
1. 1. ข้อกำหนดเบื้องต้น
เวลาที่ใช้โดยประมาณ: 1-2 ชั่วโมง
โค้ดแล็บนี้ทําได้ 2 โหมด ได้แก่ การทดสอบในเครื่องหรือบริการรวบรวมข้อมูล โหมดการทดสอบในเครื่องต้องใช้เครื่องในเครื่องและเบราว์เซอร์ Chrome (ไม่มีการสร้าง/การใช้ทรัพยากร Google Cloud) โหมดบริการรวมข้อมูลต้องมีการทำให้บริการรวมข้อมูลใช้งานได้อย่างเต็มรูปแบบใน Google Cloud
หากต้องการทำ Codelab นี้ในโหมดใดโหมดหนึ่ง คุณจะต้องมีคุณสมบัติตามข้อกําหนดเบื้องต้นบางอย่าง แต่ละข้อกำหนดจะมีเครื่องหมายกำกับไว้ว่าจำเป็นสำหรับการทดสอบในเครื่องหรือบริการรวบรวมข้อมูล
1.1 ลงทะเบียนและรับรองให้เสร็จสมบูรณ์ (บริการรวมข้อมูล)
หากต้องการใช้ Privacy Sandbox API โปรดตรวจสอบว่าคุณได้ลงทะเบียนและการรับรองทั้งสำหรับ Chrome และ Android แล้ว
1.2 เปิดใช้ Ad Privacy API (บริการทดสอบและรวบรวมข้อมูลในเครื่อง)
เนื่องจากเราจะใช้ Privacy Sandbox เราจึงขอแนะนําให้คุณเปิดใช้ Privacy Sandbox Ads API
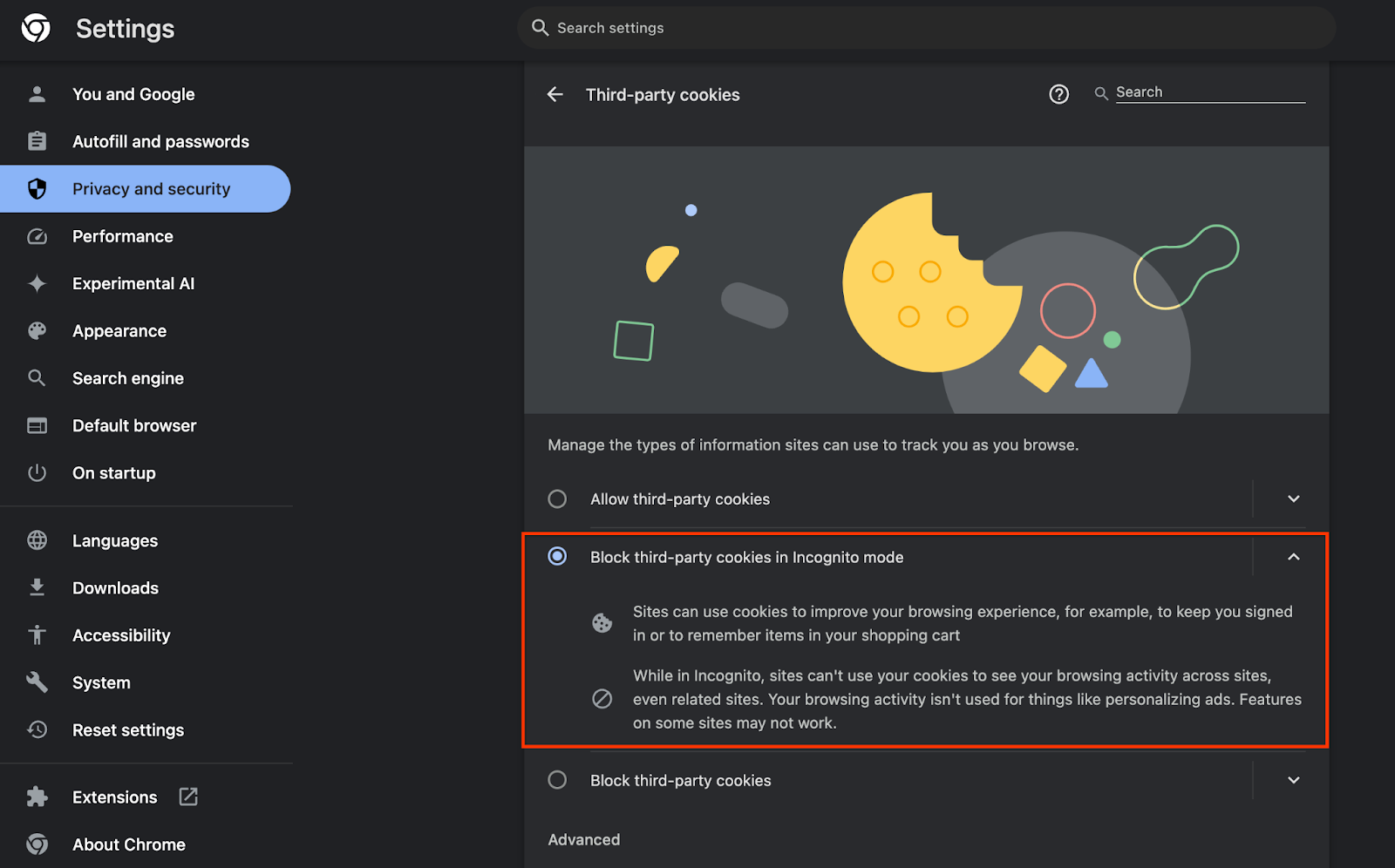
ไปที่ chrome://settings/adPrivacy ในเบราว์เซอร์ แล้วเปิดใช้ Ad Privacy API ทั้งหมด
และตรวจสอบว่าเปิดใช้คุกกี้ของบุคคลที่สามแล้ว
จาก chrome://settings/cookies ให้ตรวจสอบว่าไม่ได้บล็อกคุกกี้ของบุคคลที่สาม คุณอาจเห็นตัวเลือกที่แตกต่างกันในเมนูการตั้งค่านี้ ทั้งนี้ขึ้นอยู่กับเวอร์ชัน Chrome แต่การกำหนดค่าที่ยอมรับได้ ได้แก่
- "บล็อกคุกกี้ของบุคคลที่สามทั้งหมด" = ปิดใช้
- "บล็อกคุกกี้ของบุคคลที่สาม" = ปิดใช้
- "บล็อกคุกกี้ของบุคคลที่สามในโหมดไม่ระบุตัวตน" = เปิดใช้
1.3 ดาวน์โหลดเครื่องมือทดสอบในเครื่อง (การทดสอบในเครื่อง)
การทดสอบในเครื่องจะต้องดาวน์โหลดเครื่องมือทดสอบในเครื่อง เครื่องมือจะสร้างรายงานสรุปจากรายงานการแก้ไขข้อบกพร่องที่ไม่ได้เข้ารหัส
เครื่องมือทดสอบในเครื่องพร้อมให้ดาวน์โหลดในที่เก็บ JAR ของ Cloud Function ใน GitHub โดยควรตั้งชื่อว่า LocalTestingTool_{version}.jar
1.4. ตรวจสอบว่าได้ติดตั้ง JAVA JRE แล้ว (บริการทดสอบและการรวบรวมข้อมูลในเครื่อง)
เปิด "Terminal" และใช้ java --version เพื่อตรวจสอบว่าเครื่องของคุณติดตั้ง Java หรือ openJDK ไว้หรือไม่

หากยังไม่ได้ติดตั้ง คุณสามารถดาวน์โหลดและติดตั้งได้จากเว็บไซต์ Java หรือเว็บไซต์ openJDK
1.5. ดาวน์โหลด aggregatable_report_converter (บริการทดสอบและรวบรวมข้อมูลในพื้นที่)
คุณสามารถดาวน์โหลดสําเนาของ aggregatable_report_converter ได้จากที่เก็บ GitHub ของเดโม Privacy Sandbox ที่เก็บ GitHub พูดถึงการใช้ IntelliJ หรือ Eclipse แต่ไม่จำเป็นต้องใช้เครื่องมือใดเลย หากคุณไม่ได้ใช้เครื่องมือเหล่านี้ ให้ดาวน์โหลดไฟล์ JAR ลงในสภาพแวดล้อมในเครื่องแทน
1.6. ตั้งค่าสภาพแวดล้อม GCP (บริการรวมข้อมูล)
บริการรวบรวมข้อมูลต้องใช้สภาพแวดล้อมการทํางานที่เชื่อถือได้ซึ่งใช้ผู้ให้บริการระบบคลาวด์ ในโค้ดแล็บนี้ เราจะติดตั้งใช้งานบริการรวบรวมข้อมูลใน GCP แต่รองรับ AWS ด้วย
