Şu anda, toplama hizmetini kullanarak filtreleme kimliklerinden yararlanarak belirli ölçümleri farklı ritimlerde işleyebilirsiniz. Filtreleme kimlikleri artık Toplama Hizmetiniz içinde iş oluşturma işlemi sırasında aşağıdaki gibi iletilebilir:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
Bu filtreleme uygulamasını kullanmak için ölçüm istemci API'lerinden (Attribution Reporting API veya Private Aggregation API) başlamanız ve filtreleme kimliklerinizi iletmeniz önerilir. Bunlar, dağıtılan toplama hizmetinize iletilir. Böylece nihai özet raporunuz, beklenen filtrelenmiş sonuçlarla döndürülür.
Bunun bütçenizi nasıl etkileyeceği konusunda endişeleriniz varsa birleştirilmiş rapor hesabı bütçeniz yalnızca raporlar için job_parameters içinde belirtilen kimlikleri filtrelemek amacıyla kullanılır. Bu sayede, bütçe tükenme hatalarıyla karşılaşmadan aynı raporlar için farklı filtreleme kimlikleri belirterek işleri yeniden çalıştırabilirsiniz.
Aşağıdaki akışta, bu özelliği Private Aggregation API, Shared Storage API ve herkese açık bulutunuzdaki Aggregation Service'te nasıl kullanabileceğiniz gösterilmektedir.
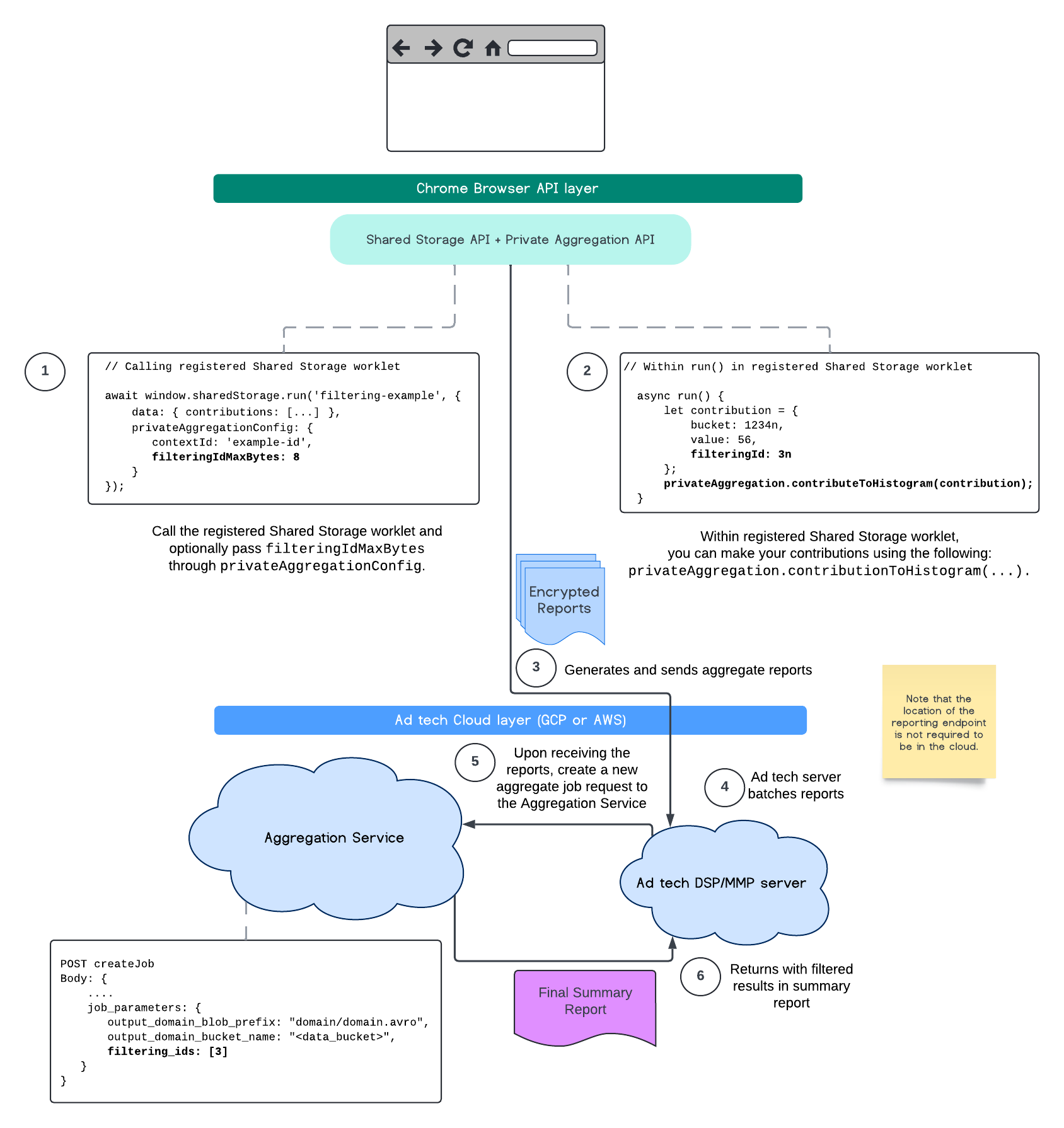
Bu akış, İlişkilendirme Raporlama API'si ile filtreleme kimliklerinin nasıl kullanılacağını ve genel bulutunuzdaki Toplama Hizmeti'ne nasıl aktarılacağını gösterir.

Daha fazla bilgi için Attribution Reporting API açıklama ve Private Aggregation API açıklama bölümlerinin yanı sıra ilk teklifi inceleyin.
Daha ayrıntılı bilgi edinmek için Attribution Reporting API veya Private Aggregation API bölümlerimize göz atın. createJob ve getJob uç noktaları hakkında daha fazla bilgiyi Aggregation Service API belgelerinde bulabilirsiniz.