מידע על המסמך הזה
בעקבות קריאת המסמך הזה:
- חשוב להבין אילו אסטרטגיות כדאי ליצור לפני שיוצרים דוחות סיכום.
- להכיר את Noise Lab, כלי שעוזר להבין את ההשפעות של פרמטרים שונים של רעשים, ומאפשר זיהוי והערכה מהירים של אסטרטגיות שונות לניהול רעשים.
משתפים משוב
המסמך הזה מסכם כמה עקרונות לעבודה עם דוחות סיכום, יש כמה גישות לניהול רעשים שלא באות לידי ביטוי כאן. הצעות, תוספות ושאלות יתקבלו בברכה.
- כדי לשלוח משוב ציבורי על אסטרטגיות לניהול רעשים, צריך להפעיל את הפרטיות או השימושיות של ה-API (epsilon), ולשתף את התצפיות שלכם כאשר הדמיה באמצעות Noise Lab: להגיב על הבעיה
- כדי לתת משוב ציבורי על Noise Lab (לשאול שאלה, לדווח על באג, שליחת בקשה להוספת תכונה): כאן אפשר לדווח על בעיה חדשה
- כדי לשלוח משוב ציבורי על היבט אחר של ה-API: כאן אפשר לדווח על בעיה חדשה
לפני שמתחילים
- למבוא, מומלץ לקרוא את המאמרים דוחות שיוך (Attribution): דוחות סיכום וסקירה כללית על המערכת המלאה בדוחות שיוך (Attribution).
- כדי לנצל את המדריך הזה בצורה הטובה ביותר, קראו את המאמרים הסבר על רעשים והסבר על מפתחות צבירה.
החלטות לגבי העיצוב
עקרון עיצוב הליבה
יש הבדלים בסיסיים בין האופן שבו קובצי cookie של צד שלישי לבין דוחות סיכום פועלים. הבדל מרכזי אחד הוא נוסף רעש לנתוני המדידה בדוחות הסיכום. ההבדל השני הוא האופן שבו מתזמנים דוחות.
כדי לגשת לנתוני המדידה של הדוח הסיכום עם אות לרעש גבוה יותר פלטפורמות בצד הביקוש (DSP) וספקי מדידת ביצועים של מודעות יצטרכו לעבוד עם המפרסמים שלהם כדי לפתח אסטרטגיות לניהול רעשים. כדי לפתח את האסטרטגיות האלה, ספקי DSP וספקי מדידה צריכים לקבל החלטות לגבי העיצוב. ההחלטות האלה עוסקות בקונספט מרכזי אחד:
ערכי הרעש של ההתפלגות נקבעים לפיהם, אבל באופן מוחלט תלוי רק בשני פרמטרים⏤epsilon ובתקציב לתרומות⏤דרך כלל אמצעי בקרה נוספים שישפיעו על יחסי האות לרעש של נתוני מדידת הפלט.
אנחנו צופים שתהליך איטרטיבי יוביל להחלטות הכי טובות, אבל כל שינוי בהחלטות האלה יוביל להוביל ליישום שונה מעט - לכן יש לקבל החלטות אלה לפני כתיבת כל איטרציה של הקוד (ולפני הצגת המודעות).
החלטה: רמת הפירוט של המאפיין
כדאי לנסות ב-Noise Lab
- עוברים למצב Advanced.
- בחלונית הצדדית 'פרמטרים', מחפשים את הקטע 'נתוני ההמרות שלך'.
- חשוב להקפיד על הפרמטרים שמוגדרים כברירת מחדל. כברירת מחדל, הערך TOTAL היומי מספר ההמרות שניתן לשייך הוא 1,000. זה ממוצע של כ-40 קטגוריה, אם משתמשים בהגדרת ברירת המחדל (מאפייני ברירת מחדל, מספר ברירת מחדל ערכים אפשריים שונים לכל מאפיין, אסטרטגיית מפתח א'). שימו לב הערך הוא 40 במספר ההמרות היומי הממוצע שניתן לשייך לכל שובר פרסום.
- לוחצים על 'סימולציה' כדי להפעיל סימולציה עם הפרמטרים שמוגדרים כברירת מחדל.
- בחלונית הצדדית 'פרמטרים', מחפשים את הקטע 'מאפיינים'. שנה שם מיקום גיאוגרפי לעיר ומשנים את מספר הערכים השונים ל-50.
- הנתון הזה משנה את הערך הממוצע של ההמרה היומית הממוצעת לשיוך count PER BUCKET. עכשיו היא הרבה יותר נמוכה. הסיבה לכך היא שאם מספר הערכים האפשריים במאפיין הזה בלי לשנות אותו בכל דבר אחר, אפשר להגדיל את מספר הקטגוריות הכולל בלי לשנות כמה אירועי המרה ייכללו בכל קטגוריה.
- לוחצים על 'הדמיה'.
- חשוב לשים לב ליחסי הרעש בסימולציה שמתקבלת: יחסי הרעש גבוהה יותר מאשר בסימולציה הקודמת.
בהתאם לעיקרון העיצוב הבסיסי, סביר להניח שערכי סיכום קטנים יותר רועשים מערכי סיכום גדולים. לכן, הבחירה שלכם משפיעה על מספר אירועי ההמרה המשויכים שמגיעים בסופו של דבר בכל קטגוריה (אחרת נקרא מפתח הצבירה שלך), והכמות משפיעה על הרעש דוחות סיכום הפלט.
החלטה אחת בתכנון שמשפיעה על מספר אירועי ההמרה המשויכים בקטגוריה אחת היא רמת הפירוט של המאפיין. ריכזנו כאן כמה דוגמאות של מפתחות צבירה והמאפיינים שלהם:
- גישה 1: מבנה מפתח אחד עם מידות משוער: מדינה x קמפיין פרסום (או הקמפיין הגדול ביותר) קטגוריית צבירה) x סוג המוצר (מתוך 10 סוגי מוצרים אפשריים)
- גישה 2: מבנה מפתח אחד עם מאפיינים מפורטים: עיר x מזהה קריאייטיב x מוצר (מתוך 100 מוצרים אפשריים)
עיר הוא מאפיין מפורט יותר מאשר מדינה. מזהה הקריאייטיב מפורט יותר מאשר קמפיין. וProduct הוא מפורט יותר מאשר סוג המוצר. לכן, גישה 2 תכלול מספר נמוך יותר של אירועים (המרות) לכל קטגוריה (= מפתח) בפלט דוח הסיכום שלו מאשר גישה 1. בהתחשב בעובדה שהרעש שנוסף הפלט מיוצג באמצעות מספר האירועים בקטגוריה, נתוני המדידה בדוחות הסיכום יהיו רועשים יותר עם גישה 2. לכל מפרסם כדאי לנסות סוגים שונים של איזון רמת פירוט בעיצוב המפתח כדי להפיק תועלת מרבית בין התוצאות.
החלטה: מבני מפתח
כדאי לנסות ב-Noise Lab
במצב הפשוט, נעשה שימוש במבנה ברירת המחדל של המפתחות. בעמודה 'מתקדם' תוכלו להתנסות במבנים שונים של מפתחות. כמה מאפיינים לדוגמה כלולים; אפשר גם לשנות אותם.
- עוברים למצב Advanced.
- בחלונית הצדדית 'פרמטרים', מחפשים את האפשרות 'אסטרטגיית מפתחות'. תצפית שאסטרטגיית ברירת המחדל, שנקראת A בכלי, משתמשת במפתח מפורט אחד מבנה שכולל את כל המאפיינים: מיקום גיאוגרפי x מזהה קמפיין x מוצר בקטגוריה שלכם.
- לוחצים על 'הדמיה'.
- חשוב לשים לב ליחסי הרעש בסימולציה שמתקבלת.
- משנים את אסטרטגיית המפתחות ל-B. פעולה זו מציגה פקדים נוספים כדי שאפשר יהיה להגדיר את מבנה המפתחות.