ทำตามวิธีการติดตั้งใช้งานใน GitHub เพื่อตั้งค่า gcloud CLI, ดาวน์โหลดไบนารีและโมดูล Terraform และสร้างทรัพยากร GCP สำหรับบริการรวบรวมข้อมูล
ขั้นตอนสำคัญในวิธีการทำให้ใช้งานได้
- ตั้งค่า CLI "gcloud" และ Terraform ในสภาพแวดล้อม
- สร้างที่เก็บข้อมูล Cloud Storage เพื่อจัดเก็บสถานะของ Terraform
- ดาวน์โหลด Dependency
- อัปเดต
adtech_setup.auto.tfvarsและเรียกใช้adtech_setupTerraform ดูตัวอย่างไฟล์adtech_setup.auto.tfvarsได้ในภาคผนวก จดชื่อที่เก็บข้อมูลที่สร้างที่นี่ ซึ่งจะใช้ในโค้ดแล็บเพื่อจัดเก็บไฟล์ที่เราสร้างขึ้น - อัปเดต
dev.auto.tfvarsแอบอ้างบัญชีบริการที่ใช้เพื่อติดตั้งใช้งาน และเรียกใช้devTerraform ดูตัวอย่างไฟล์dev.auto.tfvarsได้ในภาคผนวก - เมื่อการทําให้ใช้งานได้เสร็จสมบูรณ์แล้ว ให้บันทึก
frontend_service_cloudfunction_urlจากเอาต์พุต Terraform ซึ่งต้องใช้เพื่อส่งคําขอไปยังบริการรวบรวมข้อมูลในขั้นตอนต่อๆ ไป
1.7 เริ่มต้นใช้งานบริการรวมข้อมูลให้เสร็จสมบูรณ์ (บริการรวมข้อมูล)
บริการรวบรวมข้อมูลกำหนดให้ต้องเริ่มต้นใช้งานสำหรับผู้ประสานงานจึงจะใช้บริการได้ กรอกแบบฟอร์มเตรียมความพร้อมผู้ใช้งานใหม่ของบริการรวบรวมข้อมูลโดยระบุเว็บไซต์การรายงานและข้อมูลอื่นๆ เลือก "Google Cloud" และป้อนที่อยู่บัญชีบริการ บัญชีบริการนี้จะสร้างขึ้นในข้อกําหนดเบื้องต้นก่อนหน้า (1.6 ตั้งค่าสภาพแวดล้อม GCP) (เคล็ดลับ: หากคุณใช้ชื่อเริ่มต้นที่ระบุไว้ บัญชีบริการนี้จะขึ้นต้นด้วย "worker-sa@")
โปรดรอไม่เกิน 2 สัปดาห์เพื่อให้ขั้นตอนการเริ่มต้นใช้งานเสร็จสมบูรณ์
1.8. กำหนดเมธอดในการเรียกใช้ปลายทาง API (บริการรวบรวมข้อมูล)
โค้ดแล็บนี้มี 2 ตัวเลือกในการเรียกใช้ปลายทาง API ของบริการรวบรวมข้อมูล ได้แก่ cURL และ Postman โดย cURL เป็นวิธีที่เร็วและง่ายกว่าในการเรียกใช้ปลายทาง API จากเทอร์มินัล เนื่องจากต้องมีการตั้งค่าเพียงเล็กน้อยและไม่ต้องติดตั้งซอฟต์แวร์เพิ่มเติม อย่างไรก็ตาม หากไม่ต้องการใช้ cURL คุณสามารถใช้ Postman เพื่อเรียกใช้และบันทึกคําขอ API เพื่อใช้ในอนาคตแทนได้
ในส่วนที่ 3.2 การใช้บริการรวบรวมข้อมูล คุณจะเห็นวิธีการโดยละเอียดในการใช้ทั้ง 2 ตัวเลือก คุณสามารถดูตัวอย่างตอนนี้เพื่อเลือกว่าจะใช้วิธีการใด หากเลือก Postman ให้ทําการตั้งค่าเริ่มต้นต่อไปนี้
1.8.1. ตั้งค่าพื้นที่ทํางาน
ลงชื่อสมัครใช้บัญชี Postman เมื่อลงชื่อสมัครใช้แล้ว ระบบจะสร้างพื้นที่ทำงานให้คุณโดยอัตโนมัติ
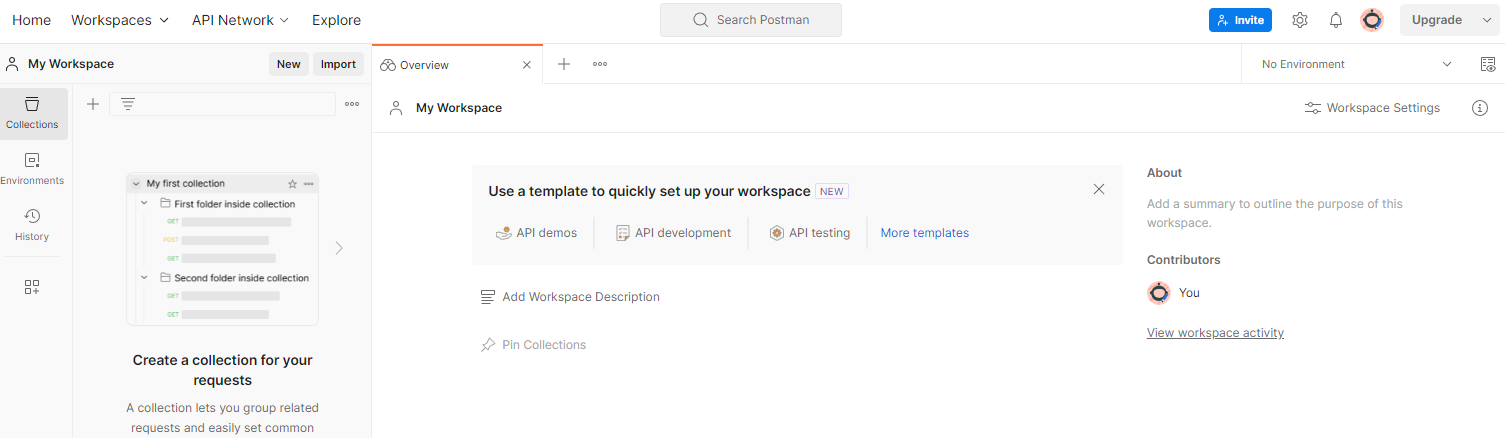
หากระบบไม่ได้สร้างพื้นที่ทำงานให้คุณ ให้ไปที่รายการการนำทางด้านบน "พื้นที่ทำงาน" แล้วเลือก "สร้างพื้นที่ทำงาน"
เลือก "พื้นที่ทํางานว่าง" คลิกถัดไป แล้วตั้งชื่อเป็น "Sandbox ความเป็นส่วนตัวของ GCP" เลือก "ส่วนตัว" แล้วคลิก "สร้าง"
ดาวน์โหลดการกำหนดค่า JSON และไฟล์สภาพแวดล้อมส่วนกลางของพื้นที่ทำงานที่กำหนดค่าไว้ล่วงหน้า
