
1. 1. 기본 요건
예상 소요 시간: 1~2시간
이 Codelab을 실행하는 방법에는 로컬 테스트와 집계 서비스의 두 가지 모드가 있습니다. 로컬 테스트 모드에는 로컬 머신과 Chrome 브라우저가 필요합니다 (Google Cloud 리소스 생성/사용 불가). 집계 서비스 모드를 사용하려면 Google Cloud에 집계 서비스를 완전히 배포해야 합니다.
두 모드 중 하나에서 이 Codelab을 실행하려면 몇 가지 기본 요건이 필요합니다. 각 요구사항은 로컬 테스트 또는 집계 서비스에 필요한지 여부에 따라 적절하게 표시됩니다.
1.1. 등록 및 증명 완료 (집계 서비스)
개인 정보 보호 샌드박스 API를 사용하려면 Chrome과 Android 모두에서 등록 및 증명을 완료해야 합니다.
1.2. 광고 개인 정보 보호 API (로컬 테스트 및 집계 서비스) 사용 설정
개인 정보 보호 샌드박스를 사용할 예정이므로 개인 정보 보호 샌드박스 광고 API를 사용 설정하는 것이 좋습니다.
브라우저에서 chrome://settings/adPrivacy로 이동하여 모든 광고 개인 정보 보호 API를 사용 설정합니다.
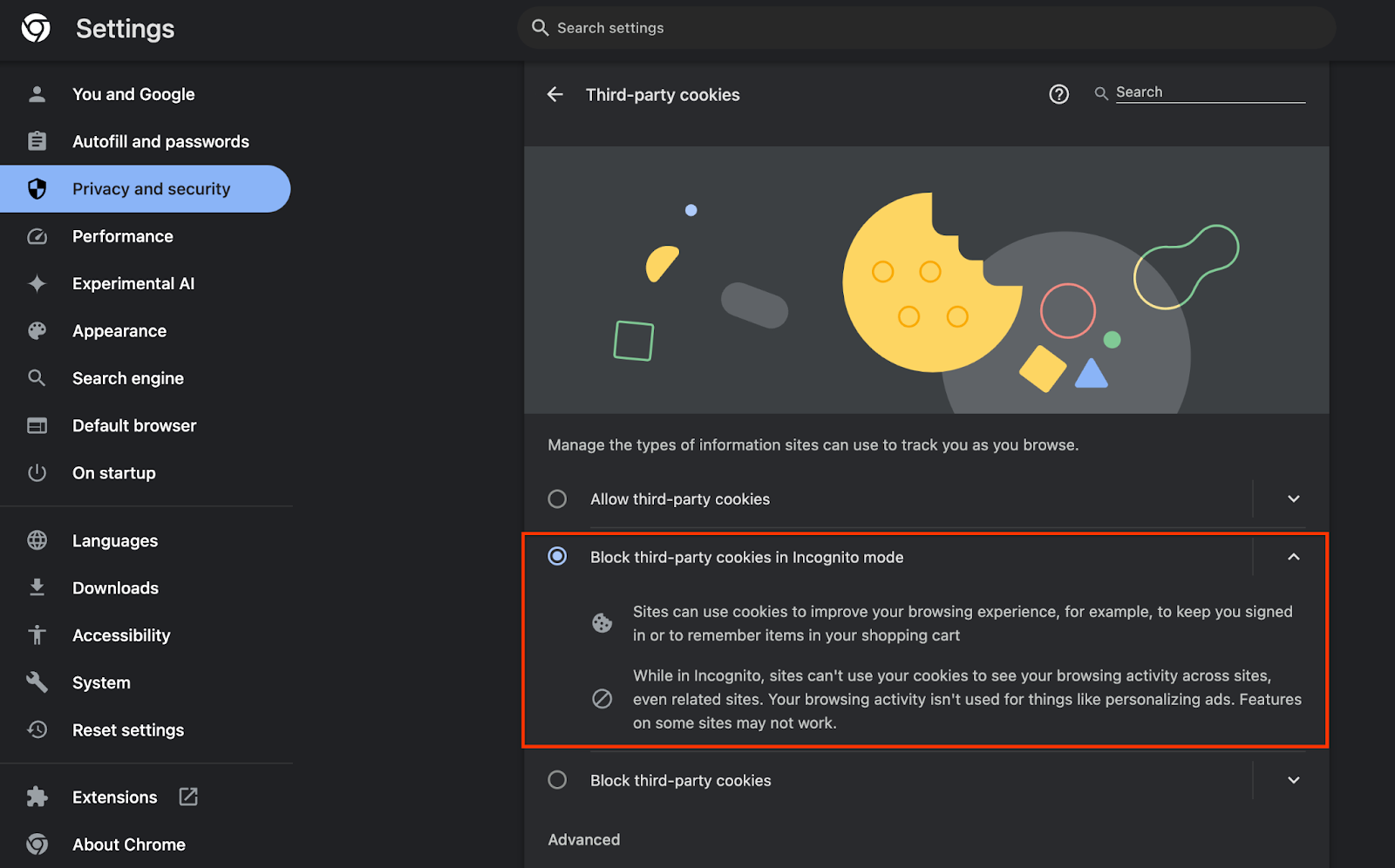
또한 서드 파티 쿠키가 사용 설정되어 있는지 확인합니다.
chrome://settings/cookies에서 서드 파티 쿠키가 차단되지 않았는지 확인합니다. Chrome 버전에 따라 이 설정 메뉴에 표시되는 옵션이 다를 수 있지만 허용되는 구성은 다음과 같습니다.
- '모든 서드 파티 쿠키 차단' = 사용 중지됨
- '서드 파티 쿠키 차단' = 사용 중지됨
- '시크릿 모드에서 서드 파티 쿠키 차단' = 사용 설정됨
1.3. 로컬 테스트 도구 다운로드 (로컬 테스트)
로컬 테스트를 실행하려면 로컬 테스트 도구를 다운로드해야 합니다. 이 도구는 암호화되지 않은 디버그 보고서에서 요약 보고서를 생성합니다.
로컬 테스트 도구는 GitHub의 Cloud Functions JAR 보관 파일에서 다운로드할 수 있습니다. 이름은 LocalTestingTool_{version}.jar여야 합니다.
1.4. JAVA JRE가 설치되어 있는지 확인 (로컬 테스트 및 집계 서비스)
'터미널'을 열고 java --version를 사용하여 머신에 Java 또는 openJDK가 설치되어 있는지 확인합니다.