- צריך להגדיר את מבנה המפתח, למשל ככה:
- מספר מבני המפתחות: 2
- מבנה מפתח 1 = מיקום גיאוגרפי x קטגוריית מוצר.
- מבנה מפתח 2 = מזהה קמפיין x קטגוריית מוצר.
- לוחצים על 'הדמיה'.
- לתשומת ליבכם: עכשיו אתם מקבלים שני דוחות סיכום לכל סוג יעד מדידה (שניים לספירת רכישות, שניים לערך רכישה), בהינתן שאתה משתמש שני מבני מפתח נפרדים. חשוב לבדוק את יחסי הרעשים שלהם.
- אפשר גם לנסות את זה עם מאפיינים מותאמים אישית משלכם. כדי לעשות זאת, צריך לחפש לגבי נתונים שאחריהם רוצים לעקוב: מימדים. כדאי להסיר את הדוגמה וליצור מאפיינים משלכם באמצעות האפשרויות 'הוספה/הסרה/איפוס' לחצנים מתחת למאפיין האחרון.
החלטה נוספת בנוגע לעיצוב שתשפיע על מספר ההמרות המשויכות אירועים בקטגוריה אחת הם מבני מפתחות שמחליטים להשתמש בו. מומלץ להביא בחשבון את הדוגמאות הבאות למפתחות צבירה:
- מבנה מפתח אחד עם כל המאפיינים; אפשר לקרוא לאסטרטגיית המפתח הזו א'.
- שני מבנים מרכזיים, שלכל אחד מהם יש קבוצת משנה של מאפיינים; כדאי לקרוא לזה אסטרטגיית מפתח ב.
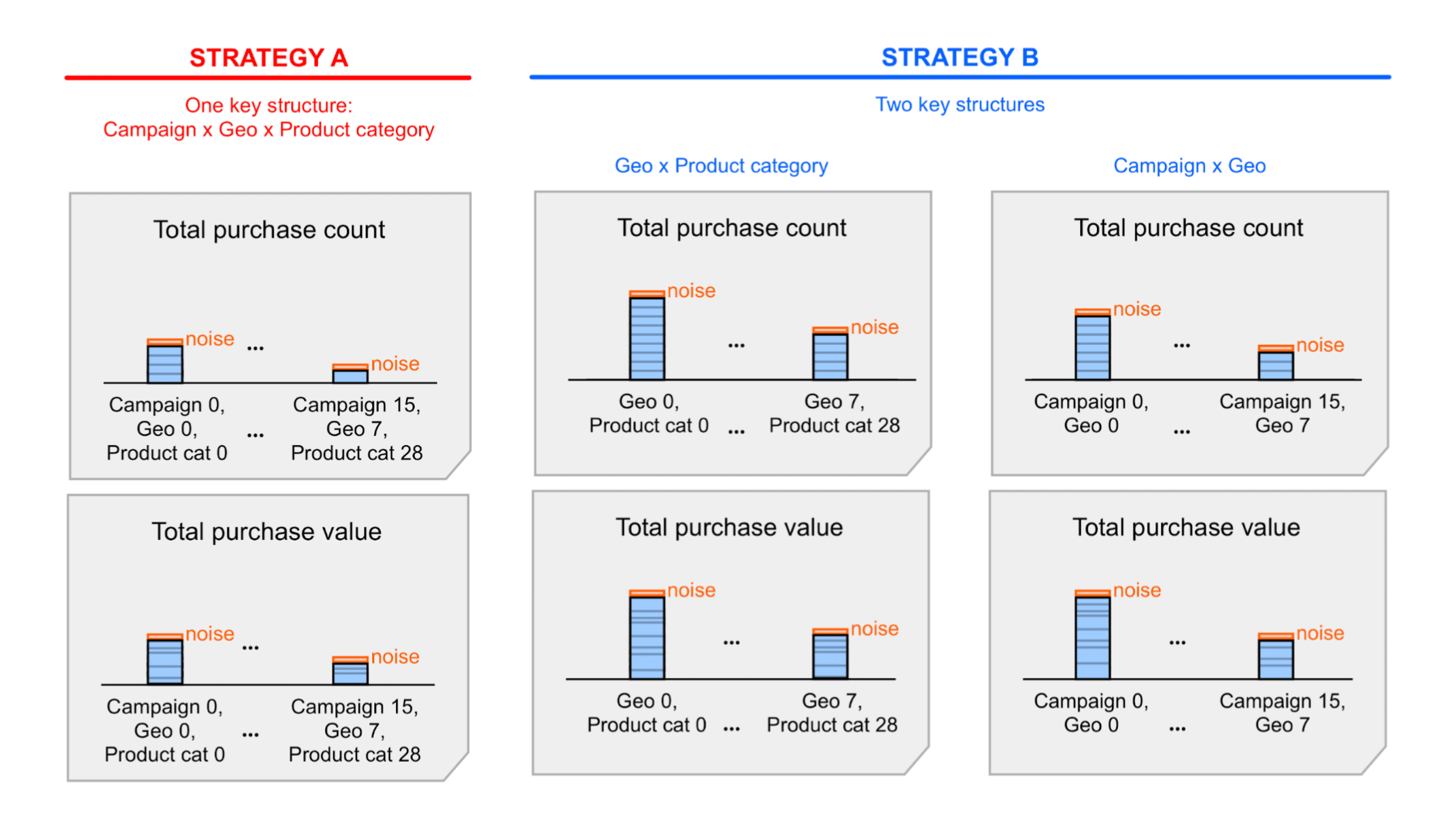
שיטה א' פשוטה יותר – אבל ייתכן שתצטרכו לאסוף (לסכם) את ערכי הסיכום עם רמת הרעש כלולים דוחות סיכום כדי לגשת לתובנות מסוימות. באמצעות סיכום הערכים האלה, מקבלים גם את סיכום הרעש. עם שיטה ב', ערכי הסיכום מוצגים בסיכום ייתכן שהדוחות כבר מספקים לך את המידע הדרוש. המשמעות היא שאסטרטגיה ב' סביר להניח שהיא תוביל ליחסי אות לרעש טובים יותר מאשר שיטה א'. אבל, ייתכן ש"רעש" כבר מקובל עם שיטה א', כך שעדיין תוכלו להחליט אסטרטגיה א' לפשטות. מידע נוסף זמין בדוגמה המפורטת שמפרטת את שתי האסטרטגיות האלה.
ניהול מפתחות הוא נושא עמוק. אפשר לבצע כמה שיטות מורכבות לשיפור יחסי האות לרעש. אחת מהן מתוארת בקטע מקש מתקדם ניהול.
החלטה: תדירות הקיבוץ
כדאי לנסות ב-Noise Lab
- לעבור למצב פשוט (או למצב מתקדם - שני המצבים פועלים) באותו אופן כשמדובר בתדירות קיבוץ)
- בחלונית הצדדית 'פרמטרים', מחפשים את אסטרטגיית הצבירה 'שלך' > תדירות הקיבוץ. מתייחס לתדירות הקיבוץ של דוחות נצברים שמעובדים באמצעות שירות הצבירה עבודה אחת.
- חשוב לבדוק את תדירות ברירת המחדל של קיבוץ הקבצים: כברירת מחדל, קיבוץ יומי של נתונים נערכת סימולציה.
- לוחצים על 'הדמיה'.
- חשוב לשים לב ליחסי הרעש בסימולציה שמתקבלת.
- משנים את תדירות הקיבוץ באצווה לשבועית.
- חשוב לשים לב ליחסי הרעש בסימולציה שמתקבלת: יחסי הרעש נמוכה יותר (טובה יותר) מהסימולציה הקודמת.
