
1. 1. Wymagania wstępne
Szacowany czas potrzebny na ukończenie samouczka: 1–2 godziny
Ćwiczenia z programowania można wykonywać w 2 trybach: Testowanie lokalne i Usługa agregacji. Tryb testowania lokalnego wymaga komputera lokalnego i przeglądarki Chrome (nie ma możliwości tworzenia ani wykorzystania zasobów Google Cloud). Tryb usługi agregacji wymaga pełnego wdrożenia usługi agregacji w Google Cloud.
Aby można było wykonać te ćwiczenia z programowania w dowolnym z tych trybów, wymagane jest kilka wymagań wstępnych. Każde wymaganie jest odpowiednio oznaczone, czy jest wymagane na potrzeby testów lokalnych czy usług agregacji.
1.1. Ukończ rejestrację i atest (usługa agregacji)
Aby korzystać z interfejsów API Piaskownicy prywatności, musisz przejść proces rejestracji i atestacji zarówno w Chrome, jak i na Androidzie.
1.2. Włącz interfejsy Ad Privacy API (usługa testów lokalnych i agregacji)
Ponieważ będziemy korzystać z Piaskownicy prywatności, zachęcamy do włączenia interfejsów API reklam w tej Piaskownicy.
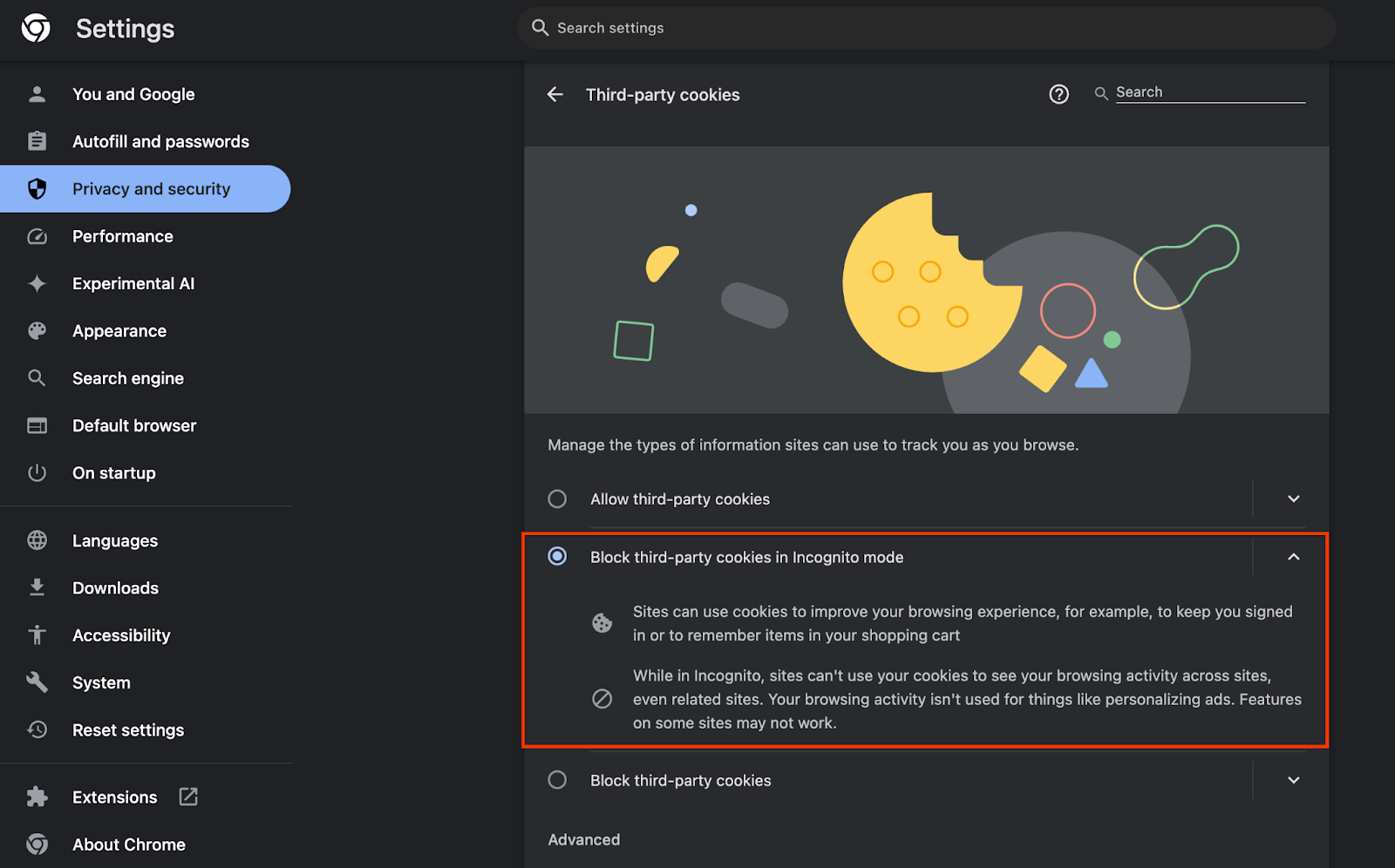
W przeglądarce otwórz stronę chrome://settings/adPrivacy i włącz wszystkie interfejsy Ad Privacy API.
Upewnij się też, że masz włączoną obsługę plików cookie innych firm.
Od chrome://settings/cookies sprawdź, czy pliki cookie innych firm NIE są blokowane. W zależności od wersji Chrome w tym menu ustawień mogą być widoczne różne opcje. Akceptowane konfiguracje są następujące:
- „Blokuj wszystkie pliki cookie innych firm” = WYŁĄCZONE
- „Blokuj pliki cookie innych firm” = WYŁĄCZONE
- „Blokuj pliki cookie innych firm w trybie incognito” = WŁĄCZONE
1.3. Pobieranie narzędzia do testowania lokalnego (testy lokalne)
Aby przeprowadzić testy lokalne, trzeba będzie pobrać narzędzie do testowania lokalnego. Narzędzie wygeneruje raporty podsumowujące na podstawie niezaszyfrowanych raportów debugowania.
Narzędzie do testowania lokalnego można pobrać z archiwów JAR funkcji w Cloud Functions na GitHubie. Powinna ona mieć nazwę LocalTestingTool_{version}.jar.
1.4 Sprawdź, czy zainstalowano JAVA JRE (usługa testowania lokalnego i agregacji)
Otwórz „Terminal” i użyj java --version, aby sprawdzić, czy na komputerze zainstalowano środowisko Java lub openJDK.

