Per essere implementata nell'Android Open Source Project (AOSP), questa spiegazione tecnica illustra i motivi alla base della personalizzazione on-device (ODP), i principi di progettazione che ne guidano lo sviluppo, la privacy attraverso un modello di riservatezza e il modo in cui contribuisce a garantire un'esperienza privata verificabile.
Prevediamo di raggiungere questo obiettivo semplificando il modello di accesso ai dati e assicurandoci che tutti i dati utente che escono dal confine di sicurezza siano con privacy differenziale a livello di (user, adopter, model_instance) (a volte abbreviato in a livello di utente in questo documento).
Tutto il codice relativo al potenziale traffico in uscita dei dati degli utenti finali dai dispositivi degli utenti finali sarà open source e verificabile da entità esterne. Nelle prime fasi della nostra proposta, cerchiamo di generare interesse e raccogliere feedback per una piattaforma che offra opportunità di personalizzazione sul dispositivo. Invitiamo stakeholder come esperti di privacy, analisti di dati e professionisti della sicurezza a interagire con noi.
Vision
La personalizzazione sul dispositivo è progettata per proteggere le informazioni degli utenti finali dalle attività con cui non hanno interagito. Le attività possono continuare a personalizzare i propri prodotti e servizi per gli utenti finali (ad esempio utilizzando modelli di machine learning adeguatamente anonimizzati e privati in modo differenziato), ma non saranno in grado di vedere le personalizzazioni esatte apportate per un utente finale (che dipende non solo dalla regola di personalizzazione generata dal proprietario dell'attività, ma anche dalla preferenza del singolo utente finale), a meno che non vi siano interazioni dirette tra l'attività e l'utente finale. Se un'attività produce modelli di machine learning o analisi statistiche, ODP cercherà di garantire che vengano anonimizzati correttamente utilizzando i meccanismi di privacy differenziale appropriati.
Il nostro piano attuale prevede di esplorare la strategia ODP in più traguardi, coprendo le caratteristiche e le funzionalità seguenti. Invitiamo inoltre le parti interessate a suggerire in modo costruttivo eventuali funzionalità o flussi di lavoro aggiuntivi per approfondire questa esplorazione:
- Un ambiente con sandbox in cui tutta la logica di business viene contenuta ed eseguita, consentendo a una moltitudine di indicatori dell'utente finale di accedere alla sandbox limitando gli output.
Datastore con crittografia end-to-end per:
- Controlli utente e altri dati correlati agli utenti. Potrebbero essere forniti dall'utente finale o raccolti e dedotti dalle attività, insieme a controlli TTL (time to live), criteri di eliminazione, norme sulla privacy e altro ancora.
- Configurazioni aziendali. ODP fornisce algoritmi per comprimere o offuscare questi dati.
- Risultati dell'elaborazione dell'attività. Questi risultati possono essere:
- Utilizzati come input nei cicli di elaborazione successivi,
- Rumore in base ai meccanismi di privacy differenziale adeguati e caricato su endpoint idonei.
- Caricato utilizzando il flusso di caricamento attendibile in Trusted Execution Environments (TEE) che esegue carichi di lavoro open source con appropriati meccanismi centrali di privacy differenziale
- Mostrato agli utenti finali.
API progettate per:
- Aggiornamento 2(a), in batch o in modo incrementale.
- Aggiorna 2(b) periodicamente, in batch o in modo incrementale.
- Carica 2(c), con meccanismi di rumore adeguati in ambienti di aggregazione attendibili. Questi risultati potrebbero diventare 2(b) per i prossimi round di elaborazione.
Cronologia
Questo è il piano attuale registrato per i test di ODP in versione beta. Le tempistiche sono soggette a variazioni.
| Funzionalità | 1° semestre 2025 | T3 2025 |
|---|---|---|
| Addestramento e inferenza on-device | Contatta il team di Privacy Sandbox per discutere delle potenziali opzioni da testare durante questo periodo di tempo. | Inizia a implementarla sui dispositivi Android T+ idonei. |
Design principles
L'ODP si basa su tre pilastri: privacy, equità e utilità.
Modello di dati a torre per una maggiore protezione della privacy
ODP segue il principio di privacy by design ed è progettato per proteggere la privacy degli utenti finali per impostazione predefinita.
