
1. 1. Pré-requisitos
Tempo estimado para a conclusão: de uma a duas horas
Há dois modos para realizar este codelab: teste local ou serviço de agregação. O modo de teste local exige uma máquina local e o navegador Chrome (sem criação/uso de recursos do Google Cloud). O modo de serviço de agregação exige uma implantação completa do serviço de agregação no Google Cloud.
Para realizar este codelab em qualquer um dos modos, alguns pré-requisitos são necessários. Cada requisito é marcado de acordo com se ele é necessário para o teste local ou o serviço de agregação.
1.1. Registro e atestado completos (serviço de agregação)
Para usar as APIs do Sandbox de privacidade, conclua a inscrição e atestado para o Chrome e o Android.
1.2. Ativar as APIs de privacidade de anúncios (serviço de testes locais e agregação)
Como vamos usar o Sandbox de privacidade, recomendamos que você ative as APIs do Sandbox de publicidade.
No navegador, acesse chrome://settings/adPrivacy e ative todas as APIs de privacidade de anúncios.
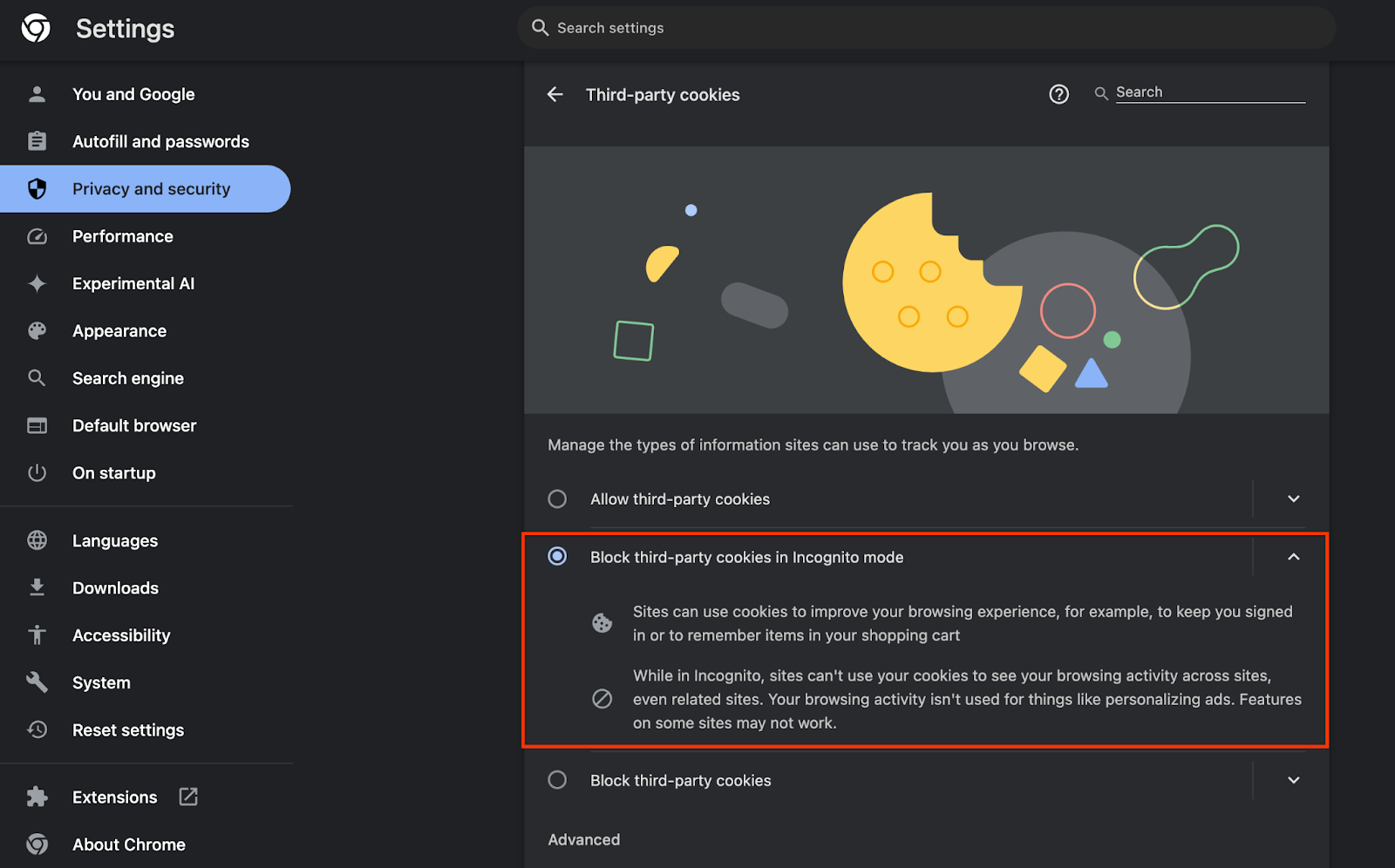
Verifique também se os cookies de terceiros estão ativados.
Em chrome://settings/cookies, verifique se os cookies de terceiros não estão sendo bloqueados. Dependendo da versão do Chrome, você pode encontrar opções diferentes nesse menu de configurações, mas as configurações aceitáveis incluem:
- "Bloquear todos os cookies de terceiros" = DESATIVADO
- "Bloquear cookies de terceiros" = DESATIVADO
- "Bloquear cookies de terceiros no modo de navegação anônima" = ATIVADO
1.3. Fazer o download da ferramenta de teste local
O teste local exige o download da ferramenta de teste local. A ferramenta vai gerar relatórios resumidos com base nos relatórios de depuração não criptografados.
A ferramenta de teste local está disponível para download nos arquivos JAR do Cloud Function no GitHub. Ele precisa ser nomeado como LocalTestingTool_{version}.jar.
1.4. Verifique se o JAVA JRE está instalado (serviço de agregação e teste local)
Abra o "Terminal" e use java --version para verificar se a máquina tem Java ou openJDK instalado.

