इसे Android ओपन सोर्स प्रोजेक्ट (एओएसपी) में लागू किया गया था. इस तकनीकी जानकारी में, डिवाइस पर मनमुताबिक अनुभव (ओडीपी) बनाने की वजह, डिज़ाइन से जुड़े सिद्धांत, गोपनीयता मॉडल के ज़रिए इसकी निजता, और इसकी पुष्टि करने वाले निजी अनुभव को पक्का करने में मदद करने के बारे में बताया गया है.
हम डेटा ऐक्सेस मॉडल को आसान बनाकर और यह पक्का करके ऐसा करने की कोशिश करेंगे कि सुरक्षा की सीमा से बाहर निकलने वाला उपयोगकर्ता का डेटा, हर (उपयोगकर्ता, उपयोगकर्ता, model_instance) लेवल पर अलग-अलग निजी हो. कभी-कभी इस दस्तावेज़ में, उपयोगकर्ता-लेवल को छोटा करके उपयोगकर्ता-लेवल कहा जाता है.
असली उपयोगकर्ताओं के डिवाइसों से, उनके डेटा को बाहर भेजने से जुड़ा सारा कोड ओपन सोर्स होगा. साथ ही, बाहरी इकाइयां इसकी पुष्टि कर सकेंगी. अपने प्रस्ताव के शुरुआती चरणों में, हम ऐसे प्लैटफ़ॉर्म के लिए दिलचस्पी पैदा करना चाहते हैं जो डिवाइस पर उपयोगकर्ताओं के हिसाब से अनुभव देने की सुविधा देता है. साथ ही, हम इस प्लैटफ़ॉर्म के बारे में सुझाव, राय या शिकायत भी इकट्ठा करना चाहते हैं. हम निजता विशेषज्ञों, डेटा विश्लेषकों, और सुरक्षा विशेषज्ञों जैसे हिस्सेदारों को हमारे साथ जुड़ने का न्योता देते हैं.
Vision
डिवाइस पर उपयोगकर्ताओं को मनमुताबिक बनाने की सुविधा, ऐसे कारोबारों से असली उपयोगकर्ताओं की जानकारी को सुरक्षित रखने के लिए बनाई गई है जिनके साथ उन्होंने इंटरैक्ट नहीं किया है. कारोबार, असली उपयोगकर्ताओं के लिए अपने प्रॉडक्ट और सेवाओं को पसंद के मुताबिक बना सकते हैं (उदाहरण के लिए, पहचान छिपाने वाले और अलग-अलग निजी मशीन लर्निंग मॉडल का इस्तेमाल करके). हालांकि, वे असली उपयोगकर्ता के लिए किए गए पसंद के मुताबिक पसंद को नहीं देख पाएंगे. (यह न सिर्फ़ कारोबार के मालिक के जनरेट किए गए कस्टमाइज़ेशन नियम पर निर्भर करता है, बल्कि असली उपयोगकर्ता की पसंद पर भी निर्भर करता है). ऐसा तब तक नहीं होगा, जब तक कि कारोबार और असली उपयोगकर्ता के बीच सीधा इंटरैक्शन न हो. अगर कोई कारोबार कोई मशीन लर्निंग मॉडल या आंकड़ों का विश्लेषण करता है, तो ओडीपी यह पक्का करने की कोशिश करेगा कि उसकी पहचान करने के लिए, डिफ़रेंशियल प्राइवसी प्रोसेस का इस्तेमाल किया जाए.
हमारी मौजूदा योजना, ओडीपी के बारे में कई माइलस्टोन हासिल करना है. इसमें यहां दी गई सुविधाएं और फ़ंक्शन शामिल हैं. हम इस एक्सप्लोरेशन को आगे बढ़ाने के लिए, दिलचस्पी रखने वाले लोगों को, किसी भी अतिरिक्त सुविधा या वर्कफ़्लो के सुझाव देने का न्योता भी देते हैं:
- सैंडबॉक्स वाला ऐसा एनवायरमेंट जिसमें कारोबार का पूरा लॉजिक शामिल होता है और उसे लागू किया जाता है. इससे, आउटपुट को सीमित करते हुए, असली उपयोगकर्ता के कई सिग्नल को सैंडबॉक्स में डालने की अनुमति मिलती है.
पूरी तरह सुरक्षित (E2EE) डेटा स्टोर इनके लिए होता है:
- उपयोगकर्ता कंट्रोल और उपयोगकर्ता से जुड़ा अन्य डेटा. यह डेटा, उपयोगकर्ता से मिल सकता है या कारोबारों के इकट्ठा किए गए डेटा से अनुमान लगाया जा सकता है. साथ ही, इसमें डेटा के सेव रहने की समयसीमा (टीटीएल) कंट्रोल, मिटाने की नीतियां, निजता नीतियां वगैरह शामिल हो सकती हैं.
- कारोबार के कॉन्फ़िगरेशन. ओडीपी, इन डेटा को छिपाने या छिपाने के लिए एल्गोरिदम उपलब्ध कराता है.
- कारोबार की प्रोसेसिंग के नतीजे. ये नतीजे ऐसे हो सकते हैं:
- प्रोसेसिंग के बाद के राउंड में इनपुट के तौर पर लिया,
- डिफ़रेंशियल प्राइवसी मैकेनिज़्म के हिसाब से कोई जानकारी नहीं दी जाएगी और ज़रूरी शर्तें पूरी करने वाले एंडपॉइंट पर अपलोड की जाएगी.
- ट्रस्टेड एक्ज़ीक्यूशन एनवायरमेंट (टीईई) में, अपलोड करने के ट्रस्टेड फ़्लो का इस्तेमाल करके अपलोड किया गया हो. साथ ही, इसमें ओपन सोर्स वाले वर्कलोड चल रहे हों और डिफ़रेंशियल प्राइवसी के सही केंद्रीय तरीके इस्तेमाल किए जा रहे हों
- असली उपयोगकर्ताओं को दिखाया जाता है.
इन कामों के लिए डिज़ाइन किए गए एपीआई:
- 2(a), बैच या बढ़ते क्रम में अपडेट करें.
