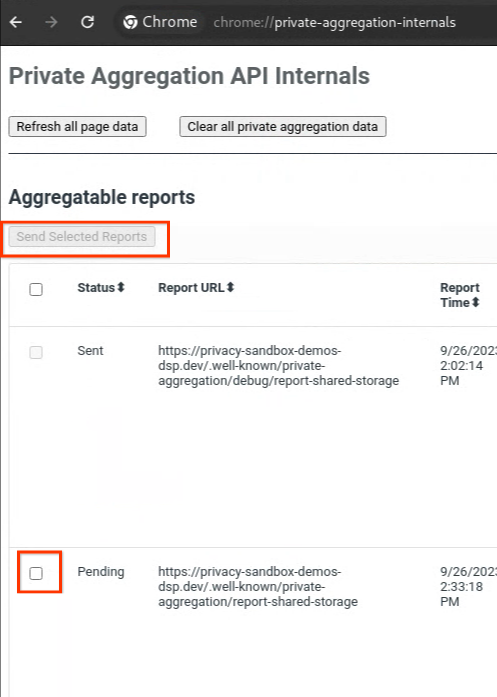
Wenn der Status Ihres Berichts Ausstehend ist, können Sie ihn auswählen und auf Ausgewählte Berichte senden klicken.
2.2. Aggregierbaren Debug-Bericht erstellen
Kopiere in chrome://private-aggregation-internals den Report Body, der am Endpunkt [reporting-origin]/.well-known/private-aggregation/report-shared-storage empfangen wurde.
Achten Sie darauf, dass im Berichtskörper die aggregation_coordinator_origin https://publickeyservice.msmt.aws.privacysandboxservices.com enthält. Das bedeutet, dass der Bericht in AWS aggregiert werden kann.
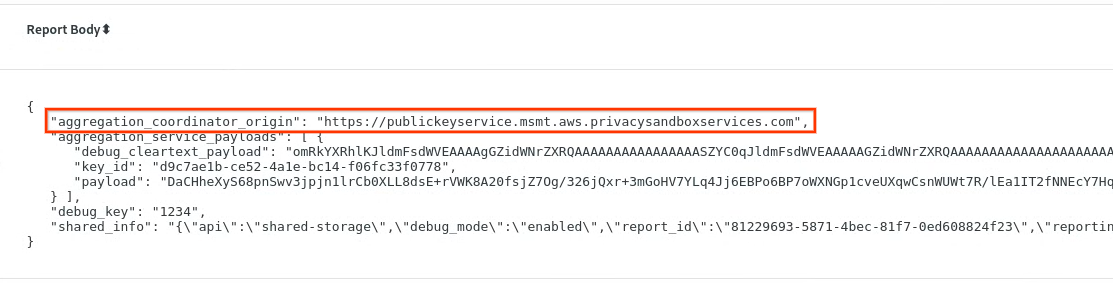
Platzieren Sie den JSON-Berichtstext in einer JSON-Datei. In diesem Beispiel können Sie vim verwenden. Sie können aber auch einen beliebigen anderen Texteditor verwenden.
vim report.json
Fügen Sie den Bericht in report.json ein und speichern Sie die Datei.

Rufen Sie dann Ihren Berichtsordner auf und verwenden Sie die Taste aggregatable_report_converter.jar, um den Bericht zu erstellen. Dadurch wird im aktuellen Verzeichnis ein aggregierbarer Bericht mit dem Namen report.avro erstellt.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Bucket-Schlüssel aus dem Debug-Bericht parsen
Für den Aggregationsdienst sind beim Batching zwei Dateien erforderlich. Der aggregierbare Bericht und die Ausgabedomaindatei. Die Ausgabedomaindatei enthält die Schlüssel, die Sie aus den aggregierten Berichten abrufen möchten. Zum Erstellen der Datei output_domain.avro benötigen Sie die Bucket-Schlüssel, die aus den Berichten abgerufen werden können.
Bucket-Schlüssel werden vom Aufrufer der API erstellt. Die Demo enthält vorab erstellte Beispiel-Bucket-Schlüssel. Da in der Demo der Debug-Modus für die private Aggregation aktiviert ist, können Sie die Debug-Nutzlast im Klartext aus dem Berichtskörper parsen, um den Bucket-Schlüssel abzurufen. In diesem Fall werden die Bucket-Schlüssel jedoch von der Website Privacy Sandbox-Demo erstellt. Da die private Aggregation für diese Website im Debug-Modus ist, können Sie den Bucket-Schlüssel mithilfe von debug_cleartext_payload aus dem Berichtskörper abrufen.
Kopieren Sie die debug_cleartext_payload aus dem Berichtstext.

