Saat ini, dengan Layanan Agregasi, Anda kini dapat memproses pengukuran tertentu pada ritme yang berbeda dengan memanfaatkan ID pemfilteran. ID pemfilteran kini dapat diteruskan saat pembuatan tugas dalam Layanan Agregasi seperti ini:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
Untuk menggunakan implementasi pemfilteran ini, sebaiknya mulai dari API klien pengukuran (Attribution Reporting API atau Private Aggregation API) dan teruskan ID pemfilteran Anda. Data ini akan diteruskan ke Layanan Agregasi yang di-deploy, sehingga laporan ringkasan akhir Anda akan ditampilkan kembali dengan hasil yang difilter sesuai harapan.
Jika Anda khawatir dengan pengaruhnya terhadap anggaran, anggaran akun laporan gabungan Anda hanya akan digunakan untuk memfilter ID yang ditentukan dalam job_parameters untuk laporan. Dengan cara ini, Anda dapat menjalankan ulang tugas untuk laporan yang sama yang menentukan ID pemfilteran yang berbeda tanpa mengalami error kehabisan anggaran.
Alur berikut menggambarkan cara Anda dapat memanfaatkannya dalam Private Aggregation API, Shared Storage API, dan hingga Aggregation Service di cloud publik Anda.
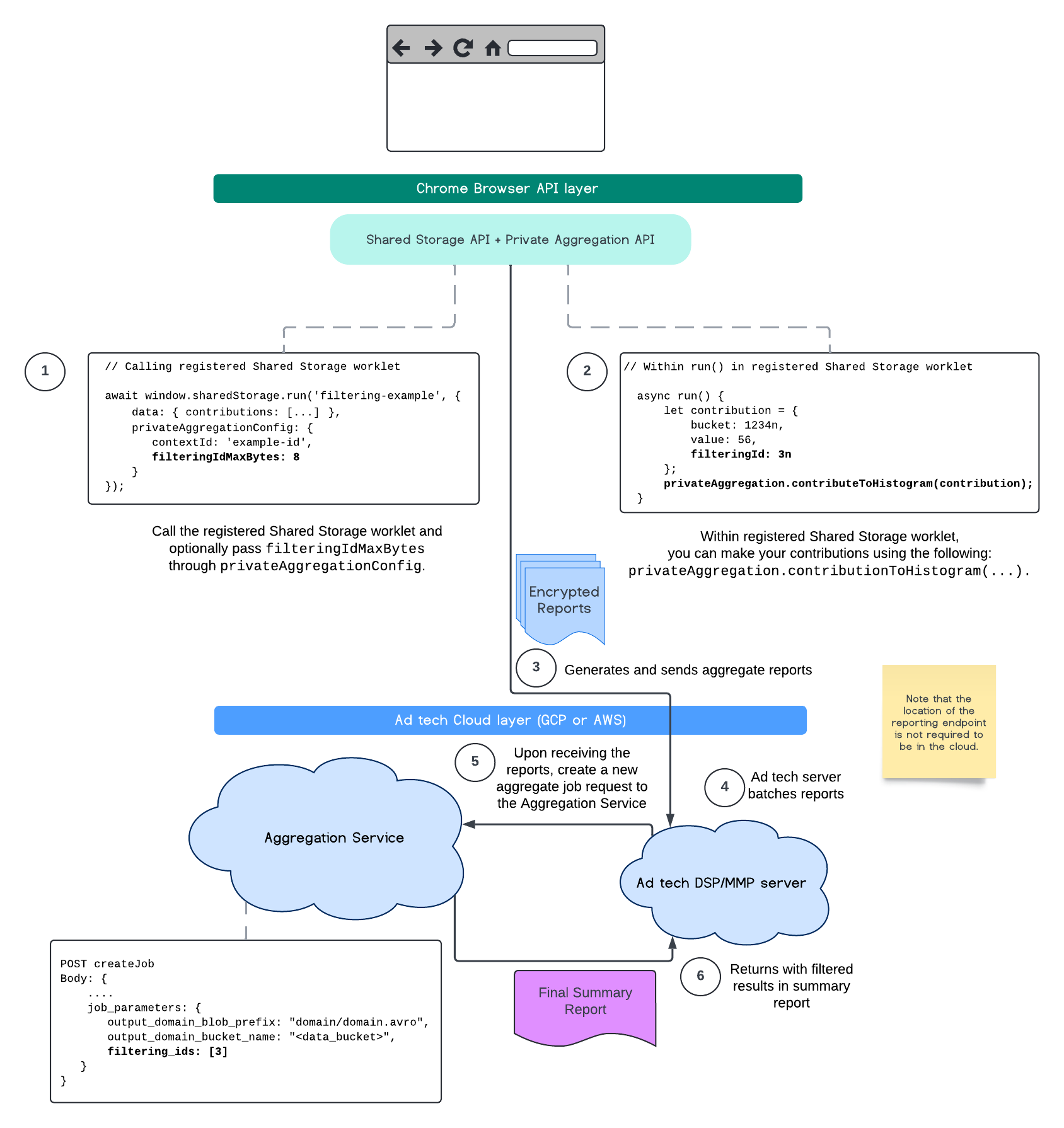
Alur ini menggambarkan cara menggunakan ID pemfilteran dengan Attribution Reporting API dan melalui Layanan Agregasi di cloud publik Anda.

Untuk bacaan lebih lanjut, lihat penjelasan Attribution Reporting API dan penjelasan Private Aggregation API, serta proposal awal.
Lanjutkan ke bagian Attribution Reporting API atau Private Aggregation API untuk membaca penjelasan yang lebih mendetail. Anda dapat membaca selengkapnya tentang endpoint createJob dan getJob di dokumentasi Aggregation Service API.