집계 가능한 보고서를 일괄 처리할 때는 개인 정보 보호 한도가 초과되지 않도록 일괄 처리 전략을 최적화하는 것이 중요합니다. 다음은 집계 서비스에 보고서 일괄 전송을 위한 몇 가지 권장 전략입니다.
신고 수집
일괄로 포함할 보고서를 수집할 때는 다음 사항에 유의하세요.
보고서 업로드 재시도
참고: 재시도 기준은 변경될 수 있습니다. 이 경우 이 섹션의 정보가 업데이트됩니다.
웹 플랫폼과 OS 플랫폼 모두에서 플랫폼은 보고서 전송을 세 번 시도하지만 세 번째 시도 후 보고서가 전송되지 않으면 전송되지 않습니다. 보고서를 보낼 수 있는 시점에 관계없이 원래 scheduled_report_time 값은 보존됩니다. 재시도 타임라인은 플랫폼마다 다릅니다.
- 웹브라우저는 브라우저가 온라인 상태일 때 보고서를 전송합니다. 보고서 전송에 실패하면 두 번째 재시도에서는 5분, 세 번째 재시도까지 15분이 대기합니다. 브라우저가 오프라인 상태가 되면 다시 온라인 상태가 된 후 1분 후에 다음 재시도가 이루어집니다. 웹에서 보고서를 전송할 때는 최대 지연 시간이 없습니다. 즉, 브라우저가 오프라인 상태가 되었다가 다시 온라인 상태가 되면 보고서가 생성된 지 얼마나 지났든지 다시 시도 정책에 따라 보고서를 전송하려고 시도합니다.
- Android 휴대전화의 네트워크 연결이 일관적이어야 합니다. 따라서 보고서를 전송하는 작업이 시간당 한 번 실행됩니다. 즉, 보고서 전송에 실패하면 다음 시간에 다시 시도되고 그 후 1시간 후에 다시 시도됩니다. 기기가 연결되어 있지 않으면 기기가 네트워크에 다시 연결된 후 실행되는 다음 보고 작업으로 보고서 전송을 다시 시도합니다. 최대 지연은 28일이며, 이는 기기가 28일 전에 생성된 보고서를 전송하지 않는다는 의미입니다.
신고 대기 중
일괄 처리를 위해 보고서를 수집할 때는 지연된 보고서가 도착할 때까지 기다리는 것이 좋습니다. 지연된 신고는 scheduled_report_time 값을 신고가 접수된 시점과 비교하여 확인할 수 있습니다. 이러한 보고서 간의 시간 차이는 지연된 보고서를 기다릴 시간을 결정하는 데 도움이 됩니다. 예를 들어 지연된 신고가 수집되면 scheduled_report_time 필드를 확인하고 신고의 90%, 95%, 99% 가 수신된 시간 지연을 시간으로 기록합니다. 이 데이터를 사용하여 지연된 보고서를 기다릴 시간을 결정할 수 있습니다.
즉시 집계 보고서를 사용하면 보고서 지연 가능성을 줄일 수 있습니다.
다음 시각화는 지연된 보고서가 예약된 보고서 시간에 따라 적절한 일괄 처리에 저장되는 것을 보여줍니다. 일괄 T는 scheduled_report_time를 나타내고 T+X는 지연된 보고서를 기다린 시간을 나타냅니다. 이렇게 하면 예약된 보고 시간에 해당하는 배치에 포함된 대부분의 보고서가 포함된 요약 보고서가 생성됩니다.
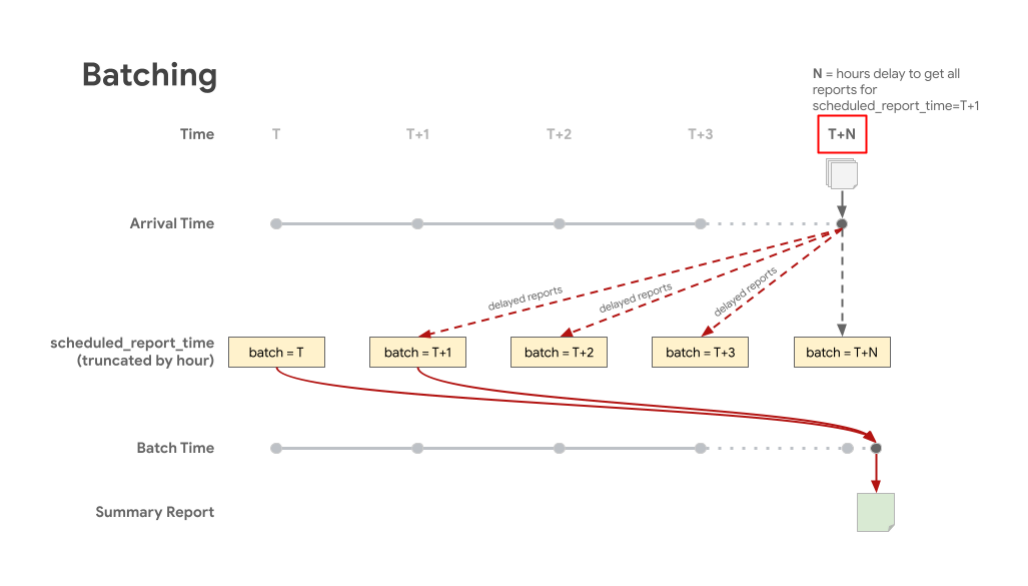
집계 가능한 보고서 회계
집계 서비스는 '중복 없음' 규칙을 유지합니다. 이 규칙은 공유 ID가 동일한 모든 집계 가능한 보고서가 동일한 일괄 처리에 포함되어야 한다고 적용합니다.
