
1. 1. Prasyarat
Perkiraan waktu penyelesaian: 1-2 jam
Ada 2 mode untuk menjalankan codelab ini: Pengujian Lokal atau Layanan Agregasi. Mode Pengujian Lokal memerlukan komputer lokal dan browser Chrome (tanpa pembuatan/penggunaan resource Google Cloud). Mode Layanan Agregasi memerlukan deployment penuh Layanan Agregasi di Google Cloud.
Untuk menjalankan codelab ini dalam kedua mode tersebut, beberapa prasyarat diperlukan. Setiap persyaratan ditandai dengan sesuai, baik diperlukan untuk Layanan Pengujian Lokal atau Layanan Agregasi.
1.1. Pendaftaran dan Pengesahan Lengkap (Layanan Agregasi)
Untuk menggunakan API Privacy Sandbox, pastikan Anda telah menyelesaikan Pendaftaran dan Pengesahan untuk Chrome dan Android.
1.2. Mengaktifkan API privasi iklan (Layanan Pengujian dan Agregasi Lokal)
Karena kami akan menggunakan Privacy Sandbox, sebaiknya Anda mengaktifkan Privacy Sandbox Ads API.
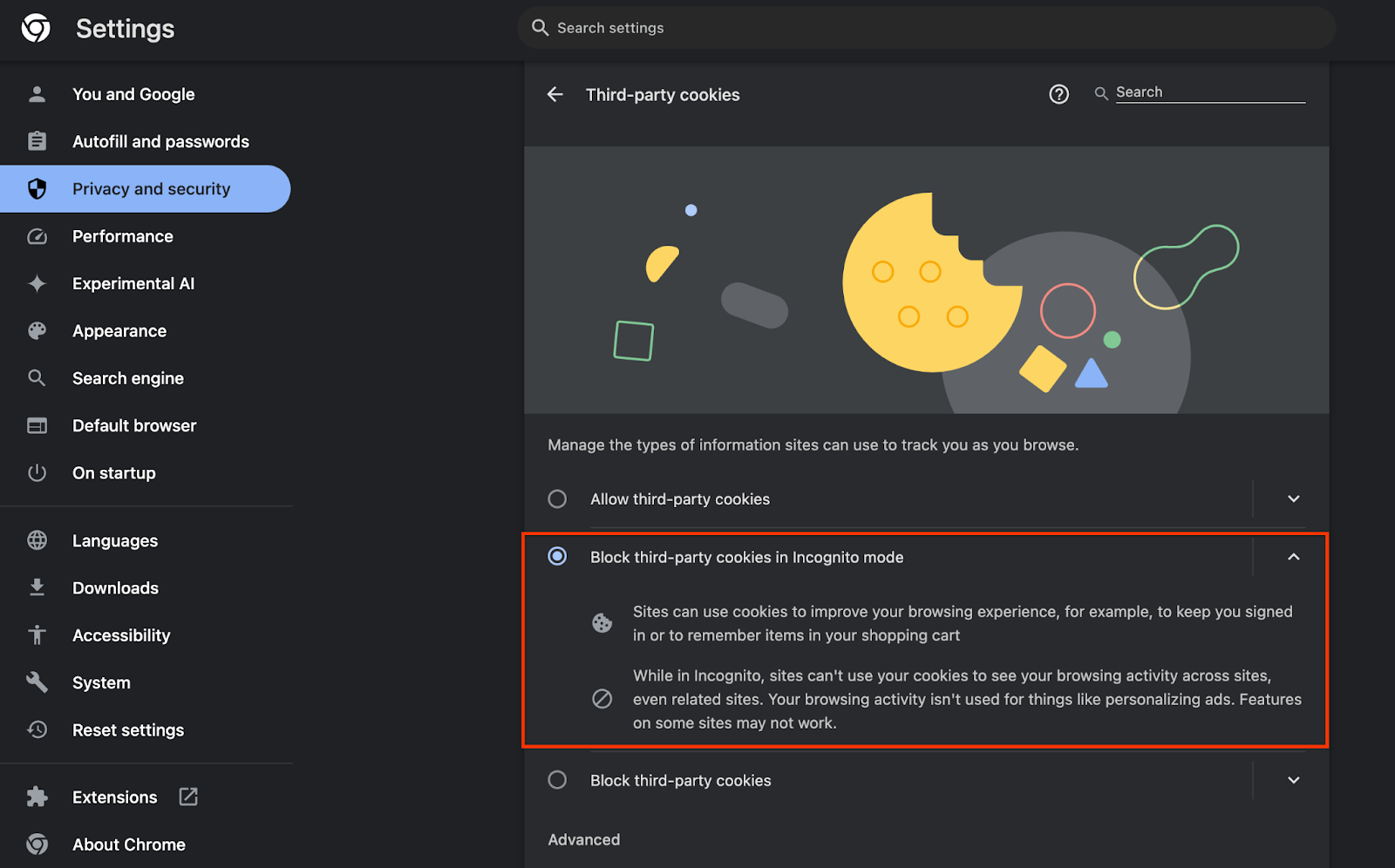
Di browser Anda, buka chrome://settings/adPrivacy dan aktifkan semua API privasi iklan.
Pastikan juga cookie pihak ketiga Anda diaktifkan.
Mulai chrome://settings/cookies, pastikan cookie pihak ketiga TIDAK diblokir. Bergantung pada versi Chrome, Anda mungkin melihat opsi yang berbeda pada menu setelan ini, tetapi konfigurasi yang dapat diterima mencakup:
- "Blokir semua cookie pihak ketiga" = DINONAKTIFKAN
- "Blokir cookie pihak ketiga" = DINONAKTIFKAN
- "Blokir cookie pihak ketiga dalam mode Samaran" = DIAKTIFKAN
1.3. Download Alat Pengujian Lokal (Pengujian Lokal)
Pengujian Lokal akan memerlukan download Alat Pengujian Lokal. Alat ini akan membuat laporan ringkasan dari laporan debug yang tidak dienkripsi.
Alat Pengujian Lokal tersedia untuk didownload di Arsip JAR Cloud Function di GitHub. Atribut ini harus diberi nama LocalTestingTool_{version}.jar.
1.4. Pastikan JAVA JRE diinstal (Layanan Pengujian dan Agregasi Lokal)
Buka "Terminal" dan gunakan java --version untuk memeriksa apakah komputer Anda telah menginstal Java atau openJDK.