ODP esplora il trasferimento dell'elaborazione della personalizzazione sul dispositivo di un utente finale. Questo approccio bilancia privacy e utilità mantenendo il più possibile i dati sul dispositivo ed elaborandoli al di fuori del dispositivo solo quando necessario. ODP si concentra su:
- Controllare i dati degli utenti finali da parte dei dispositivi, anche quando lasciano il dispositivo. Le destinazioni devono essere ambienti di esecuzione attendibili attestati offerti da fornitori di cloud pubblico che eseguono codice creato da ODP.
- Verificabilità del dispositivo di ciò che accade ai dati dell'utente finale se questi lasciano il dispositivo. ODP fornisce carichi di lavoro open source Federated Compute per coordinare il machine learning cross-device e l'analisi statistica per i suoi utenti. Il dispositivo di un utente finale attesta che questi carichi di lavoro vengono eseguiti in ambienti di esecuzione attendibili non modificati.
- Privacy tecnica garantita (ad es. aggregazione, rumore, privacy differenziale) per gli output che superano il confine controllato/verificabile dal dispositivo.
Di conseguenza, la personalizzazione sarà specifica per il dispositivo.
Inoltre, le attività richiedono anche misure sulla privacy, che la piattaforma deve risolvere. Ciò comporta la gestione dei dati aziendali non elaborati nei rispettivi server. A questo scopo, ODP adotta il seguente modello di dati:
- Ogni origine dati non elaborata verrà archiviata sul dispositivo o sul lato server, consentendo l'apprendimento e l'inferenza locale.
- Forniremo algoritmi per facilitare il processo decisionale in più origini dati, ad esempio il filtraggio tra due posizioni di dati diverse o l'addestramento o l'inferenza in varie origini.
In questo contesto, potrebbero essere presenti una torre aziendale e una torre di utenti finali:
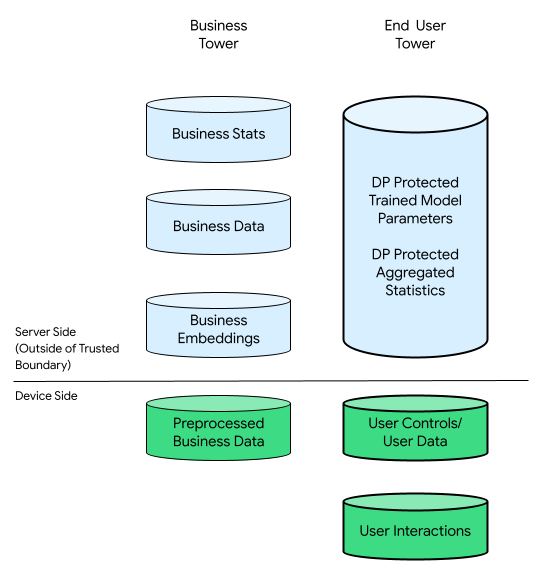
La torre degli utenti finali è costituita dai dati forniti dall'utente finale (ad esempio, informazioni e controlli dell'account), dai dati raccolti relativi alle interazioni di un utente finale con il proprio dispositivo e dai dati derivati (ad esempio, interessi e preferenze) dedotti dall'attività. I dati dedotti non sovrascrivono le dichiarazioni dirette dell'utente.
Per fare un confronto, in un'infrastruttura incentrata sul cloud, tutti i dati non elaborati della torre di utenti finali vengono trasferiti ai server delle aziende. Viceversa, in un'infrastruttura incentrata sui dispositivi, tutti i dati non elaborati provenienti dalla torre dell'utente finale rimangono nella loro origine, mentre i dati aziendali rimangono archiviati sui server.
La personalizzazione sul dispositivo combina il meglio di entrambi i mondi consentendo solo al codice open source verificato di elaborare i dati che potrebbero essere correlati agli utenti finali nei TEE utilizzando canali di output più privati.
Coinvolgimento pubblico inclusivo per soluzioni eque
La piattaforma ODP mira a garantire un ambiente equilibrato per tutti i partecipanti all'interno di un ecosistema diversificato. Riconosciamo la complessità di questo ecosistema, composto da vari attori che offrono servizi e prodotti distinti.