Jeśli nie, możesz ją pobrać i zainstalować ze strony Java lub openJDK.
1.5. Pobierz aggregatable_report_converter (lokalną usługę testowania i agregacji)
Możesz pobrać kopię pliku aggregatable_report_converter z repozytorium wersji demonstracyjnych Piaskownicy prywatności na GitHubie. W repozytorium GitHub jest mowa o używaniu IntelliJ lub Eclipse, ale żadne z nich nie jest wymagane. Jeśli nie używasz tych narzędzi, pobierz plik JAR do środowiska lokalnego.
1.6. Konfigurowanie środowiska GCP (usługa agregacji)
Usługa agregacji wymaga użycia zaufanego środowiska wykonawczego wykorzystującego dostawcę chmury. W ramach tego ćwiczenia w Codelabs usługa agregacji zostanie wdrożona w GCP, ale AWS jest też obsługiwany.
Wykonaj instrukcje wdrażania dostępne na GitHubie, aby skonfigurować interfejs wiersza poleceń gcloud, pobrać pliki binarne i moduły Terraform oraz utworzyć zasoby GCP na potrzeby usługi agregacji.
Najważniejsze kroki w instrukcjach wdrażania:
- Konfigurowanie „gcloud” interfejsu wiersza poleceń i Terraform w Twoim środowisku.
- Utwórz zasobnik Cloud Storage do przechowywania stanu Terraform.
- Pobierz zależności.
- Zaktualizuj
adtech_setup.auto.tfvarsi uruchom Terraformadtech_setup. Przykładowy plikadtech_setup.auto.tfvarsznajdziesz w załączniku. Zanotuj nazwę utworzonego tutaj zasobnika danych – będzie ona używana w ramach ćwiczeń z programowania do przechowywania utworzonych przez nas plików. - Zaktualizuj aplikację
dev.auto.tfvars, zastosuj się do konta usługi wdrażania i uruchom Terraform za pomocądev. Przykładowy plikdev.auto.tfvarsznajdziesz w załączniku. - Po zakończeniu wdrożenia przechwyć dane
frontend_service_cloudfunction_urlz danych wyjściowych Terraform, które będą potrzebne do wysyłania żądań do usługi agregacji w kolejnych krokach.
1.7. Pełne wprowadzenie usługi agregacji (usługa agregacji)
Usługa agregacji wymaga wprowadzenia koordynatorów, aby mogli z niej korzystać. Wypełnij formularz wprowadzenia do usługi agregacji, podając witrynę do raportowania i inne informacje, wybierając „Google Cloud” i wpisując adres konta usługi. To konto usługi jest tworzone w ramach poprzednich wymagań wstępnych (1.6. Skonfiguruj środowisko GCP). Wskazówka: jeśli użyjesz podanych domyślnych nazw, to konto usługi będzie zaczynać się od „worker-sa@”.
Proces wdrażania może potrwać do 2 tygodni.
1.8 Określ metodę wywoływania punktów końcowych interfejsu API (usługa agregacji)
To ćwiczenie w Codelabs udostępnia 2 opcje wywoływania punktów końcowych interfejsu Aggregation Service API: cURL i Postman. cURL to najszybszy i łatwiejszy sposób wywoływania punktów końcowych interfejsu API z poziomu terminala, ponieważ wymaga minimalnej konfiguracji i nie wymaga dodatkowego oprogramowania. Jeśli jednak nie chcesz używać cURL, możesz używać usługi Postman do wykonywania i zapisywania żądań do interfejsu API do wykorzystania w przyszłości.
W sekcji 3.2. Szczegółowe instrukcje dotyczące korzystania z obu tych opcji znajdziesz. Możesz teraz wyświetlić ich podgląd, aby określić, której metody użyjesz. Jeśli wybierzesz usługę Postman, przeprowadź poniższą konfigurację początkową.
1.8.1. Skonfiguruj obszar roboczy
Załóż konto Postman. Gdy się zarejestrujesz, automatycznie utworzymy dla Ciebie obszar roboczy.
Jeśli obszar roboczy nie został dla Ciebie utworzony, otwórz „Obszary robocze” górny element nawigacyjny i wybierz „Utwórz obszar roboczy”.
Wybierz „Pusty obszar roboczy”, kliknij Dalej i nadaj mu nazwę „Piaskownica prywatności GCP”. Wybierz „Osobiste”. i kliknij „Utwórz”.
Pobierz wstępnie skonfigurowaną konfigurację JSON i pliki środowiska globalnego dla obszaru roboczego.
Zaimportuj oba pliki JSON do „Mojego obszaru roboczego” za pomocą polecenia „Importuj”, Przycisk

Spowoduje to utworzenie „Piaskownicy prywatności w GCP” wraz z żądaniami HTTP createJob i getJob.