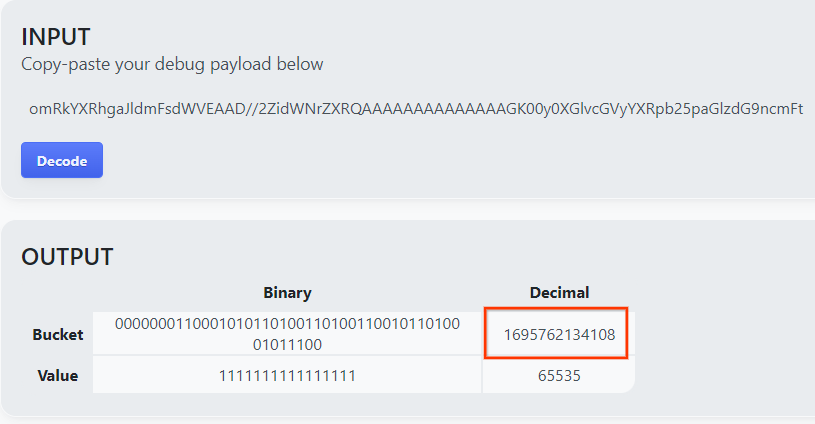
Öffnen Sie das Tool Debug payload decoder for Private Aggregation (Debug-Nutzlast-Decoder für die private Aggregation), fügen Sie Ihre debug_cleartext_payload in das Feld INPUT ein und klicken Sie auf Decode (Decodieren).
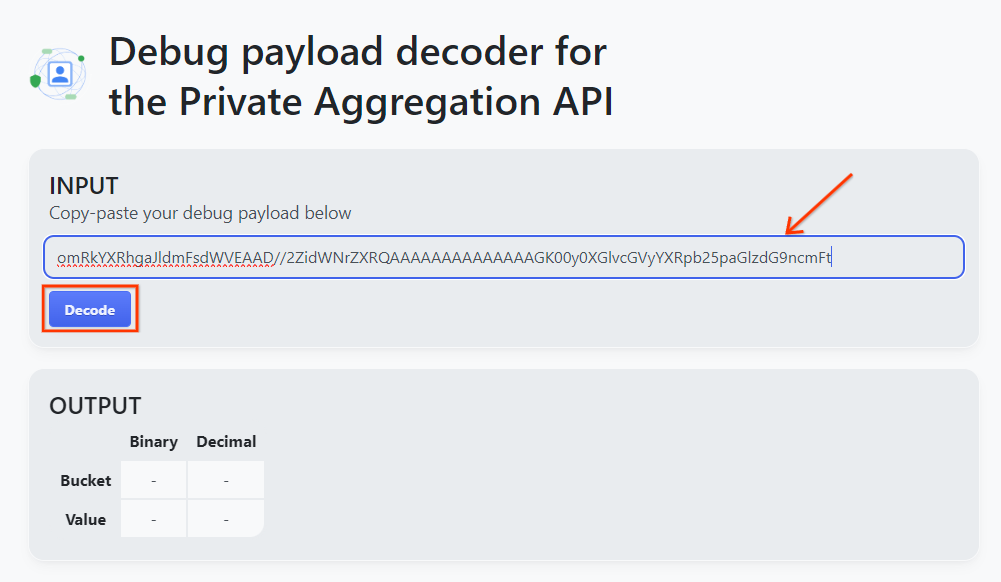
Die Seite gibt den Dezimalwert des Bucket-Schlüssels zurück. Im Folgenden finden Sie ein Beispiel für einen Bucket-Schlüssel.
2.4 Ausgabedomain „AVRO“ erstellen
Jetzt haben wir den Bucket-Schlüssel. Kopieren Sie den Dezimalwert des Bucket-Schlüssels. Erstellen Sie die output_domain.avro mit dem Bucket-Schlüssel. Ersetzen Sie
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Das Script erstellt die output_domain.avro-Datei im aktuellen Ordner.
2.5 Mit dem Tool für lokale Tests Zusammenfassungsberichte erstellen
Wir verwenden LocalTestingTool_{version}.jar, das in Abschnitt 1.1 heruntergeladen wurde, um die Zusammenfassungsberichte zu erstellen. Verwenden Sie den folgenden Befehl: Ersetzen Sie LocalTestingTool_{version}.jar durch die für LocalTestingTool heruntergeladene Version.
Führen Sie den folgenden Befehl aus, um einen Zusammenfassungsbericht in Ihrer lokalen Entwicklungsumgebung zu generieren:
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
Nach der Ausführung des Befehls sollte ein Bildschirm ähnlich dem folgenden angezeigt werden. Danach wird ein Bericht output.avro erstellt.
