
1. 1. Vorbereitung
Geschätzte Dauer: 1–2 Stunden
Es gibt zwei Modi für die Ausführung dieses Codelabs: Lokale Tests oder Aggregationsdienst. Für den Modus „Lokale Tests“ ist ein lokaler Computer und der Chrome-Browser erforderlich. Es werden keine Google Cloud-Ressourcen erstellt oder verwendet. Für den Aggregationsdienstmodus ist eine vollständige Bereitstellung des Aggregationsdienstes in Google Cloud erforderlich.
Für die Ausführung dieses Codelabs in einem der beiden Modi sind einige Voraussetzungen erforderlich. Jede Anforderung ist entsprechend gekennzeichnet, ob sie für lokale Tests oder den Aggregationsdienst erforderlich ist.
1.1. Registrierung und Attestierung abschließen (Aggregationsdienst)
Wenn Sie Privacy Sandbox APIs verwenden möchten, müssen Sie sowohl für Chrome als auch für Android die Registrierung und Attestierung durchlaufen.
1.2. APIs für den Datenschutz bei Werbung (lokaler Test- und Aggregationsdienst) aktivieren
Da wir die Privacy Sandbox verwenden werden, empfehlen wir Ihnen, die Privacy Sandbox-Werbe-APIs zu aktivieren.
Rufen Sie in Ihrem Browser chrome://settings/adPrivacy auf und aktivieren Sie alle APIs für den Datenschutz bei Werbung.
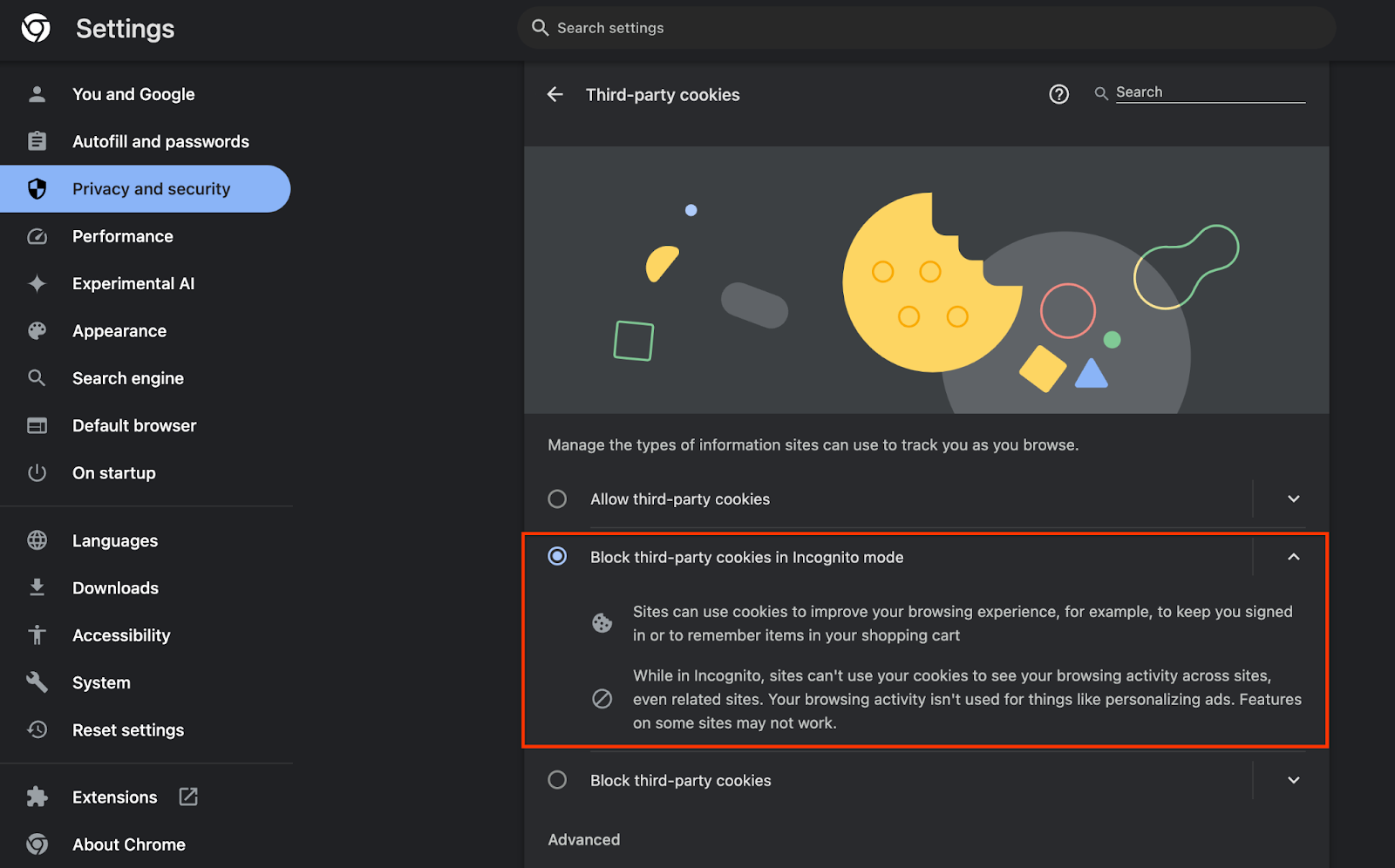
Außerdem müssen Drittanbieter-Cookies aktiviert sein.
Achten Sie darauf, dass Drittanbieter-Cookies unter chrome://settings/cookies NICHT blockiert werden. Je nach Chrome-Version werden in diesem Menü möglicherweise unterschiedliche Optionen angezeigt. Zu den zulässigen Konfigurationen gehören:
- „Alle Drittanbieter-Cookies blockieren“ = DEAKTIVIERT
- „Drittanbieter-Cookies blockieren“ = DEAKTIVIERT
- „Drittanbieter-Cookies im Inkognitomodus blockieren“ = AKTIVIERT
1.3. Lokales Testtool herunterladen (lokales Testen)
Für lokale Tests muss das Tool zum lokalen Testen heruntergeladen werden. Das Tool generiert Zusammenfassungsberichte aus den unverschlüsselten Debugberichten.
Das Tool für lokale Tests kann in den JAR-Archiven für Cloud Functions auf GitHub heruntergeladen werden. Er sollte LocalTestingTool_{version}.jar heißen.
1.4 Prüfen, ob JAVA JRE installiert ist (Local Testing and Aggregation Service)
Öffnen Sie das Terminal und prüfen Sie mit java --version, ob Java oder openJDK auf Ihrem Computer installiert ist.

Wenn es nicht installiert ist, können Sie es von der Java-Website oder der OpenJDK-Website herunterladen und installieren.