Se ele não estiver instalado, faça o download e a instalação no site do Java ou no site do OpenJDK.
1.5. Faça o download de aggregatable_report_converter (serviço de agregação e teste local)
Faça o download de uma cópia do aggregatable_report_converter no repositório do GitHub das demonstrações do Sandbox de privacidade. O repositório do GitHub menciona o uso do IntelliJ ou do Eclipse, mas nenhum deles é obrigatório. Se você não usa essas ferramentas, faça o download do arquivo JAR para seu ambiente local.
1.6. Configurar um ambiente do GCP (serviço de agregação)
O serviço de agregação exige o uso de um ambiente de execução confiável que usa um provedor de nuvem. Neste codelab, o serviço de agregação será implantado no GCP, mas a AWS também é compatível.
Siga as instruções de implantação no GitHub para configurar a CLI do gcloud, fazer o download de módulos e binários do Terraform e criar recursos do GCP para o serviço de agregação.
Principais etapas nas instruções de implantação:
- Configure a CLI "gcloud" e o Terraform no seu ambiente.
- Crie um bucket do Cloud Storage para armazenar o estado do Terraform.
- Faça o download das dependências.
- Atualize
adtech_setup.auto.tfvarse execute o Terraformadtech_setup. Consulte o apêndice para conferir um exemplo de arquivoadtech_setup.auto.tfvars. Observe o nome do bucket de dados criado aqui. Ele será usado no codelab para armazenar os arquivos criados. - Atualize
dev.auto.tfvars, imite a conta de serviço de implantação e execute o Terraformdev. Consulte o apêndice para conferir um exemplo de arquivodev.auto.tfvars. - Depois que a implantação for concluída, capture o
frontend_service_cloudfunction_urlda saída do Terraform, que será necessário para fazer solicitações ao serviço de agregação nas etapas seguintes.
1.7. Concluir a integração do serviço de agregação (serviço de agregação)
O serviço de agregação exige integração com os coordenadores para poder ser usado. Preencha o formulário de integração do serviço de agregação com seu site de relatórios e outras informações, selecione "Google Cloud" e insira o endereço da sua conta de serviço. Essa conta de serviço é criada no pré-requisito anterior (1.6. Configurar um ambiente do GCP). Dica: se você usar os nomes padrão fornecidos, essa conta de serviço vai começar com "worker-sa@".
Aguarde até duas semanas para que o processo de integração seja concluído.
1.8. Determinar o método para chamar os endpoints da API (serviço de agregação)
