
1. 1. Prérequis
Durée estimée: 1 à 2 heures
Cet atelier de programmation peut être effectué en deux modes: Test local ou Service d'agrégation. Le mode de test local nécessite un ordinateur local et le navigateur Chrome (aucune création ni utilisation de ressources Google Cloud). Le mode Service d'agrégation nécessite un déploiement complet du service d'agrégation sur Google Cloud.
Pour suivre cet atelier de programmation dans l'un ou l'autre des modes, vous devez remplir quelques conditions préalables. Chaque exigence est marquée en conséquence, selon qu'elle est requise pour les tests locaux ou le service d'agrégation.
1.1. Inscription et attestation terminées (service d'agrégation)
Pour utiliser les API Privacy Sandbox, assurez-vous d'avoir effectué l'inscription et l'attestation pour Chrome et Android.
1.2. Activer les API de confidentialité des annonces (service de test et d'agrégation local)
Étant donné que nous utiliserons la Privacy Sandbox, nous vous encourageons à activer les API Ads de la Privacy Sandbox.
Dans votre navigateur, accédez à chrome://settings/adPrivacy et activez toutes les API de confidentialité des annonces.
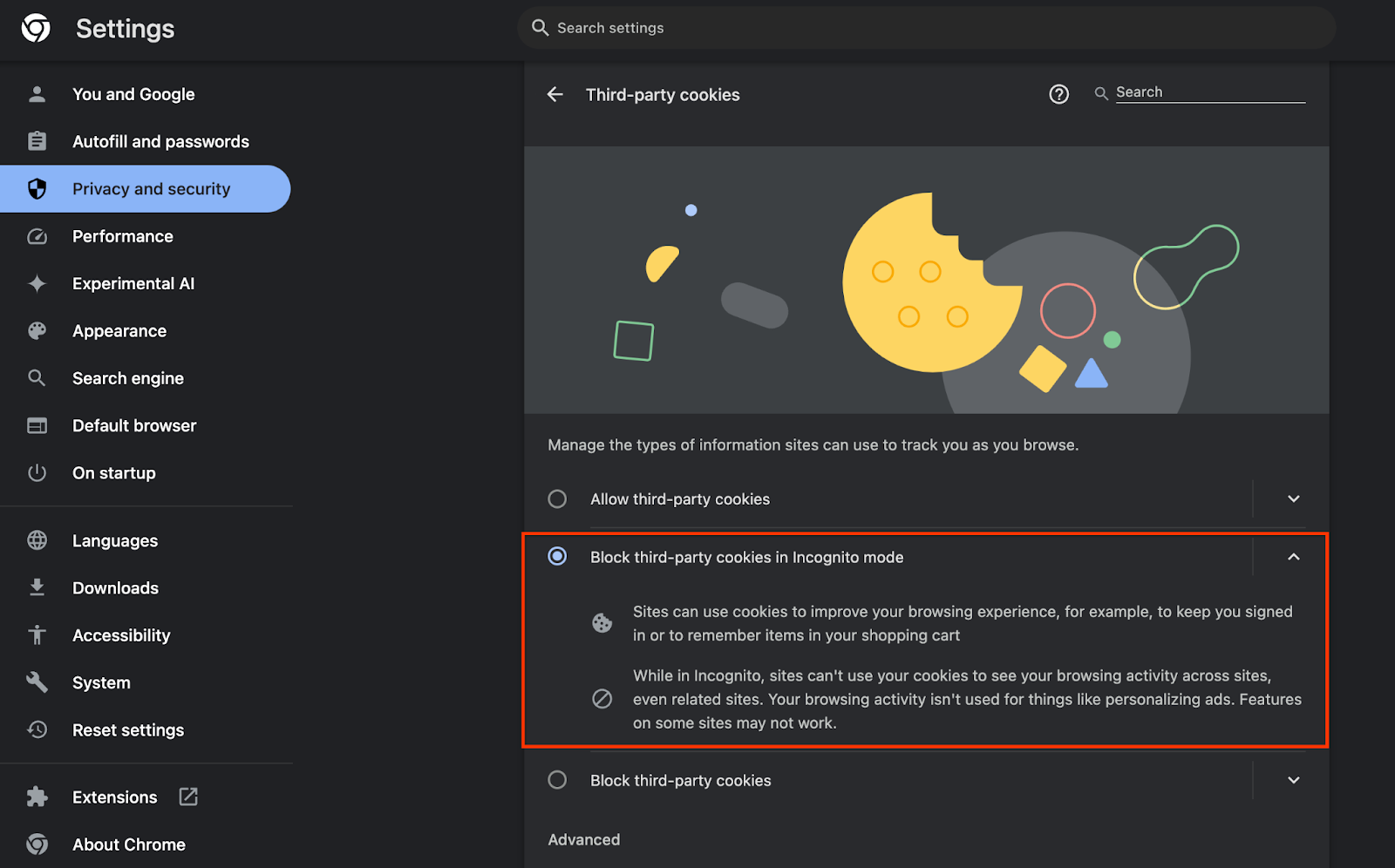
Assurez-vous également que vos cookies tiers sont activés.
Dans chrome://settings/cookies, assurez-vous que les cookies tiers ne sont PAS bloqués. Selon la version de Chrome que vous utilisez, différentes options peuvent s'afficher dans ce menu de paramètres. Voici quelques configurations acceptables:
- "Bloquer tous les cookies tiers" = DÉSACTIVÉ
- "Bloquer les cookies tiers" = DÉSACTIVÉ
- "Bloquer les cookies tiers en mode navigation privée" = ACTIVÉ
1.3. Télécharger l'outil de test local (test local)
Pour effectuer des tests en local, vous devez télécharger l'outil de test en local. L'outil génère des rapports récapitulatifs à partir des rapports de débogage non chiffrés.
L'outil de test local est disponible en téléchargement dans les archives JAR de Cloud Functions sur GitHub. Il doit être nommé LocalTestingTool_{version}.jar.
1.4. Vérifier que le JRE Java est installé (service d'agrégation et de test local)
Ouvrez Terminal et utilisez java --version pour vérifier si Java ou openJDK est installé sur votre machine.

Si ce n'est pas le cas, vous pouvez le télécharger et l'installer depuis le site Java ou le site openJDK.
