이 페이지에서는 온디바이스 맞춤설정에서 제공하는 제휴 학습 API를 사용하여 제휴 평균 학습 프로세스 및 고정 가우스 노이즈로 모델을 학습시키는 방법을 설명합니다.
시작하기 전에
시작하기 전에 테스트 기기에서 다음 단계를 완료하세요.
OnDevicePersonalization 모듈이 설치되어 있는지 확인합니다. 이 모듈은 2024년 4월에 자동 업데이트로 제공되었습니다.
# List the modules installed on the device adb shell pm list packages --apex-only --show-versioncode다음 모듈이 버전 코드 341717000 이상으로 표시되는지 확인합니다.
package:com.google.android.ondevicepersonalization versionCode:341717000해당 모듈이 목록에 없으면 설정 > 보안 및 개인 정보 보호 > 업데이트 > Google Play 시스템 업데이트로 이동하여 기기가 최신 상태인지 확인하세요. 필요에 따라 업데이트를 선택합니다.
모든 제휴 학습 관련 새 기능을 사용 설정합니다.
# Enable On-Device Personalization apk. adb shell device_config put on_device_personalization global_kill_switch false # Enable On-Device Personalization APIs. adb shell device_config put on_device_personalization enable_ondevicepersonalization_apis true # Enable On-Device Personalization overriding. adb shell device_config put on_device_personalization enable_personalization_status_override true adb shell device_config put on_device_personalization personalization_status_override_value true # Enable Federated Compute apk. adb shell device_config put on_device_personalization federated_compute_kill_switch false
제휴 학습 태스크 만들기

다이어그램의 숫자는 다음 8단계에서 더 자세히 설명합니다.
제휴 컴퓨팅 서버 구성
제휴 학습은 제휴 컴퓨팅 서버 (감소기)와 클라이언트 집합 (매퍼)에서 실행되는 맵리듀스입니다. 제휴 컴퓨팅 서버는 각 제휴 학습 태스크의 실행 중인 메타데이터 및 모델 정보를 유지관리합니다. 개략적인 설명은 다음과 같습니다.
- 제휴 학습 개발자는 새 작업을 만들고 작업 실행 메타데이터와 모델 정보를 모두 서버에 업로드합니다.
- 제휴 컴퓨팅 클라이언트가 서버에 새 태스크 할당 요청을 시작하면 서버는 태스크의 자격요건을 확인하고 자격요건을 충족하는 태스크 정보를 반환합니다.
- 제휴 컴퓨팅 클라이언트가 로컬 계산을 완료하면 이러한 계산 결과를 서버로 전송합니다. 그런 다음 서버는 이러한 계산 결과에 대해 집계 및 노이즈를 수행하고 결과를 최종 모델에 적용합니다.
이러한 개념에 대한 자세한 내용은 다음을 참조하세요.
ODP는 향상된 버전의 제휴 학습을 사용합니다. 여기서 보정된(중앙 집중식) 노이즈가 모델에 적용되기 전에 집계에 적용됩니다. 노이즈의 규모는 집계가 개인 정보 차등 보호를 유지하도록 합니다.
1단계: 제휴 컴퓨팅 서버 만들기
제휴 컴퓨팅 프로젝트의 안내에 따라 자체 제휴 컴퓨팅 서버를 설정합니다.
2단계: 저장된 FunctionalModel 준비
저장된 'FunctionalModel' 파일을 준비합니다. 'functional_model_from_keras'를 사용하여 'Model'을 'FunctionalModel'로 변환하고 'save_functional_model'을 사용하여 이 'FunctionalModel'을 'SavedModel'로 직렬화할 수 있습니다.