Este codelab oferece duas opções para chamar os endpoints da API do serviço de agregação: cURL e Postman. O cURL é a maneira mais rápida e fácil de chamar os endpoints da API no Terminal, já que requer uma configuração mínima e nenhum software adicional. No entanto, se você não quiser usar o cURL, use o Postman para executar e salvar solicitações de API para uso futuro.
Na seção 3.2. Uso do serviço de agregação, você vai encontrar instruções detalhadas sobre como usar as duas opções. Você pode conferir uma prévia deles agora para determinar qual método vai usar. Se você selecionar o Postman, faça a configuração inicial a seguir.
1.8.1. Configurar espaço de trabalho
Crie uma conta do Postman. Depois de se inscrever, um espaço de trabalho será criado automaticamente para você.
Se um espaço de trabalho não for criado para você, acesse o item de navegação "Espaços de trabalho" e selecione "Criar espaço de trabalho".
Selecione "Espaço de trabalho em branco", clique em "Próxima" e nomeie como "Sandbox de privacidade do GCP". Selecione "Pessoal" e clique em "Criar".
Faça o download da configuração JSON e dos arquivos do ambiente global do espaço de trabalho pré-configurado.
Importe os dois arquivos JSON para "Meu Workspace" usando o botão "Importar".

Isso vai criar a coleção "Sandbox de privacidade do GCP" para você, além das solicitações HTTP createJob e getJob.
1.8.2. configurar a autorização
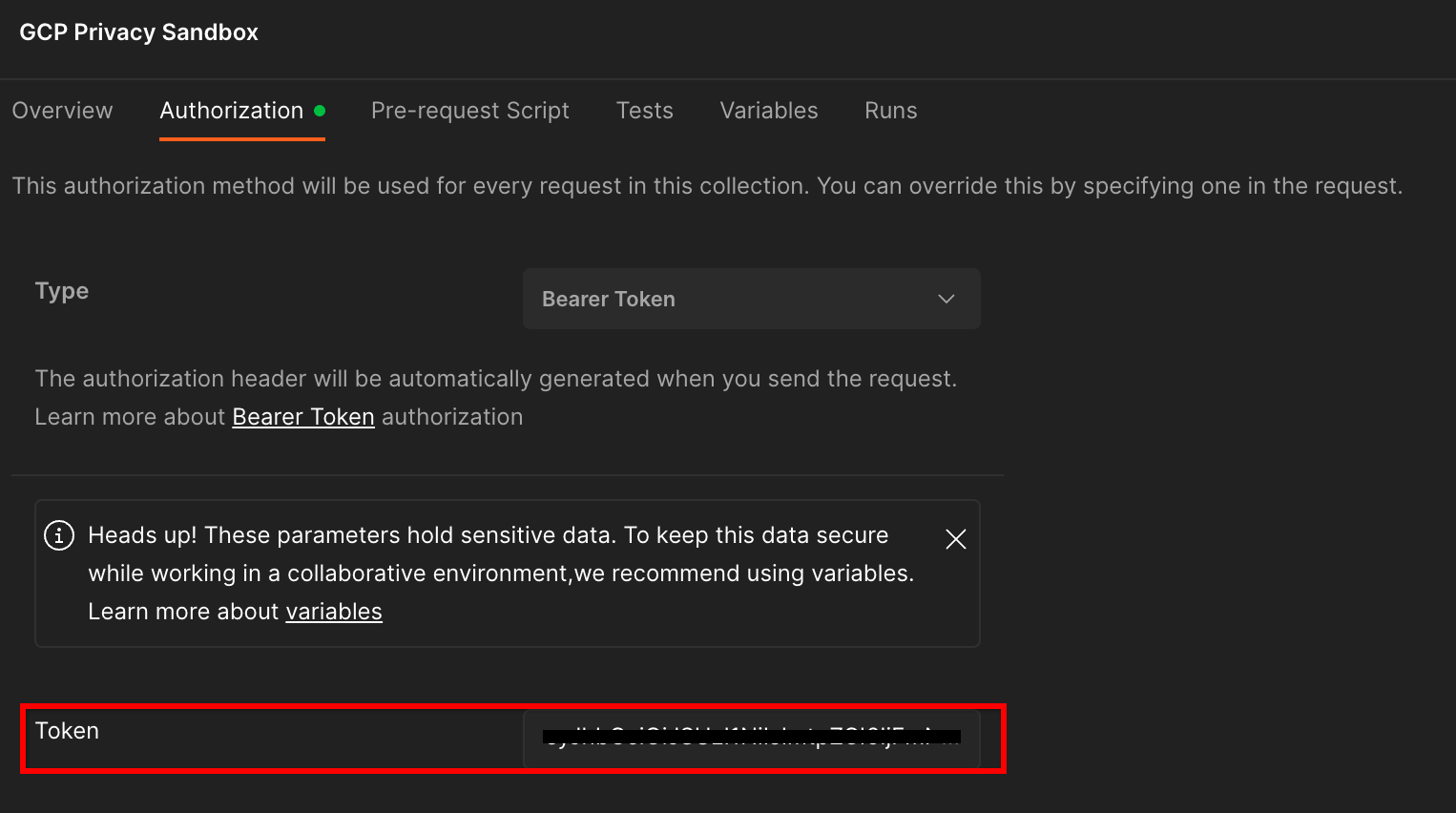
Clique na coleção "Sandbox de privacidade do GCP" e navegue até a guia "Autorização".

Você vai usar o método "Bearer Token". No ambiente do terminal, execute este comando e copie a saída.
gcloud auth print-identity-token
Em seguida, cole esse valor no campo "Token" da guia de autorização do Postman:
1.8.3. Configurar o ambiente
Acesse a "Visualização rápida do ambiente" no canto superior direito:
Clique em "Editar" e atualize o "Valor atual" de "ambiente", "região" e "id-da-função-da-nuvem":
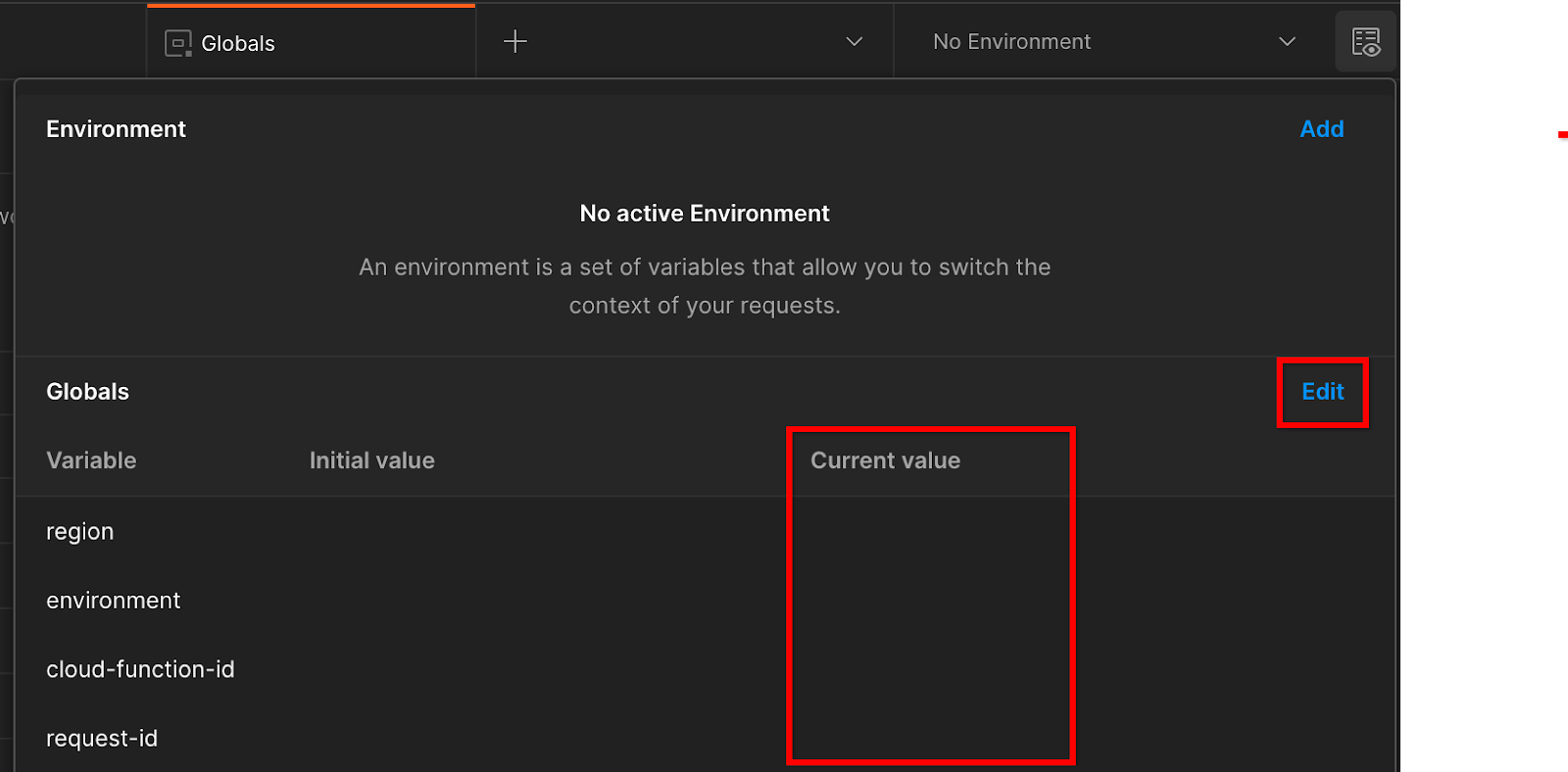
Você pode deixar "request-id" em branco por enquanto, porque vamos preencher mais tarde. Para os outros campos, use os valores do frontend_service_cloudfunction_url, que foi retornado após a conclusão bem-sucedida da implantação do Terraform no pré-requisito 1.6. O URL segue este formato: https://
2. 2. Codelab de testes locais
Tempo estimado para a conclusão: <1 hora
Você pode usar a ferramenta de teste local na sua máquina para realizar a agregação e gerar relatórios de resumo usando os relatórios de depuração não criptografados. Antes de começar, verifique se você concluiu todos os pré-requisitos com a etiqueta "Teste local".