1.8.2. Autoryzacja konfiguracji
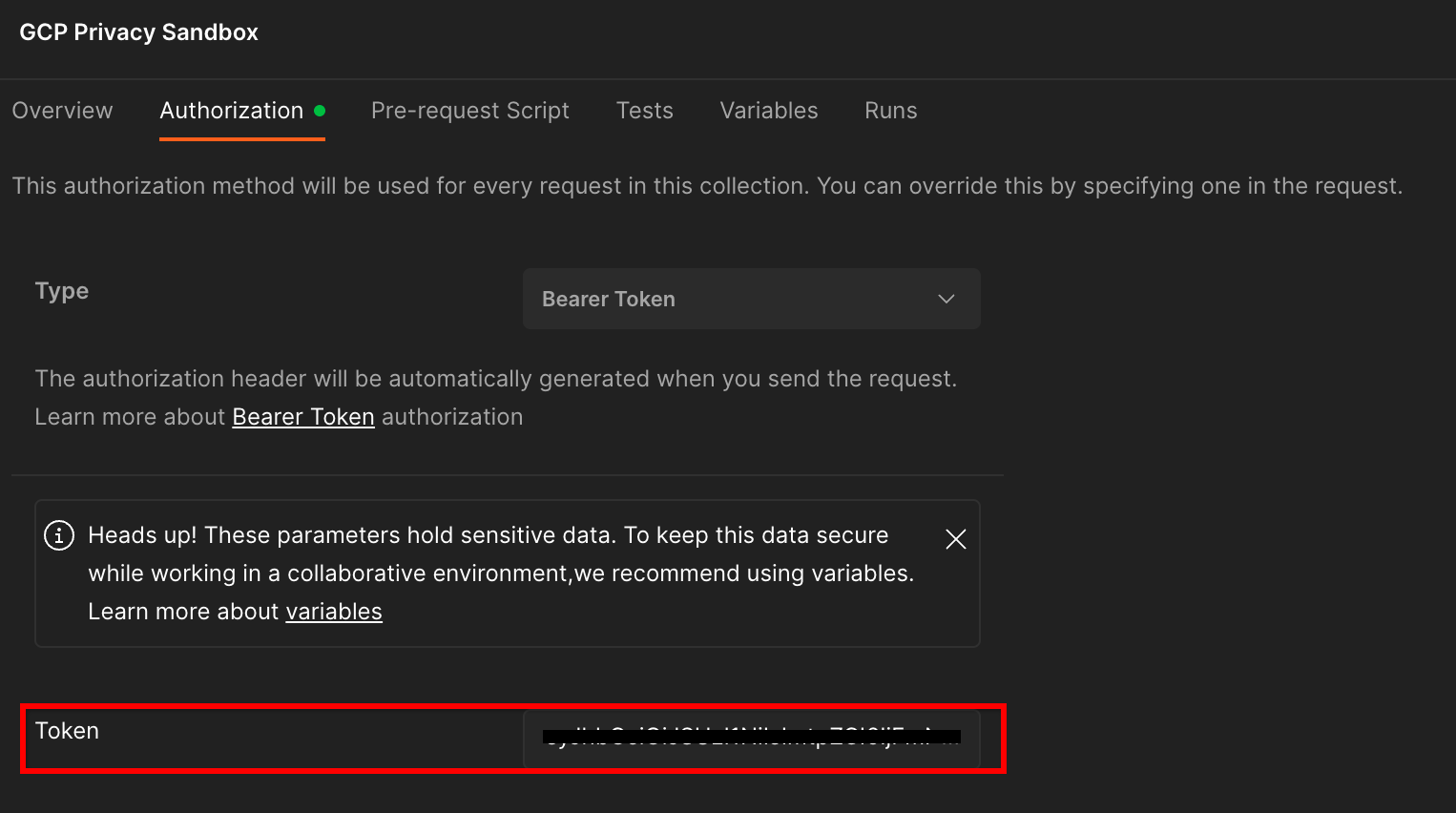
Kliknij „Piaskownica prywatności GCP”. i przejdź do sekcji „Autoryzacja” .

Musisz użyć „Tokenu okaziciela” . W środowisku terminala uruchom to polecenie i skopiuj dane wyjściowe.
gcloud auth print-identity-token
Następnie w polu „Token” wklej tę wartość. na karcie Autoryzacja Postman:
1.8.3. Skonfiguruj środowisko
Otwórz „Szybki podgląd środowiska” w prawym górnym rogu:
Kliknij „Edytuj”. i zaktualizować „Bieżącą wartość”, „Environment”, „region” i „cloud-function-id”:
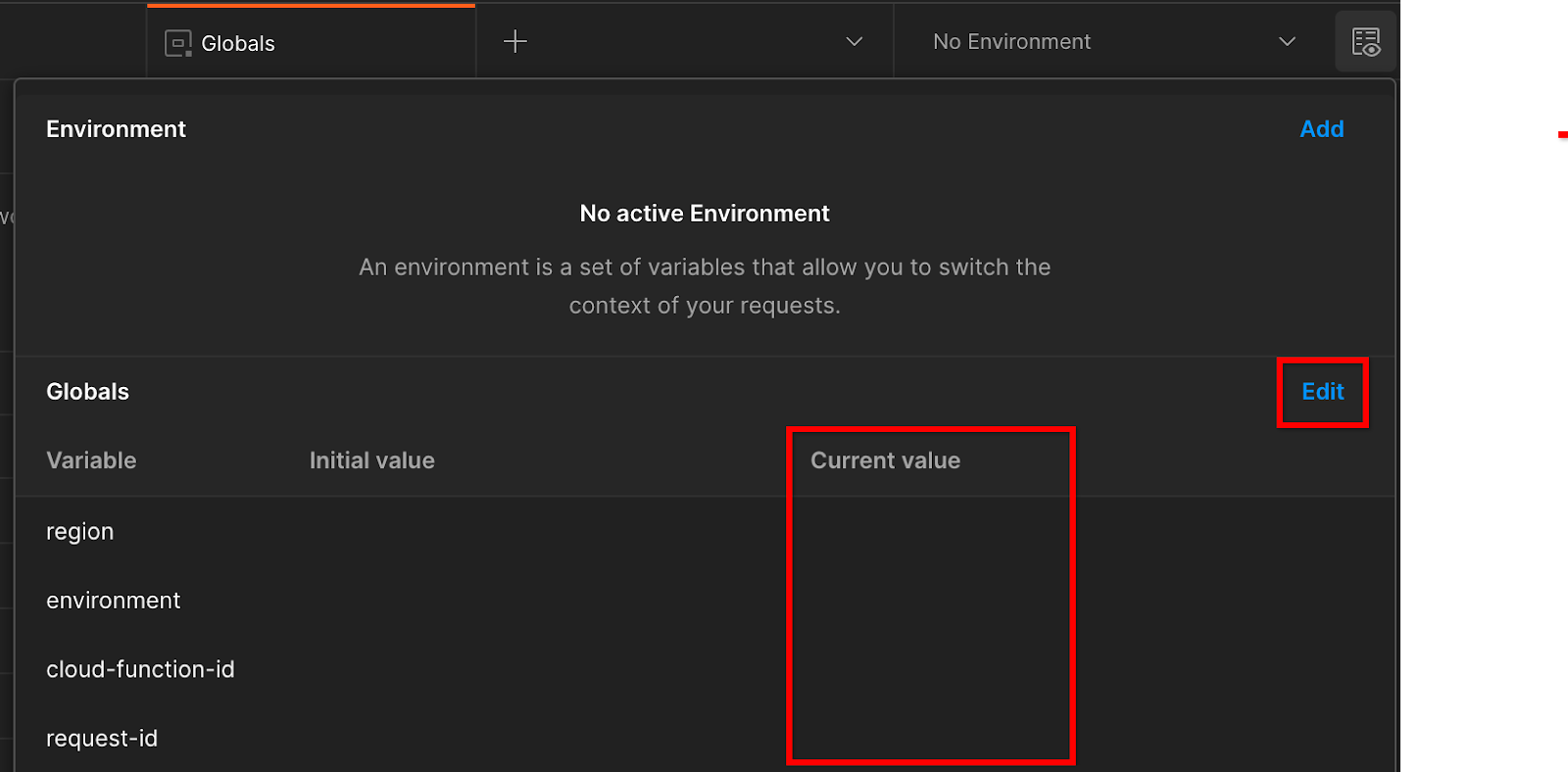
Możesz zostawić parametr „request-id”. puste, bo wypełnimy je później. W pozostałych polach użyj wartości z tabeli frontend_service_cloudfunction_url, która została zwrócona po pomyślnym ukończeniu wdrożenia Terraform w warunku wstępnym 1.6. Adres URL ma taki format: https://
2. 2. Ćwiczenie z programowania dotyczące testowania lokalnego
Szacowany czas potrzebny na ukończenie samouczka: poniżej 1 godziny
Za pomocą lokalnego narzędzia do testowania na komputerze możesz przeprowadzać agregacje i generować raporty podsumowujące na podstawie niezaszyfrowanych raportów debugowania. Zanim zaczniesz, sprawdź, czy spełniasz wszystkie wymagania wstępne oznaczone etykietą „Testowanie lokalne”.