- 2(b) को समय-समय पर अपडेट करें. इसे एक साथ या धीरे-धीरे अपडेट किया जा सकता है.
- भरोसेमंद एग्रीगेशन एनवायरमेंट में, शोर कम करने के सही तरीकों के साथ 2(c) अपलोड करें. प्रोसेसिंग के अगले राउंड के लिए, ऐसे नतीजे 2(b) हो सकते हैं.
टाइमलाइन
यह, बीटा वर्शन में ओडीपी की टेस्टिंग के लिए मौजूदा प्लान है. टाइमलाइन में बदलाव किया जा सकता है.
| सुविधा | साल 2025 की पहली छमाही | 2025 की तीसरी तिमाही |
|---|---|---|
| डिवाइस पर ट्रेनिंग + अनुमान लगाना | इस समयावधि के दौरान पायलट कार्यक्रम के संभावित विकल्पों के बारे में बातचीत करने के लिए, प्राइवसी सैंडबॉक्स की टीम से संपर्क करें. | ज़रूरी शर्तें पूरी करने वाले Android T+ डिवाइसों पर रोल आउट करना शुरू करना. |
डिज़ाइन से जुड़े सिद्धांत
ओडीपी के तीन स्तंभ हैं: निजता, निष्पक्षता, और उपयोगिता.
निजता की बेहतर सुरक्षा के लिए टावर वाला डेटा मॉडल
ओडीपी डिज़ाइन के हिसाब से निजता का पालन करता है. इसे डिफ़ॉल्ट रूप से असली उपयोगकर्ता की निजता को ध्यान में रखकर डिज़ाइन किया गया है.
ओडीपी, उपयोगकर्ता के मनमुताबिक बनाने की प्रोसेस को असली उपयोगकर्ता के डिवाइस पर ले जाने की सुविधा देता है. इस तरीके से, ज़्यादा से ज़्यादा डेटा को डिवाइस पर सेव किया जाता है और ज़रूरत पड़ने पर ही उसे डिवाइस से बाहर प्रोसेस किया जाता है. इससे निजता और काम की सुविधाओं के बीच संतुलन बना रहता है. ODP इन पर फ़ोकस करती है:
- असली उपयोगकर्ता के डेटा को डिवाइस पर कंट्रोल करना. भले ही, वह डेटा डिवाइस से हट गया हो. डेस्टिनेशन को भरोसेमंद एक्ज़ीक्यूशन एनवायरमेंट के तौर पर प्रमाणित करना होगा. ये एनवायरमेंट उन सार्वजनिक क्लाउड कंपनियों से मिलते हैं जो ओडीपी वाले कोड का इस्तेमाल करते हैं.
- डिवाइस पर यह पुष्टि की जा सकती है कि असली उपयोगकर्ता के डेटा का क्या होता है, अगर वह डिवाइस से बाहर जाता है. ODP, अपना ऐप्लिकेशन इस्तेमाल करने वाले लोगों के लिए क्रॉस-डिवाइस मशीन लर्निंग और आंकड़ों का विश्लेषण करने के लिए, ओपन सोर्स और फ़ेडरेटेड कंप्यूट वर्कलोड उपलब्ध कराता है. असली उपयोगकर्ता का डिवाइस इस बात की पुष्टि करेगा कि ऐसे वर्कलोड, ट्रस्टेड एक्ज़ीक्यूशन एनवायरमेंट में बिना किसी बदलाव के चलाए गए हैं.
- डिवाइस से कंट्रोल किए जा सकने वाले/पुष्टि किए जा सकने वाले डेटा से बाहर निकलने वाले आउटपुट की तकनीकी निजता की गारंटी (उदाहरण के लिए, एग्रीगेशन, नॉइज़, डिफ़रेंशियल प्राइवसी).
इसलिए, आपके हिसाब से अनुभव देने की सुविधा, डिवाइस के हिसाब से होगी.
इसके अलावा, कारोबारों को निजता से जुड़े उपाय भी करने होते हैं. इन उपायों को प्लैटफ़ॉर्म को पूरा करना चाहिए. इसके लिए, कारोबार का रॉ डेटा उनके सर्वर में सेव किया जाता है. इसके लिए, ओडीपी इस डेटा मॉडल को अपनाता है:
- हर रॉ डेटा सोर्स को डिवाइस या सर्वर-साइड पर सेव किया जाएगा. इससे, लोकल लर्निंग और अनुमान लगाने की सुविधा चालू हो पाएगी.
- हम कई डेटा सोर्स के लिए, फ़ैसले लेने में मदद करने के लिए एल्गोरिदम उपलब्ध कराएंगे. जैसे, डेटा की दो अलग-अलग जगहों के बीच फ़िल्टर करना या अलग-अलग सोर्स के लिए ट्रेनिंग या अनुमान लगाना.
इस संदर्भ में, कारोबार टावर और असली उपयोगकर्ता टावर हो सकते हैं:
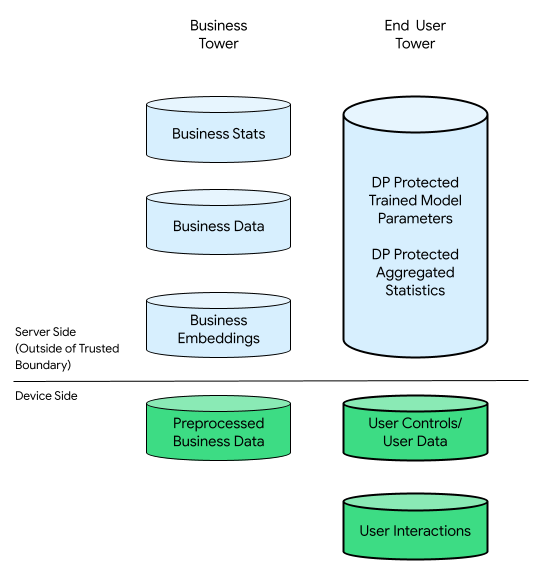
असली उपयोगकर्ता के टावर में असली उपयोगकर्ता से मिला डेटा (उदाहरण के लिए, खाते की जानकारी और कंट्रोल), असली उपयोगकर्ता के डिवाइस से उसके इंटरैक्शन से जुड़ा इकट्ठा किया गया डेटा, और कारोबार की ओर से अनुमान लगाया गया डेटा (उदाहरण के लिए, रुचियां और प्राथमिकताएं) शामिल होता है. अनुमानित डेटा, उपयोगकर्ता के सीधे तौर पर किए गए एलान को ओवरराइट नहीं करता.