Etapas do codelab
Etapa 2.1. Acionar relatório: acione os relatórios de agregação particular para coletar o relatório.
Etapa 2.2. Criar relatório AVRO de depuração: converta o relatório JSON coletado em um relatório formatado em AVRO. Essa etapa é semelhante à coleta de relatórios dos endpoints de relatórios da API e a conversão dos relatórios JSON em relatórios formatados em AVRO.
Etapa 2.3. Recuperar as chaves de bucket: as chaves de bucket são criadas por adtechs. Neste codelab, como os buckets são predefinidos, extraia as chaves de bucket conforme fornecidas.
Etapa 2.4. Criar AVRO de domínio de saída: depois que as chaves do bucket forem recuperadas, crie o arquivo AVRO de domínio de saída.
Etapa 2,5. Criar relatório resumido: use a ferramenta de testes locais para criar relatórios resumidos no ambiente local.
Etapa 2.6. Analisar os relatórios de resumo: analise o relatório de resumo criado pela ferramenta de teste local.
2.1. Relatório de acionadores
Para acionar um relatório de agregação particular, use o site de demonstração do Sandbox de privacidade (https://privacy-sandbox-demos-news.dev/?env=gcp) ou seu próprio site (por exemplo, https://adtechexample.com). Se você estiver usando seu próprio site e não tiver concluído a integração do serviço de registro, atestado e agregação, será necessário usar uma flag do Chrome e um switch da CLI.
Para esta demonstração, vamos usar o site de demonstração do Sandbox de privacidade. Acesse o link para acessar o site e confira os relatórios em chrome://private-aggregation-internals:
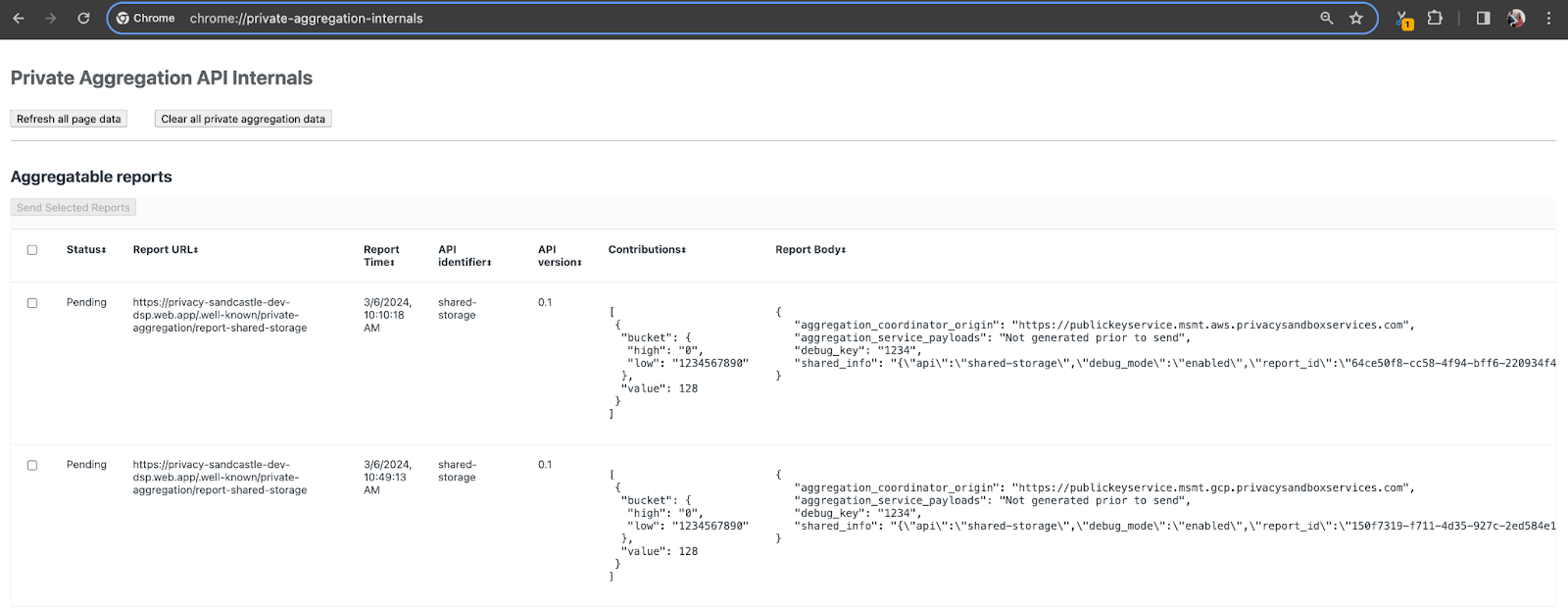
O relatório enviado para o endpoint {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage também é encontrado no "Corpo do relatório" dos relatórios exibidos na página "Chrome Internals".
