
1. 1. ज़रूरी शर्तें
पूरा होने में लगने वाला अनुमानित समय: एक से दो घंटे
इस कोडलैब को दो मोड में चलाया जा सकता है: लोकल टेस्टिंग या एग्रीगेशन सेवा. लोकल टेस्टिंग मोड के लिए, लोकल मशीन और Chrome ब्राउज़र की ज़रूरत होती है. इसके लिए, Google Cloud का कोई संसाधन बनाने/इस्तेमाल करने की ज़रूरत नहीं होती. एग्रीगेशन सेवा मोड के लिए, Google Cloud पर एग्रीगेशन सेवा को पूरी तरह से डिप्लॉय करना ज़रूरी है.
इस कोडलैब को किसी भी मोड में करने के लिए, कुछ ज़रूरी शर्तें पूरी करनी होंगी. हर ज़रूरी शर्त के हिसाब से यह मार्क किया जाता है कि वह लोकल टेस्टिंग या एग्रीगेशन सेवा के लिए ज़रूरी है या नहीं.
1.1. रजिस्ट्रेशन और पुष्टि की प्रक्रिया पूरी करना (एग्रीगेशन सेवा)
Privacy Sandbox APIs का इस्तेमाल करने के लिए, पक्का करें कि आपने Chrome और Android, दोनों के लिए रजिस्ट्रेशन और पुष्टि की प्रक्रिया पूरी कर ली हो.
1.2. विज्ञापन देखने वाले की निजता बनाए रखने के लिए एपीआई (लोकल टेस्टिंग और एग्रीगेशन सेवा) चालू करना
हम प्राइवसी सैंडबॉक्स का इस्तेमाल करेंगे. इसलिए, हमारा सुझाव है कि आप Privacy Sandbox Ads API को चालू करें.
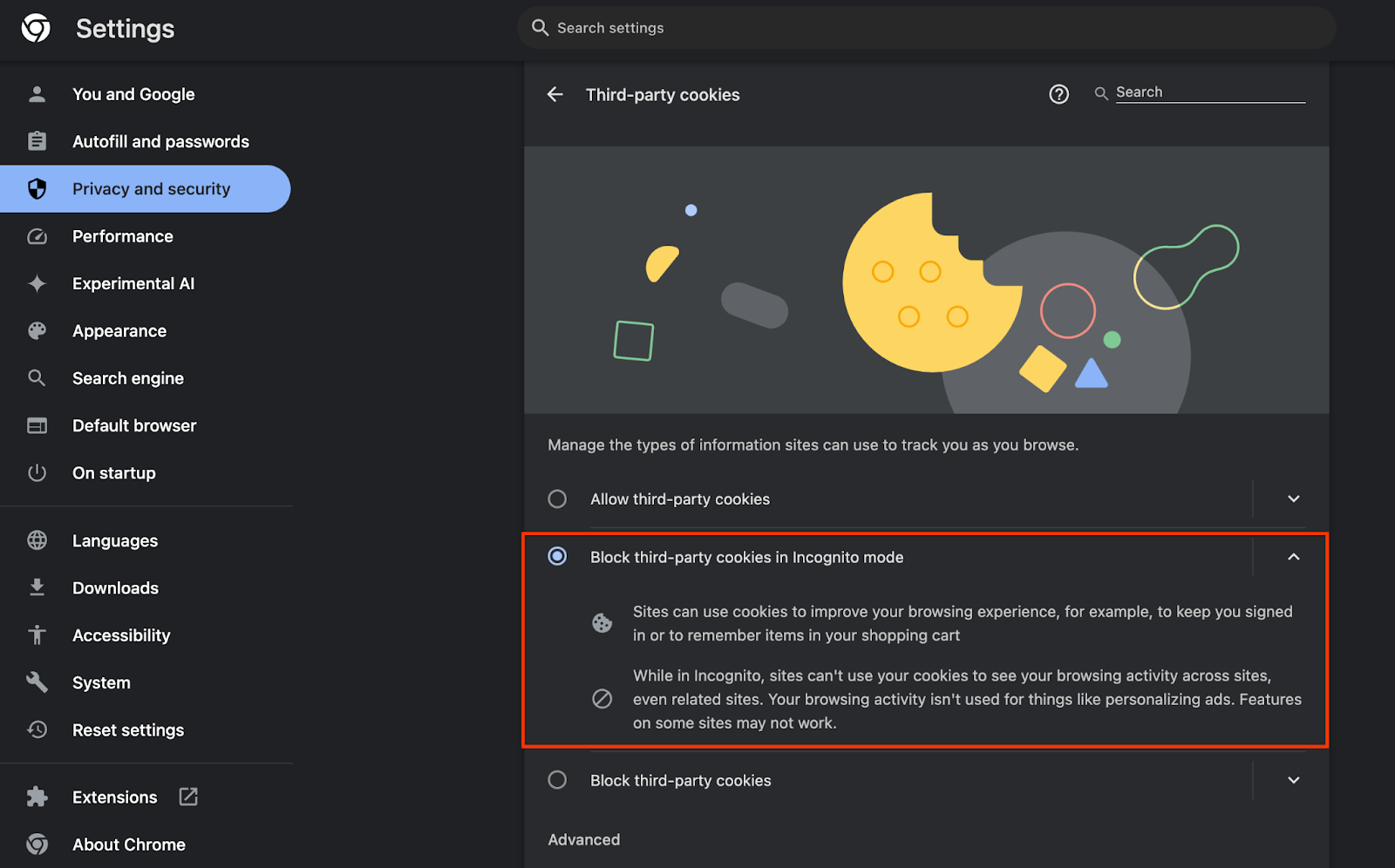
अपने ब्राउज़र में, chrome://settings/adPrivacy पर जाएं और विज्ञापन निजता से जुड़े सभी एपीआई चालू करें.
यह भी पक्का करें कि तीसरे पक्ष की कुकी चालू हों.
chrome://settings/cookies से, पक्का करें कि तीसरे पक्ष की कुकी ब्लॉक न की गई हों. आपके Chrome वर्शन के हिसाब से, आपको इस सेटिंग मेन्यू में अलग-अलग विकल्प दिख सकते हैं. हालांकि, इन कॉन्फ़िगरेशन को स्वीकार किया जा सकता है:
- "तीसरे पक्ष की सभी कुकी ब्लॉक करें" = बंद है
- "तीसरे पक्ष की कुकी ब्लॉक करें" = बंद है
- "गुप्त मोड में तीसरे पक्ष की कुकी ब्लॉक करें" = चालू है
1.3. लोकल टेस्टिंग टूल डाउनलोड करना (लोकल टेस्टिंग)
लोकल टेस्टिंग के लिए, लोकल टेस्टिंग टूल डाउनलोड करना होगा. यह टूल, एन्क्रिप्ट (सुरक्षित) नहीं की गई डीबग रिपोर्ट से खास जानकारी वाली रिपोर्ट जनरेट करेगा.
लोकल टेस्टिंग टूल, GitHub में Cloud फ़ंक्शन के JAR संग्रह में डाउनलोड करने के लिए उपलब्ध है. इसका नाम LocalTestingTool_{version}.jar होना चाहिए.
1.4. पक्का करें कि JAVA JRE इंस्टॉल हो (लोकल टेस्टिंग और एग्रीगेशन सेवा)
"Terminal" खोलें और java --version का इस्तेमाल करके देखें कि आपकी मशीन में Java या openJDK इंस्टॉल है या नहीं.

अगर यह इंस्टॉल नहीं है, तो Java साइट या openJDK साइट से डाउनलोड और इंस्टॉल किया जा सकता है.