นําเข้าไฟล์ JSON ทั้ง 2 ไฟล์ไปยัง "พื้นที่ทํางานของฉัน" ผ่านปุ่ม "นําเข้า"

ซึ่งจะสร้างคอลเล็กชัน "GCP Privacy Sandbox" ให้คุณพร้อมกับคําขอ HTTP createJob และ getJob
1.8.2. ตั้งค่าการให้สิทธิ์
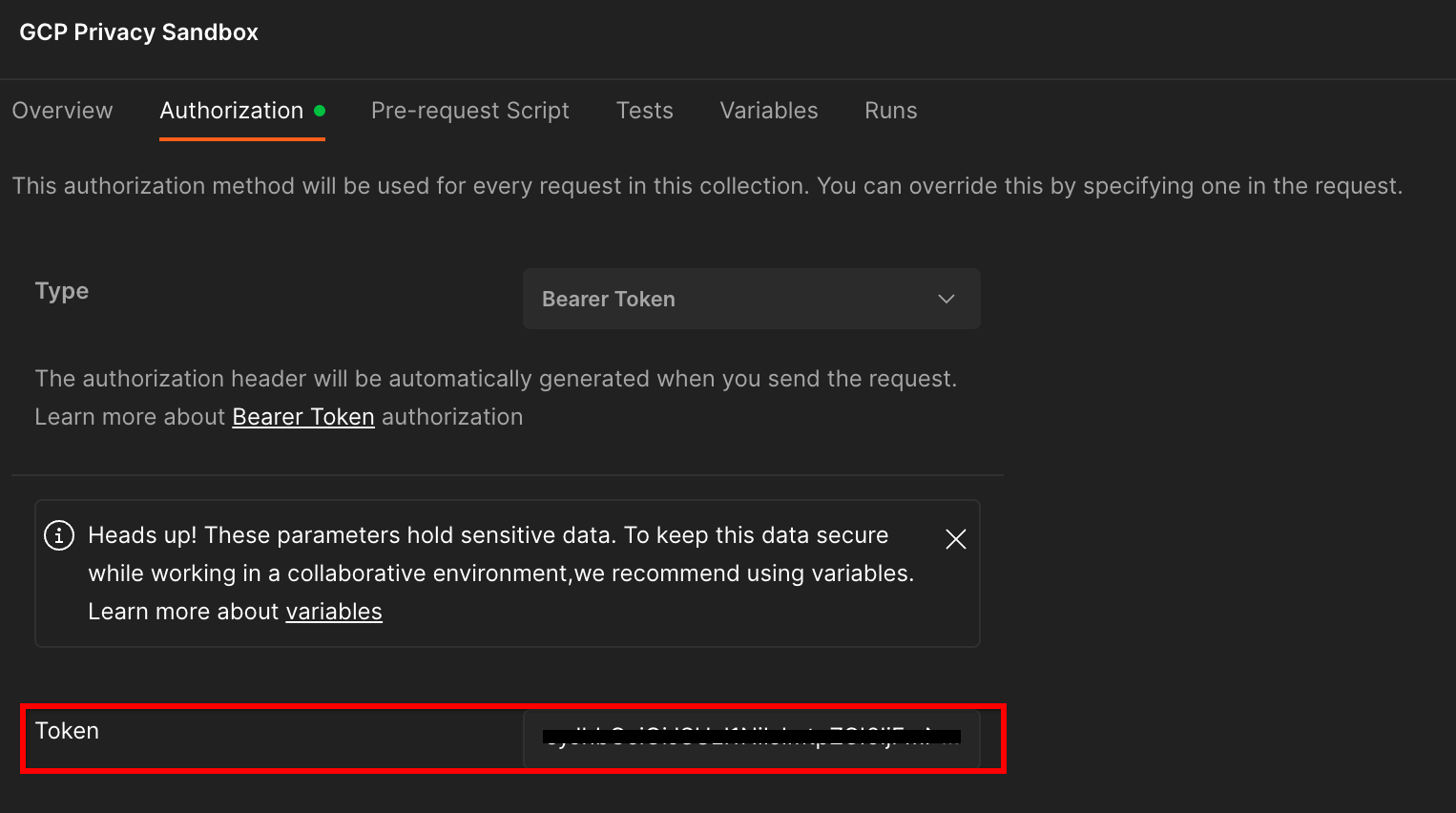
คลิกคอลเล็กชัน "Privacy Sandbox ของ GCP" แล้วไปที่แท็บ "การให้สิทธิ์"

คุณจะใช้วิธีการ "Bearer Token" จากสภาพแวดล้อมเทอร์มินัล ให้เรียกใช้คําสั่งนี้และคัดลอกเอาต์พุต
gcloud auth print-identity-token
จากนั้นวางค่าโทเค็นนี้ในช่อง "โทเค็น" ของแท็บการให้สิทธิ์ของ Postman
1.8.3. ตั้งค่าสภาพแวดล้อม
ไปที่ "ดูสภาพแวดล้อมอย่างรวดเร็ว" ที่มุมขวาบน
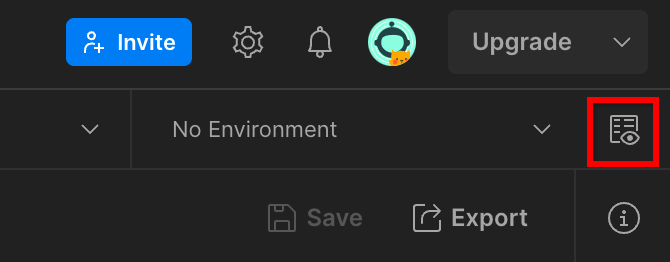
คลิก "แก้ไข" และอัปเดต "ค่าปัจจุบัน" ของ "environment", "region" และ "cloud-function-id" ดังนี้
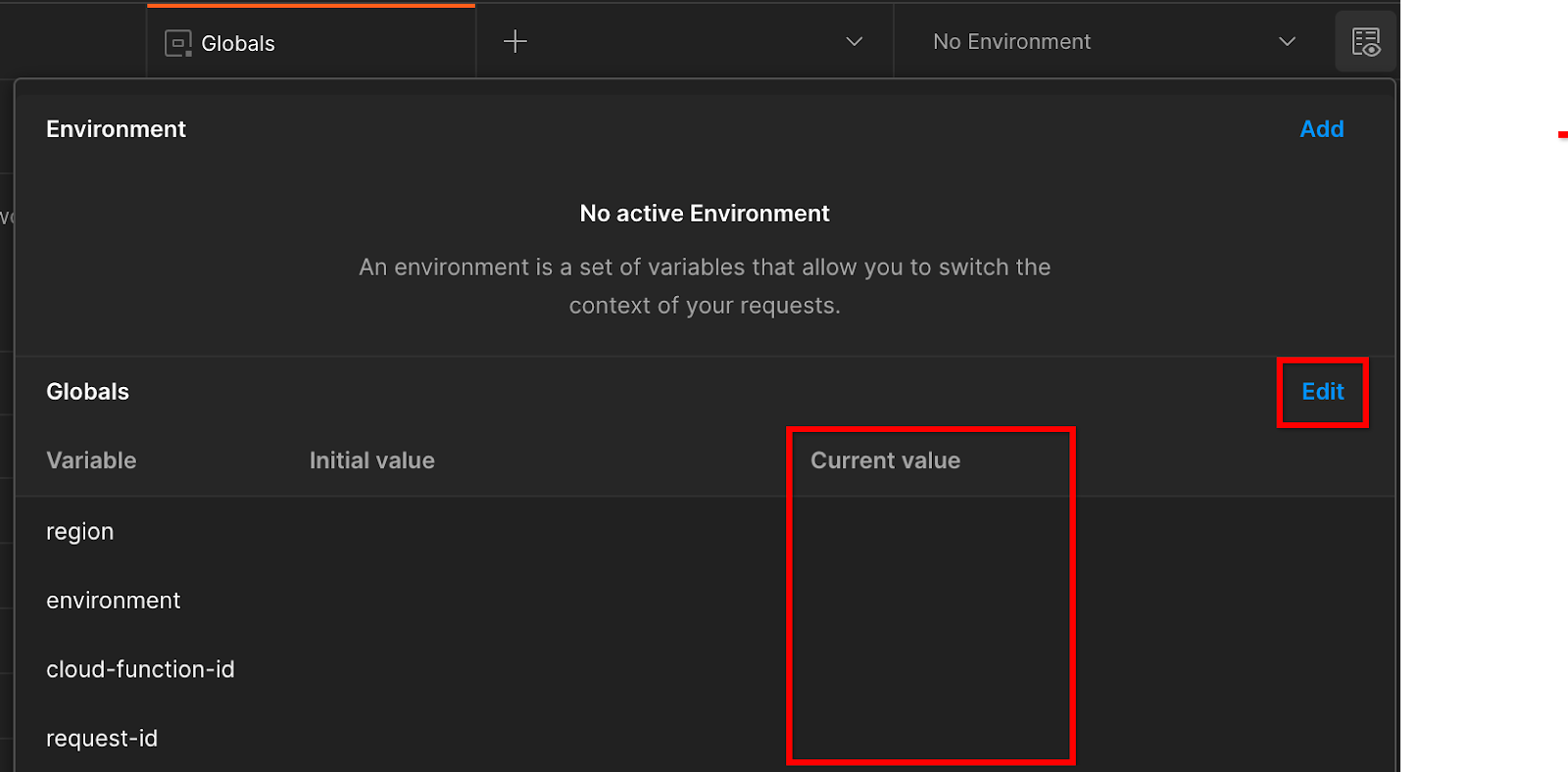
คุณเว้น "request-id" ว่างไว้ได้ก่อน เนื่องจากเราจะกรอกข้อมูลในภายหลัง สำหรับช่องอื่นๆ ให้ใช้ค่าจาก frontend_service_cloudfunction_url ซึ่งแสดงผลจากการทำให้ Terraform ใช้งานได้สำเร็จในข้อกําหนดเบื้องต้น 1.6 URL อยู่ในรูปแบบ https://
2. 2. Codelab การทดสอบในเครื่อง
เวลาที่ใช้โดยประมาณ: <1 ชั่วโมง
คุณสามารถใช้เครื่องมือทดสอบในเครื่องเพื่อทำการรวมและสร้างรายงานสรุปโดยใช้รายงานการแก้ไขข้อบกพร่องที่ไม่ได้เข้ารหัส ก่อนเริ่ม โปรดตรวจสอบว่าคุณได้ทำตามข้อกําหนดเบื้องต้นทั้งหมดที่ติดป้ายกํากับว่า "การทดสอบในเครื่อง" แล้ว
ขั้นตอนใน Codelab
ขั้นตอนที่ 2.1 ทริกเกอร์รายงาน: ทริกเกอร์การรายงานการรวบรวมข้อมูลส่วนตัวเพื่อให้รวบรวมรายงานได้
ขั้นตอนที่ 2.2 สร้างรายงานการแก้ไขข้อบกพร่อง AVRO: แปลงรายงาน JSON ที่รวบรวมเป็นรายงานรูปแบบ AVRO ขั้นตอนนี้จะคล้ายกับตอนที่ AdTech รวบรวมรายงานจากปลายทางการรายงาน API และแปลงรายงาน JSON เป็นรายงานรูปแบบ AVRO
ขั้นตอนที่ 2.3 เรียกข้อมูลคีย์ที่เก็บ: คีย์ที่เก็บข้อมูลออกแบบโดย AdTech ในโค้ดแล็บนี้ เนื่องจากมีการกำหนดที่เก็บข้อมูลไว้ล่วงหน้า ให้ดึงข้อมูลคีย์ที่เก็บข้อมูลตามที่ระบุ
ขั้นตอนที่ 2.4 สร้าง Output Domain AVRO: เมื่อดึงข้อมูลคีย์ที่เก็บข้อมูลแล้ว ให้สร้างไฟล์ Output Domain AVRO
ขั้นตอนที่ 2.5 สร้างรายงานสรุป: ใช้เครื่องมือทดสอบในเครื่องเพื่อสร้างรายงานสรุปในสภาพแวดล้อมในเครื่อง
ขั้นตอนที่ 2.6 ตรวจสอบรายงานสรุป: ตรวจสอบรายงานสรุปที่เครื่องมือทดสอบในเครื่องสร้างขึ้น
2.1 รายงานทริกเกอร์
หากต้องการเรียกให้รายงานการรวบรวมข้อมูลส่วนตัวแสดงขึ้น ให้ใช้เว็บไซต์เดโมของ Privacy Sandbox (https://privacy-sandbox-demos-news.dev/?env=gcp) หรือเว็บไซต์ของคุณเอง (เช่น https://adtechexample.com) หากคุณใช้เว็บไซต์ของคุณเองและยังไม่ได้ลงทะเบียนและการรับรอง รวมถึงยังไม่ได้เริ่มต้นใช้งานบริการรวบรวมข้อมูล คุณจะต้องใช้Flag ของ Chrome และ CLI Switch
ในการสาธิตนี้ เราจะใช้เว็บไซต์เดโมของ Privacy Sandbox ไปที่ลิงก์เพื่อไปยังเว็บไซต์ จากนั้นดูรายงานได้ที่ chrome://private-aggregation-internals