functional_model = tff.learning.models.functional_model_from_keras(keras_model=model)
tff.learning.models.save_functional_model(functional_model, saved_model_path)
3단계: 제휴 컴퓨팅 서버 구성 만들기
정책, 제휴 학습 설정, 개인 정보 차등 보호 설정이 포함된 fcp_server_config.json를 준비합니다. 예:
# Identifies the set of client devices that will participate.
population_name: "my_new_population"
# Options you can choose:
# * TRAINING_ONLY: Only one training task will be generated under this
# population.
# * TRAINING_AND_EVAL: One training task and one evaluation task will be
# generated under this population.
# * EVAL_ONLY: Only one evaluation task will be generated under this
# population.
mode: TRAINING_AND_EVAL
policies {
# Policy for sampling on-device examples. It is checked every time a
# device attempts to start a new training.
min_separation_policy {
# The minimum number of rounds before the same client participated.
minimum_separation: 3
}
# Policy for releasing training results to developers. It is checked
# when uploading a new task to the Federated Compute Server.
model_release_policy {
# Server stops training when number of training rounds reaches this
# number.
num_max_training_rounds: 1000
}
}
# Federated learning setups. They are applied inside Task Builder.
federated_learning {
learning_process {
# Use FED_AVG to build federated learning process. Options you can
# choose:
# * FED_AVG: Federated Averaging algorithm
# (https://arxiv.org/abs/2003.00295)
# * FED_SDG: Federated SGD algorithm
# (https://arxiv.org/abs/1602.05629)
type: FED_AVG
# Optimizer used at client side training. Options you can choose:
# * ADAM
# * SGD
client_optimizer: SGD
# Learning rate used at client side training.
client_learning_rate: 0.01
# Optimizer used at server side training. Options you can choose:
# * ADAM
# * SGD
server_optimizer: ADAM
# Learning rate used at server side training.
sever_learning_rate: 1
runtime_config {
# Number of participating devices for each round of training.
report_goal: 2000
}
# List of metrics to be evaluated by the model during training and
# evaluation. Federated Compute Server provides a list of allowed
# metrics.
metrics {
name: "auc-roc"
}
metrics {
name: "binary_accuracy"
}
}
# Whether or not to generate a corresponding evaluation task under the same
# population. If this field isn't set, only one training task is
# generated under this population.
evaluation {
# The task id under the same population of the source training task that
# this evaluation task evaluates.
source_training_task_id: 1
# Decides how checkpoints from the training task are chosen for
# evaluation.
# * every_k_round: the evaluation task randomly picks one checkpoint
# from the past k rounds of training task checkpoints.
# * every_k_hour: the evaluation task randomly picks one checkpoint
# from the past k hours of training task checkpoints.
checkpoint_selector: "every_1_round"
# The traffic of this evaluation task in this population.
evaluation_traffic: 0.1
# Number of participating devices for each round of evaluation.
report_goal: 200
}
}
# Differential Privacy setups. They are applied inside the Task Builder.
differential_privacy {
# The DP aggregation algorithm you want to use. Options you can choose:
# * FIXED_GAUSSIAN: Federated Learning DP-SGD with fixed clipping norm
# described in "Learning Differentially Private Recurrent
# Language Models" (https://arxiv.org/abs/1710.06963).
# * ADAPTIVE_GAUSSIAN: Federated Learning DP-SGD with quantile-based clip
# norm estimation described in "Differentially Private
# Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
# * TREE: DP-FTRL algorithm described in "Practical and Private (Deep)
# Learning without Sampling or Shuffling"
# (https://arxiv.org/abs/2103.00039).
# * ADADPTIVE_TREE: DP-FTRL with adaptive clipping norm descirbed in
# "Differentially Private Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
type: FIXED_GAUSSIAN
# Noise multiplier for the Gaussian noise.
noise_multiplier: 0.1
# The value of the clipping norm.
clip_norm: 0.1
}
4단계: 제휴 컴퓨팅 서버에 zip 구성을 제출합니다.
ZIP 파일과 fcp_server_config.json를 Federated Compute 서버에 제출합니다.
task_builder_client --task_builder_server='http://{federated_compute_server_endpoint}' --saved_model='saved_model' --task_config='fcp_server_config.json'
제휴 Compute 서버 엔드포인트는 1단계에서 설정한 서버입니다.
LiteRT 내장 연산자 라이브러리는 제한된 수의 TensorFlow 연산자(일부 TensorFlow 연산자)만 지원합니다. 지원되는 연산자 세트는 OnDevicePersonalization 모듈의 버전에 따라 다를 수 있습니다. 호환성을 보장하기 위해 작업 생성 중에 작업 빌더 내에서 연산자 확인 프로세스가 실행됩니다.
지원되는 최소 OnDevicePersonalization 모듈 버전이 태스크 메타데이터에 포함됩니다. 이 정보는 작업 빌더의 정보 메시지에서 확인할 수 있습니다.