Per stimolare l'innovazione, ODP offre API che possono essere implementate dagli sviluppatori e dalle aziende che rappresentano. La personalizzazione sul dispositivo semplifica l'integrazione di queste implementazioni, nonché la gestione di release, monitoraggio, strumenti per sviluppatori e strumenti di feedback. La personalizzazione sul dispositivo non crea una logica di business concreta, ma funge da catalizzatore per la creatività.
La modalità ODP potrebbe offrire più algoritmi con il passare del tempo. La collaborazione con l'ecosistema è essenziale per determinare il livello giusto di funzionalità e potenzialmente stabilire un limite ragionevole di risorse del dispositivo per ogni attività partecipante. Prevediamo di ricevere feedback dall'ecosistema per aiutarci a riconoscere e dare la priorità ai nuovi casi d'uso.
Utilità per sviluppatori per esperienze utente migliorate
Con ODP non c'è nessuna perdita di dati sugli eventi o ritardi nell'osservazione, poiché tutti gli eventi vengono registrati localmente a livello di dispositivo. Non ci sono errori di unione e tutti gli eventi sono associati a un dispositivo specifico. Di conseguenza, tutti gli eventi osservati formano naturalmente una sequenza cronologica che riflette le interazioni dell'utente.
Questa procedura semplificata elimina la necessità di unire o riorganizzare i dati, consentendo l'accesso ai dati utente quasi in tempo reale e senza perdita di dati. A sua volta, ciò può migliorare l'utilità percepita dagli utenti finali quando interagiscono con prodotti e servizi basati sui dati, portando potenzialmente a livelli di soddisfazione più elevati ed esperienze più significative. Con l'ODP, le attività possono adattarsi efficacemente alle esigenze dei propri utenti.
Il modello di privacy: privacy via riservatezza
Le sezioni seguenti illustrano il modello consumer-producer come base di questa analisi della privacy e la privacy dell'ambiente di calcolo rispetto all'accuratezza dell'output.
Modello consumatore-produttore come base di questa analisi della privacy
Utilizzeremo il modello consumatore-produttore per esaminare le garanzie della privacy tramite la riservatezza. I calcoli in questo modello sono rappresentati come nodi all'interno di un grafo diretto aciclico (DAG) costituito da nodi e sottografi. Ogni nodo di calcolo ha tre componenti: input consumati, output prodotti e input di mappatura degli output.

In questo modello, la protezione della privacy si applica a tutti e tre i componenti:
- Privacy dei dati inseriti. I nodi possono avere due tipi di input. Se un input viene generato da un nodo precedente, dispone già delle garanzie di privacy in uscita del nodo precedente. In caso contrario, gli input devono rispettare le norme sull'ingresso dei dati utilizzando il motore delle norme.
- Privacy dell'output. L'output potrebbe dover essere privatizzato, ad esempio quello fornito dalla privacy differenziale (DP).
- Riservatezza dell'ambiente di calcolo. Il calcolo deve avvenire in un ambiente chiuso in modo sicuro, garantendo che nessuno abbia accesso agli stati intermedi all'interno di un nodo. Le tecnologie che consentono questa funzionalità includono
Federated Computation (FC), Trusted Execution Environments
(TEE), secure Multi-Party Computation (sMPC), crittografia omomorfica (HPE)
e altro ancora. Vale la pena notare che la privacy attraverso misure di salvaguardia della riservatezza
degli stati intermediari e tutti gli output in uscita dal confine di riservatezza
devono comunque essere protetti dai meccanismi della privacy differenziale. Due claim obbligatori sono:
- La riservatezza degli ambienti, che garantisce che solo le uscite dichiarate lascino l'ambiente e
- Solidità, che consente deduzioni accurate delle rivendicazioni della privacy in uscita dalle rivendicazioni della privacy in entrata. La solidità consente la propagazione della proprietà della privacy in un DAG.
Un sistema privato garantisce la privacy degli input, la riservatezza dell'ambiente di calcolo e la privacy delle uscite. Tuttavia, il numero di applicazioni dei meccanismi di privacy differenziale può essere ridotto sigillando più elaborazioni all'interno di un ambiente di calcolo riservato.
