Cette page explique comment utiliser les API de l'apprentissage fédéré fournies par la personnalisation sur l'appareil pour entraîner un modèle avec un processus d'apprentissage par moyenne fédérée et un bruit gaussien fixe.
Avant de commencer
Avant de commencer, effectuez les étapes suivantes sur votre appareil de test:
Assurez-vous que le module OnDevicePersonalization est installé. Le module a été mis à jour automatiquement en avril 2024.
# List the modules installed on the device adb shell pm list packages --apex-only --show-versioncodeAssurez-vous que le module suivant est listé avec un code de version 341717000 ou supérieur :
package:com.google.android.ondevicepersonalization versionCode:341717000Si ce module n'est pas répertorié, accédez à Paramètres > Sécurité et confidentialité > Mises à jour > Mise à jour du système Google Play pour vous assurer que votre appareil est à jour. Sélectionnez Update (Mettre à jour) si nécessaire.
Activer toutes les nouvelles fonctionnalités liées à l'apprentissage fédéré
# Enable On-Device Personalization apk. adb shell device_config put on_device_personalization global_kill_switch false # Enable On-Device Personalization APIs. adb shell device_config put on_device_personalization enable_ondevicepersonalization_apis true # Enable On-Device Personalization overriding. adb shell device_config put on_device_personalization enable_personalization_status_override true adb shell device_config put on_device_personalization personalization_status_override_value true # Enable Federated Compute apk. adb shell device_config put on_device_personalization federated_compute_kill_switch false
Créer une tâche d'apprentissage fédéré

Les numéros du schéma sont expliqués plus en détail dans les huit étapes suivantes.
Configurer un serveur de calcul fédéré
L'apprentissage fédéré est une méthode map-reduce exécutée sur le serveur de calcul fédéré (le réducteur) et un ensemble de clients (les mappeurs). Le serveur de calcul fédéré gère les métadonnées et les informations de modèle en cours d'exécution de chaque tâche d'apprentissage fédéré. De manière générale :
- Un développeur de l'apprentissage fédéré crée une tâche et importe à la fois les métadonnées d'exécution de la tâche et les informations sur le modèle sur le serveur.
- Lorsqu'un client Compute federated envoie une nouvelle requête d'attribution de tâche au serveur, celui-ci vérifie l'éligibilité de la tâche et renvoie les informations la concernant.
- Une fois qu'un client de calcul fédéré a terminé les calculs locaux, il envoie les résultats de ces calculs au serveur. Le serveur effectue ensuite une agrégation et un bruit sur ces résultats de calcul, puis applique ces résultats au modèle final.
Pour en savoir plus sur ces concepts, consultez les ressources suivantes :
- Apprentissage fédéré: machine learning collaboratif sans données d'entraînement centralisées
- Vers l'apprentissage fédéré à grande échelle: conception du système (SysML 2019)
L'ODP utilise une version améliorée de l'apprentissage fédéré, dans laquelle le bruit calibré (centralisé) est appliqué aux agrégations avant de l'appliquer au modèle. L'échelle du bruit garantit que les agrégations préservent la confidentialité différentielle.
Étape 1 : Créer un serveur Federated Compute
Suivez les instructions du projet Federated Compute pour configurer votre propre serveur Federated Compute.
Étape 2 : Préparer un FunctionalModel enregistré
Préparez un fichier FunctionalModel enregistré. Vous pouvez utiliser 'functional_model_from_keras' pour convertir un 'Model' en 'FunctionalModel' et d'utiliser 'save_feature_model' pour sérialiser ce 'FunctionalModel' en tant que 'SavedModel.
