এই পৃষ্ঠাটি বর্ণনা করে যে কীভাবে একটি ফেডারেটেড গড় শেখার প্রক্রিয়া এবং স্থির গাউসিয়ান শব্দ সহ একটি মডেলকে প্রশিক্ষণের জন্য অন-ডিভাইস ব্যক্তিগতকরণ দ্বারা সরবরাহ করা ফেডারেটেড লার্নিং API-এর সাথে কাজ করতে হয়।
আপনি শুরু করার আগে
আপনি শুরু করার আগে, আপনার পরীক্ষা ডিভাইসে নিম্নলিখিত পদক্ষেপগুলি সম্পূর্ণ করুন:
নিশ্চিত করুন যে OnDevicePersonalization মডিউল ইনস্টল করা আছে। মডিউলটি 2024 সালের এপ্রিলে একটি স্বয়ংক্রিয় আপডেট হিসাবে উপলব্ধ হয়েছিল।
# List the modules installed on the device adb shell pm list packages --apex-only --show-versioncodeনিশ্চিত করুন যে নিম্নলিখিত মডিউলটি 341717000 বা উচ্চতর সংস্করণের কোড সহ তালিকাভুক্ত করা হয়েছে:
package:com.google.android.ondevicepersonalization versionCode:341717000যদি সেই মডিউলটি তালিকাভুক্ত না থাকে, তাহলে আপনার ডিভাইস আপ টু ডেট আছে তা নিশ্চিত করতে সেটিংস > নিরাপত্তা ও গোপনীয়তা > আপডেট > Google Play সিস্টেম আপডেটে যান। প্রয়োজন অনুযায়ী আপডেট নির্বাচন করুন।
সমস্ত ফেডারেটেড লার্নিং সম্পর্কিত নতুন বৈশিষ্ট্যগুলি সক্ষম করুন৷
# Enable On-Device Personalization apk. adb shell device_config put on_device_personalization global_kill_switch false # Enable On-Device Personalization APIs. adb shell device_config put on_device_personalization enable_ondevicepersonalization_apis true # Enable On-Device Personalization overriding. adb shell device_config put on_device_personalization enable_personalization_status_override true adb shell device_config put on_device_personalization personalization_status_override_value true # Enable Federated Compute apk. adb shell device_config put on_device_personalization federated_compute_kill_switch false
একটি ফেডারেটেড লার্নিং টাস্ক তৈরি করুন

ডায়াগ্রামের সংখ্যাগুলি নিম্নলিখিত আটটি ধাপে আরও বিস্তারিতভাবে ব্যাখ্যা করা হয়েছে।
একটি ফেডারেটেড কম্পিউট সার্ভার কনফিগার করুন
ফেডারেটেড লার্নিং হল একটি ম্যাপ-রিডুস যা ফেডারেটেড কম্পিউট সার্ভার (রিডুসার) এবং ক্লায়েন্টদের একটি সেট (ম্যাপার) এ চলে। ফেডারেটেড কম্পিউট সার্ভার প্রতিটি ফেডারেটেড লার্নিং টাস্কের চলমান মেটাডেটা এবং মডেল তথ্য বজায় রাখে। উচ্চ স্তরে:
- একজন ফেডারেটেড লার্নিং ডেভেলপার একটি নতুন টাস্ক তৈরি করে এবং সার্ভারে টাস্ক-চলমান মেটাডেটা এবং মডেল তথ্য উভয়ই আপলোড করে।
- যখন একটি ফেডারেটেড কম্পিউট ক্লায়েন্ট সার্ভারে একটি নতুন টাস্ক অ্যাসাইনমেন্ট অনুরোধ শুরু করে, সার্ভার টাস্কের যোগ্যতা পরীক্ষা করে এবং যোগ্য টাস্ক তথ্য প্রদান করে।
- একবার একটি ফেডারেটেড কম্পিউট ক্লায়েন্ট স্থানীয় গণনা শেষ করে, এটি এই গণনার ফলাফলগুলি সার্ভারে পাঠায়। সার্ভার তারপর এই গণনা ফলাফলের উপর একত্রিতকরণ এবং গোলমাল সঞ্চালন করে এবং ফলাফল চূড়ান্ত মডেলে প্রয়োগ করে।
এই ধারণাগুলি সম্পর্কে আরও জানতে, দেখুন:
- ফেডারেটেড লার্নিং: কেন্দ্রীভূত প্রশিক্ষণ ডেটা ছাড়াই সহযোগিতামূলক মেশিন লার্নিং
- স্কেলে ফেডারেটেড লার্নিং এর দিকে: সিস্টেম ডিজাইন (SysML 2019)
ODP ফেডারেটেড লার্নিং-এর একটি বর্ধিত সংস্করণ ব্যবহার করে, যেখানে মডেলে আবেদন করার আগে ক্যালিব্রেটেড (কেন্দ্রীকৃত) শব্দ সমষ্টিতে প্রয়োগ করা হয়। গোলমালের স্কেল নিশ্চিত করে যে সমষ্টিগুলি ডিফারেনশিয়াল গোপনীয়তা রক্ষা করে।
ধাপ 1. একটি ফেডারেটেড কম্পিউট সার্ভার তৈরি করুন
আপনার নিজস্ব ফেডারেটেড কম্পিউট সার্ভার সেট আপ করতে ফেডারেটেড কম্পিউট প্রকল্পের নির্দেশাবলী অনুসরণ করুন।
ধাপ 2. একটি সংরক্ষিত কার্যকরী মডেল প্রস্তুত করুন