Java가 설치되어 있지 않으면 Java 사이트 또는 openJDK 사이트에서 다운로드하여 설치할 수 있습니다.
1.5. aggregatable_report_converter 다운로드 (로컬 테스트 및 집계 서비스)
개인 정보 보호 샌드박스 데모 GitHub 저장소에서 aggregatable_report_converter의 사본을 다운로드할 수 있습니다. GitHub 저장소에 IntelliJ 또는 Eclipse 사용이 언급되어 있지만 둘 다 필수는 아닙니다. 이러한 도구를 사용하지 않는 경우 대신 JAR 파일을 로컬 환경에 다운로드하세요.
1.6. GCP 환경 설정 (집계 서비스)
집계 서비스에는 클라우드 제공업체를 사용하는 신뢰할 수 있는 실행 환경을 사용해야 합니다. 이 Codelab에서는 집계 서비스를 GCP에 배포하지만 AWS도 지원됩니다.
GitHub의 배포 안내에 따라 gcloud CLI를 설정하고, Terraform 바이너리 및 모듈을 다운로드하고, 집계 서비스의 GCP 리소스를 만듭니다.
배포 안내의 주요 단계는 다음과 같습니다.
- 환경에서 'gcloud' CLI 및 Terraform을 설정합니다.
- Terraform 상태를 저장할 Cloud Storage 버킷을 만듭니다.
- 종속 항목을 다운로드합니다.
adtech_setup.auto.tfvars를 업데이트하고adtech_setupTerraform을 실행합니다.adtech_setup.auto.tfvars파일의 예는 부록을 참고하세요. 여기에서 생성된 데이터 버킷의 이름을 알아두세요. 이 이름은 codelab에서 생성한 파일을 저장하는 데 사용됩니다.dev.auto.tfvars를 업데이트하고, 배포 서비스 계정을 가장하고,devTerraform을 실행합니다.dev.auto.tfvars파일의 예는 부록을 참고하세요.- 배포가 완료되면 나중에 집계 서비스에 요청하는 데 필요한 Terraform 출력에서
frontend_service_cloudfunction_url을 캡처합니다.
1.7. 집계 서비스 온보딩 완료 (집계 서비스)
집계 서비스를 사용하려면 코디네이터에게 온보딩해야 합니다. 보고 사이트 및 기타 정보를 제공하고 'Google Cloud'를 선택한 후 서비스 계정 주소를 입력하여 집계 서비스 온보딩 양식을 작성합니다. 이 서비스 계정은 이전 기본 요건 (1.6. GCP 환경 설정). (도움말: 제공된 기본 이름을 사용하는 경우 이 서비스 계정은 'worker-sa@'로 시작합니다.)
온보딩 프로세스가 완료될 때까지 최대 2주가 걸릴 수 있습니다.
1.8. API 엔드포인트를 호출하는 메서드 결정 (집계 서비스)
이 Codelab에서는 집계 서비스 API 엔드포인트를 호출하는 두 가지 옵션인 cURL과 Postman을 제공합니다. cURL은 최소한의 설정과 추가 소프트웨어 없이 터미널에서 API 엔드포인트를 더 빠르고 쉽게 호출할 수 있는 방법입니다. 하지만 cURL을 사용하고 싶지 않다면 Postman을 사용하여 API 요청을 실행하고 나중에 사용할 수 있도록 저장할 수 있습니다.
3.2 섹션 집계 서비스 사용량에서 두 옵션을 모두 사용하는 방법에 관한 자세한 안내를 확인할 수 있습니다. 이제 미리 보고 어떤 방법을 사용할지 결정할 수 있습니다. Postman을 선택하는 경우 다음과 같이 초기 설정을 실행합니다.
1.8.1. 작업공간 설정
Postman 계정에 가입합니다. 가입하면 작업공간이 자동으로 생성됩니다.
작업공간이 생성되지 않은 경우 '작업공간' 상단 탐색 메뉴로 이동하여 '작업공간 만들기'를 선택합니다.
'빈 워크스페이스'를 선택하고 다음을 클릭한 다음 'GCP 개인 정보 보호 샌드박스'라는 이름을 지정합니다. '개인'을 선택하고 '만들기'를 클릭합니다.
사전 구성된 워크스페이스 JSON 구성 및 전역 환경 파일을 다운로드합니다.
'가져오기' 버튼을 통해 두 JSON 파일을 모두 '내 워크스페이스'로 가져옵니다.

이렇게 하면 createJob 및 getJob HTTP 요청과 함께 'GCP 개인 정보 보호 샌드박스' 컬렉션이 생성됩니다.