functional_model = tff.learning.models.functional_model_from_keras(keras_model=model)
tff.learning.models.save_functional_model(functional_model, saved_model_path)
Étape 3 : Créer une configuration de serveur Federated Compute
Préparez un fcp_server_config.json qui inclut les règles, la configuration de l'apprentissage fédéré et la configuration de la confidentialité différentielle. Exemple :
# Identifies the set of client devices that will participate.
population_name: "my_new_population"
# Options you can choose:
# * TRAINING_ONLY: Only one training task will be generated under this
# population.
# * TRAINING_AND_EVAL: One training task and one evaluation task will be
# generated under this population.
# * EVAL_ONLY: Only one evaluation task will be generated under this
# population.
mode: TRAINING_AND_EVAL
policies {
# Policy for sampling on-device examples. It is checked every time a
# device attempts to start a new training.
min_separation_policy {
# The minimum number of rounds before the same client participated.
minimum_separation: 3
}
# Policy for releasing training results to developers. It is checked
# when uploading a new task to the Federated Compute Server.
model_release_policy {
# Server stops training when number of training rounds reaches this
# number.
num_max_training_rounds: 1000
}
}
# Federated learning setups. They are applied inside Task Builder.
federated_learning {
learning_process {
# Use FED_AVG to build federated learning process. Options you can
# choose:
# * FED_AVG: Federated Averaging algorithm
# (https://arxiv.org/abs/2003.00295)
# * FED_SDG: Federated SGD algorithm
# (https://arxiv.org/abs/1602.05629)
type: FED_AVG
# Optimizer used at client side training. Options you can choose:
# * ADAM
# * SGD
client_optimizer: SGD
# Learning rate used at client side training.
client_learning_rate: 0.01
# Optimizer used at server side training. Options you can choose:
# * ADAM
# * SGD
server_optimizer: ADAM
# Learning rate used at server side training.
sever_learning_rate: 1
runtime_config {
# Number of participating devices for each round of training.
report_goal: 2000
}
# List of metrics to be evaluated by the model during training and
# evaluation. Federated Compute Server provides a list of allowed
# metrics.
metrics {
name: "auc-roc"
}
metrics {
name: "binary_accuracy"
}
}
# Whether or not to generate a corresponding evaluation task under the same
# population. If this field isn't set, only one training task is
# generated under this population.
evaluation {
# The task id under the same population of the source training task that
# this evaluation task evaluates.
source_training_task_id: 1
# Decides how checkpoints from the training task are chosen for
# evaluation.
# * every_k_round: the evaluation task randomly picks one checkpoint
# from the past k rounds of training task checkpoints.
# * every_k_hour: the evaluation task randomly picks one checkpoint
# from the past k hours of training task checkpoints.
checkpoint_selector: "every_1_round"
# The traffic of this evaluation task in this population.
evaluation_traffic: 0.1
# Number of participating devices for each round of evaluation.
report_goal: 200
}
}
# Differential Privacy setups. They are applied inside the Task Builder.
differential_privacy {
# The DP aggregation algorithm you want to use. Options you can choose:
# * FIXED_GAUSSIAN: Federated Learning DP-SGD with fixed clipping norm
# described in "Learning Differentially Private Recurrent
# Language Models" (https://arxiv.org/abs/1710.06963).
# * ADAPTIVE_GAUSSIAN: Federated Learning DP-SGD with quantile-based clip
# norm estimation described in "Differentially Private
# Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
# * TREE: DP-FTRL algorithm described in "Practical and Private (Deep)
# Learning without Sampling or Shuffling"
# (https://arxiv.org/abs/2103.00039).
# * ADADPTIVE_TREE: DP-FTRL with adaptive clipping norm descirbed in
# "Differentially Private Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
type: FIXED_GAUSSIAN
# Noise multiplier for the Gaussian noise.
noise_multiplier: 0.1
# The value of the clipping norm.
clip_norm: 0.1
}
Étape 4 : Envoyez la configuration ZIP au serveur Federated Compute.
Envoyez le fichier ZIP et fcp_server_config.json au serveur Federated Compute.
task_builder_client --task_builder_server='http://{federated_compute_server_endpoint}' --saved_model='saved_model' --task_config='fcp_server_config.json'
Le point de terminaison Federated Compute Server est le serveur que vous avez configuré à l'étape 1.
La bibliothèque d'opérateurs intégrée LiteRT n'est compatible qu'avec un nombre limité d'opérateurs TensorFlow (certains opérateurs TensorFlow). L'ensemble d'opérateurs compatibles peut varier selon les versions du module OnDevicePersonalization. Pour garantir la compatibilité, un processus de vérification de l'opérateur est effectué dans le générateur de tâches lors de la création des tâches.