একটি সংরক্ষিত 'ফাংশনাল মডেল' ফাইল প্রস্তুত করুন। আপনি একটি 'মডেল'কে 'ফাংশনাল মডেল'- এ রূপান্তর করতে 'ফাংশনাল_মডেল_ফরম_কেরাস' ব্যবহার করতে পারেন এবং 'সংরক্ষিত মডেল' হিসেবে এই 'ফাংশনাল মডেল'কে সিরিয়ালাইজ করতে 'সেভ_ফাংশনাল_মডেল' ব্যবহার করতে পারেন।
functional_model = tff.learning.models.functional_model_from_keras(keras_model=model)
tff.learning.models.save_functional_model(functional_model, saved_model_path)
ধাপ 3. একটি ফেডারেটেড কম্পিউট সার্ভার কনফিগারেশন তৈরি করুন
একটি fcp_server_config.json প্রস্তুত করুন যার মধ্যে রয়েছে নীতি, ফেডারেটেড লার্নিং সেটআপ এবং ডিফারেনশিয়াল প্রাইভেসি সেটআপ। উদাহরণ:
# Identifies the set of client devices that will participate.
population_name: "my_new_population"
# Options you can choose:
# * TRAINING_ONLY: Only one training task will be generated under this
# population.
# * TRAINING_AND_EVAL: One training task and one evaluation task will be
# generated under this population.
# * EVAL_ONLY: Only one evaluation task will be generated under this
# population.
mode: TRAINING_AND_EVAL
policies {
# Policy for sampling on-device examples. It is checked every time a
# device attempts to start a new training.
min_separation_policy {
# The minimum number of rounds before the same client participated.
minimum_separation: 3
}
# Policy for releasing training results to developers. It is checked
# when uploading a new task to the Federated Compute Server.
model_release_policy {
# Server stops training when number of training rounds reaches this
# number.
num_max_training_rounds: 1000
}
}
# Federated learning setups. They are applied inside Task Builder.
federated_learning {
learning_process {
# Use FED_AVG to build federated learning process. Options you can
# choose:
# * FED_AVG: Federated Averaging algorithm
# (https://arxiv.org/abs/2003.00295)
# * FED_SDG: Federated SGD algorithm
# (https://arxiv.org/abs/1602.05629)
type: FED_AVG
# Optimizer used at client side training. Options you can choose:
# * ADAM
# * SGD
client_optimizer: SGD
# Learning rate used at client side training.
client_learning_rate: 0.01
# Optimizer used at server side training. Options you can choose:
# * ADAM
# * SGD
server_optimizer: ADAM
# Learning rate used at server side training.
sever_learning_rate: 1
runtime_config {
# Number of participating devices for each round of training.
report_goal: 2000
}
# List of metrics to be evaluated by the model during training and
# evaluation. Federated Compute Server provides a list of allowed
# metrics.
metrics {
name: "auc-roc"
}
metrics {
name: "binary_accuracy"
}
}
# Whether or not to generate a corresponding evaluation task under the same
# population. If this field isn't set, only one training task is
# generated under this population.
evaluation {
# The task id under the same population of the source training task that
# this evaluation task evaluates.
source_training_task_id: 1
# Decides how checkpoints from the training task are chosen for
# evaluation.
# * every_k_round: the evaluation task randomly picks one checkpoint
# from the past k rounds of training task checkpoints.
# * every_k_hour: the evaluation task randomly picks one checkpoint
# from the past k hours of training task checkpoints.
checkpoint_selector: "every_1_round"