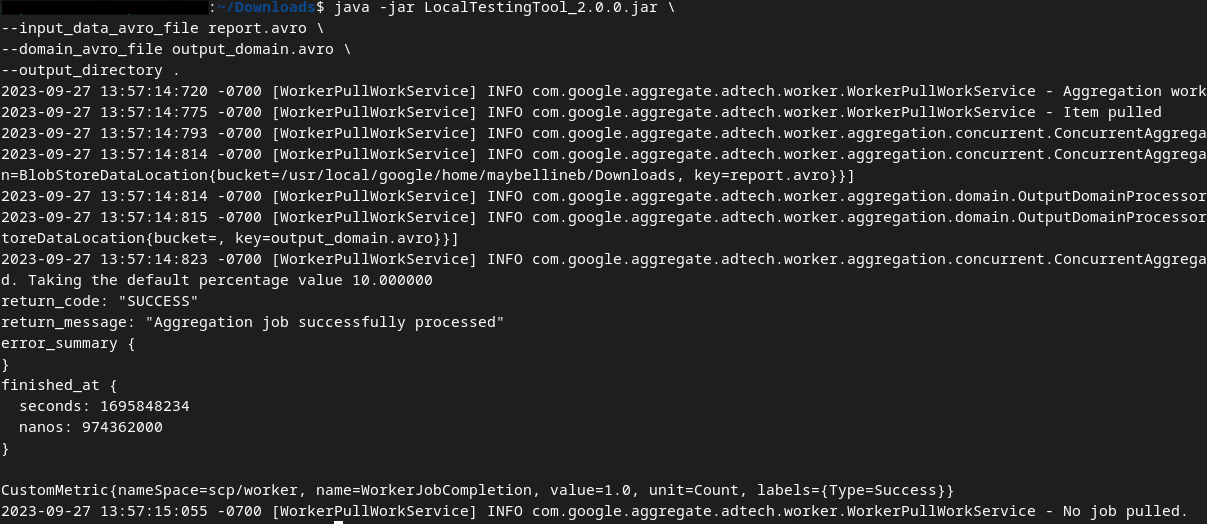
2.6. Zusammenfassungsbericht ansehen
Der erstellte Zusammenfassungsbericht ist im AVRO-Format. Damit Sie sie lesen können, müssen Sie sie von AVRO in ein JSON-Format konvertieren. Idealerweise sollte die Anzeigentechnologie so programmiert sein, dass AVRO-Berichte wieder in JSON konvertiert werden.
In diesem Codelab verwenden wir das bereitgestellte aggregatable_report_converter.jar-Tool, um den AVRO-Bericht wieder in JSON umzuwandeln.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
Dies gibt einen Bericht zurück, der in etwa so aussieht: und eine Berichtsdatei output.json, die im selben Verzeichnis erstellt wurde.

Öffnen Sie die JSON-Datei in einem Editor Ihrer Wahl, um den Zusammenfassungsbericht aufzurufen.
3. Bereitstellung des Aggregationsdiensts
So stellen Sie den Aggregationsdienst bereit:
Schritt 3: Bereitstellung des Aggregationsdienstes: Aggregationsdienst bei AWS bereitstellen
Schritt 3.1 Repository des Aggregationsdiensts klonen
Schritt 3.2 Vordefinierte Abhängigkeiten herunterladen
Schritt 3.3 Entwicklungsumgebung erstellen
Schritt 3.4 Aggregationsdienst bereitstellen
3.1. Aggregationsdienst-Repository klonen
Klonen Sie in Ihrer lokalen Umgebung das GitHub-Repository des Aggregationsdiensts.
git clone https://github.com/privacysandbox/aggregation-service.git
3.2. Vordefinierte Abhängigkeiten herunterladen
Nachdem Sie das Repository des Aggregation Service geklont haben, rufen Sie den Terraform-Ordner und den entsprechenden Cloud-Ordner des Repositorys auf. Wenn cloud_provider AWS ist, fahren Sie mit
cd <repository_root>/terraform/aws
Führen Sie in download_prebuilt_dependencies.sh aus.
bash download_prebuilt_dependencies.sh
3.3 Entwicklungsumgebung erstellen
Erstellen Sie eine Entwicklungsumgebung in dev.
mkdir dev
Kopieren Sie den Inhalt des Ordners demo in den Ordner dev.
cp -R demo/* dev
Verschieben Sie sich in den Ordner dev.
cd dev
Aktualisieren Sie die Datei main.tf und drücken Sie i für input, um die Datei zu bearbeiten.
vim main.tf
Entfernen Sie das Kommentarzeichen (#) im roten Feld und aktualisieren Sie die Bucket- und Schlüsselnamen, um den Code zu aktivieren.