1.5. aggregatable_report_converter (लोकल टेस्टिंग और एग्रीगेशन सेवा) डाउनलोड करें
Privacy Sandbox के डेमो की GitHub रिपॉज़िटरी से, aggregatable_report_converter की कॉपी डाउनलोड की जा सकती है. GitHub के डेटा स्टोर में, IntelliJ या Eclipse का इस्तेमाल करने के बारे में बताया गया है. हालांकि, इनमें से किसी का भी इस्तेमाल करना ज़रूरी नहीं है. अगर इन टूल का इस्तेमाल नहीं किया जाता है, तो JAR फ़ाइल को अपने लोकल एनवायरमेंट में डाउनलोड करें.
1.6. GCP एनवायरमेंट (एग्रीगेशन सेवा) सेट अप करना
एग्रीगेशन सेवा के लिए, भरोसेमंद एक्सीक्यूशन एनवायरमेंट का इस्तेमाल करना ज़रूरी है. यह एनवायरमेंट, क्लाउड सेवा देने वाली कंपनी का इस्तेमाल करता है. इस कोडलैब में, एग्रीगेशन सेवा को GCP में डिप्लॉय किया जाएगा. हालांकि, AWS पर भी यह काम करता है.
gcloud CLI सेट अप करने, Terraform बाइनरी और मॉड्यूल डाउनलोड करने, और एग्रीगेशन सेवा के लिए GCP संसाधन बनाने के लिए, GitHub में डिप्लॉयमेंट के निर्देश का पालन करें.
डिप्लॉयमेंट के निर्देशों में दिए गए मुख्य चरण:
- अपने एनवायरमेंट में "gcloud" सीएलआई और Terraform सेट अप करें.
- Terraform स्टेट को सेव करने के लिए, Cloud Storage बकेट बनाएं.
- डिपेंडेंसी डाउनलोड करें.
adtech_setup.auto.tfvarsको अपडेट करें औरadtech_setupTerraform को चलाएं.adtech_setup.auto.tfvarsफ़ाइल का उदाहरण देखने के लिए, परिशिष्ट देखें. यहां बनाई गई डेटा बकेट का नाम नोट करें – इसका इस्तेमाल, कोडलैब में बनाई गई फ़ाइलों को स्टोर करने के लिए किया जाएगा.dev.auto.tfvarsको अपडेट करें, डिप्लॉय करने वाले सेवा खाते के नाम पर काम करें, औरdevTerraform को चलाएं.dev.auto.tfvarsफ़ाइल का उदाहरण देखने के लिए, परिशिष्ट देखें.- डिप्लॉयमेंट पूरा होने के बाद, Terraform आउटपुट से
frontend_service_cloudfunction_urlको कैप्चर करें. इसकी ज़रूरत, अगले चरणों में एग्रीगेशन सेवा के लिए अनुरोध करने के लिए होगी.
1.7. एग्रीगेशन सेवा को शामिल करने की प्रोसेस पूरी करना (एग्रीगेशन सेवा)
Aggregation Service का इस्तेमाल करने के लिए, कोऑर्डिनेटर को इस सेवा में शामिल करना ज़रूरी है. एग्रीगेशन सेवा के लिए ऑनबोर्डिंग फ़ॉर्म भरें. इसके लिए, अपनी रिपोर्टिंग साइट और अन्य जानकारी दें. साथ ही, "Google Cloud" चुनें और अपना सेवा खाता पता डालें. यह सेवा खाता, ज़रूरी शर्तों के पिछले वर्शन (1.6. GCP एनवायरमेंट सेट अप करें). (सलाह: दिए गए डिफ़ॉल्ट नामों का इस्तेमाल करने पर, यह सेवा खाता "worker-sa@" से शुरू होगा).
शामिल होने की प्रोसेस पूरी होने में दो हफ़्ते लग सकते हैं.
1.8. एपीआई एंडपॉइंट (एग्रीगेशन सेवा) को कॉल करने का तरीका तय करना
इस कोडलैब में, एग्रीगेशन सेवा के एपीआई एंडपॉइंट को कॉल करने के लिए दो विकल्प दिए गए हैं: cURL और Postman. अपने टर्मिनल से एपीआई एंडपॉइंट को कॉल करने का सबसे तेज़ और आसान तरीका cURL है. इसकी वजह यह है कि इसके लिए कम सेटअप की ज़रूरत होती है और किसी अन्य सॉफ़्टवेयर की ज़रूरत नहीं होती. हालांकि, अगर आपको cURL का इस्तेमाल नहीं करना है, तो एपीआई अनुरोधों को लागू करने और उन्हें बाद में इस्तेमाल करने के लिए, Postman का इस्तेमाल किया जा सकता है.
सेक्शन 3.2 में. एग्रीगेशन सेवा के इस्तेमाल से जुड़ी जानकारी मिलेगी. इसमें, दोनों विकल्पों को इस्तेमाल करने के बारे में ज़्यादा जानकारी मिलेगी. अब इनकी झलक देखकर यह तय किया जा सकता है कि आपको किस तरीके का इस्तेमाल करना है. Postman चुनने पर, शुरुआती सेटअप के लिए यह तरीका अपनाएं.
1.8.1. फ़ाइल फ़ोल्डर सेट अप करना
Postman खाते के लिए साइन अप करें. साइन अप करने के बाद, आपके लिए एक फ़ाइल फ़ोल्डर अपने-आप बन जाता है.
अगर आपके लिए कोई फ़ाइल फ़ोल्डर नहीं बनाया गया है, तो सबसे ऊपर मौजूद नेविगेशन आइटम "फ़ाइल फ़ोल्डर" पर जाएं और "फ़ाइल फ़ोल्डर बनाएं" चुनें.
"खाली फ़ाइल फ़ोल्डर" चुनें. इसके बाद, 'आगे बढ़ें' पर क्लिक करें और इसे "GCP Privacy Sandbox" नाम दें. "निजी" चुनें और "बनाएं" पर क्लिक करें.
पहले से कॉन्फ़िगर किया गया फ़ाइल फ़ोल्डर JSON कॉन्फ़िगरेशन और ग्लोबल एनवायरमेंट फ़ाइलें डाउनलोड करें.
"इंपोर्ट करें" बटन का इस्तेमाल करके, दोनों JSON फ़ाइलों को "मेरा Workspace" में इंपोर्ट करें.

इससे आपके लिए, createJob और getJob एचटीटीपी अनुरोधों के साथ-साथ "GCP प्राइवसी सैंडबॉक्स" कलेक्शन बन जाएगा.