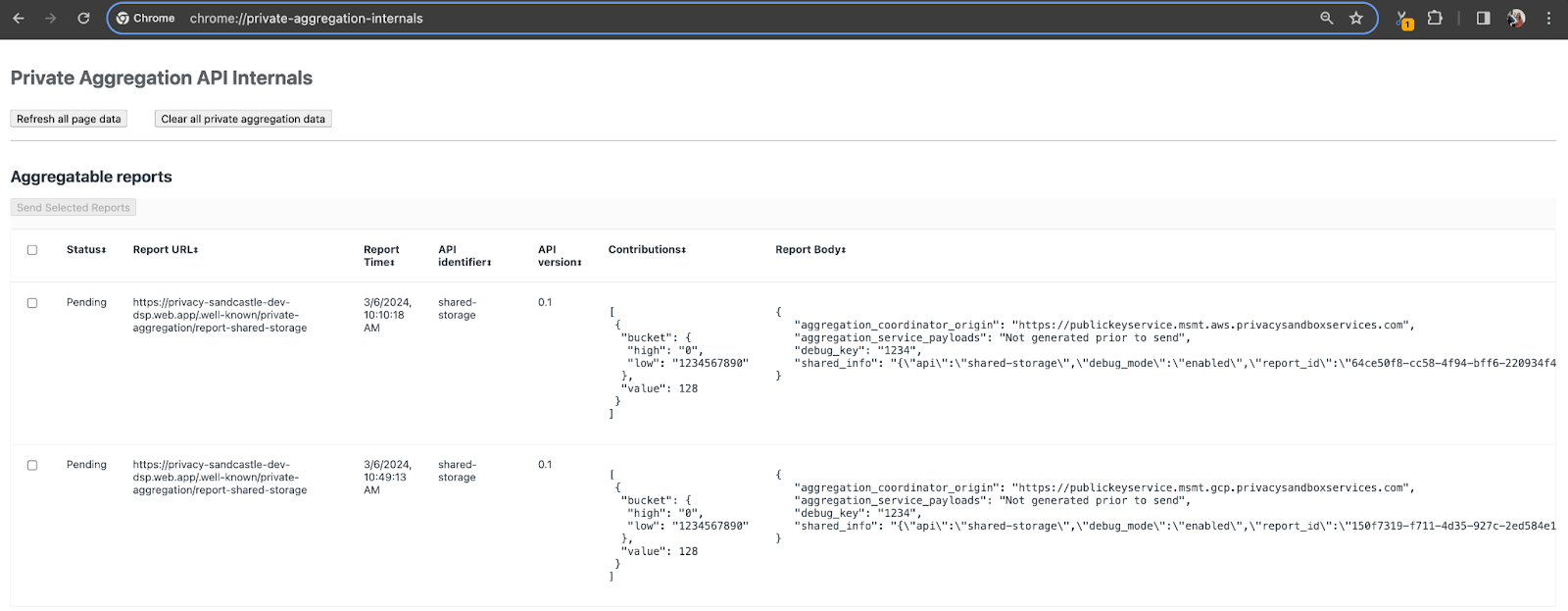
รายงานที่ส่งไปยังปลายทาง {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage จะอยู่ใน "เนื้อหารายงาน" ของรายงานที่แสดงในหน้าข้อมูลภายในของ Chrome ด้วย
คุณอาจเห็นรายงานหลายรายการที่นี่ แต่สําหรับโค้ดแล็บนี้ ให้ใช้รายงานที่รวบรวมได้ซึ่งเจาะจง GCP และสร้างโดยปลายทางการแก้ไขข้อบกพร่อง "URL ของรายงาน" จะมี "/debug/" และ aggregation_coordinator_origin field ของ "เนื้อหารายงาน" จะมี URL นี้ https://publickeyservice.msmt.gcp.privacysandboxservices.com
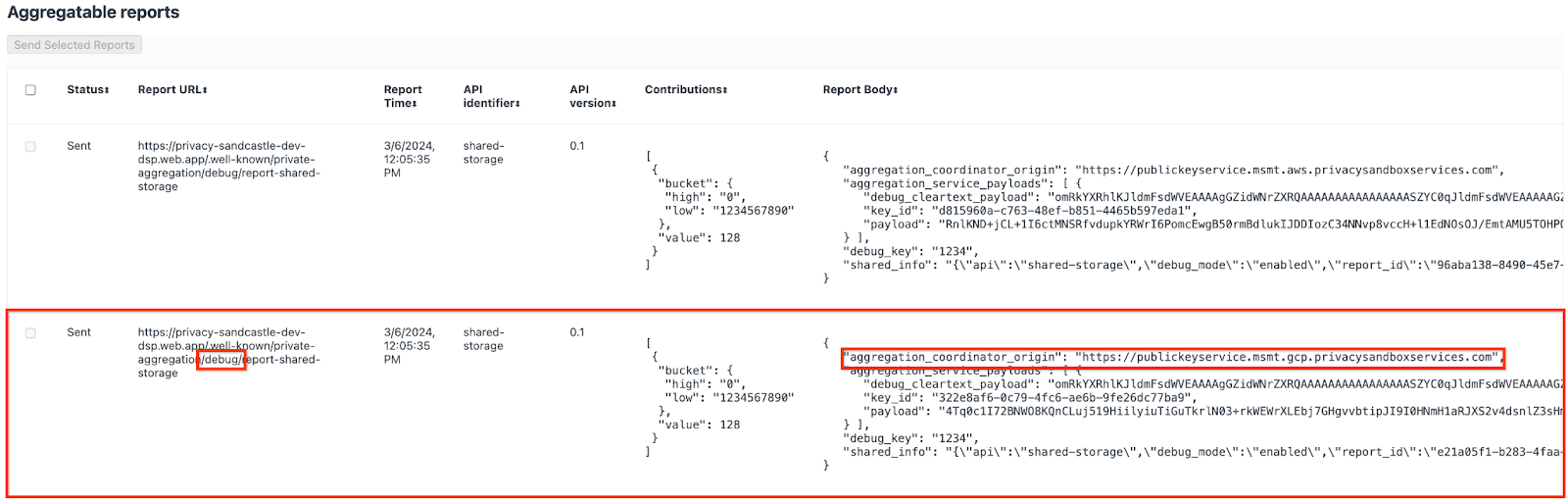
2.2 สร้างรายงานการแก้ไขข้อบกพร่องที่รวบรวมได้
คัดลอกรายงานที่พบในส่วน "เนื้อหารายงาน" ของ chrome://private-aggregation-internals และสร้างไฟล์ JSON ในโฟลเดอร์ privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar (ภายในที่เก็บข้อมูลที่ดาวน์โหลดในข้อกําหนดเบื้องต้น 1.5)
ในตัวอย่างนี้ เราจะใช้ vim เนื่องจากใช้ Linux แต่คุณใช้เครื่องมือแก้ไขข้อความใดก็ได้
vim report.json
วางรายงานลงใน report.json แล้วบันทึกไฟล์

เมื่อได้รับแล้ว ให้ใช้ aggregatable_report_converter.jar เพื่อช่วยสร้างรายงานการแก้ไขข้อบกพร่องที่รวบรวมได้ ซึ่งจะสร้างรายงานที่รวบรวมข้อมูลได้ชื่อ report.avro ในไดเรกทอรีปัจจุบัน
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3 เรียกข้อมูลคีย์ที่เก็บข้อมูลจากรายงาน
หากต้องการสร้างไฟล์ output_domain.avro คุณต้องมีคีย์ที่เก็บข้อมูลที่ดึงมาจากรายงานได้
คีย์ที่เก็บข้อมูลออกแบบโดย AdTech อย่างไรก็ตาม ในกรณีนี้ เว็บไซต์ Privacy Sandbox Demo จะสร้างคีย์ที่เก็บข้อมูล เนื่องจากการรวมข้อมูลส่วนตัวสําหรับเว็บไซต์นี้อยู่ในโหมดแก้ไขข้อบกพร่อง เราจึงใช้ debug_cleartext_payload จาก "เนื้อหารายงาน" เพื่อรับคีย์ที่เก็บข้อมูลได้
คัดลอก debug_cleartext_payload จากเนื้อหารายงาน

เปิด goo.gle/ags-payload-decoder แล้ววาง debug_cleartext_payload ในช่อง "INPUT" แล้วคลิก "Decode"
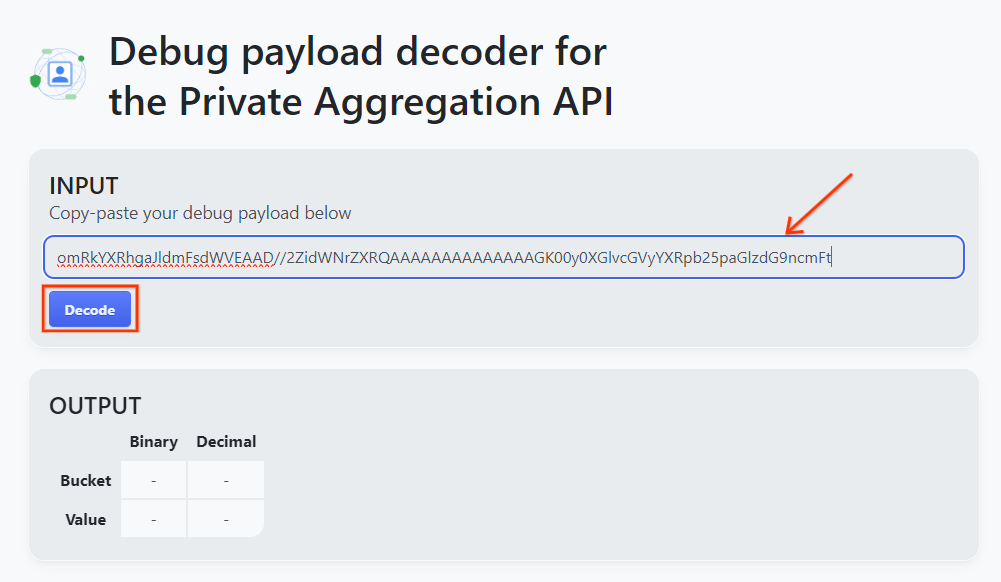
หน้าเว็บจะแสดงผลค่าทศนิยมของคีย์ที่เก็บข้อมูล ด้านล่างนี้คือตัวอย่างคีย์ที่เก็บข้อมูล
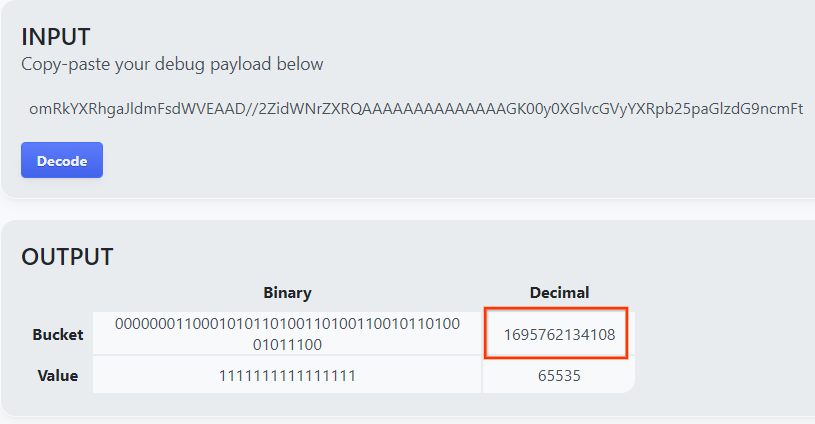
2.4 สร้างโดเมนเอาต์พุต AVRO
เมื่อเรามีคีย์ที่เก็บข้อมูลแล้ว ให้สร้าง output_domain.avro ในโฟลเดอร์เดียวกับที่เราทํางานอยู่ ตรวจสอบว่าคุณได้แทนที่คีย์ของที่เก็บข้อมูลด้วยคีย์ของที่เก็บข้อมูลที่คุณดึงข้อมูลมา
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
สคริปต์จะสร้างไฟล์ output_domain.avro ในโฟลเดอร์ปัจจุบัน
2.5 สร้างรายงานสรุปโดยใช้เครื่องมือทดสอบในเครื่อง
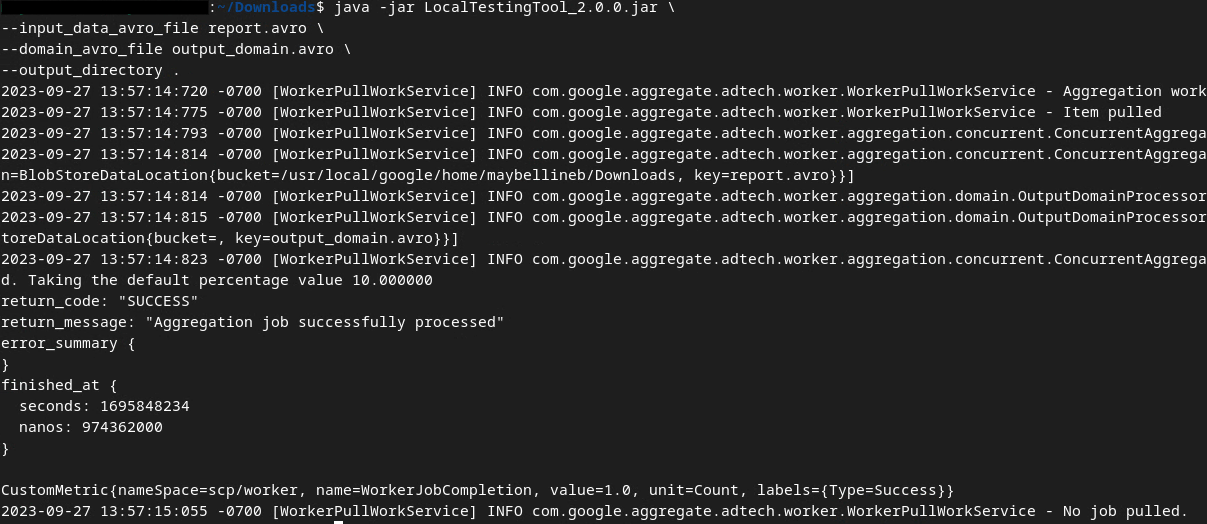