तुलना के लिए, क्लाउड-आधारित इन्फ़्रास्ट्रक्चर में, असली उपयोगकर्ता के टावर का पूरा रॉ डेटा कारोबारों के सर्वर पर ट्रांसफ़र किया जाता है. वहीं, डिवाइस पर आधारित इन्फ़्रास्ट्रक्चर में, असली उपयोगकर्ता के टावर का पूरा रॉ डेटा अपने ऑरिजिन से ही रहता है. हालांकि, कारोबार का डेटा सर्वर पर सेव रहता है.
ऑन-डिवाइस पर उपयोगकर्ताओं को मनमुताबिक अनुभव देने की सुविधा, बेहतरीन और ओपन सोर्स कोड को चालू करके, दोनों तरह की बेहतरीन सुविधाओं का इस्तेमाल करती है. ऐसा करने के लिए, पुष्टि किए गए ओपन सोर्स कोड को ऐसे डेटा को प्रोसेस करना होता है जो ज़्यादा निजी आउटपुट चैनल इस्तेमाल करके, टीईई में शामिल असली उपयोगकर्ताओं से जुड़ा हो.
सभी के लिए समाधान ढूंढने के लिए, लोगों की ज़रूरतों को ध्यान में रखना
ओडीपी का मकसद, अलग-अलग तरह के पारिस्थितिक तंत्र में हिस्सा लेने वाले सभी लोगों के लिए एक संतुलित माहौल बनाना है. हम इस नेटवर्क की जटिलता को समझते हैं. इसमें अलग-अलग सेवाएं और प्रॉडक्ट देने वाले कई प्लेयर शामिल हैं.
इनोवेशन को बढ़ावा देने के लिए, ओडीपी ऐसे एपीआई ऑफ़र करता है जिन्हें डेवलपर और उनके प्रतिनिधि लागू कर सकते हैं. डिवाइस पर उपयोगकर्ताओं के हिसाब से कॉन्टेंट दिखाने की सुविधा, रिलीज़, मॉनिटरिंग, डेवलपर टूल, और सुझाव/राय देने वाले टूल को मैनेज करने के साथ-साथ, इन सुविधाओं को आसानी से इंटिग्रेट करने में मदद करती है. डिवाइस पर उपयोगकर्ता के मनमुताबिक अनुभव पाने की सुविधा, कारोबार के लिए कोई ठोस वजह नहीं बनाती है, बल्कि यह क्रिएटिविटी को बढ़ावा देने में मदद करती है.
समय के साथ, ODP में ज़्यादा एल्गोरिदम उपलब्ध हो सकते हैं. सुविधाओं का सही लेवल तय करने के लिए नेटवर्क के साथ मिलकर काम करना ज़रूरी है. साथ ही, इस प्रोग्राम में हिस्सा लेने वाले हर कारोबार के लिए डिवाइस के संसाधनों की सही सीमा तय करना भी ज़रूरी है. हम नेटवर्क से मिलने वाले सुझावों का अनुमान लगाते हैं. इससे हमें इस्तेमाल के नए उदाहरणों को पहचानने और उन्हें प्राथमिकता देने में मदद मिलती है.
बेहतर उपयोगकर्ता अनुभव के लिए डेवलपर के लिए सुविधाएं
ओडीपी पर इवेंट डेटा या निगरानी में देरी नहीं होती. इसकी वजह यह है कि सभी इवेंट, डिवाइस के लेवल पर ही रिकॉर्ड किए जाते हैं. मीटिंग में शामिल होने से जुड़ी कोई गड़बड़ी न हो और सभी इवेंट किसी एक डिवाइस से जुड़े हों. इस वजह से, निगरानी में रखे गए सभी इवेंट, समय के हिसाब से अपने-आप क्रम में बन जाते हैं. इनसे उपयोगकर्ता के इंटरैक्शन के बारे में पता चलता है.
यह आसान प्रोसेस, डेटा को जोड़ने या दोबारा व्यवस्थित करने की ज़रूरत को खत्म करती है. इससे उपयोगकर्ता के डेटा को करीब-करीब रीयल-टाइम में ऐक्सेस किया जा सकता है और उसके डेटा को ऐक्सेस किया जा सकता है. इससे, डेटा पर आधारित प्रॉडक्ट और सेवाओं का इस्तेमाल करते समय असली उपयोगकर्ताओं को मिलने वाली सुविधाएं और बेहतर हो सकती हैं. इससे उन्हें ज़्यादा बेहतर अनुभव मिलेगा. ओडीपी की मदद से, कारोबार अपने उपयोगकर्ताओं की ज़रूरतों के मुताबिक बेहतर तरीके से काम कर सकते हैं.
निजता मॉडल: गोपनीयता के ज़रिए गोपनीयता
नीचे दिए गए सेक्शन में, निजता के इस विश्लेषण के आधार के तौर पर, उपभोक्ता-उत्पादक मॉडल के बारे में बताया गया है. साथ ही, कंप्यूटेशन एनवायरमेंट की निजता बनाम आउटपुट की सटीक जानकारी के बारे में भी बताया गया है.
निजता से जुड़े इस विश्लेषण के आधार पर, उपभोक्ता-प्रोड्यूसर मॉडल
हम उपभोक्ता-उत्पादक मॉडल का इस्तेमाल करेंगे, ताकि गोपनीयता के ज़रिए निजता की सुरक्षा के भरोसे की जांच की जा सके. इस मॉडल में, कैलकुलेशन को डायरेक्टेड ऐसाइक्लिक ग्राफ़ (डीएजी) में नोड के तौर पर दिखाया जाता है. इसमें नोड और सबग्राफ़ होते हैं. हर कंप्यूटेशन नोड में तीन कॉम्पोनेंट होते हैं: इस्तेमाल किए गए इनपुट, आउटपुट, और आउटपुट के लिए कंप्यूटेशन मैपिंग इनपुट.