1.5 aggregatable_report_converter (lokaler Test- und Aggregationsdienst) herunterladen
Sie können eine Kopie des aggregatable_report_converter aus dem GitHub-Repository für Privacy Sandbox-Demos herunterladen. Im GitHub-Repository wird die Verwendung von IntelliJ oder Eclipse erwähnt, aber beides ist nicht erforderlich. Wenn Sie diese Tools nicht verwenden, laden Sie die JAR-Datei stattdessen in Ihre lokale Umgebung herunter.
1.6 GCP-Umgebung einrichten (Aggregationsdienst)
Für den Aggregationsdienst ist die Verwendung einer vertrauenswürdigen Ausführungsumgebung erforderlich, die einen Cloud-Anbieter nutzt. In diesem Codelab wird der Aggregations-Dienst in der GCP bereitgestellt, AWS wird aber auch unterstützt.
Folgen Sie der Bereitstellungsanleitung auf GitHub, um die gcloud CLI einzurichten, Terraform-Binärdateien und ‑Module herunterzuladen und GCP-Ressourcen für den Aggregationsdienst zu erstellen.
Wichtige Schritte in der Anleitung zur Bereitstellung:
- Richten Sie die gcloud CLI und Terraform in Ihrer Umgebung ein.
- Erstellen Sie einen Cloud Storage-Bucket, um den Terraform-Zustand zu speichern.
- Abhängigkeiten herunterladen
- Aktualisieren Sie
adtech_setup.auto.tfvarsund führen Sieadtech_setupTerraform aus. Im Anhang finden Sie eine Beispieldatei vom Typadtech_setup.auto.tfvars. Notieren Sie sich den Namen des hier erstellten Daten-Buckets. Er wird im Codelab zum Speichern der erstellten Dateien verwendet. - Aktualisieren Sie
dev.auto.tfvars, übernehmen Sie die Identität des Bereitstellungs-Dienstkontos und führen SiedevTerraform aus. Im Anhang finden Sie eine Beispieldatei vom Typdev.auto.tfvars. - Nachdem die Bereitstellung abgeschlossen ist, erfassen Sie die
frontend_service_cloudfunction_urlaus der Terraform-Ausgabe. Diese ist für Anfragen an den Aggregationsdienst in späteren Schritten erforderlich.
1.7. Onboarding des Aggregationsdienstes abschließen (Aggregationsdienst)
Der Aggregationsdienst erfordert ein Onboarding durch Koordinatoren, damit er verwendet werden kann. Füllen Sie das Onboarding-Formular für den Aggregationsdienst aus. Geben Sie dazu Ihre Website für die Berichterstellung und weitere Informationen an, wählen Sie „Google Cloud“ aus und geben Sie die Adresse Ihres Dienstkontos ein. Dieses Dienstkonto wird in der vorherigen Voraussetzung (1.6. GCP-Umgebung einrichten). Hinweis: Wenn Sie die angegebenen Standardnamen verwenden, beginnt dieses Dienstkonto mit „worker-sa@“.
Die Einrichtung kann bis zu zwei Wochen dauern.
1.8. Methode zum Aufrufen der API-Endpunkte festlegen (Aggregationsservice)
In diesem Codelab werden zwei Optionen zum Aufrufen der API-Endpunkte des Aggregationsdiensts vorgestellt: cURL und Postman. cURL ist die schnellere und einfachere Möglichkeit, die API-Endpunkte über Ihr Terminal aufzurufen, da nur eine minimale Einrichtung und keine zusätzliche Software erforderlich sind. Wenn Sie cURL jedoch nicht verwenden möchten, können Sie stattdessen Postman verwenden, um API-Anfragen auszuführen und für die spätere Verwendung zu speichern.
In Abschnitt 3.2. Aggregation Service Usage finden Sie eine detaillierte Anleitung zur Verwendung beider Optionen. Sie können sich jetzt eine Vorschau ansehen, um zu entscheiden, welche Methode Sie verwenden möchten. Wenn Sie Postman auswählen, führen Sie die folgende Ersteinrichtung aus.
1.8.1. Arbeitsbereich einrichten
Registrieren Sie sich für ein Postman-Konto. Nach der Registrierung wird automatisch ein Arbeitsbereich für Sie erstellt.
Wenn kein Arbeitsbereich für Sie erstellt wird, klicken Sie oben auf „Workspaces“ und wählen Sie „Workspace erstellen“ aus.
Wählen Sie „Leere Arbeitsfläche“ aus, klicken Sie auf „Weiter“ und geben Sie den Namen „GCP Privacy Sandbox“ ein. Wählen Sie „Persönlich“ aus und klicken Sie auf „Erstellen“.
Laden Sie die JSON-Konfiguration und die Dateien der globalen Umgebung für den vorab konfigurierten Arbeitsbereich herunter.
Importieren Sie beide JSON-Dateien über die Schaltfläche „Importieren“ in „Mein Workspace“.

Dadurch werden die Sammlung „GCP Privacy Sandbox“ sowie die HTTP-Anfragen createJob und getJob für Sie erstellt.
