توضِّح هذه الصفحة كيفية استخدام واجهات برمجة تطبيقات "التعلم الموحّد" التي يوفّرها ميزة "التخصيص على الجهاز فقط" لتدريب نموذج باستخدام عملية تعلُّم متوسّط موحّد وضوضاء غاوسية ثابتة.
قبل البدء
قبل البدء، أكمِل الخطوات التالية على جهازك الاختباري:
تأكَّد من تثبيت وحدة OnDevicePersonalization. وأصبحت الوحدة متاحة كتحديث تلقائي في أبريل 2024.
# List the modules installed on the device adb shell pm list packages --apex-only --show-versioncodeتأكَّد من أنّ الوحدة التالية مُدرَجة برمز إصدار 341717000 أو إصدار أحدث:
package:com.google.android.ondevicepersonalization versionCode:341717000إذا لم تكن هذه الوحدة مُدرَجة، انتقِل إلى الإعدادات > الأمان والخصوصية > التحديثات > تحديث نظام Google Play للتأكّد من تحديث جهازك. انقر على تحديث حسب الضرورة.
تفعيل جميع الميزات الجديدة المتعلّقة بميزة "التعلم الموحّد"
# Enable On-Device Personalization apk. adb shell device_config put on_device_personalization global_kill_switch false # Enable On-Device Personalization APIs. adb shell device_config put on_device_personalization enable_ondevicepersonalization_apis true # Enable On-Device Personalization overriding. adb shell device_config put on_device_personalization enable_personalization_status_override true adb shell device_config put on_device_personalization personalization_status_override_value true # Enable Federated Compute apk. adb shell device_config put on_device_personalization federated_compute_kill_switch false
إنشاء مهمة التعلّم الموحّد

يتم شرح الأرقام الواردة في الرسم البياني بمزيد من التفصيل في الخطوات الثمانية التالية.
ضبط إعدادات خادم الحوسبة الموحّدة
التعلُّم الموحّد هو عملية ربط وتصغير يتم تنفيذها على "خادم الحوسبة الموحّدة" ("الخادم المُتصغّر") ومجموعة من العملاء ("الأدوات المُنشِئة للخريطة"). يحافظ خادم الحوسبة الموحّدة على معلومات النموذج والبيانات الوصفية قيد التشغيل لكل مهمة من مهام التعلّم الموحّد. على مستوى عالٍ:
- ينشئ مطوّر برامج التعلّم الموحّد مهمة جديدة ويحمّل كلاً من البيانات الوصفية لتنفيذ المهام ومعلومات النموذج على الخادم.
- عندما يُرسل عميل "الحوسبة الفدرالية" طلبًا جديدًا لتحديد مهمة إلى الخادم، يتحقّق الخادم من أهلية المهمة ويعرض معلومات المهمة المؤهَّلة.
- عندما ينهي برنامج الحوسبة الموحدة عمليات الحوسبة المحلية، فإنه يرسل نتائج الحوسبة هذه إلى الخادم. ثم يقوم الخادم بعملية التجميع والتشويش على نتائج الحوسبة هذه ويطبق النتيجة على النموذج النهائي.
لمعرفة المزيد حول هذه المفاهيم، راجع:
- التعلّم الموحّد: تعلُّم الآلة التعاوني بدون استخدام بيانات التدريب المركزية
- Towards Federated Learning at Scale: System Design (SysML 2019)
يستخدم مشروع ODP إصدارًا مُحسَّنًا من التعلّم الموحّد، حيث يتم تطبيق تشويش معايرة (مركزي) على البيانات المجمّعة قبل تطبيقه على النموذج. يضمن نطاق التشويش الحفاظ على الخصوصية التفاضلية في البيانات المجمّعة.
الخطوة 1: إنشاء خادم حوسبة متحدّة
اتّبِع التعليمات الواردة في مشروع "الحوسبة الفدرالية" لإعداد خادم "الحوسبة الفدرالية".