Questo modello offre due vantaggi principali. Innanzitutto, la maggior parte dei sistemi, grandi e piccoli, puoi essere rappresentata come un DAG. In secondo luogo, le proprietà Post-processing [Sezione 2.1] e composizione Lemma 2.4 della pagina La complessità della privacy differenziale di DP forniscono strumenti potenti per analizzare il compromesso in termini di privacy e accuratezza (nel peggiore dei casi) relativo a un intero grafico:
- La fase di post-elaborazione garantisce che, una volta privatizzata una quantità, questa non potrà essere "privata", se i dati originali non verranno riutilizzati. Finché tutti gli input per un nodo sono privati, il suo output è privato, indipendentemente dai suoi calcoli.
- La composizione avanzata garantisce che, se ogni parte del grafico è in formato DP, lo stesso vale per il grafico complessivo, che delimita di fatto l'output finale di un grafico ( autonomo) e ∆ (approssimativamente, se si considera che un grafico ha unità μ) e l'output di ogni unità è (Π, μ)-DP.
Queste due proprietà si traducono in due principi di progettazione per ciascun nodo:
- Proprietà 1 (da post-elaborazione) se gli input di un nodo sono tutti DP, il suo output è un DP, in grado di gestire qualsiasi logica di business arbitraria eseguita nel nodo e supportare i "condimenti segreti" delle aziende.
- Proprietà 2 (da composizione avanzata) se gli input di un nodo non sono tutti DP, il suo output deve essere reso conforme a DP. Se un nodo di calcolo è uno in esecuzione in Trusted Execution Environments ed esegue configurazioni e carichi di lavoro open source forniti dalla personalizzazione sul dispositivo, sono possibili limiti DP più stretti. In caso contrario, la personalizzazione sul dispositivo potrebbe dover utilizzare limiti DP peggiori. A causa delle limitazioni delle risorse, inizialmente verrà data la priorità agli ambienti di esecuzione attendibile offerti da un provider cloud pubblico.
Privacy dell'ambiente di calcolo rispetto all'accuratezza dell'output
D'ora in poi, la personalizzazione sul dispositivo si concentrerà sul miglioramento della sicurezza degli ambienti di calcolo riservati e sul garantire che gli stati intermedi restino inaccessibili. Questo processo di sicurezza, noto come sealing, verrà applicato a livello di sottografo, consentendo di rendere conformi DP a più nodi insieme. Ciò significa che la proprietà 1 e la proprietà 2 menzionate in precedenza si applicano a livello di sottografo.

Ovviamente l'output finale del grafico, l'output 7, viene calcolato in base alla composizione. Ciò significa che per questo grafico ci saranno 2 DP in totale, rispetto ai 3 DP totali (locali) se non è stato utilizzato il sigillamento.
In sostanza, garantendo la sicurezza dell'ambiente di calcolo ed eliminando le opportunità per gli avversari di accedere agli input e agli stati intermedi di un grafo o di un sottografo, è possibile implementare il DP centrale (ovvero l'output di un ambiente sigillato è conforme al DP), che può migliorare l'accuratezza rispetto al DP locale (ovvero i singoli input sono conformi al DP). Questo principio è alla base della considerazione di FC, TEE, sMPC e HPE come tecnologie per la privacy. Consulta il capitolo 10 di The Complexity of Differential Privacy.
Un buon esempio pratico sono l'addestramento e l'inferenza del modello. Le discussioni seguenti presuppongono che (1), la popolazione dell'addestramento e la popolazione di inferenza si sovrappongano e (2), sia le caratteristiche che le etichette costituiscono dati utente privati. Possiamo applicare la crittografia lato client a tutti gli input:

La personalizzazione sul dispositivo può applicare il DP locale alle etichette e alle funzionalità utente prima di inviarle ai server. Questo approccio non impone alcun requisito all'ambiente di esecuzione del server o alla relativa logica di business.



Questo è l'attuale design della personalizzazione sul dispositivo.