보고서가 수집된 후에는 공유 ID가 동일한 모든 보고서가 하나의 일괄 처리에 포함되도록 일괄 처리해야 합니다.
보고서가 다른 일괄 처리에서 이미 처리된 경우 처리 시 개인 정보 보호 예산 소진 오류가 발생할 수 있습니다. 보고서를 올바르게 일괄 처리하면 '중복 없음' 규칙으로 인해 일괄 항목이 거부되는 것을 방지할 수 있습니다.
공유 ID는 집계 가능한 보고서 회계를 추적하기 위해 각 보고서에 대해 생성되는 키입니다. 공유 ID를 사용하면 공유 ID가 동일한 보고서가 하나의 요약 보고서에만 기여하도록 할 수 있습니다. 즉, 하나의 공유 ID에 함께 매핑되는 보고서가 모두 단일 배치에 포함되어야 합니다. 예를 들어 보고서 X와 보고서 Y의 공유 ID가 모두 동일한 경우 보고서가 중복되어 삭제되지 않도록 보고서 X와 보고서 Y를 동일한 배치에 포함해야 합니다.
다음 이미지는 공유 ID를 생성하기 위해 함께 해싱된 shared_info 구성요소를 보여줍니다.
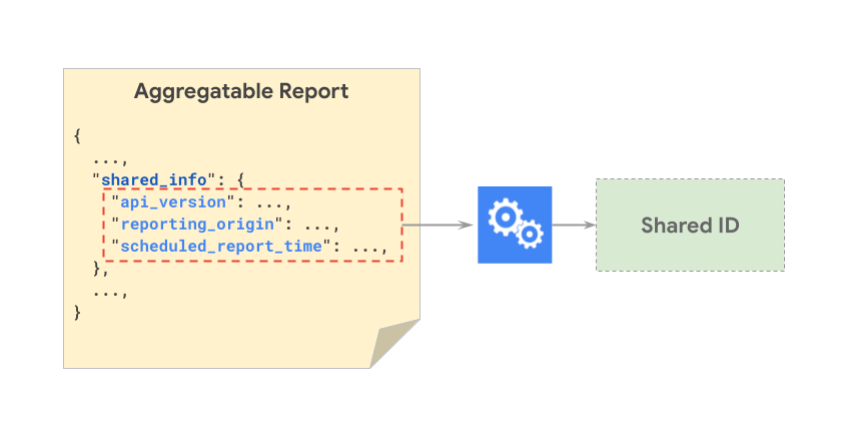
다음 이미지는 두 개의 서로 다른 보고서에 동일한 공유 ID가 있을 수 있는 방법을 보여줍니다.

참고: scheduled_report_time는 시간별로 잘리고 source_registration_time는 일 단위로 잘립니다. 또한 report_id는 공유 ID 생성 시 사용되지 않습니다. 시간 세부사항은 향후 업데이트될 수 있습니다.
일괄 처리 내 중복 신고
집계 가능한 보고서의 shared_info 필드에는 report_id 필드에 UUID가 포함되어 있으며, 이 UUID는 일괄 처리 내에서 중복된 보고서를 식별하는 데 사용됩니다. 배치에 동일한 report_id가 포함된 보고서가 두 개 이상 있으면 첫 번째 보고서만 집계되고 다른 보고서는 중복으로 간주되어 자동으로 삭제됩니다. 집계는 정상적으로 진행되고 오류가 전송되지 않습니다.
필수는 아니지만 광고 기술은 집계 전에 동일한 보고서 ID를 사용하는 중복 보고서를 필터링하면 일부 성능 향상을 기대할 수 있습니다.
report_id는 보고서마다 고유합니다.
