
1. 1. Prerequisiti
Tempo stimato per il completamento: 1-2 ore
Esistono due modalità per eseguire questo codelab: Test locale o Servizio di aggregazione. La modalità di test locale richiede un computer locale e il browser Chrome (nessuna creazione/utilizzo di risorse Google Cloud). La modalità Servizio di aggregazione richiede un deployment completo del servizio su Google Cloud.
Per eseguire questo codelab in una delle due modalità, sono necessari alcuni prerequisiti. Ogni requisito è contrassegnato di conseguenza in base al fatto che sia necessario per i test locali o per il servizio di aggregazione.
1.1. Registrazione e attestazione complete (servizio di aggregazione)
Per utilizzare le API Privacy Sandbox, assicurati di aver completato la registrazione e l'attestazione sia per Chrome che per Android.
1.2. Attivare le API di privacy per gli annunci (servizio di aggregazione e test locali)
Poiché utilizzeremo Privacy Sandbox, ti invitiamo ad attivare le API Privacy Sandbox Ads.
Sul browser, vai a chrome://settings/adPrivacy e attiva tutte le API di privacy per gli annunci.
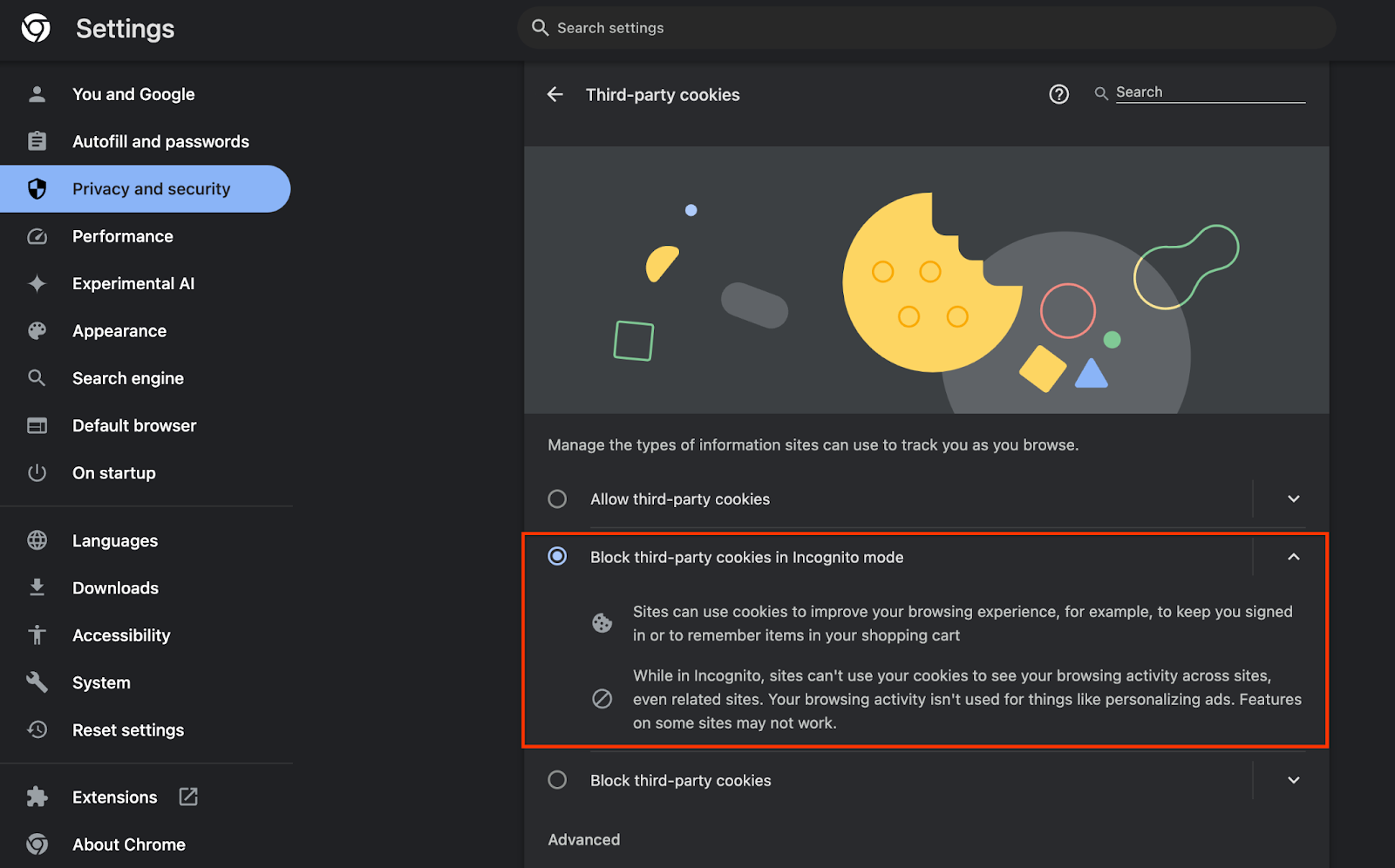
Assicurati inoltre che i cookie di terze parti siano abilitati.
Da chrome://settings/cookies, assicurati che i cookie di terze parti NON siano bloccati. A seconda della versione di Chrome, potresti vedere opzioni diverse in questo menu delle impostazioni, ma le configurazioni accettabili includono:
- "Blocca tutti i cookie di terze parti" = DISATTIVATA
- "Blocca cookie di terze parti" = DISATTIVATA
- "Blocca cookie di terze parti in modalità di navigazione in incognito" = ABILITATO
1.3. Scaricare lo strumento di test locale (test locale)
Per i test locali è necessario scaricare lo strumento di test locale. Lo strumento genererà report di riepilogo dai report di debug non criptati.
Lo strumento di test locale è disponibile per il download negli archivi JAR di Cloud Function su GitHub. Deve essere denominato LocalTestingTool_{version}.jar.
1.4. Assicurati che sia installato JAVA JRE (servizio di test e aggregazione locale)
Apri "Terminale" e usa java --version per verificare se sul tuo computer è installato Java o openJDK.

Se non è installato, puoi scaricarlo e installarlo dal sito Java o dal sito openJDK.