1.8.2. 승인 설정하기
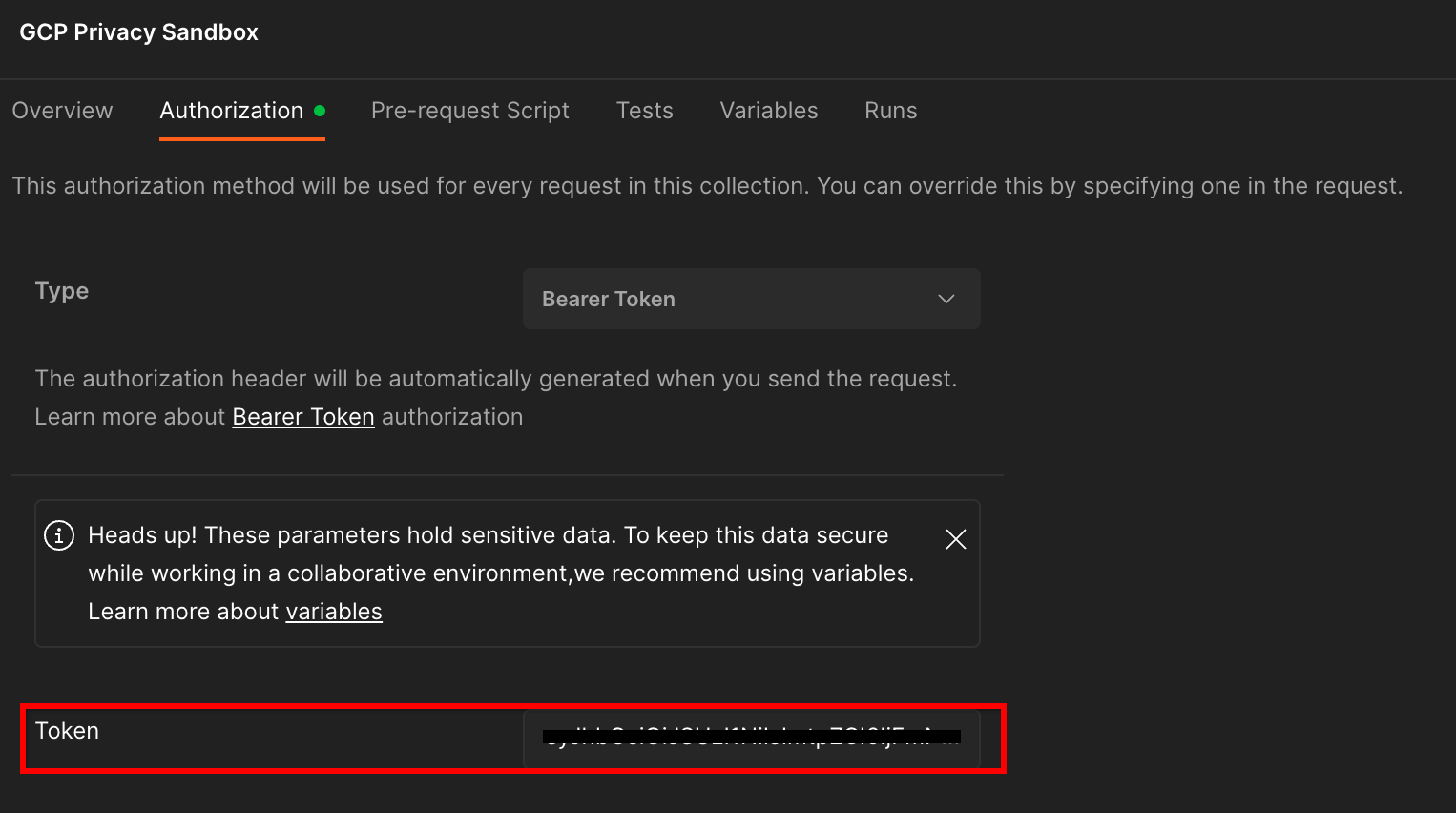
'GCP 개인 정보 보호 샌드박스' 컬렉션을 클릭하고 '승인' 탭으로 이동합니다.

'Bearer 토큰' 메서드를 사용합니다. 터미널 환경에서 이 명령어를 실행하고 출력을 복사합니다.
gcloud auth print-identity-token
그런 다음 Postman 승인 탭의 '토큰' 입력란에 이 토큰 값을 붙여넣습니다.
1.8.3. 환경 설정
오른쪽 상단의 '환경 빠른 보기'로 이동합니다.
'수정'을 클릭하고 'environment', 'region', 'cloud-function-id'의 '현재 값'을 업데이트합니다.
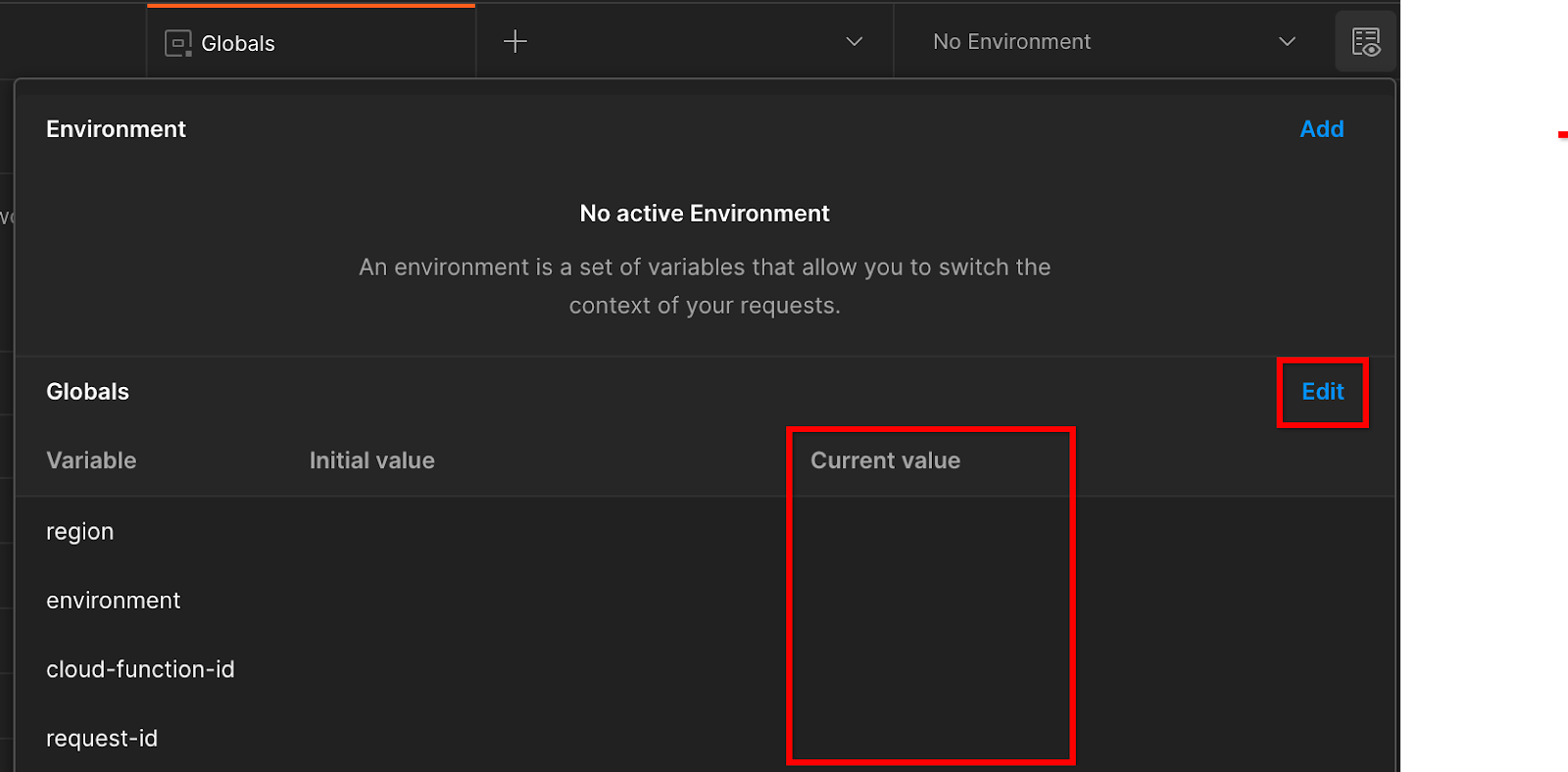
'request-id'는 나중에 Google에서 입력하므로 지금은 비워 두셔도 됩니다. 다른 필드의 경우 기본 요건 1.6의 Terraform 배포 완료 시 반환된 frontend_service_cloudfunction_url의 값을 사용합니다. URL 형식은 https://입니다.