Jika tidak terinstal, Anda dapat mendownload dan menginstal dari situs Java atau situs openJDK.
1.5. Mendownload aggregatable_report_converter (Layanan Pengujian dan Agregasi Lokal)
Anda dapat mendownload salinan aggregatable_report_converter dari repositori GitHub Demo Privacy Sandbox. Repositori GitHub menyebutkan penggunaan IntelliJ atau Eclipse, tetapi keduanya tidak wajib. Jika Anda tidak menggunakan alat tersebut, download file JAR ke lingkungan lokal Anda.
1.6. Menyiapkan Lingkungan GCP (Layanan Agregasi)
Layanan Agregasi memerlukan penggunaan Trusted Execution Environment yang menggunakan penyedia cloud. Dalam codelab ini, Layanan Agregasi akan di-deploy di GCP, tetapi AWS juga didukung.
Ikuti Petunjuk Deployment di GitHub untuk menyiapkan gcloud CLI, mendownload biner dan modul Terraform, serta membuat resource GCP untuk Layanan Agregasi.
Langkah utama dalam Petunjuk Deployment:
- Menyiapkan "gcloud" CLI dan Terraform di lingkungan Anda.
- Membuat bucket Cloud Storage untuk menyimpan status Terraform.
- Download dependensi.
- Update
adtech_setup.auto.tfvarsdan jalankan Terraformadtech_setup. Lihat Lampiran untuk contoh fileadtech_setup.auto.tfvars. Perhatikan nama bucket data yang dibuat di sini – nama ini akan digunakan dalam codelab untuk menyimpan file yang kita buat. - Update
dev.auto.tfvars, tiru identitas akun layanan deploy, dan jalankan Terraformdev. Lihat Lampiran untuk contoh filedev.auto.tfvars. - Setelah deployment selesai, ambil
frontend_service_cloudfunction_urldari output Terraform, yang akan diperlukan untuk membuat permintaan ke Layanan Agregasi pada langkah-langkah berikutnya.
1.7. Orientasi Layanan Agregasi Lengkap (Layanan Agregasi)
Layanan Agregasi memerlukan orientasi agar koordinator dapat menggunakan layanan. Lengkapi formulir Orientasi Layanan Agregasi dengan memberikan Situs Pelaporan dan informasi lainnya, memilih "Google Cloud", lalu memasukkan alamat akun layanan Anda. Akun layanan ini dibuat pada prasyarat sebelumnya (1.6. Menyiapkan Lingkungan GCP). (Petunjuk: jika Anda menggunakan nama default yang diberikan, akun layanan ini akan dimulai dengan "worker-sa@").
Tunggu hingga 2 minggu agar proses orientasi selesai.
1,8. Menentukan metode untuk memanggil endpoint API (Layanan Agregasi)