1.5. Télécharger aggregatable_report_converter (service d'agrégation et de test local)
Vous pouvez télécharger une copie de l'aggregable_report_converter à partir du dépôt GitHub des démonstrations de la Privacy Sandbox. Le dépôt GitHub mentionne l'utilisation d'IntelliJ ou d'Eclipse, mais aucun de ces IDE n'est obligatoire. Si vous n'utilisez pas ces outils, téléchargez plutôt le fichier JAR dans votre environnement local.
1.6. Configurer un environnement GCP (service d'agrégation)
Le service d'agrégation nécessite l'utilisation d'un environnement d'exécution sécurisé qui utilise un fournisseur cloud. Dans cet atelier de programmation, le service d'agrégation sera déployé dans GCP, mais AWS est également compatible.
Suivez les instructions de déploiement sur GitHub pour configurer la CLI gcloud, télécharger les binaires et les modules Terraform, et créer des ressources GCP pour le service d'agrégation.
Étapes clés des instructions de déploiement:
- Configurez la gcloud CLI et Terraform dans votre environnement.
- Créez un bucket Cloud Storage pour stocker l'état Terraform.
- Télécharger les dépendances
- Mettez à jour
adtech_setup.auto.tfvarset exécutez le Terraformadtech_setup. Pour obtenir un exemple de fichieradtech_setup.auto.tfvars, consultez l'annexe. Notez le nom du bucket de données créé ici. Il sera utilisé dans l'atelier de programmation pour stocker les fichiers que nous créerons. - Mettez à jour
dev.auto.tfvars, usurpez l'identité du compte de service de déploiement et exécutez Terraformdev. Pour obtenir un exemple de fichierdev.auto.tfvars, consultez l'annexe. - Une fois le déploiement terminé, capturez
frontend_service_cloudfunction_urlà partir de la sortie Terraform, qui sera nécessaire pour envoyer des requêtes au service d'agrégation lors des étapes suivantes.
1.7. Finaliser l'intégration du service d'agrégation (service d'agrégation)
Le service d'agrégation nécessite une intégration aux coordinateurs pour pouvoir l'utiliser. Remplissez le formulaire d'intégration du service d'agrégation en indiquant votre site de création de rapports et d'autres informations, en sélectionnant "Google Cloud" et en saisissant l'adresse de votre compte de service. Ce compte de service est créé dans l'étape préalable précédente (1.6. Configurer un environnement GCP). (Conseil: si vous utilisez les noms par défaut fournis, ce compte de service commencera par "worker-sa@".)
Le processus d'intégration peut prendre jusqu'à deux semaines.
1.8. Déterminer votre méthode d'appel des points de terminaison de l'API (service d'agrégation)