Für AWS-main.tf:
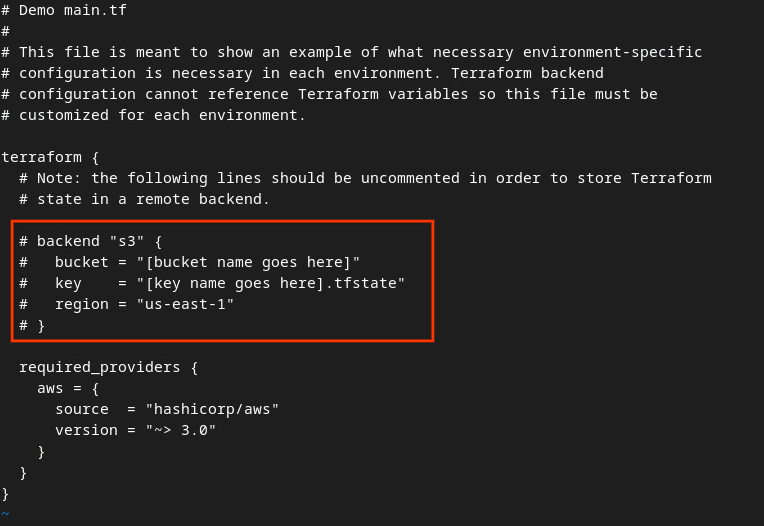
Der Code ohne Kommentarzeichen sollte in etwa so aussehen:
backend "s3" {
bucket = "<tf_state_bucket_name>"
key = "<environment_name>.tfstate"
region = "us-east-1"
}
Speichern Sie die Änderungen und schließen Sie den Editor, indem Sie esc -> :wq! drücken. Dadurch werden die Updates auf main.tf gespeichert.
Benennen Sie als Nächstes example.auto.tfvars in dev.auto.tfvars um.
mv example.auto.tfvars dev.auto.tfvars
Aktualisieren Sie dev.auto.tfvars und drücken Sie i für input, um die Datei zu bearbeiten.
vim dev.auto.tfvars
Aktualisieren Sie die Felder im roten Feld im folgenden Bild mit den richtigen AWS-ARN-Parametern, die beim Onboarding des Aggregationsdiensts, in der Umgebung und in der Benachrichtigungs-E-Mail angegeben wurden.
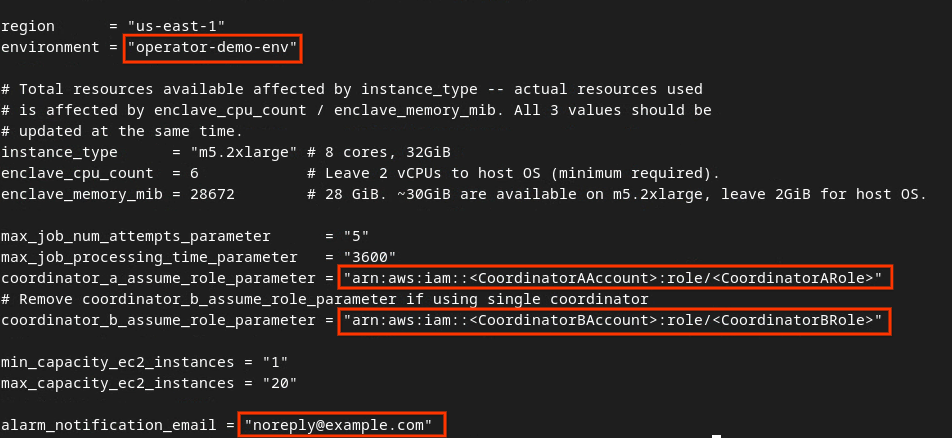
Wenn die Updates abgeschlossen sind, drücken Sie esc -> :wq!. Dadurch wird die Datei dev.auto.tfvars gespeichert. Sie sollte in etwa so aussehen wie im folgenden Bild.
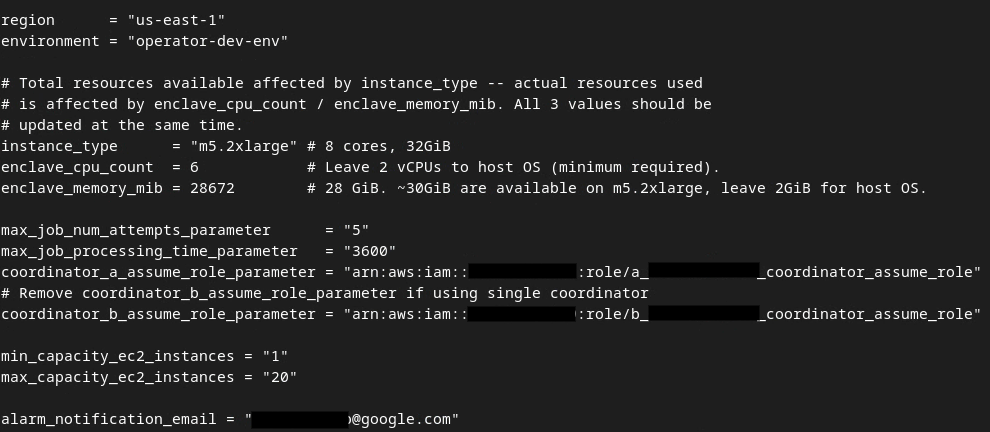
3.4. Aggregationsdienst bereitstellen
Wenn Sie den Aggregations-Dienst bereitstellen möchten, initialisieren Sie Terraform im selben Ordner
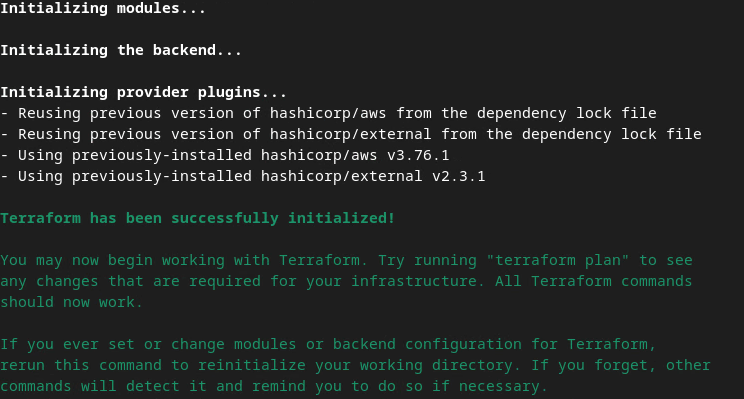
terraform init
Die Ausgabe sollte in etwa so aussehen:
Nachdem Terraform initialisiert wurde, erstellen Sie den Terraform-Ausführungsplan. Dabei wird die Anzahl der hinzuzufügenden Ressourcen und weitere Informationen zurückgegeben, ähnlich wie im folgenden Bild.