الخطوة 2: إعداد نموذج وظيفي محفوظ
حضِّر ملفًا محفوظًا من النوع FunctionalModel. يمكنك استخدام 'functional_model_from_keras' لتحويل 'Model' إلى 'FunctionalModel' واستخدام 'save_functional_model' لتسلسل 'FunctionalModel' هذا كـ 'SavedModel'.
functional_model = tff.learning.models.functional_model_from_keras(keras_model=model)
tff.learning.models.save_functional_model(functional_model, saved_model_path)
الخطوة 3: إنشاء إعداد "خادم الحوسبة الموحّدة"
يمكنك إعداد "fcp_server_config.json" يتضمّن السياسات وإعداد التعلّم الموحّد وإعداد الخصوصية التفاضلية. مثال:
# Identifies the set of client devices that will participate.
population_name: "my_new_population"
# Options you can choose:
# * TRAINING_ONLY: Only one training task will be generated under this
# population.
# * TRAINING_AND_EVAL: One training task and one evaluation task will be
# generated under this population.
# * EVAL_ONLY: Only one evaluation task will be generated under this
# population.
mode: TRAINING_AND_EVAL
policies {
# Policy for sampling on-device examples. It is checked every time a
# device attempts to start a new training.
min_separation_policy {
# The minimum number of rounds before the same client participated.
minimum_separation: 3
}
# Policy for releasing training results to developers. It is checked
# when uploading a new task to the Federated Compute Server.
model_release_policy {
# Server stops training when number of training rounds reaches this
# number.
num_max_training_rounds: 1000
}
}
# Federated learning setups. They are applied inside Task Builder.
federated_learning {
learning_process {
# Use FED_AVG to build federated learning process. Options you can
# choose:
# * FED_AVG: Federated Averaging algorithm
# (https://arxiv.org/abs/2003.00295)
# * FED_SDG: Federated SGD algorithm
# (https://arxiv.org/abs/1602.05629)
type: FED_AVG
# Optimizer used at client side training. Options you can choose:
# * ADAM
# * SGD
client_optimizer: SGD
# Learning rate used at client side training.
client_learning_rate: 0.01
# Optimizer used at server side training. Options you can choose:
# * ADAM
# * SGD
server_optimizer: ADAM
# Learning rate used at server side training.
sever_learning_rate: 1
runtime_config {
# Number of participating devices for each round of training.
report_goal: 2000
}
# List of metrics to be evaluated by the model during training and
# evaluation. Federated Compute Server provides a list of allowed
# metrics.
metrics {
name: "auc-roc"
}
metrics {
name: "binary_accuracy"
}
}
# Whether or not to generate a corresponding evaluation task under the same
# population. If this field isn't set, only one training task is
# generated under this population.
evaluation {
# The task id under the same population of the source training task that
# this evaluation task evaluates.
source_training_task_id: 1
# Decides how checkpoints from the training task are chosen for
# evaluation.
# * every_k_round: the evaluation task randomly picks one checkpoint
# from the past k rounds of training task checkpoints.
# * every_k_hour: the evaluation task randomly picks one checkpoint
# from the past k hours of training task checkpoints.
checkpoint_selector: "every_1_round"
# The traffic of this evaluation task in this population.
evaluation_traffic: 0.1
# Number of participating devices for each round of evaluation.
report_goal: 200
}
}
# Differential Privacy setups. They are applied inside the Task Builder.
differential_privacy {
# The DP aggregation algorithm you want to use. Options you can choose:
# * FIXED_GAUSSIAN: Federated Learning DP-SGD with fixed clipping norm
# described in "Learning Differentially Private Recurrent
# Language Models" (https://arxiv.org/abs/1710.06963).
# * ADAPTIVE_GAUSSIAN: Federated Learning DP-SGD with quantile-based clip
# norm estimation described in "Differentially Private
# Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
# * TREE: DP-FTRL algorithm described in "Practical and Private (Deep)
# Learning without Sampling or Shuffling"
# (https://arxiv.org/abs/2103.00039).
# * ADADPTIVE_TREE: DP-FTRL with adaptive clipping norm descirbed in
# "Differentially Private Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
type: FIXED_GAUSSIAN
# Noise multiplier for the Gaussian noise.
noise_multiplier: 0.1
# The value of the clipping norm.
clip_norm: 0.1
}
الخطوة 4. أرسِل ملف الإعدادات المضغوط إلى خادم Federated Compute.
أرسِل ملف zip وfcp_server_config.json إلى خادم "الحوسبة الموحّدة".
task_builder_client --task_builder_server='http://{federated_compute_server_endpoint}' --saved_model='saved_model' --task_config='fcp_server_config.json'
نقطة نهاية "خادم الحوسبة الموحّد" هي الخادم الذي أعددته في الخطوة 1.