1.8.2. अनुमति सेट अप करना
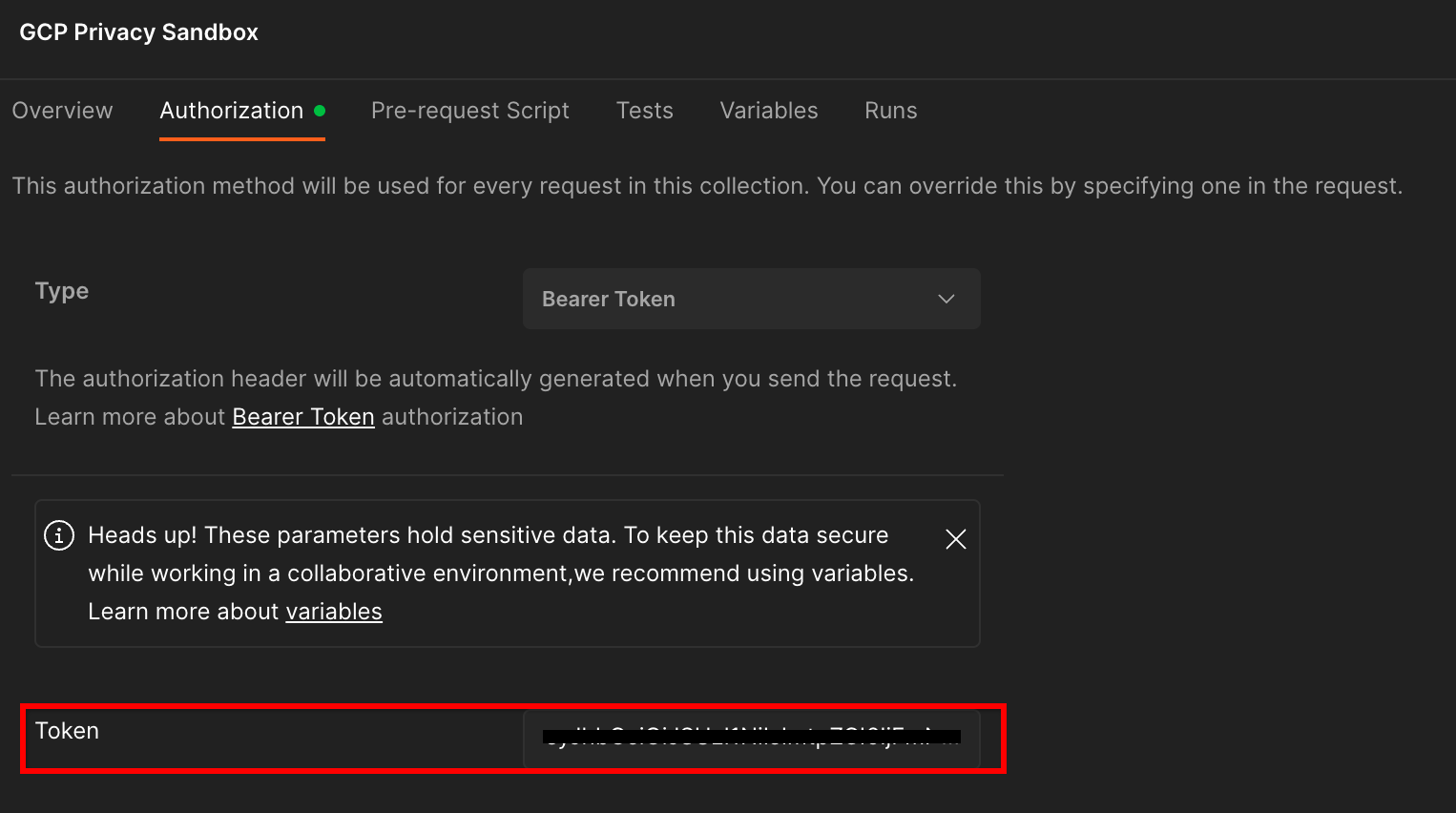
"GCP Privacy Sandbox" कलेक्शन पर क्लिक करें और "अनुमति" टैब पर जाएं.

आपको "बियरर टोकन" का तरीका इस्तेमाल करना होगा. अपने टर्मिनल एनवायरमेंट में, यह कमांड चलाएं और आउटपुट कॉपी करें.
gcloud auth print-identity-token
इसके बाद, इस टोकन की वैल्यू को Postman के अनुमति टैब के "टोकन" फ़ील्ड में चिपकाएं:
1.8.3. एनवायरमेंट सेट अप करना
सबसे ऊपर दाएं कोने में, "पर्यावरण की खास जानकारी" पर जाएं:
"बदलाव करें" पर क्लिक करें और "एनवायरमेंट", "क्षेत्र", और "cloud-function-id" की "मौजूदा वैल्यू" अपडेट करें:
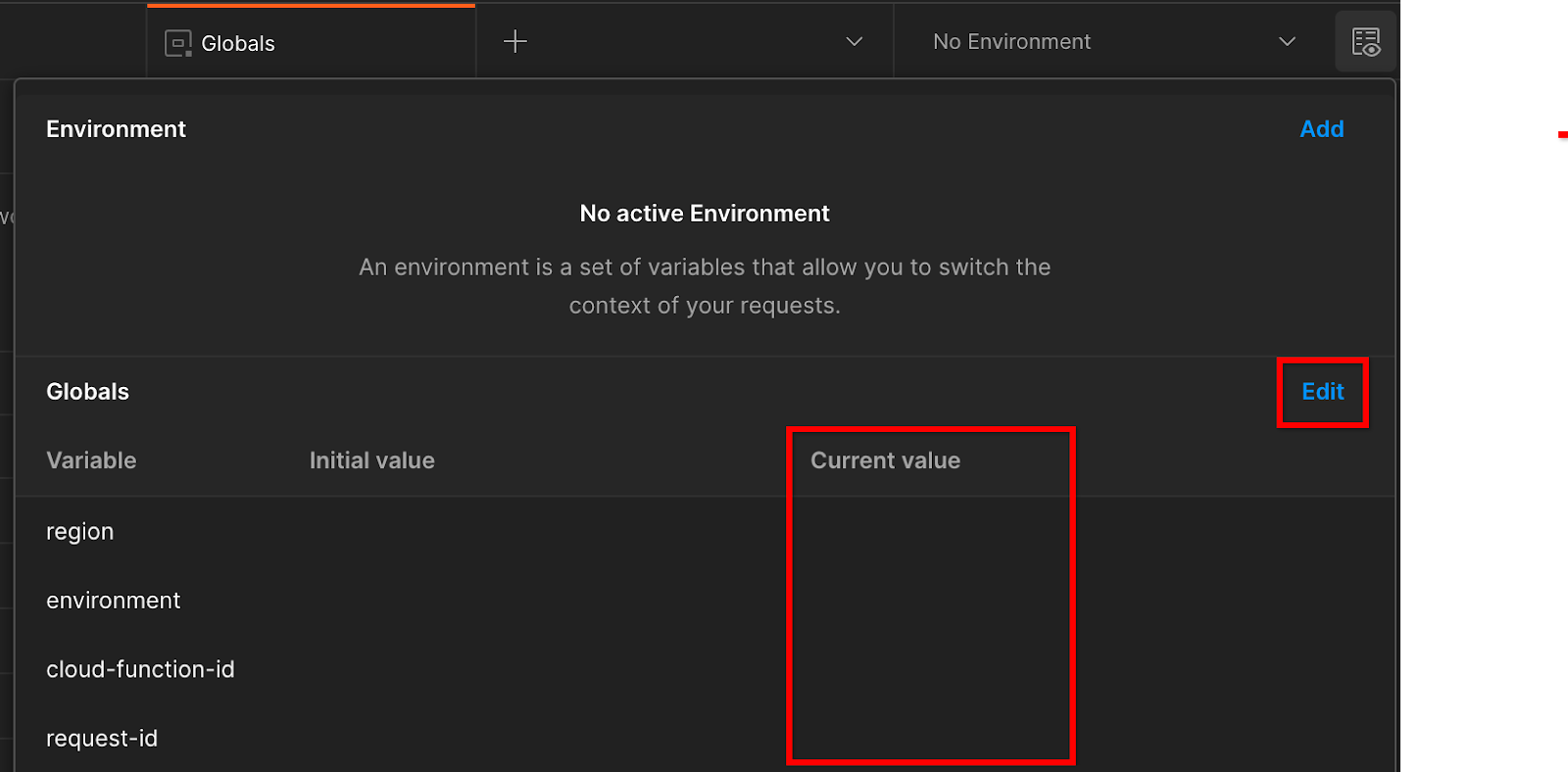
"request-id" को अभी खाली छोड़ा जा सकता है, क्योंकि हम इसे बाद में भर देंगे. अन्य फ़ील्ड के लिए, frontend_service_cloudfunction_url की वैल्यू का इस्तेमाल करें. यह वैल्यू, ज़रूरी शर्त 1.6 में Terraform डिप्लॉयमेंट पूरा होने पर मिली थी. यूआरएल इस फ़ॉर्मैट में होना चाहिए: https://
2. 2. लोकल टेस्टिंग कोडलैब
पूरा होने में लगने वाला अनुमानित समय: एक घंटे से कम
एग्रीगेशन करने और एन्क्रिप्ट (सुरक्षित) नहीं की गई डीबग रिपोर्ट का इस्तेमाल करके खास जानकारी वाली रिपोर्ट जनरेट करने के लिए, अपनी मशीन पर लोकल टेस्टिंग टूल का इस्तेमाल किया जा सकता है. शुरू करने से पहले, पक्का करें कि आपने "स्थानीय टेस्टिंग" के लेबल वाली सभी ज़रूरी शर्तें पूरी कर ली हों.