Cet atelier de programmation propose deux options pour appeler les points de terminaison de l'API du service d'agrégation: cURL et Postman. cURL est le moyen le plus rapide et le plus simple d'appeler les points de terminaison de l'API à partir de votre terminal, car il nécessite une configuration minimale et aucun logiciel supplémentaire. Toutefois, si vous ne souhaitez pas utiliser cURL, vous pouvez utiliser Postman pour exécuter et enregistrer des requêtes API à utiliser ultérieurement.
Dans la section 3.2. Aggregation Service Usage, vous trouverez des instructions détaillées sur l'utilisation des deux options. Vous pouvez les prévisualiser dès maintenant pour déterminer la méthode que vous allez utiliser. Si vous sélectionnez Postman, effectuez la configuration initiale suivante.
1.8.1. Configurer l'espace de travail
Créez un compte Postman. Une fois inscrit, un espace de travail est automatiquement créé pour vous.
Si aucun espace de travail n'est créé pour vous, accédez à l'élément de navigation supérieur "Espaces de travail", puis sélectionnez "Créer un espace de travail".
Sélectionnez "Espace de travail vide", cliquez sur "Suivant", puis nommez-le "Privacy Sandbox GCP". Sélectionnez "Personnel", puis cliquez sur "Créer".
Téléchargez la configuration JSON et les fichiers d'environnement global de l'espace de travail préconfiguré.
Importez les deux fichiers JSON dans "Mon espace de travail" à l'aide du bouton "Importer".

La collection "Privacy Sandbox GCP" sera créée pour vous, ainsi que les requêtes HTTP createJob et getJob.
1.8.2. Configurer les autorisations
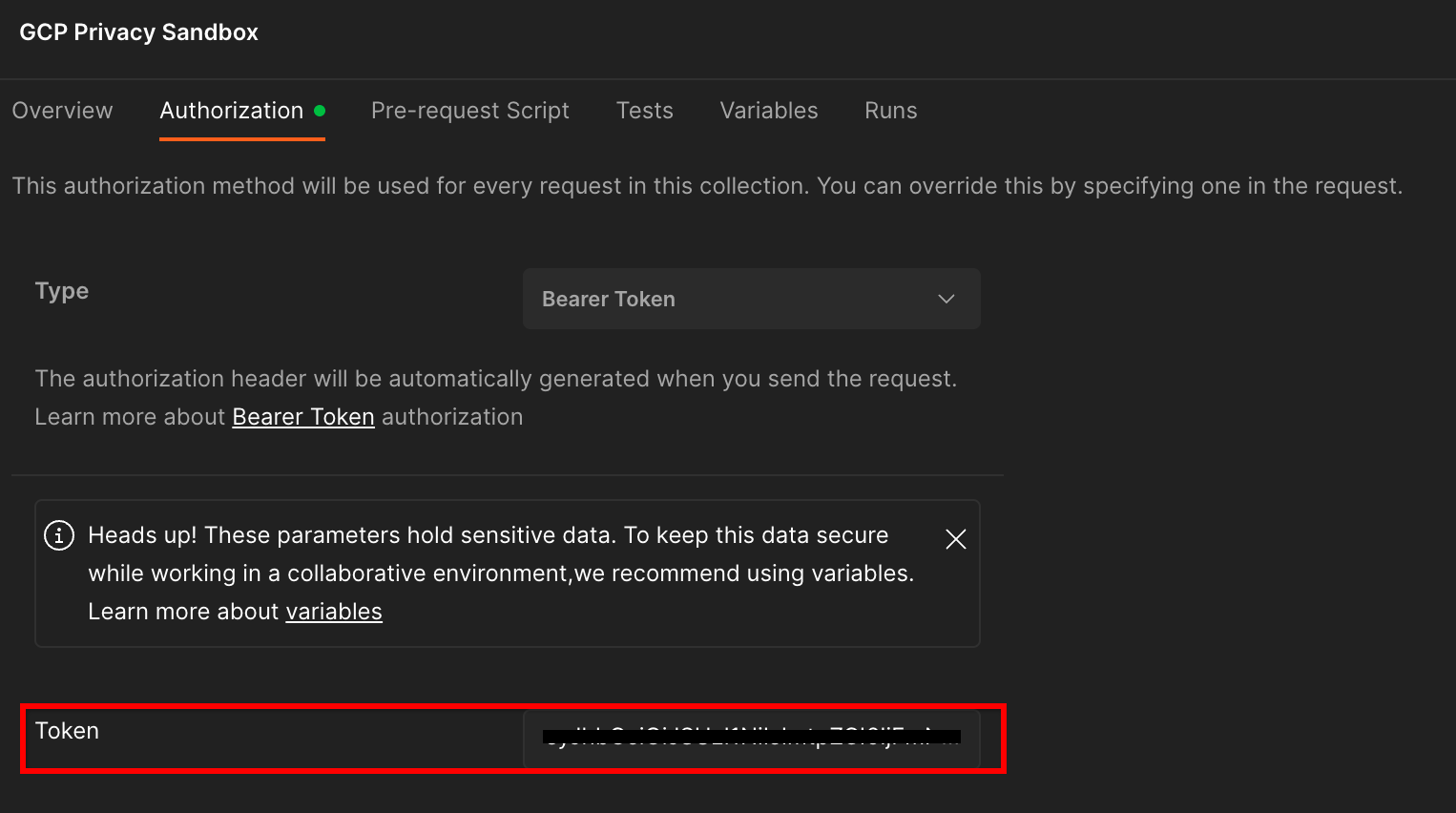
Cliquez sur la collection "Privacy Sandbox GCP", puis accédez à l'onglet "Autorisation".

Vous utiliserez la méthode "Jeton porteur". Dans votre environnement Terminal, exécutez cette commande et copiez la sortie.
gcloud auth print-identity-token
Collez ensuite cette valeur de jeton dans le champ "Jeton" de l'onglet d'autorisation de Postman:
1.8.3. Configurer l'environnement
Accédez à "Aperçu rapide de l'environnement" en haut à droite:
Cliquez sur "Modifier" et mettez à jour la valeur actuelle de "environment", "region" et "cloud-function-id":
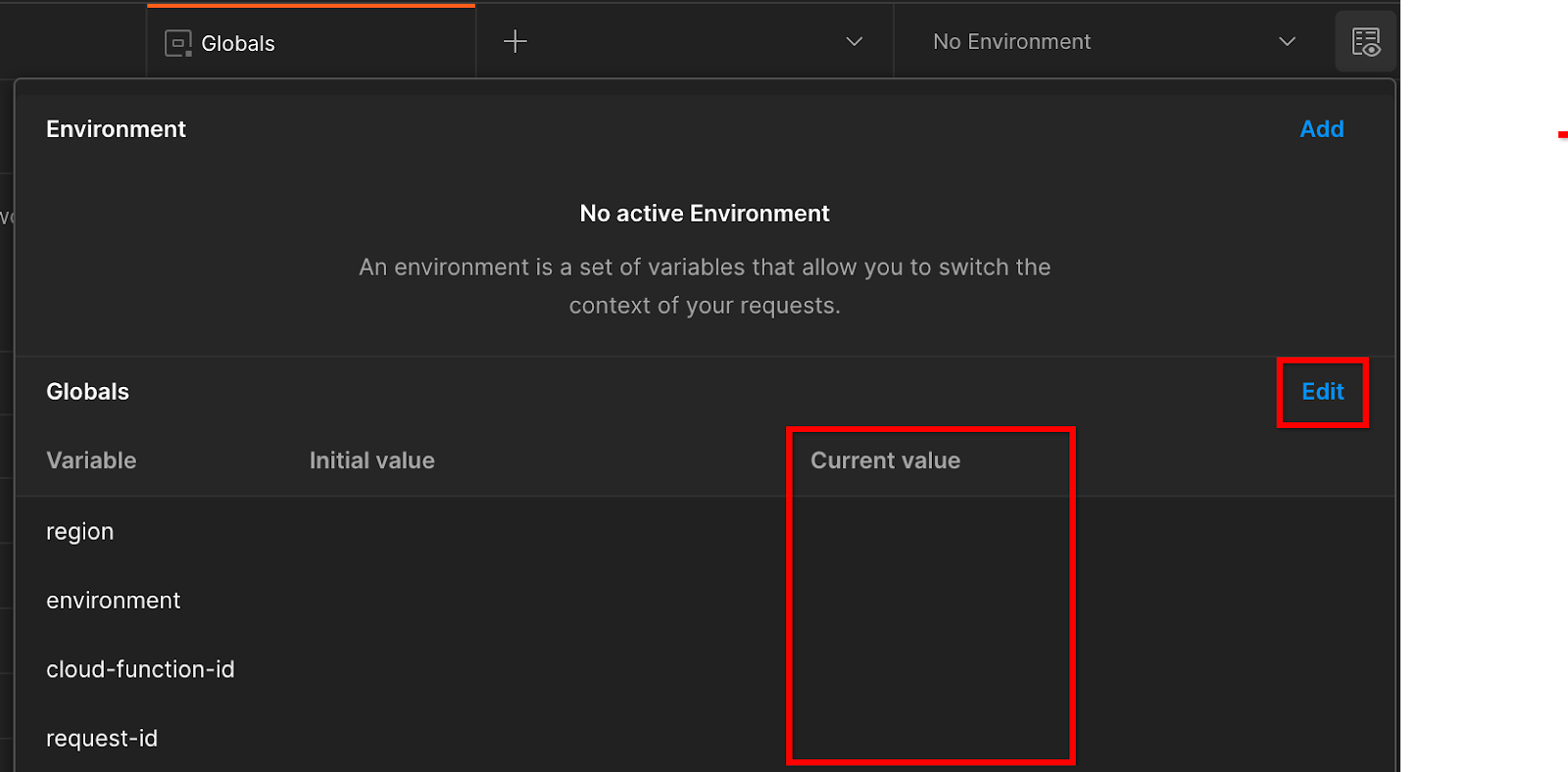
Vous pouvez laisser "request-id" vide pour le moment, car nous le remplirons plus tard. Pour les autres champs, utilisez les valeurs de frontend_service_cloudfunction_url, qui ont été renvoyées après l'achèvement réussi du déploiement Terraform dans l'étape préalable 1.6. L'URL suit le format suivant: https://
2. 2. Atelier de programmation sur les tests en local
Durée estimée: <1 heure
Vous pouvez utiliser l'outil de test local sur votre ordinateur pour effectuer une agrégation et générer des rapports récapitulatifs à l'aide des rapports de débogage non chiffrés. Avant de commencer, assurez-vous d'avoir rempli toutes les conditions préalables associées à la mention "Tests locaux".