terraform plan
Unten sehen Sie die Zusammenfassung Plan. Bei einer Neubereitstellung sollte die Anzahl der hinzugefügten Ressourcen angezeigt werden, wobei „0“ für „Ändern“ und „0“ für „Löschen“ steht.
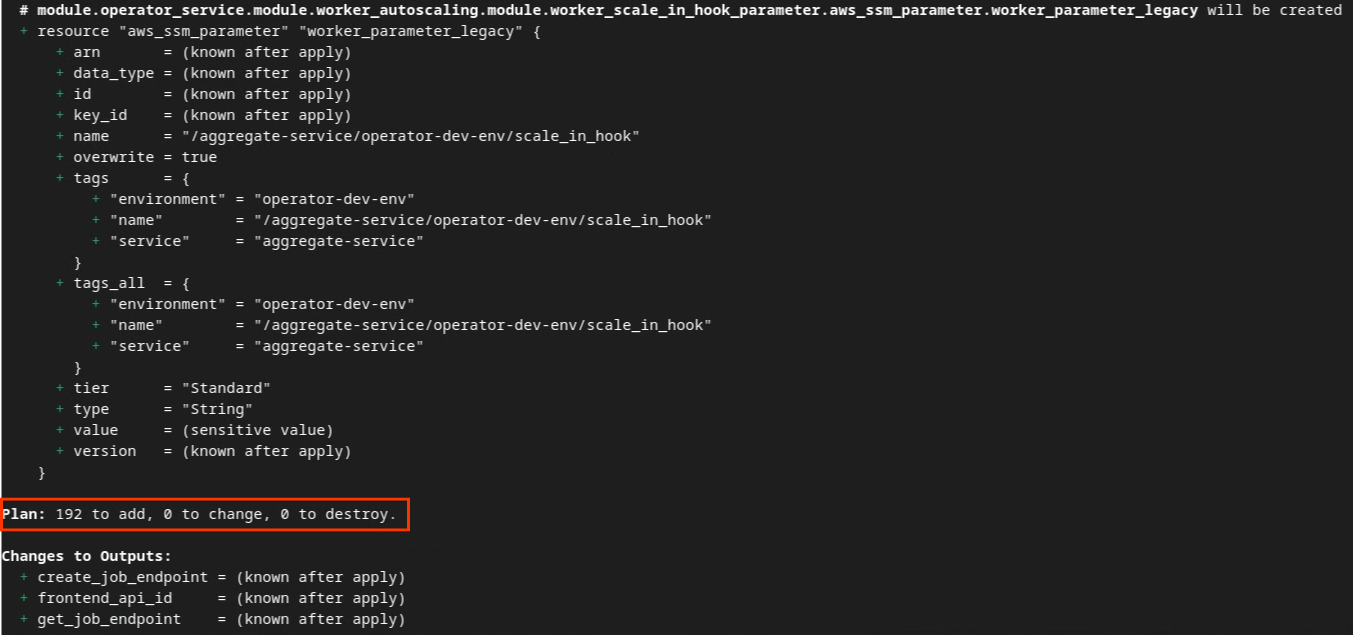
Danach können Sie mit der Anwendung von Terraform fortfahren.
terraform apply
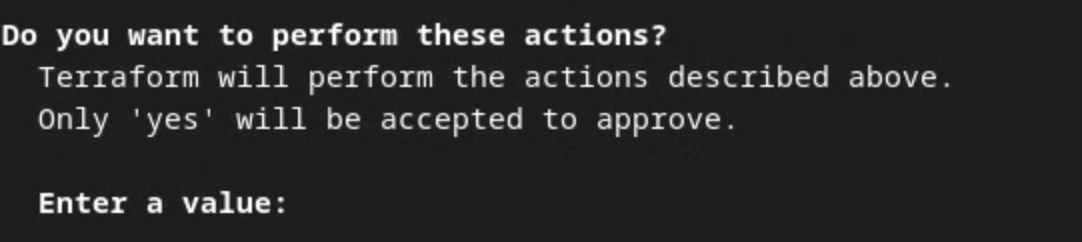
Wenn Sie von Terraform aufgefordert werden, die Ausführung der Aktionen zu bestätigen, geben Sie yes als Wert ein.