لا تتوافق مكتبة المشغّلات في LiteRT إلا مع عدد محدود من عوامل التشغيل TensorFlow (اختيار عوامل التشغيل TensorFlow). قد تختلف مجموعة مشغّلي الشبكات المتوافقة في الإصدارات المختلفة من وحدة OnDevicePersonalization. لضمان التوافق، يتم إجراء عملية التحقق من المشغل داخل أداة إنشاء المهام أثناء إنشاء المهام.
سيتم تضمين الحد الأدنى من إصدار وحدة OnDevicePersonalization المتوافق مع البيانات الوصفية للمهمة. يمكن العثور على هذه المعلومات في رسالة المعلومات الخاصة بتطبيق "أداة إنشاء المهام".
I1023 22:16:53.058027 139653371516736 task_builder_client.py:109] Success! Tasks are built, and artifacts are uploaded to the cloud. I1023 22:16:53.058399 139653371516736 task_builder_client.py:112] applied_algorithms { learning_algo: FED_AVG client_optimizer: SGD server_optimizer: SGD dp_aggregator: FIXED_GAUSSIAN } metric_results { accepted_metrics: "binary_accuracy, binary_crossentropy, recall, precision, auc-roc, auc-pr" } dp_hyperparameters { dp_delta: 0.000001 dp_epsilon: 6.4 noise_multiplier: 1.0 dp_clip_norm: 1.0 num_training_rounds: 10000 } I1023 22:16:53.058594 139653371516736 task_builder_client.py:113] training_task { min_client_version: "341912000" } eval_task { min_client_version: "341812000" }سيحدّد خادم "الحوسبة الموحّدة" هذه المهمة لجميع الأجهزة المزوّدة بوحدة OnDevicePersonalization بإصدار أعلى من 341812000.
إذا كان النموذج يتضمّن عمليات لا تتوافق مع أيّ من وحدات OnDevicePersonalization، ستظهر رسالة خطأ أثناء إنشاء المهمة.
common.TaskBuilderException: Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {'L2Loss': 'L2LossOp<CPUDevice, float>'} . Stop building remaining artifacts.يمكنك العثور على قائمة تفصيلية بعمليات التشغيل المرنة المتوافقة في GitHub.
إنشاء حزمة APK لميزة "المعالجة الفدرالية" على Android
لإنشاء حزمة APK للحوسبة الموحّدة في Android، يجب تحديد نقطة نهاية عنوان URL لخادم الحوسبة الموحّدة في AndroidManifest.xml الذي يتصل به برنامج الحوسبة الموحدة.
الخطوة الخامسة. تحديد نقطة نهاية عنوان URL لخادم الحوسبة الموحّدة
حدِّد نقطة نهاية عنوان URL لخادم "حوسبة الفِرق" (الذي أعددته في الخطوة 1) في AndroidManifest.xml الذي يتصل به "عميل حوسبة الفِرق".
<!-- Contents of AndroidManifest.xml -->
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.odpsample" >
<application android:label="OdpSample">
<!-- XML resource that contains other ODP settings. -->
<property android:name="android.ondevicepersonalization.ON_DEVICE_PERSONALIZATION_CONFIG"
android:resource="@xml/OdpSettings"></property>
<!-- The service that ODP will bind to. -->
<service android:name="com.example.odpsample.SampleService"
android:exported="true" android:isolatedProcess="true" />
</application>
</manifest>
يجب أيضًا أن يعرِّف ملف موارد XML المحدّد في العلامة <property> فئة الخدمة في علامة <service>، وأن يحدّد نقطة نهاية عنوان URL لخادم الحوسبة الموحّدة التي سيتصل بها برنامج الحوسبة الموحّد:
<!-- Contents of res/xml/OdpSettings.xml -->
<on-device-personalization>
<!-- Name of the service subclass -->
<service name="com.example.odpsample.SampleService">
<!-- If you want to use federated compute feature to train a model,
specify this tag. -->
<federated-compute-settings url="https://fcpserver.com/" />
</service>
</on-device-personalization>
الخطوة السادسة. تنفيذ واجهة برمجة التطبيقات IsolatedWorker#onTrainingExample
تنفيذ واجهة برمجة التطبيقات العامة "التخصيص على الجهاز" IsolatedWorker#onTrainingExample لإنشاء بيانات التدريب.