1.5. Scarica aggregatable_report_converter (servizio di test e aggregazione locale)
Puoi scaricare una copia di aggregatable_report_converter dal repository GitHub di Privacy Sandbox Demos. Il repository GitHub menziona l'utilizzo di IntelliJ o Eclipse, ma non è obbligatorio. Se non utilizzi questi strumenti, scarica il file JAR nel tuo ambiente locale.
1.6. Configurare un ambiente Google Cloud (servizio di aggregazione)
Il servizio di aggregazione richiede l'utilizzo di un ambiente Trusted Execution Environment che utilizza un provider cloud. In questo codelab, il servizio di aggregazione verrà implementato in Google Cloud, ma è supportato anche AWS.
Segui le istruzioni di deployment su GitHub per configurare gcloud CLI, scaricare i moduli e i binari di Terraform e creare risorse Google Cloud per il servizio di aggregazione.
Passaggi chiave nelle istruzioni di deployment:
- Configura l'interfaccia a riga di comando "gcloud" e Terraform nel tuo ambiente.
- Crea un bucket Cloud Storage per archiviare lo stato di Terraform.
- Scarica le dipendenze.
- Aggiorna
adtech_setup.auto.tfvarsed eseguiadtech_setupTerraform. Consulta l'appendice per un esempio di fileadtech_setup.auto.tfvars. Prendi nota del nome del bucket di dati creato qui: verrà utilizzato nel codelab per archiviare i file che creiamo. - Aggiorna
dev.auto.tfvars, esegui il rappresentazione dell'account di servizio di deployment ed eseguidevTerraform. Consulta l'appendice per un esempio di filedev.auto.tfvars. - Al termine del deployment, acquisizione
frontend_service_cloudfunction_urldall'output di Terraform, che sarà necessario per effettuare richieste al servizio di aggregazione nei passaggi successivi.
1.7. Completa l'onboarding del servizio di aggregazione (servizio di aggregazione)
Il servizio di aggregazione richiede l'onboarding dei coordinatori per poter essere utilizzato. Compila il modulo di onboarding del servizio di aggregazione fornendo il tuo sito di generazione di report e altre informazioni, selezionando "Google Cloud" e inserendo l'indirizzo del tuo account di servizio. Questo account di servizio viene creato nel prerequisito precedente (1.6. Configura un ambiente Google Cloud). Suggerimento: se utilizzi i nomi predefiniti forniti, questo account di servizio inizierà con "worker-sa@".
Attendi fino a 2 settimane per il completamento della procedura di onboarding.
1.8. Determina il metodo per chiamare gli endpoint dell'API (servizio di aggregazione)