Etapy ćwiczeń z programowania
Krok 2.1. Raport wyzwalacza: aktywuj raport prywatnej agregacji, aby móc zbierać ten raport.
Krok 2.2. Utwórz raport debugowania AVRO: przekonwertuj zebrany raport JSON na raport w formacie AVRO. Ten krok będzie podobny do sytuacji, gdy firmy adTech zbierają raporty z punktów końcowych raportowania interfejsu API i konwertują raporty JSON na raporty w formacie AVRO.
Krok 2.3. Pobieranie kluczy zasobnika: klucze zasobnika są projektowane przez zespół adTech. Ponieważ zasobniki są już wstępnie zdefiniowane, w ramach tego ćwiczenia w Codelabs możesz pobrać klucze zasobnika w podanej postaci.
Krok 2.4. Utwórz AVRO dla domeny wyjściowej: po pobraniu kluczy zasobnika utwórz plik AVRO domeny wyjściowej.
Krok 2.5. Utwórz raport zbiorczy: korzystając z narzędzia do testowania lokalnego, możesz tworzyć raporty podsumowujące w środowisku lokalnym.
Krok 2.6. Przejrzyj raporty podsumowujące: przejrzyj raport podsumowujący utworzony przez narzędzie do testowania lokalnego.
2.1. Raport wyzwalacza
Aby wygenerować prywatny raport zbiorczy, możesz skorzystać ze strony demonstracyjnej Piaskownicy prywatności (https://privacy-sandbox-demos-news.dev/?env=gcp) lub własnej witryny (np. https://adtechexample.com). Jeśli używasz własnej witryny i nie udało Ci się ukończyć rejestracji Wprowadzenie usługi atestu i agregacji, musisz użyć flagi Chrome i przełącznika interfejsu wiersza poleceń.
W tej prezentacji użyjemy witryny demonstracyjnej Piaskownicy prywatności. Kliknij link, aby otworzyć stronę. raporty będą dostępne na stronie chrome://private-aggregation-internals:
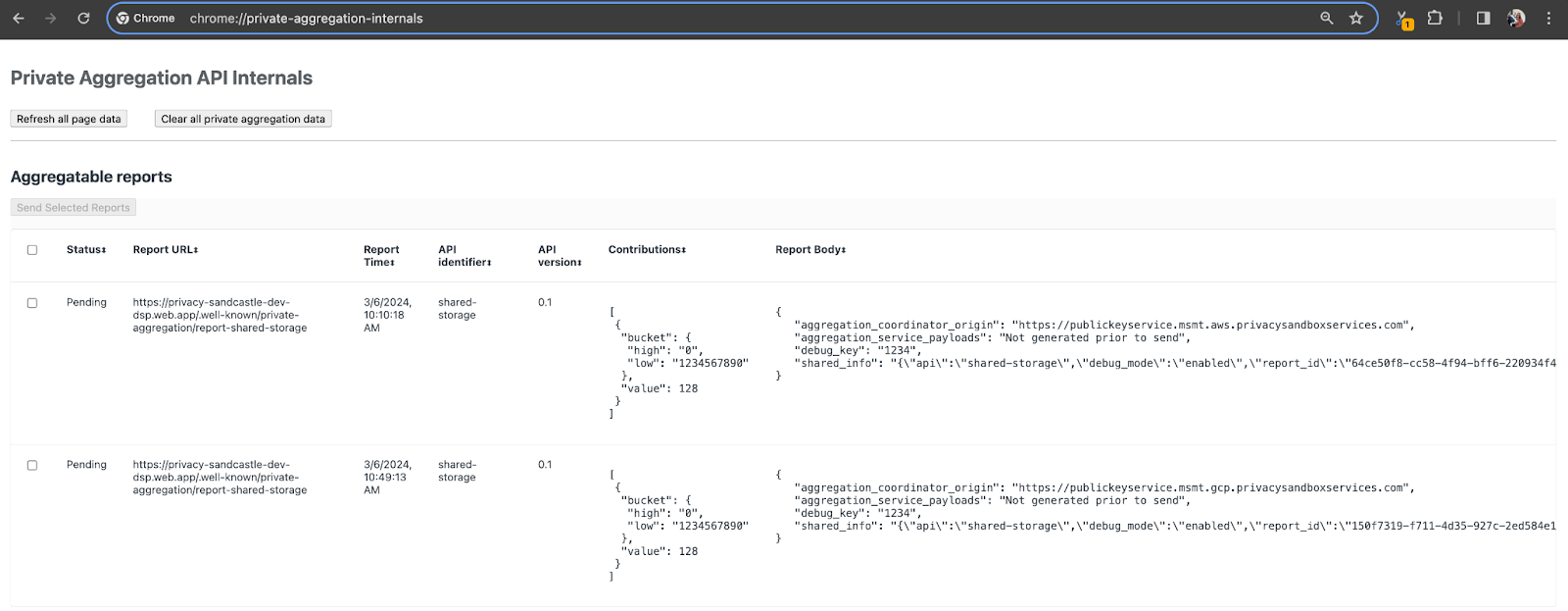
Raport wysyłany do punktu końcowego {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage znajduje się też w sekcji „Treść raportu” raportów wyświetlanych na stronie Wewnętrzne dane Chrome.