Étapes de l'atelier de programmation
Étape 2.1. Déclencher le rapport: déclenchez la création de rapports d'agrégation privée pour pouvoir les collecter.
Étape 2.2. Créer un rapport AVRO de débogage: convertissez le rapport JSON collecté en un rapport au format AVRO. Cette étape est semblable à celle où les adtechs collectent les rapports à partir des points de terminaison de création de rapports de l'API et convertissent les rapports JSON en rapports au format AVRO.
Étape 2.3. Récupérer les clés de bucket: les clés de bucket sont conçues par les adTechs. Dans cet atelier de programmation, étant donné que les buckets sont prédéfinis, récupérez les clés de bucket telles que fournies.
Étape 2.4. Créer un fichier AVRO de domaine de sortie: une fois les clés de bucket récupérées, créez le fichier AVRO du domaine de sortie.
Étape 2.5. Créer un rapport récapitulatif: utilisez l'outil de test local pour créer des rapports récapitulatifs dans l'environnement local.
Étape 2.6. Examiner les rapports récapitulatifs: examinez le rapport récapitulatif créé par l'outil de test local.
2.1. Rapport sur les déclencheurs
Pour déclencher un rapport d'agrégation privé, vous pouvez utiliser le site de démonstration de la Privacy Sandbox (https://privacy-sandbox-demos-news.dev/?env=gcp) ou votre propre site (par exemple, https://adtechexample.com). Si vous utilisez votre propre site et que vous n'avez pas terminé l'intégration du service d'inscription et d'attestation et du service d'agrégation, vous devez utiliser un indicateur Chrome et un commutateur de CLI.
Pour cette démonstration, nous allons utiliser le site de démonstration de la Privacy Sandbox. Suivez le lien pour accéder au site, puis consultez les rapports sur chrome://private-aggregation-internals:
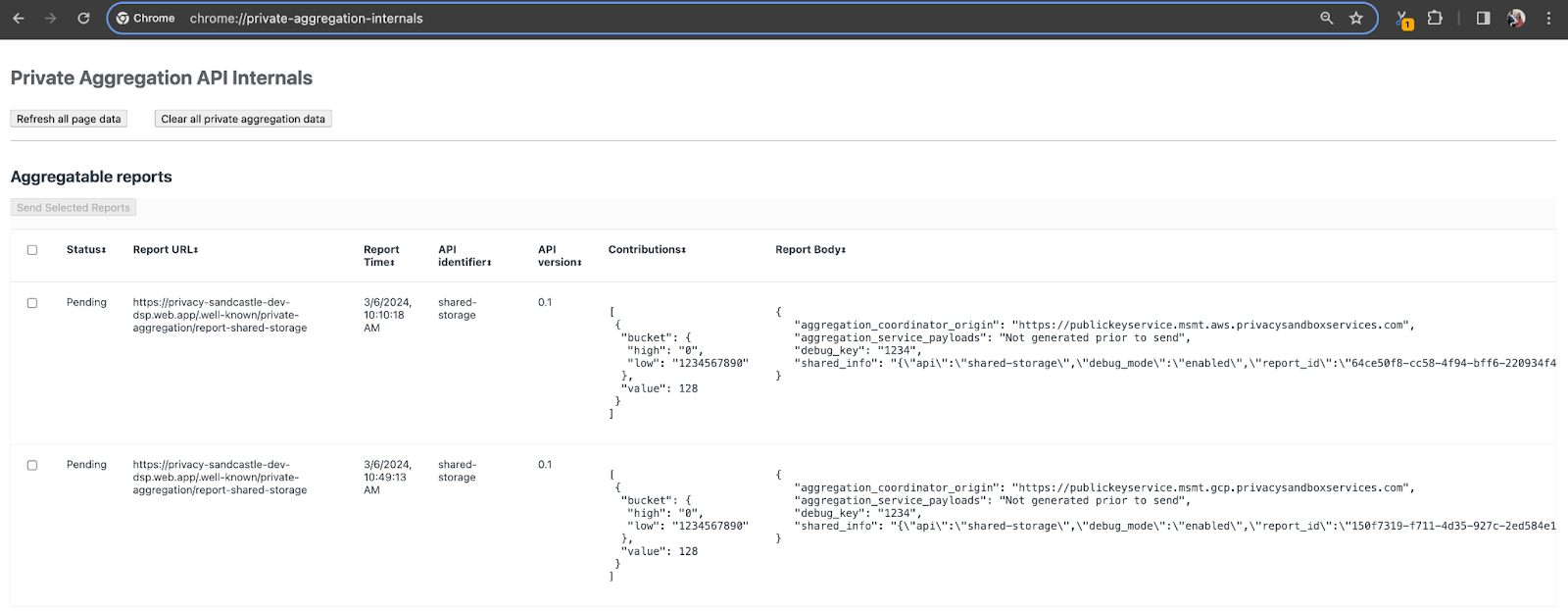
Le rapport envoyé au point de terminaison {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage se trouve également dans le corps des rapports affichés sur la page "Chrome Internals".
