Bu sayfada, ortalama ortalama öğrenim süreci ve sabit Gauss gürültüsü içeren bir modeli eğitmek için Cihaz üzerinde Kişiselleştirme tarafından sağlanan Birleşik Öğrenim API'leriyle nasıl çalışılacağı açıklanmaktadır.
Başlamadan önce
Başlamadan önce test cihazınızda aşağıdaki adımları tamamlayın:
OnDevicePersonalization modülünün yüklü olduğundan emin olun. Modül, Nisan 2024'te otomatik güncelleme olarak kullanıma sunuldu.
# List the modules installed on the device adb shell pm list packages --apex-only --show-versioncodeAşağıdaki modülün 341717000 veya daha sonraki bir sürüm koduyla listelendiğinden emin olun:
package:com.google.android.ondevicepersonalization versionCode:341717000Modül listede yoksa cihazınızın güncel olduğundan emin olmak için Ayarlar > Güvenlik ve gizlilik > Güncellemeler > Google Play sistem güncellemesi'ne gidin. Gerektiği şekilde Güncelle'yi seçin.
Birleşik Öğrenim ile ilgili tüm yeni özellikleri etkinleştir.
# Enable On-Device Personalization apk. adb shell device_config put on_device_personalization global_kill_switch false # Enable On-Device Personalization APIs. adb shell device_config put on_device_personalization enable_ondevicepersonalization_apis true # Enable On-Device Personalization overriding. adb shell device_config put on_device_personalization enable_personalization_status_override true adb shell device_config put on_device_personalization personalization_status_override_value true # Enable Federated Compute apk. adb shell device_config put on_device_personalization federated_compute_kill_switch false
Birleşik Öğrenim görevi oluşturma

Şemada gösterilen sayılar aşağıdaki sekiz adımda daha ayrıntılı olarak açıklanmıştır.
Birleşik Compute Server Yapılandırma
Birleşik Öğrenim, Birleşik Hesaplama Sunucusu'nda (azaltıcı) ve bir istemci grubunda (eşleyiciler) çalışan bir eşleme-azaltma işlemidir. Birleşik Bilgi İşlem sunucusu, her Birleşik Öğrenme görevinin çalışan meta verilerini ve model bilgilerini korur. Özet olarak:
- Bir Birleşik Öğrenim geliştiricisi yeni bir görev oluşturur ve hem görev çalıştırma meta verilerini hem de model bilgilerini sunucuya yükler.
- Bir Federated Compute istemcisi sunucuya yeni bir görev atama isteği başlattığında sunucu, görevin uygunluğunu kontrol eder ve uygun görev bilgilerini döndürür.
- Bir Federated Compute istemcisi yerel hesaplamaları tamamladıktan sonra bu hesaplama sonuçlarını sunucuya gönderir. Ardından sunucu, bu hesaplama sonuçlarını toplar ve gürültü ekler ve sonucu nihai modele uygular.
Bu kavramlar hakkında daha fazla bilgi edinmek için şu makaleleri inceleyebilirsiniz:
- Birleşik Öğrenim: Merkezi Eğitim Verileri İçermeyen İşbirliğine Dayalı Makine Öğrenimi
- Büyük Ölçekte Birleşik Öğrenim İçin: Sistem Tasarımı (SysML 2019)
ODP, Birleşik Öğrenim'in gelişmiş bir sürümünü kullanır. Bu sürümde, kalibre edilmiş (merkezileştirilmiş) gürültü, modele uygulanmadan önce toplamalara uygulanır. Gürültünün ölçeği, toplamaların diferansiyel gizliliği korumasını sağlar.
1. Adım: Birleşik Compute Server Oluşturma
Kendi Birleşik Compute Sunucunuzu kurmak için Birleşik Compute projesindeki talimatları uygulayın.