Verificabilmente privata
La personalizzazione sul dispositivo ha lo scopo di essere privata in modo verificabile. Si concentra sulla verifica di ciò che accade al di fuori dei dispositivi degli utenti. ODP scriverà il codice che elabora i dati in uscita dai dispositivi degli utenti finali e utilizzerà l'architettura RATS (Remote ATtestation procedureS) del RFC 9334 del NIST per attestare che questo codice viene eseguito non modificato in un server deprivilegiato di amministrazione dell'istanza conforme al Confidential Computing Consortium. Questi codici saranno open source e accessibili per una verifica trasparente al fine di instaurare la fiducia. Queste misure possono dare alle persone la certezza che i loro dati sono protetti e le attività possono creare una reputazione basata su una solida base di garanzia della privacy.
La riduzione della quantità di dati privati raccolti e archiviati è un altro aspetto fondamentale della personalizzazione sul dispositivo. Aderisce a questo principio adottando tecnologie come il computing federato e la privacy differenziale, consentendo la rivelazione di pattern di dati preziosi senza esporre dettagli individuali sensibili o informazioni identificabili.
La gestione di una traccia di controllo che registri le attività relative all'elaborazione e alla condivisione dei dati è un altro aspetto chiave della privacy verificabile. Ciò consente la creazione di report di controllo e l'identificazione delle vulnerabilità, a dimostrazione del nostro impegno per la privacy.
Chiediamo collaborazioni costruttive a esperti di privacy, autorità, settori e privati per aiutarci a migliorare continuamente il design e le implementazioni.
Il grafico seguente mostra il percorso del codice per l'aggregazione e il rumore cross-device in base alla privacy differenziale.
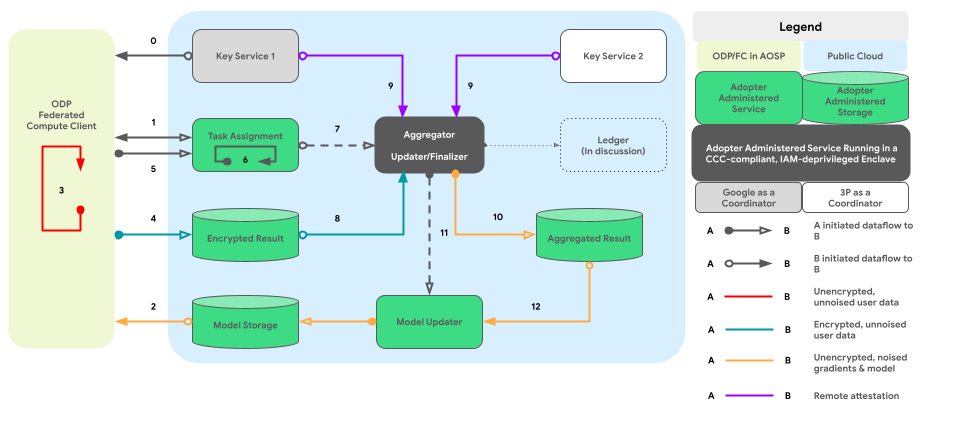
Design di alto livello
Come può essere implementata la privacy tramite la riservatezza? A livello generale, un motore di criteri creato da ODP che viene eseguito in un ambiente sigillato funge da componente di base che supervisiona ogni nodo/sottografo e monitora lo stato DP delle relative input e output:
- Dal punto di vista del motore dei criteri, dispositivi e server vengono considerati allo stesso modo. I dispositivi e i server che eseguono lo stesso motore di criteri sono considerati logicamente identici dopo che i relativi motori di criteri sono stati mutualmente attestati.
- Sui dispositivi, l'isolamento viene ottenuto tramite processi AOSP isolati (o pKVM nel lungo periodo, quando la disponibilità diventa elevata). Sui server, l'isolamento si basa su una "parte attendibile", ovvero un TEE e altre soluzioni di connessione tecnica preferite, un accordo contrattuale o entrambi.
In altre parole, tutti gli ambienti chiusi che installano ed eseguono il motore dei criteri della piattaforma sono considerati parte della nostra Trusted Computing Base (TCB). I dati possono propagarsi senza ulteriore rumore con il TCB. La crittografia lato client deve essere applicata quando i dati escono dal TCB.
Il design generale della personalizzazione sul dispositivo integra efficacemente due elementi essenziali:
- Un'architettura a processi accoppiati per l'esecuzione della logica di business
- Norme e un motore di criteri per la gestione delle operazioni di entrata, uscita e consentite dei dati.