Vous verrez peut-être de nombreux rapports ici, mais pour cet atelier de programmation, utilisez le rapport agrégable spécifique à GCP et généré par le point de terminaison de débogage. L'URL du rapport contiendra "/debug/", et le aggregation_coordinator_origin field du corps du rapport contiendra l'URL suivante: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
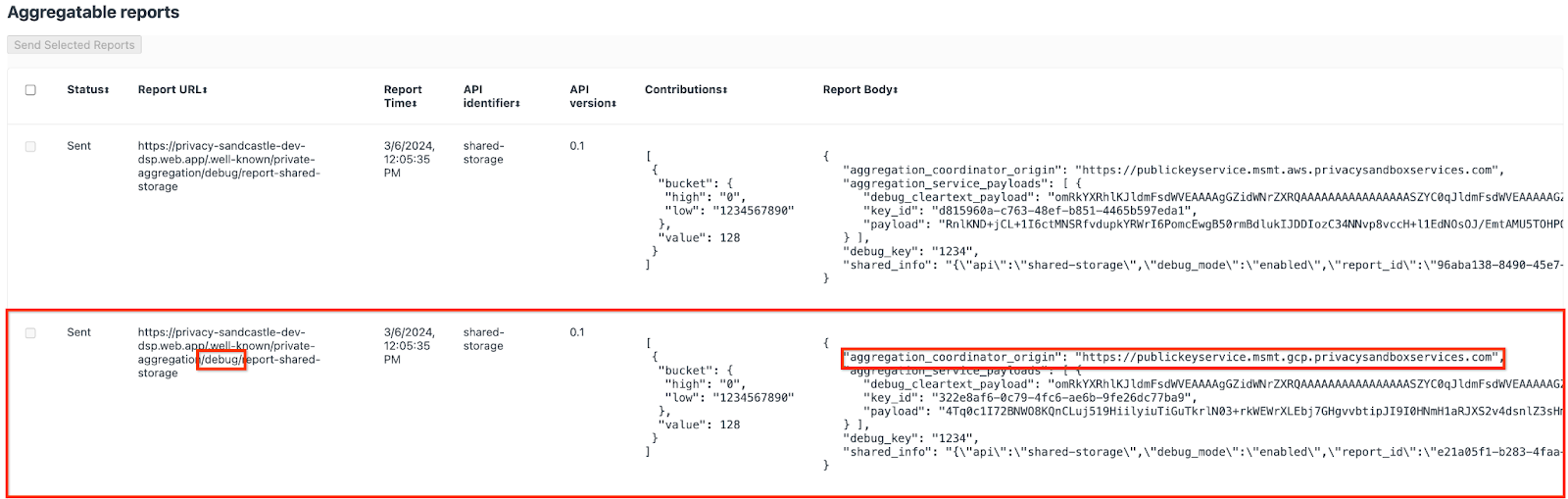
2.2. Créer un rapport agrégable de débogage
Copiez le rapport trouvé dans le "Corps du rapport" de chrome://private-aggregation-internals et créez un fichier JSON dans le dossier privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar (dans le dépôt téléchargé dans l'étape préalable 1.5).
Dans cet exemple, nous utilisons vim, car nous utilisons Linux. Vous pouvez toutefois utiliser l'éditeur de texte de votre choix.
vim report.json
Collez le rapport dans report.json et enregistrez votre fichier.

Une fois que vous avez obtenu ces informations, utilisez aggregatable_report_converter.jar pour créer le rapport agrégable de débogage. Un rapport agrégable nommé report.avro est alors créé dans votre répertoire actuel.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Récupérer la clé de bucket à partir du rapport
Pour créer le fichier output_domain.avro, vous avez besoin des clés de bucket qui peuvent être récupérées dans les rapports.
Les clés de bucket sont conçues par la technologie publicitaire. Toutefois, dans ce cas, le site Privacy Sandbox Demo crée les clés de bucket. Étant donné que l'agrégation privée de ce site est en mode débogage, nous pouvons utiliser debug_cleartext_payload dans le corps du rapport pour obtenir la clé de bucket.
Copiez l'debug_cleartext_payload dans le corps du rapport.

Ouvrez goo.gle/ags-payload-decoder, collez votre debug_cleartext_payload dans la zone "INPUT" (ENTRÉE), puis cliquez sur "Decode" (Décoder).
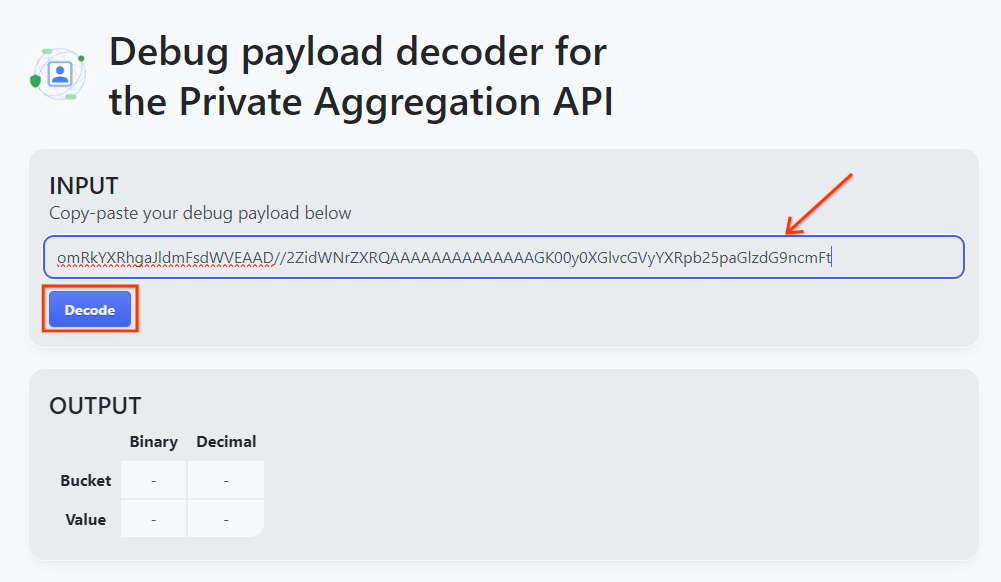
La page renvoie la valeur décimale de la clé de bucket. Vous trouverez ci-dessous un exemple de clé de bucket.