1.8.2. Autorisierung einrichten
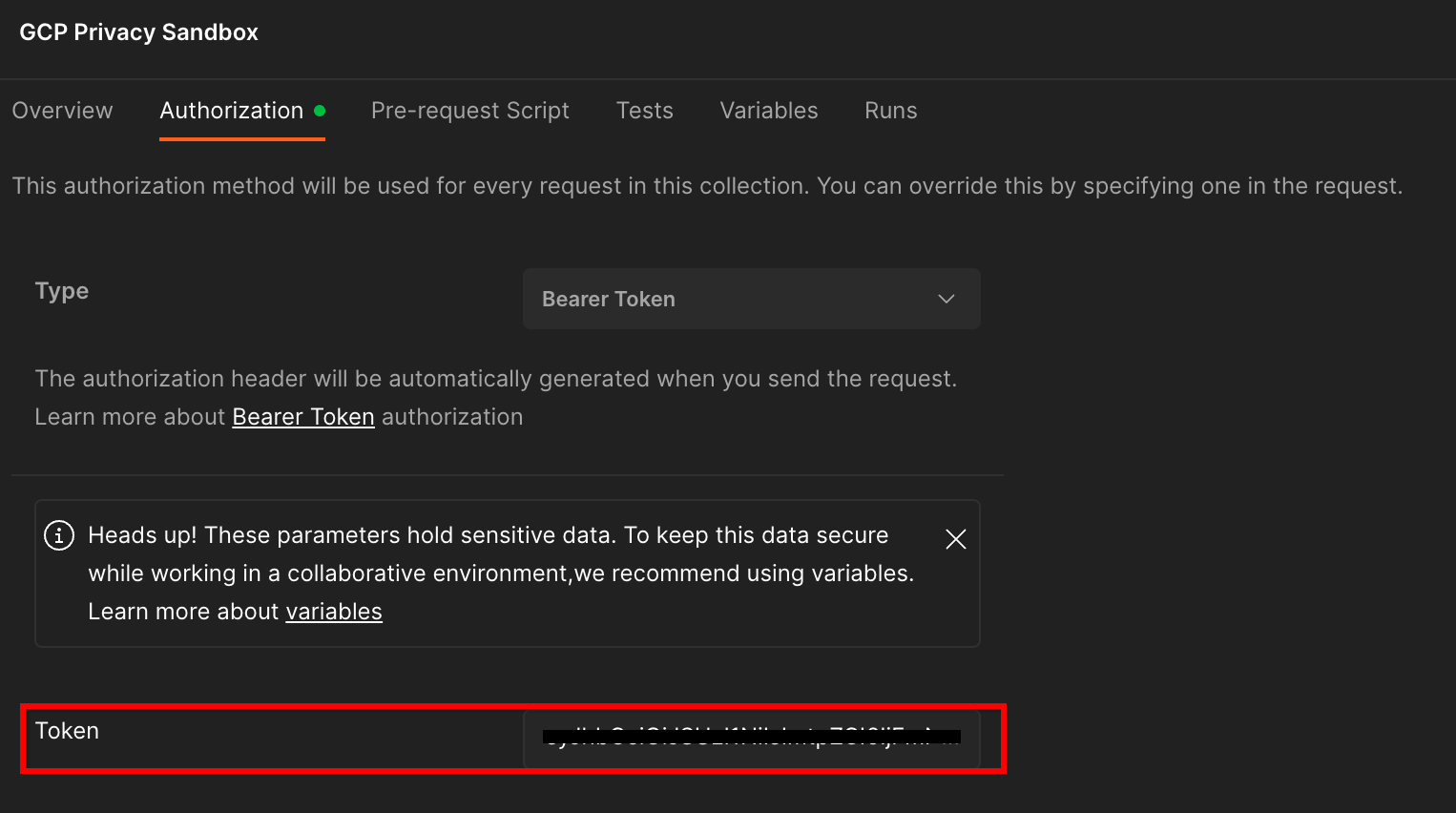
Klicken Sie auf die Sammlung „GCP Privacy Sandbox“ und gehen Sie zum Tab „Autorisierung“.

Sie verwenden die Methode „Bearer-Token“. Führen Sie diesen Befehl in Ihrer Terminalumgebung aus und kopieren Sie die Ausgabe.
gcloud auth print-identity-token
Fügen Sie diesen Tokenwert dann in das Feld „Token“ auf dem Postman-Tab „Autorisierung“ ein:
1.8.3. Umgebung einrichten
Rufen Sie oben rechts die „Umgebung – Schnellinfo“ auf:
Klicken Sie auf „Bearbeiten“ und aktualisieren Sie den „Aktuellen Wert“ für „environment“, „region“ und „cloud-function-id“:
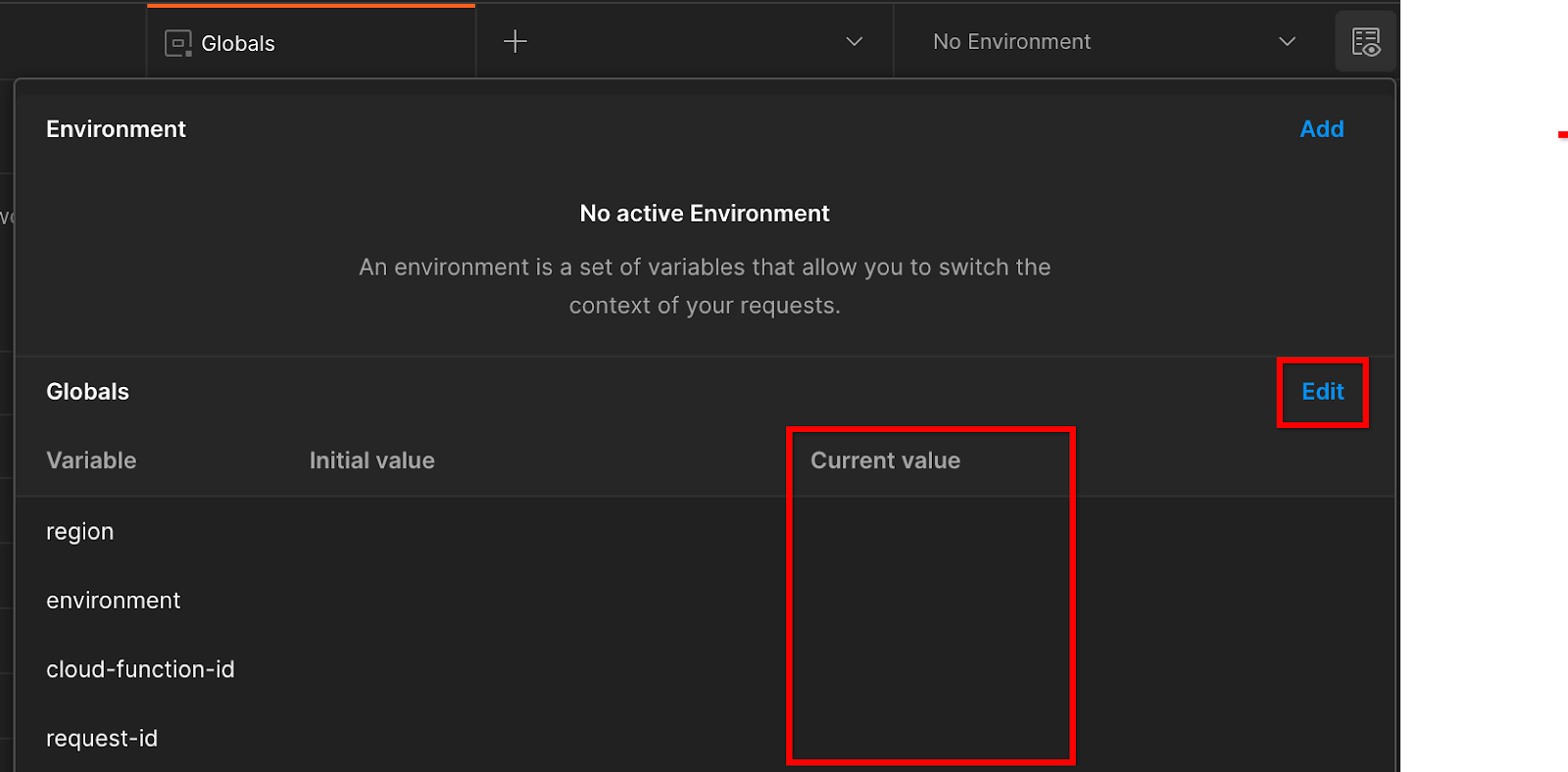
Sie können „request-id“ vorerst leer lassen, da wir sie später ausfüllen. Verwenden Sie für die anderen Felder die Werte aus frontend_service_cloudfunction_url, die nach dem erfolgreichen Abschluss der Terraform-Bereitstellung in Voraussetzung 1.6 zurückgegeben wurden. Die URL hat folgendes Format: https://
2. 2. Codelab zum lokalen Testen
Geschätzte Dauer: < 1 Stunde
Sie können das lokale Testtool auf Ihrem Computer verwenden, um die Aggregation durchzuführen und Zusammenfassungsberichte mithilfe der unverschlüsselten Debugberichte zu erstellen. Vorab: Prüfen Sie, ob Sie alle Voraussetzungen erfüllt haben, die mit „Lokale Tests“ gekennzeichnet sind.