여러 일괄 처리에서 중복된 신고
각 보고서에는 공유 ID가 할당됩니다. 공유 ID는 보고서의 shared_info 필드에서 가져온 결합된 데이터 포인트에서 생성된 ID입니다. 여러 보고서에서 동일한 공유 ID를 가질 수 있으며 각 배치는 여러 공유 ID를 포함할 수 있습니다. 공유 ID가 동일한 모든 보고서는 동일한 일괄 처리에 포함되어야 합니다. 공유 ID가 동일한 보고서가 여러 일괄 처리에 포함되는 경우 첫 번째 일괄 처리만 수락되고 나머지는 중복으로 거부됩니다. 이를 방지하려면 일괄 처리를 적절하게 만들어야 합니다.
다음 이미지는 여러 일괄 처리에 동일한 공유 ID가 있는 보고서로 인해 이후 일괄 처리가 실패할 수 있는 예를 보여줍니다. 이미지에서 공유 ID e679aa가 동일한 보고서 2개 이상이 서로 다른 일괄 처리 #1 및 #2로 일괄 처리된 것을 볼 수 있습니다. 공유 ID e679aa가 있는 모든 보고서의 예산은 일괄 처리 1의 요약 보고서 생성 중에 소진되므로 일괄 처리 2는 허용되지 않고 오류가 발생하여 실패합니다.
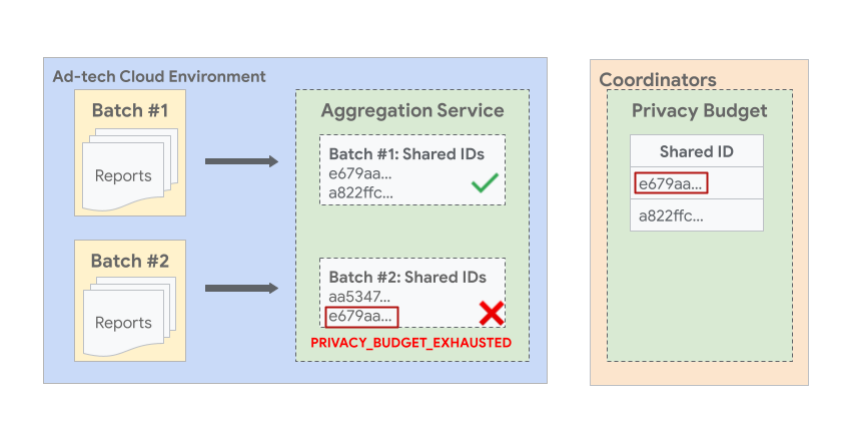
일괄 보고서
다음은 중복을 방지하고 집계 보고서 회계를 최적화하기 위해 보고서를 일괄 처리하는 데 권장되는 방법입니다.
광고주별 일괄 처리
참고: 이 전략은 기여 분석 보고서 집계에만 권장됩니다.
비공개 집계에는 광고주인 attribution_destination 필드가 없습니다. 각 배치의 집계 가능한 보고서 계정 한도가 초과되지 않도록 하려면 광고주별로 일괄 처리하는 것이 좋습니다. 즉, 단일 광고주에 속한 보고서를 동일한 배치에 포함합니다. 광고주는 공유 ID 생성 시 고려되는 필드이므로 동일한 광고주가 있는 보고서에는 동일한 공유 ID가 있을 수 있습니다. 따라서 오류를 방지하려면 동일한 일괄 처리에 있어야 합니다.
시간별 일괄 처리
일괄 처리할 때는 보고서의 예약된 보고서 시간(shared_info.scheduled_report_time)을 고려하는 것이 좋습니다. 예약된 보고서 시간은 공유 ID 생성 시 시간으로 잘리므로 최소한 보고서는 시간 간격으로 일괄 처리되어야 합니다. 즉, 동일한 시간 내에 예약된 보고서 시간이 있는 모든 보고서가 동일한 일괄 처리에 포함되어야 합니다. 그렇지 않으면 여러 일괄 처리에 동일한 공유 ID가 있는 보고서가 포함되어 작업 오류가 발생합니다.
일괄 빈도 및 노이즈
집계 가능한 보고서가 처리되는 빈도에 미치는 노이즈의 영향을 고려하는 것이 좋습니다. 집계 가능한 보고서가 더 자주 일괄 처리되는 경우(예: 보고서가 1시간에 한 번 처리됨) 전환 이벤트가 더 적게 포함되고 노이즈가 상대적으로 더 큰 영향을 미칩니다. 빈도가 줄어들고 보고서가 일주일에 한 번 처리되면 노이즈의 영향이 비교적 적습니다. 노이즈가 배치에 미치는 영향을 더 잘 이해하려면 Noise Lab을 사용하여 실험하세요.