เราจะใช้ LocalTestingTool_{version}.jar ที่ดาวน์โหลดไว้ในข้อกําหนดเบื้องต้น 1.3 เพื่อสร้างรายงานสรุปโดยใช้คําสั่งด้านล่าง แทนที่ {version} ด้วยเวอร์ชันที่คุณดาวน์โหลด อย่าลืมย้าย LocalTestingTool_{version}.jar ไปยังไดเรกทอรีปัจจุบัน หรือเพิ่มเส้นทางแบบสัมพัทธ์เพื่ออ้างอิงตำแหน่งปัจจุบัน
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
คุณควรเห็นข้อมูลคล้ายกับด้านล่างเมื่อเรียกใช้คําสั่ง ระบบจะสร้างรายงาน output.avro เมื่อดำเนินการเสร็จสิ้น
2.6 ตรวจสอบรายงานสรุป
รายงานสรุปที่สร้างจะอยู่ในรูปแบบ AVRO หากต้องการอ่านข้อมูลนี้ คุณต้องแปลงจาก AVRO เป็นรูปแบบ JSON โดยหลักการแล้ว AdTech ควรเขียนโค้ดเพื่อแปลงรายงาน AVRO กลับเป็น JSON
เราจะใช้ aggregatable_report_converter.jar เพื่อแปลงรายงาน AVRO กลับเป็น JSON
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
ซึ่งจะแสดงรายงานที่คล้ายกับด้านล่าง พร้อมกับรายงาน output.json ที่สร้างขึ้นในไดเรกทอรีเดียวกัน

Codelab เสร็จสมบูรณ์
สรุป: คุณได้รวบรวมรายงานการแก้ไขข้อบกพร่อง สร้างไฟล์โดเมนเอาต์พุต และสร้างรายงานสรุปโดยใช้เครื่องมือทดสอบในเครื่องซึ่งจำลองลักษณะการรวบรวมข้อมูลของบริการรวบรวมข้อมูล
ขั้นตอนถัดไป: เมื่อทดสอบเครื่องมือทดสอบในเครื่องแล้ว คุณสามารถลองทําแบบเดียวกันกับการทําให้บริการรวบรวมข้อมูลใช้งานได้จริงในสภาพแวดล้อมของคุณเอง กลับไปดูข้อกําหนดเบื้องต้นอีกครั้งเพื่อให้แน่ใจว่าคุณได้ตั้งค่าทุกอย่างสําหรับโหมด "บริการรวบรวมข้อมูล" แล้ว จากนั้นให้ไปยังขั้นตอนที่ 3
3. 3. Codelab บริการรวมข้อมูล
เวลาที่ใช้โดยประมาณ: 1 ชั่วโมง
ก่อนเริ่ม โปรดตรวจสอบว่าคุณได้ทําตามข้อกําหนดเบื้องต้นทั้งหมดที่ติดป้ายกํากับว่า "บริการรวบรวมข้อมูล" แล้ว
ขั้นตอนใน Codelab
ขั้นตอนที่ 3.1 การสร้างอินพุตบริการรวมข้อมูล: สร้างรายงานบริการรวมข้อมูลที่จัดกลุ่มสําหรับบริการรวมข้อมูล
- ขั้นตอนที่ 3.1.1 รายงานทริกเกอร์
- ขั้นตอนที่ 3.1.2 รวบรวมรายงานที่รวบรวมได้
- ขั้นตอนที่ 3.1.3 แปลงรายงานเป็น AVRO
- ขั้นตอนที่ 3.1.4 สร้าง output_domain AVRO
- ขั้นตอนที่ 3.1.5 ย้ายรายงานไปยังที่เก็บข้อมูล Cloud Storage
ขั้นตอนที่ 3.2 การใช้งานบริการรวมข้อมูล: ใช้ Aggregation Service API เพื่อสร้างรายงานสรุปและตรวจสอบรายงานสรุป
- ขั้นตอนที่ 3.2.1 ใช้ปลายทาง
createJobเพื่อจัดกลุ่ม - ขั้นตอนที่ 3.2.2 การใช้ปลายทาง
getJobเพื่อดึงข้อมูลสถานะการประมวลผลเป็นกลุ่ม - ขั้นตอนที่ 3.2.3 การตรวจสอบรายงานสรุป
3.1 การสร้างอินพุตบริการรวมข้อมูล
ดำเนินการต่อเพื่อสร้างรายงาน AVRO เพื่อส่งเป็นกลุ่มไปยังบริการรวบรวมข้อมูล คำสั่งเชลล์ในขั้นตอนเหล่านี้สามารถเรียกใช้ได้ภายใน Cloud Shell ของ GCP (ตราบใดที่มีการโคลนทรัพยากร Dependencies จากข้อกําหนดเบื้องต้นไปยังสภาพแวดล้อม Cloud Shell) หรือในสภาพแวดล้อมการดําเนินการในเครื่อง
3.1.1. รายงานทริกเกอร์
ไปที่ลิงก์เพื่อไปยังเว็บไซต์ จากนั้นดูรายงานได้ที่ chrome://private-aggregation-internals