I1023 22:16:53.058027 139653371516736 task_builder_client.py:109] Success! Tasks are built, and artifacts are uploaded to the cloud. I1023 22:16:53.058399 139653371516736 task_builder_client.py:112] applied_algorithms { learning_algo: FED_AVG client_optimizer: SGD server_optimizer: SGD dp_aggregator: FIXED_GAUSSIAN } metric_results { accepted_metrics: "binary_accuracy, binary_crossentropy, recall, precision, auc-roc, auc-pr" } dp_hyperparameters { dp_delta: 0.000001 dp_epsilon: 6.4 noise_multiplier: 1.0 dp_clip_norm: 1.0 num_training_rounds: 10000 } I1023 22:16:53.058594 139653371516736 task_builder_client.py:113] training_task { min_client_version: "341912000" } eval_task { min_client_version: "341812000" }제휴 컴퓨팅 서버는 버전이 341812000보다 높은 OnDevicePersonalization 모듈이 장착된 모든 기기에 이 태스크를 할당합니다.
모델에 OnDevicePersonalization 모듈에서 지원하지 않는 작업이 포함된 경우 작업 생성 중에 오류 메시지가 생성됩니다.
common.TaskBuilderException: Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {'L2Loss': 'L2LossOp<CPUDevice, float>'} . Stop building remaining artifacts.지원되는 flex 연산의 자세한 목록은 GitHub에서 확인할 수 있습니다.
Android 제휴 컴퓨팅 APK 만들기
Android 제휴 컴퓨팅 APK를 만들려면 제휴 컴퓨팅 클라이언트가 연결되는 AndroidManifest.xml에서 제휴 컴퓨팅 서버 URL 엔드포인트를 지정해야 합니다.
5단계: 제휴 Compute Server URL 엔드포인트 지정
제휴 컴퓨팅 클라이언트가 연결되는 AndroidManifest.xml에서 제휴 컴퓨팅 서버 URL 엔드포인트(1단계에서 설정)를 지정합니다.
<!-- Contents of AndroidManifest.xml -->
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.odpsample" >
<application android:label="OdpSample">
<!-- XML resource that contains other ODP settings. -->
<property android:name="android.ondevicepersonalization.ON_DEVICE_PERSONALIZATION_CONFIG"
android:resource="@xml/OdpSettings"></property>
<!-- The service that ODP will bind to. -->
<service android:name="com.example.odpsample.SampleService"
android:exported="true" android:isolatedProcess="true" />
</application>
</manifest>
<property> 태그에 지정된 XML 리소스 파일도 <service> 태그에 서비스 클래스를 선언하고 제휴 컴퓨팅 클라이언트가 연결될 제휴 컴퓨팅 서버 URL 엔드포인트를 지정해야 합니다.
<!-- Contents of res/xml/OdpSettings.xml -->
<on-device-personalization>
<!-- Name of the service subclass -->
<service name="com.example.odpsample.SampleService">
<!-- If you want to use federated compute feature to train a model,
specify this tag. -->
<federated-compute-settings url="https://fcpserver.com/" />
</service>
</on-device-personalization>
6단계: IsolatedWorker#onTrainingExample API 구현
온디바이스 맞춤설정 공개 API IsolatedWorker#onTrainingExample를 구현하여 학습 데이터를 생성합니다.
IsolatedProcess에서 실행되는 코드는 네트워크, 로컬 디스크 또는 기기에서 실행되는 기타 서비스에 직접 액세스할 수 없지만 다음 API는 사용할 수 있습니다.
- 'getRemoteData' - 해당하는 경우 개발자가 운영하는 원격 백엔드에서 다운로드한 변경 불가능한 키-값 데이터입니다.
- 'getLocalData' - 해당되는 경우 개발자가 로컬로 유지하는 변경 가능한 키-값 데이터입니다.
- 'UserData' - 플랫폼에서 제공하는 사용자 데이터입니다.
- 'getLogReader' - REQUESTS 및 EVENTS 테이블의 DAO를 반환합니다.
