
1. 1. Requisitos previos
Tiempo estimado para completar la actividad: De 1 a 2 horas
Hay 2 modos para realizar este codelab: Pruebas locales o Servicio de agregación. El modo de pruebas locales requiere una máquina local y el navegador Chrome (no se crean ni usan recursos de Google Cloud). El modo de servicio de agregación requiere una implementación completa del servicio de agregación en Google Cloud.
Para realizar este codelab en cualquiera de los modos, se requieren algunos requisitos previos. Cada requisito se marca según si es necesario para las pruebas locales o el servicio de agregación.
1.1. Completa la inscripción y la certificación (servicio de agregación)
Para usar las APIs de Privacy Sandbox, asegúrate de haber completado la Inscripción y Certificación para Chrome y Android.
1.2. Habilita las APIs de privacidad en los anuncios (servicio de agregación y pruebas locales)
Como usaremos Privacy Sandbox, te recomendamos que habilites las APIs de anuncios de Privacy Sandbox.
En el navegador, ve a chrome://settings/adPrivacy y habilita todas las APIs de privacidad en los anuncios.
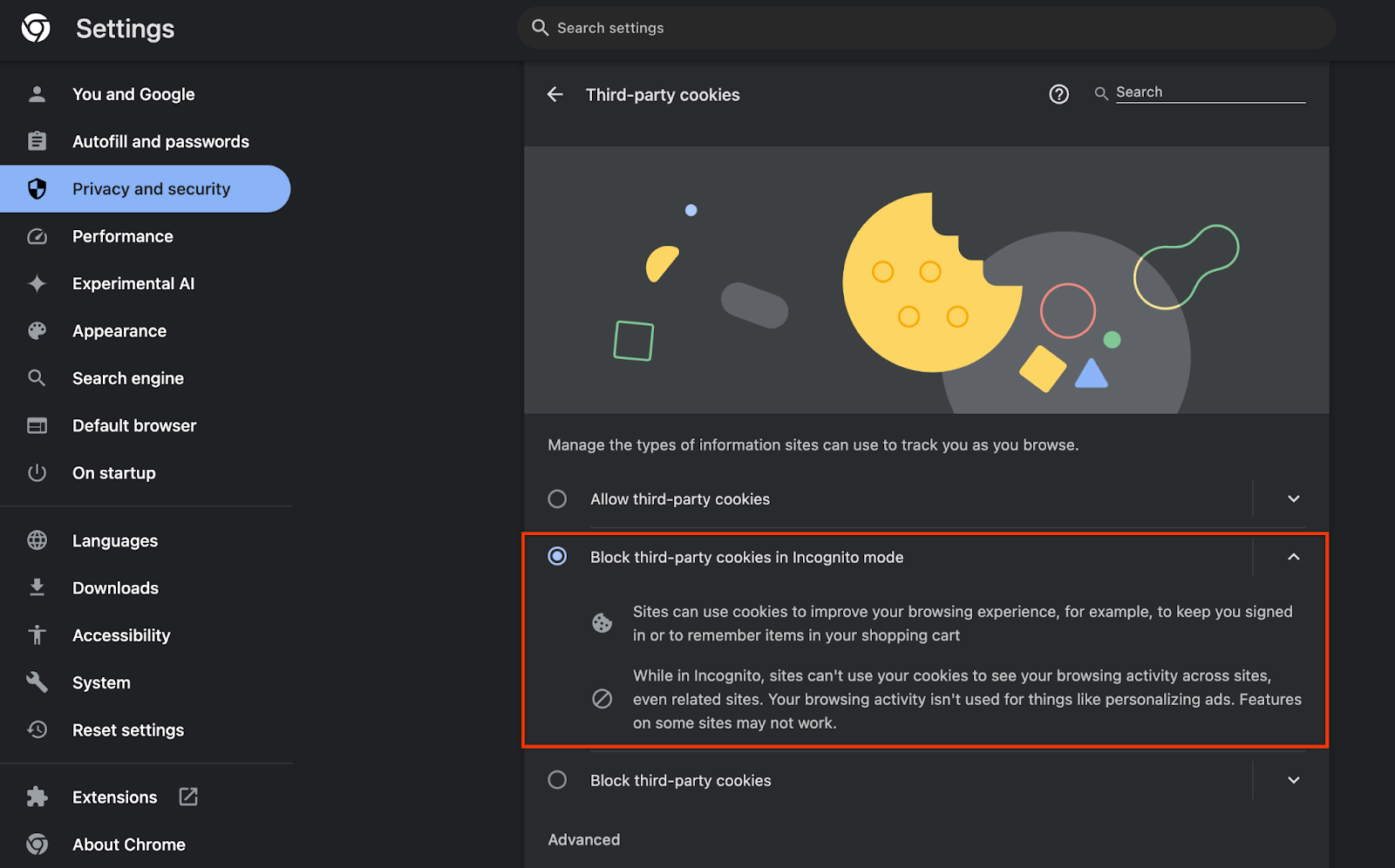
Además, asegúrate de que las cookies de terceros estén habilitadas.
En chrome://settings/cookies, asegúrate de que NO se bloqueen las cookies de terceros. Según la versión de Chrome que tengas, es posible que veas diferentes opciones en este menú de configuración, pero las configuraciones aceptables incluyen las siguientes:
- "Bloquear todas las cookies de terceros" = INHABILITADA
- "Bloquear cookies de terceros" = INHABILITADA
- "Bloquear cookies de terceros en el modo Incógnito" = Habilitado
1.3. Descarga la herramienta de pruebas locales (pruebas locales)
Para realizar pruebas locales, deberás descargar la herramienta de pruebas locales. La herramienta generará informes de resumen a partir de los informes de depuración sin encriptar.
La herramienta de pruebas locales está disponible para descargar en los archivos JAR de Cloud Functions en GitHub. Debe llamarse LocalTestingTool_{version}.jar.
