في الوقت الحالي، يمكنك الآن من خلال "خدمة التجميع" معالجة قياسات معيّنة بمعدّلات مختلفة من خلال الاستفادة من أرقام تعريف الفلترة. يمكن الآن تمرير معرّفات الفلترة عند إنشاء مهمة في خدمة التجميع على النحو التالي:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
لاستخدام عملية الفلترة هذه، ننصحك بالبدء من واجهات برمجة تطبيقات عملاء القياس (Attribution Reporting API أو Private Aggregation API) وإدخال أرقام تعريف الفلترة. وسيتم تمريرها إلى "خدمة التجميع" المنشورة، حتى يعرض تقرير الملخّص النهائي النتائج التي تمّت فلترتها على النحو المتوقّع.
إذا كنت قلقًا بشأن مدى تأثير ذلك في ميزانيتك، لن يتمّ استخدام ميزانية حساب التقارير المجمّعة إلّا لفلترة أرقام التعريف المحدّدة في job_parameters للتقارير. بهذه الطريقة، ستتمكّن من إعادة تنفيذ المهام للتقارير نفسها مع تحديد أرقام تعريف فلترة مختلفة بدون مواجهة أخطاء استنزاف الميزانية.
يوضّح المسار التالي كيفية الاستفادة من ذلك في Private Aggregation API وShared Storage API وAggregation Service في السحابة الإلكترونية العامة.
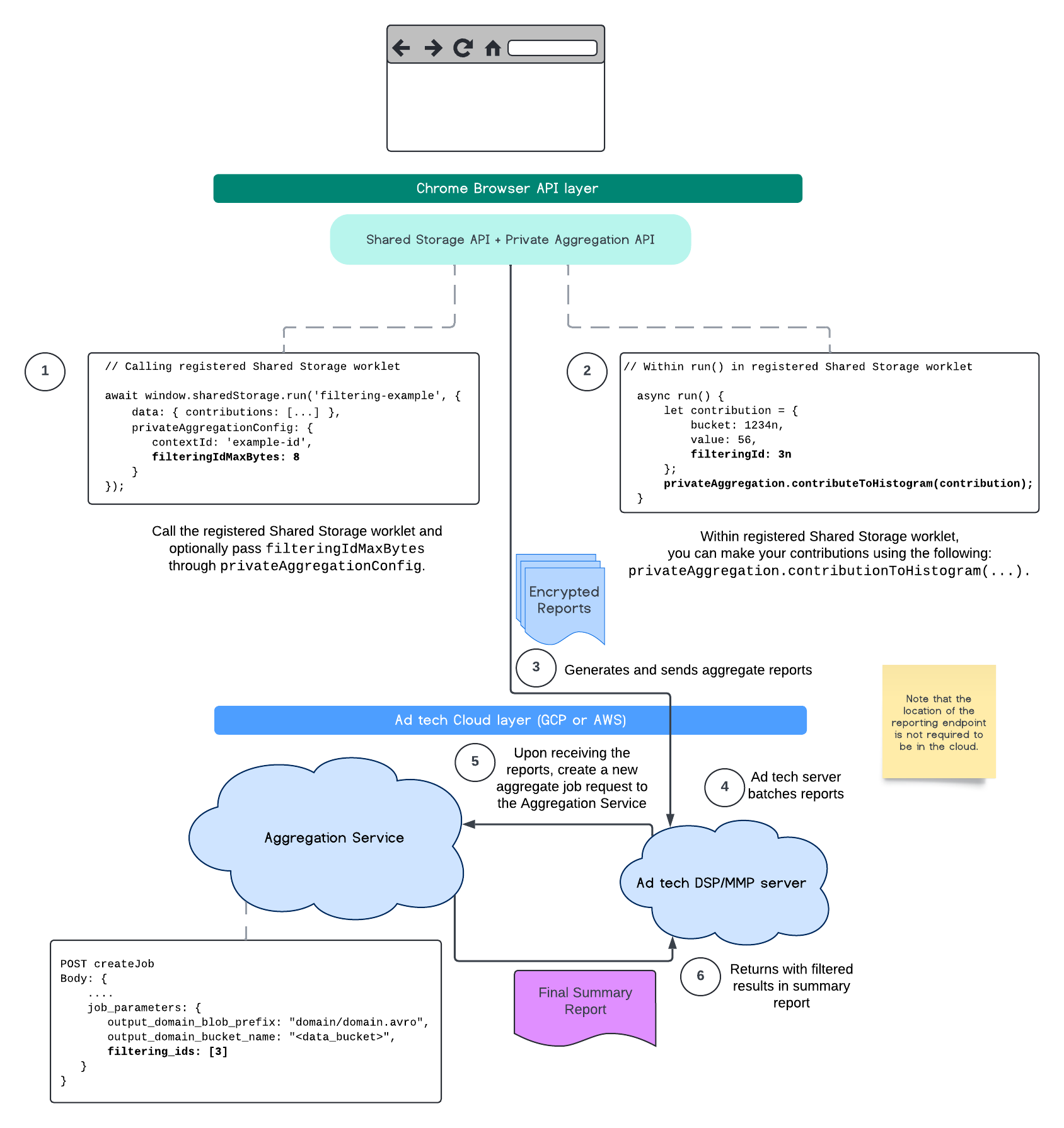
يوضّح هذا المسار كيفية الاستفادة من فلترة الأرقام التعريفية باستخدام Attribution Reporting API ووصولاً إلى خدمة التجميع في السحابة الإلكترونية العامة.

للاطّلاع على مزيد من المعلومات، يمكنك الاطّلاع على الشرح المفصّل لواجهة برمجة التطبيقات Attribution Reporting API والشرح المفصّل لواجهة برمجة التطبيقات Private Aggregation API، بالإضافة إلى الاقتراح الأوّلي.
يمكنك الانتقال إلى قسمَي Attribution Reporting API أو Private Aggregation API للاطّلاع على شرح أكثر تفصيلاً. يمكنك الاطّلاع على مزيد من المعلومات عن نقطتَي النهاية createJob وgetJob في مستندات Aggregation Service API.