इस मॉडल में, निजता की सुरक्षा तीनों कॉम्पोनेंट पर लागू होती है:
- इनपुट की निजता. नोड में दो तरह के इनपुट हो सकते हैं. अगर कोई इनपुट, किसी पुराने नोड से जनरेट होता है, तो उसमें पहले से ही उस पुराने नोड के आउटपुट की निजता की गारंटी होती है. ऐसा न होने पर, इनपुट को नीति इंजन का इस्तेमाल करके, डेटा इनग्रेस की नीतियों को मंज़ूरी देनी होगी.
- आउटपुट की निजता. ऐसा हो सकता है कि आउटपुट का निजीकरण करना ज़रूरी हो, जैसे कि डिफ़रेंशियल प्राइवसी (डीपी) से मिला डेटा.
- कंप्यूटेशन एनवायरमेंट की गोपनीयता. कंप्यूटिंग, एक सुरक्षित सील एनवायरमेंट में होनी चाहिए, ताकि यह पक्का किया जा सके कि किसी नोड के अंदर किसी भी व्यक्ति के पास बीच के राज्यों का ऐक्सेस न हो. इस सुविधा को चालू करने वाली टेक्नोलॉजी में, फ़ेडरेटेड कंप्यूटेशन (एफ़सी), हार्डवेयर पर आधारित ट्रस्टेड एक्ज़ीक्यूशन एनवायरमेंट (टीईई), सुरक्षित मल्टी-पार्टी कंप्यूटेशन (एसएमपीसी), होमोमॉर्फ़िक एन्क्रिप्शन (एचपीई), और अन्य टेक्नोलॉजी शामिल हैं. इस बात का ध्यान रखना ज़रूरी है कि निजता की सुरक्षा के लिए, मध्यस्थ राज्यों को निजता की सुरक्षा मुहैया कराई जाती है.
साथ ही, निजता की सीमा का उल्लंघन करने वाले सभी आउटपुट के लिए, डिफ़रेंशियल प्राइवसी मैकेनिज़्म की मदद लेना ज़रूरी है. दो ज़रूरी दावे ये हैं:
- एनवायरमेंट की गोपनीयता, यह पक्का करना कि सिर्फ़ एलान किए गए आउटपुट ही एनवायरमेंट से बाहर जाएं और
- साउंडनेस, ताकि इनपुट निजता के दावों से आउटपुट में होने वाले निजता दावों की सटीक कटौती की जा सके. साउंडनेस की मदद से, डीएजी में निजता प्रॉपर्टी को डिफ़ॉल्ट रूप से लागू किया जा सकता है.
निजी सिस्टम, इनपुट की निजता, कैलकुलेशन एनवायरमेंट की गोपनीयता, और आउटपुट की निजता बनाए रखता है. हालांकि, गोपनीय कंप्यूटेशन वाले माहौल में ज़्यादा प्रोसेसिंग को सील करके, अलग-अलग निजता मशीनरी के ऐप्लिकेशन की संख्या कम की जा सकती है.
इस मॉडल के दो मुख्य फ़ायदे हैं. पहली बात, बड़े और छोटे ज़्यादातर सिस्टम को डीएजी के तौर पर दिखाया जा सकता है. दूसरा, डीपी के पोस्ट-प्रोसेसिंग [सेक्शन 2.1] और कॉम्पोज़िशन डीफ़रेंशियल प्राइवसी की जटिलता में लेम्मा 2.4 प्रॉपर्टी, पूरे ग्राफ़ के लिए निजता और सटीक जानकारी के बीच के (सबसे खराब स्थिति) समझौते का विश्लेषण करने के लिए ज़बरदस्त टूल देती हैं:
- डेटा को प्रोसेस करने के बाद, यह पक्का किया जाता है कि अगर मूल डेटा का फिर से इस्तेमाल नहीं किया जाता है, तो किसी डेटा को "निजी नहीं किया जा सकता". जब तक किसी नोड के लिए सभी इनपुट निजी होते हैं, तब तक उसका आउटपुट निजी होता है, चाहे वह नोड की कंप्यूटेशन से जुड़ी हो.
- बेहतर कंपोज़िशन इस बात की गारंटी देती है कि अगर हर ग्राफ़ का हिस्सा डीपी है, तो पूरा ग्राफ़ ग्राफ़ के फ़ाइनल आउटपुट के χ और $ को करीब कम्पोज़र के हिसाब से,
ये दोनों प्रॉपर्टी, हर नोड के लिए दो डिज़ाइन सिद्धांतों में बदल जाती हैं:
- प्रॉपर्टी 1 (प्रोसेसिंग के बाद से) अगर किसी नोड के इनपुट सभी डीपी हैं, तो उसका आउटपुट डीपी होता है. इसमें नोड में लागू किए गए आर्बिट्रेरी बिज़नेस लॉजिक को शामिल किया जाता है और कारोबारों के "सीक्रेट सॉस" का इस्तेमाल किया जाता है.
- प्रॉपर्टी 2 (ऐडवांस कॉम्पोज़िशन से): अगर किसी नोड के सभी इनपुट डीपी नहीं हैं, तो उसका आउटपुट डीपी के मुताबिक होना चाहिए. अगर कोई कंप्यूटेशन नोड, ट्रस्टेड एक्ज़ीक्यूशन एनवायरमेंट पर चलता है और वह डिवाइस पर उपयोगकर्ता के हिसाब से बनाए गए, ओपन सोर्स वाले वर्कलोड और कॉन्फ़िगरेशन को लागू करता है, तो डीपी के ज़्यादा सख्त सीमाएं लागू की जा सकती हैं. ऐसा न करने पर, डिवाइस पर दिलचस्पी के मुताबिक कॉन्टेंट दिखाने की सुविधा को, डीपी के सबसे खराब सीमाओं का इस्तेमाल करना पड़ सकता है. संसाधन की कमी की वजह से, Trusted एक्ज़ीक्यूशन के लिए, सार्वजनिक क्लाउड की सेवा देने वाली कंपनी के उपलब्ध कराए गए एनवायरमेंट को शुरुआत में प्राथमिकता दी जाएगी.