1.4. Asegúrate de que el JRE de Java esté instalado (servicio de agregación y pruebas locales)
Abre “Terminal” y usa java --version para verificar si tu máquina tiene instalado Java o openJDK.

Si no está instalado, puedes descargarlo e instalarlo desde el sitio de Java o el sitio de openJDK.
1.5. Descarga aggregatable_report_converter (servicio de agregación y pruebas locales)
Puedes descargar una copia de aggregatable_report_converter desde el repositorio de GitHub de Demos de Privacy Sandbox. El repositorio de GitHub menciona el uso de IntelliJ o Eclipse, pero ninguno es obligatorio. Si no usas estas herramientas, descarga el archivo JAR en tu entorno local.
1.6. Configura un entorno de GCP (servicio de agregación)
El servicio de agregación requiere el uso de un entorno de ejecución confiable que use un proveedor de servicios en la nube. En este codelab, el servicio de agregación se implementará en GCP, pero también se admite AWS.
Sigue las instrucciones de implementación en GitHub para configurar la CLI de gcloud, descargar los módulos y objetos binarios de Terraform, y crear recursos de GCP para el servicio de agregación.
Pasos clave en las instrucciones de implementación:
- Configura la CLI de "gcloud" y Terraform en tu entorno.
- Crea un bucket de Cloud Storage para almacenar el estado de Terraform.
- Descarga las dependencias.
- Actualiza
adtech_setup.auto.tfvarsy ejecutaadtech_setupTerraform. Consulta el Apéndice para ver un ejemplo de archivoadtech_setup.auto.tfvars. Anota el nombre del bucket de datos que se crea aquí. Se usará en el codelab para almacenar los archivos que creemos. - Actualiza
dev.auto.tfvars, usa la identidad de la cuenta de servicio de implementación y ejecutadevTerraform. Consulta el Apéndice para ver un ejemplo de archivodev.auto.tfvars. - Una vez que se complete la implementación, captura el
frontend_service_cloudfunction_urldel resultado de Terraform, que se necesitará para realizar solicitudes al servicio de agregación en pasos posteriores.
1.7. Completa la integración del servicio de agregación (servicio de agregación)
El servicio de agregación requiere la integración con los coordinadores para poder usarlo. Completa el formulario de integración del servicio de agregación. Para ello, proporciona tu sitio de informes y otra información, selecciona "Google Cloud" y, luego, ingresa la dirección de tu cuenta de servicio. Esta cuenta de servicio se crea en el requisito previo anterior (1.6. Configura un entorno de GCP). (Sugerencia: Si usas los nombres predeterminados proporcionados, esta cuenta de servicio comenzará con "worker-sa@").
Espera hasta 2 semanas para que se complete el proceso de integración.
1.8. Determina tu método para llamar a los extremos de la API (servicio de agregación)
En este codelab, se proporcionan 2 opciones para llamar a los extremos de la API de Aggregation Service: cURL y Postman. cURL es la forma más rápida y sencilla de llamar a los extremos de la API desde la Terminal, ya que requiere una configuración mínima y no necesita software adicional. Sin embargo, si no quieres usar cURL, puedes usar Postman para ejecutar y guardar solicitudes a la API para usarlas en el futuro.
En el artículo 3.2. Uso del servicio de agregación, encontrarás instrucciones detalladas para usar ambas opciones. Puedes obtener una vista previa ahora para determinar qué método usarás. Si seleccionas Postman, realiza la siguiente configuración inicial.
1.8.1. Configurar espacio de trabajo
Regístrate para obtener una cuenta de Postman. Una vez que te registres, se creará automáticamente un lugar de trabajo para ti.
Si no se crea un lugar de trabajo, ve al elemento de navegación superior "Lugares de trabajo" y selecciona "Crear lugar de trabajo".
Selecciona "Espacio de trabajo en blanco", haz clic en Siguiente y asígnale el nombre "Zona de pruebas de privacidad de GCP". Selecciona “Personal” y haz clic en “Crear”.
Descarga la configuración JSON y los archivos de entorno global del espacio de trabajo preconfigurado.
Importa ambos archivos JSON a "Mi espacio de trabajo" con el botón "Importar".

Esto creará la colección "GCP Privacy Sandbox" junto con las solicitudes HTTP createJob y getJob.