لا يمكن للرمز البرمجي الذي يتم تشغيله في IsolatedProcess الوصول مباشرةً إلى الشبكة أو الأقراص المحلية أو الخدمات الأخرى التي تعمل على الجهاز، ولكن تتوفّر واجهات برمجة التطبيقات التالية:
- 'getRemoteData': بيانات مفاتيح وقيم ثابتة يتم تنزيلها من الخلفيات البعيدة التي يديرها المطوّرون، إن أمكن.
- 'getLocalData': بيانات مفتاح/قيمة قابلة للتغيير يحفظها المطوّرون محليًا، إن أمكن.
- UserData: بيانات المستخدم التي تقدّمها المنصة
- 'getLogReader': لعرض DAO لجدولَي REQUESTS وEVENTS
مثال:
@Override public void onTrainingExample(
@NonNull TrainingExampleInput input,
@NonNull Consumer<TrainingExampleOutput> consumer) {
// Check if the incoming training task is the task we want.
if (input.getPopulationName() == "my_new_population") {
TrainingExampleOutput result = new TrainingExampleOutput.Builder():
RequestLogRecord record = this.getLogReader().getRequestLogRecord(1);
int count = 1;
// Iterate logging event table.
for (ContentValues contentValues: record.rows()) {
Features features = Features.newBuilder()
// Retrieve carrier from user info.
.putFeature("carrier", buildFeature(mUserData.getCarrier()))
// Retrieve features from logging info.
.putFeature("int_feature_1",
buildFeature(contentValues.get("int_feature_1")
result.addTrainingExample(
Example.newBuilder()
.setFeatures(features).build().toByteArray())
.addResumptionToken(
String.format("token%d", count).getBytes()))
.build();
count++;
}
consumer.accept(result.build());
}
}
الخطوة السابعة: جدولة مهمة تدريب متكرّرة.
توفّر ميزة "التخصيص على الجهاز" FederatedComputeScheduler للمطوّرين لجدولة مهام الحوسبة الموحّدة أو إلغائها. هناك خيارات مختلفة لطلب إعادة النظر في القرار حتى IsolatedWorker، إمّا في جدول زمني أو عند اكتمال عملية تنزيل غير متزامن. وفي ما يلي أمثلة على كليهما.
خيار مستنِد إلى الجدول الزمني: تواصل هاتفيًا مع "
FederatedComputeScheduler#schedule" فيIsolatedWorker#onExecute.@Override public void onExecute( @NonNull ExecuteInput input, @NonNull Consumer<ExecuteOutput> consumer ) { if (input != null && input.getAppParams() != null && input.getAppParams().getString("schedule_training") != null) { if (input.getAppParams().getString("schedule_training").isEmpty()) { consumer.accept(null); return; } TrainingInterval interval = new TrainingInterval.Builder() .setMinimumInterval(Duration.ofSeconds(10)) .setSchedulingMode(2) .build(); FederatedComputeScheduler.Params params = new FederatedComputeScheduler .Params(interval); FederatedComputeInput fcInput = new FederatedComputeInput.Builder() .setPopulationName( input.getAppParams().getString("schedule_training")).build(); mFCScheduler.schedule(params, fcInput); ExecuteOutput result = new ExecuteOutput.Builder().build(); consumer.accept(result); } }خيار "اكتملت عملية التنزيل" يُرجى الاتصال برقم
FederatedComputeScheduler#scheduleفيIsolatedWorker#onDownloadCompletedإذا كان تحديد موعد مهمة التدريب يعتمد على أي بيانات أو عمليات غير متزامنة.
التحقّق من الصحة
توضِّح الخطوات التالية كيفية التحقّق من عمل مهمة "التعلّم الموحّد" بشكل صحيح.
الخطوة 8: تأكَّد من تشغيل مهمة "التعلم الموحّد" بشكلٍ سليم.
يتمّ إنشاء نقطة تفتيش جديدة للنموذج وملف مقياس جديد في كلّ جولة من التجميع من جهة الخادم.