W tym miejscu możesz zobaczyć wiele raportów, ale w przypadku tego ćwiczenia z programowania użyj agregowanego raportu dotyczącego tylko GCP i wygenerowanego przez punkt końcowy debugowania. Pole „URL raportu” będzie zawierać „/debug/” oraz aggregation_coordinator_origin field w sekcji „Treść raportu” będzie zawierać ten adres URL: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
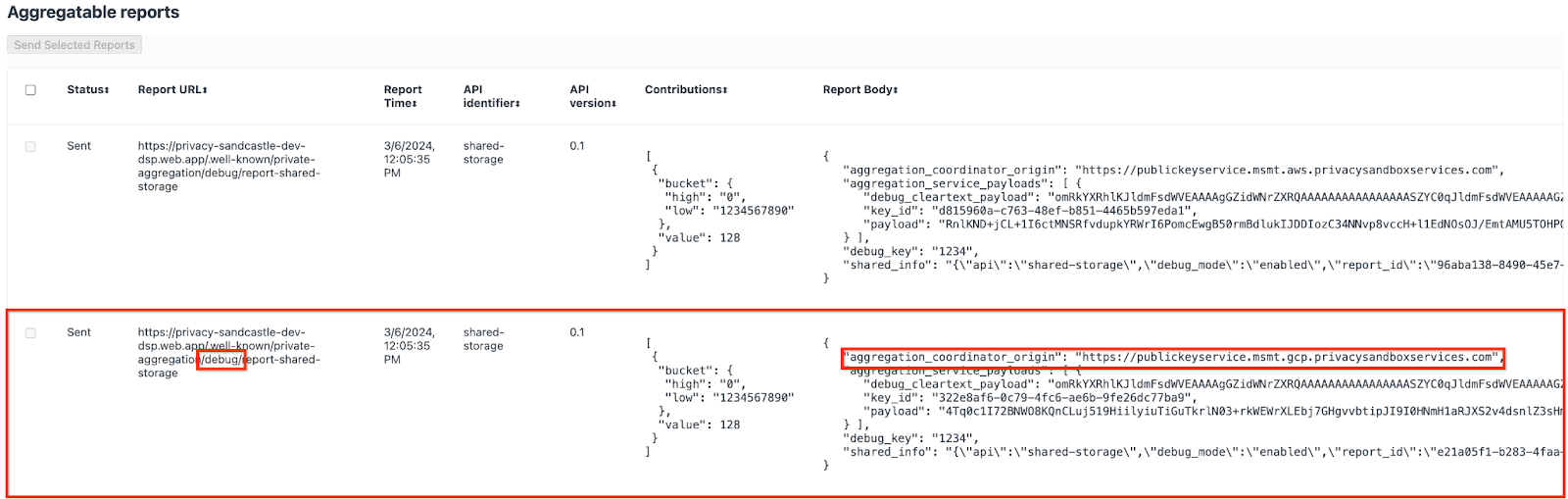
2.2. Utwórz raport możliwy do agregacji na potrzeby debugowania
Skopiuj raport widoczny w sekcji „Treść raportu” chrome://private-aggregation-internals i utwórz plik JSON w folderze privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar (w repozytorium pobranym w warunkach wstępnych 1.5).
W tym przykładzie korzystamy z vim, bo używamy Linuksa. Możesz jednak skorzystać z dowolnego edytora tekstu.
vim report.json
Wklej raport w usłudze report.json i zapisz plik.

Następnie użyj funkcji aggregatable_report_converter.jar, aby utworzyć raport agregujący na potrzeby debugowania. Spowoduje to utworzenie w bieżącym katalogu raportu agregowanego o nazwie report.avro.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Pobieranie klucza zasobnika z raportu
Aby utworzyć plik output_domain.avro, potrzebujesz kluczy zasobnika, które można pobrać z raportów.
Klucze zasobnika są zaprojektowane przez zespół adTech. W tym przypadku jednak klucze zasobnika tworzy strona Prezentacja Piaskownicy prywatności. Ponieważ agregacja prywatna dla tej witryny działa w trybie debugowania, możemy użyć pola debug_cleartext_payload z sekcji „Treść raportu” aby uzyskać klucz zasobnika.
Skopiuj identyfikator debug_cleartext_payload z treści raportu.

Otwórz goo.gle/ags-payload-decoder i wklej debug_cleartext_payload w polu „INPUT”. i kliknij „Dekoduj”.
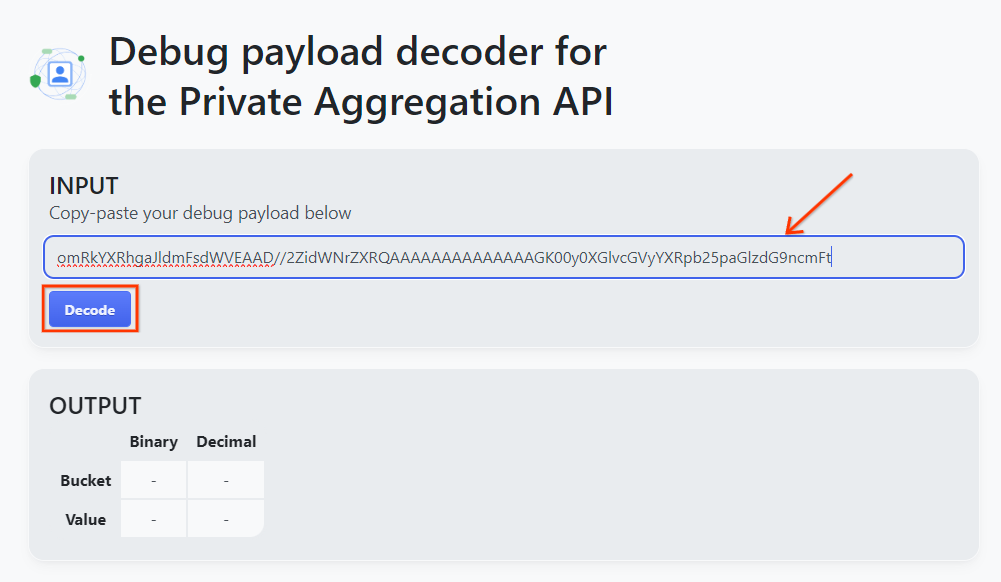
Strona zwraca wartość dziesiętną klucza zasobnika. Poniżej znajdziesz przykładowy klucz zasobnika.