1.8.2. Configura la autorización
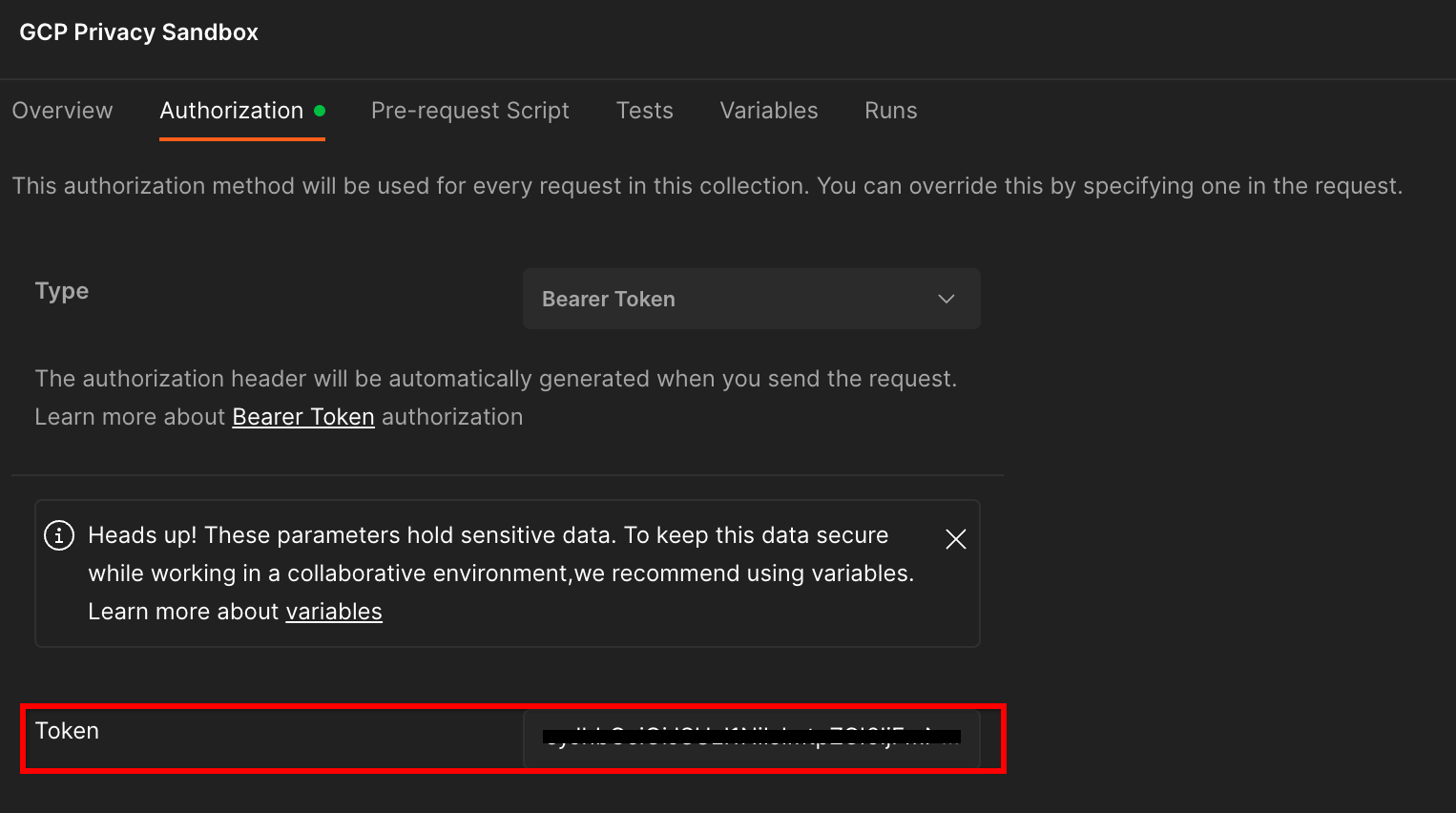
Haz clic en la colección "Privacy Sandbox de GCP" y navega a la pestaña "Autorización".

Usarás el método "Bearer Token". Desde el entorno de la terminal, ejecuta este comando y copia el resultado.
gcloud auth print-identity-token
Luego, pega este valor de token en el campo "Token" de la pestaña de autorización de Postman:
1.8.3. Cómo configurar el entorno
Navega a la sección "Vista rápida del entorno" en la esquina superior derecha:
Haz clic en “Editar” y actualiza el “Valor actual” de “environment”, “region” y “cloud-function-id”:
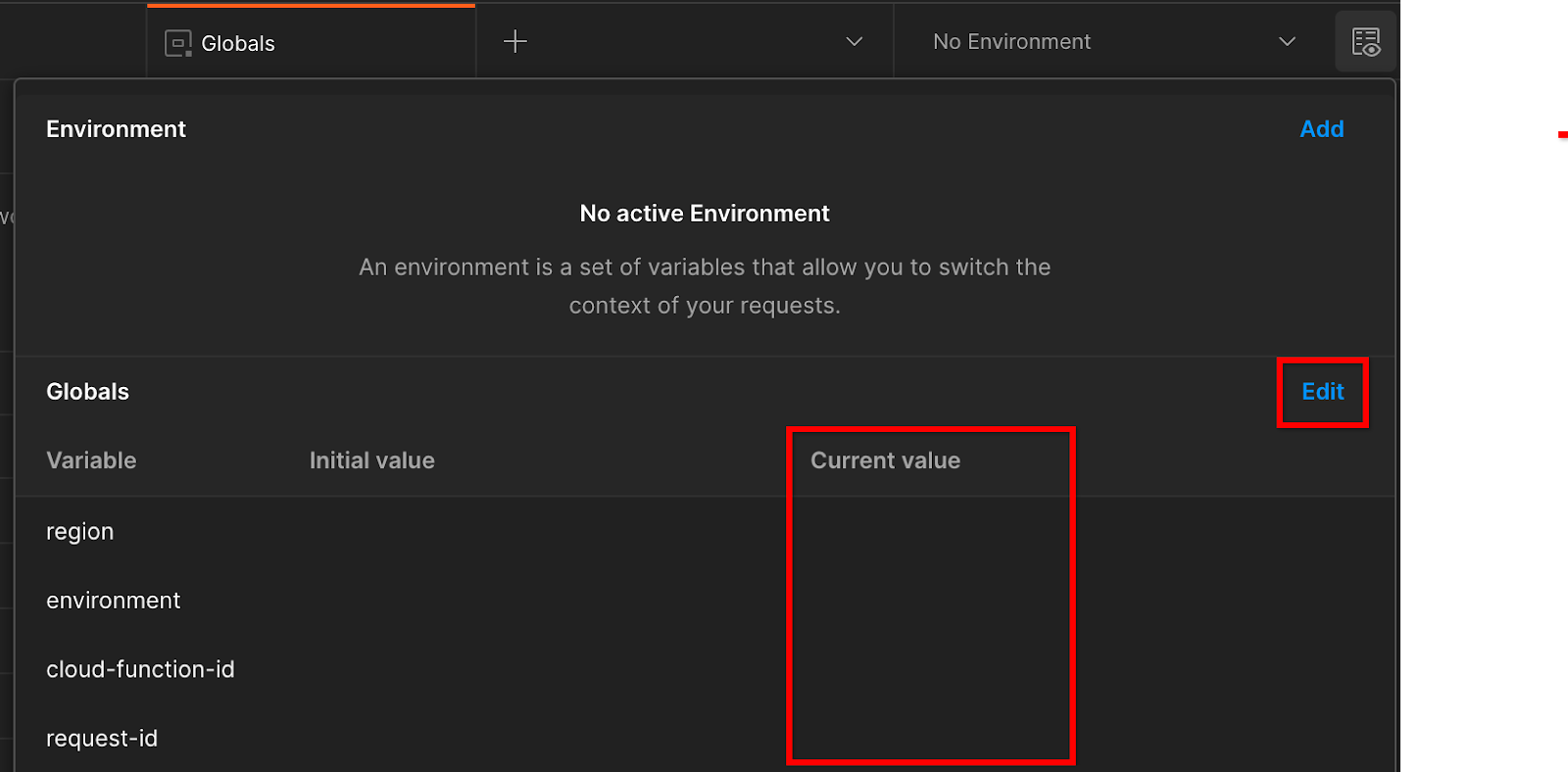
Por ahora, puedes dejar el campo "request-id" en blanco, ya que lo completaremos más adelante. Para los otros campos, usa los valores de frontend_service_cloudfunction_url, que se devolvieron cuando se completó correctamente la implementación de Terraform en el requisito previo 1.6. La URL sigue este formato: https://
2. 2. Codelab de pruebas locales
Tiempo estimado para completar la actividad: Menos de 1 hora
Puedes usar la herramienta de prueba local en tu máquina para realizar la agregación y generar informes de resumen con los informes de depuración sin encriptar. Antes de comenzar, asegúrate de haber completado todos los requisitos previos etiquetados como "Pruebas locales".