Codelab-Schritte
Schritt 2.1: Bericht auslösen: Sie können Berichte zur privaten Aggregation auslösen, um sie abrufen zu können.
Schritt 2.2: Debug-AVRO-Bericht erstellen: Der erfasste JSON-Bericht wird in einen Bericht im AVRO-Format konvertiert. Dieser Schritt ähnelt dem, wenn Anbieter von Anzeigentechnologien die Berichte von den API-Berichtsendpunkten abrufen und die JSON-Berichte in Berichte im AVRO-Format konvertieren.
Schritt 2.3: Bucket-Schlüssel abrufen: Bucket-Schlüssel werden von AdTechs erstellt. Da die Bucket in diesem Codelab vordefiniert sind, rufen Sie die Bucket-Schlüssel wie angegeben ab.
Schritt 2.4: „Create Output Domain AVRO“ (AVRO-Datei für Ausgabedomain erstellen): Nachdem die Bucketschlüssel abgerufen wurden, erstellen Sie die AVRO-Datei für die Ausgabedomain.
Schritt 2.5: Zusammenfassungsbericht erstellen: Mit dem Tool für lokale Tests können Sie Zusammenfassungsberichte in der lokalen Umgebung erstellen.
Schritt 2.6: Zusammenfassungsberichte prüfen: Sehen Sie sich den Zusammenfassungsbericht an, der vom Tool für lokale Tests erstellt wird.
2.1. Triggerbericht
Sie können einen Bericht zur privaten Aggregation über die Privacy Sandbox-Demoseite (https://privacy-sandbox-demos-news.dev/?env=gcp) oder über Ihre eigene Website (z.B. https://adtechbeispiel.de) auslösen. Wenn Sie Ihre eigene Website verwenden und die Registrierung und Attestierung sowie das Onboarding des Aggregationsdiensts noch nicht abgeschlossen haben, müssen Sie ein Chrome-Flag und einen Befehlszeilenschalter verwenden.
Für diese Demo verwenden wir die Privacy Sandbox-Demowebsite. Klicken Sie auf den Link, um die Website aufzurufen. Die Berichte finden Sie dann unter chrome://private-aggregation-internals:
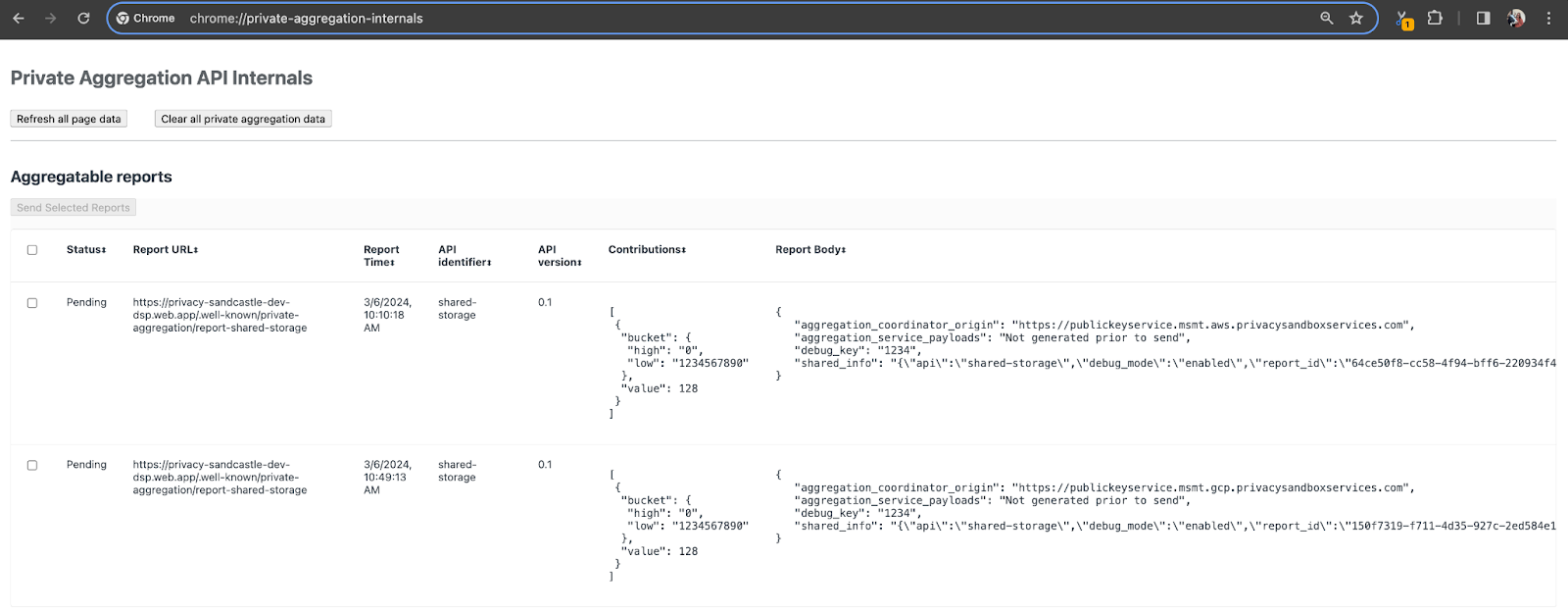
Der Bericht, der an den {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage-Endpunkt gesendet wird, ist auch im „Berichtskörper“ der Berichte zu finden, die auf der Seite „Chrome Internals“ angezeigt werden.