La version minimale prise en charge du module OnDevicePersonalization sera incluse dans les métadonnées de la tâche. Vous trouverez ces informations dans le message d'information du générateur de tâches.
I1023 22:16:53.058027 139653371516736 task_builder_client.py:109] Success! Tasks are built, and artifacts are uploaded to the cloud. I1023 22:16:53.058399 139653371516736 task_builder_client.py:112] applied_algorithms { learning_algo: FED_AVG client_optimizer: SGD server_optimizer: SGD dp_aggregator: FIXED_GAUSSIAN } metric_results { accepted_metrics: "binary_accuracy, binary_crossentropy, recall, precision, auc-roc, auc-pr" } dp_hyperparameters { dp_delta: 0.000001 dp_epsilon: 6.4 noise_multiplier: 1.0 dp_clip_norm: 1.0 num_training_rounds: 10000 } I1023 22:16:53.058594 139653371516736 task_builder_client.py:113] training_task { min_client_version: "341912000" } eval_task { min_client_version: "341812000" }Le serveur de calcul fédéré attribue cette tâche à tous les appareils équipés d'un module OnDevicePersonalization dont la version est supérieure à 341812000.
Si votre modèle inclut des opérations non compatibles avec les modules OnDevicePersonalization, un message d'erreur s'affiche lors de la création de la tâche.
common.TaskBuilderException: Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {'L2Loss': 'L2LossOp<CPUDevice, float>'} . Stop building remaining artifacts.Vous trouverez une liste détaillée des opérations flexibles compatibles sur GitHub.
Créer un APK Android Federated Compute
Pour créer un APK Android Federated Compute, vous devez spécifier le point de terminaison d'URL Federated Compute Server dans votre AndroidManifest.xml, auquel se connecte votre client Federated Compute.
Étape 5 : Spécifier le point de terminaison de l'URL du serveur Federated Compute
Spécifiez le point de terminaison de l'URL du serveur de calcul fédéré (que vous avez configuré à l'étape 1) dans votre fichier AndroidManifest.xml, auquel votre client de calcul fédéré se connecte.
<!-- Contents of AndroidManifest.xml -->
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.odpsample" >
<application android:label="OdpSample">
<!-- XML resource that contains other ODP settings. -->
<property android:name="android.ondevicepersonalization.ON_DEVICE_PERSONALIZATION_CONFIG"
android:resource="@xml/OdpSettings"></property>
<!-- The service that ODP will bind to. -->
<service android:name="com.example.odpsample.SampleService"
android:exported="true" android:isolatedProcess="true" />
</application>
</manifest>
Le fichier de ressources XML spécifié dans la balise <property> doit également déclarer la classe de service dans une balise <service> et spécifier le point de terminaison de l'URL du serveur de calcul fédéré auquel le client de calcul fédéré se connectera:
<!-- Contents of res/xml/OdpSettings.xml -->
<on-device-personalization>
<!-- Name of the service subclass -->
<service name="com.example.odpsample.SampleService">
<!-- If you want to use federated compute feature to train a model,
specify this tag. -->
<federated-compute-settings url="https://fcpserver.com/" />
</service>
</on-device-personalization>
Étape 6 : Implémenter l'API IsolatedWorker#onTrainingExample
Implémentez l'API publique de personnalisation sur l'appareil IsolatedWorker#onTrainingExample pour générer des données d'entraînement.
Le code exécuté dans le IsolatedProcess n'a pas d'accès direct au réseau, aux disques locaux ni aux autres services exécutés sur l'appareil. Toutefois, les API suivantes sont disponibles :
- 'getRemoteData' : données clé-valeur immuables téléchargées à partir de backends distants gérés par le développeur, le cas échéant.
- getLocalData : données clé-valeur modifiables conservées par les développeurs, le cas échéant.
- UserData : données utilisateur fournies par la plate-forme.
- 'getLogReader' : renvoie un DAO pour les tables REQUESTS et EVENTS.