החלטה נוספת בנוגע לעיצוב שתשפיע על מספר ההמרות המשויכות אירועים בקטגוריה יחידה היא תדירות הקיבוץ באצווה שבה אתם מחליטים להשתמש. תדירות קיבוץ הנתונים היא התדירות שבה אתם מעבדים דוחות נצברים.
דוח שמתוזמן לצבירת נתונים בתדירות גבוהה יותר (למשל, בכל שעה) כוללים פחות אירועי המרה מאשר אותו דוח, אבל בתדירות נמוכה יותר. לוח זמנים לצבירת נתונים (למשל, כל שבוע). כתוצאה מכך, הדוח השעתי יכלול יותר "רעש".`` כוללים פחות אירועי המרה מאשר אותו דוח, אבל בתדירות נמוכה יותר. לוח זמנים לצבירת נתונים (למשל, כל שבוע). כתוצאה מכך, הדוח השעתי יחס אות לרעש נמוך יותר מהדוח השבועי, כך שכל שאר התנאים זהים. כדאי להתנסות בדרישות הדיווח בתדירויות שונות, ולבדוק את יחסי האות לרעש בכל אחת מהן.
מידע נוסף זמין ב- קיבוץ באצווה וצבירה לאורך תקופות ארוכות יותר.
החלטה: משתני הקמפיין שמשפיעים על המרות שניתן לשייך
כדאי לנסות ב-Noise Lab
אמנם קשה לחזות את זה, וייתכנו שינויים משמעותיים בנוסף להשפעות עונתיות, נסו להעריך את מספר ההמרות היומיות המרות שניתן לשייך מנגיעה אחת לעוצמה הקרובה ביותר של 10: 10, 100, 1,000 או 10,000.
- עוברים למצב Advanced.
- בחלונית הצדדית 'פרמטרים', מחפשים את הקטע 'נתוני ההמרות שלך'.
- חשוב להקפיד על הפרמטרים שמוגדרים כברירת מחדל. כברירת מחדל, הערך TOTAL היומי מספר ההמרות שניתן לשייך הוא 1,000. זה ממוצע של כ-40 קטגוריה, אם משתמשים בהגדרת ברירת המחדל (מאפייני ברירת מחדל, מספר ברירת מחדל ערכים אפשריים שונים לכל מאפיין, אסטרטגיית מפתח א'). שימו לב הערך הוא 40 במספר ההמרות היומי הממוצע שניתן לשייך לכל שובר פרסום.
- לוחצים על 'סימולציה' כדי להפעיל סימולציה עם הפרמטרים שמוגדרים כברירת מחדל.
- חשוב לשים לב ליחסי הרעש בסימולציה שמתקבלת.
- עכשיו מגדירים את TOTAL ההמרות היומיות לשיוך כ-100. חשוב לבדוק שהפעולה הזו מקטינה את הערך של הממוצע היומי הממוצע שניתן לשייך במספר ההמרות לכל BUCKET.
- לוחצים על 'הדמיה'.
- שימו לב שיחסי הרעש גבוהים עכשיו: הסיבה לכך היא שכאשר שיהיו פחות המרות לכל קטגוריה, יותר רעש יושג פרטיות.
הבחנה חשובה היא המספר הכולל של המרות אפשריות לעומת המספר הכולל של המרות מיוחסות אפשריות. האחרונה היא הגורם שבסופו של דבר משפיע על הרעש בדוחות הסיכום. משויך המרות הן קבוצת משנה של סך כל ההמרות שעלולות ליצור קמפיינים משתנים, כגון תקציב מודעות וטירגוט של מודעות. לדוגמה, ניתן לצפות מספר גבוה יותר של המרות משויכות עבור קמפיין פרסום בשווי 10 מיליון דולר לעומת מודעה בשווי 10,000 דולר הקמפיין, כל השאר שווה.
מידע שיש לשקול:
- הערכה של המרות משויכות לפי אינטראקציה אחת באותו מכשיר מודל השיוך (Attribution), מאחר שהם נכללים בהיקף של דוחות הסיכום שנאספים באמצעות Attribution Reporting API.
- כדאי לקחת בחשבון גם את ספירת התרחישים הגרועים ביותר וגם את ספירת התרחישים הטובים ביותר של המרות משויכות. לדוגמה, כל שאר הערכים שווים, תקציבי קמפיין מינימליים ומקסימליים למפרסם, ואז לחזות המרות שניתן לשייך לשתי התוצאות, כקלט סימולציה.
- אם אתם שוקלים להשתמש ארגז החול לפרטיות ב-Android, יש להביא בחשבון המרות משויכות מפלטפורמות שונות במסגרת החישוב.
החלטה: שימוש בהתאמה לעומס (scaling)
כדאי לנסות ב-Noise Lab
- עוברים למצב Advanced.
- בחלונית הצדדית 'פרמטרים', מחפשים את אסטרטגיית הצבירה 'שלך' > הרחבה. כברירת מחדל, ההגדרה היא 'כן'.
- לצורך הבנת ההשפעות החיוביות של התאמה לעומס (scaling) על רעש יחס, תחילה הגדר את 'התאמה' ל'לא'
- לוחצים על 'הדמיה'.
- חשוב לשים לב ליחסי הרעש בסימולציה שמתקבלת.
- הגדרת 'התאמה' ל'כן'. שימו לב ש-Noise Lab מחושב באופן אוטומטי את גורמי קנה המידה שבהם יש להשתמש בהינתן הטווחים (ערכים ממוצעים ומקסימליים) יעדי המדידה לתרחיש שלכם. במערכת אמיתית או בגרסת מקור לניסיון כדאי לבצע חישוב משלכם לכל קנה מידה.
- לוחצים על 'הדמיה'.
- בדיקה שיחסי הרעש נמוכים יותר (טוב יותר) בשנייה סימולציה. הסיבה לכך היא שנעשה שימוש בהתאמה לעומס (scaling).
בהתאם לעקרון העיצוב העיקרי, הרעש שנוסף פונקציה של תקציב התרומה.
לכן, כדי להגדיל את יחסי האות לרעש, תוכלו להחליט שנאספים במהלך אירוע המרה על ידי התאמה שלהם לתרומה (והסרה של שינוי ההיקף שלהם לאחר צבירת נתונים). אפשר להשתמש בהתאמה לעומס כדי להגדיל את יחסי האות לרעש.
החלטה: מספר יעדי המדידה וחלוקת התקציב לפרטיות
הדבר קשור להתאמה לעומס (scaling): חשוב לקרוא את המאמר שימוש ב- התאמה לעומס (scaling).
כדאי לנסות ב-Noise Lab
יעד מדידה הוא נקודה נפרדת על הגרף שנאספת באירועי המרה.
- עוברים למצב Advanced.
- בחלונית הצדדית 'פרמטרים', מחפשים את הנתונים שאחריהם רוצים לעקוב: יעדי מדידה. כברירת מחדל, הגדרתם שני יעדי מדידה: רכישה ולמספר הרכישות.
- לוחצים על 'סימולציה' כדי להפעיל סימולציה עם יעדי ברירת המחדל.
- לוחצים על 'הסרה'. הפעולה הזו תסיר את יעד המדידה האחרון (רכישה) במקרה כזה).
- לוחצים על 'הדמיה'.
- חשוב לבדוק שיחסי הרעש במסגרת ערך הרכישה נמוכים עכשיו (טוב יותר) לסימולציה השנייה. זה כי יש לך פחות מדידה, כך שיעד המדידה היחיד שלכם מקבל עכשיו את כל תקציב לתרומות.
- לוחצים על 'איפוס'. עכשיו יש לכם שוב שני יעדי מדידה: רכישה ולמספר הרכישות. שימו לב ש-Noise Lab מחשב באופן אוטומטי שיש להשתמש בהם בהתאם לטווחים (הערכים הממוצעים והמקסימליים) יעדי מדידה לתרחיש שלכם. כברירת מחדל, Noise Lab מפצל התקציב באופן שווה בין יעדי המדידה.