Questo codelab fornisce due opzioni per chiamare gli endpoint dell'API del servizio di aggregazione: cURL e Postman. cURL è il modo più rapido e semplice per chiamare gli endpoint dell'API dal terminale, poiché richiede una configurazione minima e nessun software aggiuntivo. Tuttavia, se non vuoi utilizzare cURL, puoi utilizzare Postman per eseguire e salvare le richieste API per un uso futuro.
Nella sezione 3.2. Utilizzo del servizio di aggregazione, troverai istruzioni dettagliate per l'utilizzo di entrambe le opzioni. Puoi visualizzarne l'anteprima per decidere quale metodo utilizzare. Se selezioni Postman, esegui la seguente configurazione iniziale.
1.8.1. Configura spazio di lavoro
Registrati per creare un account Postman. Una volta effettuata la registrazione, viene creato automaticamente uno spazio di lavoro.
Se non è stata creata un'area di lavoro per te, vai all'elemento di navigazione superiore "Spazi di lavoro" e seleziona "Crea spazio di lavoro".
Seleziona "Spazio di lavoro vuoto", fai clic su Avanti e assegna il nome "Privacy Sandbox di Google Cloud". Seleziona "Personale" e fai clic su "Crea".
Scarica la configurazione JSON e i file dell'ambiente globale dello spazio di lavoro preconfigurato.
Importa entrambi i file JSON in "La mia area di lavoro" tramite il pulsante "Importa".

Verrà creata la raccolta "Privacy Sandbox di Google Cloud" insieme alle richieste HTTP createJob e getJob.
1.8.2. Configura l'autorizzazione
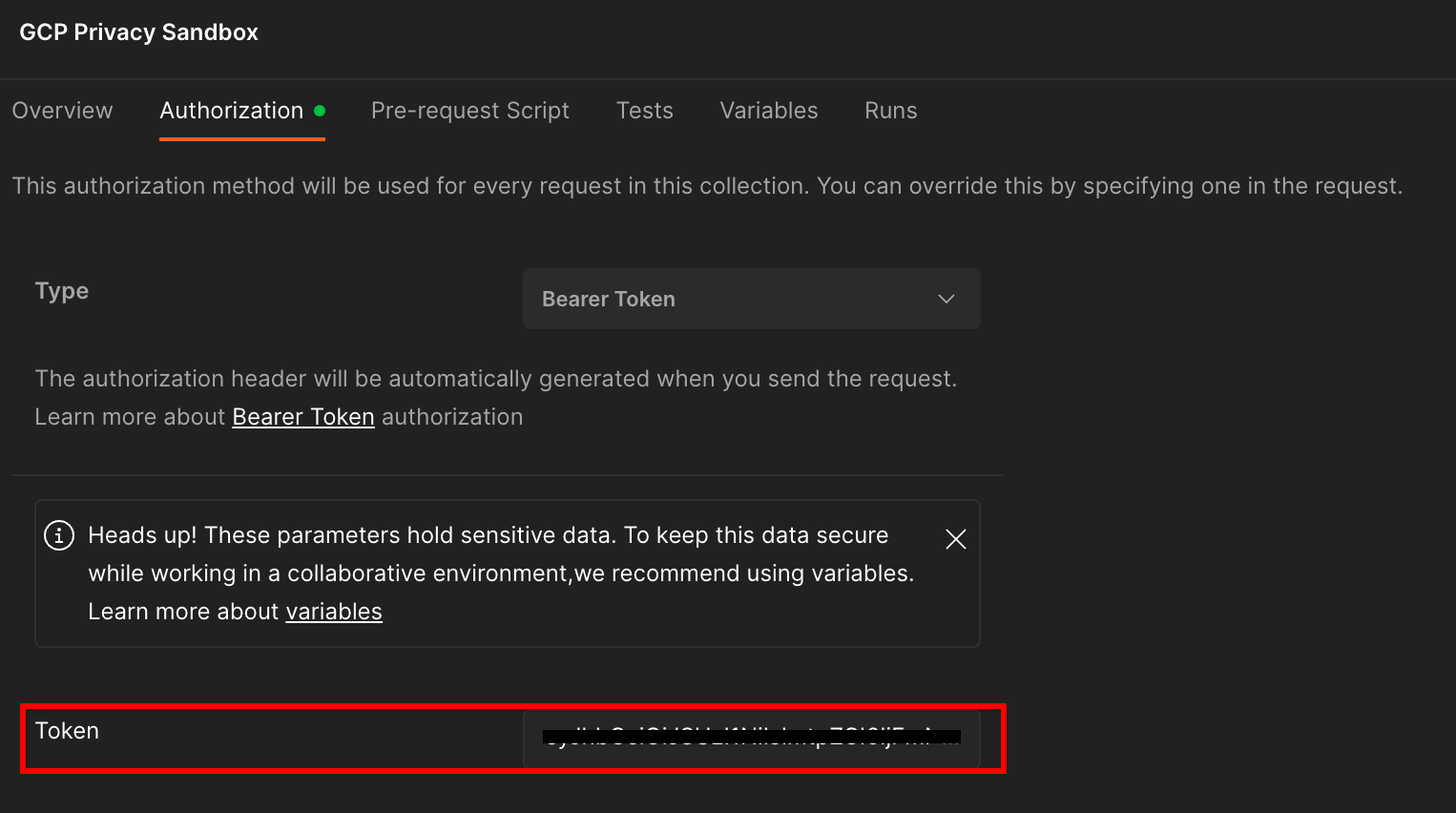
Fai clic sulla raccolta "Privacy Sandbox di Google Cloud" e vai alla scheda "Autorizzazione".

Dovrai utilizzare il metodo "Token bearer". Nell'ambiente Terminal, esegui questo comando e copia l'output.
gcloud auth print-identity-token
Poi incolla questo valore del token nel campo "Token" della scheda di autorizzazione di Postman:
1.8.3. Configura l'ambiente
Vai a "Anteprima rapida dell'ambiente" nell'angolo in alto a destra:
Fai clic su "Modifica" e aggiorna il "Valore corrente" di "environment", "region" e "cloud-function-id":
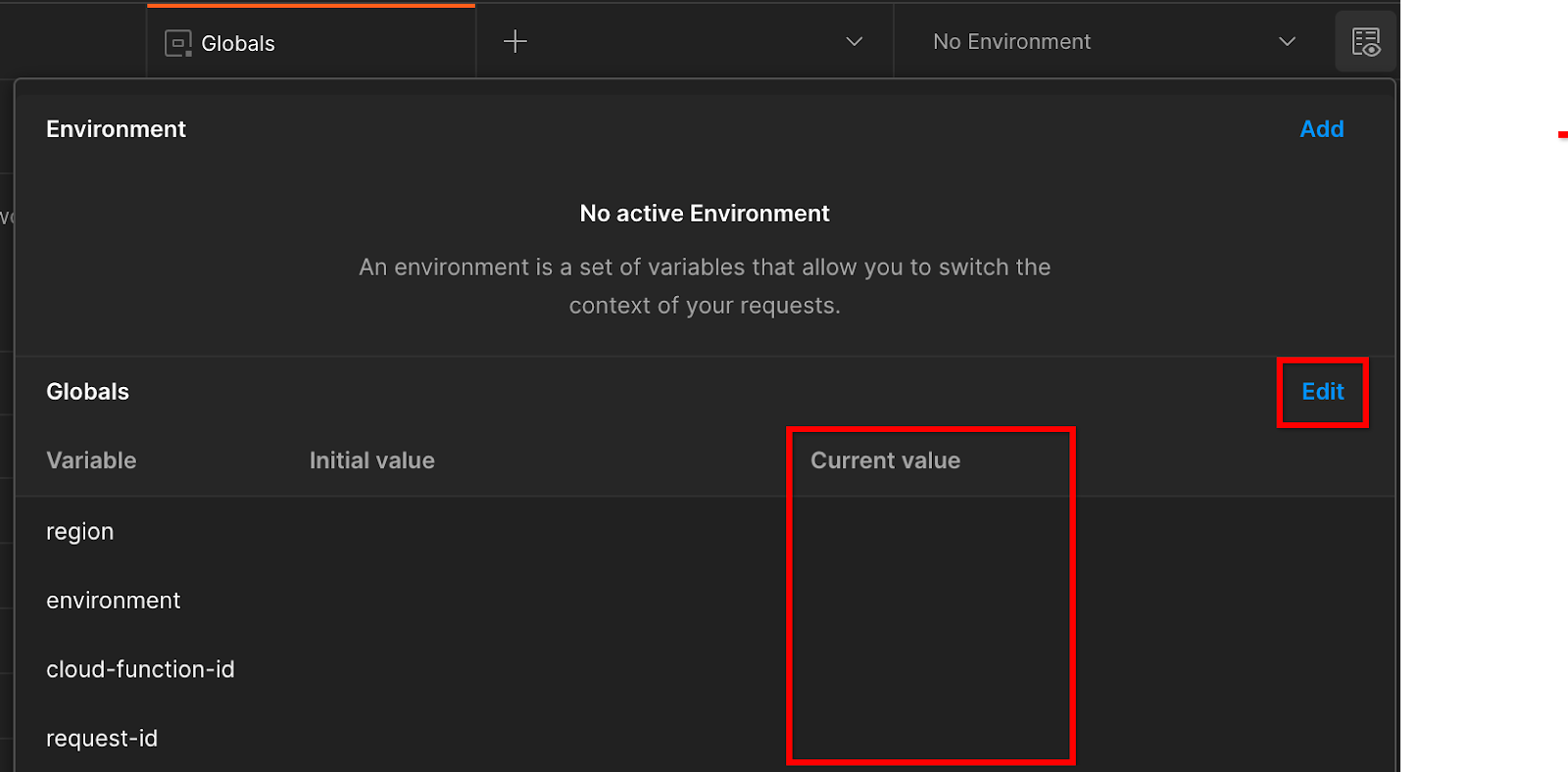
Per il momento puoi lasciare vuoto il campo "request-id", che verrà compilato in un secondo momento. Per gli altri campi, utilizza i valori di frontend_service_cloudfunction_url, restituiti dal completamento del deployment di Terraform nel Prerequisito 1.6. L'URL deve avere il seguente formato: https://
2. 2. Codelab sui test locali
Tempo stimato per il completamento: meno di 1 ora
Puoi utilizzare lo strumento di test locale sul tuo computer per eseguire l'aggregazione e generare report di riepilogo utilizzando i report di debug non criptati. Prima di iniziare, assicurati di aver completato tutti i prerequisiti contrassegnati come "Test locale".