2. adım: Kayıtlı bir işlevsel model hazırlama
Kayıtlı bir 'FunctionalModel' dosyası hazırlayın. Bir "Model"i "FunctionalModel" yapmak için 'functional_model_from_keras' yöntemini kullanabilir ve bu 'FunctionalModel'i, "SavedModel" olarak serileştirmek için 'save_function_model' komutunu kullanabilirsiniz.
functional_model = tff.learning.models.functional_model_from_keras(keras_model=model)
tff.learning.models.save_functional_model(functional_model, saved_model_path)
3. Adım: Birleşik Compute Server yapılandırması oluşturma
Politikaları, birleşik öğrenim kurulumunu ve diferansiyel gizlilik kurulumunu içeren bir fcp_server_config.json hazırlayın. Örnek:
# Identifies the set of client devices that will participate.
population_name: "my_new_population"
# Options you can choose:
# * TRAINING_ONLY: Only one training task will be generated under this
# population.
# * TRAINING_AND_EVAL: One training task and one evaluation task will be
# generated under this population.
# * EVAL_ONLY: Only one evaluation task will be generated under this
# population.
mode: TRAINING_AND_EVAL
policies {
# Policy for sampling on-device examples. It is checked every time a
# device attempts to start a new training.
min_separation_policy {
# The minimum number of rounds before the same client participated.
minimum_separation: 3
}
# Policy for releasing training results to developers. It is checked
# when uploading a new task to the Federated Compute Server.
model_release_policy {
# Server stops training when number of training rounds reaches this
# number.
num_max_training_rounds: 1000
}
}
# Federated learning setups. They are applied inside Task Builder.
federated_learning {
learning_process {
# Use FED_AVG to build federated learning process. Options you can
# choose:
# * FED_AVG: Federated Averaging algorithm
# (https://arxiv.org/abs/2003.00295)
# * FED_SDG: Federated SGD algorithm
# (https://arxiv.org/abs/1602.05629)
type: FED_AVG
# Optimizer used at client side training. Options you can choose:
# * ADAM
# * SGD
client_optimizer: SGD
# Learning rate used at client side training.
client_learning_rate: 0.01
# Optimizer used at server side training. Options you can choose:
# * ADAM
# * SGD
server_optimizer: ADAM
# Learning rate used at server side training.
sever_learning_rate: 1
runtime_config {
# Number of participating devices for each round of training.
report_goal: 2000
}
# List of metrics to be evaluated by the model during training and
# evaluation. Federated Compute Server provides a list of allowed
# metrics.
metrics {
name: "auc-roc"
}
metrics {
name: "binary_accuracy"
}
}
# Whether or not to generate a corresponding evaluation task under the same
# population. If this field isn't set, only one training task is
# generated under this population.
evaluation {
# The task id under the same population of the source training task that
# this evaluation task evaluates.
source_training_task_id: 1
# Decides how checkpoints from the training task are chosen for
# evaluation.
# * every_k_round: the evaluation task randomly picks one checkpoint
# from the past k rounds of training task checkpoints.
# * every_k_hour: the evaluation task randomly picks one checkpoint
# from the past k hours of training task checkpoints.
checkpoint_selector: "every_1_round"
# The traffic of this evaluation task in this population.
evaluation_traffic: 0.1
# Number of participating devices for each round of evaluation.
report_goal: 200
}
}
# Differential Privacy setups. They are applied inside the Task Builder.
differential_privacy {
# The DP aggregation algorithm you want to use. Options you can choose:
# * FIXED_GAUSSIAN: Federated Learning DP-SGD with fixed clipping norm
# described in "Learning Differentially Private Recurrent
# Language Models" (https://arxiv.org/abs/1710.06963).
# * ADAPTIVE_GAUSSIAN: Federated Learning DP-SGD with quantile-based clip
# norm estimation described in "Differentially Private
# Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
# * TREE: DP-FTRL algorithm described in "Practical and Private (Deep)
# Learning without Sampling or Shuffling"
# (https://arxiv.org/abs/2103.00039).
# * ADADPTIVE_TREE: DP-FTRL with adaptive clipping norm descirbed in
# "Differentially Private Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
type: FIXED_GAUSSIAN
# Noise multiplier for the Gaussian noise.
noise_multiplier: 0.1
# The value of the clipping norm.
clip_norm: 0.1
}
4. Adım. Sıkıştırılmış yapılandırmayı Federated Compute sunucusuna gönderin.
ZIP dosyasını ve fcp_server_config.json dosyasını Birleşik Compute sunucusuna gönderin.