2. 2. 로컬 테스트 Codelab
예상 소요 시간: 1시간 미만
컴퓨터의 로컬 테스트 도구를 사용하여 집계를 실행하고 암호화되지 않은 디버그 보고서를 사용하여 요약 보고서를 생성할 수 있습니다. 시작하기 전에 '로컬 테스트'로 라벨이 지정된 모든 기본 요건을 완료했는지 확인하세요.
Codelab 단계
2.1단계. 보고서 트리거: 보고서를 수집할 수 있도록 비공개 집계 보고를 트리거합니다.
2.2단계. 디버그 AVRO 보고서 만들기: 수집된 JSON 보고서를 AVRO 형식 보고서로 변환합니다. 이 단계는 광고 기술이 API 보고 엔드포인트에서 보고서를 수집하고 JSON 보고서를 AVRO 형식 보고서로 변환하는 것과 유사합니다.
2.3단계. 버킷 키 가져오기: 버킷 키는 광고 기술에서 설계합니다. 이 Codelab에서는 버킷이 사전 정의되어 있으므로 제공된 대로 버킷 키를 검색합니다.
2.4단계. 출력 도메인 AVRO 만들기: 버킷 키를 가져온 후 출력 도메인 AVRO 파일을 만듭니다.
2.5단계. 요약 보고서 만들기: 로컬 테스트 도구를 사용하여 로컬 환경에서 요약 보고서를 만들 수 있습니다.
2.6단계. 요약 보고서 검토: 로컬 테스트 도구에서 생성한 요약 보고서를 검토합니다.
2.1. 트리거 보고서
비공개 집계 보고서를 트리거하려면 개인 정보 보호 샌드박스 데모 사이트 (https://privacy-sandbox-demos-news.dev/?env=gcp) 또는 자체 사이트 (예: https://adtechexample.com)를 사용하면 됩니다. 자체 사이트를 사용 중이며 등록 및 증명, 집계 서비스 온보딩을 완료하지 않은 경우 Chrome 플래그 및 CLI 스위치를 사용해야 합니다.
이 데모에서는 개인 정보 보호 샌드박스 데모 사이트를 사용합니다. 링크를 따라 사이트로 이동한 다음 chrome://private-aggregation-internals에서 보고서를 확인할 수 있습니다.
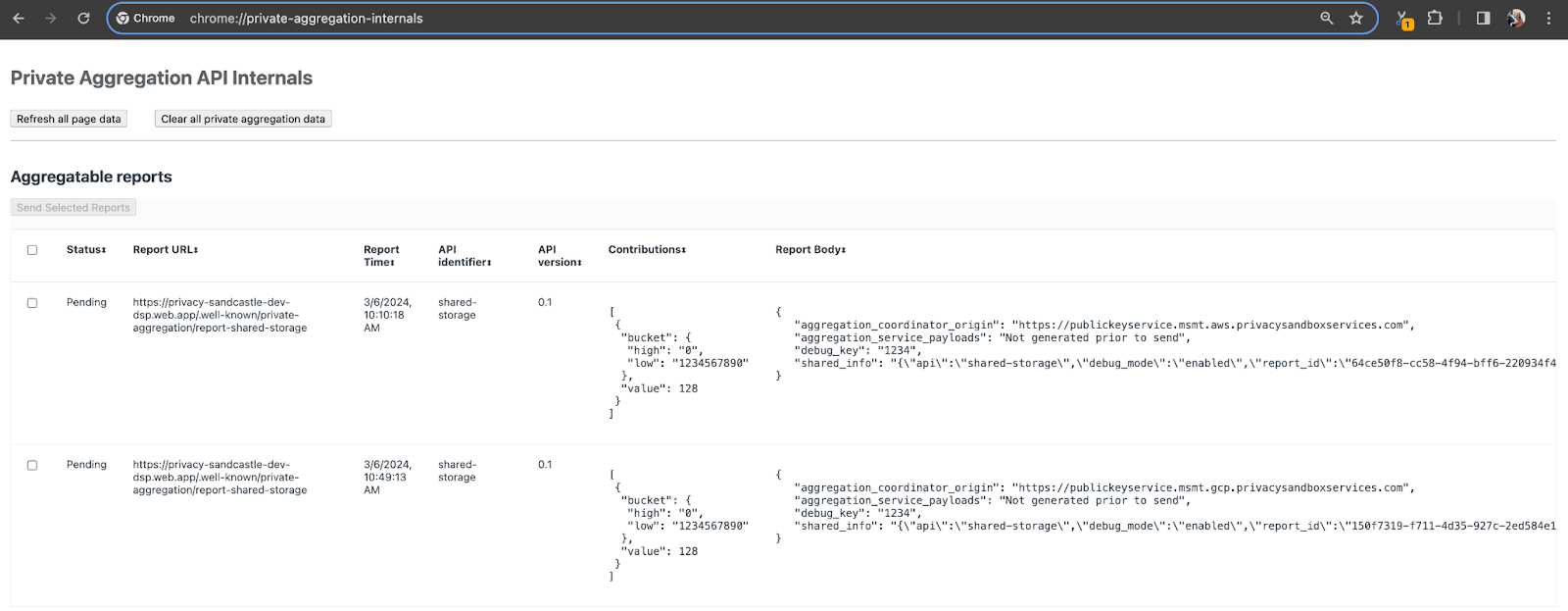
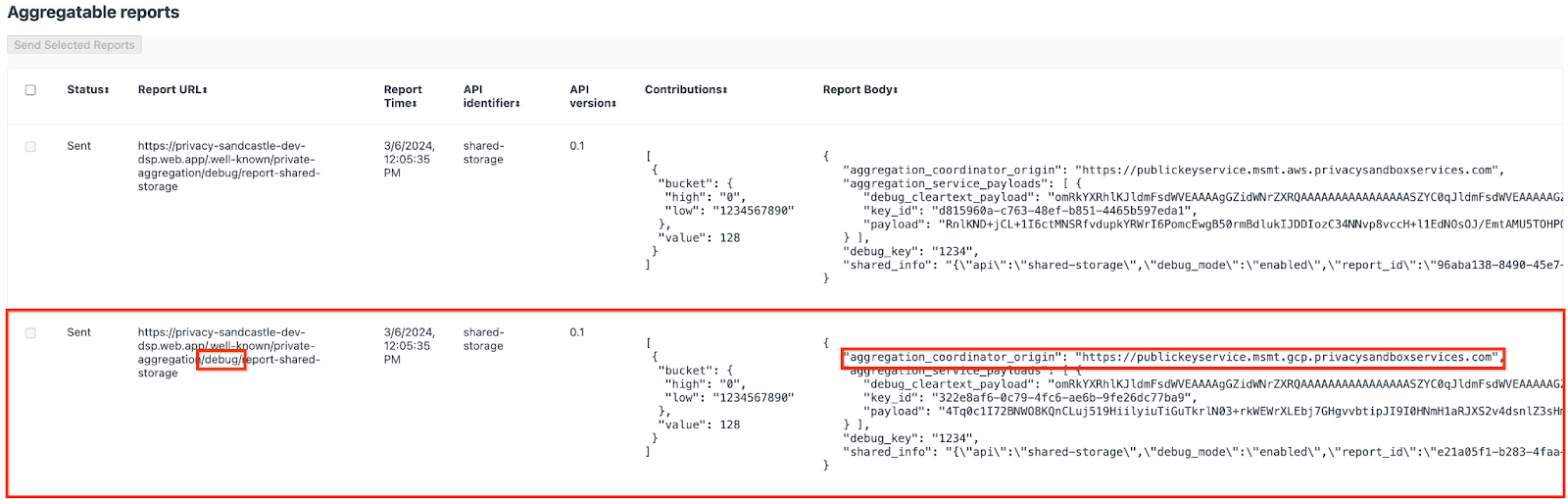
{reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage 엔드포인트로 전송되는 보고서는 Chrome 내부 페이지에 표시되는 보고서의 '보고서 본문'에서도 확인할 수 있습니다.