Pasos del codelab
Paso 2.1: Activar informe: Activa los informes de agregación privada para poder recopilarlos.
Paso 2.2. Crear informe de depuración de Avro: Convierte el informe JSON recopilado en un informe con formato AVRO. Este paso será similar al que se realiza cuando las plataformas de tecnología publicitaria recopilan los informes de los extremos de informes de la API y convierten los informes JSON en informes con formato AVRO.
Paso 2.3. Recupera las claves de bucket: Las claves de bucket son diseñadas por adTechs. En este codelab, como los buckets están predefinidos, recupera las claves de bucket como se proporciona.
Paso 2.4. Crea un archivo AVRO de dominio de salida: Una vez que se recuperen las claves del bucket, crea el archivo AVRO de dominio de salida.
Paso 2.5: Crear informe de resumen: Usa la herramienta de pruebas locales para poder crear informes de resumen en el entorno local.
Paso 2.6. Revisa los informes de resumen: Revisa el informe de resumen que crea la herramienta de pruebas locales.
2.1. Informe de activadores
Para activar un informe de agregación privada, puedes usar el sitio de demostración de Privacy Sandbox (https://privacy-sandbox-demos-news.dev/?env=gcp) o tu propio sitio (p.ej., https://adtechexample.com). Si usas tu propio sitio y no completaste la integración de los servicios de inscripción y certificación y agregación, deberás usar una marca de Chrome y un interruptor de CLI.
Para esta demostración, usaremos el sitio de demostración de Privacy Sandbox. Sigue el vínculo para ir al sitio. Luego, puedes ver los informes en chrome://private-aggregation-internals:
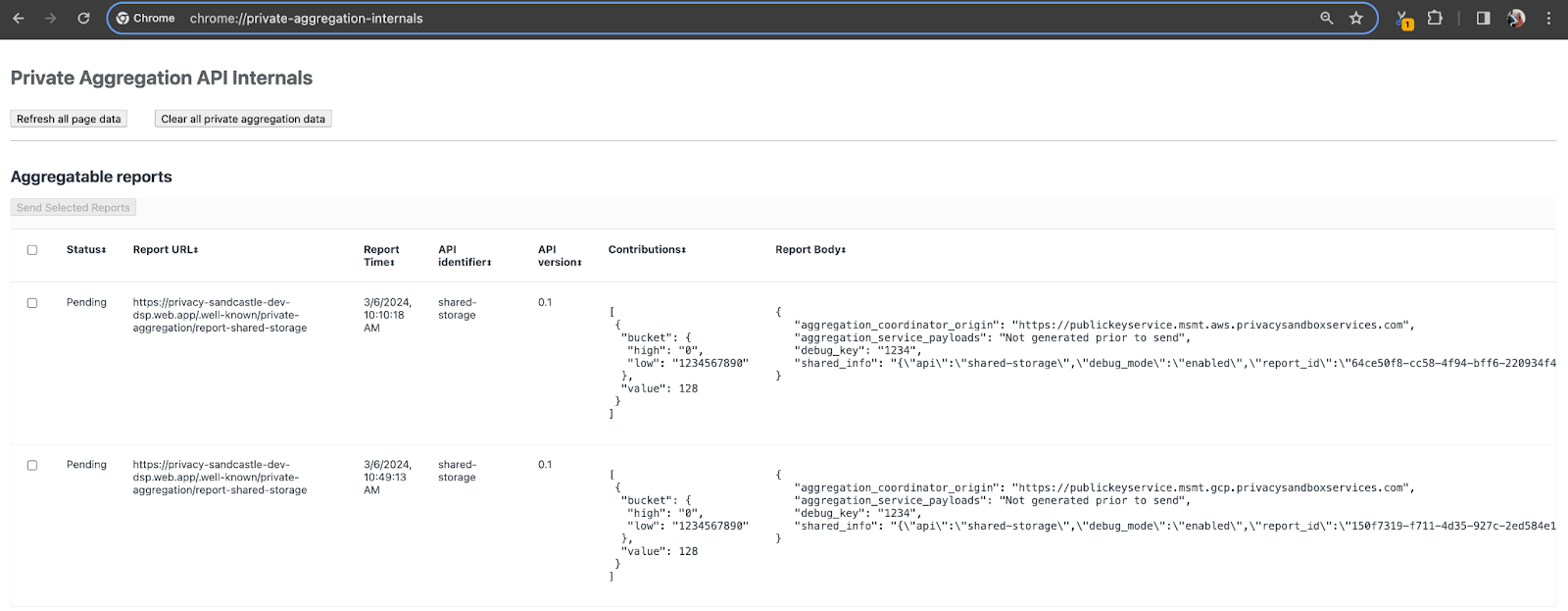
El informe que se envía al extremo {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage también se encuentra en el "Cuerpo del informe" de los informes que se muestran en la página de información interna de Chrome.