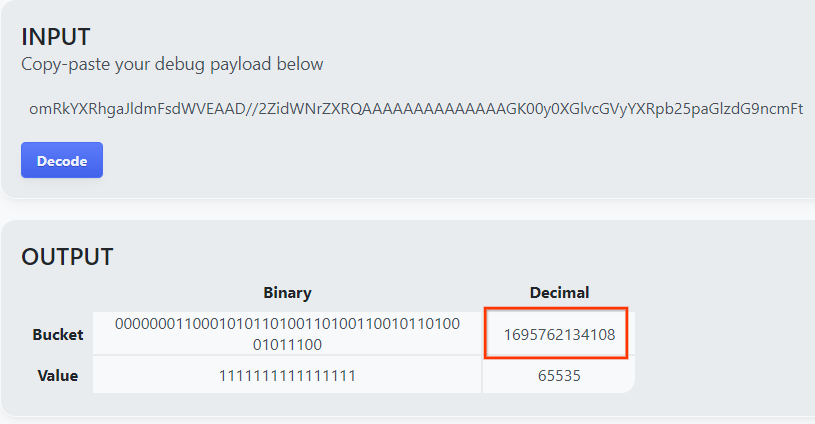
2.4. Créer un domaine de sortie AVRO
Maintenant que nous disposons de la clé de bucket, créons le output_domain.avro dans le même dossier que celui dans lequel nous avons travaillé. Veillez à remplacer la clé de bucket par celle que vous avez récupérée.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Le script crée le fichier output_domain.avro dans votre dossier actuel.
2.5. Créer des rapports récapitulatifs à l'aide de l'outil de test local
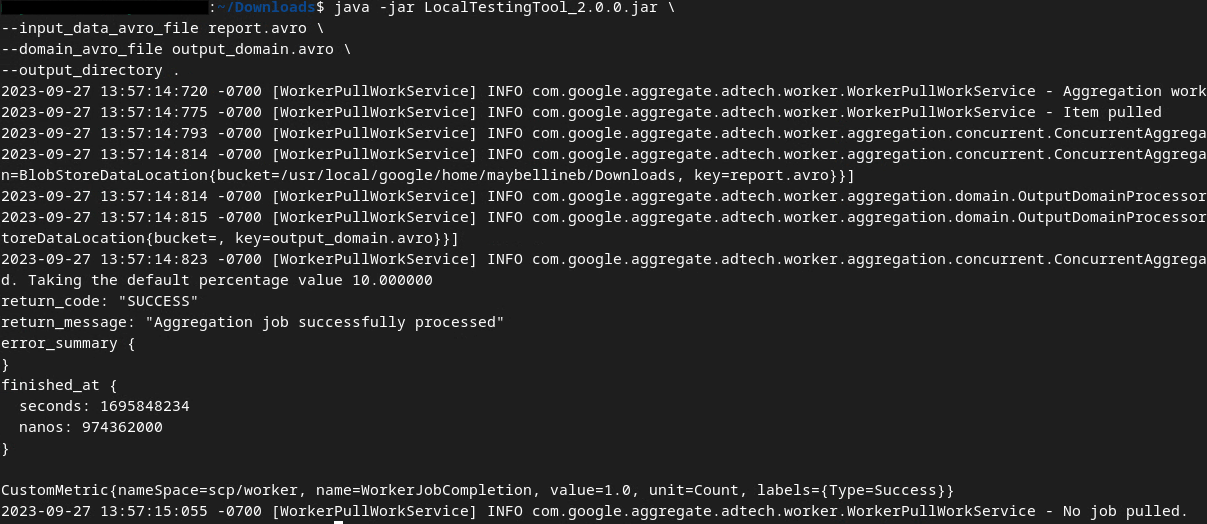
Nous utiliserons LocalTestingTool_{version}.jar, téléchargé dans la condition préalable 1.3, pour créer les rapports récapitulatifs à l'aide de la commande ci-dessous. Remplacez {version} par la version que vous avez téléchargée. N'oubliez pas de déplacer LocalTestingTool_{version}.jar vers le répertoire actuel ou d'ajouter un chemin relatif pour faire référence à son emplacement actuel.
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
Une fois la commande exécutée, un résultat semblable à celui ci-dessous doit s'afficher. Un rapport output.avro est créé une fois l'opération terminée.
2.6. Examiner le rapport récapitulatif
Le rapport récapitulatif créé est au format AVRO. Pour pouvoir le lire, vous devez le convertir du format AVRO au format JSON. Idéalement, la technologie publicitaire doit écrire du code pour convertir les rapports AVRO en JSON.
Nous allons utiliser aggregatable_report_converter.jar pour convertir le rapport AVRO en JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
Un rapport semblable à celui-ci est renvoyé. ainsi qu'un fichier output.json de rapport créé dans le même répertoire.

Atelier de programmation terminé !
Résumé:Vous avez collecté un rapport de débogage, créé un fichier de domaine de sortie et généré un rapport récapitulatif à l'aide de l'outil de test local qui simule le comportement d'agrégation du service d'agrégation.
Étapes suivantes:Maintenant que vous avez testé l'outil de test local, vous pouvez essayer le même exercice avec un déploiement en direct du service d'agrégation dans votre propre environnement. Passez en revue les conditions préalables pour vous assurer que vous avez tout configuré pour le mode "Service d'agrégation", puis passez à l'étape 3.
3. 3. Atelier de programmation sur le service d'agrégation
Durée estimée: 1 heure
Avant de commencer, assurez-vous d'avoir rempli toutes les conditions préalables associées à "Service d'agrégation".
Étapes de l'atelier de programmation
Étape 3.1. Création d'entrées pour le service d'agrégation: créez les rapports du service d'agrégation qui sont regroupés pour le service d'agrégation.
- Étape 3.1.1 Rapport sur les déclencheurs
- Étape 3.1.2 Collecter des rapports agrégables
- Étape 3.1.3 Convertir des rapports au format AVRO
- Étape 3.1.4 Créer un domaine AVRO output_domain
- Étape 3.1.5 Déplacer des rapports vers un bucket Cloud Storage
Étape 3.2. Utilisation du service d'agrégation: utilisez l'API Service Aggregation pour créer et consulter des rapports récapitulatifs.
- Étape 3.2.1 Utiliser le point de terminaison
createJobpour effectuer des lots - Étape 3.2.2 Utiliser le point de terminaison
getJobpour récupérer l'état d'un lot - Étape 3.2.3 Examiner le rapport récapitulatif
3.1. Création d'entrées de service d'agrégation
Créez les rapports AVRO à envoyer par lot au service d'agrégation. Les commandes shell de ces étapes peuvent être exécutées dans Cloud Shell de GCP (à condition que les dépendances des conditions préalables soient clonées dans votre environnement Cloud Shell) ou dans un environnement d'exécution local.