Möglicherweise sehen Sie hier viele Berichte. Verwenden Sie für dieses Codelab jedoch den aggregierbaren Bericht, der GCP-spezifisch ist und vom Debug-Endpunkt generiert wird. Die „Berichts-URL“ enthält „/debug/“ und die aggregation_coordinator_origin field des „Berichtskörpers“ enthält diese URL: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
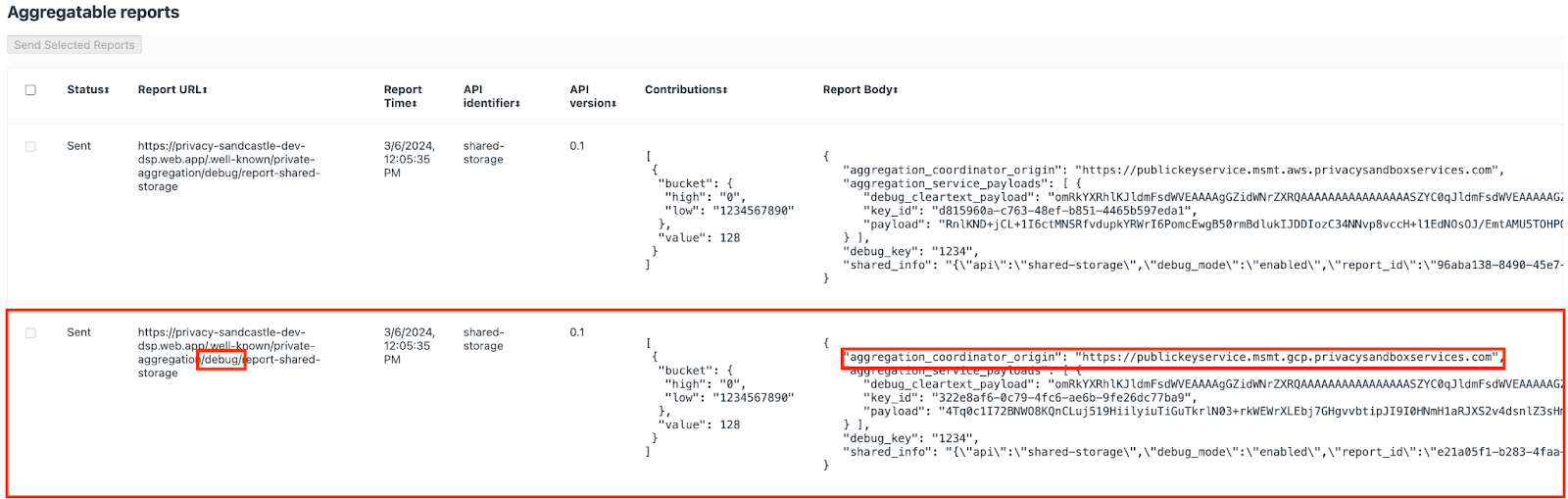
2.2. Aggregierbaren Bericht zur Fehlerbehebung erstellen
Kopieren Sie den Bericht im „Report Body“ von chrome://private-aggregation-internals und erstellen Sie eine JSON-Datei im Ordner privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar (im in Vorraussetzung 1.5 heruntergeladenen Repository).
In diesem Beispiel verwenden wir vim, da wir Linux verwenden. Sie können aber auch einen beliebigen anderen Texteditor verwenden.
vim report.json
Fügen Sie den Bericht in report.json ein und speichern Sie die Datei.

Verwenden Sie dann aggregatable_report_converter.jar, um den Bericht zu erstellen, der für die Fehlerbehebung aggregiert werden kann. Dadurch wird im aktuellen Verzeichnis ein aggregierbarer Bericht mit dem Namen report.avro erstellt.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Bucket-Schlüssel aus dem Bericht abrufen
Zum Erstellen der Datei output_domain.avro benötigen Sie die Bucket-Schlüssel, die aus den Berichten abgerufen werden können.
Bucket-Schlüssel werden von der AdTech-Plattform erstellt. In diesem Fall werden die Bucket-Schlüssel jedoch von der Website Privacy Sandbox Demo erstellt. Da die private Aggregation für diese Website im Debug-Modus ist, können wir den Bucket-Schlüssel mithilfe des debug_cleartext_payload aus dem „Berichtskörper“ abrufen.
Kopieren Sie die debug_cleartext_payload aus dem Berichtstext.

Öffnen Sie goo.gle/ags-payload-decoder, fügen Sie Ihre debug_cleartext_payload in das Feld „INPUT“ ein und klicken Sie auf „Decode“.
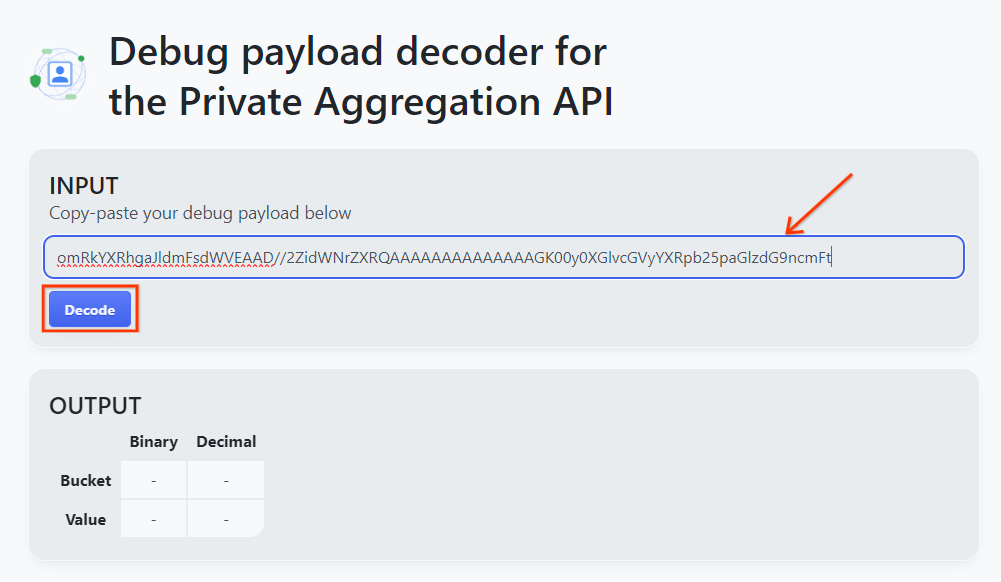
Die Seite gibt den Dezimalwert des Bucket-Schlüssels zurück. Unten sehen Sie ein Beispiel für einen Bucket-Schlüssel.
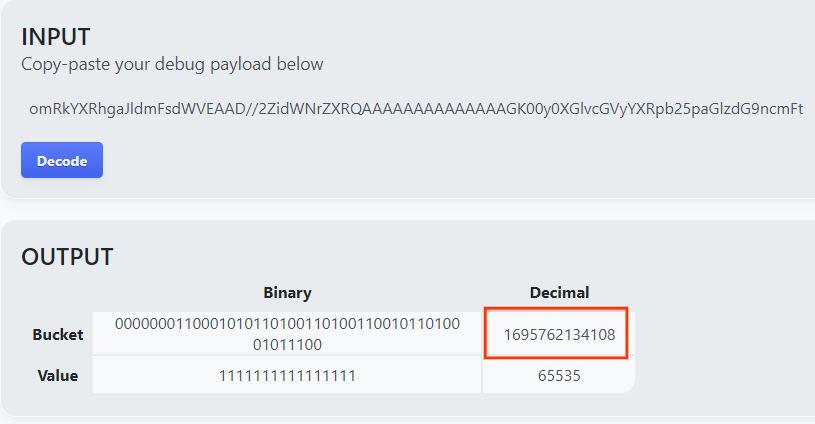
2.4 Ausgabedomain „AVRO“ erstellen
Nachdem wir den Bucket-Schlüssel haben, erstellen wir die output_domain.avro im selben Ordner, in dem wir gearbeitet haben. Ersetzen Sie „bucket_key“ durch den Bucket-Schlüssel, den Sie abgerufen haben.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Das Script erstellt die output_domain.avro-Datei im aktuellen Ordner.