Es posible que veas muchos informes aquí, pero para este codelab, usa el informe agregable que es específico de GCP y que genera el extremo de depuración. La "URL del informe" contendrá "/debug/" y el aggregation_coordinator_origin field del "Cuerpo del informe" contendrá esta URL: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
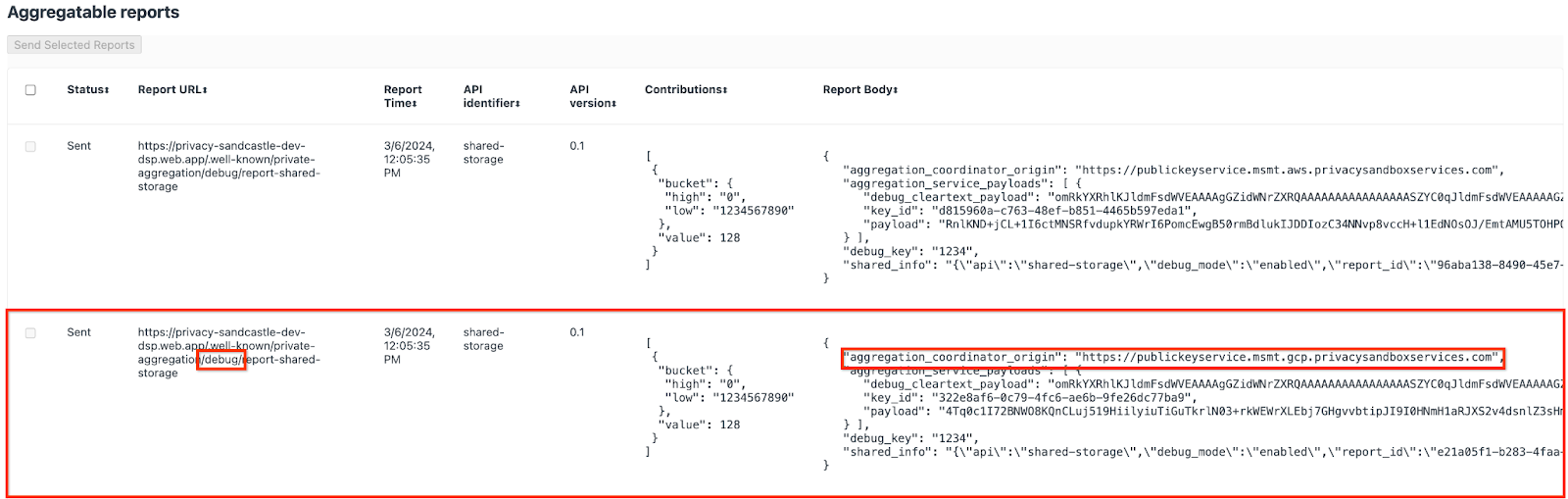
2.2. Crea un informe agregable de depuración
Copia el informe que se encuentra en el "Cuerpo del informe" de chrome://private-aggregation-internals y crea un archivo JSON en la carpeta privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar (dentro del repositorio que se descargó en el requisito previo 1.5).
En este ejemplo, usamos vim, ya que estamos usando Linux. Sin embargo, puedes usar el editor de texto que quieras.
vim report.json
Pega el informe en report.json y guarda el archivo.

Una vez que lo tengas, usa aggregatable_report_converter.jar para crear el informe agregable de depuración. Esto crea un informe agregable llamado report.avro en tu directorio actual.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Cómo recuperar la clave de bucket del informe
Para crear el archivo output_domain.avro, necesitas las claves de bucket que se pueden recuperar de los informes.
La tecnología publicitaria diseña las claves de bucket. Sin embargo, en este caso, el sitio Demo de Privacy Sandbox crea las claves de bucket. Dado que la agregación privada para este sitio está en modo de depuración, podemos usar el debug_cleartext_payload del "Cuerpo del informe" para obtener la clave del bucket.
Continúa y copia el debug_cleartext_payload del cuerpo del informe.

Abre goo.gle/ags-payload-decoder, pega tu debug_cleartext_payload en el cuadro "INPUT" y haz clic en "Decode".
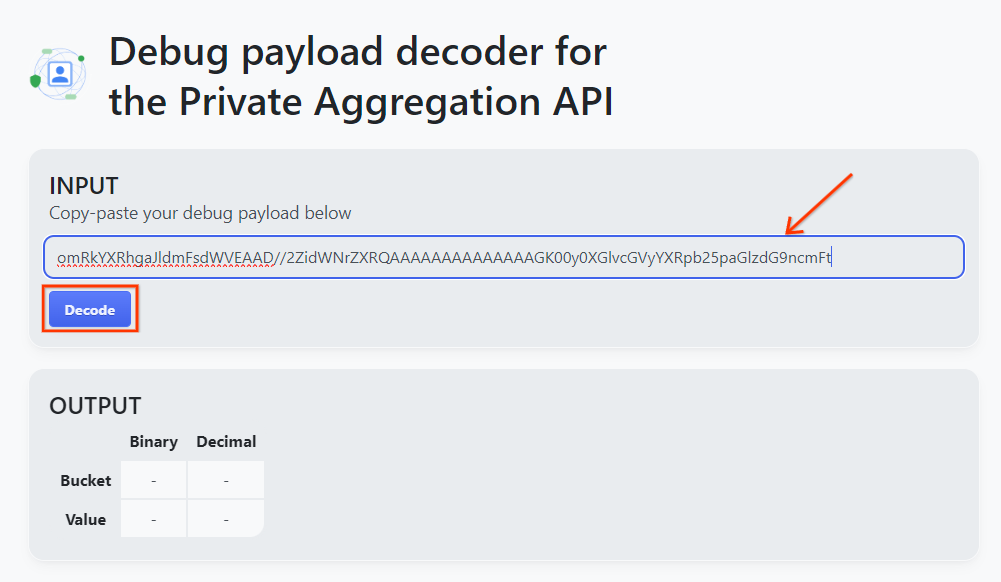
La página muestra el valor decimal de la clave del bucket. A continuación, se muestra una clave de bucket de ejemplo.