여기에는 여러 보고서가 표시될 수 있지만 이 Codelab에서는 디버그 엔드포인트에서 생성된 GCP용 집계 가능한 보고서를 사용하세요. 'Report URL'에는 '/debug/'가 포함되고 'Report Body'의 aggregation_coordinator_origin field에는 https://publickeyservice.msmt.gcp.privacysandboxservices.com URL이 포함됩니다.
2.2. 집계 가능한 디버그 보고서 만들기
chrome://private-aggregation-internals의 'Report Body'(보고서 본문)에 있는 보고서를 복사하고 privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar 폴더(요구사항 1.5에서 다운로드한 저장소 내)에 JSON 파일을 만듭니다.
이 예에서는 Linux를 사용하고 있으므로 vim을 사용합니다. 하지만 원하는 텍스트 편집기를 사용할 수 있습니다.
vim report.json
보고서를 report.json에 붙여넣고 파일을 저장합니다.

그런 다음 aggregatable_report_converter.jar를 사용하여 집계 가능한 디버그 보고서를 만듭니다. 그러면 현재 디렉터리에 집계 가능한 report.avro 보고서가 생성됩니다.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. 보고서에서 버킷 키 가져오기
output_domain.avro 파일을 만들려면 보고서에서 가져올 수 있는 버킷 키가 필요합니다.
버킷 키는 애드테크에서 설계합니다. 하지만 이 경우 개인 정보 보호 샌드박스 데모 사이트에서 버킷 키를 만듭니다. 이 사이트의 비공개 집계가 디버그 모드이므로 '보고서 본문'의 debug_cleartext_payload을 사용하여 버킷 키를 가져올 수 있습니다.
보고서 본문에서 debug_cleartext_payload를 복사합니다.

goo.gle/ags-payload-decoder를 열고 debug_cleartext_payload를 'INPUT' 상자에 붙여넣은 다음 'Decode'를 클릭합니다.
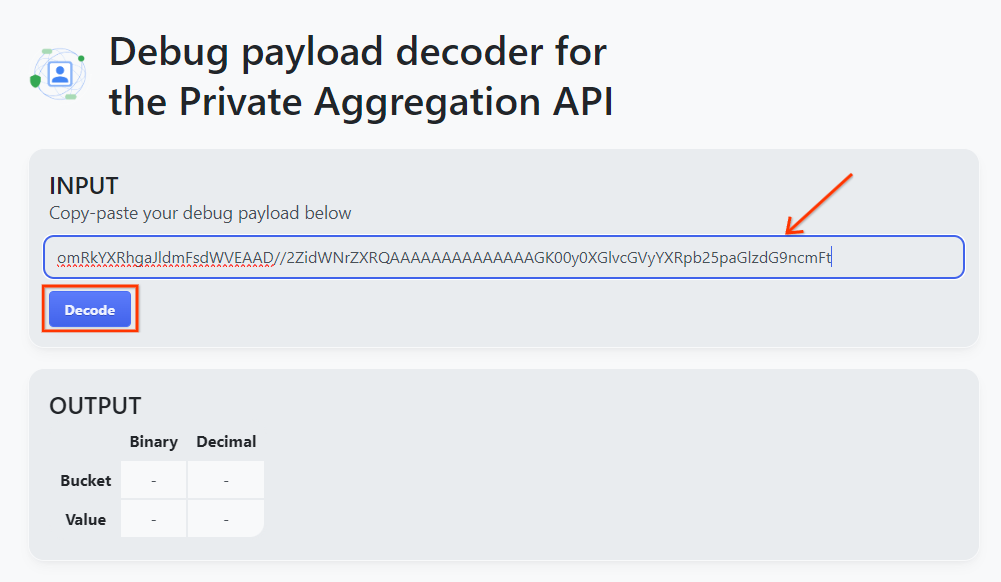
페이지는 버킷 키의 십진수 값을 반환합니다. 다음은 샘플 버킷 키입니다.