Exemple :
@Override public void onTrainingExample(
@NonNull TrainingExampleInput input,
@NonNull Consumer<TrainingExampleOutput> consumer) {
// Check if the incoming training task is the task we want.
if (input.getPopulationName() == "my_new_population") {
TrainingExampleOutput result = new TrainingExampleOutput.Builder():
RequestLogRecord record = this.getLogReader().getRequestLogRecord(1);
int count = 1;
// Iterate logging event table.
for (ContentValues contentValues: record.rows()) {
Features features = Features.newBuilder()
// Retrieve carrier from user info.
.putFeature("carrier", buildFeature(mUserData.getCarrier()))
// Retrieve features from logging info.
.putFeature("int_feature_1",
buildFeature(contentValues.get("int_feature_1")
result.addTrainingExample(
Example.newBuilder()
.setFeatures(features).build().toByteArray())
.addResumptionToken(
String.format("token%d", count).getBytes()))
.build();
count++;
}
consumer.accept(result.build());
}
}
Étape 7 : Planifier une tâche d'entraînement récurrente.
La personnalisation sur l'appareil fournit un FederatedComputeScheduler permettant aux développeurs de planifier ou d'annuler des tâches de calcul fédérées. Il existe différentes options pour l'appeler via IsolatedWorker, que ce soit de façon planifiée ou à la fin d'un téléchargement asynchrone. Vous trouverez des exemples dans les deux cas.
Option basée sur la planification. Appelez
FederatedComputeScheduler#scheduleàIsolatedWorker#onExecute.@Override public void onExecute( @NonNull ExecuteInput input, @NonNull Consumer<ExecuteOutput> consumer ) { if (input != null && input.getAppParams() != null && input.getAppParams().getString("schedule_training") != null) { if (input.getAppParams().getString("schedule_training").isEmpty()) { consumer.accept(null); return; } TrainingInterval interval = new TrainingInterval.Builder() .setMinimumInterval(Duration.ofSeconds(10)) .setSchedulingMode(2) .build(); FederatedComputeScheduler.Params params = new FederatedComputeScheduler .Params(interval); FederatedComputeInput fcInput = new FederatedComputeInput.Builder() .setPopulationName( input.getAppParams().getString("schedule_training")).build(); mFCScheduler.schedule(params, fcInput); ExecuteOutput result = new ExecuteOutput.Builder().build(); consumer.accept(result); } }Option "Téléchargement terminé". Appelez
FederatedComputeScheduler#scheduledansIsolatedWorker#onDownloadCompletedsi la planification d'une tâche d'entraînement dépend de données ou de processus asynchrones.
Validation
Les étapes suivantes décrivent comment vérifier si la tâche de l'apprentissage fédéré s'exécute correctement.
Étape 8 : Vérifiez si la tâche de l'apprentissage fédéré s'exécute correctement.
Un nouveau point de contrôle du modèle et un nouveau fichier de métriques sont générés à chaque cycle d'agrégation côté serveur.
Les métriques se trouvent dans un fichier au format JSON contenant des paires clé-valeur. Le fichier est généré par la liste de Metrics que vous avez définie à l'étape 3. Voici un exemple de fichier JSON de métriques représentatif:
{"server/client_work/train/binary_accuracy":0.5384615659713745, "server/client_work/train/binary_crossentropy":0.694046676158905, "server/client_work/train/recall":0.20000000298023224, "server/client_work/train/precision":0.3333333432674408, "server/client_work/train/auc-roc":0.3500000238418579, "server/client_work/train/auc-pr":0.44386863708496094, "server/finalizer/update_non_finite":0.0}
Vous pouvez utiliser un script semblable au script suivant pour obtenir les métriques du modèle et surveiller les performances d'entraînement :
import collections
import json
import matplotlib.pyplot as plt
from google.cloud import storage
# The population_name you set in fcp_server_config.json in Step 3.
POPULATION_NAME = 'my_new_population'
# The Google Cloud storage you set in Step 1.
GCS_BUCKET_NAME = 'fcp-gcs'
NUM_TRAINING_ROUND = 1000
storage_client = storage.Client()
bucket = storage_client.bucket(GCS_BUCKET_NAME)
metrics = collections.defaultdict(list)
for i in range(NUM_TRAINING_ROUND):
blob = bucket.blob('{}/{}/1/{}/s/0/metrics'.format(GCS_BUCKET_NAME, POPULATION_NAME, i+1))
with blob.open("r") as f:
metric = json.loads(f.read())
for metric_name in metric.keys():
metrics[metric_name].append(metric[metric_name])
for metric_name in metrics:
print(metric_name)
plt.plot(metrics[metric_name])
plt.show()

Notez que dans l'exemple de graphique précédent :
- L'axe des x correspond au nombre d'entraînements circulaires.