Sobald terraform apply abgeschlossen ist, werden die folgenden Endpunkte für createJob und getJob zurückgegeben. Außerdem wird frontend_api_id zurückgegeben, das Sie in Abschnitt 1.9 in Postman aktualisieren müssen.

4. Eingabe für Aggregationsdienst erstellen
Erstellen Sie die AVRO-Berichte für die Batchverarbeitung im Aggregationsdienst.
Schritt 4: Eingabe für den Aggregationsdienst erstellen: Erstellen Sie die Berichte für den Aggregationsdienst, die für den Aggregationsdienst in Batches zusammengefasst werden.
Schritt 4.1 Triggerbericht
Schritt 4.2 Berichte erfassen, die zusammengefasst werden können
Schritt 4.3 Berichte in AVRO konvertieren
Schritt 4.4 Ausgabedomain „AVRO“ erstellen
4.1. Triggerbericht
Rufen Sie die Privacy Sandbox-Demowebsite auf. Dadurch wird ein Bericht zur privaten Aggregation ausgelöst. Sie können den Bericht unter chrome://private-aggregation-internals aufrufen.
Wenn der Status Ihres Berichts Ausstehend ist, können Sie ihn auswählen und auf Ausgewählte Berichte senden klicken.
4.2. Berichte erfassen, die zusammengefasst werden können
Erfassen Sie Ihre aggregierbaren Berichte über die .well-known-Endpunkte Ihrer entsprechenden API.
- Private Aggregation
[reporting-origin] /.well-known/private-aggregation/report-shared-storage - Attributionsberichte – Zusammenfassungsbericht
[reporting-origin] /.well-known/attribution-reporting/report-aggregate-attribution
In diesem Codelab führen Sie die Berichterstellung manuell durch. In der Produktion werden die Berichte von AdTech-Anbietern programmatisch erfasst und konvertiert.
Kopiere in chrome://private-aggregation-internals den Report Body, der am Endpunkt [reporting-origin]/.well-known/private-aggregation/report-shared-storage empfangen wurde.
Achten Sie darauf, dass im Berichtskörper die aggregation_coordinator_origin https://publickeyservice.msmt.aws.privacysandboxservices.com enthält. Das bedeutet, dass der Bericht in AWS aggregiert werden kann.
Platzieren Sie den JSON-Berichtstext in einer JSON-Datei. In diesem Beispiel können Sie vim verwenden. Sie können aber auch einen beliebigen anderen Texteditor verwenden.
vim report.json
Fügen Sie den Bericht in report.json ein und speichern Sie die Datei.
4.3. Berichte in AVRO konvertieren
Die von den .well-known-Endpunkten empfangenen Berichte sind im JSON-Format und müssen in das AVRO-Berichtsformat konvertiert werden. Rufen Sie den Berichtsordner auf und erstellen Sie mit aggregatable_report_converter.jar einen aggregierten Bericht zur Fehlerbehebung. Dadurch wird im aktuellen Verzeichnis ein aggregierbarer Bericht mit dem Namen report.avro erstellt.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
4.4. Ausgabedomain „AVRO“ erstellen
Zum Erstellen der Datei output_domain.avro benötigen Sie die Bucket-Schlüssel, die aus den Berichten abgerufen werden können.
Bucket-Schlüssel werden von der Anzeigentechnologie erstellt. In diesem Fall werden die Bucket-Schlüssel jedoch von der Website Privacy Sandbox-Demo erstellt. Da die private Aggregation für diese Website im Debug-Modus ist, können Sie den Bucket-Schlüssel mithilfe von debug_cleartext_payload aus dem Berichtskörper abrufen.
Kopieren Sie die debug_cleartext_payload aus dem Berichtstext.
Öffnen Sie goo.gle/ags-payload-decoder, fügen Sie Ihre debug_cleartext_payload in das Feld INPUT ein und klicken Sie auf Decode.
Die Seite gibt den Dezimalwert des Bucket-Schlüssels zurück. Im Folgenden finden Sie ein Beispiel für einen Bucket-Schlüssel.
Nachdem wir den Bucket-Schlüssel haben, können wir die output_domain.avro erstellen. Ersetzen Sie
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Das Script erstellt die output_domain.avro-Datei im aktuellen Ordner.