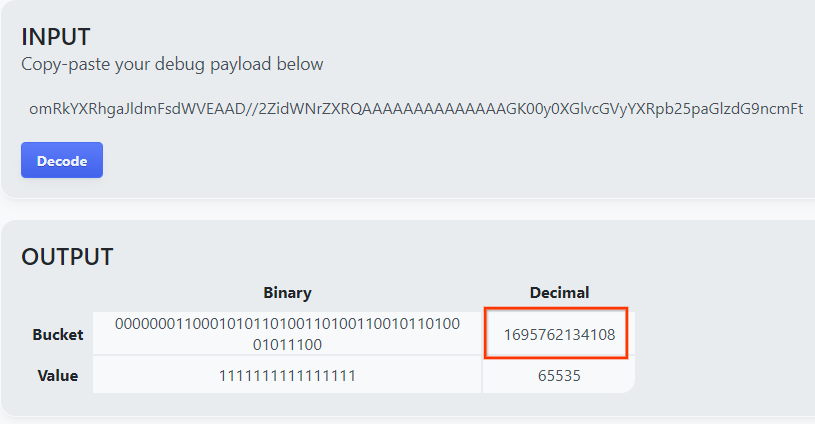
2.4. 출력 도메인 AVRO 만들기
이제 버킷 키가 있으므로 작업한 폴더에서 output_domain.avro를 만들어 보겠습니다. 버킷 키를 가져온 버킷 키로 바꿔야 합니다.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
스크립트가 현재 폴더에 output_domain.avro 파일을 만듭니다.
2.5. 로컬 테스트 도구를 사용하여 요약 보고서 만들기
기본 요건 1.3에서 다운로드한 LocalTestingTool_{version}.jar를 사용하여 아래 명령어를 통해 요약 보고서를 만듭니다. {version}을 다운로드한 버전으로 바꿉니다. LocalTestingTool_{version}.jar를 현재 디렉터리로 이동하거나 상대 경로를 추가하여 현재 위치를 참조해야 합니다.
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
명령어를 실행하면 아래와 비슷한 내용이 표시됩니다. 이 작업이 완료되면 보고서 output.avro가 생성됩니다.
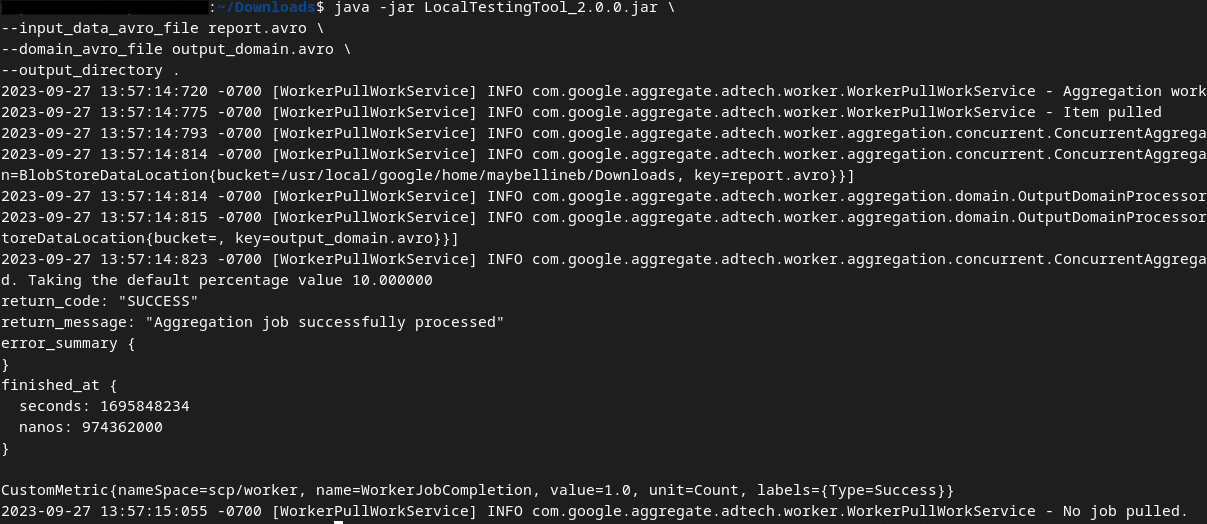
2.6. 요약 보고서 검토
생성된 요약 보고서는 AVRO 형식입니다. 이를 읽으려면 AVRO에서 JSON 형식으로 변환해야 합니다. 이상적으로는 광고 기술에서 AVRO 보고서를 JSON으로 다시 변환하는 코드를 작성해야 합니다.
aggregatable_report_converter.jar를 사용하여 AVRO 보고서를 JSON으로 다시 변환합니다.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
그러면 다음과 유사한 보고서가 반환됩니다. 같은 디렉터리에 생성된 보고서 output.json와 함께

Codelab이 완료되었습니다.
요약: 집계 서비스의 집계 동작을 시뮬레이션하는 로컬 테스트 도구를 사용하여 디버그 보고서를 수집하고, 출력 도메인 파일을 구성하고, 요약 보고서를 생성했습니다.
다음 단계: 이제 로컬 테스트 도구를 실험했으므로 자체 환경에서 집계 서비스의 실시간 배포를 사용하여 동일한 연습을 시도해 볼 수 있습니다. 기본 요건을 다시 검토하여 '집계 서비스' 모드에 맞게 모든 항목을 설정했는지 확인한 다음 3단계로 진행합니다.
3. 3. 집계 서비스 Codelab
예상 소요 시간: 1시간
시작하기 전에 '집계 서비스'로 라벨이 지정된 모든 기본 요건을 완료했는지 확인하세요.
Codelab 단계
3.1단계. 집계 서비스 입력 생성: 집계 서비스에 일괄 처리되는 집계 서비스 보고서를 만듭니다.
- 3.1.1단계. 트리거 보고서
- 3.1.2단계. 집계 가능한 보고서 수집
- 3.1.3단계. 보고서를 AVRO로 변환
- 3.1.4단계. output_domain AVRO 만들기
- 3.1.5단계. 보고서를 Cloud Storage 버킷으로 이동
3.2단계. 집계 서비스 사용: 집계 서비스 API를 사용하여 요약 보고서를 만들고 요약 보고서를 검토합니다.
- 3.2.1단계
createJob엔드포인트를 사용하여 일괄 처리 - 3.2.2단계.
getJob엔드포인트를 사용하여 일괄 처리 상태 검색 - 3.2.3단계. 요약 보고서 검토
3.1. 집계 서비스 입력 생성
집계 서비스에 일괄 처리하기 위한 AVRO 보고서를 만듭니다. 이 단계의 셸 명령어는 기본 요건의 종속 항목이 Cloud Shell 환경에 클론된 경우 GCP의 Cloud Shell 내에서 실행하거나 로컬 실행 환경에서 실행할 수 있습니다.