예:
@Override public void onTrainingExample(
@NonNull TrainingExampleInput input,
@NonNull Consumer<TrainingExampleOutput> consumer) {
// Check if the incoming training task is the task we want.
if (input.getPopulationName() == "my_new_population") {
TrainingExampleOutput result = new TrainingExampleOutput.Builder():
RequestLogRecord record = this.getLogReader().getRequestLogRecord(1);
int count = 1;
// Iterate logging event table.
for (ContentValues contentValues: record.rows()) {
Features features = Features.newBuilder()
// Retrieve carrier from user info.
.putFeature("carrier", buildFeature(mUserData.getCarrier()))
// Retrieve features from logging info.
.putFeature("int_feature_1",
buildFeature(contentValues.get("int_feature_1")
result.addTrainingExample(
Example.newBuilder()
.setFeatures(features).build().toByteArray())
.addResumptionToken(
String.format("token%d", count).getBytes()))
.build();
count++;
}
consumer.accept(result.build());
}
}
7단계: 반복 학습 작업을 예약합니다.
온디바이스 맞춤설정은 개발자가 제휴 컴퓨팅 작업을 예약하거나 취소할 수 있는 FederatedComputeScheduler를 제공합니다. IsolatedWorker를 통해 일정에 따라 또는 비동기 다운로드가 완료될 때 호출하는 다양한 옵션이 있습니다. 두 가지 모두의 예는 다음과 같습니다.
일정 기반 옵션
IsolatedWorker#onExecute에서FederatedComputeScheduler#schedule을 호출합니다.@Override public void onExecute( @NonNull ExecuteInput input, @NonNull Consumer<ExecuteOutput> consumer ) { if (input != null && input.getAppParams() != null && input.getAppParams().getString("schedule_training") != null) { if (input.getAppParams().getString("schedule_training").isEmpty()) { consumer.accept(null); return; } TrainingInterval interval = new TrainingInterval.Builder() .setMinimumInterval(Duration.ofSeconds(10)) .setSchedulingMode(2) .build(); FederatedComputeScheduler.Params params = new FederatedComputeScheduler .Params(interval); FederatedComputeInput fcInput = new FederatedComputeInput.Builder() .setPopulationName( input.getAppParams().getString("schedule_training")).build(); mFCScheduler.schedule(params, fcInput); ExecuteOutput result = new ExecuteOutput.Builder().build(); consumer.accept(result); } }전체 옵션 다운로드 학습 작업 예약이 비동기 데이터 또는 프로세스에 종속되는 경우
IsolatedWorker#onDownloadCompleted에서FederatedComputeScheduler#schedule를 호출합니다.
유효성 검사
다음 단계에서는 제휴 학습 작업이 올바르게 실행되고 있는지 확인하는 방법을 설명합니다.
8단계: 제휴 학습 작업이 올바르게 실행되고 있는지 확인합니다.
서버 측 집계를 진행할 때마다 새 모델 체크포인트와 새 측정항목 파일이 생성됩니다.
측정항목은 키-값 쌍의 JSON 형식 파일에 있습니다. 파일은 3단계에서 정의한 Metrics 목록에 의해 생성됩니다. 대표적인 측정항목 JSON 파일의 예는 다음과 같습니다.
{"server/client_work/train/binary_accuracy":0.5384615659713745, "server/client_work/train/binary_crossentropy":0.694046676158905, "server/client_work/train/recall":0.20000000298023224, "server/client_work/train/precision":0.3333333432674408, "server/client_work/train/auc-roc":0.3500000238418579, "server/client_work/train/auc-pr":0.44386863708496094, "server/finalizer/update_non_finite":0.0}
다음 스크립트와 유사한 것을 사용하여 모델 측정항목을 가져오고 학습 성능을 모니터링할 수 있습니다.
import collections
import json
import matplotlib.pyplot as plt
from google.cloud import storage
# The population_name you set in fcp_server_config.json in Step 3.
POPULATION_NAME = 'my_new_population'
# The Google Cloud storage you set in Step 1.
GCS_BUCKET_NAME = 'fcp-gcs'
NUM_TRAINING_ROUND = 1000
storage_client = storage.Client()
bucket = storage_client.bucket(GCS_BUCKET_NAME)
metrics = collections.defaultdict(list)
for i in range(NUM_TRAINING_ROUND):
blob = bucket.blob('{}/{}/1/{}/s/0/metrics'.format(GCS_BUCKET_NAME, POPULATION_NAME, i+1))
with blob.open("r") as f:
metric = json.loads(f.read())
for metric_name in metric.keys():
metrics[metric_name].append(metric[metric_name])
for metric_name in metrics:
print(metric_name)
plt.plot(metrics[metric_name])
plt.show()

위의 예시 그래프에서 다음 사항에 유의하세요.