- לוחצים על 'הדמיה'.
- חשוב לשים לב ליחסי הרעש בסימולציה שמתקבלת. חשוב לשים לב גורמי התאמה לעומס שמוצגים בסימולציה.
- עכשיו נתאים אישית את החלוקה של תקציב הפרטיות כדי לשפר את הביצועים ביחסי אות לרעש.
- לשנות את אחוז התקציב שהוקצה לכל יעד מדידה. בהינתן ברירת המחדל יעד מדידה 1, כלומר ערך רכישה, טווח רחב יותר (בין 0 ל-1,000) מיעד מדידה 2, כלומר מספר הרכישות (בין 1 ל-1, כלומר תמיד שווה ל-1). בגלל במצב כזה נדרש "יותר מקום לקנה המידה": עדיף להקצות יותר תורמות ליעד מדידה 1 מאשר ליעד מדידה 2, כך ניתן להרחיב אותו בצורה יעילה יותר (ראו התאמה),
- מקצים 70% מהתקציב ליעד מדידה 1. מקצים 30% למדידה יעד 2.
- לוחצים על 'הדמיה'.
- חשוב לשים לב ליחסי הרעש בסימולציה שמתקבלת. לרכישה עכשיו יחסי הרעש נמוכים יותר (טוב יותר) באופן משמעותי סימולציה. בספירה של הרכישות, הם כמעט לא השתנו.
- להמשיך לשנות את חלוקת התקציב בין המדדים השונים. תראי איך זה משפיע רעשי רקע.
לתשומת ליבכם: אתם יכולים להגדיר יעדי מדידה בהתאמה אישית משלכם באמצעות הלחצנים הוספה/הסרה/איפוס.
אם אתם מודדים נקודה אחת על הגרף (יעד מדידה) על אירוע המרה, כמו מספר ההמרות. הנקודה על הגרף יכולה לקבל את כל תקציב התרומה (65, 536). אם מגדירים כמה יעדי מדידה באירוע המרה, כמו מספר ההמרות וערך הרכישה, אז נקודות הנתונים האלה יצטרכו לשתף את תקציב התרומה. זה אומר שיש לכם פחות מקום פנוי לשיפור ערכים.
לכן, ככל שיש לכם יותר יעדי מדידה, כך היחסים בין האות לרעש נמוכים יותר. יהיו (רעש גבוה יותר).
החלטה נוספת לגבי יעדי מדידה היא חלוקת התקציב. אם מחלקים את תקציב התרומה באופן שווה בין שתי נקודות על הגרף, כל נקודה על הגרף מקבלת התקציב של 65536/2 = 32768. האפשרות הזו עשויה להיות אופטימלית או לא, בהתאם ערך מקסימלי האפשרי לכל נקודה על הגרף. לדוגמה, אם אתם מודדים ערך רכישה עם ערך מקסימלי 1, וערך רכישה עם בין 1 ל-120, ערך הרכישה יפיקו תועלת "יותר מקום" את הגודל שלו - כלומר, לקבל נתח גדול יותר תקציב לתרומות. יוצגו לכם אם צריך לתת עדיפות ליעדי מדידה מסוימים אחרים ביחס להשפעה של רעש.
החלטה: ניהול גורמים חיצוניים
כדאי לנסות ב-Noise Lab
יעד מדידה הוא נקודה נפרדת על הגרף שנאספת באירועי המרה.
- עוברים למצב Advanced.
- בחלונית הצדדית 'פרמטרים', מחפשים את אסטרטגיית הצבירה 'שלך' > הרחבה.
- ודא ש'התאמה' מוגדרת ל'כן'. לתשומת ליבכם: 'מעבדת רעש' שמחשב באופן אוטומטי את גורמי המידה שבהם יש להשתמש, בהתבסס על הטווחים (הערכים הממוצעים והערכים המקסימליים) שהגדרתם ליעדי המדידה.
- נניח שהרכישה הגדולה ביותר שהתרחשה אי פעם הייתה 2,000$, רוב הרכישות מתבצעות בטווח של 10$-120$. קודם נראה מה קורה אם נשתמש בגישת התאמה מילולית (לא מומלץ): הזן 2,000$ ערך מקסימלי של purchaseValue.
- לוחצים על 'הדמיה'.
- חשוב לוודא שיחסי הרעש גבוהים. הסיבה לכך היא שהתאמת הגודל שמחושב כרגע על סמך 2,000$, כשבפועל וערכי הרכישה יהיו נמוכים משמעותית.
- עכשיו נשתמש בגישה פרגמטית יותר להתאמה לעומס (scaling). שינוי הצעת המחיר המקסימלית כערך הרכישה של 120$.
- לוחצים על 'הדמיה'.
- שימו לב שיחסי הרעש נמוכים (טוב יותר) בסימולציה השנייה.
כדי ליישם התאמה של קנה מידה, בדרך כלל מחשבים גורם קנה מידה על סמך הערך המקסימלי האפשרי לאירוע המרה נתון (מידע נוסף בדוגמה הזו).
עם זאת, הימנעו משימוש בערך מקסימלי מילולי כדי לחשב את גורם הגודל הזה, זה יחמיר את יחסי האות לרעש. במקום זאת, הסירו ערכים של חריג חשוד טעות להשתמש בערך מקסימלי פרגמטי.
ניהול חריגים הוא נושא עמוק. אפשר לבצע כמה שיטות מורכבות לשיפור יחסי האות לרעש. אחת מהן מתוארת ניהול מתקדם של חריגים חשודי טעות.
השלבים הבאים
עכשיו, אחרי שבדקתם אסטרטגיות שונות לניהול רעשים בתרחיש לדוגמה שלכם, ואתם מוכנים להתחיל להתנסות בדוחות סיכום באמצעות איסוף של מדידה דרך גרסת מקור לניסיון. כדאי לעיין במדריכים ובטיפים כדי לנסות את ה-API.
נספח
סיור מהיר במעבדת הרעש
בעזרת Noise Lab אפשר במהירות להעריך ולהשוות אסטרטגיות לניהול רעשים. אפשר להשתמש בה כדי:
- להבין את הפרמטרים העיקריים שיכולים להשפיע על רעש, את ההשפעה שיש להם.
- לבצע סימולציה של השפעת רעש על נתוני מדידת הפלט שניתנו החלטות עיצוב שונות. לשנות את הפרמטרים של העיצוב עד שמגיעים יחס אות לרעש שמתאים לתרחיש לדוגמה שלכם.
- נשמח לקבל מכם משוב לגבי השימוש בדוחות הסיכום: של אפסילון ושל פרמטרים של רעש פועלים בשבילך, ואילו מהם לא? איפה נמצאים את נקודות הפיתוי?
אפשר לחשוב על זה כשלב הכנה. מעבדת רעש יוצרת נתוני מדידה כדי לדמות פלט של דוח סיכום על סמך של הקלט. הוא לא נשמר ולא משתף נתונים.
יש שני מצבים שונים ב-Noise Lab:
- מצב פשוט: הבנת היסודות של אמצעי הבקרה שיש לכם רעשי רקע.
- מצב מתקדם: בדיקה של אסטרטגיות שונות לניהול רעשים והערכה איזה מהם מוביל ליחסי האותות הטובים ביותר לרעש בתרחישים לדוגמה שלכם.