कंप्यूटेशन एनवायरमेंट प्राइवसी बनाम आउटपुट ऐक्यूरसी
इसके बाद से, डिवाइस पर उपयोगकर्ताओं को मनमुताबिक अनुभव देने की सुविधा, गोपनीय कंप्यूटेशन सिस्टम की सुरक्षा को बेहतर बनाने पर फ़ोकस करेगी. साथ ही, यह पक्का करने पर भी ध्यान दिया जाएगा कि इंटरमीडिएट स्टेट को ऐक्सेस न किया जा सके. इस सुरक्षा प्रक्रिया को सीलिंग कहा जाता है. इसे सबग्राफ़ लेवल पर लागू किया जाएगा. इससे कई नोड एक साथ डीपी का पालन कर सकेंगे. इसका मतलब है कि ऊपर बताई गई प्रॉपर्टी 1 और प्रॉपर्टी 2, सबग्राफ़ लेवल पर लागू होती हैं.

बेशक, फ़ाइनल ग्राफ़ आउटपुट, आउटपुट 7, हर कंपोज़िशन के लिए DP'ed होता है. इसका मतलब है कि इस ग्राफ़ के लिए कुल दो डीपी होंगी. अगर सीलिंग का इस्तेमाल नहीं किया गया है, तो कुल तीन (लोकल) डीपी जोड़ें.
इसके लिए, यह बेहद ज़रूरी है कि कंप्यूटेशन एनवायरमेंट को सुरक्षित करके और प्रतिस्पर्धियों को ग्राफ़ या सबग्राफ़ के इनपुट और इंटरमीडिएट स्टेट को ऐक्सेस करने के मौके खत्म करके, सेंट्रल डीपी लागू किया जा सके. इसका मतलब है कि सील्ड एनवायरमेंट का आउटपुट डीपी, लोकल डीपी की तुलना में सटीक नतीजे दे सकता है. यह सिद्धांत, एफ़सी, टीईई, एसएमपीसी, और एचपीई को निजता टेक्नोलॉजी के तौर पर शामिल करने पर निर्भर करता है. डिफ़रेंशियल प्राइवसी की जटिलता में, दसवां अध्याय देखें.
मॉडल की ट्रेनिंग और अनुमान लगाने का उदाहरण एक अच्छा और व्यावहारिक उदाहरण है. यहां दी गई चर्चाओं में यह माना गया है कि (1) ट्रेनिंग पॉप्युलेशन और अनुमान लगाने के लिए इस्तेमाल की जाने वाली पॉप्युलेशन ओवरलैप होती है और (2) सुविधाओं और लेबल, दोनों में उपयोगकर्ता का निजी डेटा शामिल होता है. हम सभी इनपुट पर डीपी का इस्तेमाल कर सकते हैं:

डिवाइस पर उपयोगकर्ता के हिसाब से कॉन्टेंट दिखाने की सुविधा, उपयोगकर्ता लेबल और सुविधाओं को सर्वर पर भेजने से पहले, उन पर लोकल डीपी लागू कर सकती है. इस तरीके से, सर्वर के एक्सीक्यूशन एनवायरमेंट या उसके कारोबारी लॉजिक पर कोई ज़रूरी शर्त नहीं लागू होती.



यह मौजूदा, डिवाइस पर मनमुताबिक बनाने का डिज़ाइन है.
निजी होने की पुष्टि की जा सकती है
डिवाइस को मनमुताबिक बनाने की सुविधा का मकसद, उपयोगकर्ता की निजता को सुरक्षित रखना है. इससे, इस बात की पुष्टि करने पर ध्यान दिया जाता है कि उपयोगकर्ता के डिवाइस पर क्या होता है. ओडीपी, उस कोड को बनाएगा जो असली उपयोगकर्ताओं के डिवाइस से डेटा को प्रोसेस करता है. साथ ही, वह एनआईएसटी की आरएफ़सी 9334 रिमोट अटेस्टेशन प्रोसेस (आरएटीएस) आर्किटेक्चर का इस्तेमाल करके यह पुष्टि करेगा कि इस कोड में, कॉन्फ़िडेंशियल कंप्यूटिंग कंसोर्टियम के मुताबिक, बिना खास अधिकार वाले सर्वर को चलाए जाने की प्रोसेस में कोई बदलाव नहीं किया गया है. ये कोड ओपन सोर्स होंगे और इन्हें ऐक्सेस किया जा सकेगा, ताकि भरोसा बढ़ाने के लिए साफ़ तौर पर पुष्टि की जा सके. ऐसे तरीकों से लोगों में यह भरोसा पैदा होता है कि उनका डेटा सुरक्षित है. साथ ही, कारोबार, निजता की सुरक्षा के लिए मज़बूत बुनियाद के आधार पर भरोसा कर सकते हैं.
इकट्ठा और सेव किए जाने वाले निजी डेटा की मात्रा को कम करना, डिवाइस को मनमुताबिक बनाने का एक और अहम पहलू है. इस सिद्धांत का पालन करने के लिए, फ़ेडरेटेड कंप्यूट और डिफ़रेंशियल प्राइवसी जैसी टेक्नोलॉजी का इस्तेमाल किया जाता है. साथ ही, किसी व्यक्ति की संवेदनशील जानकारी या पहचान ज़ाहिर करने वाली जानकारी को सार्वजनिक किए बिना, उसके अहम डेटा पैटर्न को सार्वजनिक किया जाता है.
निजता की पुष्टि करने का एक और अहम पहलू, ऑडिट ट्रेल को बनाए रखना है. इससे डेटा प्रोसेस करने और शेयर करने से जुड़ी गतिविधियों को लॉग किया जाता है. इससे ऑडिट रिपोर्ट बनाने और जोखिम की आशंकाओं की पहचान करने में मदद मिलती है. साथ ही, यह पता चलता है कि निजता को लेकर हमारी प्रतिबद्धताएं हैं.