- x축은 학습 라운드 수입니다.
- y축은 각 라운드의 auc-roc 값입니다.
기기 내 맞춤설정에서 이미지 분류 모델 학습
이 가이드에서는 EMNIST 데이터 세트를 사용해 ODP에서 제휴 학습 작업을 실행하는 방법을 보여줍니다.
1단계: tff.learning.models.FunctionalModel을 만듭니다.
def get_image_classification_input_spec():
return (
tf.TensorSpec([None, 28, 28, 1], tf.float32),
tf.TensorSpec([None, 1], tf.int64),
)
def create_and_save_image_classification_functional_model(
model_path: str,
) -> None:
keras_model = emnist_models.create_original_fedavg_cnn_model(
only_digits=True
)
functional_model = tff.learning.models.functional_model_from_keras(
keras_model=keras_model,
input_spec=get_image_classification_input_spec(),
loss_fn=tf.keras.losses.SparseCategoricalCrossentropy(),
)
tff.learning.models.save_functional_model(functional_model, model_path)
- emnist keras 모델 세부정보는 emnist_models에서 확인할 수 있습니다.
- TfLite는 아직 tf.sparse.SparseTensor 또는 tf.RaggedTensor를 제대로 지원하지 않습니다. 모델을 빌드할 때는 tf.Tensor를 최대한 많이 사용합니다.
- ODP 작업 빌더는 학습 프로세스를 빌드할 때 모든 측정항목을 덮어쓰므로 측정항목을 지정할 필요가 없습니다. 이 주제는 2단계 태스크 빌더 구성을 만듭니다.
두 가지 유형의 모델 입력이 지원됩니다.
유형 1. 튜플(features_tensor, label_tensor)입니다.
- 모델을 만들 때 input_spec은 다음과 같습니다.
def get_input_spec(): return ( tf.TensorSpec([None, 28, 28, 1], tf.float32), tf.TensorSpec([None, 1], tf.int64), )- 이전 항목을 다음 ODP 공개 API IsolatedWorker#onTrainingExamples와 페어링하여 기기에서 학습 데이터를 생성합니다.
return tf.train.Example( features=tf.train.Features( feature={ 'x': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0] * 784) ), 'y': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()유형 2.
Tuple(Dict[feature_name, feature_tensor], label_tensor)- 모델을 만들 때 input_spec은 다음과 같습니다.
def get_input_spec() -> ( Tuple[collections.OrderedDict[str, tf.TensorSpec], tf.TensorSpec] ): return ( collections.OrderedDict( [('feature-1', tf.TensorSpec([None, 1], tf.float32)), ('feature-2', tf.TensorSpec([None, 1], tf.float32))] ), tf.TensorSpec([None, 1], tf.int64), )- 앞의 API를 다음 ODP 공개 API IsolatedWorker#onTrainingExamples와 페어링하여 학습 데이터를 생성합니다.
return tf.train.Example( features=tf.train.Features( feature={ 'feature-1': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0]) ), 'feature-2': tf.train.Feature( float_list=tf.train.FloatList(value=[2.0]) ), 'my_label': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()- 태스크 빌더 구성에서 label_name을 등록해야 합니다.
mode: TRAINING_AND_EVAL # Task execution mode population_name: "my_example_model" label_name: "my_label"
ODP는 학습 프로세스를 빌드할 때 DP를 자동으로 처리합니다. 따라서 기능 모델을 만들 때 노이즈를 추가할 필요가 없습니다.
저장된 함수 모델의 출력은 GitHub 저장소의 샘플과 같이 표시됩니다.
2단계: 태스크 빌더 구성 만들기
GitHub 저장소에서 작업 빌더 구성 샘플을 확인할 수 있습니다.
