Mit dem Aggregationsdienst können Sie jetzt bestimmte Messwerte mithilfe von Filter-IDs in unterschiedlichen Intervallen verarbeiten. Filter-IDs können jetzt bei der Joberstellung in Ihrem Aggregationsdienst so übergeben werden:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
Wenn Sie diese Filterimplementierung verwenden möchten, sollten Sie mit den APIs für Messclients (Attribution Reporting API oder Private Aggregation API) beginnen und Ihre Filter-IDs übergeben. Diese werden an Ihren bereitgestellten Aggregationsdienst übergeben, damit der endgültige Zusammenfassungsbericht die erwarteten gefilterten Ergebnisse enthält.
Wenn Sie wissen möchten, wie sich das auf Ihr Budget auswirkt, wird das Gesamtbudget Ihres Berichtskontos nur für die Filterung von IDs verwendet, die in Ihrer job_parameters für Berichte angegeben sind. So können Sie Jobs für dieselben Berichte noch einmal mit anderen Filter-IDs ausführen, ohne dass Fehler auftreten, die auf ein ausgeschöpftes Budget zurückzuführen sind.
Im folgenden Ablauf wird dargestellt, wie Sie dies in der Private Aggregation API, der Shared Storage API und bis zum Aggregation Service in Ihrer öffentlichen Cloud nutzen können.
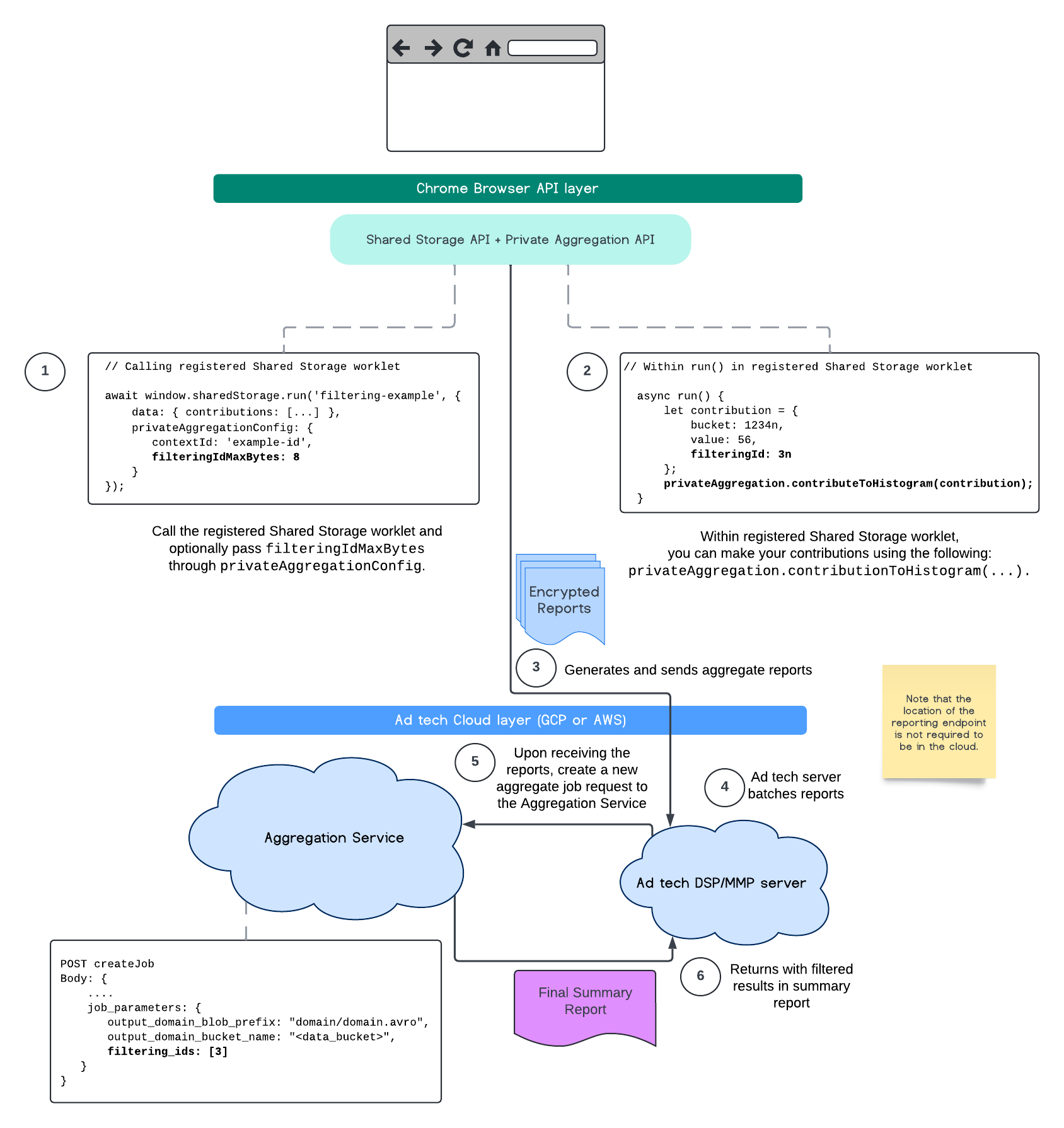
In diesem Ablauf wird dargestellt, wie Sie IDs mit der Attribution Reporting API filtern und bis zum Aggregation Service in Ihrer öffentlichen Cloud weiterleiten.

Weitere Informationen finden Sie in den Erläuterungen zur Attribution Reporting API und zur Private Aggregation API sowie im ursprünglichen Vorschlag.
Weitere Informationen finden Sie in den Abschnitten Attribution Reporting API oder Private Aggregation API. Weitere Informationen zu den Endpunkten createJob und getJob finden Sie in der Dokumentation zur Aggregation Service API.