Passaggi del codelab
Passaggio 2.1. Attiva report: attiva i report di aggregazione privata per poterli raccogliere.
Passaggio 2.2. Crea report di debug AVRO: converti il report JSON raccolto in un report in formato AVRO. Questo passaggio sarà simile a quando le adTech raccolgono i report dagli endpoint di reporting dell'API e li convertono in report in formato AVRO.
Passaggio 2.3. Recupera le chiavi del bucket: le chiavi del bucket sono progettate dalle adTech. In questo codelab, poiché i bucket sono predefiniti, recupera le chiavi dei bucket come indicato.
Passaggio 2.4. Crea file Avro del dominio di output: dopo aver recuperato le chiavi del bucket, crea il file Avro del dominio di output.
Passaggio 2.5. Crea report di riepilogo: utilizza lo strumento di test locale per creare report di riepilogo nell'ambiente locale.
Passaggio 2.6. Esamina i report di riepilogo: esamina il report di riepilogo creato dallo strumento di test locale.
2.1. Report Trigger
Per attivare un report di aggregazione privato, puoi utilizzare il sito demo di Privacy Sandbox (https://privacy-sandbox-demos-news.dev/?env=gcp) o il tuo sito (ad es. https://adtechexample.com). Se utilizzi il tuo sito e non hai completato la registrazione e l'attestazione e l'onboarding del servizio di aggregazione, dovrai utilizzare un flag di Chrome e un'opzione CLI.
Per questa demo, utilizzeremo il sito demo di Privacy Sandbox. Segui il link per accedere al sito, quindi puoi visualizzare i report all'indirizzo chrome://private-aggregation-internals:
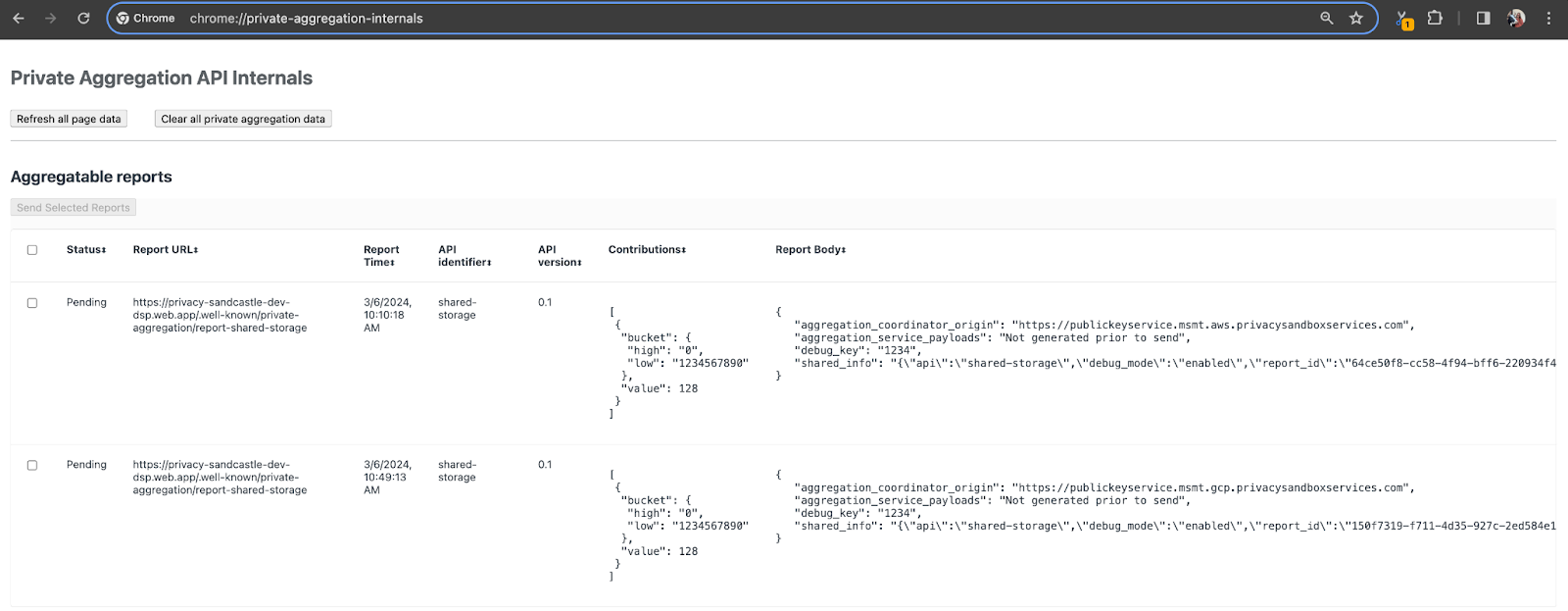
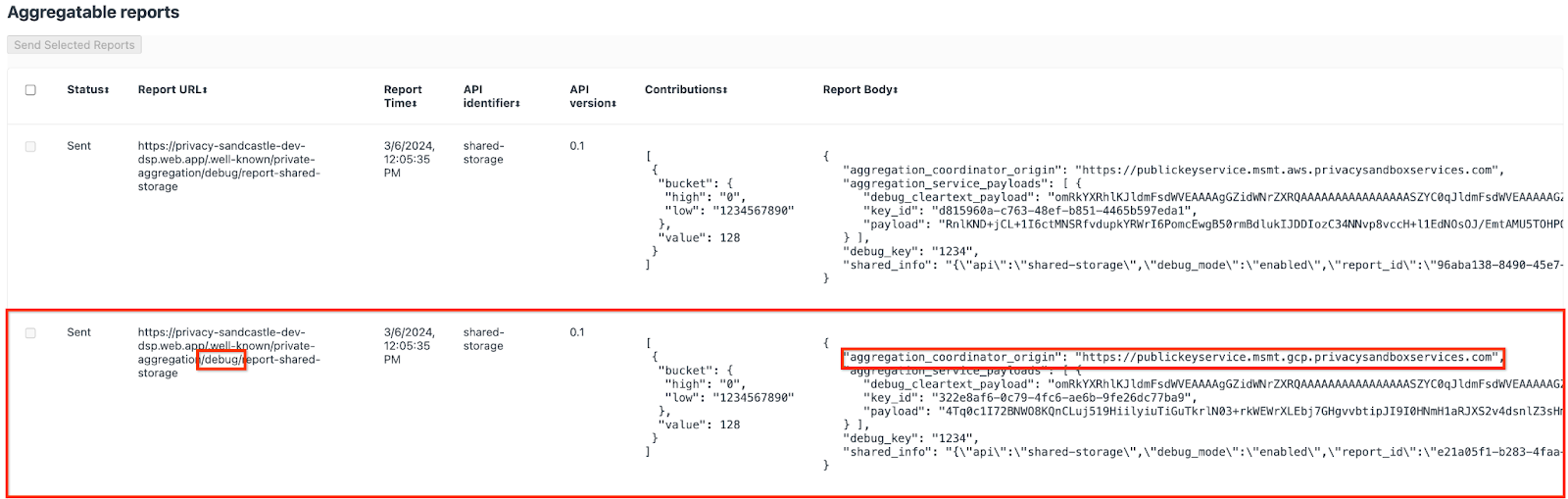
Il report inviato all'endpoint {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage si trova anche nel "Testo del report" dei report visualizzati nella pagina Informazioni interne di Chrome.