2.5 Zusammenfassungsberichte mit dem Tool für lokale Tests erstellen
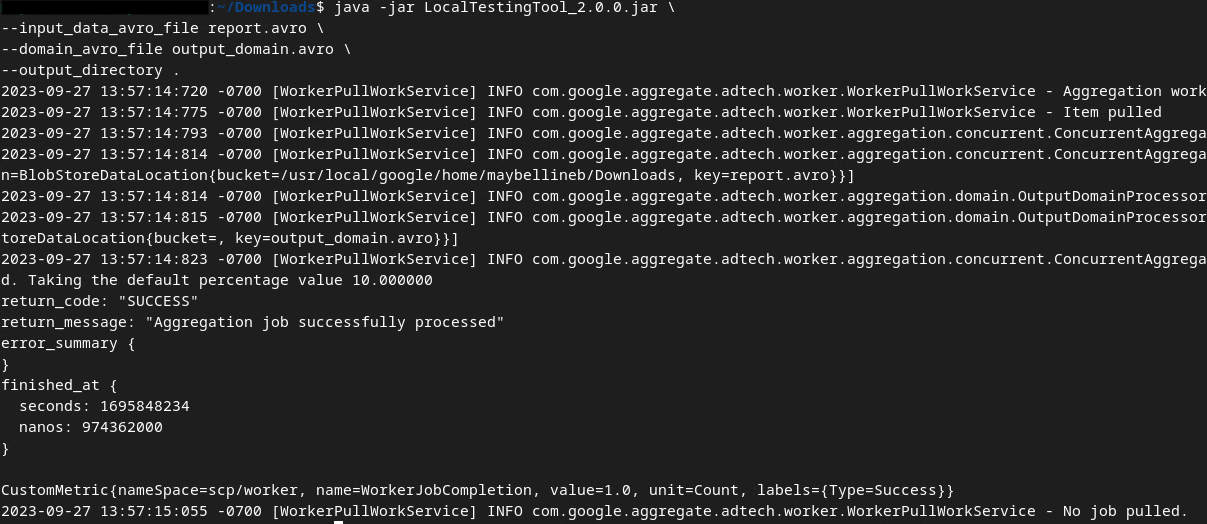
Wir verwenden LocalTestingTool_{version}.jar, das in Vorraussetzung 1.3 heruntergeladen wurde, um mit dem folgenden Befehl die Zusammenfassungsberichte zu erstellen. Ersetzen Sie {version} durch die heruntergeladene Version. Vergessen Sie nicht, LocalTestingTool_{version}.jar in das aktuelle Verzeichnis zu verschieben oder einen relativen Pfad hinzuzufügen, der auf den aktuellen Speicherort verweist.
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
Nach der Ausführung des Befehls sollte eine Ausgabe ähnlich der folgenden angezeigt werden. Danach wird ein Bericht output.avro erstellt.
2.6. Zusammenfassungsbericht ansehen
Der erstellte Zusammenfassungsbericht ist im AVRO-Format. Damit Sie sie lesen können, müssen Sie sie von AVRO in ein JSON-Format konvertieren. Idealerweise sollte die Anzeigentechnologie Code schreiben, um AVRO-Berichte wieder in JSON umzuwandeln.
Wir verwenden aggregatable_report_converter.jar, um den AVRO-Bericht wieder in JSON umzuwandeln.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
Dies gibt einen Bericht zurück, der in etwa so aussieht: und eine Berichtsdatei output.json, die im selben Verzeichnis erstellt wurde.

Codelab abgeschlossen
Zusammenfassung:Sie haben einen Debugbericht erfasst, eine Ausgabedomaindatei erstellt und mit dem lokalen Testtool einen Zusammenfassungsbericht generiert, der das Aggregationsverhalten des Aggregationsdiensts simuliert.
Nächste Schritte:Nachdem Sie das Tool für lokale Tests ausprobiert haben, können Sie dieselbe Übung mit einer Live-Bereitstellung des Aggregationsdienstes in Ihrer eigenen Umgebung wiederholen. Sehen Sie sich die Voraussetzungen noch einmal an, um sicherzugehen, dass Sie alles für den Modus „Aggregation Service“ eingerichtet haben, und fahren Sie dann mit Schritt 3 fort.
3. 3. Codelab zum Aggregationsdienst
Geschätzte Dauer: 1 Stunde
Vorab: Prüfen Sie, ob Sie alle Voraussetzungen erfüllt haben, die mit „Aggregation Service“ gekennzeichnet sind.
Codelab-Schritte
Schritt 3.1: Eingabe für Aggregationsdienst erstellen: Erstellen Sie die Berichte für den Aggregationsdienst, die für den Aggregationsdienst in Batches zusammengefasst werden.
- Schritt 3.1.1 Triggerbericht
- Schritt 3.1.2 Zusammenfassbare Berichte erheben
- Schritt 3.1.3 Berichte in AVRO konvertieren
- Schritt 3.1.4 output_domain AVRO erstellen
- Schritt 3.1.5 Berichte in einen Cloud Storage-Bucket verschieben
Schritt 3.2: Nutzung des Aggregationsdiensts: Mit der Aggregation Service API können Sie Zusammenfassungsberichte erstellen und prüfen.
- Schritt 3.2.1
createJob-Endpunkt für Batches verwenden - Schritt 3.2.2 Batchstatus über den
getJob-Endpunkt abrufen - Schritt 3.2.3 Zusammenfassungsbericht prüfen
3.1. Eingabe für Aggregationsdienst erstellen
Erstellen Sie die AVRO-Berichte für die Batchverarbeitung im Aggregationsdienst. Die Shell-Befehle in diesen Schritten können in der Cloud Shell von GCP ausgeführt werden, sofern die Abhängigkeiten aus den Voraussetzungen in Ihre Cloud Shell-Umgebung geklont wurden, oder in einer lokalen Ausführungsumgebung.
3.1.1. Triggerbericht
Klicken Sie auf den Link, um die Website aufzurufen. Die Berichte finden Sie dann unter chrome://private-aggregation-internals:
Der Bericht, der an den {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage-Endpunkt gesendet wird, ist auch im „Berichtskörper“ der Berichte zu finden, die auf der Seite „Chrome Internals“ angezeigt werden.