- L'axe des ordonnées correspond à la valeur de l'AUC-ROC de chaque tour.
Entraîner un modèle de classification d'images pour la personnalisation sur l'appareil
Dans ce tutoriel, l'ensemble de données EMNIST est utilisé pour montrer comment exécuter une tâche d'apprentissage fédéré sur l'ODP.
Étape 1 : Créez un modèle tff.learning.models.FunctionalModel.
def get_image_classification_input_spec():
return (
tf.TensorSpec([None, 28, 28, 1], tf.float32),
tf.TensorSpec([None, 1], tf.int64),
)
def create_and_save_image_classification_functional_model(
model_path: str,
) -> None:
keras_model = emnist_models.create_original_fedavg_cnn_model(
only_digits=True
)
functional_model = tff.learning.models.functional_model_from_keras(
keras_model=keras_model,
input_spec=get_image_classification_input_spec(),
loss_fn=tf.keras.losses.SparseCategoricalCrossentropy(),
)
tff.learning.models.save_functional_model(functional_model, model_path)
- Vous trouverez les détails du modèle Keras emnist dans emnist_models.
- TfLite n'est pas encore compatible avec tf.sparse.SparseTensor ni avec tf.RaggedTensor. Essayez d'utiliser tf.Tensor autant que possible lorsque vous créez le modèle.
- L'outil de création de tâches ODP écrase toutes les métriques lors de la création du processus d'apprentissage. Il n'est donc pas nécessaire de spécifier des métriques. Ce sujet sera traité plus en détail à l'Étape 2 : Créez la configuration du générateur de tâches.
Deux types d'entrées de modèle sont acceptés :
Saisissez 1. Un tuple(features_tensor, label_tensor).
- Lors de la création du modèle, l'input_spec se présente comme suit:
def get_input_spec(): return ( tf.TensorSpec([None, 28, 28, 1], tf.float32), tf.TensorSpec([None, 1], tf.int64), )- Associez ce qui précède à l'implémentation suivante de l'API publique ODP IsolatedWorker#onTrainingExamples pour générer des données d'entraînement sur l'appareil :
return tf.train.Example( features=tf.train.Features( feature={ 'x': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0] * 784) ), 'y': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()Type 2.
Tuple(Dict[feature_name, feature_tensor], label_tensor)- Lorsque vous créez le modèle, input_spec se présente comme suit :
def get_input_spec() -> ( Tuple[collections.OrderedDict[str, tf.TensorSpec], tf.TensorSpec] ): return ( collections.OrderedDict( [('feature-1', tf.TensorSpec([None, 1], tf.float32)), ('feature-2', tf.TensorSpec([None, 1], tf.float32))] ), tf.TensorSpec([None, 1], tf.int64), )- Associez ce qui précède à l'implémentation suivante de l'API publique ODP IsolatedWorker#onTrainingExamples pour générer des données d'entraînement :
return tf.train.Example( features=tf.train.Features( feature={ 'feature-1': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0]) ), 'feature-2': tf.train.Feature( float_list=tf.train.FloatList(value=[2.0]) ), 'my_label': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()- N'oubliez pas d'enregistrer label_name dans la configuration de l'outil de création de tâches.
mode: TRAINING_AND_EVAL # Task execution mode population_name: "my_example_model" label_name: "my_label"
L'ODP gère automatiquement la DP lors de la création du processus d'apprentissage. Il n'est donc pas nécessaire d'ajouter du bruit lors de la création du modèle fonctionnel.
La sortie de ce modèle fonctionnel enregistré devrait ressembler à l'exemple de notre dépôt GitHub.
Étape 2 : Créer la configuration du générateur de tâches
Vous trouverez des exemples de configuration du générateur de tâches dans notre dépôt GitHub.