कोडलैब के चरण
दूसरा चरण. रिपोर्ट ट्रिगर करें: रिपोर्ट इकट्ठा करने के लिए, निजी एग्रीगेशन रिपोर्टिंग को ट्रिगर करें.
दूसरा चरण. डीबग AVRO रिपोर्ट बनाएं: इकट्ठा की गई JSON रिपोर्ट को AVRO फ़ॉर्मैट की रिपोर्ट में बदलें. यह चरण उसी तरह का होगा जब विज्ञापन टेक्नोलॉजी कंपनियां, एपीआई रिपोर्टिंग एंडपॉइंट से रिपोर्ट इकट्ठा करती हैं और JSON रिपोर्ट को AVRO फ़ॉर्मैट वाली रिपोर्ट में बदलती हैं.
दूसरा चरण. बकेट पासकोड वापस पाना: बकेट पासकोड, विज्ञापन टेक्नोलॉजी कंपनियां डिज़ाइन करती हैं. इस कोडलैब में, बकेट पहले से तय होती हैं. इसलिए, बकेट की कुंजियों को दिए गए तरीके से वापस पाएं.
दूसरा चरण. आउटपुट डोमेन AVRO फ़ाइल बनाएं: बकेट कुंजियां वापस पाने के बाद, आउटपुट डोमेन AVRO फ़ाइल बनाएं.
दूसरा चरण. खास जानकारी वाली रिपोर्ट बनाना: लोकल एनवायरमेंट में खास जानकारी वाली रिपोर्ट बनाने के लिए, लोकल टेस्टिंग टूल का इस्तेमाल करें.
दूसरा चरण. खास जानकारी वाली रिपोर्ट की समीक्षा करना: लोकल टेस्टिंग टूल से जनरेट की गई खास जानकारी वाली रिपोर्ट की समीक्षा करें.
2.1. ट्रिगर रिपोर्ट
निजी एग्रीगेशन रिपोर्ट को ट्रिगर करने के लिए, Privacy Sandbox की डेमो साइट (https://privacy-sandbox-demos-news.dev/?env=gcp) या अपनी साइट (उदाहरण के लिए, https://adtechexample.com) का इस्तेमाल किया जा सकता है. अगर अपनी साइट का इस्तेमाल किया जा रहा है और आपने रजिस्ट्रेशन और पुष्टि की प्रक्रिया और एग्रीगेशन सेवा को शामिल करने की प्रोसेस पूरी नहीं की है, तो आपको Chrome फ़्लैग और सीएलआई स्विच का इस्तेमाल करना होगा.
इस डेमो के लिए, हम Privacy Sandbox की डेमो साइट का इस्तेमाल करेंगे. साइट पर जाने के लिए, लिंक पर जाएं. इसके बाद, chrome://private-aggregation-internals पर जाकर रिपोर्ट देखी जा सकती हैं:
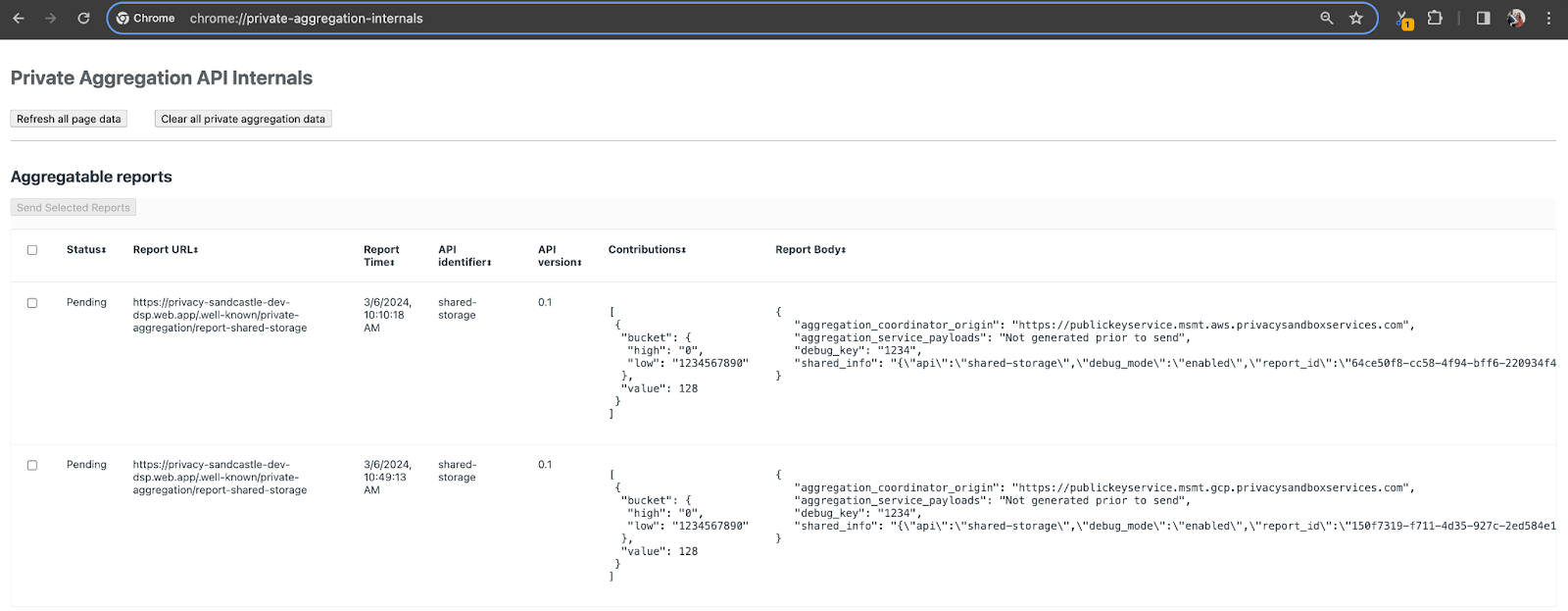
{reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage एंडपॉइंट पर भेजी गई रिपोर्ट, Chrome के इंटरनल पेज पर दिखने वाली रिपोर्ट के "रिपोर्ट बॉडी" में भी दिखती है.