task_builder_client --task_builder_server='http://{federated_compute_server_endpoint}' --saved_model='saved_model' --task_config='fcp_server_config.json'
Birleşik Compute Server uç noktası, 1. adımda ayarladığınız sunucudur.
LiteRT'ın yerleşik operatör kitaplığı yalnızca sınırlı sayıda TensorFlow operatörünü destekler (Seçilen TensorFlow operatörleri). Desteklenen operatör grubu, OnDevicePersonalization modülünün farklı sürümlerinde değişiklik gösterebilir. Uyumluluğu sağlamak için görev oluşturma sırasında görev oluşturucuda bir operatör doğrulama süreci yürütülür.
Desteklenen minimum OnDevicePersonalization modülü sürümü, görev meta verilerine dahil edilir. Bu bilgiler, görev oluşturucunun bilgi mesajında yer alır.
I1023 22:16:53.058027 139653371516736 task_builder_client.py:109] Success! Tasks are built, and artifacts are uploaded to the cloud. I1023 22:16:53.058399 139653371516736 task_builder_client.py:112] applied_algorithms { learning_algo: FED_AVG client_optimizer: SGD server_optimizer: SGD dp_aggregator: FIXED_GAUSSIAN } metric_results { accepted_metrics: "binary_accuracy, binary_crossentropy, recall, precision, auc-roc, auc-pr" } dp_hyperparameters { dp_delta: 0.000001 dp_epsilon: 6.4 noise_multiplier: 1.0 dp_clip_norm: 1.0 num_training_rounds: 10000 } I1023 22:16:53.058594 139653371516736 task_builder_client.py:113] training_task { min_client_version: "341912000" } eval_task { min_client_version: "341812000" }Federated Compute sunucusu, bu görevi 341812000'den daha yeni bir sürüme sahip bir OnDevicePersonalization modülüne sahip tüm cihazlara atar.
Modeliniz, herhangi bir OnDevicePersonalization modülü tarafından desteklenmeyen işlemler içeriyorsa görev oluşturma sırasında bir hata mesajı oluşturulur.
common.TaskBuilderException: Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {'L2Loss': 'L2LossOp<CPUDevice, float>'} . Stop building remaining artifacts.Desteklenen esnek işlemlerin ayrıntılı listesini GitHub'da bulabilirsiniz.
Android Federated Compute APK'sı oluşturma
Android Federated Compute APK'sı oluşturmak için AndroidManifest.xml öğenizde, Federated Compute Client'ınızın bağlandığı Birleşik Compute Server URL uç noktasını belirtmeniz gerekir.
5. Adım: Federated Compute Server URL uç noktasını belirtin
Birleşik Compute İstemcinizin bağlanacağı AndroidManifest.xml bölümünde, 1. adımda ayarladığınız Birleşik Compute Server URL uç noktasını belirtin.
