篩選 ID 指南
目前,您可以使用匯總服務,透過篩選 ID 以不同頻率處理特定評估。您現在可以在匯總服務中,在建立工作時傳遞篩選 ID,如下所示:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
如要使用這個篩選導入方式,建議您從評估用戶端 API (Attribution Reporting API 或 Private Aggregation API) 開始,並傳入篩選 ID。這些值會傳遞至已部署的匯總服務,讓最終摘要報表傳回預期的篩選結果。
如果您擔心這會對預算造成影響,請注意,匯總報表帳戶的預算只會用於篩選報表中指定的 job_parameters。這樣一來,您就能針對指定不同篩選 ID 的相同報表重新執行作業,而不會發生預算用盡的錯誤。
以下流程圖說明如何在Private Aggregation API、Shared Storage API 和公用雲端的Aggregation Service 中使用這項功能。
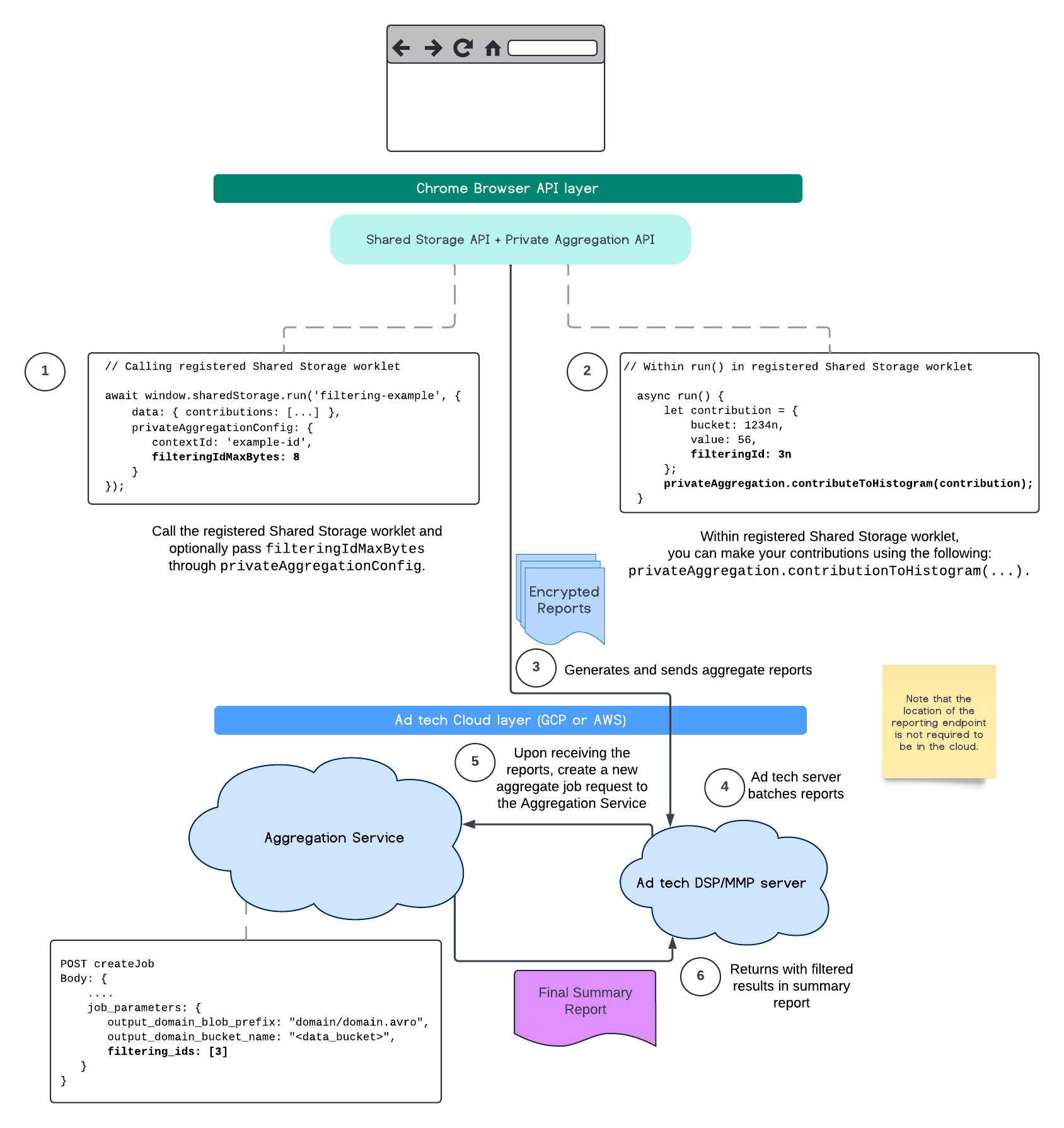
這項流程說明如何使用 Attribution Reporting API 和匯總服務,在公用雲端中篩選 ID。

如需進一步瞭解,請參閱 Attribution Reporting API 說明和 Private Aggregation API 說明,以及最初的提案。
如要進一步瞭解相關資訊,請繼續閱讀「Attribution Reporting API」或「Private Aggregation API」相關章節。如要進一步瞭解 createJob 和 getJob 端點,請參閱 Aggregation Service API 說明文件。
除非另有註明,否則本頁面中的內容是採用創用 CC 姓名標示 4.0 授權,程式碼範例則為阿帕契 2.0 授權。詳情請參閱《Google Developers 網站政策》。Java 是 Oracle 和/或其關聯企業的註冊商標。
上次更新時間:2024-12-05 (世界標準時間)。
[null,null,["上次更新時間:2024-12-05 (世界標準時間)。"],[[["The Aggregation Service now allows processing certain measurements at different cadences using filtering IDs."],["Filtering IDs are specified during job creation to control which data is included in the aggregated reports."],["Budgets are only consumed for filtering IDs specified in the job parameters, enabling flexible report generation without budget exhaustion."],["This functionality is integrated with the Attribution Reporting API and Private Aggregation API for flexible data processing."],["Detailed documentation and explainers are available for further information on implementation and usage."]]],["The Aggregation Service now supports processing measurements at different cadences using filtering IDs. These IDs, passed during job creation, specify which data to include. Filtering IDs are initiated via the Attribution Reporting or Private Aggregation APIs. Budget is only consumed for specified filtering IDs, allowing job reruns with different IDs. This process is facilitated through the Private Aggregation and Shared Storage APIs, as well as with the Attribution Reporting API, flowing through to the Aggregation Service.\n"]]