आपको यहां कई रिपोर्ट दिख सकती हैं, लेकिन इस कोडलैब के लिए, एग्रीगेट की जा सकने वाली ऐसी रिपोर्ट का इस्तेमाल करें जो GCP के लिए खास तौर पर बनाई गई हो और डीबग एंडपॉइंट से जनरेट की गई हो. "रिपोर्ट यूआरएल" में "/debug/" शामिल होगा और "रिपोर्ट बॉडी" के aggregation_coordinator_origin field में यह यूआरएल शामिल होगा: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
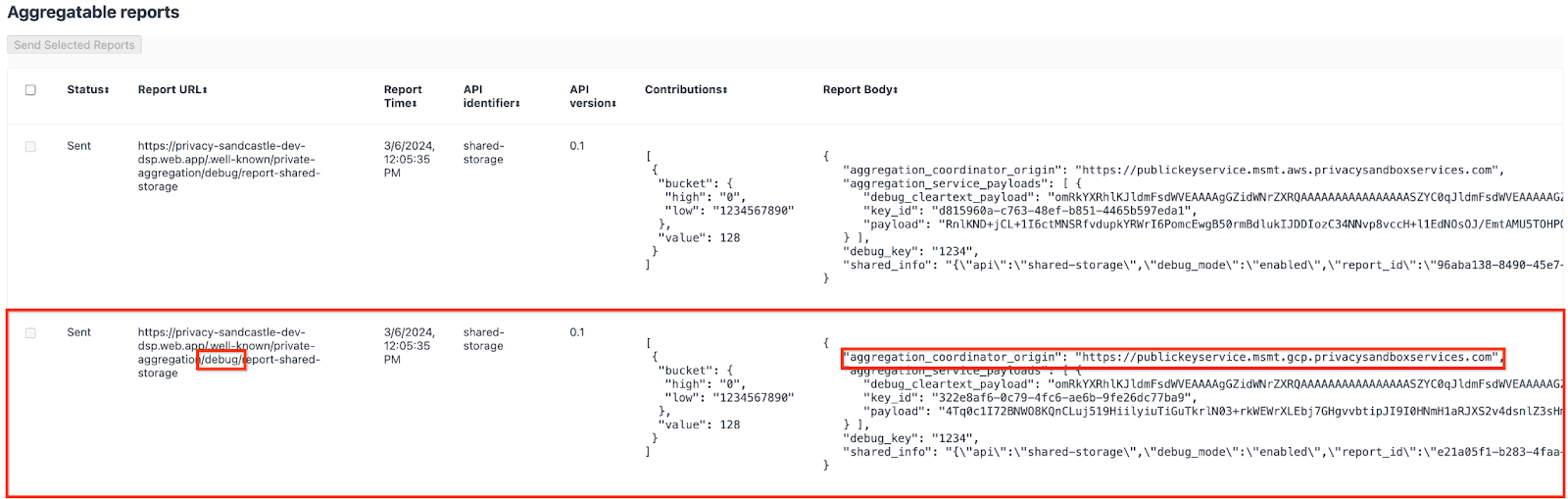
2.2. एग्रीगेट की जा सकने वाली डीबग रिपोर्ट बनाना
chrome://private-aggregation-internals के "रिपोर्ट बॉडी" में मिली रिपोर्ट को कॉपी करें और privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar फ़ोल्डर में JSON फ़ाइल बनाएं. यह फ़ोल्डर, ज़रूरी शर्त 1.5 में डाउनलोड किए गए repo में मौजूद होना चाहिए.
इस उदाहरण में, हमने vim का इस्तेमाल किया है, क्योंकि हमने Linux का इस्तेमाल किया है. हालांकि, आपके पास अपनी पसंद का कोई भी टेक्स्ट एडिटर इस्तेमाल करने का विकल्प है.
vim report.json
रिपोर्ट को report.json में चिपकाएं और अपनी फ़ाइल सेव करें.

इसके बाद, aggregatable_report_converter.jar का इस्तेमाल करके, डीबग की जा सकने वाली रिपोर्ट बनाएं. इससे आपकी मौजूदा डायरेक्ट्री में, report.avro नाम की एक रिपोर्ट बन जाएगी. इसमें डेटा इकट्ठा किया जा सकता है.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. रिपोर्ट से बकेट कुंजी वापस पाना
output_domain.avro फ़ाइल बनाने के लिए, आपको बकेट की ऐसी कुंजियां चाहिए जिन्हें रिपोर्ट से वापस पाया जा सके.
बकेट कुंजियों को विज्ञापन टेक्नोलॉजी (adTech) डिज़ाइन करता है. हालांकि, इस मामले में, साइट Privacy Sandbox Demo, बकेट पासकोड बनाती है. इस साइट के लिए निजी एग्रीगेशन, डीबग मोड में है. इसलिए, हम बकेट कुंजी पाने के लिए, "रिपोर्ट बॉडी" से debug_cleartext_payload का इस्तेमाल कर सकते हैं.
अब रिपोर्ट के मुख्य हिस्से से debug_cleartext_payload को कॉपी करें.

goo.gle/ags-payload-decoder खोलें और "इनपुट" बॉक्स में अपना debug_cleartext_payload चिपकाएं. इसके बाद, "डिकोड करें" पर क्लिक करें.
यह पेज, बकेट की कुंजी की दशमलव वैल्यू दिखाता है. यहां बकेट की एक सैंपल कुंजी दी गई है.
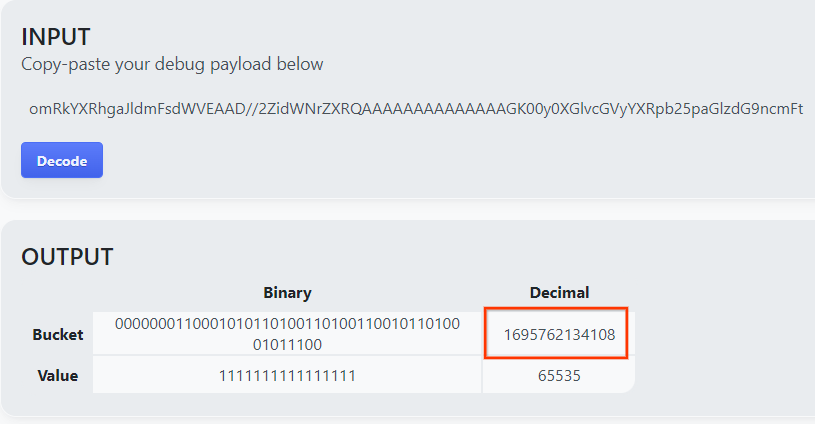
2.4. आउटपुट डोमेन AVRO बनाना
अब हमारे पास बकेट कुंजी है. आइए, उसी फ़ोल्डर में output_domain.avro बनाएं जिसमें हम काम कर रहे हैं. पक्का करें कि आपने बकेट कुंजी को, वापस लाई गई बकेट कुंजी से बदल दिया हो.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
स्क्रिप्ट, आपके मौजूदा फ़ोल्डर में output_domain.avro फ़ाइल बनाती है.