تكون المقاييس في ملف بتنسيق JSON يتضمّن أزواج مفاتيح وقيم. يتم إنشاء الملف من خلال قائمة Metrics التي حدّدتها في الخطوة 3. في ما يلي مثال على ملف JSON للمقاييس التمثيلية:
{"server/client_work/train/binary_accuracy":0.5384615659713745, "server/client_work/train/binary_crossentropy":0.694046676158905, "server/client_work/train/recall":0.20000000298023224, "server/client_work/train/precision":0.3333333432674408, "server/client_work/train/auc-roc":0.3500000238418579, "server/client_work/train/auc-pr":0.44386863708496094, "server/finalizer/update_non_finite":0.0}
يمكنك استخدام شيء مشابه للنص البرمجي التالي للحصول على مقاييس النموذج ومراقبة أداء التدريب:
import collections
import json
import matplotlib.pyplot as plt
from google.cloud import storage
# The population_name you set in fcp_server_config.json in Step 3.
POPULATION_NAME = 'my_new_population'
# The Google Cloud storage you set in Step 1.
GCS_BUCKET_NAME = 'fcp-gcs'
NUM_TRAINING_ROUND = 1000
storage_client = storage.Client()
bucket = storage_client.bucket(GCS_BUCKET_NAME)
metrics = collections.defaultdict(list)
for i in range(NUM_TRAINING_ROUND):
blob = bucket.blob('{}/{}/1/{}/s/0/metrics'.format(GCS_BUCKET_NAME, POPULATION_NAME, i+1))
with blob.open("r") as f:
metric = json.loads(f.read())
for metric_name in metric.keys():
metrics[metric_name].append(metric[metric_name])
for metric_name in metrics:
print(metric_name)
plt.plot(metrics[metric_name])
plt.show()
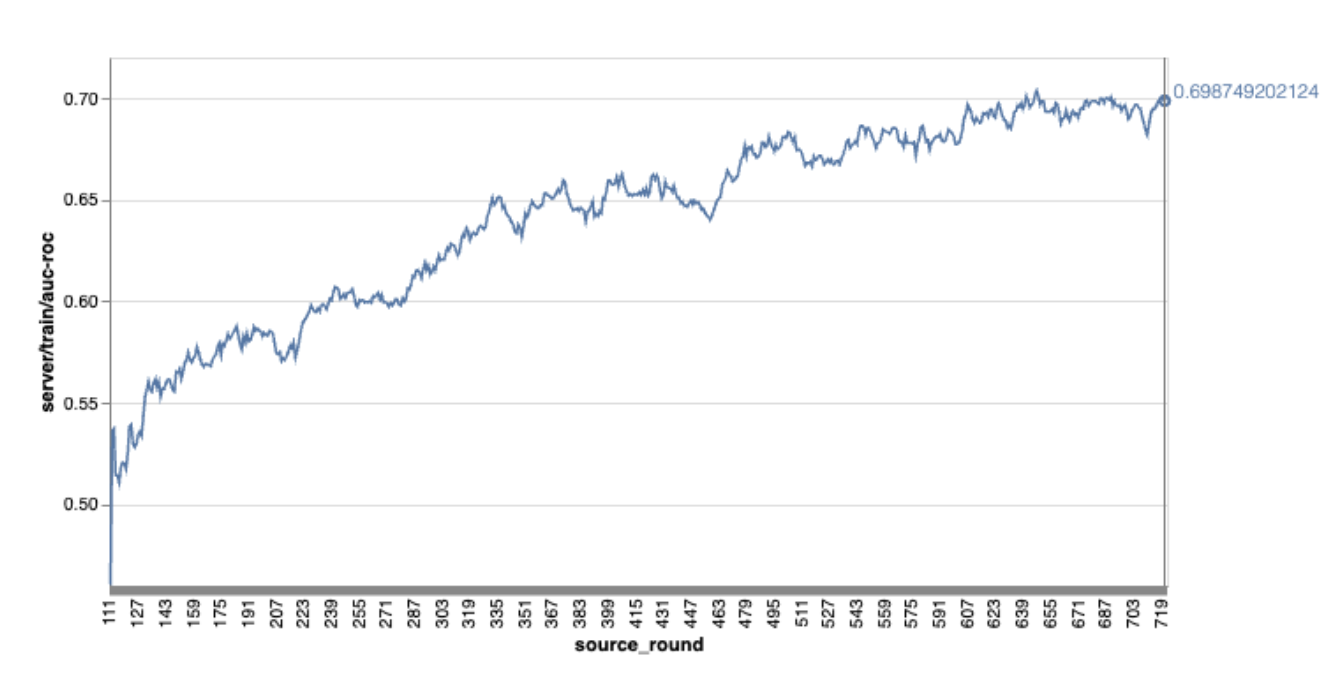
لاحظ أنه في المثال السابق للرسم البياني:
- المحور السيني هو عدد جولات التدريب.