# The traffic of this evaluation task in this population.
evaluation_traffic: 0.1
# Number of participating devices for each round of evaluation.
report_goal: 200
}
}
# Differential Privacy setups. They are applied inside the Task Builder.
differential_privacy {
# The DP aggregation algorithm you want to use. Options you can choose:
# * FIXED_GAUSSIAN: Federated Learning DP-SGD with fixed clipping norm
# described in "Learning Differentially Private Recurrent
# Language Models" (https://arxiv.org/abs/1710.06963).
# * ADAPTIVE_GAUSSIAN: Federated Learning DP-SGD with quantile-based clip
# norm estimation described in "Differentially Private
# Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
# * TREE: DP-FTRL algorithm described in "Practical and Private (Deep)
# Learning without Sampling or Shuffling"
# (https://arxiv.org/abs/2103.00039).
# * ADADPTIVE_TREE: DP-FTRL with adaptive clipping norm descirbed in
# "Differentially Private Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
type: FIXED_GAUSSIAN
# Noise multiplier for the Gaussian noise.
noise_multiplier: 0.1
# The value of the clipping norm.
clip_norm: 0.1
}
ধাপ 4. ফেডারেটেড কম্পিউট সার্ভারে জিপ কনফিগারেশন জমা দিন।
ফেডারেটেড কম্পিউট সার্ভারে জিপ ফাইল এবং fcp_server_config.json জমা দিন।
task_builder_client --task_builder_server='http://{federated_compute_server_endpoint}' --saved_model='saved_model' --task_config='fcp_server_config.json'
ফেডারেটেড কম্পিউট সার্ভার এন্ডপয়েন্ট হল সেই সার্ভার যা আপনি ধাপ 1 এ সেট আপ করেছেন।
LiteRT বিল্ট-ইন অপারেটর লাইব্রেরি শুধুমাত্র সীমিত সংখ্যক টেনসরফ্লো অপারেটরকে সমর্থন করে (টেনসরফ্লো অপারেটর নির্বাচন করুন)। সমর্থিত অপারেটর সেটটি OnDevicePersonalization মডিউলের বিভিন্ন সংস্করণে পরিবর্তিত হতে পারে। সামঞ্জস্য নিশ্চিত করতে, টাস্ক তৈরির সময় টাস্ক নির্মাতার মধ্যে একটি অপারেটর যাচাইকরণ প্রক্রিয়া পরিচালিত হয়।
ন্যূনতম সমর্থিত OnDevicePersonalization মডিউল সংস্করণ টাস্ক মেটাডেটা অন্তর্ভুক্ত করা হবে। এই তথ্য টাস্ক নির্মাতার তথ্য বার্তা পাওয়া যাবে.
I1023 22:16:53.058027 139653371516736 task_builder_client.py:109] Success! Tasks are built, and artifacts are uploaded to the cloud. I1023 22:16:53.058399 139653371516736 task_builder_client.py:112] applied_algorithms { learning_algo: FED_AVG client_optimizer: SGD server_optimizer: SGD dp_aggregator: FIXED_GAUSSIAN } metric_results { accepted_metrics: "binary_accuracy, binary_crossentropy, recall, precision, auc-roc, auc-pr" } dp_hyperparameters { dp_delta: 0.000001 dp_epsilon: 6.4 noise_multiplier: 1.0 dp_clip_norm: 1.0 num_training_rounds: 10000 } I1023 22:16:53.058594 139653371516736 task_builder_client.py:113] training_task { min_client_version: "341912000" } eval_task { min_client_version: "341812000" }ফেডারেটেড কম্পিউট সার্ভার 341812000-এর বেশি সংস্করণ সহ একটি OnDevicePersonalization মডিউল দিয়ে সজ্জিত সমস্ত ডিভাইসে এই কাজটি বরাদ্দ করবে।
যদি আপনার মডেলে এমন ক্রিয়াকলাপ অন্তর্ভুক্ত থাকে যা কোনো OnDevicePersonalization মডিউল দ্বারা সমর্থিত নয়, তাহলে টাস্ক তৈরির সময় একটি ত্রুটি বার্তা তৈরি হবে।