학습 및 평가 측정항목
측정항목에서 사용자 데이터가 유출될 수 있다는 점을 감안할 때 Task Builder에는 학습 프로세스에서 생성하고 해제할 수 있는 측정항목 목록이 있습니다. GitHub 저장소에서 전체 목록을 확인할 수 있습니다.
다음은 새 태스크 빌더 구성을 만들 때의 측정항목 목록입니다.
federated_learning { learning_process { metrics { name: "binary_accuracy" } metrics { name: "binary_crossentropy" } metrics { name: "recall" } metrics { name: "precision" } metrics { name: "auc-roc" } metrics { name: "auc-pr" } } }
관심 있는 측정항목이 현재 목록에 없는 경우 Google에 문의하세요.
DP 구성
지정해야 하는 DP 관련 구성은 다음과 같습니다.
policies { min_separation_policy { minimum_separation: 1 } model_release_policy { num_max_training_rounds: 1000 dp_target_epsilon: 10 dp_delta: 0.000001 } } differential_privacy { type: FIXED_GAUSSIAN clip_norm: 0.1 noise_multiplier: 0.1 }- 유효성 검사를 통과하기 위해
dp_target_epsilon또는noise_mulitipiler가 있습니다(noise_to_epsilonepislon_to_noise). - GitHub 저장소에서 이러한 기본 설정을 확인할 수 있습니다.
- 유효성 검사를 통과하기 위해
3단계: 저장된 모델 및 작업 빌더 구성을 개발자의 클라우드 스토리지에 업로드합니다.
작업 빌더 구성을 업로드할 때 artifact_building 필드를 업데이트해야 합니다.
4단계: (선택사항) 새 태스크를 만들지 않고 아티팩트 빌드 테스트
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint}
샘플 모델은 Flex Ops 검사와 dp 검사를 모두 통해 검증됩니다. skip_flex_ops_check와 skip_dp_check를 추가하여 검증 중에 우회할 수 있습니다 (일부 Flex 작업이 누락되어 현재 버전의 ODP 클라이언트에 이 모델을 배포할 수 없음).
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint} --skip_flex_ops_check=True --skip_dp_check=True
flex_ops_check: TensorFlow Lite 내장 연산자 라이브러리는 제한된 수의 TensorFlow 연산자만 지원합니다(TensorFlow Lite 및 TensorFlow 연산자 호환성). 호환되지 않는 모든 TensorFlow 작업은 flex 대리자(Android.bp)를 사용하여 설치해야 합니다. 모델에 지원되지 않는 작업이 포함된 경우 Google에 문의하여 등록하세요.
Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {...}작업 빌더를 디버그하는 가장 좋은 방법은 로컬에서 시작하는 것입니다.
# Starts a server at localhost:5000 bazel run //python/taskbuilder:task_builder # Links to a server at localhost:5000 by removing task_builder_server flag bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --skip_flex_ops_check=True --skip_dp_check=True
구성에 지정된 Cloud Storage에서 결과 아티팩트를 찾을 수 있습니다. GitHub 저장소의 예와 같이 표시됩니다.
5단계: 아티팩트를 빌드하고 FCP 서버에서 새 학습 및 평가 작업 쌍을 만듭니다.
build_artifact_only 플래그를 삭제하면 빌드된 아티팩트가 FCP 서버에 업로드됩니다. 학습 태스크와 평가 태스크 쌍이 성공적으로 생성되었는지 확인해야 합니다.
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config.pbtxt --task_builder_server=${task_builder_server_endpoint}
6단계: FCP 클라이언트 측 준비
- ODP 공개 API
IsolatedWorker#onTrainingExamples를 구현하여 학습 데이터를 생성합니다. FederatedComputeScheduler#schedule을 호출합니다.- Android 소스 저장소에서 예시를 몇 가지 확인해 보세요.
7단계: 모니터링
서버 측정항목
GitHub 저장소에서 설정 안내를 확인하세요.