Você pode encontrar muitos relatórios aqui, mas neste codelab, use o relatório agregável específico do GCP e gerado pelo endpoint de depuração. O "URL do relatório" vai conter "/debug/", e o aggregation_coordinator_origin field do "Corpo do relatório" vai conter este URL: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
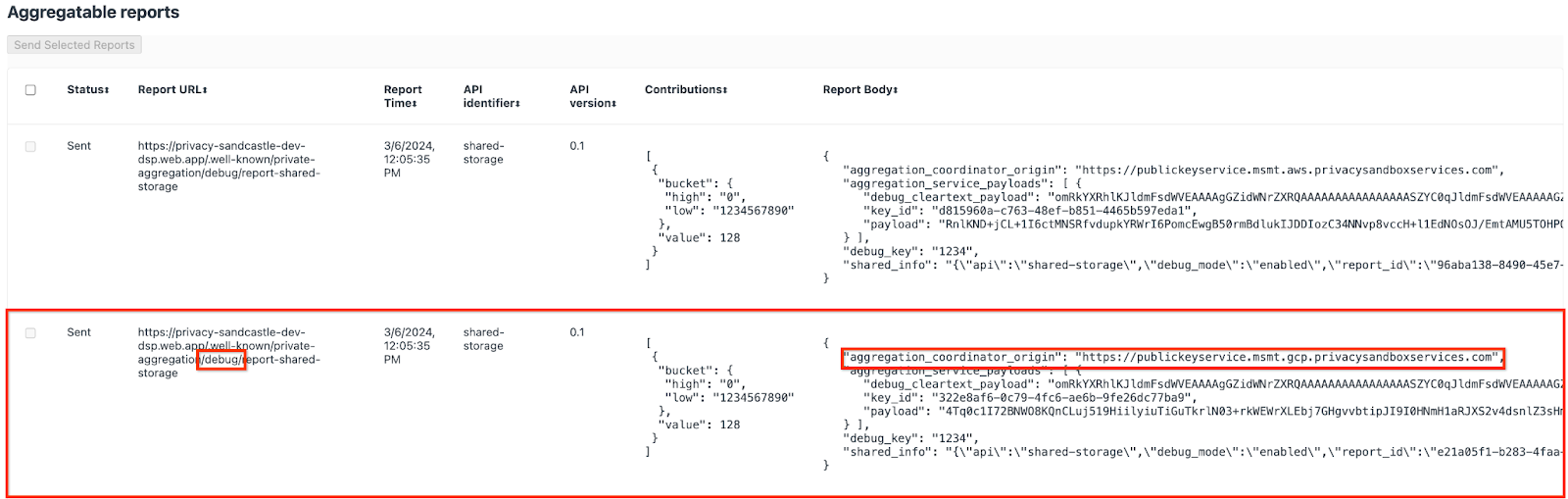
2.2. Criar um relatório agregável de depuração
Copie o relatório encontrado no "Corpo do relatório" de chrome://private-aggregation-internals e crie um arquivo JSON na pasta privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar (dentro do repositório salvo na etapa 1.5).
Neste exemplo, estamos usando o vim, já que estamos usando o Linux. Mas você pode usar qualquer editor de texto.
vim report.json
Cole o relatório em report.json e salve o arquivo.

Depois disso, use aggregatable_report_converter.jar para ajudar a criar o relatório agregável de depuração. Isso cria um relatório agregável chamado report.avro no seu diretório atual.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Extrair a chave do bucket do relatório
Para criar o arquivo output_domain.avro, você precisa das chaves do bucket que podem ser recuperadas dos relatórios.
As chaves de bucket são criadas pela adtech. No entanto, neste caso, a demonstração do Sandbox de privacidade cria as chaves do bucket. Como a agregação privada para esse site está no modo de depuração, podemos usar o debug_cleartext_payload do "Corpo do relatório" para conseguir a chave do bucket.
Copie o debug_cleartext_payload do corpo do relatório.

Abra goo.gle/ags-payload-decoder e cole o debug_cleartext_payload na caixa "INPUT" e clique em "Decode".
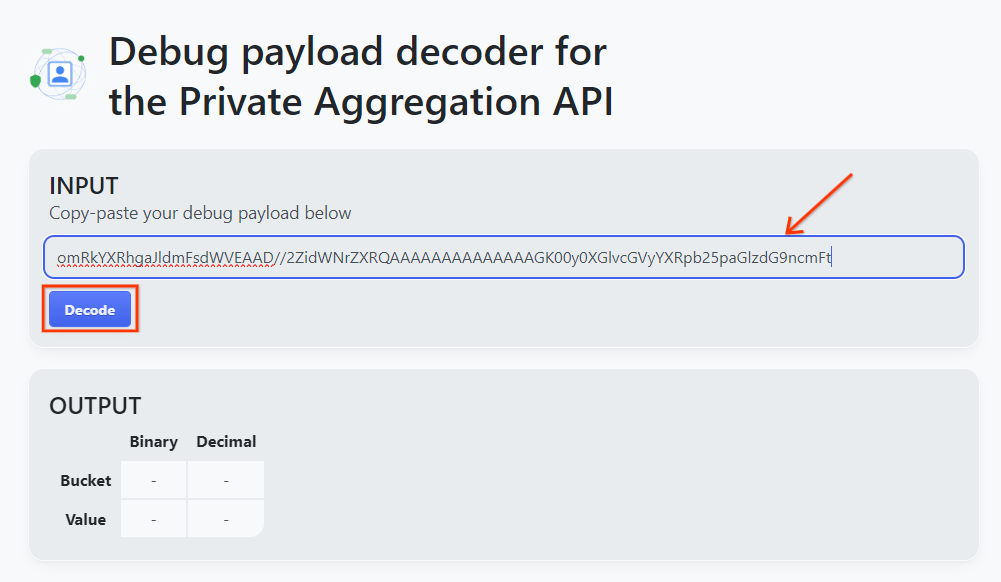
A página retorna o valor decimal da chave do bucket. Confira abaixo um exemplo de chave de bucket.