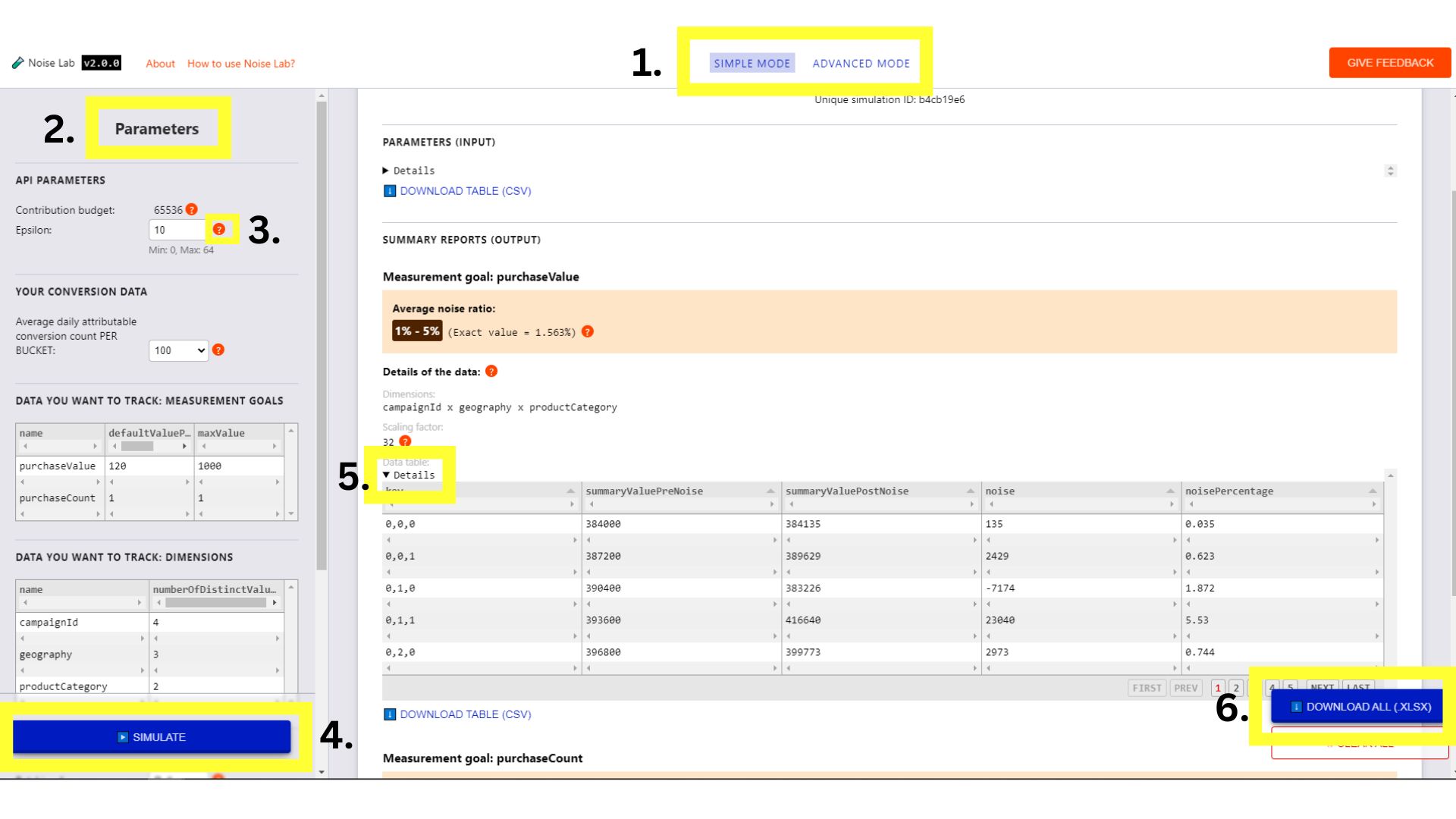
אפשר ללחוץ על הלחצנים בתפריט העליון כדי לעבור בין העיצובים מצבים (מספר 1. בצילום המסך למטה).
מצב פשוט
- במצב פשוט אתם שולטים בפרמטרים (מופיעים בצד שמאל). או #2. בצילום המסך שלמטה, כמו Epsilon, ולראות איך הם משפיעים על רעש.
- לכל פרמטר יש הסבר קצר (לחצן `?`). לחץ על אלה כדי לראות הסבר על כל פרמטר (מס' 3. בצילום המסך למטה)
- כדי להתחיל, לוחצים על "Simulate" לחצן כדי לבדוק איך הפלט נראה לייק (#4. בצילום המסך למטה)
- בקטע 'פלט' אפשר לראות מגוון פרטים. במידה מסוימת ליד הרכיבים יש הסימן '?'. הקדש את הזמן כדי ללחוץ על כל `?` כדי לראות הסבר על הפרטים השונים של המידע.
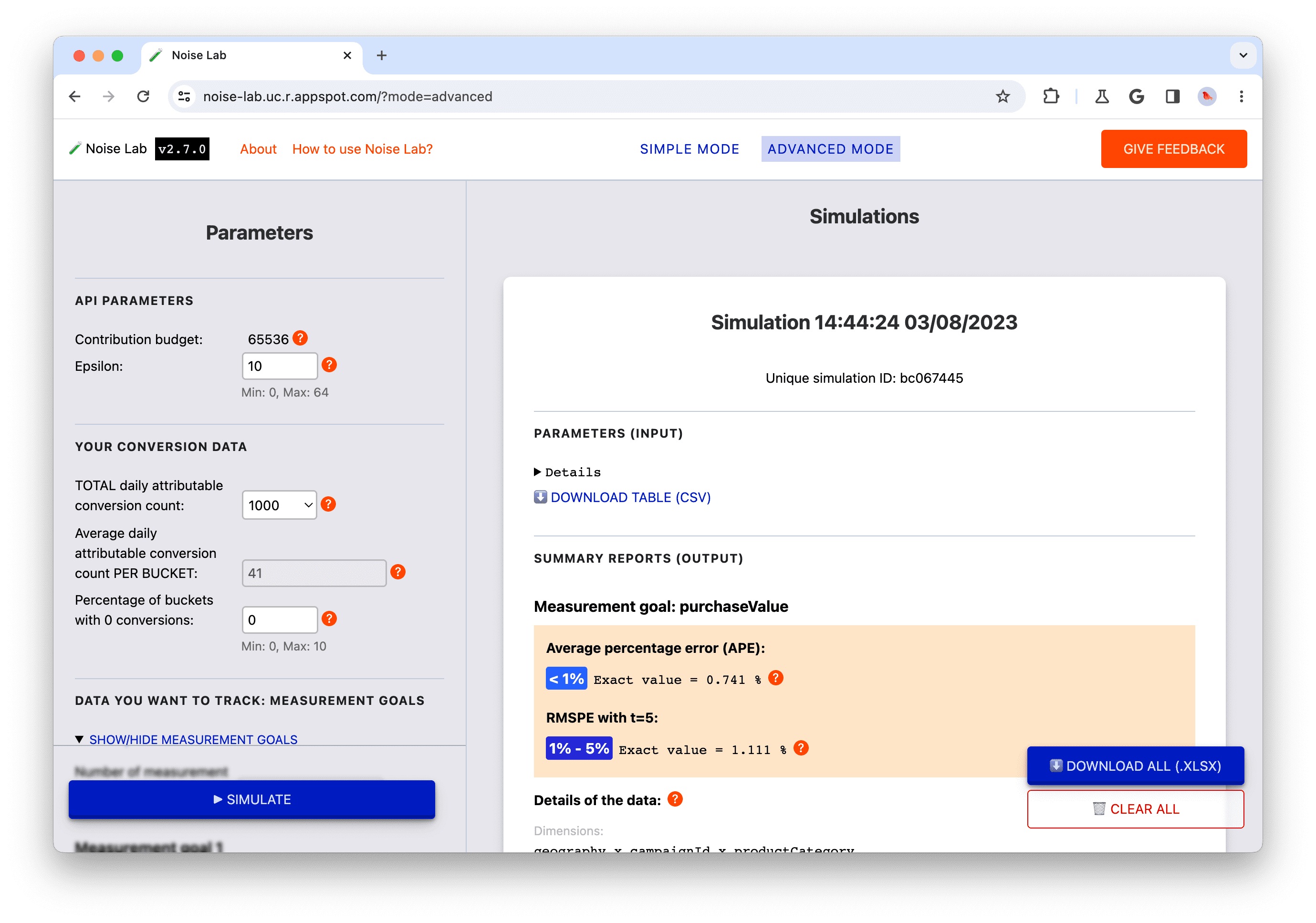
- בקטע 'פלט', לוחצים על המתג 'פרטים'. אם אתם רוצים לראות גרסה מורחבת של הטבלה (מספר 5. בצילום המסך שבהמשך)
- מתחת לכל טבלת נתונים בקטע הפלט, מופיעה אפשרות כדי להוריד את הטבלה לשימוש במצב אופליין. כמו כן, בתחתית בפינה הימנית העליונה, יש אפשרות להוריד את כל טבלאות הנתונים (מס' 6. צילום המסך שלמטה)
- בודקים הגדרות שונות של הפרמטרים בקטע 'פרמטרים'
ולוחצים על 'סימולציה' כדי לראות איך הן משפיעות על הפלט:
ממשק Noise Lab למצב פשוט.