2.5. लोकल टेस्टिंग टूल का इस्तेमाल करके खास जानकारी वाली रिपोर्ट बनाना
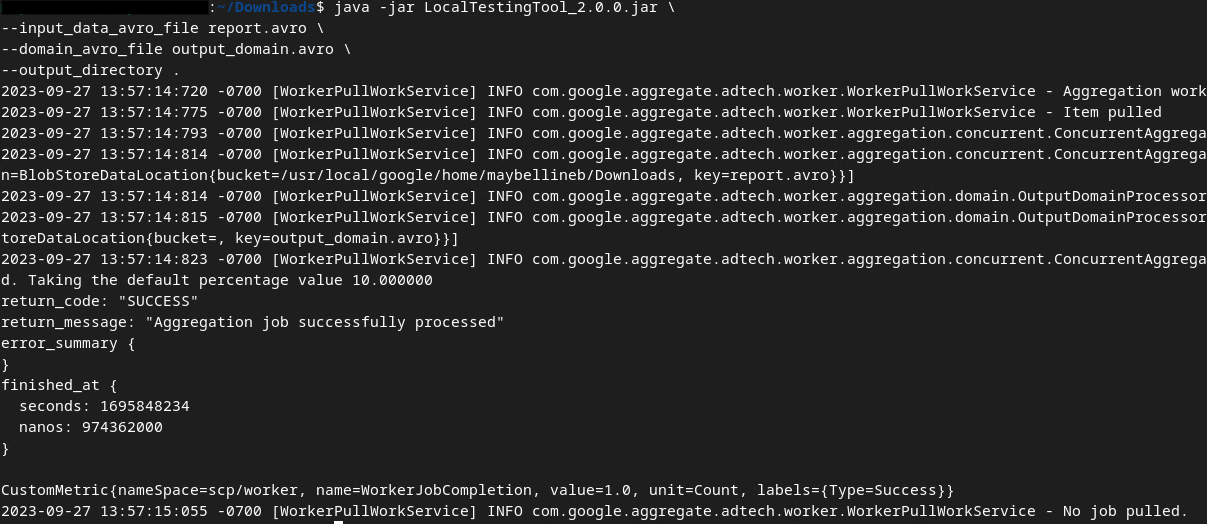
हम यहां दिए गए निर्देश का इस्तेमाल करके खास जानकारी वाली रिपोर्ट बनाने के लिए, ज़रूरी शर्त 1.3 में डाउनलोड किए गए LocalTestingTool_{version}.jar का इस्तेमाल करेंगे. {version} को डाउनलोड किए गए वर्शन से बदलें. LocalTestingTool_{version}.jar को मौजूदा डायरेक्ट्री में ले जाना न भूलें या उसकी मौजूदा जगह का रेफ़रंस देने के लिए, कोई रिलेटिव पाथ जोड़ें.
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
निर्देश चलाने के बाद, आपको कुछ ऐसा दिखेगा. यह प्रोसेस पूरी होने के बाद, एक रिपोर्ट output.avro बनाई जाती है.
2.6. खास जानकारी वाली रिपोर्ट की समीक्षा करना
खास जानकारी वाली रिपोर्ट, AVRO फ़ॉर्मैट में बनाई जाती है. इसे पढ़ने के लिए, आपको इसे AVRO से JSON फ़ॉर्मैट में बदलना होगा. आम तौर पर, adTech को AVRO रिपोर्ट को वापस JSON में बदलने के लिए कोड लिखना चाहिए.
हम AVRO रिपोर्ट को फिर से JSON में बदलने के लिए, aggregatable_report_converter.jar का इस्तेमाल करेंगे.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
इससे नीचे दी गई रिपोर्ट मिलती है. साथ ही, उसी डायरेक्ट्री में बनाई गई रिपोर्ट output.json भी शामिल है.

कोडलैब पूरा हो गया!
खास जानकारी: आपने डीबग रिपोर्ट इकट्ठा की है, आउटपुट डोमेन फ़ाइल बनाई है, और स्थानीय टेस्टिंग टूल का इस्तेमाल करके खास जानकारी वाली रिपोर्ट जनरेट की है. यह टूल, एग्रीगेशन सेवा के एग्रीगेशन व्यवहार को सिम्युलेट करता है.
अगले चरण: लोकल टेस्टिंग टूल का इस्तेमाल करने के बाद, अपने एनवायरमेंट में एग्रीगेशन सेवा को लाइव डिप्लॉय करके, यही एक्सपेरिमेंट दोहराया जा सकता है. ज़रूरी शर्तों को फिर से देखें और पक्का करें कि आपने "एग्रीगेशन सेवा" मोड के लिए, सब कुछ सेट अप कर लिया है. इसके बाद, तीसरे चरण पर जाएं.
3. 3. एग्रीगेशन सेवा का कोडलैब
पूरा होने में लगने वाला अनुमानित समय: एक घंटा
शुरू करने से पहले, पक्का करें कि आपने "एग्रीगेशन सेवा" के लेबल वाली सभी ज़रूरी शर्तें पूरी कर ली हों.
कोडलैब के चरण
तीसरा चरण. एग्रीगेशन सेवा का इनपुट बनाना: एग्रीगेशन सेवा के लिए बैच में भेजी जाने वाली एग्रीगेशन सेवा रिपोर्ट बनाएं.
- तीसरा चरण 3.1.1. ट्रिगर रिपोर्ट
- तीसरा चरण 3.1.2. एग्रीगेट की जा सकने वाली रिपोर्ट इकट्ठा करना
- तीसरा चरण 3.1.3. रिपोर्ट को AVRO में बदलना
- तीसरा चरण: 3.1.4. output_domain AVRO फ़ॉर्मैट में डेटा सेव करना
- तीसरा चरण 3.1.5. रिपोर्ट को Cloud Storage बकेट में ले जाना
तीसरा चरण. एग्रीगेशन सेवा का इस्तेमाल: खास जानकारी वाली रिपोर्ट बनाने और उनकी समीक्षा करने के लिए, एग्रीगेशन सेवा एपीआई का इस्तेमाल करें.
- तीसरा चरण 3.2.1. बैच में भेजने के लिए
createJobएंडपॉइंट का इस्तेमाल करना - तीसरा चरण 3.2.2. बैच का स्टेटस पाने के लिए
getJobएंडपॉइंट का इस्तेमाल करना - तीसरा चरण: 3.2.3. खास जानकारी वाली रिपोर्ट की समीक्षा करना
3.1. एग्रीगेशन सेवा के लिए इनपुट बनाना
एग्रीगेशन सेवा में बैच करने के लिए, AVRO रिपोर्ट बनाएं. इन चरणों में दिए गए शेल निर्देशों को GCP के Cloud Shell में चलाया जा सकता है. हालांकि, ऐसा तब तक ही किया जा सकता है, जब तक ज़रूरी शर्तों की डिपेंडेंसी को आपके Cloud Shell एनवायरमेंट में क्लोन नहीं किया जाता. इसके अलावा, इन निर्देशों को स्थानीय तौर पर भी चलाया जा सकता है.
3.1.1. ट्रिगर रिपोर्ट
साइट पर जाने के लिए, लिंक पर जाएं. इसके बाद, chrome://private-aggregation-internals पर जाकर रिपोर्ट देखी जा सकती हैं:
{reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage एंडपॉइंट पर भेजी गई रिपोर्ट, Chrome के इंटरनल पेज पर दिखने वाली रिपोर्ट के "रिपोर्ट बॉडी" में भी दिखती है.
आपको यहां कई रिपोर्ट दिख सकती हैं, लेकिन इस कोडलैब के लिए, एग्रीगेट की जा सकने वाली ऐसी रिपोर्ट का इस्तेमाल करें जो GCP के लिए खास तौर पर बनाई गई हो और डीबग एंडपॉइंट से जनरेट की गई हो. "रिपोर्ट यूआरएल" में "/debug/" शामिल होगा और "रिपोर्ट बॉडी" के aggregation_coordinator_origin field में यह यूआरएल शामिल होगा: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
3.1.2. एग्रीगेट की जा सकने वाली रिपोर्ट इकट्ठा करना
अपने एपीआई के .well-known एंडपॉइंट से, एग्रीगेट की जा सकने वाली रिपोर्ट इकट्ठा करें.
- निजी एग्रीगेशन:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - एट्रिब्यूशन रिपोर्टिंग - खास जानकारी वाली रिपोर्ट:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
इस कोडलैब के लिए, हम रिपोर्ट को मैन्युअल तरीके से इकट्ठा करते हैं. प्रोडक्शन में, adTechs को प्रोग्राम के हिसाब से रिपोर्ट इकट्ठा करके उन्हें बदलना चाहिए.