- المحور y هو قيمة auc-roc لكل جولة.
التدريب على نموذج تصنيف الصور عند التخصيص على الجهاز
في هذا البرنامج التعليمي، يتم استخدام مجموعة بيانات EMNIST لعرض كيفية تنفيذ مهمة تعلُّم موحَّد على ODP.
الخطوة 1: أنشئ tff.learning.models.FunctionalModel.
def get_image_classification_input_spec():
return (
tf.TensorSpec([None, 28, 28, 1], tf.float32),
tf.TensorSpec([None, 1], tf.int64),
)
def create_and_save_image_classification_functional_model(
model_path: str,
) -> None:
keras_model = emnist_models.create_original_fedavg_cnn_model(
only_digits=True
)
functional_model = tff.learning.models.functional_model_from_keras(
keras_model=keras_model,
input_spec=get_image_classification_input_spec(),
loss_fn=tf.keras.losses.SparseCategoricalCrossentropy(),
)
tff.learning.models.save_functional_model(functional_model, model_path)
- يمكنك العثور على تفاصيل نموذج emnist keras في emnist_models.
- لا يتوافق TfLite بعد مع tf.sparse.SparseTensor أو tf.RaggedTensor. حاوِل استخدام tf.Tensor قدر الإمكان عند إنشاء النموذج.
- ستستبدل "أداة إنشاء مهام ODP" جميع المقاييس عند إنشاء عملية التعلُّم، ولن تحتاج إلى تحديد أي مقاييس. سيتم تناول هذا الموضوع بشكل أكبر في الخطوة 2. أنشئ إعدادات "أداة إنشاء المهام".
يتوفّر نوعان من مدخلات النماذج:
النوع 1: صف(features_tensor, label_tensor).
- عند إنشاء النموذج، تظهر قيمة enter_spec على النحو التالي:
def get_input_spec(): return ( tf.TensorSpec([None, 28, 28, 1], tf.float32), tf.TensorSpec([None, 1], tf.int64), )- يمكنك إقران ما سبق بعملية التنفيذ التالية لواجهة برمجة تطبيقات ODP العامة، وهي IsolatedWorker#onTrainingExamples لإنشاء بيانات التدريب على الجهاز:
return tf.train.Example( features=tf.train.Features( feature={ 'x': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0] * 784) ), 'y': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()النوع 2
Tuple(Dict[feature_name, feature_tensor], label_tensor)- عند إنشاء النموذج، تظهر قيمة enter_spec على النحو التالي:
def get_input_spec() -> ( Tuple[collections.OrderedDict[str, tf.TensorSpec], tf.TensorSpec] ): return ( collections.OrderedDict( [('feature-1', tf.TensorSpec([None, 1], tf.float32)), ('feature-2', tf.TensorSpec([None, 1], tf.float32))] ), tf.TensorSpec([None, 1], tf.int64), )- يمكنك إقران ما سبق مع التنفيذ التالي لواجهة برمجة تطبيقات ODP العامة IsolatedWorker#onTrainingExamples لإنشاء بيانات التدريب:
return tf.train.Example( features=tf.train.Features( feature={ 'feature-1': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0]) ), 'feature-2': tf.train.Feature( float_list=tf.train.FloatList(value=[2.0]) ), 'my_label': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()- احرِص على تسجيل label_name في إعدادات أداة إنشاء المهام.
mode: TRAINING_AND_EVAL # Task execution mode population_name: "my_example_model" label_name: "my_label"
يتعامل ODP مع DP تلقائيًا عند إنشاء عملية التعلم. لذلك ليست هناك حاجة لإيجاد تشويش عند إنشاء النموذج الوظيفي.
ومن المفترض أن يكون ناتج هذا النموذج الوظيفي المحفوظ مماثلاً للعيّنة في مستودع GitHub.
الخطوة 2: إنشاء إعدادات "أداة إنشاء المهام"
يمكنك العثور على عيّنات من إعدادات "أداة إنشاء المهام" في مستودع GitHub.
مقاييس التدريب والتقييم
بما أنّ المقاييس قد تسرّب بيانات المستخدم، ستتوفّر في "أداة إنشاء المهام" قائمة بالمقاييس التي يمكن لعملية التعلُّم إنشاؤها وإصدارها. يمكنك العثور على القائمة الكاملة في مستودع GitHub.