Potresti visualizzare molti report qui, ma per questo codelab, utilizza il report aggregabile specifico per Google Cloud e generato dall'endpoint di debug. L'URL report conterrà "/debug/" e il aggregation_coordinator_origin field del "Testo del report" conterrà questo URL: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
2.2. Crea report aggregabile di debug
Copia il report trovato nel "Report Body" di chrome://private-aggregation-internals e crea un file JSON nella cartella privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar (all'interno del repository scaricato nel Prerequisito 1.5).
In questo esempio utilizziamo vim perché stiamo usando Linux. Tuttavia, puoi utilizzare qualsiasi editor di testo.
vim report.json
Incolla il report in report.json e salva il file.

Una volta ottenuto, utilizza aggregatable_report_converter.jar per creare il report aggregabile per il debug. Viene creato un report aggregabile denominato report.avro nella directory corrente.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Recupera la chiave del bucket dal report
Per creare il file output_domain.avro, devi disporre delle chiavi del bucket che possono essere recuperate dai report.
Le chiavi dei bucket sono progettate dall'adTech. Tuttavia, in questo caso, il sito Privacy Sandbox Demo crea le chiavi del bucket. Poiché l'aggregazione privata per questo sito è in modalità di debug, possiamo utilizzare debug_cleartext_payload dal "Testo del report" per ottenere la chiave del bucket.
Copia debug_cleartext_payload dal corpo del report.

Apri goo.gle/ags-payload-decoder, incolla il tuo debug_cleartext_payload nella casella "INPUT" e fai clic su "Decodifica".
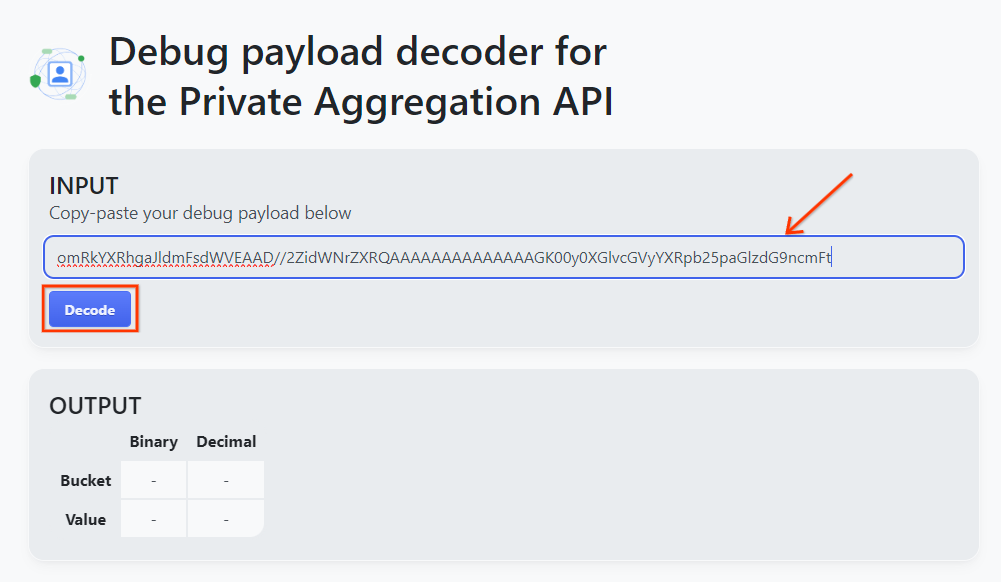
La pagina restituisce il valore decimale della chiave del bucket. Di seguito è riportata una chiave del bucket di esempio.