4.5. Berichte in den AWS-Bucket verschieben
Nachdem die AVRO-Berichte (aus Abschnitt 3.2.3) und die Ausgabedomain (aus Abschnitt 3.2.4) erstellt wurden, verschieben Sie die Berichte und die Ausgabedomain in die S3-Buckets für die Berichterstellung.
Wenn Sie die AWS CLI in Ihrer lokalen Umgebung eingerichtet haben, können Sie die Berichte mit den folgenden Befehlen in den entsprechenden S3-Bucket und den Berichtsordner kopieren.
aws s3 cp report.avro s3://<report_bucket_name>/<report_folder>/
aws s3 cp output_domain.avro s3://<report_bucket_name>/<output_domain_folder>/
5. Nutzung des Aggregationsdiensts
Über die terraform apply werden die create_job_endpoint, get_job_endpoint und frontend_api_id zurückgegeben. Kopieren Sie frontend_api_id und fügen Sie es in die globale Postman-Variable frontend_api_id ein, die Sie im Abschnitt mit den Voraussetzungen (1.9) eingerichtet haben.
Schritt 5: Aggregationsdienst verwenden: Mit der Aggregation Service API können Sie Zusammenfassungsberichte erstellen und prüfen.
Schritt 5.1 Mit dem Endpunkt „createJob“ Jobs in Batches ausführen
Schritt 5.2 Batchstatus mit dem Endpunkt „getJob“ abrufen
Schritt 5.3 Zusammenfassungsbericht prüfen
5.1. createJob-Endpunkt für Batches verwenden
Öffnen Sie in Postman die Sammlung Privacy Sandbox und wählen Sie createJob aus.
Wählen Sie „Body“ und dann „raw“ aus, um die Nutzlast Ihrer Anfrage zu platzieren.
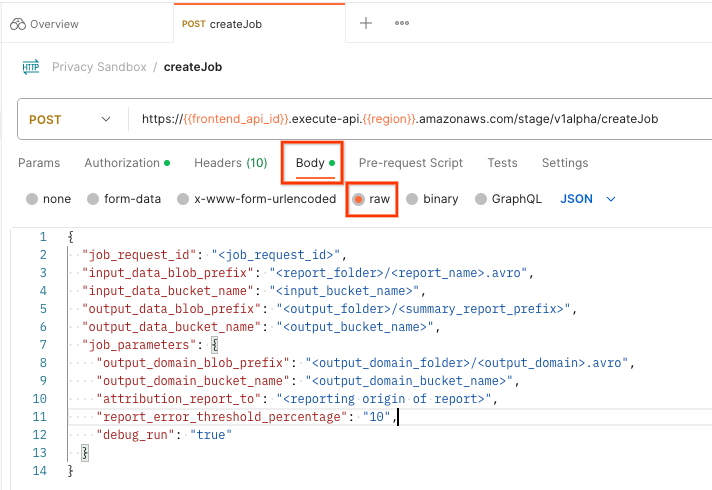
Das createJob-Nutzlastschema ist auf github verfügbar und sieht in etwa so aus: Ersetzen Sie die <> durch die entsprechenden Felder.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
], // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Wenn Sie auf Senden klicken, wird der Job mit der job_request_id erstellt. Sie sollten eine HTTP-202-Antwort erhalten, sobald die Anfrage vom Aggregationsdienst akzeptiert wurde. Weitere mögliche Rückgabecodes finden Sie unter HTTP-Antwortcodes.

5.2. Batch-Status mit dem Endpunkt „getJob“ abrufen
Sie können den Status der Jobanfrage mit dem Endpunkt getJob prüfen. Wählen Sie in der Sammlung Privacy Sandbox die Option getJob aus.
Aktualisieren Sie unter „Params“ den Wert „job_request_id“ auf die job_request_id, die in der createJob-Anfrage gesendet wurde.
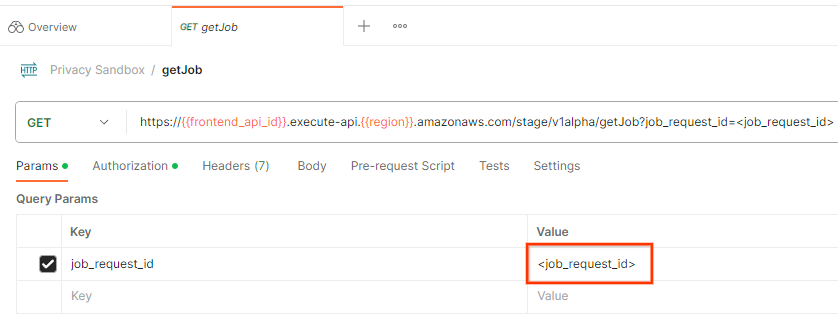
Das Ergebnis der getJob sollte den Status Ihrer Jobanfrage mit dem HTTP-Status 200 zurückgeben. Der Body der Anfrage enthält die erforderlichen Informationen wie job_status, return_message und error_messages (falls der Job einen Fehler verursacht hat).