Questo design coeso offre alle aziende una condizione di parità in cui possono eseguire il loro codice proprietario in un ambiente di esecuzione affidabile e accedere ai dati utente che hanno superato i controlli delle norme appropriati.
Le sezioni seguenti approfondiranno questi due aspetti chiave.
Architettura a processi accoppiati per l'esecuzione della logica di business
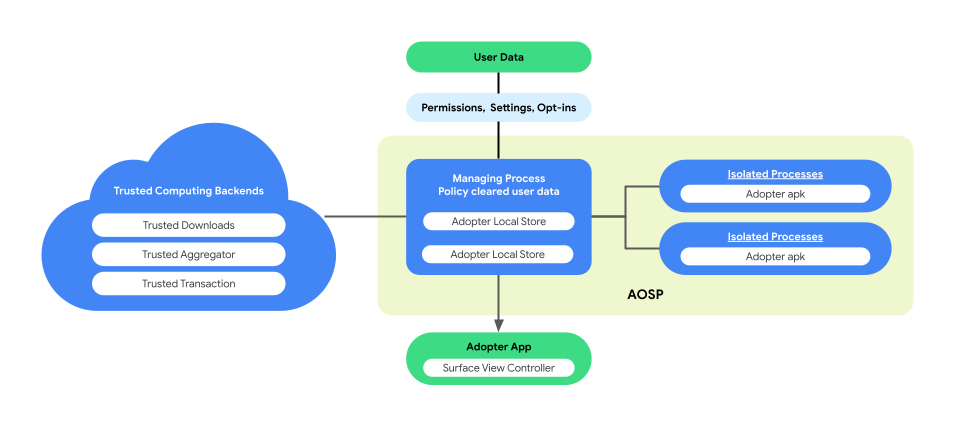
La personalizzazione sul dispositivo introduce un'architettura di processo accoppiata in AOSP per migliorare la privacy degli utenti e la sicurezza dei dati durante l'esecuzione della logica aziendale. Questa architettura è composta da:
ManagingProcess. Questo processo crea e gestisce i processi isolati, assicurandone l'isolamento a livello di processo con accesso limitato alle API consentite e senza autorizzazioni di rete o disco. Il processo di gestione gestisce la raccolta di tutti i dati aziendali, di tutti i dati degli utenti finali e delle norme, li rimuove per il codice aziendale e li inserisce in Processi isolati per l'esecuzione. Inoltre, media l'interazione tra IsolatedProcesses e altri processi, come system_server.
IsolatedProcess. Designato come isolato (
isolatedprocess=truenel file manifest), questo processo riceve dati aziendali, dati degli utenti finali cancellati in base ai criteri e codice aziendale da ManagingProcess. Consentono al codice aziendale di operare sui propri dati e sui dati degli utenti finali approvati dalle norme. Il processo IsolatedProcess comunica esclusivamente con il processo ManagingProcess per le operazioni di entrata e di uscita, senza autorizzazioni aggiuntive.
L'architettura con processi combinati offre l'opportunità di una verifica indipendente delle norme sulla privacy dei dati degli utenti finali senza richiedere alle aziende di rendere open source la logica o il codice di business. Con il metodo ManagementProcess che mantiene l'indipendenza degli IsolatedProcessi e l'esecuzione efficiente della logica di business da parte degli IsolatedProcessi, questa architettura garantisce una soluzione più sicura ed efficiente per preservare la privacy degli utenti durante la personalizzazione.
La figura seguente mostra questa architettura di processo abbinato.