<!-- Contents of AndroidManifest.xml -->
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.odpsample" >
<application android:label="OdpSample">
<!-- XML resource that contains other ODP settings. -->
<property android:name="android.ondevicepersonalization.ON_DEVICE_PERSONALIZATION_CONFIG"
android:resource="@xml/OdpSettings"></property>
<!-- The service that ODP will bind to. -->
<service android:name="com.example.odpsample.SampleService"
android:exported="true" android:isolatedProcess="true" />
</application>
</manifest>
<property> etiketinde belirtilen XML kaynak dosyası, hizmet sınıfını bir <service> etiketinde de tanımlamalı ve birleşik bilgi işlem istemcisinin bağlanacağı birleşik bilgi işlem sunucusu URL uç noktasını belirtmelidir:
<!-- Contents of res/xml/OdpSettings.xml -->
<on-device-personalization>
<!-- Name of the service subclass -->
<service name="com.example.odpsample.SampleService">
<!-- If you want to use federated compute feature to train a model,
specify this tag. -->
<federated-compute-settings url="https://fcpserver.com/" />
</service>
</on-device-personalization>
6. Adım: IsolatedWorker#onTrainingExample API'yi uygulayın
Eğitim verileri oluşturmak için Cihaz Üzerinde Kişiselleştirme herkese açık API'sini IsolatedWorker#onTrainingExample uygulayın.
IsolatedProcess içinde çalışan kodun ağa, yerel disklere veya cihazda çalışan diğer hizmetlere doğrudan erişimi yoktur, ancak aşağıdaki API'ler kullanılabilir:
- "getRemoteData": Varsa, geliştirici tarafından çalıştırılan uzaktan arka uçlardan indirilen sabit anahtar/değer verileri.
- "getLocalData": Geçerliyse, geliştiricilerin yerel olarak sakladığı değişken anahtar/değer çifti verileri.
- "UserData": Kullanıcı verileri, platform tarafından sağlanır.
- 'getLogReader': REQUESTS ve EVENTS tabloları için bir DAO döndürür.
Örnek:
@Override public void onTrainingExample(
@NonNull TrainingExampleInput input,
@NonNull Consumer<TrainingExampleOutput> consumer) {
// Check if the incoming training task is the task we want.
if (input.getPopulationName() == "my_new_population") {
TrainingExampleOutput result = new TrainingExampleOutput.Builder():
RequestLogRecord record = this.getLogReader().getRequestLogRecord(1);
int count = 1;
// Iterate logging event table.
for (ContentValues contentValues: record.rows()) {
Features features = Features.newBuilder()
// Retrieve carrier from user info.
.putFeature("carrier", buildFeature(mUserData.getCarrier()))
// Retrieve features from logging info.
.putFeature("int_feature_1",
buildFeature(contentValues.get("int_feature_1")
result.addTrainingExample(
Example.newBuilder()
.setFeatures(features).build().toByteArray())
.addResumptionToken(
String.format("token%d", count).getBytes()))
.build();
count++;
}
consumer.accept(result.build());
}
}
7. Adım: Yinelenen bir eğitim görevi planlayın.
Cihaz Üzerinde Kişiselleştirme, geliştiricilerin birleşik bilgi işlem işlerini planlamasına veya iptal etmesine FederatedComputeScheduler olanak tanır. IsolatedWorker üzerinden planlı olarak veya eşzamansız bir indirme tamamlandığında çağrılmasını sağlayan farklı seçenekler vardır. Her iki yöntemle ilgili örnekleri aşağıda bulabilirsiniz.
Programa dayalı seçenek.
IsolatedWorker#onExecuteBölgesindeFederatedComputeScheduler#scheduleAranjmanları İçin Arayın.@Override public void onExecute( @NonNull ExecuteInput input, @NonNull Consumer<ExecuteOutput> consumer ) { if (input != null && input.getAppParams() != null && input.getAppParams().getString("schedule_training") != null) { if (input.getAppParams().getString("schedule_training").isEmpty()) { consumer.accept(null); return; } TrainingInterval interval = new TrainingInterval.Builder() .setMinimumInterval(Duration.ofSeconds(10)) .setSchedulingMode(2) .build(); FederatedComputeScheduler.Params params = new FederatedComputeScheduler .Params(interval); FederatedComputeInput fcInput = new FederatedComputeInput.Builder() .setPopulationName( input.getAppParams().getString("schedule_training")).build(); mFCScheduler.schedule(params, fcInput); ExecuteOutput result = new ExecuteOutput.Builder().build(); consumer.accept(result); } }İndirme Tamamlandı Seçeneği. Bir eğitim görevinin planlanması eşzamansız verilere veya işlemlere bağlıysa
IsolatedWorker#onDownloadCompletediçindeFederatedComputeScheduler#scheduleişlevini çağırın.