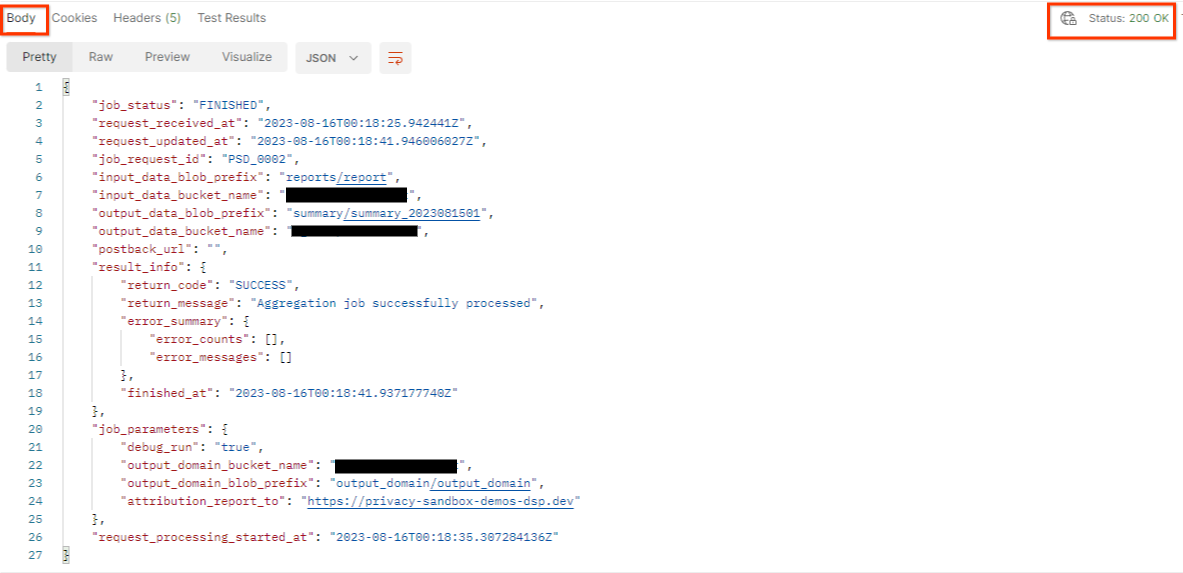
Da sich die Website für den generierten Demobericht von der Website unterscheidet, die Sie mit Ihrer AWS-ID verknüpft haben, erhalten Sie möglicherweise eine Antwort mit dem Rückgabecode PRIVACY_BUDGET_AUTHORIZATION_ERROR. Das ist normal, da die Website der Berichtsquelle nicht mit der Website für die Berichterstellung übereinstimmt, die für die AWS-ID eingerichtet wurde.
{
"job_status": "FINISHED",
"request_received_at": "2023-12-07T22:50:58.830956Z",
"request_updated_at": "2023-12-07T22:51:10.526326456Z",
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"postback_url": "",
"result_info": {
"return_code": "PRIVACY_BUDGET_AUTHORIZATION_ERROR",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-12-07T22:51:10.517730898Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"attribution_report_to": "https://privacy-sandbox-demos-dsp.dev",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
},
"request_processing_started_at": "2023-12-07T22:51:06.034472697Z"
}
5.3. Zusammenfassungsbericht prüfen
Sobald Sie den Zusammenfassungsbericht in Ihrem Ausgabe-S3-Bucket erhalten haben, können Sie ihn in Ihre lokale Umgebung herunterladen. Zusammenfassungsberichte sind im AVRO-Format und können wieder in JSON umgewandelt werden. Sie können den Bericht mit aggregatable_report_converter.jar mit dem folgenden Befehl lesen.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
Dadurch wird ein JSON mit aggregierten Werten für jeden Bucket-Schlüssel zurückgegeben, der in etwa so aussieht wie in der Abbildung unten.

Wenn Ihre createJob-Anfrage debug_run als true enthält, können Sie den Zusammenfassungsbericht im Debug-Ordner im output_data_blob_prefix erhalten. Der Bericht ist im AVRO-Format und kann mit dem vorherigen Befehl in JSON umgewandelt werden.
Der Bericht enthält den Bucket-Schlüssel, den fehlerfreien Messwert und den Fehler, der dem fehlerfreien Messwert hinzugefügt wird, um den zusammengefassten Bericht zu erstellen. Der Bericht sieht in etwa so aus:

Die Anmerkungen enthalten außerdem in_reports und in_domain, was Folgendes bedeutet:
- in_reports: Der Bucket-Schlüssel ist in den aggregierten Berichten verfügbar.
- in_domain: Der Bucket-Schlüssel ist in der AVRO-Datei „output_domain“ verfügbar.