3.1.1. 트리거 보고서
링크를 따라 사이트로 이동한 다음 chrome://private-aggregation-internals에서 보고서를 확인할 수 있습니다.
{reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage 엔드포인트로 전송되는 보고서는 Chrome 내부 페이지에 표시되는 보고서의 '보고서 본문'에서도 확인할 수 있습니다.
여기에는 여러 보고서가 표시될 수 있지만 이 Codelab에서는 디버그 엔드포인트에서 생성된 GCP용 집계 가능한 보고서를 사용하세요. 'Report URL'에는 '/debug/'가 포함되고 'Report Body'의 aggregation_coordinator_origin field에는 https://publickeyservice.msmt.gcp.privacysandboxservices.com URL이 포함됩니다.
3.1.2. 집계 가능한 보고서 수집
해당 API의 .well-known 엔드포인트에서 집계 가능한 보고서를 수집합니다.
- 비공개 집계:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - Attribution Reporting - Summary Report(기여 분석 보고서 - 요약 보고서):
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
이 Codelab에서는 보고서 수집을 수동으로 실행합니다. 프로덕션에서는 광고 기술이 프로그래매틱 방식으로 보고서를 수집하고 변환해야 합니다.
chrome://private-aggregation-internals의 'Report Body'에 있는 JSON 보고서를 복사해 보겠습니다.
이 예에서는 Linux를 사용하고 있으므로 vim을 사용합니다. 하지만 원하는 텍스트 편집기를 사용할 수 있습니다.
vim report.json
보고서를 report.json에 붙여넣고 파일을 저장합니다.
3.1.3. 보고서를 AVRO로 변환
.well-known 엔드포인트에서 수신된 보고서는 JSON 형식이며 AVRO 보고서 형식으로 변환해야 합니다. JSON 보고서가 있으면 report.json가 저장된 위치로 이동하여 aggregatable_report_converter.jar를 사용하여 집계 가능한 디버그 보고서를 만듭니다. 그러면 현재 디렉터리에 집계 가능한 report.avro 보고서가 생성됩니다.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. output_domain AVRO 만들기
output_domain.avro 파일을 만들려면 보고서에서 가져올 수 있는 버킷 키가 필요합니다.
버킷 키는 애드테크에서 설계합니다. 하지만 이 경우 개인 정보 보호 샌드박스 데모 사이트에서 버킷 키를 만듭니다. 이 사이트의 비공개 집계가 디버그 모드이므로 '보고서 본문'의 debug_cleartext_payload을 사용하여 버킷 키를 가져올 수 있습니다.
보고서 본문에서 debug_cleartext_payload를 복사합니다.
goo.gle/ags-payload-decoder를 열고 debug_cleartext_payload를 'INPUT' 상자에 붙여넣은 다음 'Decode'를 클릭합니다.
페이지는 버킷 키의 십진수 값을 반환합니다. 다음은 샘플 버킷 키입니다.
이제 버킷 키가 있으므로 작업한 폴더에서 output_domain.avro를 만들어 보겠습니다. 버킷 키를 가져온 버킷 키로 바꿔야 합니다.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
스크립트가 현재 폴더에 output_domain.avro 파일을 만듭니다.
3.1.5. 보고서를 Cloud Storage 버킷으로 이동
AVRO 보고서 및 출력 도메인이 생성되면 보고서 및 출력 도메인을 Cloud Storage의 버킷 (요구사항 1.6에서 확인)으로 이동합니다.
로컬 환경에 gcloud CLI가 설정되어 있으면 아래 명령어를 사용하여 파일을 해당 폴더에 복사합니다.
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
또는 파일을 버킷에 수동으로 업로드합니다. 'reports'라는 폴더를 만들고 여기에 report.avro 파일을 업로드합니다. 'output_domains'라는 폴더를 만들고 여기에 output_domain.avro 파일을 업로드합니다.
3.2. 집계 서비스 사용량
기본 요건 1.8에서 집계 서비스 엔드포인트에 API를 요청하기 위해 cURL 또는 Postman을 선택했음을 기억합니다. 아래에서 두 가지 옵션에 대한 안내를 확인하세요.
작업이 오류와 함께 실패하면 GitHub의 문제 해결 문서에서 계속 진행하는 방법을 자세히 알아보세요.
3.2.1. createJob 엔드포인트를 사용하여 일괄 처리
아래의 cURL 또는 Postman 안내에 따라 작업을 만듭니다.
cURL
'터미널'에서 요청 본문 파일 (body.json)을 만들고 아래에 붙여넣습니다. 자리표시자 값을 업데이트해야 합니다. 각 필드가 나타내는 내용에 관한 자세한 내용은 이 API 문서를 참고하세요.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
다음 요청을 실행합니다. cURL 요청 URL의 자리표시자를 frontend_service_cloudfunction_url의 값으로 바꿉니다. frontend_service_cloudfunction_url의 값은 기본 요건 1.6의 Terraform 배포가 완료된 후 출력됩니다.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
집계 서비스에서 요청을 수락하면 HTTP 202 응답이 수신됩니다. 가능한 다른 응답 코드는 API 사양에 설명되어 있습니다.
Postman
createJob 엔드포인트의 경우 집계 서비스에 집계 가능한 보고서, 출력 도메인, 요약 보고서의 위치와 파일 이름을 제공하려면 요청 본문이 필요합니다.
createJob 요청의 '본문' 탭으로 이동합니다.

제공된 JSON 내의 자리표시자를 바꿉니다. 이러한 필드와 그 의미에 관한 자세한 내용은 API 문서를 참고하세요.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
createJob API 요청을 '전송'합니다.

응답 코드는 페이지 하단에서 확인할 수 있습니다.

집계 서비스에서 요청을 수락하면 HTTP 202 응답이 수신됩니다. 가능한 다른 응답 코드는 API 사양에 설명되어 있습니다.
3.2.2. getJob 엔드포인트를 사용하여 일괄 처리 상태 검색
아래의 cURL 또는 Postman 안내에 따라 작업을 가져옵니다.
cURL
터미널에서 아래 요청을 실행합니다. URL의 자리표시자를 frontend_service_cloudfunction_url의 값으로 바꿉니다. frontend_service_cloudfunction_url는 createJob 요청에 사용한 것과 동일한 URL입니다. 'job_request_id'의 경우 createJob 엔드포인트로 만든 작업의 값을 사용합니다.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
결과는 HTTP 상태 200으로 작업 요청 상태를 반환해야 합니다. 요청 'Body'에는 job_status, return_message, error_messages와 같은 필수 정보가 포함됩니다 (작업에 오류가 발생한 경우).