Métriques d'entraînement et d'évaluation
Étant donné que les métriques peuvent divulguer des données utilisateur, l'outil de création de tâches contient une liste des métriques que le processus d'apprentissage peut générer et publier. Vous trouverez la liste complète dans notre dépôt GitHub.
Voici un exemple de liste de métriques lorsque vous créez une configuration de générateur de tâches:
federated_learning { learning_process { metrics { name: "binary_accuracy" } metrics { name: "binary_crossentropy" } metrics { name: "recall" } metrics { name: "precision" } metrics { name: "auc-roc" } metrics { name: "auc-pr" } } }
Si les métriques qui vous intéressent ne figurent pas dans la liste actuelle, contactez-nous.
Configurations DP
Vous devez spécifier quelques configurations liées à DP:
policies { min_separation_policy { minimum_separation: 1 } model_release_policy { num_max_training_rounds: 1000 dp_target_epsilon: 10 dp_delta: 0.000001 } } differential_privacy { type: FIXED_GAUSSIAN clip_norm: 0.1 noise_multiplier: 0.1 }dp_target_epsilonounoise_mulitipilerest présent pour réussir la validation : (noise_to_epsilonepislon_to_noise).- Vous trouverez ces paramètres par défaut dans notre dépôt GitHub.
Étape 3 : Importez le modèle enregistré et la configuration du générateur de tâches dans le stockage cloud de n'importe quel développeur
N'oubliez pas de mettre à jour les champs artifact_building lorsque vous importez la configuration du générateur de tâches.
Étape 4 : (Facultatif) Tester la compilation d'artefacts sans créer de tâche
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint}
L'exemple de modèle est validé à la fois par la vérification des opérations flexibles et par la vérification des dp. Vous pouvez ajouter skip_flex_ops_check et skip_dp_check pour contourner la validation (ce modèle ne peut pas être déployé dans la version actuelle du client ODP en raison de quelques opérations flexibles manquantes).
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint} --skip_flex_ops_check=True --skip_dp_check=True
flex_ops_check: la bibliothèque d'opérateurs intégrée TensorFlow Lite n'est compatible qu'avec un nombre limité d'opérateurs TensorFlow (compatibilité avec TensorFlow Lite et les opérateurs TensorFlow). Toutes les opérations TensorFlow incompatibles doivent être installées à l'aide du délégué flex (Android.bp). Si un modèle contient des opérations non compatibles, contactez-nous pour les enregistrer :
Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {...}Le meilleur moyen de déboguer un générateur de tâches consiste à en démarrer un localement:
# Starts a server at localhost:5000 bazel run //python/taskbuilder:task_builder # Links to a server at localhost:5000 by removing task_builder_server flag bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --skip_flex_ops_check=True --skip_dp_check=True
Vous pouvez trouver les artefacts correspondants dans Cloud Storage spécifié dans la configuration. Ce devrait ressembler à l'exemple de notre dépôt GitHub.
Étape 5 : Créez des artefacts et une paire de tâches d'entraînement et d'évaluation sur le serveur FCP.
Supprimez l'indicateur build_artifact_only. Les artefacts compilés seront alors importés sur le serveur FCP. Vous devez vérifier qu'une paire de tâches d'entraînement et d'évaluation a bien été créée
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config.pbtxt --task_builder_server=${task_builder_server_endpoint}
Étape 6 : Préparer le côté client de FCP
- Implémentez l'API publique ODP
IsolatedWorker#onTrainingExamplespour générer des données d'entraînement. - Appelez
FederatedComputeScheduler#schedule. - Vous trouverez quelques exemples dans notre dépôt source Android.
Étape 7 : Surveillance
Métriques de serveur
Retrouvez les instructions de configuration dans notre dépôt GitHub.
