עכשיו, בעזרת שירות האגרגציה, אפשר לעבד מדידות מסוימות בקצב שונה באמצעות שימוש במזהי סינון. מעכשיו אפשר להעביר את המזהים לסינון בזמן יצירת המשימה בשירות הצבירה באופן הבא:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
כדי להשתמש בהטמעת הסינון הזו, מומלץ להתחיל מממשקי ה-API של לקוחות המדידה (Attribution Reporting API או Private Aggregation API) ולהעביר את מזהי הסינון. הנתונים האלה יועברו לשירות הצבירה שנפרס, כך שדוח הסיכום הסופי יחזיר את התוצאות המסוננות הצפויות.
אם אתם מודאגים מההשפעה של השינוי הזה על התקציב, התקציב של חשבון הדוחות המצטבר ינוצל רק לסינון מזהי חשבונות שצוינו ב-job_parameters של הדוחות. כך תוכלו להריץ מחדש משימות של אותם דוחות עם מזהי סינון שונים, בלי להיתקל בשגיאות של מיצוי התקציב.
התהליך הבא מראה איך אפשר להשתמש בכך ב-Private Aggregation API, ב-Shared Storage API וב-Aggregation Service בענן הציבורי.
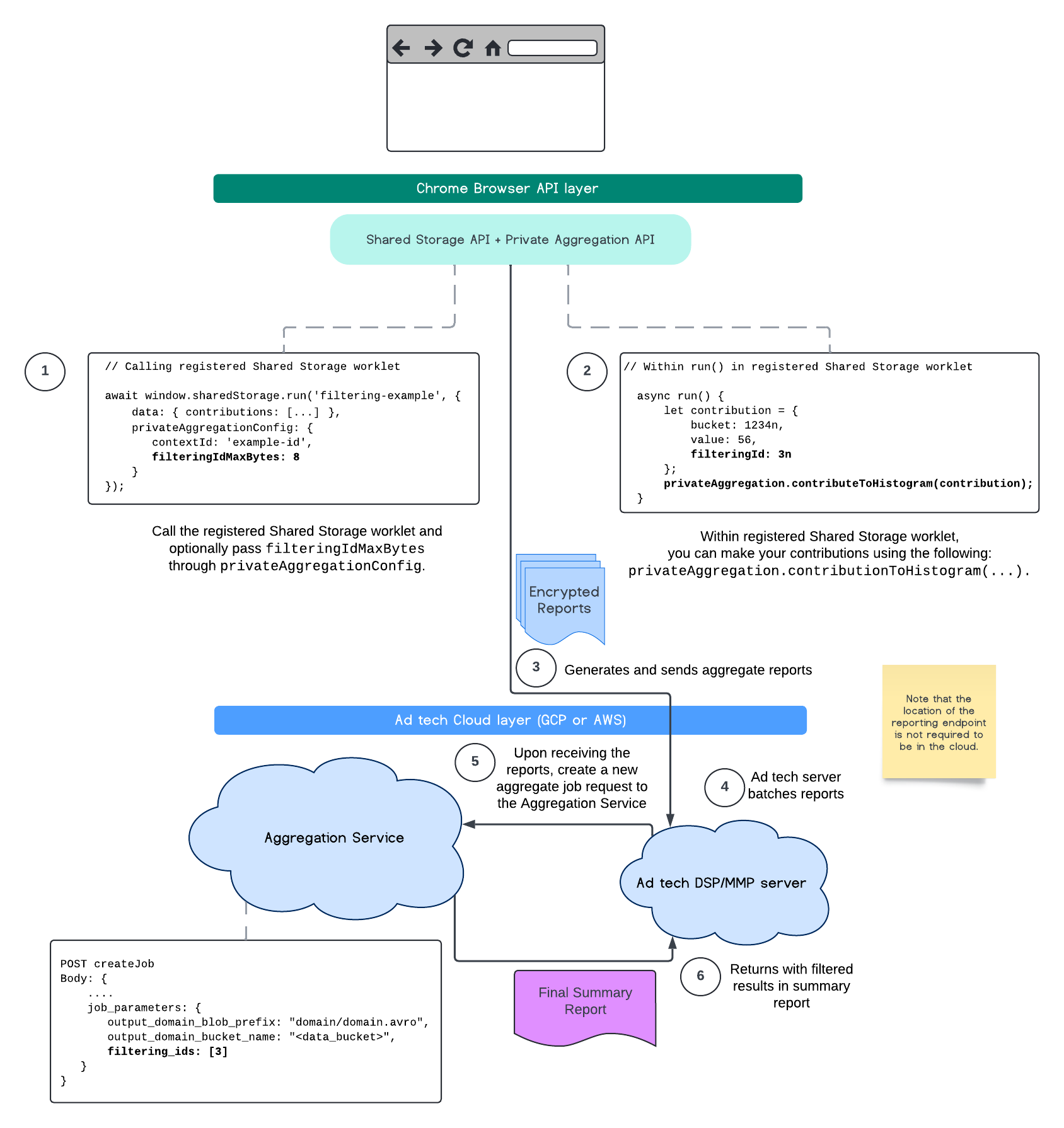
התהליך הזה מתאר איך משתמשים בפילטרים של מזהי Attribution Reporting API ועד ל-Aggregation Service בענן הציבורי.

למידע נוסף, אפשר לעיין בהסבר על Attribution Reporting API ובהסבר על Private Aggregation API, וגם בהצעה הראשונית.
מידע מפורט יותר זמין בקטעים Attribution Reporting API או Private Aggregation API. מידע נוסף על נקודות הקצה createJob ו-getJob זמין במסמכי התיעוד של Aggregation Service API.