Postman
작업 요청 상태를 확인하려면 getJob 엔드포인트를 사용하면 됩니다. getJob 요청의 'Params' 섹션에서 job_request_id 값을 createJob 요청에서 전송된 job_request_id로 업데이트합니다.
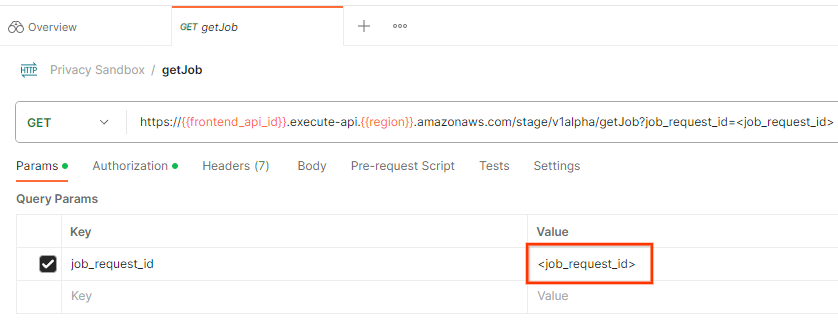
getJob 요청을 '전송'합니다.

결과는 HTTP 상태 200으로 작업 요청 상태를 반환해야 합니다. 요청 'Body'에는 job_status, return_message, error_messages (작업에 오류가 발생한 경우)와 같은 필수 정보가 포함됩니다.
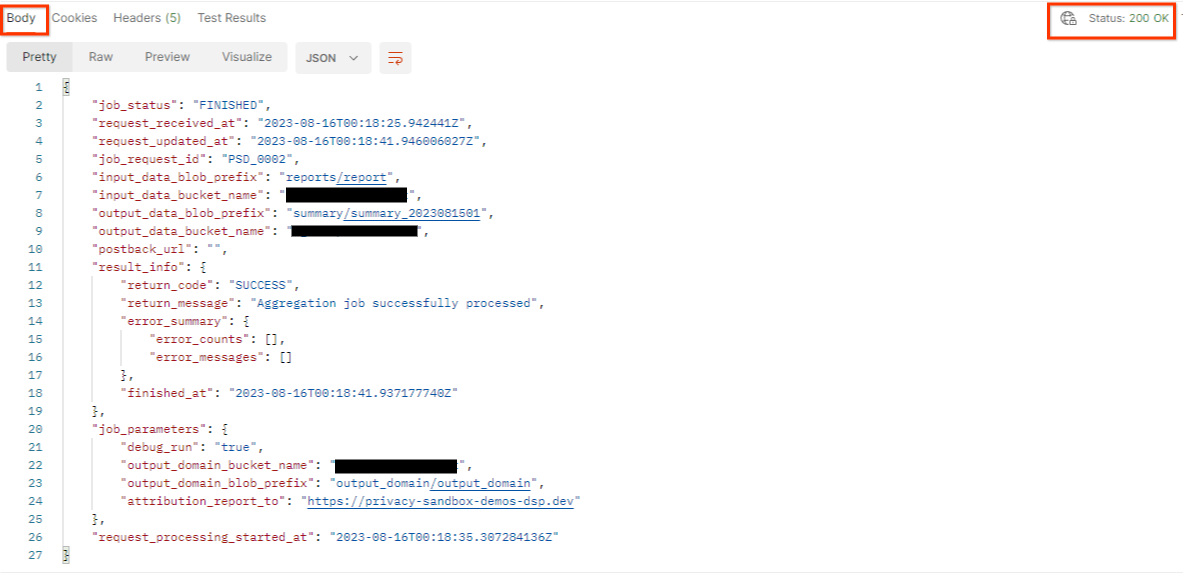
3.2.3. 요약 보고서 검토
출력 Cloud Storage 버킷에서 요약 보고서를 수신하면 로컬 환경에 다운로드할 수 있습니다. 요약 보고서는 AVRO 형식이며 JSON으로 다시 변환할 수 있습니다. aggregatable_report_converter.jar를 사용하여 아래 명령어로 보고서를 읽을 수 있습니다.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
그러면 아래와 같이 각 버킷 키의 집계된 값의 JSON이 반환됩니다.

createJob 요청에 debug_run가 true로 포함된 경우 output_data_blob_prefix에 있는 디버그 폴더에서 요약 보고서를 수신할 수 있습니다. 보고서는 AVRO 형식이며 위의 명령어를 사용하여 JSON으로 변환할 수 있습니다.
보고서에는 버킷 키, 노이즈 제거된 측정항목, 노이즈 제거된 측정항목에 추가되어 요약 보고서를 형성하는 노이즈가 포함됩니다. 보고서는 다음과 유사합니다.

주석에는 'in_reports' 또는 'in_domain'도 포함되며, 이는 다음을 의미합니다.
- in_reports - 집계 가능한 보고서 내에서 버킷 키를 사용할 수 있습니다.
- in_domain - 버킷 키는 output_domain AVRO 파일 내에서 사용할 수 있습니다.
Codelab이 완료되었습니다.
요약: 자체 클라우드 환경에 집계 서비스를 배포하고, 디버그 보고서를 수집하고, 출력 도메인 파일을 생성하고, 이러한 파일을 Cloud Storage 버킷에 저장하고, 작업을 실행했습니다.
다음 단계: 환경에서 집계 서비스를 계속 사용하거나 4단계의 정리 안내에 따라 방금 만든 클라우드 리소스를 삭제합니다.
4. 4. 삭제
Terraform을 통해 집계 서비스에 생성된 리소스를 삭제하려면 adtech_setup 및 dev (또는 다른 환경) 폴더에서 destroy 명령어를 사용합니다.
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
집계 가능한 보고서 및 요약 보고서가 포함된 Cloud Storage 버킷을 삭제하려면 다음 단계를 따르세요.
$ gcloud storage buckets delete gs://my-bucket
Chrome 쿠키 설정을 기본 요건 1.2에서 이전 상태로 되돌릴 수도 있습니다.
5. 5. 부록
adtech_setup.auto.tfvars 파일 예
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
dev.auto.tfvars 파일 예
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20