3.1.1. Rapport sur les déclencheurs
Suivez le lien pour accéder au site, puis consultez les rapports sur chrome://private-aggregation-internals:
Le rapport envoyé au point de terminaison {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage se trouve également dans le corps des rapports affichés sur la page "Chrome Internals".
Vous verrez peut-être de nombreux rapports ici, mais pour cet atelier de programmation, utilisez le rapport agrégable spécifique à GCP et généré par le point de terminaison de débogage. L'URL du rapport contiendra "/debug/", et le aggregation_coordinator_origin field du corps du rapport contiendra l'URL suivante: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
3.1.2. Collecter des rapports agrégables
Collectez vos rapports agrégables à partir des points de terminaison .well-known de votre API correspondante.
- Private Aggregation:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - Attribution Reporting - Summary Report (Rapport récapitulatif sur l'attribution) :
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
Pour cet atelier de programmation, nous effectuons la collecte des rapports manuellement. En production, les technologies publicitaires doivent collecter et convertir les rapports de manière programmatique.
Copions le rapport JSON dans le corps du rapport de chrome://private-aggregation-internals.
Dans cet exemple, nous utilisons vim, car nous utilisons Linux. Vous pouvez toutefois utiliser l'éditeur de texte de votre choix.
vim report.json
Collez le rapport dans report.json et enregistrez votre fichier.
3.1.3. Convertir des rapports au format AVRO
Les rapports reçus des points de terminaison .well-known sont au format JSON et doivent être convertis au format de rapport AVRO. Une fois que vous avez le rapport JSON, accédez à l'emplacement où report.json est stocké et utilisez aggregatable_report_converter.jar pour créer le rapport de débogage agrégable. Un rapport agrégable nommé report.avro est alors créé dans votre répertoire actuel.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. Créer un domaine AVRO output_domain
Pour créer le fichier output_domain.avro, vous avez besoin des clés de bucket qui peuvent être récupérées dans les rapports.
Les clés de bucket sont conçues par la technologie publicitaire. Toutefois, dans ce cas, le site Privacy Sandbox Demo crée les clés de bucket. Étant donné que l'agrégation privée pour ce site est en mode débogage, nous pouvons utiliser debug_cleartext_payload dans le corps du rapport pour obtenir la clé de bucket.
Copiez l'debug_cleartext_payload dans le corps du rapport.
Ouvrez goo.gle/ags-payload-decoder, collez votre debug_cleartext_payload dans la zone "INPUT" (ENTRÉE), puis cliquez sur "Decode" (Décoder).
La page renvoie la valeur décimale de la clé de bucket. Vous trouverez ci-dessous un exemple de clé de bucket.
Maintenant que nous disposons de la clé de bucket, créons le output_domain.avro dans le même dossier que celui dans lequel nous avons travaillé. Veillez à remplacer la clé de bucket par celle que vous avez récupérée.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Le script crée le fichier output_domain.avro dans votre dossier actuel.
3.1.5. Déplacer des rapports vers un bucket Cloud Storage
Une fois les rapports AVRO et le domaine de sortie créés, déplacez-les dans le bucket Cloud Storage (que vous avez noté dans la condition préalable 1.6).
Si la CLI gcloud est configurée dans votre environnement local, utilisez les commandes ci-dessous pour copier les fichiers dans les dossiers correspondants.
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
Dans le cas contraire, importez les fichiers manuellement dans votre bucket. Créez un dossier nommé "rapports" et importez-y le fichier report.avro. Créez un dossier nommé "output_domains" et importez-y le fichier output_domain.avro.
3.2. Utilisation du service d'agrégation
Dans le prérequis 1.8, vous avez sélectionné cURL ou Postman pour envoyer des requêtes API aux points de terminaison du service d'agrégation. Vous trouverez ci-dessous les instructions pour les deux options.
Si votre tâche échoue et qu'une erreur s'affiche, consultez notre documentation de dépannage sur GitHub pour savoir comment procéder.
3.2.1. Utiliser le point de terminaison createJob pour effectuer des lots
Suivez les instructions cURL ou Postman ci-dessous pour créer une tâche.
cURL
Dans le "Terminal", créez un fichier de corps de requête (body.json) et collez-y le code ci-dessous. Veillez à modifier les valeurs des espaces réservés. Pour en savoir plus sur ce que représente chaque champ, consultez la documentation de l'API.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Exécutez la requête suivante. Remplacez les espaces réservés dans l'URL de la requête cURL par les valeurs de frontend_service_cloudfunction_url, qui sont affichées une fois le déploiement Terraform terminé dans l'étape préalable 1.6.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
Vous devriez recevoir une réponse HTTP 202 une fois la requête acceptée par le service d'agrégation. Les autres codes de réponse possibles sont documentés dans les spécifications de l'API.
Postman
Pour le point de terminaison createJob, un corps de requête est requis pour fournir au service d'agrégation l'emplacement et les noms de fichiers des rapports agrégables, des domaines de sortie et des rapports récapitulatifs.
Accédez à l'onglet "Body" (Corps) de la requête createJob:

Remplacez les espaces réservés dans le fichier JSON fourni. Pour en savoir plus sur ces champs et ce qu'ils représentent, consultez la documentation de l'API.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
"Envoyer" la requête API createJob:

Le code de réponse se trouve dans la moitié inférieure de la page:

Vous devriez recevoir une réponse HTTP 202 une fois la requête acceptée par le service d'agrégation. Les autres codes de réponse possibles sont documentés dans les spécifications de l'API.
3.2.2. Utiliser le point de terminaison getJob pour récupérer l'état d'un lot
Suivez les instructions ci-dessous pour obtenir une tâche à l'aide de cURL ou de Postman.
cURL
Exécutez la requête ci-dessous dans votre terminal. Remplacez les espaces réservés de l'URL par les valeurs de frontend_service_cloudfunction_url, qui est la même URL que celle que vous avez utilisée pour la requête createJob. Pour "job_request_id", utilisez la valeur de la tâche que vous avez créée avec le point de terminaison createJob.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
Le résultat doit renvoyer l'état de votre requête d'emploi avec un code d'état HTTP 200. Le corps de la requête contient les informations nécessaires, telles que job_status, return_message et error_messages (si la tâche a généré une erreur).