รายงานที่ส่งไปยังปลายทาง {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage จะอยู่ใน "เนื้อหารายงาน" ของรายงานที่แสดงในหน้าข้อมูลภายในของ Chrome ด้วย
คุณอาจเห็นรายงานหลายรายการที่นี่ แต่สําหรับโค้ดแล็บนี้ ให้ใช้รายงานที่รวบรวมได้ซึ่งเจาะจง GCP และสร้างโดยปลายทางการแก้ไขข้อบกพร่อง "URL ของรายงาน" จะมี "/debug/" และ aggregation_coordinator_origin field ของ "เนื้อหารายงาน" จะมี URL นี้ https://publickeyservice.msmt.gcp.privacysandboxservices.com
3.1.2. รวบรวมรายงานที่รวบรวมได้
รวบรวมรายงานที่รวบรวมข้อมูลได้จากปลายทาง .well-known ของ API ที่เกี่ยวข้อง
- การรวมข้อมูลส่วนตัว:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - การรายงานการระบุแหล่งที่มา - รายงานสรุป:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
สําหรับโค้ดแล็บนี้ เราจะรวบรวมรายงานด้วยตนเอง ในเวอร์ชันที่ใช้งานจริง เทคโนโลยีโฆษณาจะรวบรวมและแปลงรายงานแบบเป็นโปรแกรม
มาคัดลอกรายงาน JSON ในส่วน "เนื้อหารายงาน" จาก chrome://private-aggregation-internals กัน
ในตัวอย่างนี้ เราจะใช้ vim เนื่องจากใช้ Linux แต่คุณใช้เครื่องมือแก้ไขข้อความใดก็ได้
vim report.json
วางรายงานลงใน report.json แล้วบันทึกไฟล์
3.1.3. แปลงรายงานเป็น AVRO
รายงานที่ได้รับจากปลายทาง .well-known อยู่ในรูปแบบ JSON และต้องแปลงเป็นรูปแบบรายงาน AVRO เมื่อได้รายงาน JSON แล้ว ให้ไปที่ตำแหน่งที่จัดเก็บ report.json และใช้ aggregatable_report_converter.jar เพื่อช่วยสร้างรายงานการแก้ไขข้อบกพร่องแบบรวม ซึ่งจะสร้างรายงานที่รวบรวมข้อมูลได้ชื่อ report.avro ในไดเรกทอรีปัจจุบัน
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. สร้าง output_domain AVRO
หากต้องการสร้างไฟล์ output_domain.avro คุณต้องมีคีย์ที่เก็บข้อมูลที่ดึงมาจากรายงานได้
คีย์ที่เก็บข้อมูลออกแบบโดย AdTech อย่างไรก็ตาม ในกรณีนี้ เว็บไซต์ Privacy Sandbox Demo จะสร้างคีย์ที่เก็บข้อมูล เนื่องจากการรวมข้อมูลส่วนตัวสําหรับเว็บไซต์นี้อยู่ในโหมดแก้ไขข้อบกพร่อง เราจึงใช้ debug_cleartext_payload จาก "เนื้อหารายงาน" เพื่อรับคีย์ที่เก็บข้อมูลได้
คัดลอก debug_cleartext_payload จากเนื้อหารายงาน
เปิด goo.gle/ags-payload-decoder แล้ววาง debug_cleartext_payload ในช่อง "INPUT" แล้วคลิก "Decode"
หน้าเว็บจะแสดงผลค่าทศนิยมของคีย์ที่เก็บข้อมูล ด้านล่างนี้คือตัวอย่างคีย์ที่เก็บข้อมูล
เมื่อเรามีคีย์ที่เก็บข้อมูลแล้ว ให้สร้าง output_domain.avro ในโฟลเดอร์เดียวกับที่เราทํางานอยู่ ตรวจสอบว่าคุณได้แทนที่คีย์ของที่เก็บข้อมูลด้วยคีย์ของที่เก็บข้อมูลที่คุณดึงข้อมูลมา
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
สคริปต์จะสร้างไฟล์ output_domain.avro ในโฟลเดอร์ปัจจุบัน
3.1.5. ย้ายรายงานไปยังที่เก็บข้อมูล Cloud Storage
เมื่อสร้างรายงาน AVRO และโดเมนเอาต์พุตแล้ว ให้ย้ายรายงานและโดเมนเอาต์พุตไปยังที่เก็บข้อมูลใน Cloud Storage (ที่คุณบันทึกไว้ในข้อกําหนดเบื้องต้น 1.6)