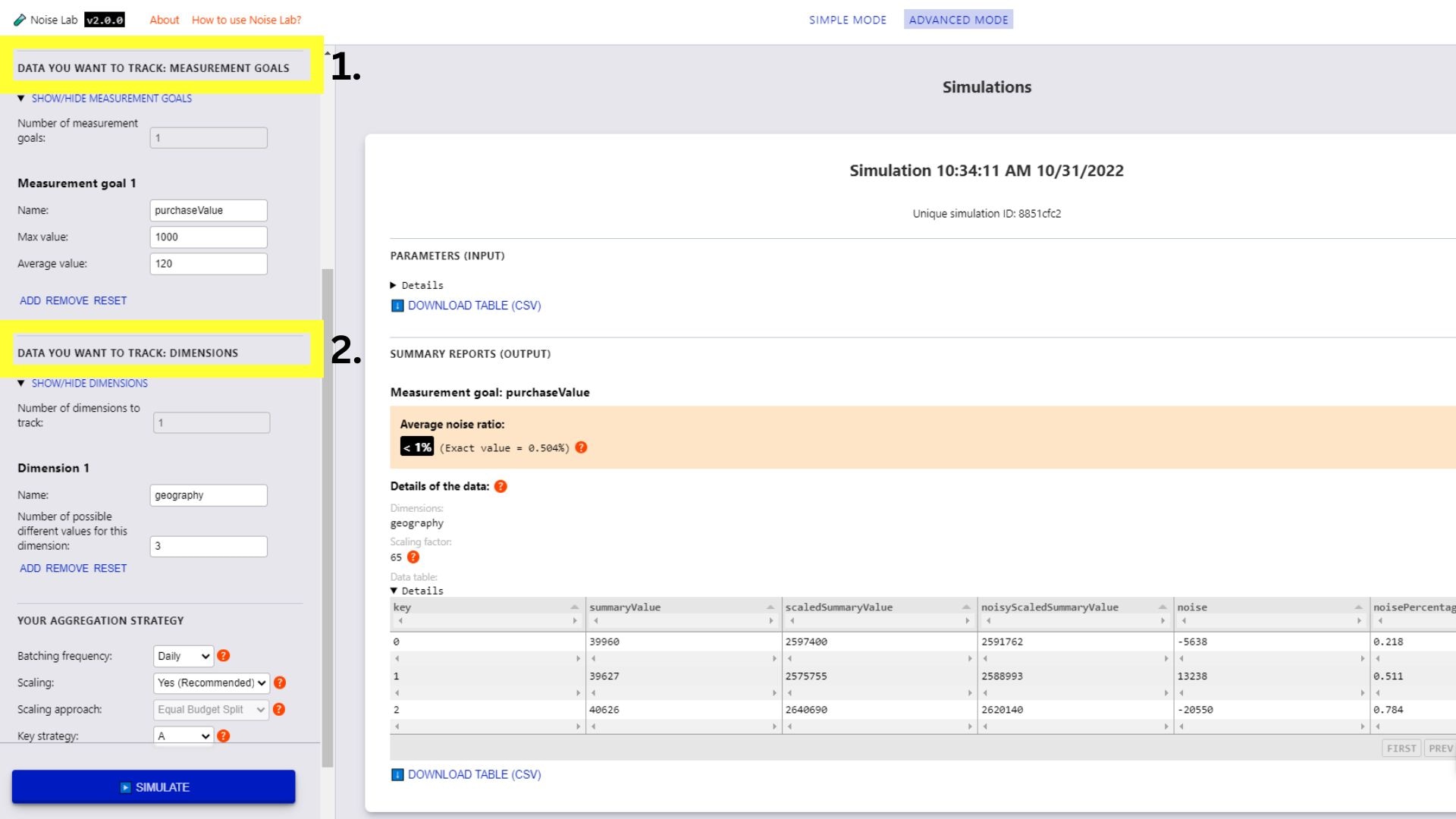
מצב מתקדם
- במצב Advanced יש לכם יותר שליטה על הפרמטרים. שלך יכולים להוסיף יעדים ומימדים מותאמים אישית של מדידה (מספר 1 ו-2. בצילום המסך). שלמטה)
- גוללים למטה בקטע 'פרמטרים' כדי לראות את המפתח.
אפשרות שיטה. אפשר להשתמש כך כדי לבדוק מבנים שונים של מפתחות.
(#3. בצילום המסך למטה)
- כדי לבדוק מבני מפתח שונים, מחליפים את אסטרטגיית המפתח ל-B.
- צריך להזין את מספר מבני המפתחות השונים שבהם רוצים להשתמש (ברירת המחדל היא '2')
- לוחצים על 'יצירת מבני מפתחות'
- תוכלו לראות אפשרויות להגדרת מבני המפתחות באמצעות לחיצה על תיבות הסימון ליד המפתחות שרוצים לכלול בכל מבנה מפתחות.
- לוחצים על Simulate (הדמיה) כדי לראות את הפלט.