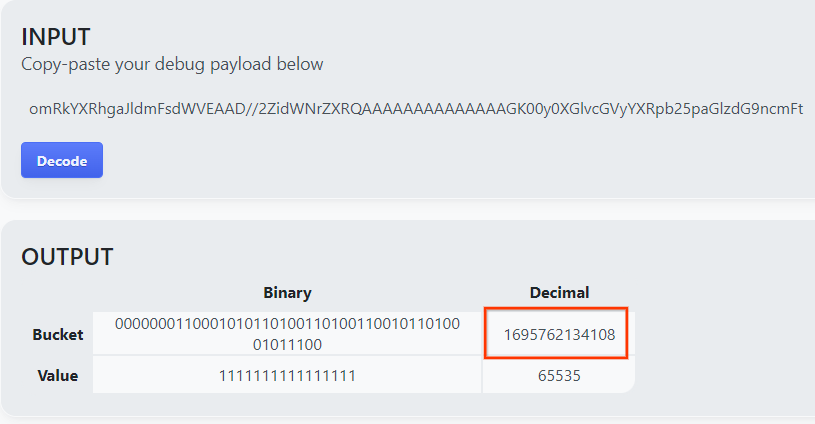
2.4. Crea dominio di output AVRO
Ora che abbiamo la chiave del bucket, creiamo il file output_domain.avro nella stessa cartella in cui abbiamo lavorato. Assicurati di sostituire la chiave del bucket con quella che hai recuperato.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Lo script crea il file output_domain.avro nella cartella corrente.
2.5. Creare report di riepilogo utilizzando lo strumento di test locale
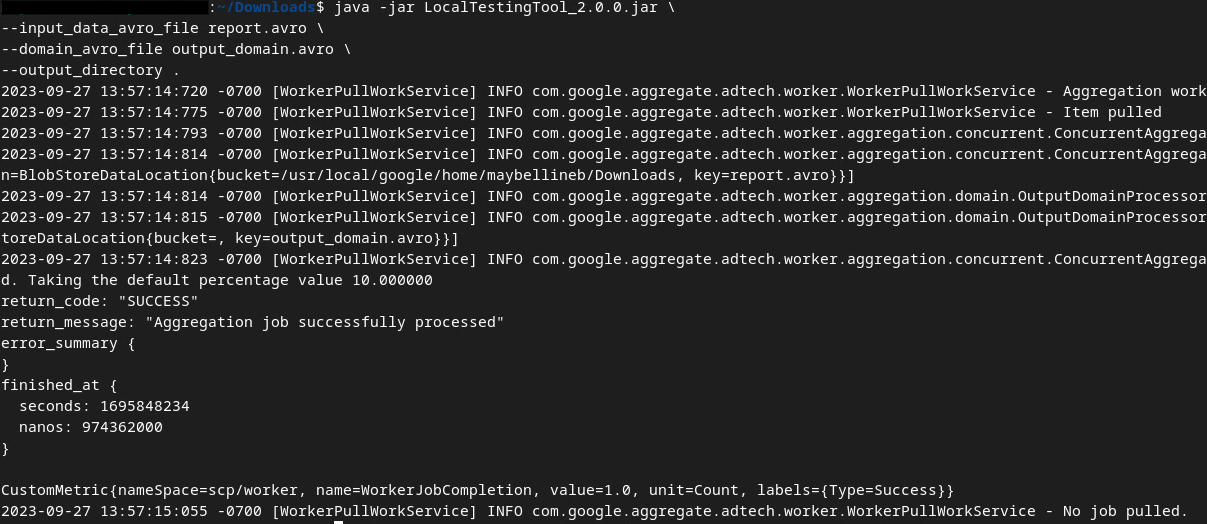
Utilizzeremo LocalTestingTool_{version}.jar scaricato nel Prerequisito 1.3 per creare i report di riepilogo utilizzando il comando riportato di seguito. Sostituisci {version} con la versione che hai scaricato. Ricordati di spostare LocalTestingTool_{version}.jar nella directory corrente o di aggiungere un percorso relativo per fare riferimento alla posizione corrente.
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
Una volta eseguito il comando, dovresti visualizzare un messaggio simile al seguente. Al termine dell'operazione viene creato un report output.avro.
2.6. Esamina il report di riepilogo
Il report di riepilogo creato è in formato AVRO. Per poterlo leggere, devi convertirlo da AVRO a un formato JSON. Idealmente, la tecnologia adTech dovrebbe scrivere codice per convertire i report AVRO in JSON.
Utilizzeremo aggregatable_report_converter.jar per convertire nuovamente il report AVRO in JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
Viene restituito un report simile al seguente. Insieme a un report output.json creato nella stessa directory.

Codelab completato.
Riepilogo: hai raccolto un report di debug, creato un file di dominio di output e generato un report di riepilogo utilizzando lo strumento di test locale che simula il comportamento di aggregazione del servizio di aggregazione.
Passaggi successivi:ora che hai sperimentato lo strumento di test locale, puoi provare lo stesso esercizio con un deployment in produzione del servizio di aggregazione nel tuo ambiente. Rivedi i prerequisiti per assicurarti di aver configurato tutto per la modalità "Servizio di aggregazione", quindi vai al passaggio 3.
3. 3. Codelab del servizio di aggregazione
Tempo stimato per il completamento: 1 ora
Prima di iniziare, assicurati di aver completato tutti i prerequisiti etichettati come "Servizio di aggregazione".
Passaggi del codelab
Passaggio 3.1. Creazione di input per il servizio di aggregazione: crea i report del servizio di aggregazione raggruppati per il servizio di aggregazione.
- Passaggio 3.1.1. Report Trigger
- Passaggio 3.1.2. Raccogliere report aggregabili
- Passaggio 3.1.3. Converti i report in AVRO
- Passaggio 3.1.4. Crea output_domain AVRO
- Passaggio 3.1.5. Spostare i report nel bucket Cloud Storage
Passaggio 3.2. Utilizzo del servizio di aggregazione: utilizza l'API del servizio di aggregazione per creare report di riepilogo e rivederli.