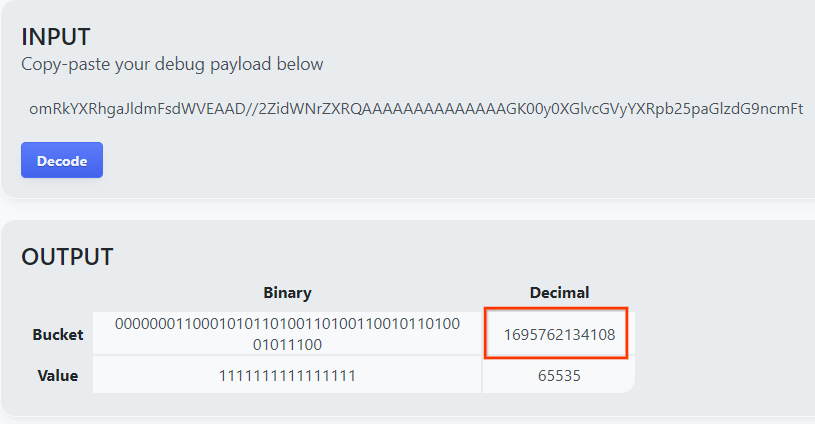
2.4. Crea un dominio de salida AVRO
Ahora que tenemos la clave del bucket, creemos el output_domain.avro en la misma carpeta en la que hemos estado trabajando. Asegúrate de reemplazar la clave del bucket por la que recuperaste.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
La secuencia de comandos crea el archivo output_domain.avro en la carpeta actual.
2.5. Cómo crear informes de resumen con la herramienta de pruebas locales
Usaremos LocalTestingTool_{version}.jar que se descargó en el requisito previo 1.3 para crear los informes de resumen con el siguiente comando. Reemplaza {version} por la versión que descargaste. Recuerda mover LocalTestingTool_{version}.jar al directorio actual o agregar una ruta de acceso relativa para hacer referencia a su ubicación actual.
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
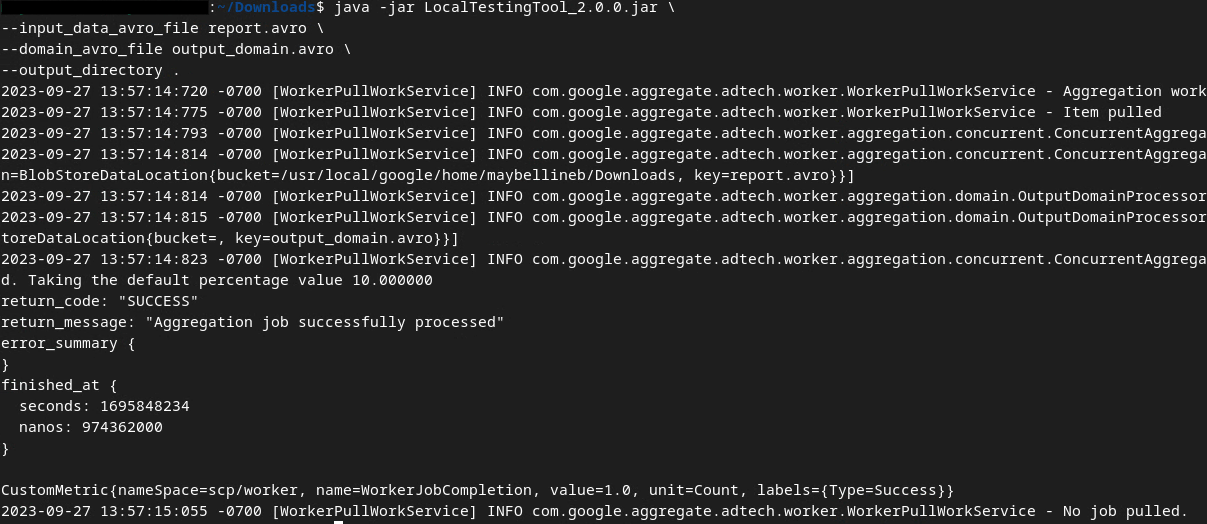
Deberías ver algo similar a lo siguiente una vez que se ejecute el comando. Se crea un informe output.avro una vez que se completa.
2.6. Revisa el informe de resumen
El informe de resumen que se crea está en formato AVRO. Para poder leerlo, debes convertirlo de AVRO a un formato JSON. Idealmente, adTech debería escribir código para convertir los informes de AVRO en JSON.
Usaremos aggregatable_report_converter.jar para volver a convertir el informe AVRO en JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
Esto muestra un informe similar al siguiente. Junto con un informe output.json creado en el mismo directorio.

¡Codelab completado!
Resumen: Recopilaste un informe de depuración, creaste un archivo de dominio de salida y generaste un informe de resumen con la herramienta de prueba local que simula el comportamiento de agregación del servicio de agregación.
Próximos pasos: Ahora que experimentaste con la herramienta de pruebas locales, puedes probar el mismo ejercicio con una implementación activa del servicio de agregación en tu propio entorno. Revisa los requisitos previos para asegurarte de haber configurado todo para el modo "Servicio de agregación" y, luego, continúa con el paso 3.
3. 3. Codelab de servicio de agregación
Tiempo estimado para completar la actividad: 1 hora
Antes de comenzar, asegúrate de haber completado todos los requisitos previos etiquetados como "Servicio de agregación".