ממשק Noise Lab למצב Advanced 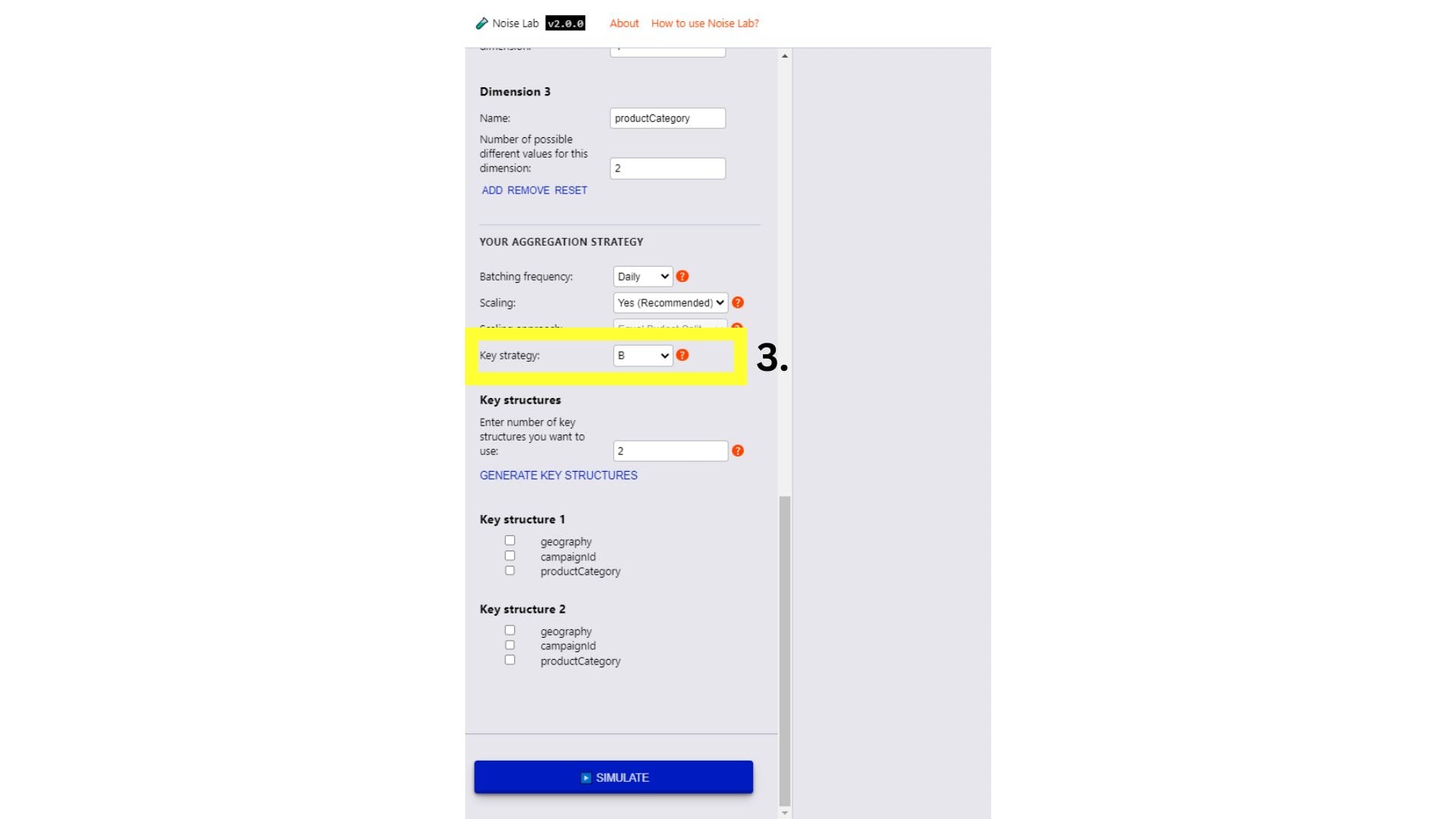
ממשק Noise Lab למצב Advanced
מדדי רעשים
קונספט מרכזי
המערכת מוסיפה רעש כדי להגן על הפרטיות של כל משתמש.
ערך רעש גבוה מצביע על כך שקטגוריות/מפתחות הם מועטים להכיל תכנים שנוספו ממספר מוגבל של אירועים רגישים. סיימתי באופן אוטומטי באמצעות Noise Lab, כדי לאפשר לאנשים "להסתתר בקהל", או בתוך במילים אחרות, מגן על האנשים המוגבלים האלה עם כמות גדולה יותר של נתונים של רעש נוסף.
ערך רעש נמוך מציין שהגדרת הנתונים תוכננה דרך שכבר מאפשרת לאנשים "להסתתר בקהל". המשמעות היא קטגוריות מכילות תרומות ממספר מספיק של אירועים כדי להבטיח הפרטיות של כל משתמש מוגנת.
ההצהרה הזו נכונה גם לגבי אחוז השגיאה הממוצע (APE) ו-RMSRE_T (שגיאה יחסית של שורש כלומר ריבוע עם סף).
APE (אחוז ממוצע של שגיאה)
APE הוא היחס בין הרעש לבין האות, כלומר ערך הסיכום האמיתי.p> ערכי APE נמוכים יותר מעידים על יחס טוב יותר של אות לרעש.
נוסחה
לכל דוח סיכום נתון, APE מחושב באופן הבא:
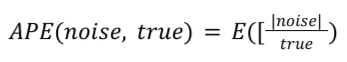
True הוא ערך הסיכום האמיתי. APE הוא ממוצע הרעש בכל ערך סיכום אמיתי, הממוצע של כל הרשומות בדוח סיכום. ב-Noise Lab, הערך הזה מוכפל ב-100 כדי לציין אחוז.
יתרונות וחסרונות
לקטגוריות עם גודל קטן יותר יש השפעה לא פרופורציונלית על הערך הסופי של APE. זה עלול להטעות כשבודקים את הרעש. לכן הוספנו עוד מדד, RMSRE_T, שמטרתו לצמצם את המגבלה הזו של APE. פרטים נוספים זמינים בדוגמאות.
קוד
בודקים את קוד המקור לצורך חישוב APE.
RMSRE_T (שגיאה יחסית של שורש כלומר ריבוע עם סף)
RMSRE_T (שגיאה יחסית של שורש כלומר ריבוע עם סף) הוא מדד נוסף לרעש.
איך לפרש את RMSRE_T
ערכי RMSRE_T נמוכים יותר מציינים יחסי אות לרעש טובים יותר.
לדוגמה, אם יחס הרעשים המקובל בתרחיש לדוגמה שלכם הוא 20%, ו-RMSRE_T הוא 0.2, אתם יכולים להיות בטוחים שרמות הרעש נמצאות בטווח הקביל שלכם.
נוסחה
עבור דוח סיכום נתון, RMSRE_T מחושב באופן הבא:
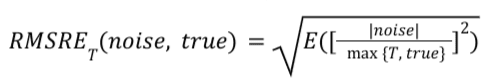
יתרונות וחסרונות
RMSRE_T הוא קצת יותר מורכב להבנה מ-APE. עם זאת, יש לה כמה יתרונות שבמקרים מסוימים, היא מתאימה יותר מ-APE לניתוח רעש בדוחות סיכום:
- RMSRE_T יציב יותר. 'T' הוא סף מינימום. 'T' משמש למתן משקל קטן יותר בחישוב RMSRE_T לקטגוריות שיש להן פחות המרות ולכן הן רגישות יותר לרעשים עקב גודלן הקטן. עם T, המדד לא נמצא בעלייה חדה בקטגוריות עם מעט המרות. אם T שווה ל-5, ערך "רעש" קטן מ-1 בקטגוריה עם 0 המרות לא יוצג כחלק מ-1. במקום זאת, המגבלה תוגבל ל-0.2, כלומר 1/5, כי T שווה ל-5. המדד הזה יציב יותר, ולכן קל יותר להשוות אותו לקטגוריות קטנות יותר שרגישות יותר לרעש.
- RMSRE_T מאפשר צבירת נתונים בקלות. הכרת ה-RMSRE_T של מספר קטגוריות, יחד עם הספירות האמיתיות שלהן, מאפשרת לך לחשב את ה-RMSRE_T של הסכום שלהן. כך אפשר גם לבצע אופטימיזציה ל-RMSRE_T עבור הערכים המשולבים האלה.
אפשר לצבור נתונים ב-APE, אבל הנוסחה מורכבת למדי כי היא כוללת את הערך המוחלט של סכום הרעשים של לפלס. לכן קשה יותר לבצע אופטימיזציה של מומחי המוצרים (APE).
קוד
לעיין בקוד המקור לחישוב RMSRE_T.