Codelab ini menyediakan 2 opsi untuk memanggil endpoint Aggregation Service API: cURL dan Postman. cURL adalah cara yang lebih cepat dan mudah untuk memanggil endpoint API dari Terminal Anda, karena memerlukan penyiapan minimal dan tanpa software tambahan. Namun, jika tidak ingin menggunakan cURL, Anda dapat menggunakan Postman untuk menjalankan dan menyimpan permintaan API untuk penggunaan di masa mendatang.
Di bagian 3.2. Penggunaan Layanan Agregasi, Anda akan menemukan petunjuk mendetail untuk menggunakan kedua opsi tersebut. Anda dapat melihat pratinjaunya sekarang untuk menentukan metode yang akan digunakan. Jika Anda memilih Postman, lakukan penyiapan awal berikut.
1.8.1. Siapkan ruang kerja
Daftar untuk membuat akun Postman. Setelah mendaftar, ruang kerja akan dibuat secara otomatis.
Jika ruang kerja tidak dibuat untuk Anda, buka "Ruang kerja" item navigasi atas dan pilih "{i>Create Workspace<i}".
Pilih "Ruang kerja kosong", klik berikutnya, lalu beri nama "GCP Privacy Sandbox". Pilih "Pribadi" dan klik "Buat".
Download konfigurasi JSON dan file Lingkungan Global yang telah dikonfigurasi sebelumnya.
Impor kedua file JSON ke "Ruang Kerja Saya" melalui "Impor" tombol.

Tindakan ini akan membuat "Privacy Sandbox GCP" untuk Anda beserta permintaan HTTP createJob dan getJob.
1.8.2. Menyiapkan otorisasi
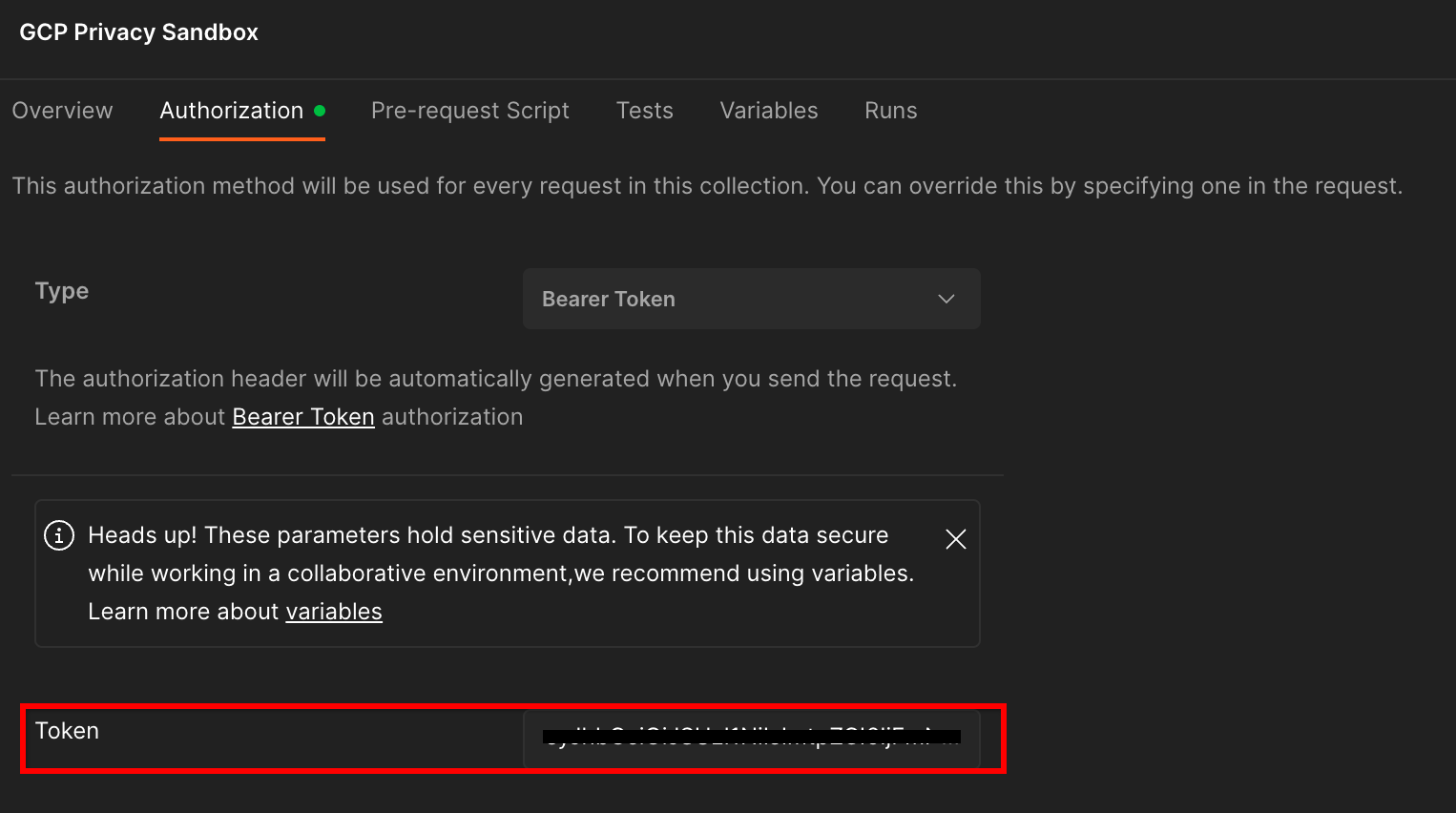
Klik "GCP Privacy Sandbox" pengumpulan gambar dan arahkan ke "Otorisasi" .

Anda akan menggunakan "Bearer Token" . Dari lingkungan Terminal Anda, jalankan perintah ini dan salin outputnya.
gcloud auth print-identity-token
Kemudian, tempel nilai token ini ke dalam "Token" pada tab otorisasi Postman:
1.8.3. Lingkungan penyiapan
Buka "Tampilan cepat lingkungan" di sudut kanan atas:
Klik "Edit" dan perbarui "Nilai Saat Ini" "environment", "region", dan "cloud-function-id":
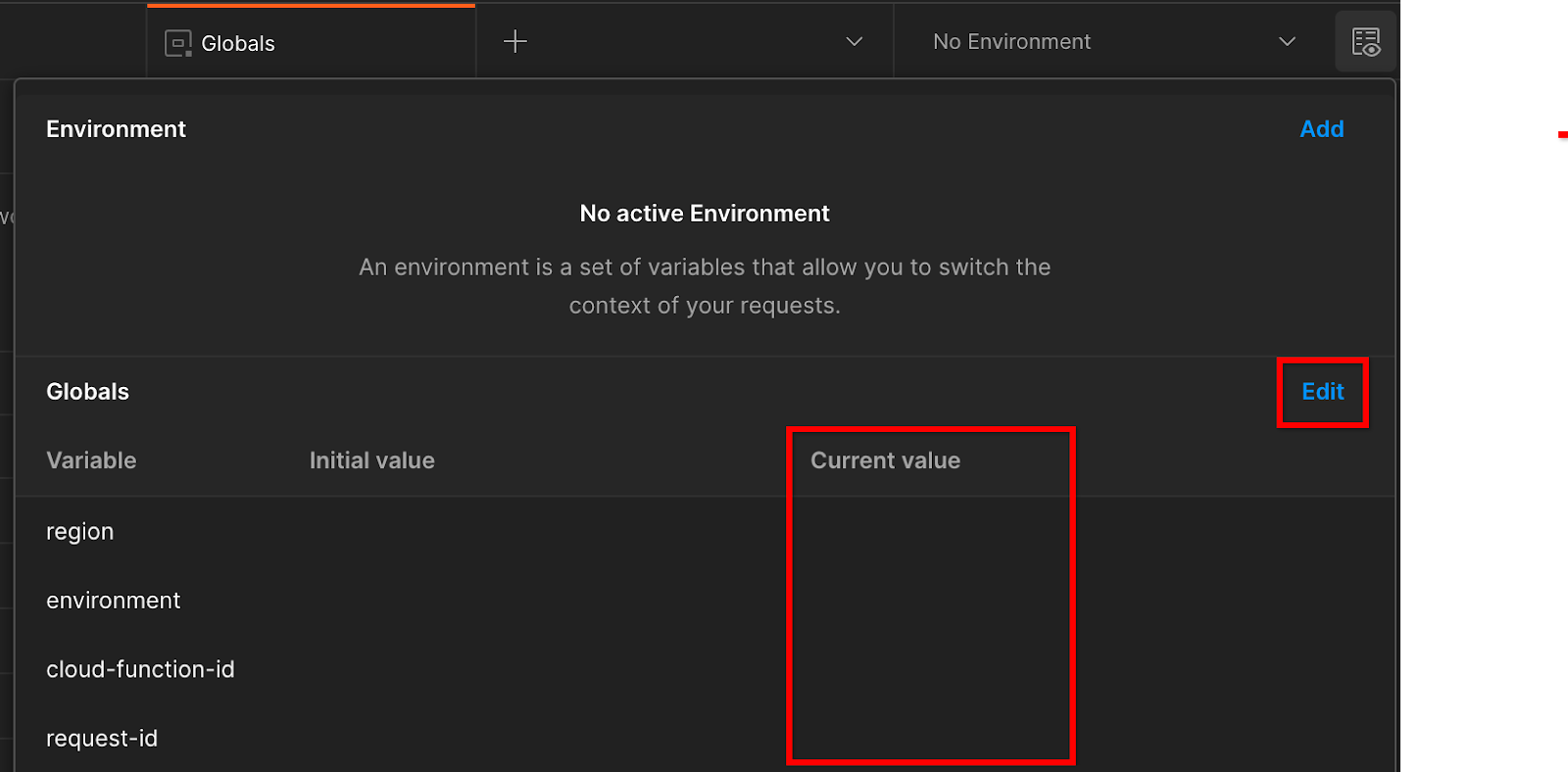
Anda dapat meninggalkan "request-id" kosong untuk saat ini, karena
kita akan mengisinya nanti. Untuk kolom lainnya, gunakan nilai dari frontend_service_cloudfunction_url, yang ditampilkan dari keberhasilan penyelesaian deployment Terraform di Prasyarat 1.6. URL mengikuti format ini: https://
2. 2. Codelab Pengujian Lokal
Perkiraan waktu selesai: <1 jam
Anda dapat menggunakan alat pengujian lokal di mesin untuk melakukan agregasi dan membuat laporan ringkasan menggunakan laporan debug yang tidak dienkripsi. Sebelum memulai, pastikan Anda telah menyelesaikan semua Prasyarat yang diberi label "Pengujian Lokal".