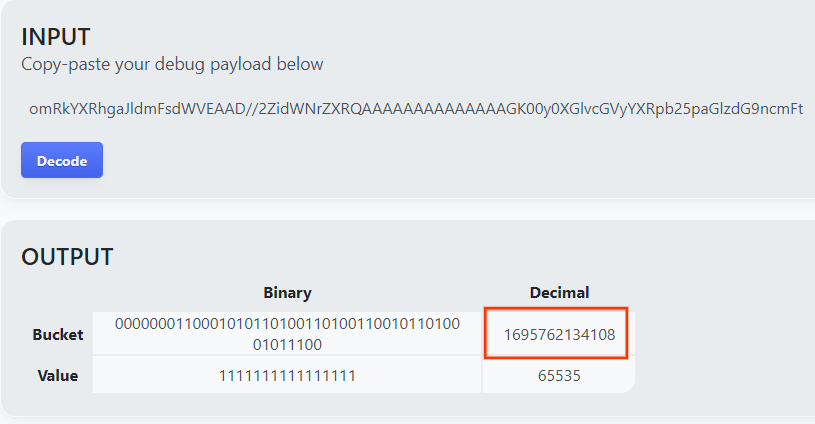
2.4. Criar AVRO de domínio de saída
Agora que temos a chave do bucket, vamos criar o output_domain.avro na mesma pasta em que estamos trabalhando. Substitua a chave do bucket pela chave que você extraiu.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
O script cria o arquivo output_domain.avro na sua pasta atual.
2.5. Criar relatórios de resumo usando a ferramenta de teste local
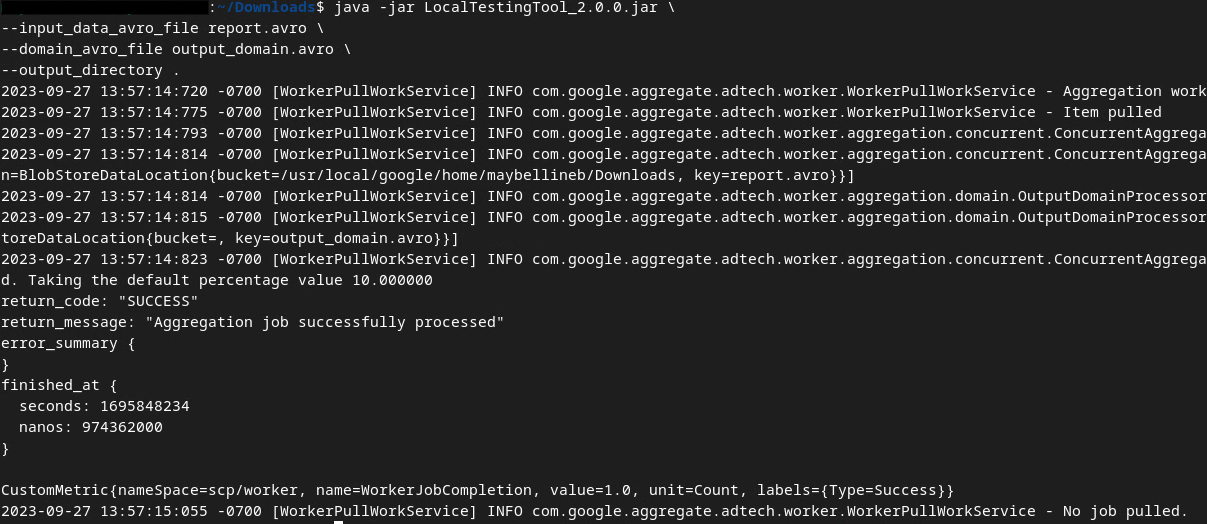
Usaremos LocalTestingTool_{version}.jar, que foi feito o download na etapa 1.3, para criar os relatórios de resumo usando o comando abaixo. Substitua {version} pela versão que você fez o download. Mova LocalTestingTool_{version}.jar para o diretório atual ou adicione um caminho relativo para referenciar o local atual.
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
Você vai notar algo semelhante ao abaixo quando o comando for executado. Um relatório output.avro é criado quando isso é concluído.
2.6. Analisar o relatório de resumo
O relatório de resumo criado é no formato AVRO. Para ler isso, você precisa converter o formato AVRO em JSON. O ideal é que a adTech escreva um código para converter os relatórios AVRO em JSON.
Vamos usar aggregatable_report_converter.jar para converter o relatório AVRO em JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
Isso vai retornar um relatório semelhante ao abaixo. Além de um relatório output.json criado no mesmo diretório.

Codelab concluído
Resumo:você coletou um relatório de depuração, criou um arquivo de domínio de saída e gerou um relatório de resumo usando a ferramenta de teste local, que simula o comportamento de agregação do serviço de agregação.
Próximas etapas:agora que você já testou a ferramenta de teste local, tente fazer o mesmo exercício com uma implantação ativa do serviço de agregação no seu próprio ambiente. Revise os pré-requisitos para garantir que você configurou tudo para o modo "Serviço de agregação" e prossiga para a etapa 3.
3. 3. Codelab do serviço de agregação
Tempo estimado para a conclusão: 1 hora
Antes de começar, verifique se você concluiu todos os pré-requisitos marcados como "Serviço de agregação".
Etapas do codelab
Etapa 3.1. Criação de entrada do serviço de agregação: crie os relatórios do serviço de agregação que são agrupados para o serviço de agregação.
- Etapa 3.1.1. Relatório de acionadores
- Etapa 3.1.2. Coletar relatórios agregáveis
- Etapa 3.1.3. Converter relatórios para AVRO
- Etapa 3.1.4. Criar AVRO de output_domain
- Etapa 3.1.5. Mover relatórios para o bucket do Cloud Storage
Etapa 3.2. Uso do serviço de agregação: use a API Aggregation Service para criar e revisar relatórios de resumo.