Pasos del codelab
Paso 3.1. Creación de entradas del servicio de agregación: Crea los informes del servicio de agregación que se agrupan para el servicio de agregación.
- Paso 3.1.1: Informe de activadores
- Paso 3.1.2. Recopila informes agregables
- Paso 3.1.3: Cómo convertir informes a AVRO
- Paso 3.1.4. Crea AVRO de output_domain
- Paso 3.1.5 Cómo mover informes al bucket de Cloud Storage
Paso 3.2. Uso del servicio de agregación: Usa la API de Aggregation Service para crear informes de resumen y revisarlos.
- Paso 3.2.1: Usa el extremo
createJobpara realizar tareas por lotes - Paso 3.2.2. Usa el extremo
getJobpara recuperar el estado del lote - Paso 3.2.3: Revisa el informe de resumen
3.1. Creación de entradas de servicios de agregación
Continúa con la creación de los informes AVRO para enviarlos por lotes al servicio de agregación. Los comandos de shell de estos pasos se pueden ejecutar en Cloud Shell de GCP (siempre que las dependencias de los requisitos previos se clonen en tu entorno de Cloud Shell) o en un entorno de ejecución local.
3.1.1. Informe de activadores
Sigue el vínculo para ir al sitio. Luego, puedes ver los informes en chrome://private-aggregation-internals:
El informe que se envía al extremo {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage también se encuentra en el "Cuerpo del informe" de los informes que se muestran en la página de información interna de Chrome.
Es posible que veas muchos informes aquí, pero para este codelab, usa el informe agregable que es específico de GCP y que genera el extremo de depuración. La "URL del informe" contendrá "/debug/" y el aggregation_coordinator_origin field del "Cuerpo del informe" contendrá esta URL: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
3.1.2. Recopila informes agregables
Recopila tus informes agregables de los extremos .well-known de tu API correspondiente.
- Private Aggregation:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - Attribution Reporting - Summary Report:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
En este codelab, realizaremos la recopilación de informes de forma manual. En producción, se espera que las plataformas de tecnología publicitaria recopilen y conviertan los informes de forma programática.
Vamos a copiar el informe JSON en el "Cuerpo del informe" de chrome://private-aggregation-internals.
En este ejemplo, usamos vim, ya que estamos usando Linux. Sin embargo, puedes usar el editor de texto que quieras.
vim report.json
Pega el informe en report.json y guarda el archivo.
3.1.3. Cómo convertir informes a AVRO
Los informes recibidos de los extremos .well-known están en formato JSON y deben convertirse al formato de informe AVRO. Una vez que tengas el informe JSON, navega a la ubicación en la que se almacena report.json y usa aggregatable_report_converter.jar para crear el informe agregable de depuración. Esto crea un informe agregable llamado report.avro en tu directorio actual.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. Crea AVRO de output_domain
Para crear el archivo output_domain.avro, necesitas las claves de bucket que se pueden recuperar de los informes.
La tecnología publicitaria diseña las claves de bucket. Sin embargo, en este caso, el sitio Demo de Privacy Sandbox crea las claves de bucket. Dado que la agregación privada para este sitio está en modo de depuración, podemos usar el debug_cleartext_payload del "Cuerpo del informe" para obtener la clave del bucket.
Continúa y copia el debug_cleartext_payload del cuerpo del informe.
Abre goo.gle/ags-payload-decoder, pega tu debug_cleartext_payload en el cuadro "INPUT" y haz clic en "Decode".
La página muestra el valor decimal de la clave del bucket. A continuación, se muestra una clave de bucket de ejemplo.
Ahora que tenemos la clave del bucket, creemos el output_domain.avro en la misma carpeta en la que hemos estado trabajando. Asegúrate de reemplazar la clave del bucket por la que recuperaste.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
La secuencia de comandos crea el archivo output_domain.avro en la carpeta actual.
3.1.5. Cómo mover informes al bucket de Cloud Storage
Una vez que se hayan creado los informes y el dominio de salida de AVRO, mueve los informes y el dominio de salida al bucket de Cloud Storage (que anotaste en el requisito previo 1.6).
Si configuraste la CLI de gcloud en tu entorno local, usa los siguientes comandos para copiar los archivos en las carpetas correspondientes.
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
De lo contrario, sube los archivos manualmente a tu bucket. Crea una carpeta llamada “informes” y sube el archivo report.avro allí. Crea una carpeta llamada "output_domains" y sube el archivo output_domain.avro allí.
3.2. Uso del servicio de agregación
Recuerda que, en el requisito previo 1.8, seleccionaste cURL o Postman para realizar solicitudes de API a los extremos del servicio de agregación. A continuación, encontrarás instrucciones para ambas opciones.
Si tu trabajo falla con un error, consulta nuestra documentación de solución de problemas en GitHub para obtener más información sobre cómo proceder.
3.2.1. Usa el extremo createJob para realizar tareas por lotes
Usa las instrucciones de cURL o Postman que se indican a continuación para crear un trabajo.
cURL
En "Terminal", crea un archivo de cuerpo de solicitud (body.json) y pega lo siguiente. Asegúrate de actualizar los valores de los marcadores de posición. Consulta esta documentación de la API para obtener más información sobre lo que representa cada campo.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Ejecuta la siguiente solicitud. Reemplaza los marcadores de posición en la URL de la solicitud de cURL por los valores de frontend_service_cloudfunction_url, que se muestra después de completar correctamente la implementación de Terraform en el requisito previo 1.6.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
Deberías recibir una respuesta HTTP 202 una vez que el servicio de agregación acepte la solicitud. Otros códigos de respuesta posibles se documentan en las especificaciones de la API.
Cartero
Para el extremo createJob, se requiere un cuerpo de solicitud para proporcionar al servicio de agregación la ubicación y los nombres de archivo de los informes agregables, los dominios de salida y los informes de resumen.