Langkah-langkah codelab
Langkah 2.1. Laporan pemicu: Memicu pelaporan Agregasi Pribadi agar dapat mengumpulkan laporan.
Langkah 2.2. Buat Laporan Debug AVRO: Konversi laporan JSON yang dikumpulkan menjadi laporan berformat AVRO. Langkah ini akan serupa dengan saat Teknologi Iklan mengumpulkan laporan dari endpoint pelaporan API dan mengonversi laporan JSON menjadi laporan berformat AVRO.
Langkah 2.3. Mengambil Kunci Bucket: Kunci bucket didesain oleh adTech. Dalam codelab ini, karena bucket telah ditentukan sebelumnya, ambil kunci bucket seperti yang disediakan.
Langkah 2.4. Buat Domain Output AVRO: Setelah kunci bucket diambil, buat file AVRO Domain Output.
Langkah 2.5. Buat Laporan Ringkasan: Gunakan Alat Pengujian Lokal untuk membuat Laporan Ringkasan di Lingkungan Lokal.
Langkah 2.6. Tinjau Laporan Ringkasan: Tinjau Laporan Ringkasan yang dibuat oleh Alat Pengujian Lokal.
2.1. Laporan pemicu
Untuk memicu laporan agregasi pribadi, Anda dapat menggunakan situs demo Privacy Sandbox (https://privacy-sandbox-demos-news.dev/?env=gcp) atau situs Anda sendiri (mis., https://adtechexample.com). Jika Anda menggunakan situs sendiri dan belum menyelesaikan Pendaftaran & Orientasi Layanan Pengesahan dan Agregasi, Anda harus menggunakan tanda Chrome dan tombol CLI.
Untuk demo ini, kami akan menggunakan situs demo Privacy Sandbox. Ikuti link untuk membuka situs; kemudian, Anda dapat melihat laporan tersebut di chrome://private-aggregation-internals:
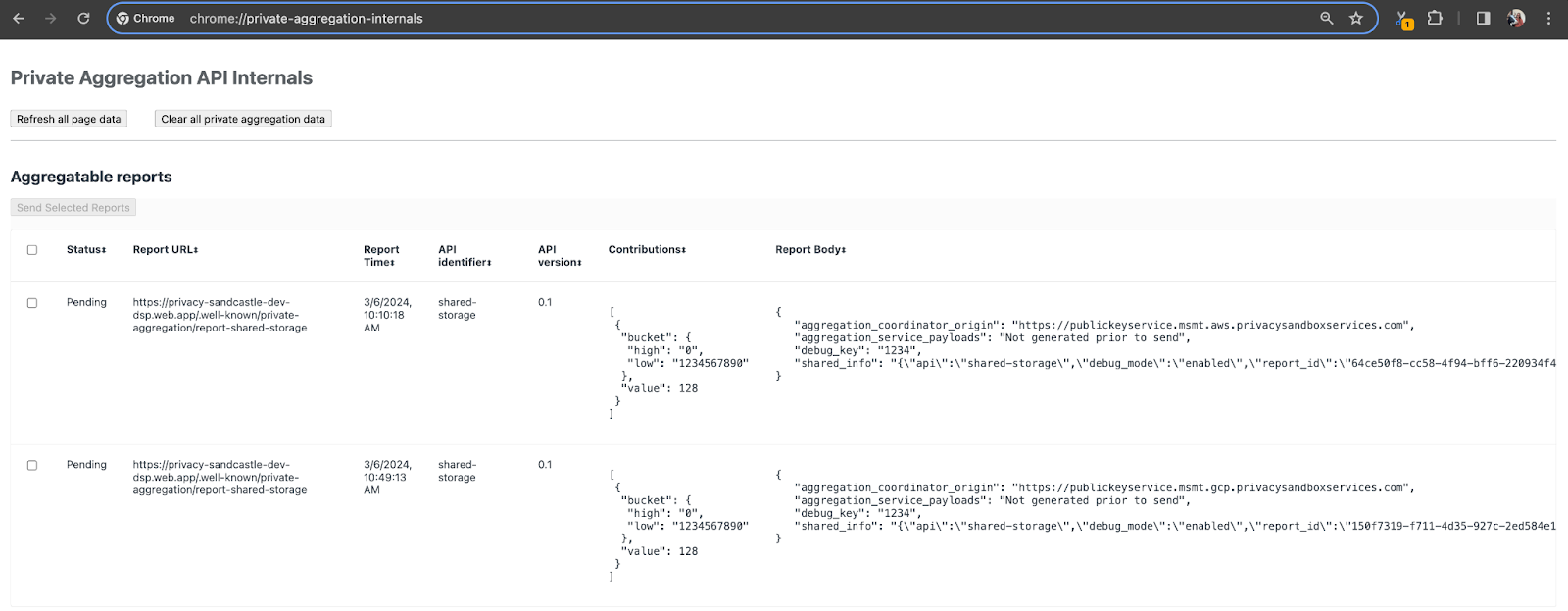
Laporan yang dikirim ke endpoint {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage juga ditemukan di "Isi Laporan" laporan yang ditampilkan di halaman Internal Chrome.