Doğrulama
Aşağıdaki adımlarda, Birleşik Öğrenim görevinin düzgün çalışıp çalışmadığını nasıl doğrulayacağınız açıklanmaktadır.
8. Adım: Birleştirilmiş Öğrenme görevinin düzgün çalışıp çalışmadığını doğrulayın.
Her sunucu tarafı toplama turunda yeni bir model kontrol noktası ve yeni bir metrik dosyası oluşturulur.
Metrikler, anahtar/değer çiftlerinin JSON biçimli bir dosyasında yer alır. Dosya, 3. adımda tanımladığınız Metrics listesi tarafından oluşturulur. Temsil edici bir metrik JSON dosyası örneği aşağıda verilmiştir:
{"server/client_work/train/binary_accuracy":0.5384615659713745, "server/client_work/train/binary_crossentropy":0.694046676158905, "server/client_work/train/recall":0.20000000298023224, "server/client_work/train/precision":0.3333333432674408, "server/client_work/train/auc-roc":0.3500000238418579, "server/client_work/train/auc-pr":0.44386863708496094, "server/finalizer/update_non_finite":0.0}
Model metriklerini almak ve eğitim performansını izlemek için aşağıdaki komut dosyasına benzer bir şey kullanabilirsiniz:
import collections
import json
import matplotlib.pyplot as plt
from google.cloud import storage
# The population_name you set in fcp_server_config.json in Step 3.
POPULATION_NAME = 'my_new_population'
# The Google Cloud storage you set in Step 1.
GCS_BUCKET_NAME = 'fcp-gcs'
NUM_TRAINING_ROUND = 1000
storage_client = storage.Client()
bucket = storage_client.bucket(GCS_BUCKET_NAME)
metrics = collections.defaultdict(list)
for i in range(NUM_TRAINING_ROUND):
blob = bucket.blob('{}/{}/1/{}/s/0/metrics'.format(GCS_BUCKET_NAME, POPULATION_NAME, i+1))
with blob.open("r") as f:
metric = json.loads(f.read())
for metric_name in metric.keys():
metrics[metric_name].append(metric[metric_name])
for metric_name in metrics:
print(metric_name)
plt.plot(metrics[metric_name])
plt.show()

Önceki örnek grafikte şunları unutmayın:
- X ekseni, eğitim turunun sayısıdır.
- Y ekseni, her turun auc-roc değeridir.
Cihaz üzerinde kişiselleştirmede görüntü sınıflandırma modeli eğitme
Bu eğitimde, ODP'de birleşik öğrenim görevinin nasıl çalıştırılacağını göstermek için EMNIST veri kümesi kullanılmaktadır.
1. Adım: tff.learning.models.FunctionalModel sınıfından bir model oluşturun.
def get_image_classification_input_spec():
return (
tf.TensorSpec([None, 28, 28, 1], tf.float32),
tf.TensorSpec([None, 1], tf.int64),
)
def create_and_save_image_classification_functional_model(
model_path: str,
) -> None:
keras_model = emnist_models.create_original_fedavg_cnn_model(
only_digits=True
)
functional_model = tff.learning.models.functional_model_from_keras(
keras_model=keras_model,
input_spec=get_image_classification_input_spec(),
loss_fn=tf.keras.losses.SparseCategoricalCrossentropy(),
)
tff.learning.models.save_functional_model(functional_model, model_path)
- Emnist keras model ayrıntılarını emnist_models dosyasında bulabilirsiniz.