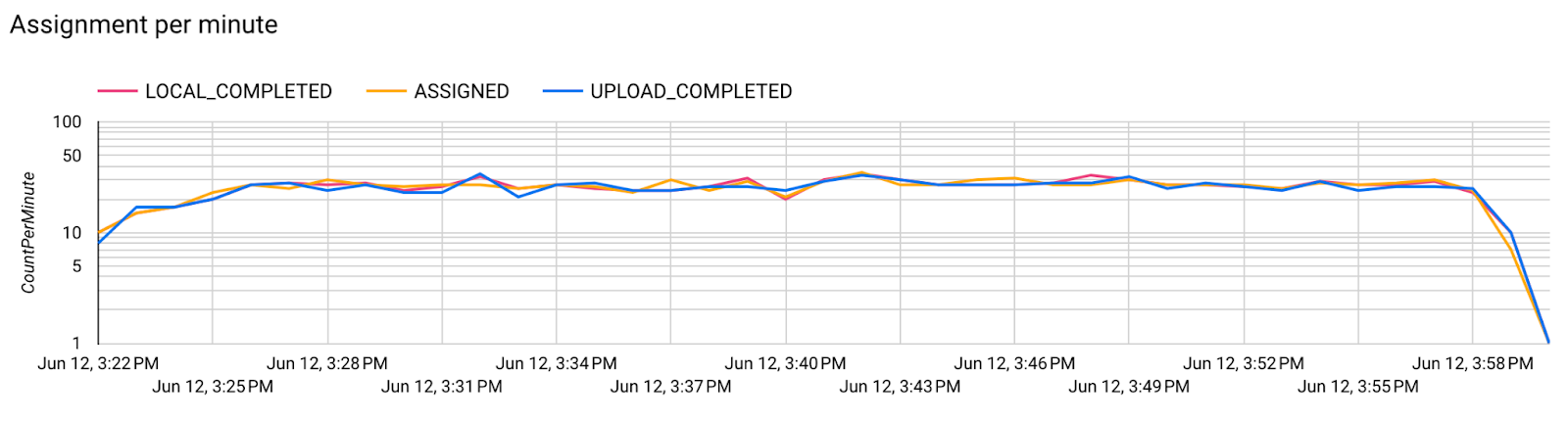
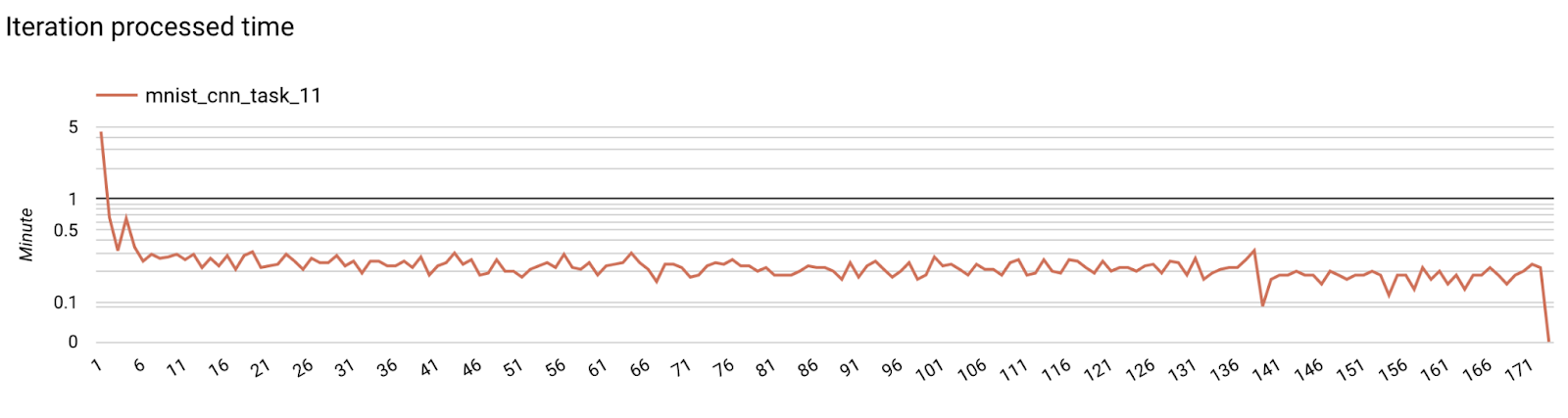

- 모델 측정항목

하나의 다이어그램에서 여러 실행의 측정항목을 비교할 수 있습니다. 예를 들면 다음과 같습니다.
- 보라색 선은
noise_multiplier0.1입니다. - 분홍색 선은
noise_multipiler0.3입니다.