В настоящее время с помощью Службы агрегирования вы можете обрабатывать определенные измерения с разной частотой, используя идентификаторы фильтрации. Идентификаторы фильтрации теперь можно передавать при создании заданий в вашей службе агрегации следующим образом:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
Чтобы использовать эту реализацию фильтрации, рекомендуется начать с клиентских API для измерения ( API Attribution Reporting API или Private Aggregation API ) и передать свои идентификаторы фильтрации. Они будут переданы в развернутую службу агрегирования, и окончательный сводный отчет вернется с ожидаемыми отфильтрованными результатами.
Если вас беспокоит, как это повлияет на ваш бюджет, совокупный бюджет аккаунта отчета будет использоваться только для фильтрации идентификаторов, указанных в параметре job_parameters для отчетов. Таким образом, вы сможете повторно запускать задания для тех же отчетов, указав разные идентификаторы фильтрации, не сталкиваясь с ошибками исчерпания бюджета.
В следующем потоке показано, как вы можете использовать это в API частной агрегации , API общего хранилища и в службе агрегации в общедоступном облаке.
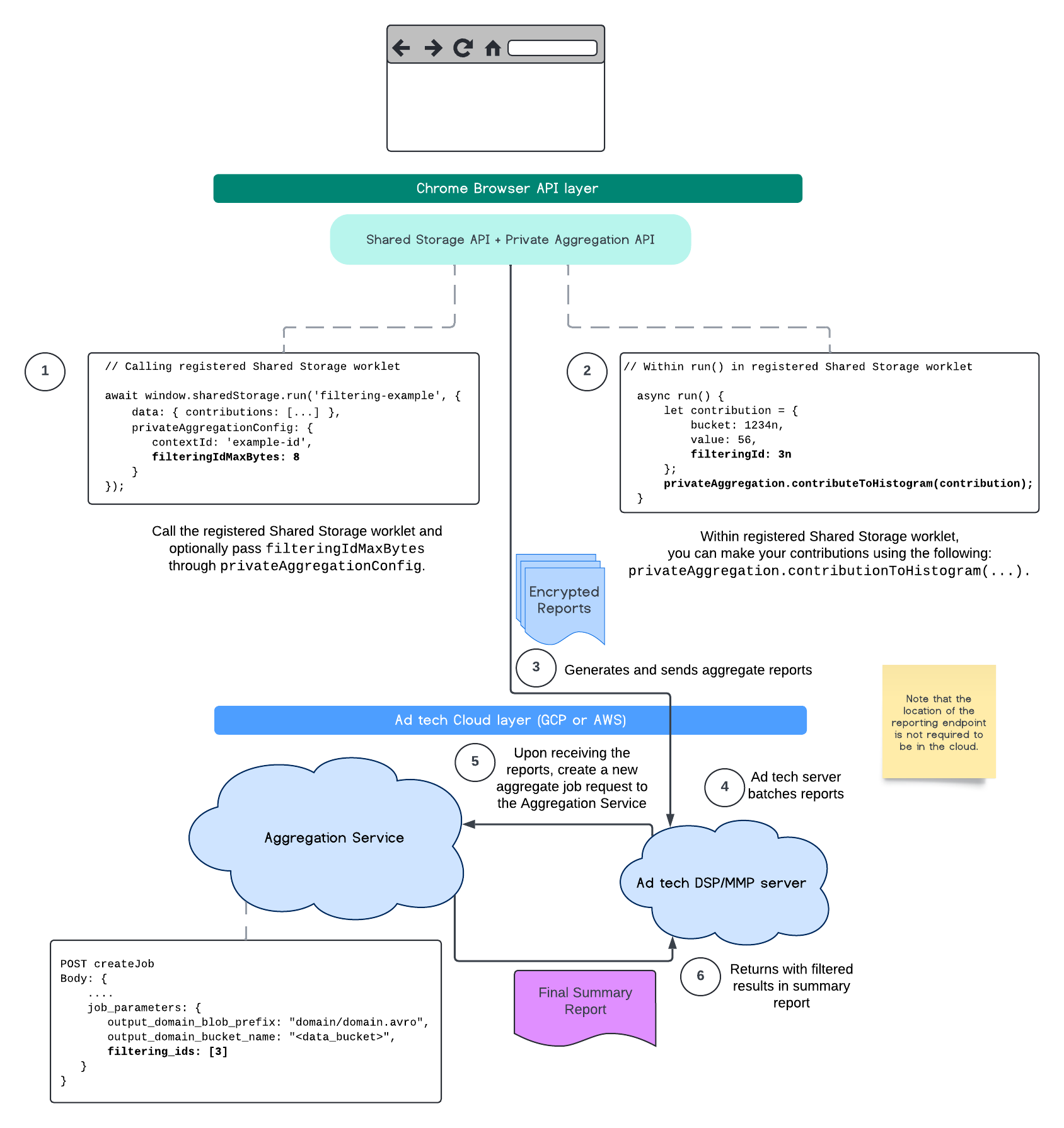
В этом потоке показано, как использовать идентификаторы фильтрации с API отчетов об атрибуции и через службу агрегации в общедоступном облаке.

Для дальнейшего чтения ознакомьтесь с объяснением API отчетов об атрибуции и объяснением API частного агрегирования , а также с первоначальным предложением .
Перейдите к разделам API отчетов по атрибуции или API частного агрегирования, чтобы получить более подробную информацию об учетной записи. Подробнее о конечных точках createJob и getJob можно прочитать в документации по API Aggregation Service .