หากคุณตั้งค่า gcloud CLI ในสภาพแวดล้อมในเครื่อง ให้ใช้คำสั่งด้านล่างเพื่อคัดลอกไฟล์ไปยังโฟลเดอร์ที่เกี่ยวข้อง
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
หรือจะอัปโหลดไฟล์ไปยังที่เก็บข้อมูลด้วยตนเองก็ได้ สร้างโฟลเดอร์ชื่อ "รายงาน" แล้วอัปโหลดไฟล์ report.avro ลงในโฟลเดอร์ดังกล่าว สร้างโฟลเดอร์ชื่อ "output_domains" แล้วอัปโหลดไฟล์ output_domain.avro ลงในโฟลเดอร์ดังกล่าว
3.2 การใช้บริการรวมข้อมูล
โปรดทราบว่าในข้อกําหนดเบื้องต้น 1.8 คุณได้เลือก cURL หรือ Postman เพื่อทำคําขอ API ไปยังปลายทางของบริการรวบรวมข้อมูล ด้านล่างนี้คือวิธีการสำหรับทั้ง 2 ตัวเลือก
หากงานไม่สำเร็จเนื่องจากมีข้อผิดพลาด โปรดดูข้อมูลเพิ่มเติมเกี่ยวกับวิธีดำเนินการต่อในเอกสารประกอบเกี่ยวกับการแก้ปัญหาใน GitHub
3.2.1. ใช้ปลายทาง createJob เพื่อจัดกลุ่ม
ใช้วิธีการ cURL หรือ Postman ด้านล่างเพื่อสร้างงาน
cURL
ใน "เทอร์มินัล" ให้สร้างไฟล์เนื้อหาคำขอ (body.json) แล้ววางไว้ด้านล่าง อย่าลืมอัปเดตค่าตัวยึดตำแหน่ง ดูข้อมูลเพิ่มเติมเกี่ยวกับสิ่งที่แต่ละช่องแสดงได้จากเอกสารประกอบเกี่ยวกับ API นี้
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
ดำเนินการตามคำขอต่อไปนี้ แทนที่ตัวยึดตําแหน่งใน URL ของคําขอ cURL ด้วยค่าจาก frontend_service_cloudfunction_url ซึ่งแสดงผลหลังจากการทําให้ Terraform ใช้งานได้สําเร็จในข้อกําหนดเบื้องต้น 1.6
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
คุณควรได้รับการตอบกลับ HTTP 202 เมื่อบริการรวบรวมข้อมูลยอมรับคำขอแล้ว โค้ดตอบกลับอื่นๆ ที่เป็นไปได้จะระบุไว้ในข้อกําหนดของ API
Postman
สําหรับปลายทาง createJob คุณต้องใช้เนื้อหาคําขอเพื่อระบุตําแหน่งและชื่อไฟล์ของรายงานที่รวบรวมได้ โดเมนเอาต์พุต และรายงานสรุปให้กับบริการรวบรวมข้อมูล
ไปที่แท็บ "เนื้อหา" ของคำขอ createJob

แทนที่ตัวยึดตําแหน่งใน JSON ที่ระบุ ดูข้อมูลเพิ่มเติมเกี่ยวกับฟิลด์เหล่านี้และสิ่งที่แสดงได้ที่เอกสารประกอบเกี่ยวกับ API
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
"ส่ง" คำขอ createJob API

รหัสการตอบกลับจะอยู่ครึ่งล่างของหน้า

คุณควรได้รับการตอบกลับ HTTP 202 เมื่อบริการรวบรวมข้อมูลยอมรับคำขอแล้ว โค้ดตอบกลับอื่นๆ ที่เป็นไปได้จะระบุไว้ในข้อกําหนดของ API
3.2.2. การใช้ปลายทาง getJob เพื่อดึงข้อมูลสถานะการประมวลผลเป็นกลุ่ม
ใช้วิธีการ cURL หรือ Postman ด้านล่างเพื่อรับงาน
cURL
ดำเนินการตามคำขอด้านล่างในเทอร์มินัล แทนที่ตัวยึดตําแหน่งใน URL ด้วยค่าจาก frontend_service_cloudfunction_url ซึ่งเป็น URL เดียวกับที่คุณใช้สําหรับคําขอ createJob สำหรับ "job_request_id" ให้ใช้ค่าจากงานที่สร้างขึ้นด้วยปลายทาง createJob
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