Anda mungkin melihat banyak laporan di sini, tetapi untuk codelab ini, gunakan laporan gabungan yang khusus untuk GCP dan dihasilkan oleh endpoint debug. "URL Laporan" akan berisi "/debug/" dan aggregation_coordinator_origin field "Isi Laporan" akan berisi URL ini: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
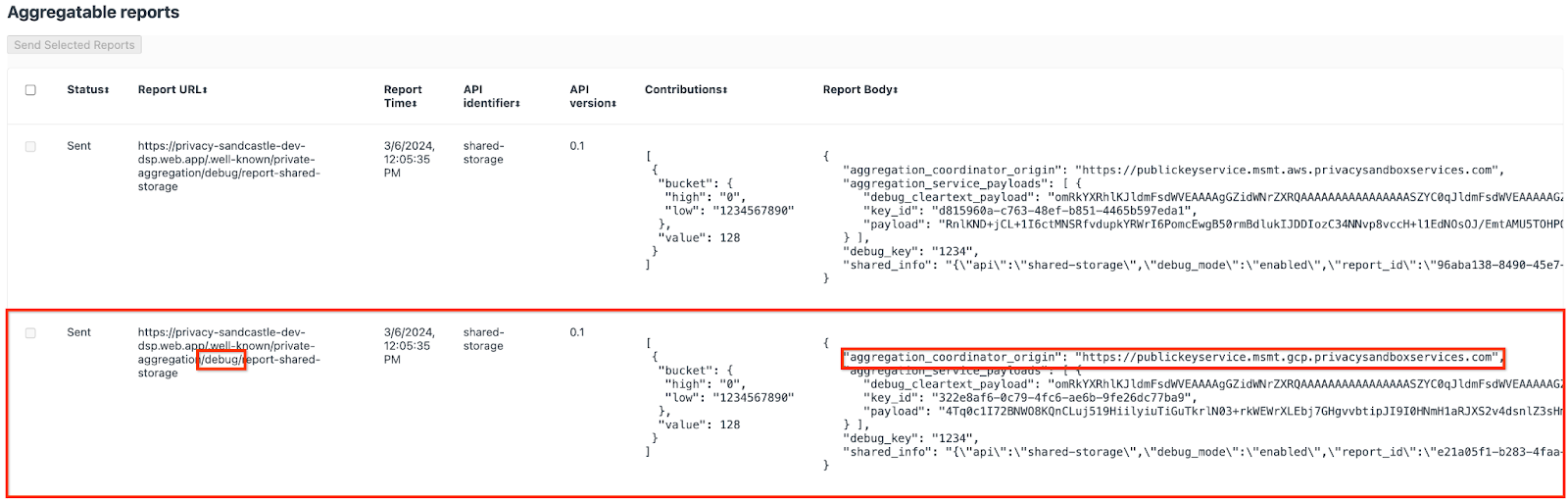
2.2. Buat Laporan Agregat Debug
Salin laporan yang ada di "Isi Laporan" dari chrome://private-aggregation-internals dan buat file JSON di folder privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar (dalam repo yang didownload di Prasyarat 1.5).
Dalam contoh ini, kita menggunakan {i>vim<i} karena kita menggunakan linux. Tetapi Anda dapat menggunakan editor teks apa pun yang Anda inginkan.
vim report.json
Tempel laporan ke report.json dan simpan file Anda.

Setelah Anda memilikinya, gunakan aggregatable_report_converter.jar untuk membantu membuat laporan agregat debug. Tindakan ini akan membuat laporan gabungan yang disebut report.avro di direktori Anda saat ini.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Mengambil Kunci Bucket dari Laporan
Untuk membuat file output_domain.avro, Anda memerlukan kunci bucket yang dapat diambil dari laporan.
Kunci bucket didesain oleh adTech. Namun, dalam kasus ini, Demo Privacy Sandbox situs akan membuat kunci bucket. Karena agregasi pribadi untuk situs ini berada dalam mode debug, kita dapat menggunakan debug_cleartext_payload dari "Isi Laporan" untuk mendapatkan kunci bucket.
Lanjutkan dan salin debug_cleartext_payload dari isi laporan.

Buka goo.gle/ags-payload-decoder, lalu tempel debug_cleartext_payload Anda di "INPUT" kotak teks dan klik "Dekode".
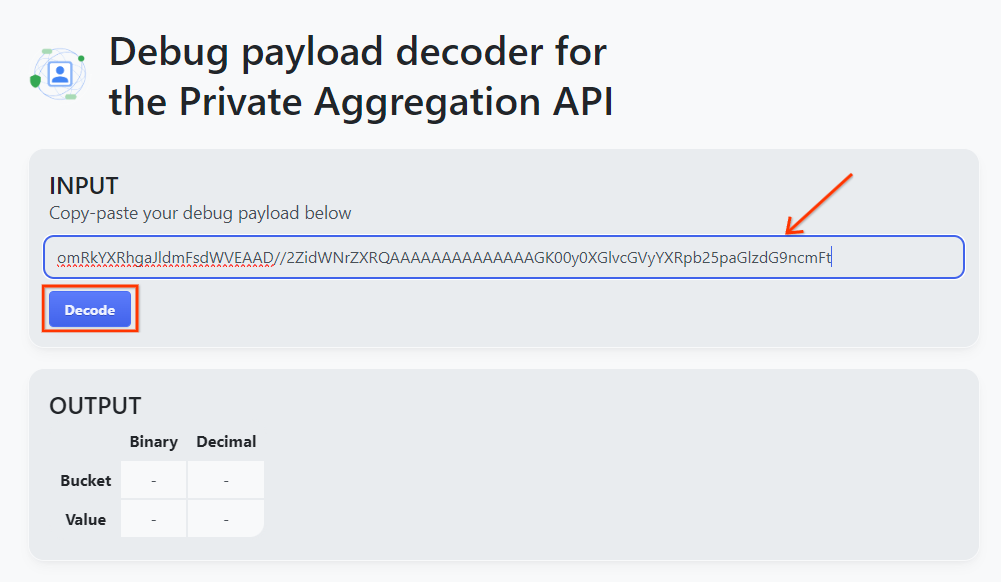
Halaman akan menampilkan nilai desimal kunci bucket. Di bawah ini adalah contoh kunci bucket.