अब chrome://private-aggregation-internals से "रिपोर्ट के मुख्य हिस्से" में JSON रिपोर्ट कॉपी करें.
इस उदाहरण में, हमने vim का इस्तेमाल किया है, क्योंकि हम Linux का इस्तेमाल कर रहे हैं. हालांकि, आपके पास अपनी पसंद का कोई भी टेक्स्ट एडिटर इस्तेमाल करने का विकल्प है.
vim report.json
रिपोर्ट को report.json में चिपकाएं और अपनी फ़ाइल सेव करें.
3.1.3. रिपोर्ट को AVRO में बदलना
.well-known एंडपॉइंट से मिली रिपोर्ट, JSON फ़ॉर्मैट में होती हैं. इन्हें AVRO रिपोर्ट फ़ॉर्मैट में बदलना ज़रूरी है. JSON रिपोर्ट मिलने के बाद, उस जगह पर जाएं जहां report.json सेव है. इसके बाद, aggregatable_report_converter.jar का इस्तेमाल करके, डीबग की जा सकने वाली रिपोर्ट बनाएं. इससे आपकी मौजूदा डायरेक्ट्री में, report.avro नाम की एक रिपोर्ट बन जाएगी. इसमें डेटा इकट्ठा किया जा सकता है.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. output_domain AVRO फ़ॉर्मैट में डेटा सेव करना
output_domain.avro फ़ाइल बनाने के लिए, आपको बकेट की ऐसी कुंजियां चाहिए जिन्हें रिपोर्ट से वापस पाया जा सके.
बकेट कुंजियों को विज्ञापन टेक्नोलॉजी (adTech) डिज़ाइन करता है. हालांकि, इस मामले में, साइट Privacy Sandbox Demo, बकेट पासकोड बनाती है. इस साइट के लिए निजी एग्रीगेशन, डीबग मोड में है. इसलिए, हम बकेट कुंजी पाने के लिए, "रिपोर्ट बॉडी" से debug_cleartext_payload का इस्तेमाल कर सकते हैं.
अब रिपोर्ट के मुख्य हिस्से से debug_cleartext_payload को कॉपी करें.
goo.gle/ags-payload-decoder खोलें और "इनपुट" बॉक्स में अपना debug_cleartext_payload चिपकाएं. इसके बाद, "डिकोड करें" पर क्लिक करें.
यह पेज, बकेट की कुंजी की दशमलव वैल्यू दिखाता है. यहां बकेट की एक सैंपल कुंजी दी गई है.
अब हमारे पास बकेट कुंजी है. आइए, उसी फ़ोल्डर में output_domain.avro बनाएं जिसमें हम काम कर रहे हैं. पक्का करें कि आपने बकेट कुंजी को, वापस लाई गई बकेट कुंजी से बदल दिया हो.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
स्क्रिप्ट, आपके मौजूदा फ़ोल्डर में output_domain.avro फ़ाइल बनाती है.
3.1.5. रिपोर्ट को Cloud Storage बकेट में ले जाना
AVRO रिपोर्ट और आउटपुट डोमेन बन जाने के बाद, रिपोर्ट और आउटपुट डोमेन को Cloud Storage की उस बकेट में ले जाएं जिसे आपने ज़रूरी शर्त 1.6 में नोट किया था.
अगर आपने अपने लोकल एनवायरमेंट में gcloud CLI सेट अप किया है, तो फ़ाइलों को उनके संबंधित फ़ोल्डर में कॉपी करने के लिए, नीचे दिए गए निर्देशों का इस्तेमाल करें.
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
इसके अलावा, फ़ाइलों को अपनी बकेट में मैन्युअल तरीके से अपलोड करें. "रिपोर्ट" नाम का फ़ोल्डर बनाएं और उसमें report.avro फ़ाइल अपलोड करें. "output_domains" नाम का फ़ोल्डर बनाएं और उसमें output_domain.avro फ़ाइल अपलोड करें.
3.2. Aggregation Service का इस्तेमाल
ज़रूरी शर्त 1.8 में याद रखें कि आपने एग्रीगेशन सेवा के एंडपॉइंट पर एपीआई अनुरोध करने के लिए, cURL या Postman में से किसी एक को चुना था. यहां आपको दोनों विकल्पों के लिए निर्देश मिलेंगे.
अगर आपकी जॉब किसी गड़बड़ी की वजह से पूरी नहीं हो पाती है, तो आगे की कार्रवाई के बारे में ज़्यादा जानने के लिए, GitHub पर समस्या हल करने से जुड़ा दस्तावेज़ देखें.
3.2.1. बैच में भेजने के लिए createJob एंडपॉइंट का इस्तेमाल करना
कोई जॉब बनाने के लिए, cURL या Postman के निर्देशों का इस्तेमाल करें.
cURL
अपने "टर्मिनल" में, अनुरोध बॉडी फ़ाइल (body.json) बनाएं और यहां चिपकाएं. प्लेसहोल्डर वैल्यू को ज़रूर अपडेट करें. हर फ़ील्ड किस बारे में जानकारी देता है, इस बारे में ज़्यादा जानने के लिए यह एपीआई दस्तावेज़ देखें.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
नीचे दिया गया अनुरोध पूरा करें. cURL अनुरोध के यूआरएल में मौजूद प्लेसहोल्डर को frontend_service_cloudfunction_url की वैल्यू से बदलें. यह वैल्यू, ज़रूरी शर्त 1.6 में Terraform डिप्लॉयमेंट पूरा होने के बाद दिखती है.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
एग्रीगेशन सेवा से अनुरोध स्वीकार होने के बाद, आपको एचटीटीपी 202 कोड वाला जवाब मिलना चाहिए. अन्य संभावित रिस्पॉन्स कोड, एपीआई के स्पेसिफ़िकेशन में दस्तावेज़ के तौर पर मौजूद हैं.
Postman
createJob एंडपॉइंट के लिए, अनुरोध बॉडी ज़रूरी है, ताकि एग्रीगेशन सेवा को एग्रीगेट की जा सकने वाली रिपोर्ट, आउटपुट डोमेन, और खास जानकारी वाली रिपोर्ट की जगह और फ़ाइल के नाम दिए जा सकें.
createJob अनुरोध के "बॉडी" टैब पर जाएं:

दिए गए JSON में प्लेसहोल्डर बदलें. इन फ़ील्ड और इनके बारे में ज़्यादा जानने के लिए, एपीआई से जुड़ा दस्तावेज़ देखें.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
createJob एपीआई अनुरोध "भेजें":

रिस्पॉन्स कोड, पेज के निचले हिस्से में दिखता है:

एग्रीगेशन सेवा से अनुरोध स्वीकार होने के बाद, आपको एचटीटीपी 202 कोड वाला जवाब मिलना चाहिए. अन्य संभावित रिस्पॉन्स कोड, एपीआई के स्पेसिफ़िकेशन में दस्तावेज़ के तौर पर मौजूद हैं.
3.2.2. बैच का स्टेटस पाने के लिए getJob एंडपॉइंट का इस्तेमाल करना
नौकरी पाने के लिए, cURL या Postman के निर्देशों का इस्तेमाल करें.
cURL
अपने टर्मिनल में नीचे दिया गया अनुरोध चलाएं. यूआरएल में प्लेसहोल्डर को frontend_service_cloudfunction_url की वैल्यू से बदलें. यह वही यूआरएल है जिसका इस्तेमाल आपने createJob अनुरोध के लिए किया था. "job_request_id" के लिए, createJob एंडपॉइंट की मदद से बनाई गई जॉब की वैल्यू का इस्तेमाल करें.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
नतीजे में, एचटीटीपी स्टेटस 200 के साथ, नौकरी के अनुरोध की स्थिति दिखनी चाहिए. अनुरोध के "बॉडी" में ज़रूरी जानकारी होती है. जैसे, job_status, return_message, और error_messages (अगर जॉब में कोई गड़बड़ी हुई है).