common.TaskBuilderException: Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {'L2Loss': 'L2LossOp<CPUDevice, float>'} . Stop building remaining artifacts.আপনি GitHub- এ সমর্থিত ফ্লেক্স অপ্সের একটি বিস্তারিত তালিকা খুঁজে পেতে পারেন।
একটি অ্যান্ড্রয়েড ফেডারেটেড কম্পিউট APK তৈরি করুন
একটি Android ফেডারেটেড কম্পিউট APK তৈরি করতে, আপনাকে আপনার AndroidManifest.xml এ ফেডারেটেড কম্পিউট সার্ভার URL এন্ডপয়েন্ট নির্দিষ্ট করতে হবে, যেটির সাথে আপনার ফেডারেটেড কম্পিউট ক্লায়েন্ট সংযোগ করে।
ধাপ 5. ফেডারেটেড কম্পিউট সার্ভার URL এন্ডপয়েন্ট নির্দিষ্ট করুন
আপনার AndroidManifest.xml এ ফেডারেটেড কম্পিউট সার্ভার ইউআরএল এন্ডপয়েন্ট (যা আপনি ধাপ 1 এ সেট আপ করেছেন) উল্লেখ করুন, যেটির সাথে আপনার ফেডারেটেড কম্পিউট ক্লায়েন্ট সংযোগ করে।
<!-- Contents of AndroidManifest.xml -->
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.odpsample" >
<application android:label="OdpSample">
<!-- XML resource that contains other ODP settings. -->
<property android:name="android.ondevicepersonalization.ON_DEVICE_PERSONALIZATION_CONFIG"
android:resource="@xml/OdpSettings"></property>
<!-- The service that ODP will bind to. -->
<service android:name="com.example.odpsample.SampleService"
android:exported="true" android:isolatedProcess="true" />
</application>
</manifest>
<property> ট্যাগে নির্দিষ্ট করা XML রিসোর্স ফাইলটিকে অবশ্যই একটি <service> ট্যাগে সার্ভিস ক্লাস ঘোষণা করতে হবে এবং ফেডারেটেড কম্পিউট সার্ভার ইউআরএল এন্ডপয়েন্ট উল্লেখ করতে হবে যার সাথে ফেডারেটেড কম্পিউট ক্লায়েন্ট সংযোগ করবে:
<!-- Contents of res/xml/OdpSettings.xml -->
<on-device-personalization>
<!-- Name of the service subclass -->
<service name="com.example.odpsample.SampleService">
<!-- If you want to use federated compute feature to train a model,
specify this tag. -->
<federated-compute-settings url="https://fcpserver.com/" />
</service>
</on-device-personalization>
ধাপ 6. IsolatedWorker#onTrainingExample API প্রয়োগ করুন
প্রশিক্ষণ ডেটা তৈরি করতে অন-ডিভাইস ব্যক্তিগতকরণ পাবলিক API IsolatedWorker#onTrainingExample প্রয়োগ করুন।
IsolatedProcess প্রসেসে চলমান কোডের নেটওয়ার্ক, স্থানীয় ডিস্ক বা ডিভাইসে চলমান অন্যান্য পরিষেবাগুলিতে সরাসরি অ্যাক্সেস নেই; যাইহোক, নিম্নলিখিত API পাওয়া যায়:
- 'getRemoteData' - প্রযোজ্য হলে দূরবর্তী, বিকাশকারী পরিচালিত ব্যাকএন্ড থেকে ডাউনলোড করা অপরিবর্তনীয় কী-মান ডেটা।
- 'getLocalData' - পরিবর্তনযোগ্য কী-মান ডেটা স্থানীয়ভাবে বিকাশকারীদের দ্বারা স্থায়ী হয়, যদি প্রযোজ্য হয়।
- 'UserData' - প্ল্যাটফর্ম দ্বারা প্রদত্ত ব্যবহারকারীর ডেটা।
- 'getLogReader' - অনুরোধ এবং ইভেন্ট টেবিলের জন্য একটি DAO প্রদান করে।
উদাহরণ:
@Override public void onTrainingExample(
@NonNull TrainingExampleInput input,
@NonNull Consumer<TrainingExampleOutput> consumer) {
// Check if the incoming training task is the task we want.
if (input.getPopulationName() == "my_new_population") {
TrainingExampleOutput result = new TrainingExampleOutput.Builder():
RequestLogRecord record = this.getLogReader().getRequestLogRecord(1);
int count = 1;
// Iterate logging event table.
for (ContentValues contentValues: record.rows()) {
Features features = Features.newBuilder()
// Retrieve carrier from user info.
.putFeature("carrier", buildFeature(mUserData.getCarrier()))
// Retrieve features from logging info.