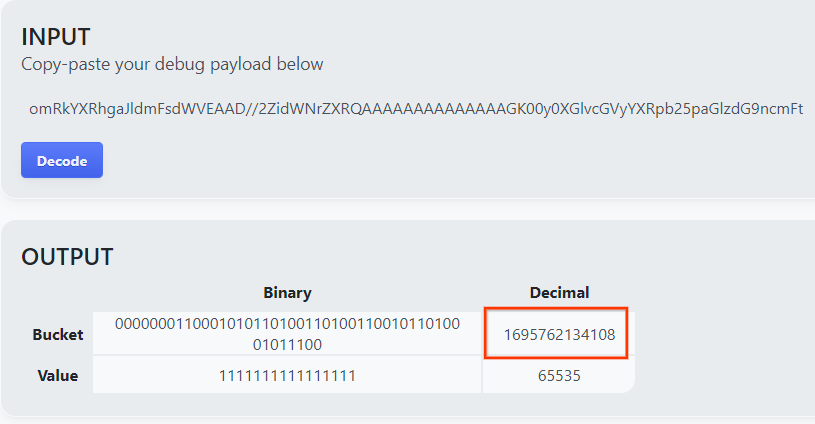
2.4. Utwórz AVRO domeny wyjściowej
Skoro mamy już klucz zasobnika, utwórzmy output_domain.avro w tym samym folderze, nad którym pracowaliśmy. Pamiętaj, aby zastąpić klucz zasobnika pobranym kluczem.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Skrypt utworzy plik output_domain.avro w bieżącym folderze.
2.5. Tworzenie raportów podsumowujących za pomocą narzędzia do testowania lokalnego
Użyjemy pliku LocalTestingTool_{version}.jar pobranego w warunkach wstępnych 1.3 do utworzenia raportów podsumowujących przy użyciu poniższego polecenia. Zastąp {version} pobraną wersją. Pamiętaj, aby przenieść plik LocalTestingTool_{version}.jar do bieżącego katalogu lub dodać ścieżkę względną, aby odwołać się do jego bieżącej lokalizacji.
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
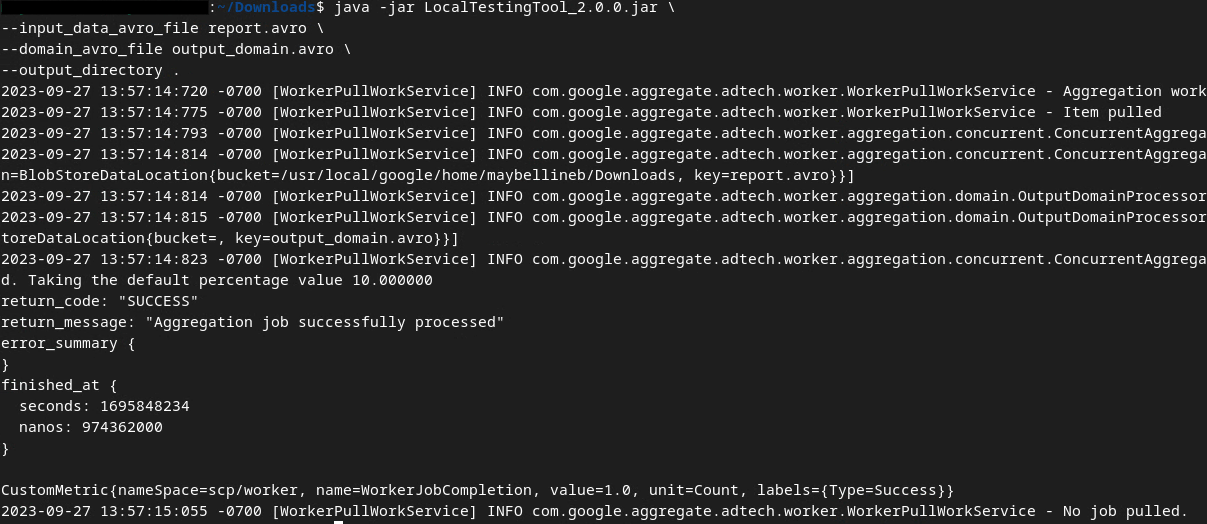
Po uruchomieniu polecenia zobaczysz wygląd podobny do tego poniżej. Po zakończeniu zostanie utworzony raport output.avro.
2.6 Sprawdzanie raportu podsumowującego
Tworzony raport podsumowujący ma format AVRO. Aby móc odczytać te dane, musisz przekonwertować je z AVRO na format JSON. Idealnie byłoby, gdyby firma adTech napisała kod konwertujący raporty AVRO z powrotem do formatu JSON.
Wykorzystamy aggregatable_report_converter.jar do przekonwertowania raportu AVRO z powrotem na JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
Spowoduje to zwrócenie raportu podobnego do tego poniżej. Wraz z raportem output.json utworzonym w tym samym katalogu.

Ćwiczenie z programowania ukończone.
Podsumowanie: udało Ci się zebrać raport debugowania, utworzyć plik wyjściowy domeny i wygenerować raport podsumowujący za pomocą lokalnego narzędzia do testowania, które symuluje działanie agregacji w usłudze agregacji.
Dalsze kroki: po przetestowaniu narzędzia do testowania lokalnego możesz wypróbować to samo ćwiczenie z aktywnym wdrożeniem usługi agregacji w swoim środowisku. Sprawdź wymagania wstępne, aby upewnić się, że wszystko jest skonfigurowane na potrzeby „usługi agregacji”. i przejdź do kroku 3.
3. 3. Ćwiczenie z programowania usługi agregacji
Szacowany czas potrzebny na ukończenie samouczka: 1 godzina
Zanim zaczniesz, sprawdź, czy spełniasz wszystkie wymagania wstępne oznaczone etykietą „Usługa agregacji”.
Etapy ćwiczeń z programowania
Krok 3.1. Tworzenie danych wejściowych w usłudze agregacji: służy do tworzenia raportów usługi agregacji, które są grupowane na potrzeby tej usługi.
- Krok 3.1.1 Raport wyzwalacza
- Krok 3.1.2 Zbieranie raportów agregowanych
- Krok 3.1.3 Konwertuj raporty na AVRO
- Krok 3.1.4 Utwórz AVRO dla domeny wyjściowej
- Krok 3.1.5 Przenoszenie raportów do zasobnika Cloud Storage
Krok 3.2. Wykorzystanie usługi agregacji: ten interfejs umożliwia tworzenie raportów podsumowujących i przeglądanie raportów podsumowujących za pomocą interfejsu Aggregation Service API.
- Krok 3.2.1 Wykorzystanie
createJobpunktu końcowego do grupowania - Krok 3.2.2 Używanie punktu końcowego
getJobdo pobierania stanu grupy - Krok 3.2.3 Przeglądanie raportu Podsumowanie
3.1. Utworzenie danych wejściowych usługi agregacji
Przejdź dalej do tworzenia raportów AVRO do grupowania w usłudze agregacji. Polecenia powłoki opisane w tych krokach możesz uruchomić w Cloud Shell GCP (o ile zależności z wymagań wstępnych zostaną sklonowane do środowiska Cloud Shell) lub w lokalnym środowisku wykonawczym.