हम निजता के विशेषज्ञों, संस्थाओं, उद्योगों, और लोगों से मिलकर काम करने की मांग करते हैं. इससे हमें अपने ऐप्लिकेशन के डिज़ाइन और उसे लागू करने के तरीके को लगातार बेहतर बनाने में मदद मिलती है.
नीचे दिया गया ग्राफ़, हर डिफ़रेंशियल प्राइवसी के हिसाब से क्रॉस-डिवाइस एग्रीगेशन और नॉइज़िंग का कोड पाथ दिखाता है.
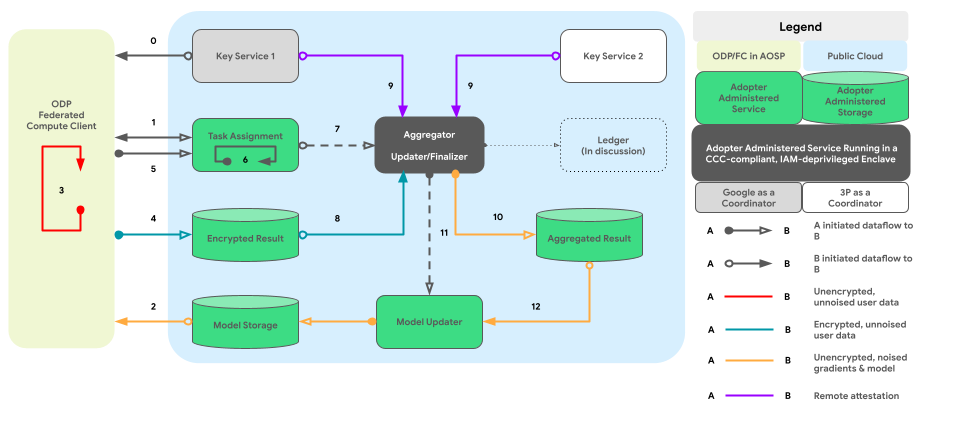
बेहतरीन डिज़ाइन
गोपनीयता के ज़रिए निजता को कैसे लागू किया जा सकता है? हाई लेवल पर, ओडीपी से लिखा गया पॉलिसी इंजन, सील एनवायरमेंट में चलता है. यह हर नोड/सबग्राफ़ की निगरानी करने के लिए कोर कॉम्पोनेंट के तौर पर काम करता है. साथ ही, यह उनके इनपुट और आउटपुट के डीपी स्टेटस को ट्रैक करता है:
- नीति इंजन के हिसाब से, डिवाइसों और सर्वर को एक जैसा माना जाता है. एक जैसे पॉलिसी इंजन का इस्तेमाल करने वाले डिवाइसों और सर्वर को लॉजिकल रूप से एक जैसा माना जाता है. हालांकि, ऐसा तब ही माना जाता है, जब नीति वाले इंजन की अलग-अलग पुष्टि कर दी गई हो.
- डिवाइसों पर, एओएसपी आइसोलेटेड प्रोसेस से आइसोलेशन किया जाता है. इसके अलावा, उपलब्धता ज़्यादा होने पर लंबे समय तक pKVM का इस्तेमाल करके आइसोलेशन किया जाता है. सर्वर पर, डेटा को अलग रखने की सुविधा, "भरोसेमंद पक्ष" पर निर्भर करती है. यह पक्ष, टीईई के साथ-साथ, डेटा को सुरक्षित रखने के लिए उपलब्ध अन्य तकनीकी समाधानों में से किसी एक या दोनों का इस्तेमाल करता है.
दूसरे शब्दों में, प्लैटफ़ॉर्म नीति इंजन को इंस्टॉल और चलाने वाले सभी सील किए गए एनवायरमेंट को, हमारे भरोसेमंद कंप्यूटिंग बेस (टीसीबी) का हिस्सा माना जाता है. टीसीबी की मदद से, डेटा को बिना किसी अतिरिक्त शोर के प्रोपेगेट किया जा सकता है. जब डेटा, टीसीबी से बाहर जाता है, तो डीपी लागू करना ज़रूरी होता है.
ऑन-डिवाइस पर उपयोगकर्ताओं के हिसाब से कॉन्टेंट दिखाने की सुविधा के बेहतर डिज़ाइन में, ये दो ज़रूरी एलिमेंट बेहतर तरीके से इंटिग्रेट किए गए हैं:
- कारोबारी नियमों को लागू करने के लिए, पेयर की गई प्रोसेस का आर्किटेक्चर
- डेटा इन्ग्रेस डेटा ट्रैफ़िक, इग्रेस डेटा ट्रैफ़िक, और अनुमति वाली कार्रवाइयों को मैनेज करने के लिए नीतियां और पॉलिसी इंजन.
इस बेहतर डिज़ाइन की मदद से, कारोबारों को एक ऐसा प्लैटफ़ॉर्म मिलता है जहां वे अपने मालिकाना कोड को ट्रस्टेड एक्ज़ीक्यूशन एनवायरमेंट में चला सकते हैं. साथ ही, नीति से जुड़ी ज़रूरी शर्तें पूरी करने वाले उपयोगकर्ता के डेटा को ऐक्सेस कर सकते हैं.
नीचे दिए गए सेक्शन में, इन दो अहम पहलुओं के बारे में ज़्यादा जानकारी दी गई है.