- Etapa 3.2.1. Como usar o endpoint
createJobpara lotes - Etapa 3.2.2. Como usar o endpoint
getJobpara recuperar o status do lote - Etapa 3.2.3. Como analisar o relatório resumido
3.1. Criação de entrada de serviço de agregação
Crie os relatórios AVRO para agrupamento no serviço de agregação. Os comandos do shell nestas etapas podem ser executados no Cloud Shell do GCP, desde que as dependências dos pré-requisitos sejam clonadas no seu ambiente do Cloud Shell, ou em um ambiente de execução local.
3.1.1. Relatório de acionadores
Acesse o link para acessar o site e confira os relatórios em chrome://private-aggregation-internals:
O relatório enviado para o endpoint {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage também é encontrado no "Corpo do relatório" dos relatórios exibidos na página "Chrome Internals".
Você pode encontrar muitos relatórios aqui, mas neste codelab, use o relatório agregável específico do GCP e gerado pelo endpoint de depuração. O "URL do relatório" vai conter "/debug/", e o aggregation_coordinator_origin field do "Corpo do relatório" vai conter este URL: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
3.1.2. Coletar relatórios agregáveis
Colete os relatórios agregáveis dos endpoints conhecidos da API correspondente.
- Agregação particular:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - Relatórios de atribuição: relatório de resumo:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
Neste codelab, vamos realizar a coleta de relatórios manualmente. Na produção, as adtechs precisam coletar e converter os relatórios de forma programática.
Vamos copiar o relatório JSON no "Corpo do relatório" de chrome://private-aggregation-internals.
Neste exemplo, usamos o vim, já que estamos usando o Linux. Mas você pode usar qualquer editor de texto.
vim report.json
Cole o relatório em report.json e salve o arquivo.
3.1.3. Converter relatórios para AVRO
Os relatórios recebidos dos endpoints .well-known estão no formato JSON e precisam ser convertidos no formato de relatório AVRO. Depois de ter o relatório JSON, navegue até onde report.json está armazenado e use aggregatable_report_converter.jar para ajudar a criar o relatório agregável de depuração. Isso cria um relatório agregável chamado report.avro no seu diretório atual.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. Criar AVRO de output_domain
Para criar o arquivo output_domain.avro, você precisa das chaves do bucket que podem ser recuperadas dos relatórios.
As chaves de bucket são criadas pela adtech. No entanto, neste caso, a demonstração do Sandbox de privacidade cria as chaves do bucket. Como a agregação privada para esse site está no modo de depuração, podemos usar o debug_cleartext_payload do "Corpo do relatório" para conseguir a chave do bucket.
Copie o debug_cleartext_payload do corpo do relatório.
Abra goo.gle/ags-payload-decoder e cole o debug_cleartext_payload na caixa "INPUT" e clique em "Decode".
A página retorna o valor decimal da chave do bucket. Confira abaixo um exemplo de chave de bucket.
Agora que temos a chave do bucket, vamos criar o output_domain.avro na mesma pasta em que estamos trabalhando. Substitua a chave do bucket pela chave que você extraiu.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
O script cria o arquivo output_domain.avro na sua pasta atual.
3.1.5. Mover relatórios para o bucket do Cloud Storage
Depois que os relatórios e o domínio de saída do AVRO forem criados, mova os relatórios e o domínio de saída para o bucket no Cloud Storage (que você observou no pré-requisito 1.6).
Se você tiver a configuração da CLI gcloud no seu ambiente local, use os comandos abaixo para copiar os arquivos para as pastas correspondentes.
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
Caso contrário, faça upload dos arquivos manualmente para o bucket. Crie uma pasta chamada "reports" e faça upload do arquivo report.avro nela. Crie uma pasta chamada "output_domains" e faça o upload do arquivo output_domain.avro nela.
3.2. Uso do serviço de agregação
Na etapa 1.8, você selecionou o cURL ou o Postman para fazer solicitações de API aos endpoints do serviço de agregação. Confira abaixo as instruções para as duas opções.
Se o job falhar com um erro, consulte nossa documentação de solução de problemas no GitHub para mais informações sobre como proceder.
3.2.1. Como usar o endpoint createJob para lotes
Use as instruções do cURL ou do Postman abaixo para criar um job.
cURL
No "Terminal", crie um arquivo de corpo de solicitação (body.json) e cole o código abaixo. Atualize os valores dos marcadores de posição. Consulte a documentação da API para mais informações sobre o que cada campo representa.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Execute a seguinte solicitação. Substitua os marcadores de posição no URL da solicitação do cURL pelos valores de frontend_service_cloudfunction_url, que é gerado após a conclusão da implantação do Terraform no pré-requisito 1.6.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
Você vai receber uma resposta HTTP 202 quando a solicitação for aceita pelo serviço de agregação. Outros possíveis códigos de resposta estão documentados nas especificações da API.
Carteiro
Para o endpoint createJob, é necessário um corpo de solicitação para fornecer ao serviço de agregação o local e os nomes de arquivo dos relatórios agregáveis, domínios de saída e relatórios de resumo.
Navegue até a guia "Body" da solicitação createJob:

Substitua os marcadores de posição no JSON fornecido. Para mais informações sobre esses campos e o que eles representam, consulte a documentação da API.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
"Enviar" a solicitação da API createJob:

O código de resposta pode ser encontrado na metade inferior da página:

Você vai receber uma resposta HTTP 202 quando a solicitação for aceita pelo serviço de agregação. Outros possíveis códigos de resposta estão documentados nas especificações da API.
3.2.2. Como usar o endpoint getJob para recuperar o status do lote
Use as instruções do cURL ou do Postman abaixo para receber um job.
cURL
Execute a solicitação abaixo no terminal. Substitua os marcadores de posição no URL pelos valores de frontend_service_cloudfunction_url, que é o mesmo URL usado para a solicitação createJob. Para "job_request_id", use o valor do job que você criou com o endpoint createJob.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
O resultado deve retornar o status da solicitação de job com um status HTTP de 200. O "Corpo" da solicitação contém as informações necessárias, como job_status, return_message e error_messages (se o job tiver falhado).