Postman
नौकरी के अनुरोध की स्थिति देखने के लिए, getJob एंडपॉइंट का इस्तेमाल किया जा सकता है. getJob अनुरोध के "पैरामीटर" सेक्शन में, job_request_id वैल्यू को job_request_id पर अपडेट करें. यह वैल्यू, createJob अनुरोध में भेजी गई थी.
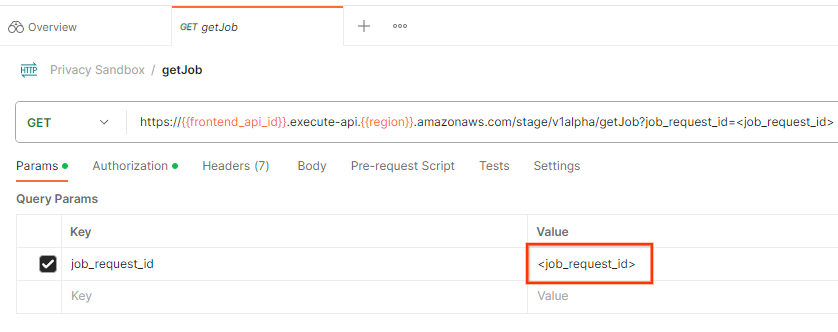
getJob अनुरोध "भेजें":

नतीजे में, एचटीटीपी स्टेटस 200 के साथ, नौकरी के अनुरोध की स्थिति दिखनी चाहिए. अनुरोध के "बॉडी" में ज़रूरी जानकारी होती है. जैसे, job_status, return_message, और error_messages (अगर जॉब में कोई गड़बड़ी हुई है).
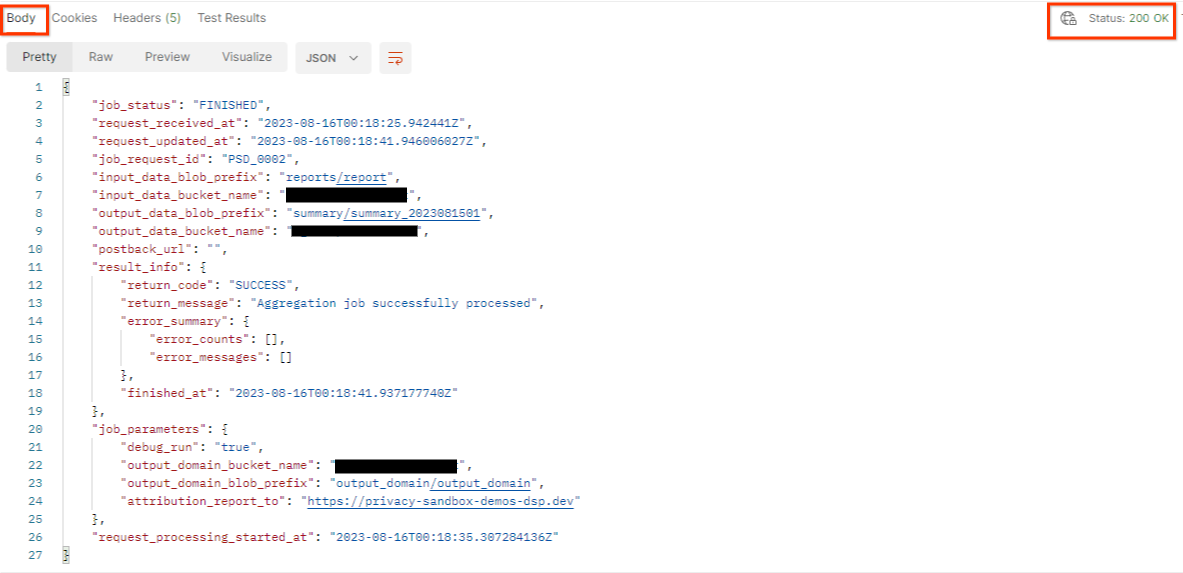
3.2.3. खास जानकारी वाली रिपोर्ट की समीक्षा करना
आउटपुट Cloud Storage बकेट में खास जानकारी वाली रिपोर्ट मिलने के बाद, उसे अपने लोकल एनवायरमेंट में डाउनलोड किया जा सकता है. समरी रिपोर्ट, AVRO फ़ॉर्मैट में होती हैं और इन्हें JSON में बदला जा सकता है. नीचे दिए गए निर्देश का इस्तेमाल करके, अपनी रिपोर्ट पढ़ने के लिए aggregatable_report_converter.jar का इस्तेमाल किया जा सकता है.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
इससे हर बकेट की की की एग्रीगेट की गई वैल्यू का JSON मिलता है, जो नीचे दिए गए JSON जैसा दिखता है.

अगर आपके createJob अनुरोध में debug_run को 'सही' के तौर पर शामिल किया गया है, तो आपको समरी रिपोर्ट output_data_blob_prefix में मौजूद डीबग फ़ोल्डर में मिल सकती है. रिपोर्ट, AVRO फ़ॉर्मैट में है और ऊपर दिए गए निर्देश का इस्तेमाल करके, इसे JSON में बदला जा सकता है.
रिपोर्ट में बकेट की, बिना गड़बड़ी वाली मेट्रिक, और गड़बड़ी वाली मेट्रिक शामिल होती है. गड़बड़ी वाली मेट्रिक को बिना गड़बड़ी वाली मेट्रिक में जोड़कर, खास जानकारी वाली रिपोर्ट बनाई जाती है. रिपोर्ट इस तरह की होती है.

एनोटेशन में "in_reports" और/या "in_domain" भी शामिल होते हैं. इसका मतलब है:
- in_reports - बकेट का पासकोड, एग्रीगेट की जा सकने वाली रिपोर्ट में उपलब्ध होता है.
- in_domain - output_domain AVRO फ़ाइल में बकेट पासकोड उपलब्ध होता है.
कोडलैब पूरा हो गया!
खास जानकारी: आपने अपने क्लाउड एनवायरमेंट में एग्रीगेशन सेवा को डिप्लॉय किया है, डीबग रिपोर्ट इकट्ठा की है, आउटपुट डोमेन फ़ाइल बनाई है, इन फ़ाइलों को Cloud Storage बकेट में सेव किया है, और जॉब को सफलतापूर्वक चलाया है!
अगले चरण: अपने एनवायरमेंट में एग्रीगेशन सेवा का इस्तेमाल जारी रखें या चरण 4 में दिए गए क्लीन-अप निर्देशों का पालन करके, अभी बनाए गए क्लाउड रिसॉर्स मिटाएं.
4. 4. मिटाना
Terraform की मदद से एग्रीगेशन सेवा के लिए बनाए गए संसाधनों को मिटाने के लिए, adtech_setup और dev (या अन्य एनवायरमेंट) फ़ोल्डर में destroy कमांड का इस्तेमाल करें:
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
एग्रीगेट की जा सकने वाली रिपोर्ट और खास जानकारी वाली रिपोर्ट को सेव करने वाली Cloud Storage बकेट को मिटाने के लिए:
$ gcloud storage buckets delete gs://my-bucket
आपके पास Chrome की कुकी सेटिंग को, ज़रूरी शर्त 1.2 से पहले की स्थिति पर वापस लाने का विकल्प भी है.
5. 5. अन्य जानकारी
adtech_setup.auto.tfvars फ़ाइल का उदाहरण
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
dev.auto.tfvars फ़ाइल का उदाहरण
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20