Möglicherweise sehen Sie hier viele Berichte. Verwenden Sie für dieses Codelab jedoch den aggregierbaren Bericht, der GCP-spezifisch ist und vom Debug-Endpunkt generiert wird. Die „Berichts-URL“ enthält „/debug/“ und die aggregation_coordinator_origin field des „Berichtskörpers“ enthält diese URL: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
3.1.2. Zusammenfassbare Berichte erheben
Erfassen Sie Ihre aggregierbaren Berichte über die .well-known-Endpunkte Ihrer entsprechenden API.
- Private Aggregation:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - Attributionsberichte – Zusammenfassungsbericht:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
In diesem Codelab führen wir die Berichterstellung manuell durch. In der Produktionsumgebung sollten die Berichte programmatisch erfasst und konvertiert werden.
Kopieren Sie den JSON-Bericht im „Berichtskörper“ von chrome://private-aggregation-internals.
In diesem Beispiel verwenden wir vim, da wir Linux verwenden. Sie können aber auch einen beliebigen anderen Texteditor verwenden.
vim report.json
Fügen Sie den Bericht in report.json ein und speichern Sie die Datei.
3.1.3. Berichte in AVRO konvertieren
Die von den .well-known-Endpunkten empfangenen Berichte sind im JSON-Format und müssen in das AVRO-Berichtsformat konvertiert werden. Rufen Sie den Speicherort von report.json auf und verwenden Sie aggregatable_report_converter.jar, um den aggregierten Debug-Bericht zu erstellen. Dadurch wird im aktuellen Verzeichnis ein aggregierbarer Bericht mit dem Namen report.avro erstellt.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. output_domain AVRO erstellen
Zum Erstellen der Datei output_domain.avro benötigen Sie die Bucket-Schlüssel, die aus den Berichten abgerufen werden können.
Bucket-Schlüssel werden von der AdTech-Plattform erstellt. In diesem Fall werden die Bucket-Schlüssel jedoch von der Website Privacy Sandbox Demo erstellt. Da die private Aggregation für diese Website im Debug-Modus ist, können wir den Bucket-Schlüssel mithilfe des debug_cleartext_payload aus dem „Berichtskörper“ abrufen.
Kopieren Sie die debug_cleartext_payload aus dem Berichtstext.
Öffnen Sie goo.gle/ags-payload-decoder, fügen Sie Ihre debug_cleartext_payload in das Feld „INPUT“ ein und klicken Sie auf „Decode“.
Die Seite gibt den Dezimalwert des Bucket-Schlüssels zurück. Unten sehen Sie ein Beispiel für einen Bucket-Schlüssel.
Nachdem wir den Bucket-Schlüssel haben, erstellen wir die output_domain.avro im selben Ordner, in dem wir gearbeitet haben. Ersetzen Sie „bucket_key“ durch den Bucket-Schlüssel, den Sie abgerufen haben.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Das Script erstellt die output_domain.avro-Datei im aktuellen Ordner.
3.1.5. Berichte in einen Cloud Storage-Bucket verschieben
Nachdem Sie die AVRO-Berichte und die Ausgabedomain erstellt haben, verschieben Sie die Berichte und die Ausgabedomain in den Bucket in Cloud Storage, den Sie in Voraussetzung 1.6 angegeben haben.
Wenn Sie die gcloud CLI in Ihrer lokalen Umgebung eingerichtet haben, können Sie die Dateien mit den folgenden Befehlen in die entsprechenden Ordner kopieren.
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
Andernfalls laden Sie die Dateien manuell in Ihren Bucket hoch. Erstellen Sie einen Ordner mit dem Namen „Berichte“ und laden Sie die Datei report.avro dort hoch. Erstellen Sie einen Ordner mit dem Namen „output_domains“ und laden Sie die Datei output_domain.avro dort hoch.
3.2. Nutzung des Aggregationsdienstes
In Voraussetzung 1.8 haben Sie entweder cURL oder Postman für API-Anfragen an die Endpunkte des Aggregationsdienstes ausgewählt. Unten finden Sie eine Anleitung für beide Optionen.
Wenn Ihr Job fehlschlägt, finden Sie in unserer Dokumentation zur Fehlerbehebung auf GitHub weitere Informationen dazu, wie Sie vorgehen können.
3.2.1. createJob-Endpunkt für Batches verwenden
Verwende die Anleitungen unten für cURL oder Postman, um einen Job zu erstellen.
cURL
Erstellen Sie im Terminal eine Datei mit dem Anfragetext (body.json) und fügen Sie den folgenden Text ein. Aktualisieren Sie die Platzhalterwerte. Weitere Informationen zu den einzelnen Feldern findest du in der API-Dokumentation.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Führen Sie die folgende Anfrage aus. Ersetzen Sie die Platzhalter in der URL der cURL-Anfrage durch die Werte aus frontend_service_cloudfunction_url, die nach Abschluss der Terraform-Bereitstellung in Vorraussetzung 1.6 ausgegeben werden.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
Sie sollten eine HTTP-202-Antwort erhalten, sobald die Anfrage vom Aggregationsdienst akzeptiert wurde. Weitere mögliche Antwortcodes sind in den API-Spezifikationen dokumentiert.
Postman
Für den Endpunkt createJob ist ein Anfragetext erforderlich, um dem Aggregationsdienst den Speicherort und die Dateinamen der aggregierbaren Berichte, Ausgabedomains und Zusammenfassungsberichte zur Verfügung zu stellen.
Rufen Sie den Tab „Body“ (Text) der createJob-Anfrage auf:

Ersetzen Sie die Platzhalter in der bereitgestellten JSON-Datei. Weitere Informationen zu diesen Feldern und ihrer Bedeutung finden Sie in der API-Dokumentation.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Senden Sie die createJob API-Anfrage:

Der Antwortcode befindet sich in der unteren Hälfte der Seite:

Sobald die Anfrage vom Aggregationsdienst akzeptiert wurde, sollten Sie eine HTTP-202-Antwort erhalten. Weitere mögliche Antwortcodes sind in den API-Spezifikationen dokumentiert.
3.2.2. Batchstatus über den getJob-Endpunkt abrufen
Verwende die Anleitungen unten für cURL oder Postman, um einen Job zu erhalten.
cURL
Führen Sie die folgende Anfrage in Ihrem Terminal aus. Ersetzen Sie die Platzhalter in der URL durch die Werte aus frontend_service_cloudfunction_url. Das ist dieselbe URL, die Sie für die createJob-Anfrage verwendet haben. Verwenden Sie für „job_request_id“ den Wert aus dem Job, den Sie mit dem createJob-Endpunkt erstellt haben.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
Das Ergebnis sollte den Status Ihrer Jobanfrage mit dem HTTP-Status 200 zurückgeben. Der „Body“ der Anfrage enthält die erforderlichen Informationen wie job_status, return_message und error_messages (falls der Job einen Fehler verursacht hat).