- Passaggio 3.2.1. Utilizzo di
createJobEndpoint per il batch - Passaggio 3.2.2. Utilizzo dell'endpoint
getJobper recuperare lo stato del batch - Passaggio 3.2.3. Esaminare il report di riepilogo
3.1. Creazione di input per il servizio di aggregazione
Procedi creando i report AVRO per l'aggregazione nel servizio di aggregazione. I comandi shell in questi passaggi possono essere eseguiti in Cloud Shell di Google Cloud (a condizione che le dipendenze dei prerequisiti siano clonate nel tuo ambiente Cloud Shell) o in un ambiente di esecuzione locale.
3.1.1. Report Trigger
Segui il link per accedere al sito, quindi puoi visualizzare i report all'indirizzo chrome://private-aggregation-internals:
Il report inviato all'endpoint {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage si trova anche nel "Testo del report" dei report visualizzati nella pagina Informazioni interne di Chrome.
Potresti visualizzare molti report qui, ma per questo codelab, utilizza il report aggregabile specifico per Google Cloud e generato dall'endpoint di debug. L'URL report conterrà "/debug/" e il aggregation_coordinator_origin field del "Testo del report" conterrà questo URL: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
3.1.2. Raccogliere report aggregabili
Raccogli i report aggregabili dagli endpoint .well-known della tua API corrispondente.
- Private Aggregation:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - Attribution Reporting - Report di riepilogo:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
Per questo codelab, eseguiamo la raccolta dei report manualmente. In produzione, le piattaforme ad tech devono raccogliere e convertire i report in modo programmatico.
Andiamo avanti e copiamo il report JSON in "Testo report" da chrome://private-aggregation-internals.
In questo esempio utilizziamo vim perché stiamo usando Linux. Tuttavia, puoi utilizzare qualsiasi editor di testo.
vim report.json
Incolla il report in report.json e salva il file.
3.1.3. Converti i report in AVRO
I report ricevuti dagli endpoint .well-known sono in formato JSON e devono essere convertiti in formato report AVRO. Una volta ottenuto il report JSON, vai alla posizione in cui è archiviato report.json e utilizza aggregatable_report_converter.jar per creare il report aggregabile di debug. Viene creato un report aggregabile denominato report.avro nella directory corrente.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. Crea output_domain AVRO
Per creare il file output_domain.avro, devi disporre delle chiavi del bucket che possono essere recuperate dai report.
Le chiavi dei bucket sono progettate dall'adTech. Tuttavia, in questo caso, il sito Privacy Sandbox Demo crea le chiavi del bucket. Poiché l'aggregazione privata per questo sito è in modalità di debug, possiamo utilizzare debug_cleartext_payload dal "Testo del report" per ottenere la chiave del bucket.
Copia debug_cleartext_payload dal corpo del report.
Apri goo.gle/ags-payload-decoder, incolla il tuo debug_cleartext_payload nella casella "INPUT" e fai clic su "Decodifica".
La pagina restituisce il valore decimale della chiave del bucket. Di seguito è riportata una chiave del bucket di esempio.
Ora che abbiamo la chiave del bucket, creiamo il file output_domain.avro nella stessa cartella in cui abbiamo lavorato. Assicurati di sostituire la chiave del bucket con quella che hai recuperato.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Lo script crea il file output_domain.avro nella cartella corrente.
3.1.5. Spostare i report nel bucket Cloud Storage
Dopo aver creato i report e il dominio di output Avro, spostali nel bucket in Cloud Storage (che hai annotato nel Prerequisito 1.6).
Se hai configurato gcloud CLI nel tuo ambiente locale, utilizza i comandi riportati di seguito per copiare i file nelle cartelle corrispondenti.
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
In caso contrario, carica manualmente i file nel bucket. Crea una cartella denominata "report" e carica il file report.avro al suo interno. Crea una cartella denominata "output_domains" e carica il file output_domain.avro al suo interno.
3.2. Utilizzo del servizio di aggregazione
Ricorda che nel Prerequisito 1.8 hai selezionato cURL o Postman per effettuare richieste API agli endpoint del servizio di aggregazione. Di seguito sono riportate le istruzioni per entrambe le opzioni.
Se il job non va a buon fine a causa di un errore, consulta la nostra documentazione sulla risoluzione dei problemi in GitHub per ulteriori informazioni su come procedere.
3.2.1. Utilizzo di createJob Endpoint per il batch
Utilizza le istruzioni di cURL o Postman riportate di seguito per creare un job.
cURL
In "Terminale", crea un file del corpo della richiesta (body.json) e incolla il codice riportato di seguito. Assicurati di aggiornare i valori segnaposto. Per ulteriori informazioni su cosa rappresenta ogni campo, consulta questa documentazione dell'API.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Esegui la richiesta riportata di seguito. Sostituisci i segnaposto nell'URL della richiesta cURL con i valori di frontend_service_cloudfunction_url, che viene visualizzato dopo il completamento del deployment di Terraform nel Prerequisito 1.6.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
Una volta che la richiesta viene accettata dal servizio di aggregazione, dovresti ricevere una risposta HTTP 202. Altri possibili codici di risposta sono documentati nelle specifiche dell'API.
Postman
Per l'endpoint createJob, è necessario un corpo della richiesta per fornire al servizio di aggregazione la posizione e i nomi dei file dei report aggregabili, dei domini di output e dei report di riepilogo.
Vai alla scheda "Testo" della richiesta createJob:

Sostituisci i segnaposto all'interno del file JSON fornito. Per ulteriori informazioni su questi campi e su cosa rappresentano, consulta la documentazione dell'API.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
"Invia" la richiesta all'API createJob:

Il codice di risposta si trova nella metà inferiore della pagina:

Una volta che la richiesta viene accettata dal servizio di aggregazione, dovresti ricevere una risposta HTTP 202. Altri possibili codici di risposta sono documentati nelle specifiche dell'API.
3.2.2. Utilizzo dell'endpoint getJob per recuperare lo stato del batch
Utilizza le istruzioni di cURL o Postman riportate di seguito per ottenere un job.
cURL
Esegui la richiesta riportata di seguito nel terminale. Sostituisci i segnaposto nell'URL con i valori di frontend_service_cloudfunction_url, lo stesso URL utilizzato per la richiesta createJob. Per "job_request_id", utilizza il valore del job creato con l'endpoint createJob.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
Il risultato dovrebbe restituire lo stato della richiesta di job con un codice di stato HTTP 200. Il "corpo" della richiesta contiene le informazioni necessarie, come job_status, return_message e error_messages (se il job ha generato un errore).