- TfLite'ta henüz tf.sparse.SparseTensor veya tf.RaggedTensor için yeterli destek yoktur. Modeli oluştururken mümkün olduğunca tf.Tensor kullanmaya çalışın.
- ODP Görev Oluşturucu, öğrenme sürecini oluştururken tüm metriklerin üzerine yazar. Herhangi bir metrik belirtilmesine gerek yoktur. Bu konuyla ilgili daha fazla bilgiyi 2. adımda bulabilirsiniz. Görev Oluşturucu yapılandırmasını oluşturun.
İki tür model girişi desteklenir:
1. tür Tuple(features_tensor, label_tensor).
- Model oluşturulurken enter_spec şu şekilde görünür:
def get_input_spec(): return ( tf.TensorSpec([None, 28, 28, 1], tf.float32), tf.TensorSpec([None, 1], tf.int64), )- Cihazda eğitim verileri oluşturmak için öncekini aşağıdaki ODP herkese açık API'si IsolatedWorker#onTrainingExamples uygulamasıyla eşleyin:
return tf.train.Example( features=tf.train.Features( feature={ 'x': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0] * 784) ), 'y': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()Tür 2.
Tuple(Dict[feature_name, feature_tensor], label_tensor)- Model oluşturulurken enter_spec şu şekilde görünür:
def get_input_spec() -> ( Tuple[collections.OrderedDict[str, tf.TensorSpec], tf.TensorSpec] ): return ( collections.OrderedDict( [('feature-1', tf.TensorSpec([None, 1], tf.float32)), ('feature-2', tf.TensorSpec([None, 1], tf.float32))] ), tf.TensorSpec([None, 1], tf.int64), )- Eğitim verileri oluşturmak için öncekini aşağıdaki ODP herkese açık API'si olan IsolatedWorker#onTrainingExamples uygulamasıyla eşleyin:
return tf.train.Example( features=tf.train.Features( feature={ 'feature-1': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0]) ), 'feature-2': tf.train.Feature( float_list=tf.train.FloatList(value=[2.0]) ), 'my_label': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()- Görev Oluşturucu yapılandırmasında label_name değerini kaydetmeyi unutmayın.
mode: TRAINING_AND_EVAL # Task execution mode population_name: "my_example_model" label_name: "my_label"
ODP, öğrenme sürecini oluştururken DP'yi otomatik olarak işler. Bu nedenle, işlevsel modeli oluştururken gürültü eklemenize gerek yoktur.
Bu kayıtlı işlevsel modelin çıkışı, GitHub depomuzda bulunan örnek gibi görünmelidir.
2. adım: Görev Oluşturucu yapılandırmasını oluşturma
Görev Oluşturucu yapılandırması örneklerini GitHub depomuzda bulabilirsiniz.
Eğitim ve Değerlendirme Metrikleri
Metriklerin kullanıcı verilerini sızdırabileceği göz önünde bulundurulduğunda Görev Oluşturucu'da, öğrenme sürecinin oluşturup yayınlayabileceği metriklerin listesi bulunur. Tam listeyi GitHub depomuzda bulabilirsiniz.
Aşağıda, yeni bir görev oluşturucu yapılandırması oluştururken örnek bir metrik listesi görebilirsiniz:
federated_learning { learning_process { metrics { name: "binary_accuracy" } metrics { name: "binary_crossentropy" } metrics { name: "recall" } metrics { name: "precision" } metrics { name: "auc-roc" } metrics { name: "auc-pr" } } }
İlgilendiğiniz metrikler mevcut listede yoksa bizimle iletişime geçin.
DP yapılandırmaları
DP ile ilgili birkaç yapılandırmanın belirtilmesi gerekir:
policies { min_separation_policy { minimum_separation: 1 } model_release_policy { num_max_training_rounds: 1000 dp_target_epsilon: 10 dp_delta: 0.000001 } } differential_privacy { type: FIXED_GAUSSIAN clip_norm: 0.1 noise_multiplier: 0.1 }- Doğrulamayı geçmek için
dp_target_epsilonveyanoise_mulitipilermevcut: (noise_to_epsilonepislon_to_noise). - Bu varsayılan ayarları GitHub depomuzda bulabilirsiniz.