3.1.1. Raport wyzwalacza
Kliknij link, aby otworzyć stronę. raporty będą dostępne na stronie chrome://private-aggregation-internals:
Raport wysyłany do punktu końcowego {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage znajduje się też w sekcji „Treść raportu” raportów wyświetlanych na stronie Wewnętrzne dane Chrome.
W tym miejscu możesz zobaczyć wiele raportów, ale w przypadku tego ćwiczenia z programowania użyj agregowanego raportu dotyczącego tylko GCP i wygenerowanego przez punkt końcowy debugowania. Pole „URL raportu” będzie zawierać „/debug/” oraz aggregation_coordinator_origin field w sekcji „Treść raportu” będzie zawierać ten adres URL: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
3.1.2. Zbieranie raportów agregowanych
Zbieraj raporty zbiorcze z punktów końcowych .well-known odpowiedniego interfejsu API.
- Agregacja prywatna:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - Raportowanie atrybucji – raport zbiorczy:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
W przypadku tych ćwiczeń w programie zbieranie raportów robimy ręcznie. Na etapie produkcji zespoły ds. technologii reklamowych muszą automatycznie zbierać i konwertować raporty.
Skopiujmy teraz raport JSON w sekcji „Treść raportu”. od chrome://private-aggregation-internals.
W tym przykładzie korzystamy z vim, bo używamy Linuksa. Możesz jednak skorzystać z dowolnego edytora tekstu.
vim report.json
Wklej raport w usłudze report.json i zapisz plik.
3.1.3. Konwertuj raporty na AVRO
Raporty otrzymywane z punktów końcowych .well-known mają format JSON i trzeba je przekonwertować na format raportu AVRO. Po wygenerowaniu raportu JSON przejdź do miejsca, w którym jest przechowywany plik report.json, i użyj adresu aggregatable_report_converter.jar, aby utworzyć raport agregujący na potrzeby debugowania. Spowoduje to utworzenie w bieżącym katalogu raportu agregowanego o nazwie report.avro.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. Utwórz AVRO dla domeny wyjściowej
Aby utworzyć plik output_domain.avro, potrzebujesz kluczy zasobnika, które można pobrać z raportów.
Klucze zasobnika są zaprojektowane przez zespół adTech. W tym przypadku jednak klucze zasobnika tworzy strona Prezentacja Piaskownicy prywatności. Ponieważ agregacja prywatna dla tej witryny działa w trybie debugowania, możemy użyć pola debug_cleartext_payload z sekcji „Treść raportu” aby uzyskać klucz zasobnika.
Skopiuj identyfikator debug_cleartext_payload z treści raportu.
Otwórz goo.gle/ags-payload-decoder i wklej debug_cleartext_payload w polu „INPUT”. i kliknij „Dekoduj”.
Strona zwraca wartość dziesiętną klucza zasobnika. Poniżej znajdziesz przykładowy klucz zasobnika.
Skoro mamy już klucz zasobnika, utwórzmy output_domain.avro w tym samym folderze, nad którym pracowaliśmy. Pamiętaj, aby zastąpić klucz zasobnika pobranym kluczem.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Skrypt utworzy plik output_domain.avro w bieżącym folderze.
3.1.5. Przenoszenie raportów do zasobnika Cloud Storage
Po utworzeniu raportów i domeny wyjściowej AVRO przenieś raporty i domenę wyjściową do zasobnika w Cloud Storage (zanotowano to w warunkach wstępnych 1.6).
Jeśli masz skonfigurowany interfejs wiersza poleceń gcloud w środowisku lokalnym, skopiuj pliki do odpowiednich folderów za pomocą poniższych poleceń.
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
W przeciwnym razie ręcznie prześlij pliki do zasobnika. Utwórz folder o nazwie „raporty”. i prześlij do niego plik report.avro. Utwórz folder o nazwie „output_domains” i prześlij do niego plik output_domain.avro.
3.2. Wykorzystanie usługi agregacji
Wywołaj w wymaganiu wstępnym 1.8 wybranie cURL lub Postman do wysyłania żądań do interfejsu API do punktów końcowych usługi agregacji. Poniżej zamieszczamy instrukcje dotyczące obu tych opcji.
Jeśli zadanie zakończy się niepowodzeniem z powodu błędu, zapoznaj się z dokumentacją rozwiązywania problemów w GitHubie, aby dowiedzieć się, co zrobić dalej.
3.2.1. Wykorzystanie createJob punktu końcowego do grupowania
Aby utworzyć zadanie, użyj podanych niżej instrukcji cURL lub Postman.
cURL
W „Terminalu” utwórz plik z treścią żądania (body.json) i wklej w nim poniższy kod. Pamiętaj o zaktualizowaniu wartości zmiennych. Więcej informacji o każdym polu znajdziesz w tej dokumentacji interfejsu API.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Wykonaj poniższe żądanie. Zastąp zmienne w adresie URL żądania cURL wartościami z tabeli frontend_service_cloudfunction_url, które są wyświetlane po pomyślnym zakończeniu wdrożenia Terraform w warunku wstępnym 1.6.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
Po zaakceptowaniu żądania przez usługę agregacji otrzymasz odpowiedź HTTP 202. Inne możliwe kody odpowiedzi są udokumentowane w specyfikacji interfejsu API.
Postman
W przypadku punktu końcowego createJob treść żądania jest wymagana, aby udostępnić usłudze agregacji lokalizacje i nazwy plików raportów agregowanych, domen wyjściowych oraz raportów podsumowujących.
Przejdź do sekcji „Treść” żądania createJob. :

Zastąp zmienne w podanym pliku JSON. Więcej informacji o tych polach i ich znaczeniu znajdziesz w dokumentacji interfejsu API.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
„Wyślij” żądanie do interfejsu API createJob:

Kod odpowiedzi znajdziesz w dolnej części strony:

Po zaakceptowaniu żądania przez usługę agregacji otrzymasz odpowiedź HTTP 202. Inne możliwe kody odpowiedzi są udokumentowane w specyfikacji interfejsu API.