Postman
Sie können den Status der Jobanfrage mit dem Endpunkt getJob prüfen. Aktualisieren Sie in der getJob-Anfrage im Abschnitt „Params“ den Wert von job_request_id auf den job_request_id, der in der createJob-Anfrage gesendet wurde.
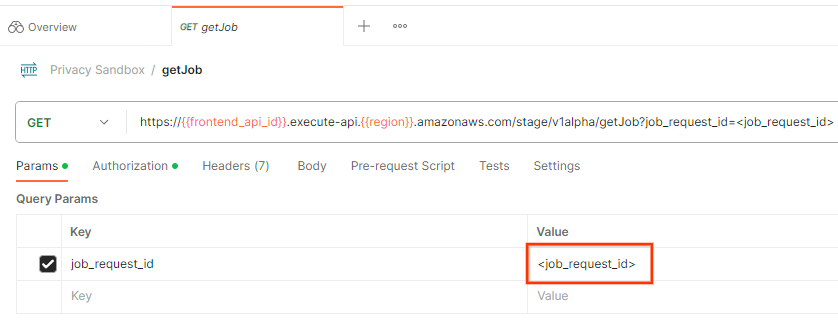
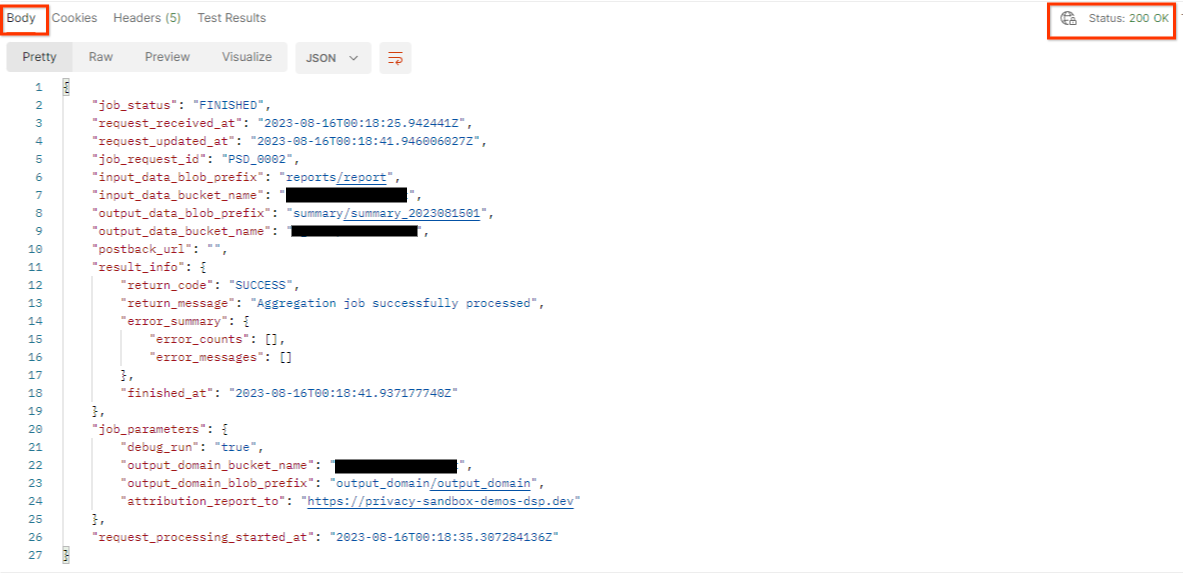
Senden Sie die getJob-Anfrage:

Das Ergebnis sollte den Status Ihrer Jobanfrage mit dem HTTP-Status 200 zurückgeben. Der „Body“ der Anfrage enthält die erforderlichen Informationen wie job_status, return_message und error_messages (falls der Job einen Fehler verursacht hat).
3.2.3. Zusammenfassungsbericht prüfen
Sobald Sie den Zusammenfassungsbericht in Ihrem Cloud Storage-Bucket für die Ausgabe erhalten haben, können Sie ihn in Ihre lokale Umgebung herunterladen. Zusammenfassungsberichte sind im AVRO-Format und können wieder in JSON umgewandelt werden. Sie können aggregatable_report_converter.jar mit dem folgenden Befehl verwenden, um den Bericht zu lesen.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
Dadurch wird ein JSON-Objekt mit aggregierten Werten für jeden Bucket-Schlüssel zurückgegeben, das in etwa so aussieht:

Wenn Ihre createJob-Anfrage debug_run als „wahr“ enthält, können Sie den Zusammenfassungsbericht im Debug-Ordner im output_data_blob_prefix-Ordner abrufen. Der Bericht ist im AVRO-Format und kann mit dem obigen Befehl in JSON konvertiert werden.
Der Bericht enthält den Bucket-Schlüssel, den fehlerfreien Messwert und den Fehler, der dem fehlerfreien Messwert hinzugefügt wird, um den zusammengefassten Bericht zu erstellen. Der Bericht sieht in etwa so aus:

Die Anmerkungen enthalten außerdem „in_reports“ und/oder „in_domain“. Das bedeutet:
- in_reports: Der Bucket-Schlüssel ist in den aggregierten Berichten verfügbar.
- in_domain: Der Bucket-Schlüssel ist in der AVRO-Datei „output_domain“ verfügbar.
Codelab abgeschlossen
Zusammenfassung:Sie haben den Aggregations-Dienst in Ihrer eigenen Cloud-Umgebung bereitgestellt, einen Debug-Bericht erfasst, eine Ausgabedomaindatei erstellt, diese Dateien in einem Cloud Storage-Bucket gespeichert und einen Job erfolgreich ausgeführt.
Nächste Schritte:Verwenden Sie den Aggregation Service weiterhin in Ihrer Umgebung oder löschen Sie die gerade erstellten Cloud-Ressourcen gemäß der Anleitung zur Bereinigung in Schritt 4.
4. 4. Klären
Wenn Sie die für den Aggregationsdienst über Terraform erstellten Ressourcen löschen möchten, verwenden Sie den Befehl „destroy“ in den Ordnern adtech_setup und dev (oder einer anderen Umgebung):
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
So löschen Sie den Cloud Storage-Bucket, der Ihre aggregierten Berichte und Zusammenfassungsberichte enthält:
$ gcloud storage buckets delete gs://my-bucket
Sie können auch die Chrome-Cookie-Einstellungen aus Voraussetzung 1.2 auf den vorherigen Zustand zurücksetzen.
5. 5. Anhang
adtech_setup.auto.tfvars-Beispieldatei
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
dev.auto.tfvars-Beispieldatei
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20