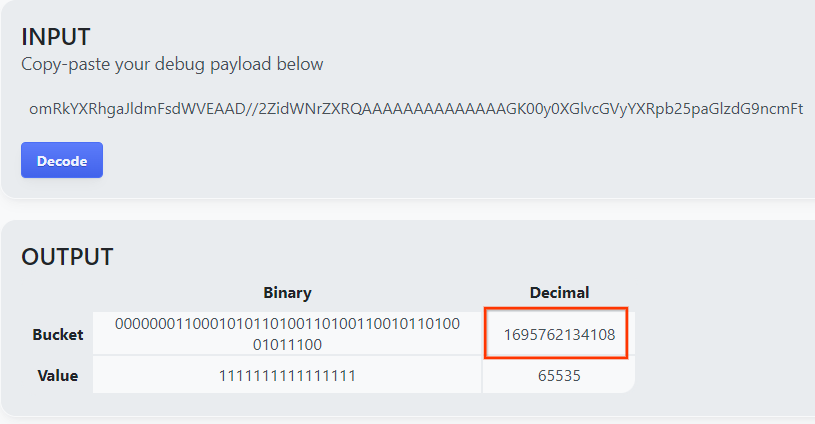
2.4. Membuat Domain Output AVRO
Setelah memiliki kunci bucket, mari kita buat output_domain.avro di folder yang sama dengan yang kita kerjakan. Pastikan Anda mengganti kunci bucket dengan kunci bucket yang Anda ambil.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Skrip akan membuat file output_domain.avro di folder Anda saat ini.
2.5. Membuat Laporan Ringkasan menggunakan Alat Pengujian Lokal
Kita akan menggunakan LocalTestingTool_{version}.jar yang telah didownload di Prasyarat 1.3 untuk membuat laporan ringkasan menggunakan perintah di bawah. Ganti {version} dengan versi yang Anda download. Jangan lupa memindahkan LocalTestingTool_{version}.jar ke direktori saat ini, atau menambahkan jalur relatif untuk mereferensikan lokasi saat ini.
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
Anda akan melihat sesuatu yang mirip dengan di bawah ini setelah perintah dijalankan. Laporan output.avro akan dibuat setelah proses ini selesai.
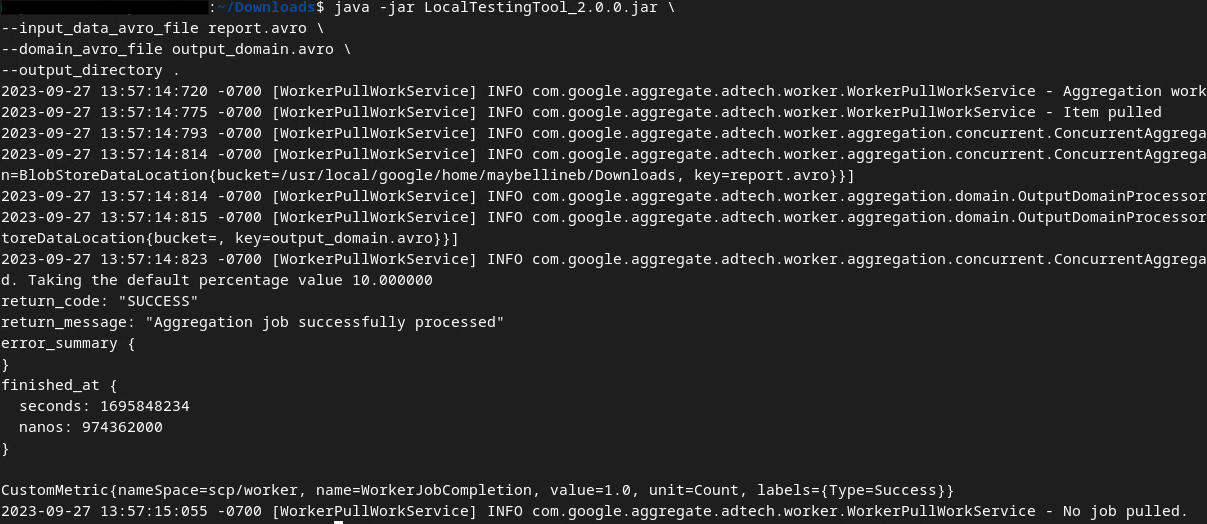
2.6. Meninjau Laporan Ringkasan
Laporan ringkasan yang dibuat menggunakan format AVRO. Agar dapat membaca teks ini, Anda perlu mengonversinya dari AVRO ke format JSON. Idealnya, adTech harus menulis kode untuk mengonversi laporan AVRO kembali ke JSON.
Kita akan menggunakan aggregatable_report_converter.jar untuk mengonversi laporan AVRO kembali ke JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
Tindakan ini akan menampilkan laporan yang mirip dengan yang di bawah ini. Bersama dengan laporan output.json yang dibuat dalam direktori yang sama.

Codelab selesai!
Ringkasan: Anda telah mengumpulkan laporan debug, membuat file domain output, dan membuat laporan ringkasan menggunakan alat pengujian lokal yang menyimulasikan perilaku agregasi Layanan Agregasi.
Langkah berikutnya: Setelah bereksperimen dengan alat Pengujian Lokal, Anda dapat mencoba latihan yang sama dengan deployment langsung Layanan Agregasi di lingkungan Anda sendiri. Lihat kembali prasyarat guna memastikan Anda telah menyiapkan semuanya untuk "Layanan Agregasi" lalu lanjutkan ke langkah 3.
3. 3. Codelab Layanan Agregasi
Perkiraan waktu selesai: 1 jam
Sebelum memulai, pastikan Anda telah menyelesaikan semua Prasyarat yang diberi label "Layanan Agregasi".
Langkah-langkah codelab
Langkah 3.1. Pembuatan Input Layanan Agregasi: Membuat laporan Layanan Agregasi yang dikelompokkan untuk Layanan Agregasi.
- Langkah 3.1.1. Laporan Pemicu
- Langkah 3.1.2. Mengumpulkan Laporan Agregat
- Langkah 3.1.3. Konversi Laporan ke AVRO
- Langkah 3.1.4. Buat AVRO output_domain
- Langkah 3.1.5. Memindahkan Laporan ke bucket Cloud Storage
Langkah 3.2. Penggunaan Layanan Agregasi: Gunakan Aggregation Service API untuk membuat Laporan Ringkasan dan meninjau Laporan Ringkasan.
- Langkah 3.2.1. Menggunakan Endpoint
createJobuntuk mengelompokkan - Langkah 3.2.2. Menggunakan Endpoint
getJobuntuk mengambil status batch - Langkah 3.2.3. Meninjau Laporan Ringkasan
3.1. Pembuatan Input Layanan Agregasi
Lanjutkan membuat laporan AVRO untuk pengelompokan ke Layanan Agregasi. Perintah shell dalam langkah-langkah ini dapat dijalankan dalam Cloud Shell GCP (selama dependensi dari Prasyarat di-clone ke lingkungan Cloud Shell Anda) atau di lingkungan eksekusi lokal.