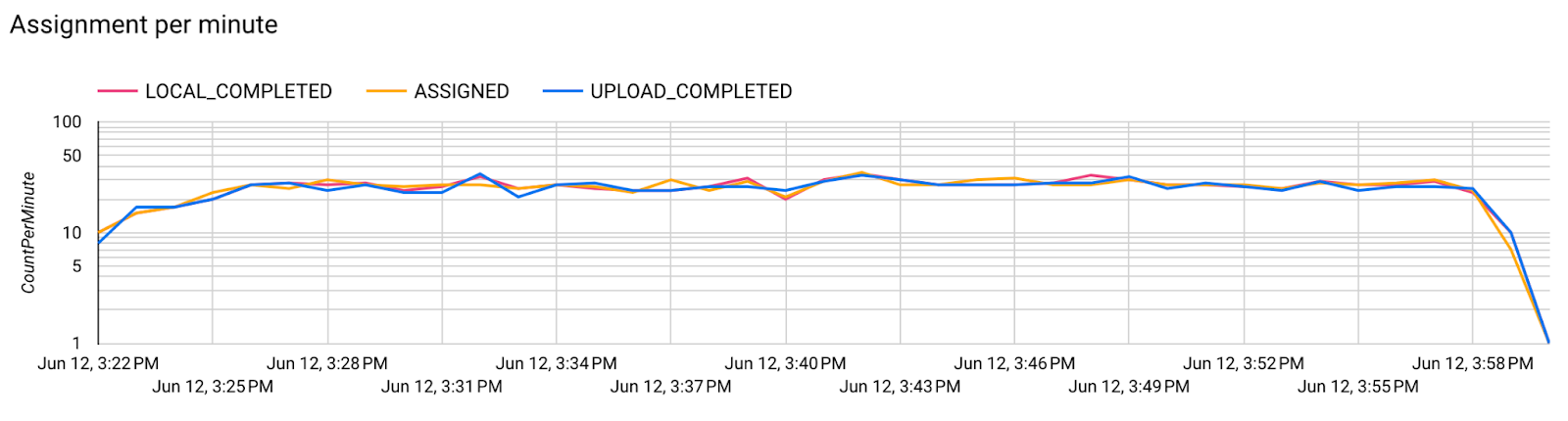
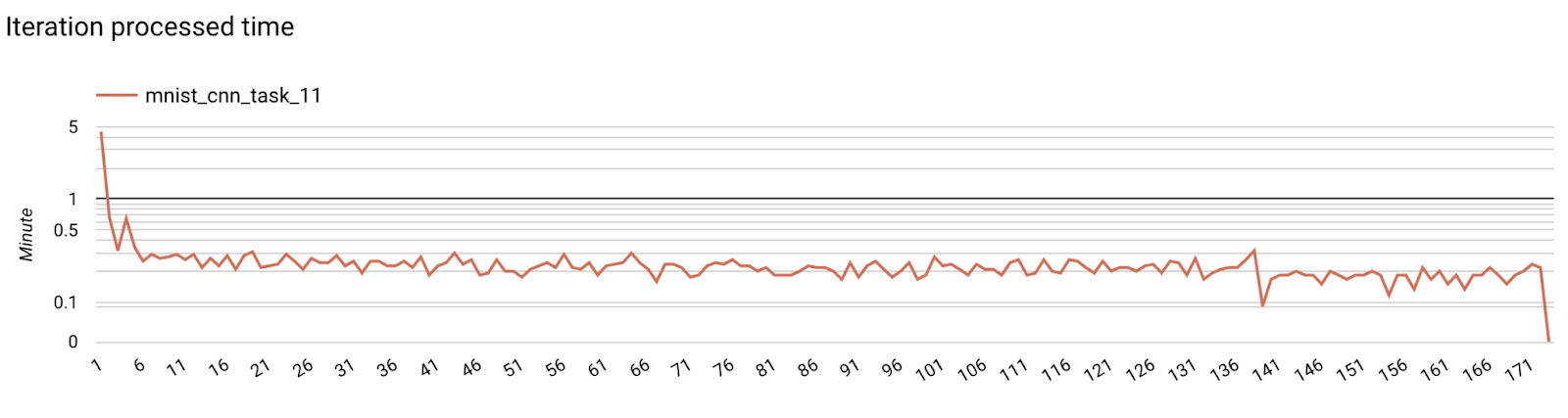

- Métriques du modèle

Il est possible de comparer les métriques de différentes exécutions dans un seul diagramme. Exemple :
- La ligne violette représente
noise_multiplier0,1. - La ligne rose correspond à
noise_multipiler0,3.