बिज़नेस लॉजिक को लागू करने के लिए पेयर-प्रोसेस आर्किटेक्चर
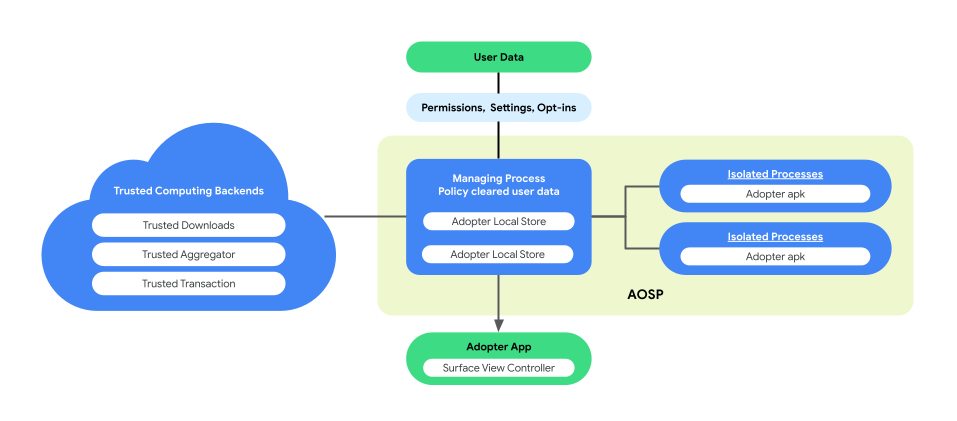
डिवाइस पर उपयोगकर्ता के हिसाब से कॉन्टेंट दिखाने की सुविधा, AOSP में पेयर की गई प्रोसेस के आर्किटेक्चर को शामिल करती है. इससे, कारोबार के लॉजिक को लागू करने के दौरान, उपयोगकर्ता की निजता और डेटा की सुरक्षा को बेहतर बनाया जा सकता है. इस आर्किटेक्चर में ये शामिल हैं:
प्रोसेस मैनेज करना. यह प्रोसेस, Isolatedप्रोसेस को बनाती है और मैनेज करती है. यह पक्का करती है कि वे प्रोसेस-लेवल पर अलग-अलग रहें और ऐक्सेस सिर्फ़ अनुमति वाली सूची में शामिल एपीआई तक सीमित रहे और नेटवर्क या डिस्क की अनुमतियां न हों. मैनेज करने की प्रोसेस, कारोबार के पूरे डेटा को इकट्ठा करने का काम करती है. साथ ही, असली उपयोगकर्ता का सारा डेटा, और नीति उन्हें कारोबार कोड के लिए साफ़ करती है. इससे उन्हें प्रोसेस की प्रोसेस को पूरा करने के लिए, IsolatedProcesses में भेज दिया जाता है. इसके अलावा, यह अलग-अलग प्रोसेस और दूसरी प्रोसेस, जैसे कि System_server के बीच होने वाले इंटरैक्शन को मीडिएशन करता है.
आइसोलेटेडप्रोसेस. इस प्रोसेस को आइसोलेटेड (
isolatedprocess=trueमेनिफ़ेस्ट में बताया गया है) के तौर पर सेट किया गया है. इस प्रोसेस को मैनेज करने की प्रोसेस से कारोबार का डेटा, असली उपयोगकर्ता का डेटा, और नीति की ओर से साफ़ तौर पर बताया गया डेटा मिलता है. साथ ही, इस प्रोसेस को कारोबार कोड भी मिलता है. इनकी मदद से, कारोबार कोड को उसके डेटा और नीति के हिसाब से तय किए गए असली उपयोगकर्ता के डेटा पर काम करने की अनुमति मिलती है. आइसोलेटेड प्रोसेस, इन्ग्रेस डेटा ट्रैफ़िक और इग्रेस डेटा ट्रैफ़िक को मैनेज करने की प्रोसेस से खास तौर पर जानकारी शेयर करती है. इसके लिए, कोई अतिरिक्त अनुमति नहीं दी जाती है.
पेयर की गई प्रोसेस के आर्किटेक्चर की मदद से, असली उपयोगकर्ता के डेटा की निजता से जुड़ी नीतियों की स्वतंत्र पुष्टि की जा सकती है. इसके लिए, कारोबारों को अपने कारोबार के लॉजिक या कोड को ओपन-सोर्स करने की ज़रूरत नहीं होती. Isolatedप्रोसेस को मैनेज करने की प्रोसेस और अलग-अलग कारोबारी लॉजिक का बेहतर तरीके से इस्तेमाल करके, Isolatedप्रोसेस को कैसे मैनेज करता है. इससे, लोगों की दिलचस्पी के मुताबिक विज्ञापन दिखाने के दौरान, उपयोगकर्ता की निजता को बनाए रखने के लिए, ज़्यादा सुरक्षित और बेहतर समाधान मिलता है.
नीचे दिए गए डायग्राम में, पेयर किए गए प्रोसेस आर्किटेक्चर को दिखाया गया है.
डेटा ऑपरेशन के लिए नीतियां और नीति इंजन
डिवाइस पर उपयोगकर्ताओं को मनमुताबिक अनुभव देने की सुविधा की मदद से, प्लैटफ़ॉर्म और कारोबार के लॉजिक के बीच नीति को लागू करने से जुड़ी एक लेयर बनाई जा सकती है. इसका मकसद ऐसे टूल का सेट देना है जो असली उपयोगकर्ता और कारोबार के कंट्रोल को एक ही जगह पर और कार्रवाई करने लायक नीति फ़ैसलों में मैप करते हैं. इसके बाद, इन नीतियों को सभी फ़्लो और कारोबारों पर पूरी तरह से और भरोसेमंद तरीके से लागू किया जाता है.
पेयर किए गए प्रोसेस आर्किटेक्चर में, पॉलिसी इंजन, मैनेज करने की प्रोसेस में होता है. यह असली उपयोगकर्ता और कारोबार के डेटा के इन्ग्रेस डेटा ट्रैफ़िक और इग्रेस डेटा ट्रैफ़िक पर नज़र रखता है. यह, अनुमति वाली सूची में शामिल ऑपरेशन को IsolatedProcess को भी भेजेगा. कवरेज के कुछ उदाहरणों में, उपयोगकर्ता के कंट्रोल का सम्मान करना, बच्चों की सुरक्षा, बिना सहमति के डेटा शेयर होने से रोकना, और कारोबार की निजता शामिल है.