ผลลัพธ์ควรแสดงสถานะคำของานของคุณที่มีสถานะ HTTP 200 "เนื้อหา" ของคำขอมีข้อมูลที่จำเป็น เช่น job_status, return_message และ error_messages (หากงานเกิดข้อผิดพลาด)
Postman
หากต้องการตรวจสอบสถานะคำของาน คุณสามารถใช้ปลายทาง getJob ในส่วน "Params" ของคําขอ getJob ให้อัปเดตค่า job_request_id เป็น job_request_id ที่ส่งในคําขอ createJob
"ส่ง" คำขอ getJob

ผลลัพธ์ควรแสดงสถานะคำของานของคุณที่มีสถานะ HTTP 200 "เนื้อหา" ของคําขอมีข้อมูลที่จําเป็น เช่น job_status, return_message และ error_messages (หากงานเกิดข้อผิดพลาด)
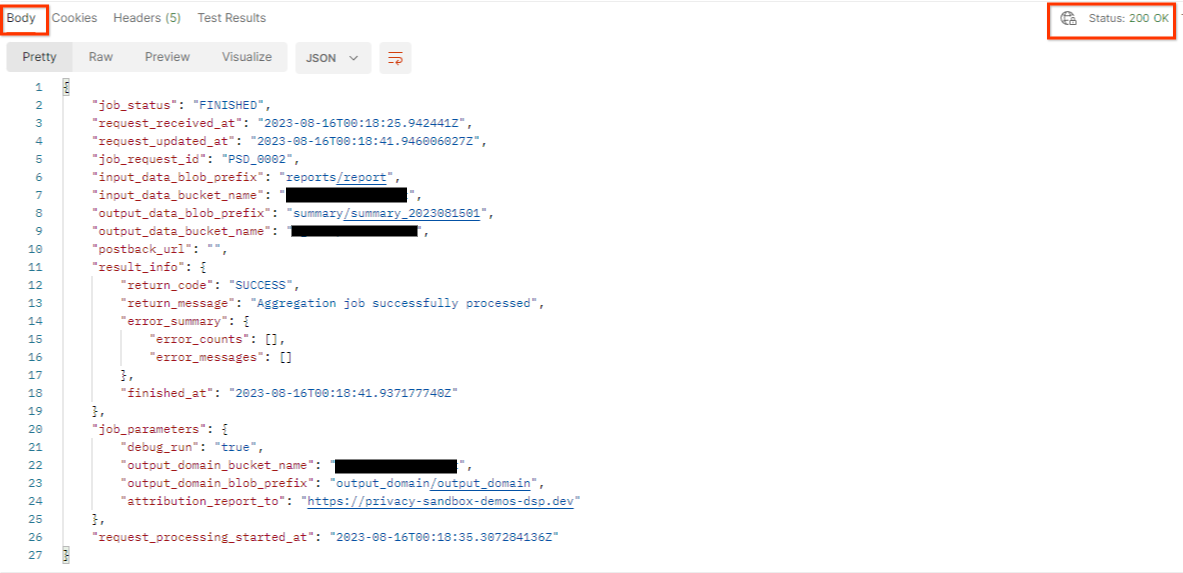
3.2.3. การตรวจสอบรายงานสรุป
เมื่อได้รับรายงานสรุปในที่เก็บข้อมูล Cloud Storage ของเอาต์พุตแล้ว คุณจะดาวน์โหลดรายงานนี้ลงในสภาพแวดล้อมในเครื่องได้ รายงานสรุปอยู่ในรูปแบบ AVRO และสามารถแปลงกลับเป็น JSON ได้ คุณสามารถใช้ aggregatable_report_converter.jar เพื่ออ่านรายงานโดยใช้คําสั่งด้านล่าง
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
ซึ่งจะแสดงผล JSON ของค่ารวมของคีย์ที่เก็บข้อมูลแต่ละรายการซึ่งมีลักษณะคล้ายกับด้านล่าง

หากคำขอ createJob มี debug_run เป็น "จริง" คุณจะได้รับการรายงานสรุปในโฟลเดอร์แก้ไขข้อบกพร่องที่อยู่ใน output_data_blob_prefix รายงานอยู่ในรูปแบบ AVRO และสามารถแปลงเป็น JSON โดยใช้คําสั่งข้างต้น
รายงานมีคีย์ที่เก็บข้อมูล เมตริกที่ไม่มีสัญญาณรบกวน และสัญญาณรบกวนซึ่งเพิ่มลงในเมตริกที่ไม่มีสัญญาณรบกวนเพื่อสร้างรายงานสรุป รายงานจะมีลักษณะคล้ายกับด้านล่าง

คําอธิบายประกอบยังมี "in_reports" และ/หรือ "in_domain" ซึ่งหมายความว่า
- in_reports - คีย์ที่เก็บข้อมูลจะอยู่ในรายงานที่รวบรวมข้อมูลได้
- in_domain - คีย์ที่เก็บข้อมูลอยู่ในไฟล์ AVRO ของ output_domain
Codelab เสร็จสมบูรณ์
สรุป: คุณได้ติดตั้งใช้งานบริการรวบรวมข้อมูลในสภาพแวดล้อมระบบคลาวด์ของคุณเอง รวบรวมรายงานการแก้ไขข้อบกพร่อง สร้างไฟล์โดเมนเอาต์พุต จัดเก็บไฟล์เหล่านี้ในที่เก็บข้อมูล Cloud Storage และเรียกใช้งานที่ประสบความสําเร็จ
ขั้นตอนถัดไป: ใช้บริการรวบรวมข้อมูลในสภาพแวดล้อมต่อไป หรือลบทรัพยากรระบบคลาวด์ที่คุณเพิ่งสร้างขึ้นโดยทําตามวิธีการล้างข้อมูลในขั้นตอนที่ 4
4. 4. การจัดระเบียบ
หากต้องการลบทรัพยากรที่สร้างไว้สําหรับบริการรวบรวมข้อมูลผ่าน Terraform ให้ใช้คําสั่ง destroy ในโฟลเดอร์ adtech_setup และ dev (หรือสภาพแวดล้อมอื่นๆ) ดังนี้
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
วิธีลบที่เก็บข้อมูล Cloud Storage ที่มีรายงานที่รวบรวมได้และรายงานสรุป
$ gcloud storage buckets delete gs://my-bucket
นอกจากนี้ คุณยังเลือกเปลี่ยนการตั้งค่าคุกกี้ Chrome จากข้อกําหนดเบื้องต้น 1.2 กลับไปเป็นสถานะก่อนหน้าได้ด้วย
5. 5. ภาคผนวก
ไฟล์ adtech_setup.auto.tfvars ตัวอย่าง
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
ไฟล์ dev.auto.tfvars ตัวอย่าง
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20