3.1.1. Laporan Pemicu
Ikuti link untuk membuka situs; kemudian, Anda dapat melihat laporan tersebut di chrome://private-aggregation-internals:
Laporan yang dikirim ke endpoint {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage juga ditemukan di "Isi Laporan" laporan yang ditampilkan di halaman Internal Chrome.
Anda mungkin melihat banyak laporan di sini, tetapi untuk codelab ini, gunakan laporan gabungan yang khusus untuk GCP dan dihasilkan oleh endpoint debug. "URL Laporan" akan berisi "/debug/" dan aggregation_coordinator_origin field "Isi Laporan" akan berisi URL ini: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
3.1.2. Mengumpulkan Laporan Agregat
Kumpulkan laporan agregat dari endpoint .well-known dari API terkait Anda.
- Agregasi Pribadi:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - Pelaporan Atribusi - Laporan Ringkasan:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
Untuk codelab ini, kita melakukan pengumpulan laporan secara manual. Dalam produksi, adTech diharapkan mengumpulkan dan mengonversi laporan secara terprogram.
Mari kita lanjutkan dan salin laporan JSON di "Isi Laporan" dari chrome://private-aggregation-internals.
Dalam contoh ini, kita menggunakan {i>vim<i} karena kita menggunakan linux. Tetapi Anda dapat menggunakan editor teks apa pun yang Anda inginkan.
vim report.json
Tempel laporan ke report.json dan simpan file Anda.
3.1.3. Konversi Laporan ke AVRO
Laporan yang diterima dari endpoint .well-known menggunakan format JSON dan perlu dikonversi ke dalam format laporan AVRO. Setelah Anda memiliki laporan JSON, buka tempat report.json disimpan dan gunakan aggregatable_report_converter.jar untuk membantu membuat laporan agregat debug. Tindakan ini akan membuat laporan gabungan yang disebut report.avro di direktori Anda saat ini.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. Buat AVRO output_domain
Untuk membuat file output_domain.avro, Anda memerlukan kunci bucket yang dapat diambil dari laporan.
Kunci bucket didesain oleh adTech. Namun, dalam kasus ini, Demo Privacy Sandbox situs akan membuat kunci bucket. Karena agregasi pribadi untuk situs ini berada dalam mode debug, kita dapat menggunakan debug_cleartext_payload dari "Isi Laporan" untuk mendapatkan kunci bucket.
Lanjutkan dan salin debug_cleartext_payload dari isi laporan.
Buka goo.gle/ags-payload-decoder, lalu tempel debug_cleartext_payload Anda di "INPUT" kotak teks dan klik "Dekode".
Halaman akan menampilkan nilai desimal kunci bucket. Di bawah ini adalah contoh kunci bucket.
Setelah memiliki kunci bucket, mari kita buat output_domain.avro di folder yang sama dengan yang kita kerjakan. Pastikan Anda mengganti kunci bucket dengan kunci bucket yang Anda ambil.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Skrip akan membuat file output_domain.avro di folder Anda saat ini.
3.1.5. Memindahkan Laporan ke bucket Cloud Storage
Setelah laporan AVRO dan domain output dibuat, lanjutkan untuk memindahkan domain laporan dan output ke dalam bucket di Cloud Storage (yang telah Anda catat di Prasyarat 1.6).
Jika Anda sudah menyiapkan gcloud CLI di lingkungan lokal, gunakan perintah di bawah ini untuk menyalin file ke folder yang sesuai.
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
Jika tidak, upload file tersebut ke bucket Anda secara manual. Buat folder bernama "laporan" lalu upload file report.avro di sana. Buat folder bernama "output_domains" lalu upload file output_domain.avro di sana.
3.2. Penggunaan Layanan Agregasi
Ingat kembali pada Prasyarat 1.8 bahwa Anda memilih cURL atau Postman untuk membuat permintaan API ke endpoint Layanan Agregasi. Di bawah ini Anda akan menemukan petunjuk untuk kedua opsi tersebut.
Jika tugas Anda gagal disertai error, periksa dokumentasi pemecahan masalah kami di GitHub untuk mengetahui informasi selengkapnya tentang cara melanjutkan.
3.2.1. Menggunakan Endpoint createJob untuk mengelompokkan
Gunakan petunjuk cURL atau Postman di bawah untuk membuat tugas.
cURL
Di "Terminal", buat file isi permintaan (body.json) dan tempel di bawah ini. Pastikan untuk memperbarui nilai placeholder. Lihat dokumentasi API ini untuk informasi selengkapnya tentang apa yang direpresentasikan oleh setiap kolom.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Jalankan permintaan di bawah ini. Ganti placeholder di URL permintaan cURL dengan nilai dari frontend_service_cloudfunction_url, yang merupakan output setelah deployment Terraform berhasil diselesaikan pada Prasyarat 1.6.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
Anda akan menerima respons HTTP 202 setelah permintaan diterima oleh Layanan Agregasi. Kode respons lain yang mungkin didokumentasikan dalam spesifikasi API.
Postman
Untuk endpoint createJob, isi permintaan diperlukan untuk memberikan lokasi dan nama file laporan agregat, domain output, dan laporan ringkasan kepada Layanan Agregasi.
Buka "Isi" permintaan createJob :

Ganti placeholder dalam JSON yang disediakan. Untuk informasi selengkapnya tentang kolom ini dan apa yang diwakilinya, lihat dokumentasi API.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
"Kirim" permintaan API createJob:

Kode respons dapat ditemukan di bagian bawah halaman:

Anda akan menerima respons HTTP 202 setelah permintaan diterima oleh Layanan Agregasi. Kode respons lain yang mungkin didokumentasikan dalam spesifikasi API.
3.2.2 Menggunakan Endpoint getJob untuk mengambil status batch
Gunakan petunjuk cURL atau Postman di bawah untuk mendapatkan pekerjaan.
cURL
Jalankan permintaan di bawah ini di Terminal Anda. Ganti placeholder di URL dengan nilai dari frontend_service_cloudfunction_url, yang merupakan URL yang sama seperti yang Anda gunakan untuk permintaan createJob. Untuk "job_request_id", gunakan nilai dari tugas yang Anda buat dengan endpoint createJob.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
Hasilnya akan menampilkan status permintaan tugas Anda dengan status HTTP 200. Permintaan "Isi" berisi informasi yang diperlukan seperti job_status, return_message, dan error_messages (jika tugas mengalami error).