.putFeature("int_feature_1",
buildFeature(contentValues.get("int_feature_1")
result.addTrainingExample(
Example.newBuilder()
.setFeatures(features).build().toByteArray())
.addResumptionToken(
String.format("token%d", count).getBytes()))
.build();
count++;
}
consumer.accept(result.build());
}
}
ধাপ 7. একটি পুনরাবৃত্ত প্রশিক্ষণ টাস্ক নির্ধারণ করুন।
অন-ডিভাইস ব্যক্তিগতকরণ ডেভেলপারদের ফেডারেটেড কম্পিউট কাজের সময়সূচী বা বাতিল করতে একটি FederatedComputeScheduler প্রদান করে। IsolatedWorker মাধ্যমে এটিকে কল করার বিভিন্ন বিকল্প রয়েছে, হয় একটি সময়সূচীতে বা যখন একটি অ্যাসিঙ্ক ডাউনলোড সম্পূর্ণ হয়। উভয়ের উদাহরণ অনুসরণ করা হয়।
সময়সূচী ভিত্তিক বিকল্প।
IsolatedWorker#onExecuteএFederatedComputeScheduler#scheduleকল করুন।@Override public void onExecute( @NonNull ExecuteInput input, @NonNull Consumer<ExecuteOutput> consumer ) { if (input != null && input.getAppParams() != null && input.getAppParams().getString("schedule_training") != null) { if (input.getAppParams().getString("schedule_training").isEmpty()) { consumer.accept(null); return; } TrainingInterval interval = new TrainingInterval.Builder() .setMinimumInterval(Duration.ofSeconds(10)) .setSchedulingMode(2) .build(); FederatedComputeScheduler.Params params = new FederatedComputeScheduler .Params(interval); FederatedComputeInput fcInput = new FederatedComputeInput.Builder() .setPopulationName( input.getAppParams().getString("schedule_training")).build(); mFCScheduler.schedule(params, fcInput); ExecuteOutput result = new ExecuteOutput.Builder().build(); consumer.accept(result); } }সম্পূর্ণ অপশন ডাউনলোড করুন।
IsolatedWorker#onDownloadCompletedএFederatedComputeScheduler#scheduleএ কল করুন যদি কোনো প্রশিক্ষণের কাজ শিডিউল করা কোনো অ্যাসিঙ্ক্রোনাস ডেটা বা প্রক্রিয়ার উপর নির্ভর করে।
বৈধতা
ফেডারেটেড লার্নিং টাস্কটি সঠিকভাবে চলছে কিনা তা কীভাবে যাচাই করা যায় তা নিম্নলিখিত পদক্ষেপগুলি বর্ণনা করে।
ধাপ 8. ফেডারেটেড শেখার কাজটি সঠিকভাবে চলছে কিনা তা যাচাই করুন।
সার্ভার সাইড একত্রিতকরণের প্রতিটি রাউন্ডে একটি নতুন মডেল চেকপয়েন্ট এবং একটি নতুন মেট্রিক ফাইল তৈরি হয়।
মেট্রিকগুলি কী-মান জোড়াগুলির একটি JSON-ফরম্যাটেড ফাইলে রয়েছে৷ ফাইলটি আপনার ধাপ 3-এ সংজ্ঞায়িত Metrics তালিকা দ্বারা তৈরি করা হয়েছে। একটি প্রতিনিধি মেট্রিক্স JSON ফাইলের একটি উদাহরণ নিম্নরূপ:
{"server/client_work/train/binary_accuracy":0.5384615659713745, "server/client_work/train/binary_crossentropy":0.694046676158905, "server/client_work/train/recall":0.20000000298023224, "server/client_work/train/precision":0.3333333432674408, "server/client_work/train/auc-roc":0.3500000238418579, "server/client_work/train/auc-pr":0.44386863708496094, "server/finalizer/update_non_finite":0.0}