דוגמאות
דוח סיכום עם שלוש קטגוריות:
- קטגוריה_1 = רעש: 10, trueSummaryValue: 100
- קטגוריה_2 = רעש: 20, trueSummaryValue: 100
- קטגוריה_3 = רעש: 20, trueSummaryValue: 200
APE = (0.1 + 0.2 + 0.1) / 3 = 13%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,200))^2) / 3) = sqrt( (0.01 + 0.04 + 0.01) / 3) = 0.14
דוח סיכום עם שלוש קטגוריות:
- קטגוריה_1 = רעש: 10, trueSummaryValue: 100
- קטגוריה_2 = רעש: 20, trueSummaryValue: 100
- קטגוריה_3 = רעש: 20, trueSummaryValue: 20
APE = (0.1 + 0.2 + 1) / 3 = 43%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,20))^2) / 3) = sqrt( (0.01 + 0.04 + 1.0) / 3) = 0.59
דוח סיכום עם שלוש קטגוריות:
- קטגוריה_1 = רעש: 10, trueSummaryValue: 100
- קטגוריה_2 = רעש: 20, trueSummaryValue: 100
- קטגוריה_3 = רעש: 20, trueSummaryValue: 0
APE = (0.1 + 0.2 + אינסוף) / 3 = אינסוף
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,0))^2) / 3) = sqrt( (0.01 + 0.04 + 16.0) / 3) = 2.31
ניהול מפתחות מתקדם
לספקי DSP או לחברות למדידת ביצועים של מודעות יש אלפי פרסום גלובלי לקוחות במגוון תחומים, מטבעות ומחיר רכישה הפוטנציאלית. משמעות הדבר היא שיצירה וניהול של מפתח צבירה אחד לכל יהיה מאוד לא פרקטי. בנוסף, מאתגר לבחור ערך מצטבר מקסימלי ותקציב צבירה שיכול להגביל את השפעת הרעש בקרב אלפי המפרסמים ברחבי העולם. במקום זאת, נמחיש את התרחישים הבאים:
אסטרטגיית מפתח א'
ספק הפרסום הדיגיטלי מחליט ליצור ולנהל מפתח אחד בכל הלקוחות שלנו. בכל המפרסמים ובכל המטבעות, הטווח של הרכישות משתנות מנפח נמוך, מרכישות יוקרתיות ועד לנפח גבוה, רכישות. התוצאה תהיה המפתח הבא:
| מפתח (כמה מטבעות) | |
|---|---|
| ערך מצטבר מקסימלי | 5,000,000 |
| טווח של ערך רכישה | [120 - 5000000] |
אסטרטגיית מפתח ב'
ספק הפרסום הדיגיטלי מחליט ליצור ולנהל שני מפתחות בכל הלקוחות שלנו. החברה מחליטים להפריד את המפתחות לפי מטבע. בכל רחבי המפרסמים וכל המטבעות, טווח הרכישות שונה מנפח נמוך, רכישות מתקדמות לרכישות בנפחים גדולים ובעלויות נמוכות. הפרדה לפי מטבע, הם יוצרים 2 מפתחות:
| מפתח 1 (דולר ארה"ב) | מפתח 2 (¥) | |
|---|---|---|
| ערך מצטבר מקסימלי | 40,000$ | 5,000,000¥ |
| טווח של ערך רכישה | [120 - 40,000] | [15,000 - 5,000,000] |
בתוצאה של שיטת מפתח ב' תהיה פחות רעש מאשר בתוצאה של שיטת מפתח א', כי שערכי המטבע אינם מתחלקים באופן אחיד בין מטבעות. לדוגמה, מומלץ להביא בחשבון את האופן שבו רכישות המוצגות ב-¥ משתלבות עם רכישות המוצגות דולר ארה"ב ישנה את הנתונים הבסיסיים ואת תפוקת הרעש שמתקבלת.
אסטרטגיית מפתח ג'
ספק הפרסום הדיגיטלי מחליט ליצור ולנהל ארבעה מפתחות בכל לקוחות הפרסום שלו, ולהפריד ביניהם לפי המטבע x המפרסם ענף:
| מקש 1 (דולר ארה"ב x מפרסמים של תכשיטים יוקרתיים) |
מקש 2 (¥ x מפרסמים של תכשיטים יוקרתיים) |
מקש 3 (דולר ארה"ב x מפרסמים של קמעונאי ביגוד) |
מקש 4 (¥ x מפרסמים של קמעונאי ביגוד) |
|
|---|---|---|---|---|
| ערך מצטבר מקסימלי | 40,000$ | 5,000,000¥ | 2,000 ש"ח | 65,000¥ |
| טווח של ערך רכישה | [10,000 - 40,000] | [1,250,000 - 5,000,000] | [120 - 500] | [15,000 - 65,000] |
בתוצאה של שיטת מפתח ג' תהיה פחות רעש מאשר שיטת מפתח ב', כי ערכי הרכישה של המפרסמים לא מתחלקים באופן אחיד בין המפרסמים. עבור לדוגמה, נסו לחשוב איך רכישה של תכשיטי יוקרה משתלבת עם רכישות לכובעי מצחייה ישנו את הנתונים הבסיסיים וכתוצאה מכך ישנו את הרעש.
כדאי ליצור ערכים מצטברים מקסימליים משותפים וגורמי התאמה לעומס (scaling) משותפים. משותף לכמה מפרסמים כדי לצמצם את הרעש הפלט. לדוגמה, אפשר לנסות את השיטות השונות הבאות המפרסמים שלך:
- שיטה אחת שמופרדת לפי מטבע (USD, ¥, CAD וכו')
- אסטרטגיה אחת שמופרדת לפי התחום של המפרסם (ביטוח, רכב, קמעונאות וכו')
- שיטה אחת שמופרדת לפי טווחים דומים של ערכי רכישה ([100], [1000], [10000] וכו')
על ידי יצירת אסטרטגיות מרכזיות סביב נושאים משותפים, מפתחות קל יותר לנהל את הקוד התואם, ויחסי האות לרעש הופכים גבוהה יותר. ניסוי עם אסטרטגיות שונות עם מפרסם שונה נפוצות לגילוי נקודות הטיה בהגדלה של השפעת הרעש לעומת הקוד ניהול.
ניהול מתקדם של חריגים
נתייחס לתרחיש שרלוונטי לשני מפרסמים:
- מפרסם א':
- מחיר הרכישה בכל המוצרים באתר של מפרסם א' האפשרויות הן בין [120$ ל-1,000$] , בטווח של 880$.
- מחירי הרכישות מתחלקים באופן שווה על פני הטווח של 880$ ללא חריגים מחוץ לשתי סטיות תקן ממחיר הרכישה החציוני.
- מפרסם ב':
- מחיר הרכישה בכל המוצרים באתר של מפרסם ב' האפשרויות הן בין [120$ ל-1,000$] , בטווח של 880$.
- מחירי הרכישות משתנים באופן משמעותי לטווח של $120- $500, כאשר 5% בלבד מהרכישות מתרחשות בטווח של 500$-1,000$.
בהינתן הדרישות לגבי התקציב לתרומות והמתודולוגיה שלפיה חלים רעש על התוצאות הסופיות, ברירת המחדל של מפרסם ב' תהיה רעשי רקע רועש יותר מאשר למפרסם א', מאחר שלמפרסם ב' יש פוטנציאל גבוה יותר לחריגים יוצאי דופן להשפיע על של החישובים הבסיסיים.
אפשר לצמצם את הבעיה באמצעות הגדרה ספציפית של מפתח. בדיקה של אסטרטגיות מרכזיות שעוזרים לנהל נתונים חריגים, ולפזר באופן שווה יותר את ערכי הרכישה בכל טווח הרכישה של המפתח.
עבור מפרסם ב', תוכלו ליצור שני מפתחות נפרדים כדי לתעד שני מפתחות שונים טווחי ערך רכישה. בדוגמה הזו, טכנולוגיית הפרסום ציינו שחריגים חשודי טעות יופיעו מעל ערך הרכישה בסך 2,000 ש"ח. נסי ליישם שני מפתחות נפרדים עבור המפרסם הזה:
- מבנה מפתח 1 : מפתח שמתעד רק רכישות בין טווח של 120 $עד 500$ (כ-95% מנפח הרכישות הכולל).
- מבנה מפתח 2: מפתח שמבצע רק רכישות מעל 500$ (כ-5% מנפח הרכישות הכולל).
יישום של אסטרטגיית המפתח הזו יעזור לכם לנהל את "רעשי" התוכן של מפרסם ב' כדי להפיק את המרב מדוחות הסיכום. בהינתן גודל קטן יותר לטווחים, למפתח א' ולמפתח ב' צריכה להיות התפלגות אחידה יותר של הנתונים בכל מפתח תואם של המפתח הבודד הקודם. התוצאה תהיה פחות רעש בפלט של כל מקש בפלט של המפתח הבודד הקודם.