- Doğrulamayı geçmek için
3. Adım: Kayıtlı modeli ve görev oluşturucu yapılandırmasını herhangi bir geliştiricinin bulut depolama alanına yükleme
Görev Oluşturucu yapılandırmasını yüklerken artifact_building alanlarını güncellemeyi unutmayın.
4. Adım. (isteğe bağlı) Yeni bir görev oluşturmadan yapı oluşturmayı test etme
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint}
Örnek model hem esnek işlem kontrolü hem de DP kontrolü ile doğrulanır. Doğrulama sırasında atlamak için skip_flex_ops_check ve skip_dp_check ekleyebilirsiniz (bu model, eksik birkaç esnek işlem nedeniyle ODP istemcisinin mevcut sürümüne dağıtılamaz).
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint} --skip_flex_ops_check=True --skip_dp_check=True
flex_ops_check: TensorFlow Lite yerleşik operatör kitaplığı yalnızca sınırlı sayıda TensorFlow operatörünü destekler (TensorFlow Lite ve TensorFlow operatör uyumluluğu). Uyumlu olmayan tüm tensorflow işlemlerinin, flex temsilcisi (Android.bp) kullanılarak yüklenmesi gerekir. Bir model desteklenmeyen işlemler içeriyorsa bunları kaydettirmek için bize ulaşın:
Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {...}Görev Oluşturucu'nun hatalarını ayıklamanın en iyi yolu, yerel olarak başlatmaktır:
# Starts a server at localhost:5000 bazel run //python/taskbuilder:task_builder # Links to a server at localhost:5000 by removing task_builder_server flag bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --skip_flex_ops_check=True --skip_dp_check=True
Sonuç olarak elde edilen yapıları, yapılandırmada belirtilen bulut depolama alanında bulabilirsiniz. Bu kod, GitHub depomuzdaki örneğe benzer bir olmalıdır.
5. Adım: FCP sunucusunda yapı oluşturun ve yeni bir eğitim ve değerlendirme görevi çifti oluşturun.
build_artifact_only işaretini kaldırdığınızda oluşturulan yapı FCP sunucusuna yüklenir. Eğitim ve değerlendirme görevlerinden oluşan bir çiftin başarıyla oluşturulduğunu kontrol etmelisiniz.
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config.pbtxt --task_builder_server=${task_builder_server_endpoint}
6. Adım: FCP istemci tarafını hazırlama
- Eğitim verileri oluşturmak için ODP herkese açık API'sini
IsolatedWorker#onTrainingExamplesuygulayın. FederatedComputeScheduler#schedulenumaralı telefonu arayın.- Android kaynak depomuzda birkaç örnek bulabilirsiniz.
7. Adım: İzleme
Sunucu metrikleri
GitHub depomuzda kurulum talimatlarını bulun.