আপনি মডেল মেট্রিক্স পেতে এবং প্রশিক্ষণ কর্মক্ষমতা নিরীক্ষণ করতে নিম্নলিখিত স্ক্রিপ্ট অনুরূপ কিছু ব্যবহার করতে পারেন:
import collections
import json
import matplotlib.pyplot as plt
from google.cloud import storage
# The population_name you set in fcp_server_config.json in Step 3.
POPULATION_NAME = 'my_new_population'
# The Google Cloud storage you set in Step 1.
GCS_BUCKET_NAME = 'fcp-gcs'
NUM_TRAINING_ROUND = 1000
storage_client = storage.Client()
bucket = storage_client.bucket(GCS_BUCKET_NAME)
metrics = collections.defaultdict(list)
for i in range(NUM_TRAINING_ROUND):
blob = bucket.blob('{}/{}/1/{}/s/0/metrics'.format(GCS_BUCKET_NAME, POPULATION_NAME, i+1))
with blob.open("r") as f:
metric = json.loads(f.read())
for metric_name in metric.keys():
metrics[metric_name].append(metric[metric_name])
for metric_name in metrics:
print(metric_name)
plt.plot(metrics[metric_name])
plt.show()

উল্লেখ্য যে পূর্ববর্তী উদাহরণ গ্রাফে:
- x-অক্ষ হল বৃত্তাকার প্রশিক্ষণের সংখ্যা।
- y-অক্ষ হল প্রতিটি রাউন্ডের auc-roc-এর মান।
অন-ডিভাইস ব্যক্তিগতকরণের উপর একটি চিত্র শ্রেণীবিভাগ মডেল প্রশিক্ষণ
এই টিউটোরিয়ালে, EMNIST ডেটাসেটটি প্রদর্শন করতে ব্যবহার করা হয়েছে কিভাবে ODP-তে একটি ফেডারেটেড লার্নিং টাস্ক চালাতে হয়।
ধাপ 1. একটি tff.learning.models.FunctionalModel তৈরি করুন
def get_image_classification_input_spec():
return (
tf.TensorSpec([None, 28, 28, 1], tf.float32),
tf.TensorSpec([None, 1], tf.int64),
)
def create_and_save_image_classification_functional_model(
model_path: str,
) -> None:
keras_model = emnist_models.create_original_fedavg_cnn_model(
only_digits=True
)
functional_model = tff.learning.models.functional_model_from_keras(
keras_model=keras_model,
input_spec=get_image_classification_input_spec(),
loss_fn=tf.keras.losses.SparseCategoricalCrossentropy(),
)
tff.learning.models.save_functional_model(functional_model, model_path)
- আপনি emnist_models এ এমনিস্ট কেরাস মডেলের বিবরণ খুঁজে পেতে পারেন।
- TfLite-এর এখনও tf.sparse.SparseTensor বা tf.RaggedTensor-এর জন্য ভাল সমর্থন নেই। মডেল তৈরি করার সময় যতটা সম্ভব tf.Tensor ব্যবহার করার চেষ্টা করুন।
- ওডিপি টাস্ক বিল্ডার শেখার প্রক্রিয়া তৈরি করার সময় সমস্ত মেট্রিক্স ওভাররাইট করবে, কোনও মেট্রিক্স নির্দিষ্ট করার প্রয়োজন নেই। এই বিষয়টি ধাপ 2-এ আরও কভার করা হবে। টাস্ক বিল্ডার কনফিগারেশন তৈরি করুন ।
দুটি ধরণের মডেল ইনপুট সমর্থিত:
টাইপ 1. একটি টিপল (features_tensor, label_tensor)।
- মডেল তৈরি করার সময়, input_spec এর মত দেখায়:
def get_input_spec(): return ( tf.TensorSpec([None, 28, 28, 1], tf.float32), tf.TensorSpec([None, 1], tf.int64), )- ডিভাইসে প্রশিক্ষণের ডেটা জেনারেট করতে ODP পাবলিক API IsolatedWorker#onTrainingExamples- এর নিম্নলিখিত বাস্তবায়নের সাথে পূর্ববর্তীটি যুক্ত করুন:
return tf.train.Example( features=tf.train.Features( feature={ 'x': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0] * 784) ), 'y': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()2
Tuple(Dict[feature_name, feature_tensor], label_tensor)- মডেল তৈরি করার সময়, input_spec এর মত দেখায়:
def get_input_spec() -> ( Tuple[collections.OrderedDict[str, tf.TensorSpec], tf.TensorSpec] ): return ( collections.OrderedDict( [('feature-1', tf.TensorSpec([None, 1], tf.float32)), ('feature-2', tf.TensorSpec([None, 1], tf.float32))] ), tf.TensorSpec([None, 1], tf.int64), )- প্রশিক্ষণের ডেটা জেনারেট করতে ODP পাবলিক API IsolatedWorker#onTrainingExamples- এর নিম্নলিখিত বাস্তবায়নের সাথে পূর্ববর্তীটি যুক্ত করুন:
return tf.train.Example( features=tf.train.Features( feature={ 'feature-1': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0]) ), 'feature-2': tf.train.Feature( float_list=tf.train.FloatList(value=[2.0]) ), 'my_label': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()- টাস্ক বিল্ডার কনফিগারেশনে লেবেল_নাম নিবন্ধন করতে ভুলবেন না।
mode: TRAINING_AND_EVAL # Task execution mode population_name: "my_example_model" label_name: "my_label"
শেখার প্রক্রিয়া তৈরি করার সময় ODP স্বয়ংক্রিয়ভাবে ডিপি পরিচালনা করে। সুতরাং কার্যকরী মডেল তৈরি করার সময় কোন শব্দ যোগ করার প্রয়োজন নেই।
এই সংরক্ষিত কার্যকরী মডেলের আউটপুটটি আমাদের GitHub সংগ্রহস্থলের নমুনার মতো হওয়া উচিত।
ধাপ 2. টাস্ক বিল্ডার কনফিগারেশন তৈরি করুন
আপনি আমাদের GitHub সংগ্রহস্থলে টাস্ক বিল্ডার কনফিগারেশনের নমুনা খুঁজে পেতে পারেন।
প্রশিক্ষণ এবং মূল্যায়ন মেট্রিক্স
প্রদত্ত যে মেট্রিক্স ব্যবহারকারীর ডেটা ফাঁস করতে পারে, টাস্ক বিল্ডারের কাছে মেট্রিকগুলির একটি তালিকা থাকবে যা শেখার প্রক্রিয়া তৈরি এবং প্রকাশ করতে পারে। আপনি আমাদের GitHub সংগ্রহস্থলে সম্পূর্ণ তালিকা খুঁজে পেতে পারেন।
একটি নতুন টাস্ক বিল্ডার কনফিগারেশন তৈরি করার সময় এখানে একটি নমুনা মেট্রিক তালিকা রয়েছে:
federated_learning { learning_process { metrics { name: "binary_accuracy" } metrics { name: "binary_crossentropy" } metrics { name: "recall" } metrics { name: "precision" } metrics { name: "auc-roc" } metrics { name: "auc-pr" } } }
আপনি আগ্রহী মেট্রিক্স বর্তমান তালিকায় না থাকলে, আমাদের সাথে যোগাযোগ করুন।
ডিপি কনফিগারেশন
কিছু ডিপি সম্পর্কিত কনফিগারেশন রয়েছে যা নির্দিষ্ট করতে হবে:
policies { min_separation_policy { minimum_separation: 1 } model_release_policy { num_max_training_rounds: 1000 dp_target_epsilon: 10 dp_delta: 0.000001 } } differential_privacy { type: FIXED_GAUSSIAN clip_norm: 0.1 noise_multiplier: 0.1 }- হয়
dp_target_epsilonবাnoise_mulitipilerবৈধকরণ পাস করতে উপস্থিত: (noise_to_epsilonepislon_to_noise)। - আপনি আমাদের GitHub সংগ্রহস্থলে এই ডিফল্ট সেটিংস খুঁজে পেতে পারেন।