Postman
Pour vérifier l'état de la demande de tâche, vous pouvez utiliser le point de terminaison getJob. Dans la section "Params" de la requête getJob, remplacez la valeur job_request_id par celle qui a été envoyée dans la requête createJob.job_request_id
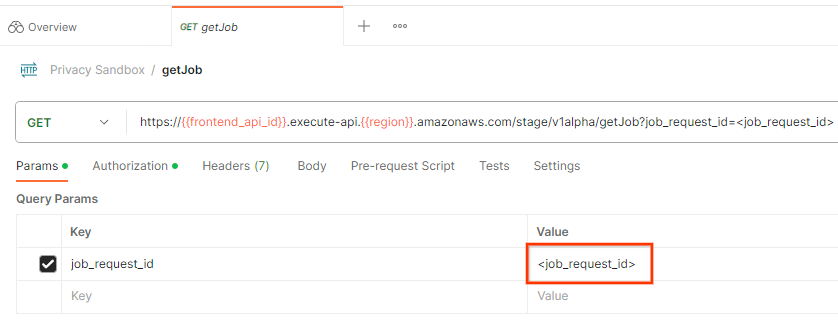
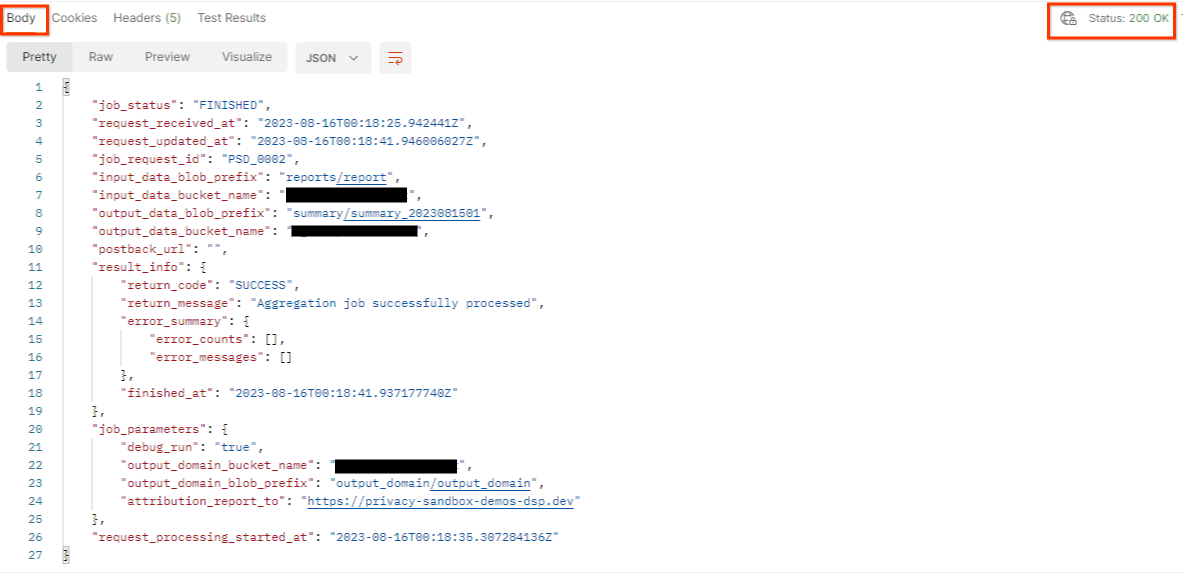
"Envoyer" la requête getJob:

Le résultat doit renvoyer l'état de votre requête d'emploi avec un code d'état HTTP 200. Le corps de la requête contient les informations nécessaires, telles que job_status, return_message et error_messages (si la tâche a généré une erreur).
3.2.3. Examiner le rapport récapitulatif
Une fois que vous avez reçu votre rapport récapitulatif dans votre bucket Cloud Storage de sortie, vous pouvez le télécharger dans votre environnement local. Les rapports récapitulatifs sont au format AVRO et peuvent être convertis en JSON. Vous pouvez utiliser aggregatable_report_converter.jar pour lire votre rapport à l'aide de la commande ci-dessous.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
Cela renvoie un fichier JSON des valeurs agrégées de chaque clé de bucket, qui ressemble à celui ci-dessous.

Si votre requête createJob inclut debug_run comme "true", vous pouvez recevoir votre rapport récapitulatif dans le dossier de débogage situé dans output_data_blob_prefix. Le rapport est au format AVRO et peut être converti au format JSON à l'aide de la commande ci-dessus.
Le rapport contient la clé de bucket, la métrique non bruitée et le bruit ajouté à la métrique non bruitée pour former le rapport récapitulatif. Le rapport ressemble à celui ci-dessous.

Les annotations contiennent également "in_reports" et/ou "in_domain", ce qui signifie:
- in_reports : la clé de bucket est disponible dans les rapports agrégables.
- in_domain : la clé du bucket est disponible dans le fichier AVRO output_domain.
Atelier de programmation terminé !
Résumé:Vous avez déployé le service d'agrégation dans votre propre environnement cloud, collecté un rapport de débogage, créé un fichier de domaine de sortie, stocké ces fichiers dans un bucket Cloud Storage et exécuté une tâche avec succès.
Étapes suivantes:continuez à utiliser le service d'agrégation dans votre environnement ou supprimez les ressources cloud que vous venez de créer en suivant les instructions de nettoyage de l'étape 4.
4. 4. Effectuer un nettoyage
Pour supprimer les ressources créées pour le service d'agrégation via Terraform, utilisez la commande destroy dans les dossiers adtech_setup et dev (ou un autre environnement) :
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
Pour supprimer le bucket Cloud Storage contenant vos rapports agrégables et vos rapports récapitulatifs:
$ gcloud storage buckets delete gs://my-bucket
Vous pouvez également choisir de rétablir les paramètres des cookies Chrome de l'étape 1.2 à leur état précédent.
5. 5. Annexe
Fichier adtech_setup.auto.tfvars d'exemple
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
Fichier dev.auto.tfvars d'exemple
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20