Postman
Per controllare lo stato della richiesta di job, puoi utilizzare l'endpoint getJob. Nella sezione "Params" della richiesta getJob, aggiorna il valore job_request_id con il valore job_request_id inviato nella richiesta createJob.
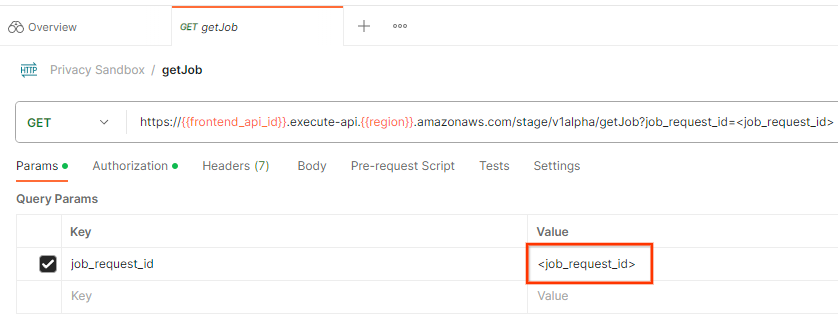
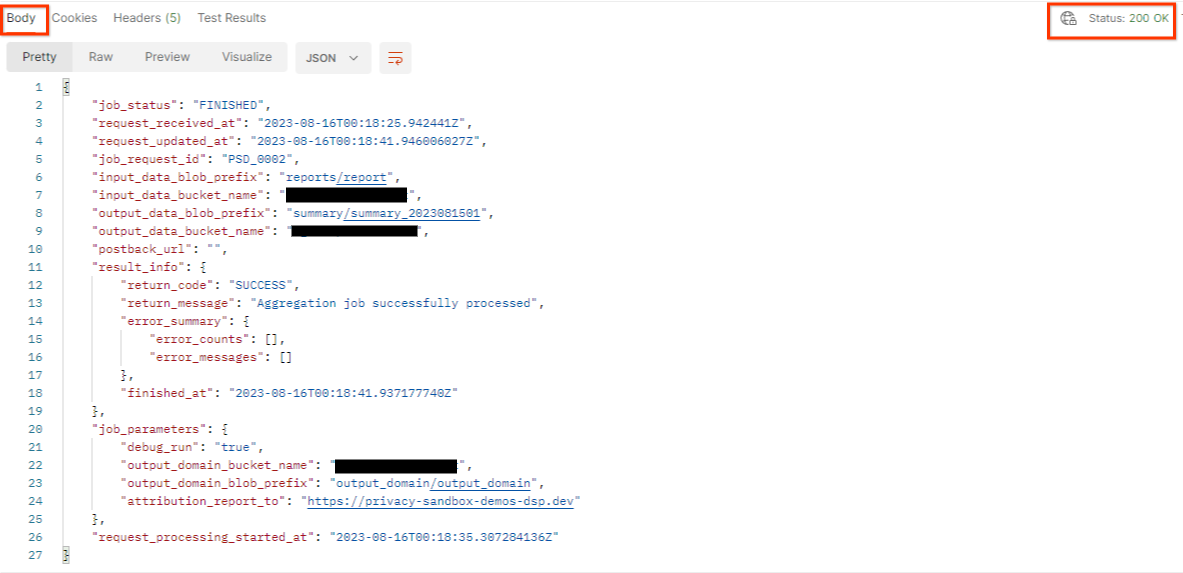
"Invia" la richiesta getJob:

Il risultato dovrebbe restituire lo stato della richiesta di job con un codice di stato HTTP 200. Il "corpo" della richiesta contiene le informazioni necessarie, come job_status, return_message e error_messages (se il job ha generato un errore).
3.2.3. Esaminare il report di riepilogo
Una volta ricevuto il report di riepilogo nel bucket Cloud Storage di output, puoi scaricarlo nel tuo ambiente locale. I report di riepilogo sono in formato AVRO e possono essere convertiti nuovamente in JSON. Puoi utilizzare aggregatable_report_converter.jar per leggere il report utilizzando il comando riportato di seguito.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
Viene restituito un file JSON dei valori aggregati di ogni chiave del bucket simile al seguente.

Se la richiesta createJob include debug_run come true, puoi ricevere il report di riepilogo nella cartella di debug che si trova in output_data_blob_prefix. Il report è in formato AVRO e può essere convertito in JSON utilizzando il comando riportato sopra.
Il report contiene la chiave del bucket, la metrica senza rumore e il rumore aggiunto alla metrica senza rumore per formare il report di riepilogo. Il report è simile al seguente.

Le annotazioni contengono anche "in_reports" e/o "in_domain", il che significa che:
- in_reports: la chiave del bucket è disponibile all'interno dei report aggregabili.
- in_domain: la chiave del bucket è disponibile all'interno del file AVRO output_domain.
Codelab completato.
Riepilogo: hai eseguito il deployment del servizio di aggregazione nel tuo ambiente cloud, hai raccolto un report di debug, hai creato un file di dominio di output, hai archiviato questi file in un bucket Cloud Storage ed eseguito un job con esito positivo.
Passaggi successivi:continua a utilizzare il servizio di aggregazione nel tuo ambiente o elimina le risorse cloud che hai appena creato seguendo le istruzioni di pulizia nel passaggio 4.
4. 4. Eliminazione
Per eliminare le risorse create per il servizio di aggregazione tramite Terraform, utilizza il comando destroy nelle cartelle adtech_setup e dev (o in un altro ambiente):
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
Per eliminare il bucket Cloud Storage contenente i report aggregabili e di riepilogo:
$ gcloud storage buckets delete gs://my-bucket
Puoi anche scegliere di ripristinare le impostazioni dei cookie di Chrome dal Prerequisito 1.2 allo stato precedente.
5. 5. Appendice
File adtech_setup.auto.tfvars di esempio
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
File dev.auto.tfvars di esempio
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20