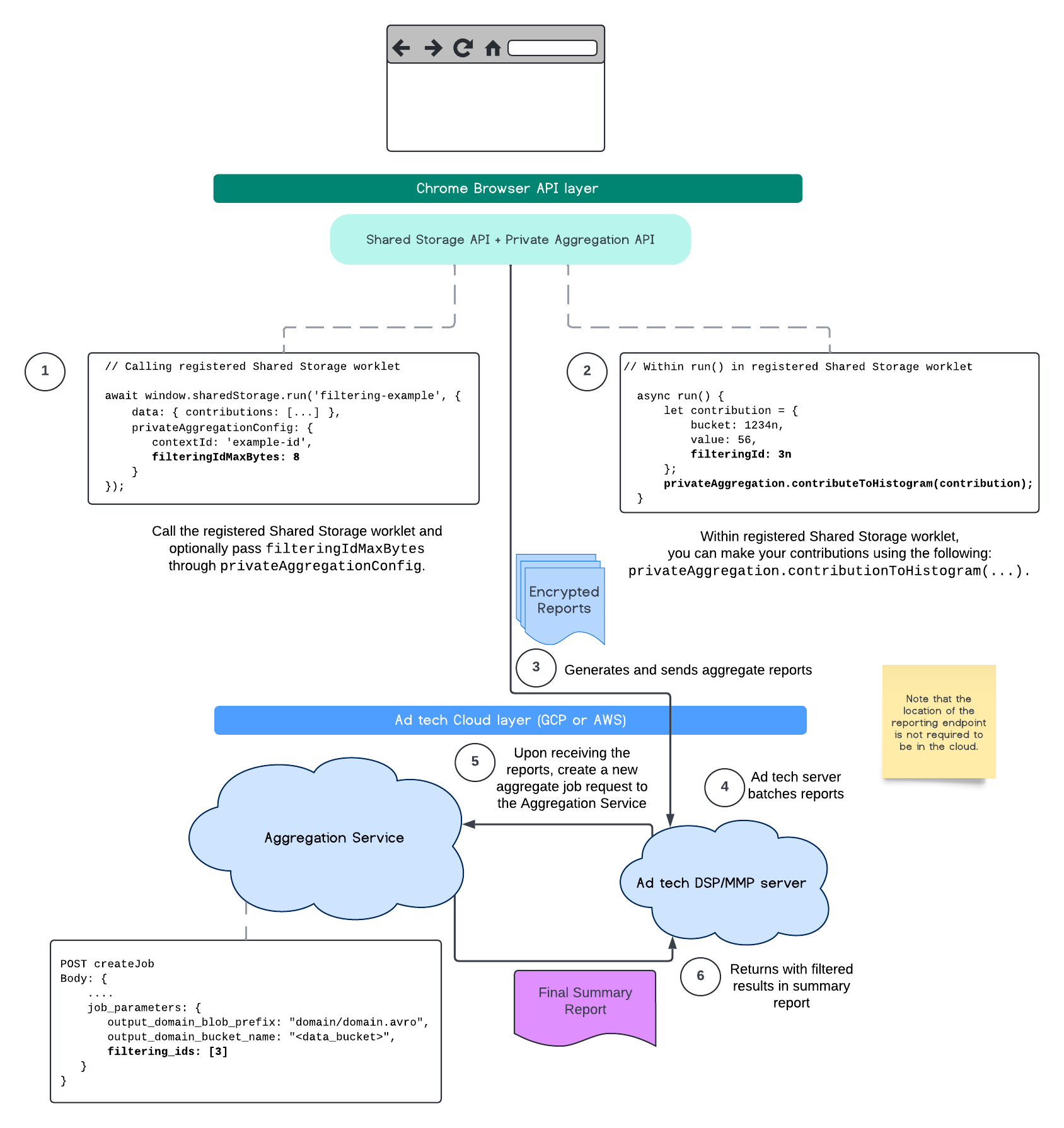
En este momento, con el servicio de agregación, puedes procesar ciertas mediciones en diferentes cadencias aprovechando los IDs de filtrado. Los IDs de filtrado ahora se pueden pasar en la creación de trabajos dentro de tu servicio de agregación de la siguiente manera:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
Para usar esta implementación de filtrado, se recomienda comenzar desde las APIs de cliente de medición (API de Attribution Reporting o API de Private Aggregation) y pasar tus IDs de filtrado. Se pasarán a tu servicio de agregación implementado para que tu informe de resumen final muestre los resultados filtrados esperados.
Si te preocupa cómo esto afectará tu presupuesto, ten en cuenta que el presupuesto de tu cuenta de informes agregados solo se consumirá para filtrar los IDs que se especifican en tu job_parameters para los informes. De esta manera, podrás volver a ejecutar trabajos para los mismos informes especificando diferentes IDs de filtrado sin encontrar errores de agotamiento del presupuesto.
En el siguiente flujo, se muestra cómo puedes usar esto en la API de Private Aggregation, la API de Shared Storage y hasta el servicio de agregación en tu nube pública.
En este flujo, se muestra cómo usar los IDs de filtrado con la API de Attribution Reporting y hasta el servicio de agregación en tu nube pública.

Para obtener más información, consulta la explicación de la API de Attribution Reporting y la explicación de la API de Private Aggregation, así como la propuesta inicial.
Continúa con nuestras secciones de la API de Attribution Reporting o de la API de Private Aggregation para obtener una explicación más detallada. Puedes obtener más información sobre los extremos createJob y getJob en la documentación de la API de Aggregation Service.