Postman
Untuk memeriksa status permintaan tugas, Anda dapat menggunakan endpoint getJob. Di "Params" di permintaan getJob, perbarui nilai job_request_id ke job_request_id yang dikirim dalam permintaan createJob.
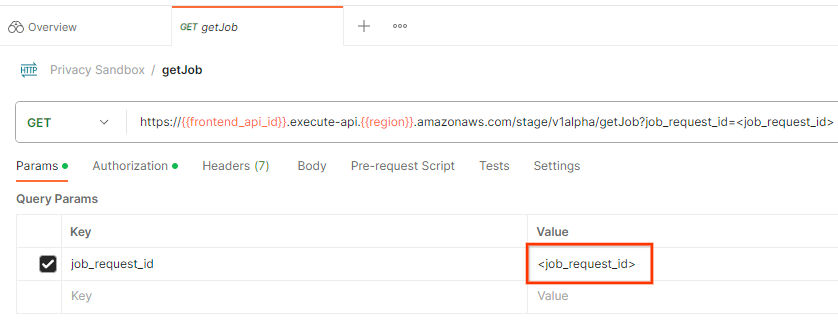
"Kirim" permintaan getJob:

Hasilnya akan menampilkan status permintaan tugas Anda dengan status HTTP 200. Permintaan "Isi" berisi informasi yang diperlukan seperti job_status, return_message, dan error_messages (jika tugas mengalami error).
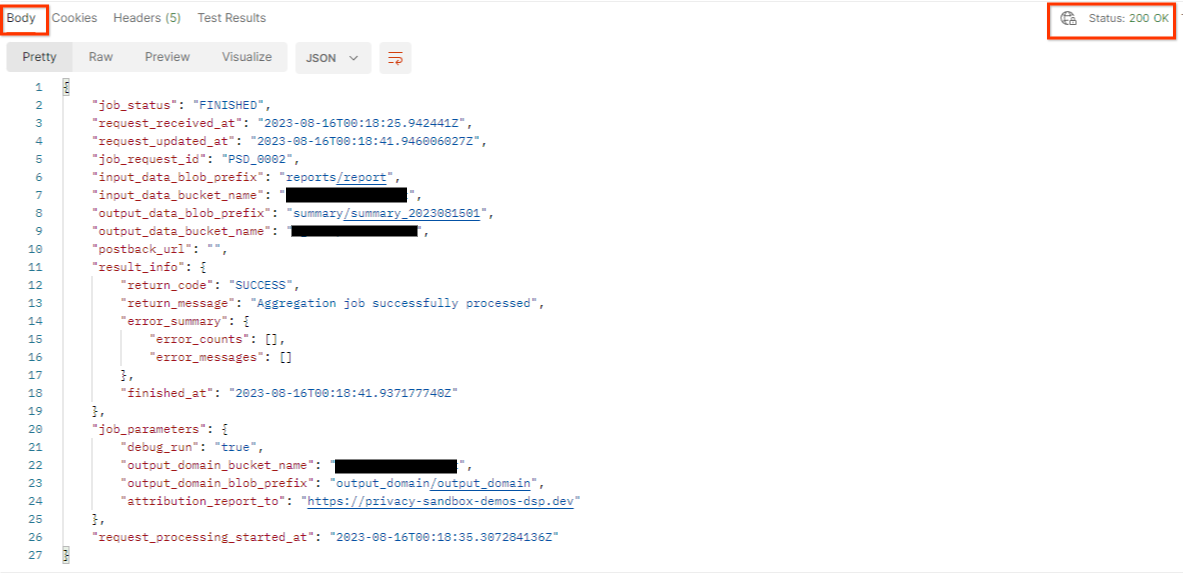
3.2.3 Meninjau Laporan Ringkasan
Setelah menerima laporan ringkasan di bucket Cloud Storage output, Anda dapat mendownloadnya ke lingkungan lokal. Laporan ringkasan dalam format AVRO dan dapat dikonversi kembali ke JSON. Anda dapat menggunakan aggregatable_report_converter.jar untuk membaca laporan menggunakan perintah di bawah.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
Tindakan ini akan menampilkan json nilai gabungan dari setiap kunci bucket yang terlihat mirip dengan yang di bawah ini.

Jika permintaan createJob Anda menyertakan debug_run sebagai benar (true), Anda dapat menerima laporan ringkasan di folder debug yang terletak di output_data_blob_prefix. Laporan ini dalam format AVRO dan dapat dikonversi menggunakan perintah di atas menjadi JSON.
Laporan berisi kunci bucket, metrik yang tidak memiliki derau, dan derau yang ditambahkan ke metrik yang tidak memiliki derau untuk membentuk laporan ringkasan. Laporannya serupa dengan di bawah ini.

Anotasi juga berisi "in_reports" dan/atau "in_domain" yang berarti:
- in_reports - kunci bucket tersedia di dalam laporan agregat.
- in_domain - kunci bucket tersedia di dalam file AVRO output_domain.
Codelab selesai!
Ringkasan: Anda telah men-deploy Layanan Agregasi di lingkungan cloud Anda sendiri, mengumpulkan laporan debug, membuat file domain output, menyimpan file tersebut di bucket Cloud Storage, dan menjalankan tugas yang berhasil.
Langkah berikutnya: Terus gunakan Layanan Agregasi di lingkungan Anda, atau hapus resource cloud yang baru saja dibuat dengan mengikuti petunjuk pembersihan di langkah 4.
4. 4. Membersihkan
Guna menghapus resource yang dibuat untuk Layanan Agregasi melalui Terraform, gunakan perintah penghancuran di folder adtech_setup dan dev (atau lingkungan lainnya):
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
Untuk menghapus bucket Cloud Storage yang menyimpan laporan agregat dan laporan ringkasan Anda:
$ gcloud storage buckets delete gs://my-bucket
Anda juga dapat memilih untuk mengembalikan setelan cookie Chrome Anda dari Prasyarat 1.2 ke kondisi sebelumnya.
5. 5. Lampiran
Contoh file adtech_setup.auto.tfvars
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
Contoh file dev.auto.tfvars
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20