في ما يلي نموذج لقائمة المقاييس عند إنشاء إعدادات جديدة لصانع المهام:
federated_learning { learning_process { metrics { name: "binary_accuracy" } metrics { name: "binary_crossentropy" } metrics { name: "recall" } metrics { name: "precision" } metrics { name: "auc-roc" } metrics { name: "auc-pr" } } }
إذا لم تكن المقاييس التي تهمّك مضمّنة في القائمة الحالية، يُرجى التواصل معنا.
إعدادات DP
هناك بعض الإعدادات ذات الصلة بـ DP والتي تحتاج إلى تحديد:
policies { min_separation_policy { minimum_separation: 1 } model_release_policy { num_max_training_rounds: 1000 dp_target_epsilon: 10 dp_delta: 0.000001 } } differential_privacy { type: FIXED_GAUSSIAN clip_norm: 0.1 noise_multiplier: 0.1 }- يتوفّر إما
dp_target_epsilonأوnoise_mulitipilerلاجتياز عملية التحقّق: (noise_to_epsilonepislon_to_noise). - يمكنك العثور على هذه الإعدادات التلقائية في مستودع GitHub.
- يتوفّر إما
الخطوة 3: تحميل النموذج المحفوظ وإعدادات "أداة إنشاء المهام" إلى مساحة التخزين في السحابة الإلكترونية لأي مطوّر
احرِص على تعديل حقول artifact_building عند تحميل إعدادات أداة إنشاء المهام.
الخطوة 4. (اختياري) اختبار إنشاء العناصر بدون إنشاء مهمة جديدة
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint}
يتم التحقّق من صحة نموذج النموذج من خلال كلّ من فحص العمليات المرنة وفحص dp. ويمكنك إضافة skip_flex_ops_check وskip_dp_check لتجاوزهما أثناء عملية التحقّق (لا يمكن نشر هذا النموذج إلى الإصدار الحالي من برنامج ODP بسبب عدم توفّر بعض العمليات المرنة).
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint} --skip_flex_ops_check=True --skip_dp_check=True
flex_ops_check: لا تتوافق مكتبة عوامل التشغيل المضمّنة في TensorFlow Lite إلا مع عدد محدود من عوامل تشغيل TensorFlow (توافق TensorFlow Lite مع عوامل تشغيل TensorFlow). يجب تثبيت جميع عمليات tensorflow غير المتوافقة باستخدام رمز التفويض flex (Android.bp). إذا كان النموذج يتضمّن عمليات غير متوافقة، يُرجى التواصل معنا لتسجيلها:
Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {...}إنّ أفضل طريقة لتصحيح أخطاء أداة إنشاء المهام هي بدء إحدى هذه الأدوات على الجهاز:
# Starts a server at localhost:5000 bazel run //python/taskbuilder:task_builder # Links to a server at localhost:5000 by removing task_builder_server flag bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --skip_flex_ops_check=True --skip_dp_check=True
يمكنك العثور على العناصر الناتجة في مساحة التخزين السحابي المحدّدة في الإعدادات. ومن المفترض أن يظهر على شكل مثال في مستودع GitHub.
الخطوة الخامسة. أنشئ عناصر وأنشئ زوجًا جديدًا من مهام التدريب والتقييم على خادم FCP.
أزِل علامة build_artifact_only وسيتم تحميل العناصر المدمجة إلى خادم سرعة عرض المحتوى على الصفحة. يجب التحقّق من إنشاء زوج من مهام التدريب والتقييم بنجاح.
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config.pbtxt --task_builder_server=${task_builder_server_endpoint}
الخطوة السادسة. الاستعداد لاستخدام ميزة "التشفير من جهة العميل"
- نفِّذ واجهة برمجة تطبيقات ODP العامة
IsolatedWorker#onTrainingExamplesلإنشاء بيانات التدريب. - يُرجى الاتصال على
FederatedComputeScheduler#schedule. - يمكنك الاطّلاع على بعض الأمثلة في مستودع مصادر Android.
الخطوة السابعة: المراقبة
مقاييس الخادم
يمكنك العثور على تعليمات الإعداد في مستودع GitHub.



- مقاييس النماذج

من الممكن مقارنة المقاييس من عمليات تشغيل مختلفة في رسم تخطيطي واحد. على سبيل المثال:
- الخط الأرجواني هو
noise_multiplier0.1 - السطر الوردي مصحوبًا بـ
noise_multipiler0.3