3.2.2. Używanie punktu końcowego getJob do pobierania stanu grupy
Znajdź pracę, korzystając z poniższych instrukcji dotyczących cURL lub Postman.
cURL
Wykonaj poniższe żądanie w Terminalu. Zastąp zmienne w adresie URL wartościami z pola frontend_service_cloudfunction_url. Jest to ten sam adres URL, który został użyty w żądaniu createJob. W przypadku parametru „job_request_id” użyj wartości z zadania utworzonego z punktem końcowym createJob.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
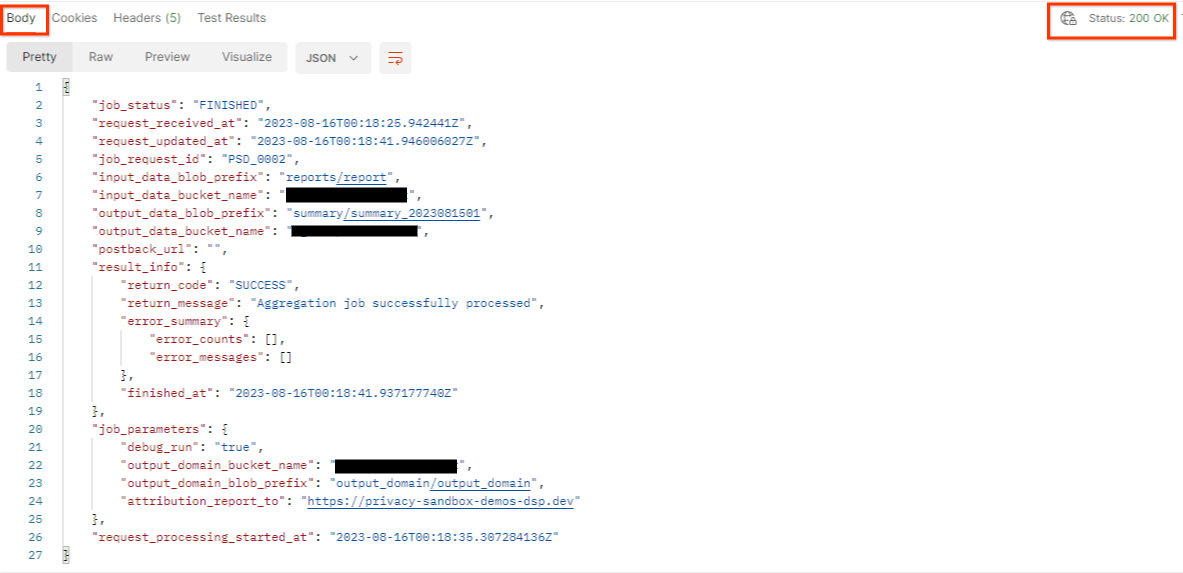
Wynik powinien zwrócić stan żądania zadania ze stanem HTTP 200. Żądanie „Treść” zawiera niezbędne informacje, takie jak job_status, return_message i error_messages (jeśli w zadaniu wystąpił błąd).
Postman
Aby sprawdzić stan żądania zadania, możesz użyć punktu końcowego getJob. W sekcji „Parametry” żądania getJob, zaktualizuj wartość job_request_id do job_request_id, która została wysłana w żądaniu createJob.
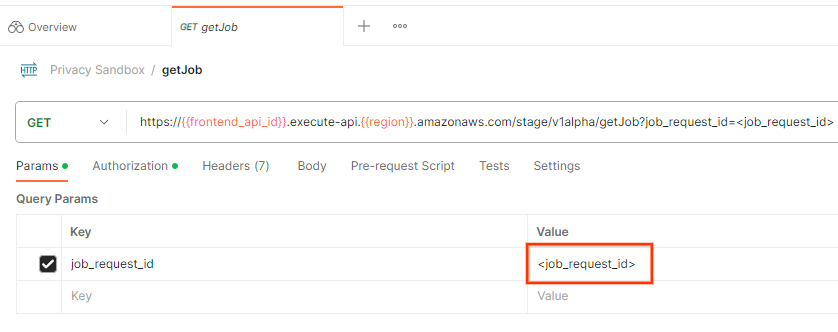
„Wyślij” żądanie getJob:

Wynik powinien zwrócić stan żądania zadania ze stanem HTTP 200. Żądanie „Treść” zawiera niezbędne informacje, takie jak job_status, return_message i error_messages (jeśli w zadaniu wystąpił błąd).
3.2.3 Przeglądanie raportu Podsumowanie
Gdy otrzymasz raport podsumowujący do wyjściowego zasobnika Cloud Storage, możesz go pobrać do środowiska lokalnego. Raporty podsumowujące są w formacie AVRO i można je przekonwertować z powrotem na plik JSON. Aby odczytać raport, użyj polecenia aggregatable_report_converter.jar, używając poniższego polecenia.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
Zwracany jest plik JSON zawierający wartości zagregowane każdego klucza zasobnika, podobne do pokazanego poniżej.

Jeśli żądanie createJob zawiera wartość debug_run jako true, raport podsumowania będzie dostępny w folderze debugowania, który znajduje się w folderze output_data_blob_prefix. Raport ma format AVRO i można go przekonwertować na format JSON za pomocą powyższego polecenia.
Raport zawiera klucz zasobnika, niezaszumione dane i szum dodany do niezaszumionych danych w celu utworzenia raportu podsumowującego. Raport jest podobny do tego poniżej.

Adnotacje zawierają też parametr „in_reports”. i/lub „in_domain” co oznacza, że:
- in_reports – klucz zasobnika jest dostępny w raportach agregowanych.
- in_domain – klucz zasobnika jest dostępny w pliku AVRO wyjściowej domeny.
Ćwiczenie z programowania ukończone.
Podsumowanie: udało Ci się wdrożyć usługę agregacji w swoim środowisku w chmurze, zebrać raport debugowania, utworzyć wyjściowy plik domeny, zapisać te pliki w zasobniku Cloud Storage i wykonać udane zadanie.
Dalsze kroki: kontynuuj korzystanie w swoim środowisku z usługi agregacji lub usuń utworzone zasoby w chmurze zgodnie z instrukcjami czyszczenia podanymi w kroku 4.
4. 4. Porządkowanie roszczeń
Aby usunąć za pomocą Terraform zasoby utworzone na potrzeby usługi agregacji, użyj polecenia zniszczenia w folderach adtech_setup i dev (lub innym środowisku):
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
Aby usunąć zasobnik Cloud Storage, w którym znajdują się raporty agregowane i raporty podsumowujące:
$ gcloud storage buckets delete gs://my-bucket
Możesz też przywrócić ustawienia plików cookie Chrome z wymagań wstępnych 1.2 do ich poprzedniego stanu.
5. 5. Dodatek
Przykładowy plik adtech_setup.auto.tfvars
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
Przykładowy plik dev.auto.tfvars
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20