इस नीति को लागू करने के इस तरीके में तीन तरह के वर्कफ़्लो शामिल हैं. इनका इस्तेमाल किया जा सकता है:
- ट्रस्टेड एक्ज़ीक्यूशन एनवायरमेंट (टीईई) कम्यूनिकेशन के साथ, स्थानीय तौर पर शुरू किए गए ऑफ़लाइन वर्कफ़्लो:
- डेटा डाउनलोड करने का फ़्लो: भरोसेमंद डाउनलोड
- डेटा अपलोड करने के फ़्लो: भरोसेमंद लेन-देन
- स्थानीय तौर पर शुरू किए गए, ऑनलाइन वर्कफ़्लो:
- रीयल-टाइम में विज्ञापन दिखाने के फ़्लो
- अनुमान फ़्लो
- स्थानीय तौर पर शुरू किए गए, ऑफ़लाइन वर्कफ़्लो:
- ऑप्टिमाइज़ेशन फ़्लो: उपयोगकर्ता के डिवाइस पर मॉडल को ट्रेनिंग देने की सुविधा, फ़ेडरेटेड लर्निंग (FL) की मदद से लागू की गई
- रिपोर्टिंग फ़्लो: फ़ेडरेटेड Analytics (FA) के ज़रिए लागू किया गया क्रॉस-डिवाइस एग्रीगेशन
नीचे दी गई इमेज में, नीतियों और नीति इंजन के हिसाब से आर्किटेक्चर दिखाया गया है.
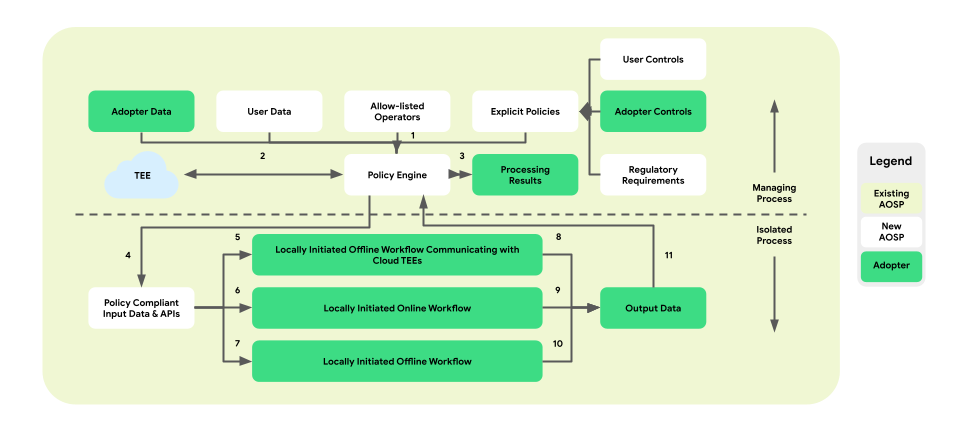
- डाउनलोड करें: 1 -> 2 -> 4 -> 7 -> 10 -> 11 -> 3
- दिखाया जा रहा है: 1 + 3 -> 4 -> 6 -> 9 -> 11 -> 3
- ऑप्टिमाइज़ेशन: 2 (ट्रेनिंग प्लान उपलब्ध कराता है) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
- रिपोर्टिंग: 3 (एग्रीगेशन प्लान उपलब्ध कराता है) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
कुल मिलाकर, डिवाइस को मनमुताबिक बनाने की सुविधा के पेयर-प्रोसेस आर्किटेक्चर में, नीति के उल्लंघन को ठीक करने के तरीके (एनफ़ोर्समेंट) से जुड़ी लेयर और नीति इंजन की सुविधा आने से, यह पक्का किया जाता है कि कारोबार के लॉजिक के हिसाब से काम करने के लिए, निजता की सुरक्षा वाला एक अलग माहौल मिले. साथ ही, यह ज़रूरी डेटा और कार्रवाइयों का कंट्रोल भी देता है.
लेयर वाले एपीआई प्लैटफ़ॉर्म
उपयोगकर्ता के डिवाइस पर मनमुताबिक अनुभव पाने की सुविधा की मदद से, दिलचस्पी रखने वाले कारोबारों को कई लेयर वाले एपीआई आर्किटेक्चर मिलते हैं. सबसे ऊपर की लेयर में, खास तरह के इस्तेमाल के लिए बनाए गए ऐप्लिकेशन शामिल होते हैं. संभावित कारोबार अपने डेटा को इन ऐप्लिकेशन से कनेक्ट कर सकते हैं. इन्हें टॉप-लेयर एपीआई कहा जाता है. टॉप-लेयर एपीआई, मिड-लेयर एपीआई पर बनाए जाते हैं.
आने वाले समय में, हम और भी टॉप-लेयर एपीआई जोड़ेंगे. अगर किसी टॉप-लेयर एपीआई का इस्तेमाल किसी खास काम के लिए नहीं किया जा सकता या मौजूदा टॉप-लेयर एपीआई में ज़रूरत के मुताबिक बदलाव नहीं किए जा सकते, तो कारोबारों को सीधे तौर पर मिड-लेयर एपीआई लागू करने की सुविधा मिलती है. इससे, प्रोग्रामिंग प्रिमिटिव के ज़रिए ताकत और ज़रूरत के हिसाब से सुविधाएं मिलती हैं.
नतीजा
डिवाइस पर उपयोगकर्ताओं के हिसाब से कॉन्टेंट दिखाने की सुविधा, रिसर्च के शुरुआती चरण में है. इसका मकसद, लंबे समय तक काम करने वाले ऐसे समाधान के लिए दिलचस्पी और सुझाव, शिकायत या राय पाना है जो असली उपयोगकर्ता की निजता से जुड़ी चिंताओं को हल करता हो. इसके लिए, नई और बेहतर टेक्नोलॉजी का इस्तेमाल किया जाएगा.
हम निजता विशेषज्ञों, डेटा विश्लेषकों, और संभावित असली उपयोगकर्ताओं जैसे हिस्सेदारों के साथ काम करना चाहते हैं. इससे हमें यह पक्का करने में मदद मिलेगी कि ओडीपी उनकी ज़रूरतों को पूरा करता है और उनकी समस्याओं को हल करता है.