À l'heure actuelle, avec le service d'agrégation, vous pouvez traiter certaines mesures à différentes fréquences en utilisant des ID de filtrage. Vous pouvez désormais transmettre des ID de filtrage lors de la création d'une tâche dans votre service d'agrégation comme suit:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
Pour utiliser cette implémentation de filtrage, nous vous recommandons de commencer par les API clientes de mesure (API Attribution Reporting ou API Private Aggregation) et de transmettre vos ID de filtrage. Ils seront transmis à votre service d'agrégation déployé afin que votre rapport récapitulatif final renvoie les résultats filtrés attendus.
Si vous vous demandez comment cela affectera votre budget, sachez que le budget de votre compte de rapports agrégé ne sera utilisé que pour les ID de filtrage spécifiés dans votre job_parameters pour les rapports. Vous pourrez ainsi réexécuter des tâches pour les mêmes rapports en spécifiant différents ID de filtrage sans rencontrer d'erreurs d'épuisement du budget.
Le flux suivant montre comment vous pouvez utiliser cette fonctionnalité dans l'API Private Aggregation, l'API Shared Storage et le service d'agrégation de votre cloud public.
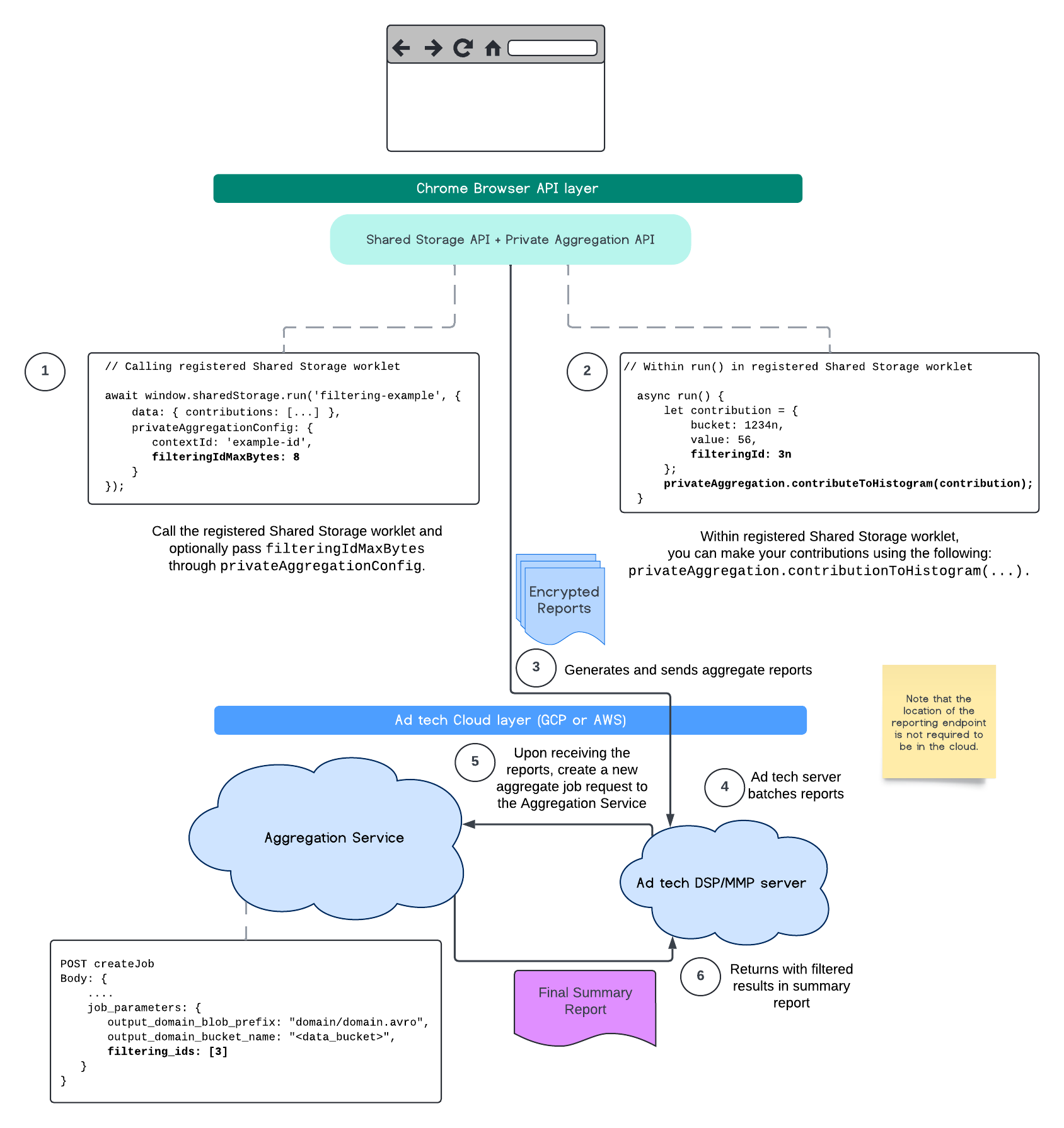
Ce flux explique comment utiliser les ID de filtrage avec l'API Attribution Reporting et le service d'agrégation dans votre cloud public.

Pour en savoir plus, consultez la présentation de l'API Attribution Reporting et la présentation de l'API Private Aggregation, ainsi que la proposition initiale.
Pour en savoir plus, consultez les sections API Attribution Reporting ou API Private Aggregation. Pour en savoir plus sur les points de terminaison createJob et getJob, consultez la documentation de l'API Aggregation Service.