Navega a la pestaña "Cuerpo" de la solicitud createJob:

Reemplaza los marcadores de posición dentro del JSON proporcionado. Para obtener más información sobre estos campos y lo que representan, consulta la documentación de la API.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
"Envía" la solicitud a la API de createJob:

El código de respuesta se encuentra en la mitad inferior de la página:

Deberías recibir una respuesta HTTP 202 una vez que el servicio de agregación acepte la solicitud. Otros códigos de respuesta posibles se documentan en las especificaciones de la API.
3.2.2. Usa el extremo getJob para recuperar el estado del lote
Usa las instrucciones de cURL o Postman que se indican a continuación para obtener un trabajo.
cURL
Ejecuta la siguiente solicitud en la terminal. Reemplaza los marcadores de posición en la URL por los valores de frontend_service_cloudfunction_url, que es la misma URL que usaste para la solicitud createJob. Para "job_request_id", usa el valor del trabajo que creaste con el extremo createJob.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
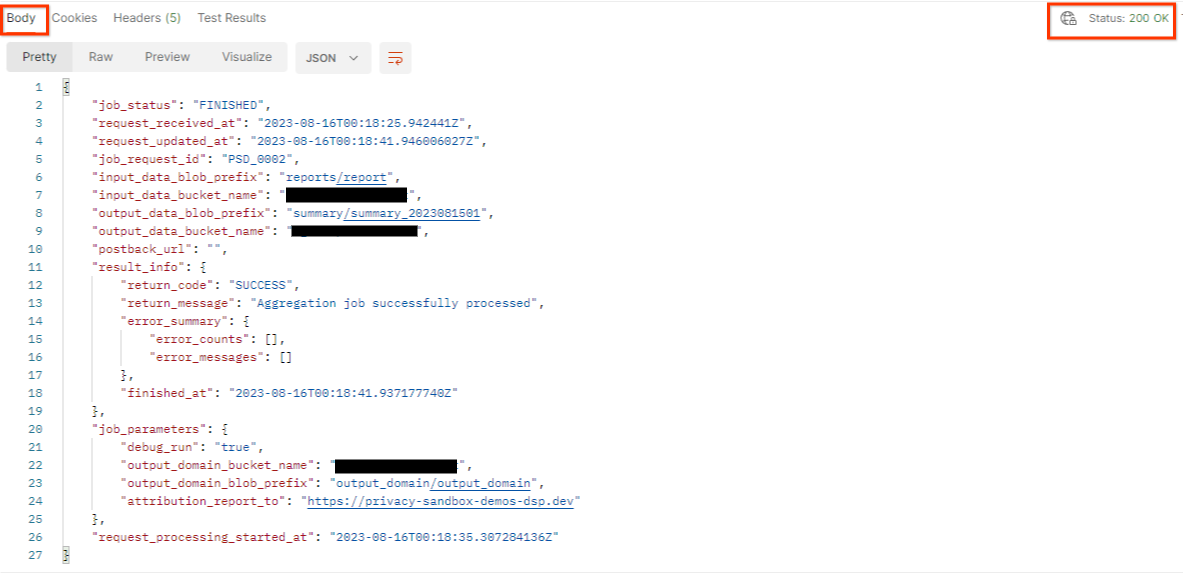
El resultado debería mostrar el estado de tu solicitud de trabajo con un estado HTTP de 200. El "cuerpo" de la solicitud contiene la información necesaria, como job_status, return_message y error_messages (si la tarea tuvo un error).
Cartero
Para verificar el estado de la solicitud de trabajo, puedes usar el extremo getJob. En la sección "Params" de la solicitud getJob, actualiza el valor job_request_id al job_request_id que se envió en la solicitud createJob.
"Envía" la solicitud getJob:

El resultado debería mostrar el estado de tu solicitud de trabajo con un estado HTTP de 200. El "cuerpo" de la solicitud contiene la información necesaria, como job_status, return_message y error_messages (si la tarea tuvo un error).
3.2.3. Revisa el informe de resumen
Una vez que recibas tu informe de resumen en tu bucket de Cloud Storage de salida, podrás descargarlo en tu entorno local. Los informes de resumen están en formato AVRO y se pueden volver a convertir a JSON. Puedes usar aggregatable_report_converter.jar para leer tu informe con el siguiente comando.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
Esto muestra un JSON de valores agregados de cada clave de bucket que se parece al siguiente.

Si tu solicitud de createJob incluye debug_run como verdadero, puedes recibir tu informe de resumen en la carpeta de depuración que se encuentra en output_data_blob_prefix. El informe está en formato AVRO y se puede convertir a JSON con el comando anterior.
El informe contiene la clave del bucket, la métrica sin ruido y el ruido que se agrega a la métrica sin ruido para formar el informe de resumen. El informe es similar al siguiente.

Las anotaciones también contienen "in_reports" o "in_domain", lo que significa lo siguiente:
- in_reports: La clave de bucket está disponible en los informes agregables.
- in_domain: La clave del bucket está disponible dentro del archivo AVRO output_domain.
¡Codelab completado!
Resumen: Implementaste el servicio de agregación en tu propio entorno de nube, recopilaste un informe de depuración, creaste un archivo de dominio de salida, almacenaste estos archivos en un bucket de Cloud Storage y ejecutaste un trabajo de forma correcta.
Próximos pasos: Continúa usando el servicio de agregación en tu entorno o borra los recursos de nube que acabas de crear siguiendo las instrucciones de limpieza del paso 4.
4. 4. Corrección
Para borrar los recursos creados para el servicio de agregación a través de Terraform, usa el comando destroy en las carpetas adtech_setup y dev (o cualquier otro entorno):
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
Para borrar el bucket de Cloud Storage que contiene tus informes agregables y de resumen, sigue estos pasos:
$ gcloud storage buckets delete gs://my-bucket
También puedes revertir la configuración de cookies de Chrome del requisito previo 1.2 a su estado anterior.
5. 5. Apéndice
Archivo adtech_setup.auto.tfvars de ejemplo
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
Archivo dev.auto.tfvars de ejemplo
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20