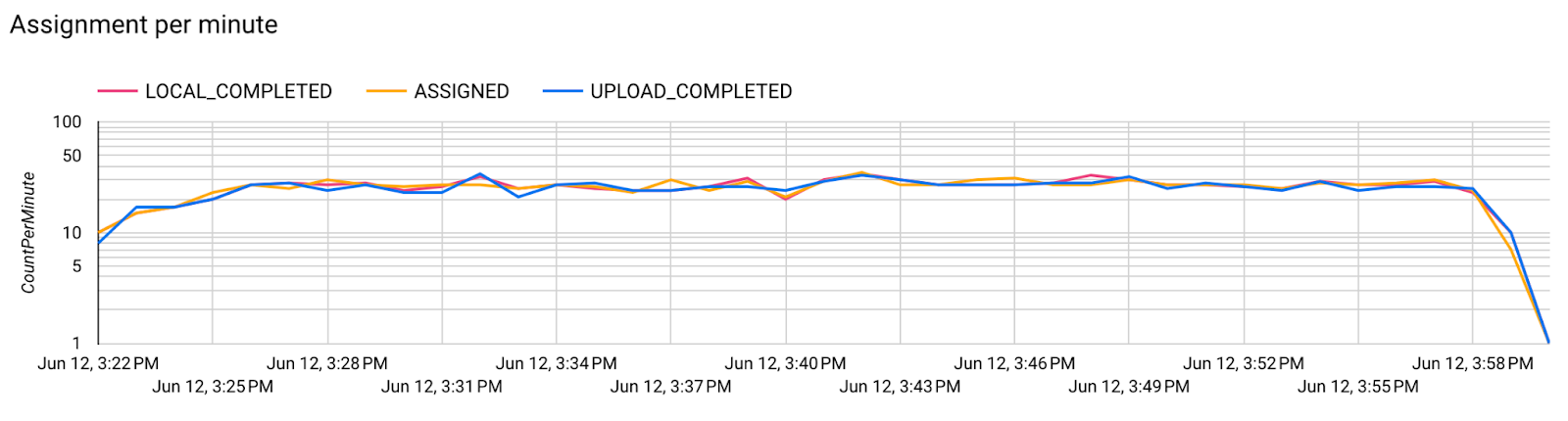
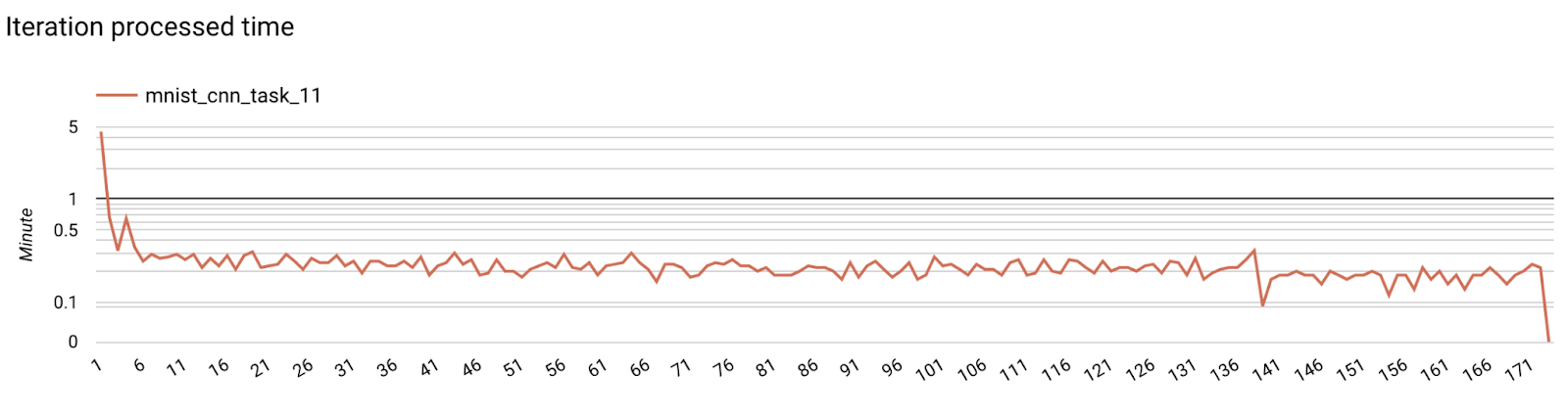

- Model Metrikleri

Farklı çalıştırmalara ait metrikleri tek bir diyagramda karşılaştırmak mümkündür. Örneğin:
- Mor çizgi,
noise_multiplier0,1 ile gösterilmiştir. - Pembe çizgi
noise_multipiler0,3'tür