Postman
Para verificar o status da solicitação de job, use o endpoint getJob. Na seção "Params" da solicitação getJob, atualize o valor job_request_id para o job_request_id que foi enviado na solicitação createJob.
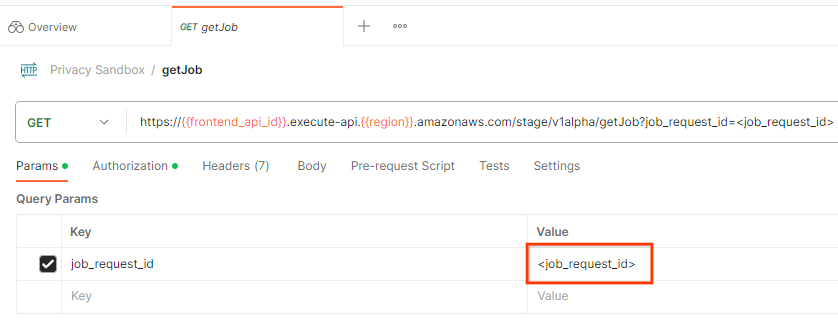
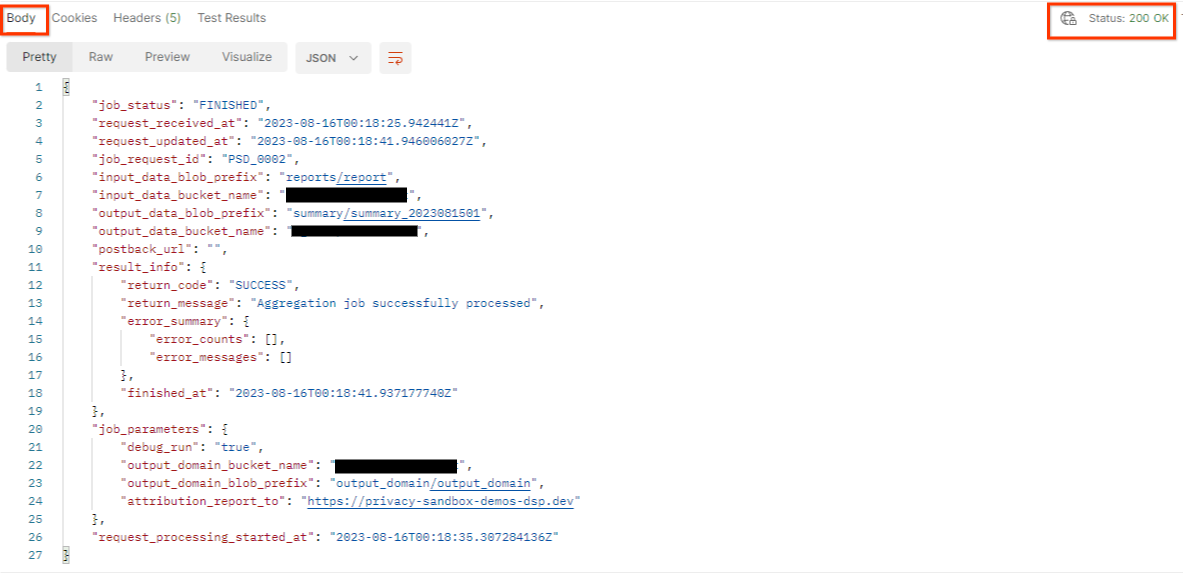
"Enviar" a solicitação getJob:

O resultado deve retornar o status da solicitação de job com um status HTTP de 200. O "Corpo" da solicitação contém as informações necessárias, como job_status, return_message e error_messages (se o job tiver falhado).
3.2.3. Como analisar o relatório resumido
Depois de receber o relatório de resumo no bucket de saída do Cloud Storage, você pode fazer o download dele para o ambiente local. Os relatórios de resumo estão no formato AVRO e podem ser convertidos de volta em JSON. Você pode usar aggregatable_report_converter.jar para ler o relatório usando o comando abaixo.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
Isso retorna um JSON de valores agregados de cada chave de bucket semelhante ao abaixo.

Se a solicitação createJob incluir debug_run como verdadeiro, você poderá receber o relatório de resumo na pasta de depuração localizada no output_data_blob_prefix. O relatório está no formato AVRO e pode ser convertido em JSON usando o comando acima.
O relatório contém a chave do bucket, a métrica sem ruído e o ruído adicionado à métrica sem ruído para formar o relatório resumido. O relatório é semelhante ao abaixo.

As anotações também contêm "in_reports" e/ou "in_domain", que significam:
- in_reports: a chave do bucket está disponível nos relatórios agregáveis.
- in_domain: a chave do bucket está disponível no arquivo AVRO output_domain.
Codelab concluído
Resumo:você implantou o serviço de agregação no seu próprio ambiente de nuvem, coletou um relatório de depuração, criou um arquivo de domínio de saída, armazenou esses arquivos em um bucket do Cloud Storage e executou um job com sucesso.
Próximas etapas:continue usando o serviço de agregação no seu ambiente ou exclua os recursos de nuvem que você acabou de criar seguindo as instruções de limpeza na etapa 4.
4. 4. Limpeza
Para excluir os recursos criados para o serviço de agregação pelo Terraform, use o comando de destruição nas pastas adtech_setup e dev (ou outro ambiente):
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
Para excluir o bucket do Cloud Storage que contém seus relatórios agregados e de resumo:
$ gcloud storage buckets delete gs://my-bucket
Você também pode reverter as configurações de cookies do Chrome do pré-requisito 1.2 para o estado anterior.
5. 5. Apêndice
Exemplo de arquivo adtech_setup.auto.tfvars:
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
Exemplo de arquivo dev.auto.tfvars:
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20