Criteri e motori dei criteri per le operazioni sui dati
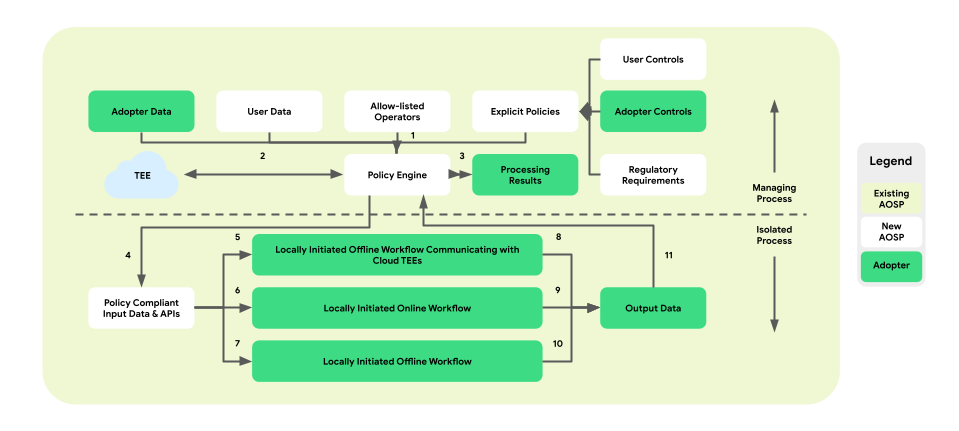
La personalizzazione sul dispositivo introduce un livello di applicazione dei criteri tra la piattaforma e la logica di business. L'obiettivo è fornire una serie di strumenti che riconoscano i controlli aziendali e degli utenti finali in modo da prendere decisioni centralizzate e strategiche sui criteri. Queste norme vengono quindi applicate in modo completo e affidabile ai flussi e alle aziende.
Nell'architettura a processo accoppiato, il motore dei criteri si trova all'interno di ManagingProcess, che supervisiona l'ingresso e l'uscita dei dati dell'utente finale e dell'azienda. Fornirà inoltre a IsolatedProcess anche le operazioni consentite. Esempi di aree di copertura includono il rispetto del controllo per gli utenti finali, la protezione dei minori, la prevenzione della condivisione dei dati senza consenso e la privacy aziendale.
Questa architettura di applicazione dei criteri comprende tre tipi di flussi di lavoro che possono essere sfruttati:
- Workflow offline avviati localmente con comunicazioni Trusted Execution Environment (TEE):
- Flussi di download dei dati: download attendibili
- Flussi di caricamento dei dati: transazioni attendibili
- Workflow online avviati localmente:
- Flussi di distribuzione in tempo reale
- Flussi di inferenza
- Flussi di lavoro offline avviati localmente:
- Flussi di ottimizzazione: addestramento del modello on-device implementato tramite la formazione federata (FL)
- Flussi di report: aggregazione cross-device implementata tramite Federated Analytics (FA)
La figura seguente mostra l'architettura dal punto di vista dei criteri e dei motori delle policy.
- Scarica: 1 -> 2 -> 4 -> 7 -> 10 -> 11 -> 3
- Porzioni: 1 + 3 -> 4 -> 6 -> 9 -> 11 -> 3
- Ottimizzazione: 2 (fornisce un piano di allenamento) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
- Reporting: 3 (fornisce un piano di aggregazione) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
Nel complesso, l'introduzione del livello di applicazione dei criteri e del motore dei criteri nell'architettura a processi accoppiati della personalizzazione sul dispositivo garantisce un ambiente isolato e incentrato sulla tutela della privacy per l'esecuzione della logica di business, fornendo al contempo accesso controllato ai dati e alle operazioni necessari.
Superfici API a livelli
On-Device Personalization fornisce un'architettura API a più livelli per le attività interessate. Il livello superiore è costituito da applicazioni create per casi d'uso specifici. Le potenziali aziende possono connettere i propri dati a queste applicazioni, note come API di livello superiore. Le API di livello superiore si basano sulle API di livello intermedio.
Nel tempo, prevediamo di aggiungere altre API di primo livello. Quando un'API di primo livello non è disponibile per un determinato caso d'uso o quando le API di primo livello esistenti non sono sufficientemente flessibili, le attività possono implementare direttamente le API di secondo livello, che offrono potenza e flessibilità tramite le primitive di programmazione.
Conclusione
La personalizzazione sul dispositivo è una proposta di ricerca in fase iniziale per sollecitare interesse e feedback su una soluzione a lungo termine che risponda ai dubbi sulla privacy dell'utente finale con le tecnologie più recenti e migliori che si prevede supportino un'elevata utilità.
Vorremmo interagire con stakeholder come esperti di privacy, analisti dei dati e potenziali utenti finali per garantire che l'ODP soddisfi le loro esigenze e risponda ai loro dubbi.