- হয়
ধাপ 3. যেকোন ডেভেলপারের ক্লাউড স্টোরেজে সংরক্ষিত মডেল এবং টাস্ক বিল্ডার কনফিগারেশন আপলোড করুন
টাস্ক বিল্ডার কনফিগারেশন আপলোড করার সময় artifact_building ক্ষেত্র আপডেট করতে ভুলবেন না।
ধাপ 4. (ঐচ্ছিক) একটি নতুন টাস্ক তৈরি না করে আর্টিফ্যাক্ট বিল্ডিং পরীক্ষা করুন
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint}
নমুনা মডেলটি ফ্লেক্স অপস চেক এবং ডিপি চেক উভয়ের মাধ্যমে যাচাই করা হয়; আপনি বৈধকরণের সময় বাইপাস করতে skip_flex_ops_check এবং skip_dp_check যোগ করতে পারেন (কিছু অনুপস্থিত ফ্লেক্স অপ্সের কারণে এই মডেলটি ODP ক্লায়েন্টের বর্তমান সংস্করণে স্থাপন করা যাবে না)।
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint} --skip_flex_ops_check=True --skip_dp_check=True
flex_ops_check: TensorFlow Lite বিল্ট-ইন অপারেটর লাইব্রেরি শুধুমাত্র সীমিত সংখ্যক TensorFlow অপারেটর সমর্থন করে ( TensorFlow Lite এবং TensorFlow অপারেটর সামঞ্জস্য )। ফ্লেক্স ডেলিগেট ( Android.bp ) ব্যবহার করে সমস্ত বেমানান tensorflow ops ইনস্টল করতে হবে। যদি কোনো মডেলে অসমর্থিত অপ্স থাকে, সেগুলি নিবন্ধন করতে আমাদের সাথে যোগাযোগ করুন:
Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {...}একটি টাস্ক বিল্ডার ডিবাগ করার সর্বোত্তম উপায় হল স্থানীয়ভাবে একটি শুরু করা:
# Starts a server at localhost:5000 bazel run //python/taskbuilder:task_builder # Links to a server at localhost:5000 by removing task_builder_server flag bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --skip_flex_ops_check=True --skip_dp_check=True
আপনি কনফিগারেশনে নির্দিষ্ট করা ক্লাউড স্টোরেজে ফলস্বরূপ আর্টিফ্যাক্টগুলি খুঁজে পেতে পারেন। এটি এমন কিছু হওয়া উচিত যা আমাদের GitHub সংগ্রহস্থলের উদাহরণের মতো দেখায়।
ধাপ 5. আর্টিফ্যাক্ট তৈরি করুন এবং FCP সার্ভারে প্রশিক্ষণ এবং ইভাল কাজগুলির একটি নতুন জোড়া তৈরি করুন।
build_artifact_only পতাকাটি সরান এবং নির্মিত শিল্পকর্মগুলি FCP সার্ভারে আপলোড করা হবে। আপনার পরীক্ষা করা উচিত যে একজোড়া প্রশিক্ষণ এবং ইভাল কাজগুলি সফলভাবে তৈরি হয়েছে
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config.pbtxt --task_builder_server=${task_builder_server_endpoint}
ধাপ 6. FCP ক্লায়েন্ট সাইড প্রস্তুত করুন
- প্রশিক্ষণের ডেটা তৈরি করতে ODP পাবলিক API
IsolatedWorker#onTrainingExamplesপ্রয়োগ করুন। -
FederatedComputeScheduler#scheduleকল করুন। - আমাদের অ্যান্ড্রয়েড সোর্স রিপোজিটরিতে কয়েকটি উদাহরণ খুঁজুন।
ধাপ 7. পর্যবেক্ষণ
সার্ভার মেট্রিক্স
আমাদের GitHub সংগ্রহস্থলে সেটআপ নির্দেশাবলী খুঁজুন।
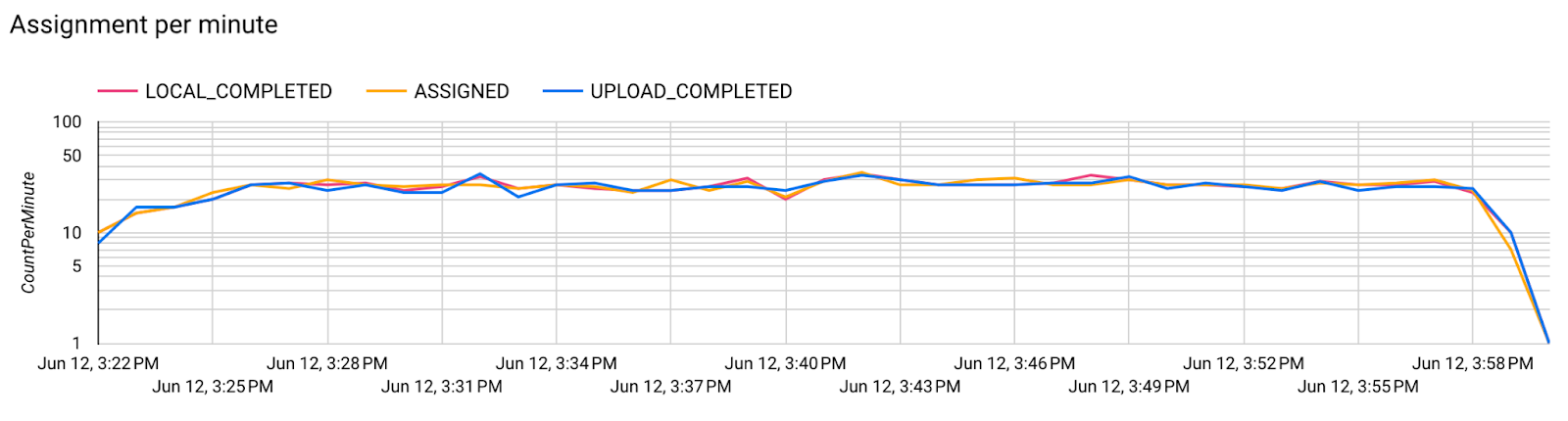
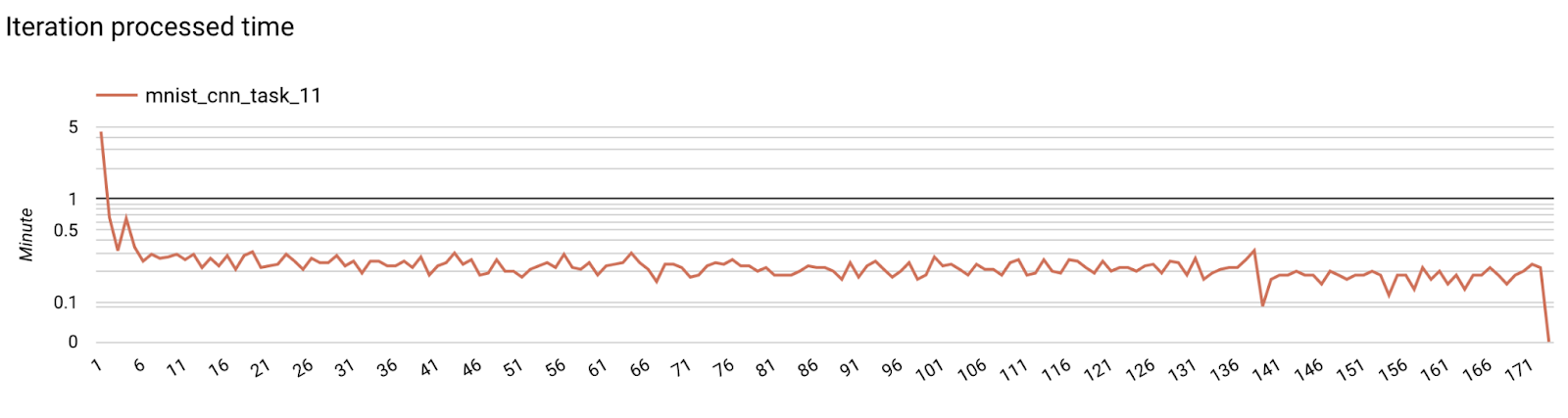

- মডেল মেট্রিক্স

একটি ডায়াগ্রামে বিভিন্ন রান থেকে মেট্রিক্স তুলনা করা সম্ভব। যেমন:
- বেগুনি লাইনটি
noise_multiplier0.1 সহ - গোলাপী লাইনটি
noise_multipiler0.3 সহ